

{kind=link}
Meet KitikiPlot, a cutting-edge tool engineered to uncover and visualize complex “Sliding Window” patterns in sequential and time-series categorical data. This cutting-edge technology is engineered to equip professionals across multiple domains, including genomics, air quality monitoring, and climate forecasting, enabling them to extract valuable insights with unparalleled clarity and accuracy. Crafted with simplicity and flexibility in mind, this tool effortlessly integrates with Python’s vast information landscape, generating captivating visual outputs to facilitate seamless sample recognition. Let’s uncover its potential by transforming the approach to analyzing categorical sequences.
Studying Targets
- Can you visualize trends in sequential and time-series categorical data effectively with the KitikiPlot?
- Uncover the underlying characteristics of your data to strategically design visualizations that effectively convey insights for specific datasets and goals.
- Foster widespread adoption of KitikiPlot across diverse disciplines, including genomics, climate assessment, and atmospheric pollution surveillance.
- Python enables developers to create complex visualizations of data structures through the utilization of libraries such as matplotlib and seaborn.
- The significance of legible presentation is crucial for efficacious assessment of categorized data, thereby optimizing strategic decision-making procedures.
KitikiPlot: Simplify Advanced Knowledge Visualization
KitikiPlot is a powerful visualization tool engineered to streamline complex data presentation, ideal for applications such as sliding window graphs and real-time information visualization. It offers unparalleled flexibility, rich visualizations, and effortless integration with Python, rendering it the ideal choice for applications in genomics, air quality monitoring, and climate forecasting. KitikiPlot seamlessly converts raw data into compelling visualizations, empowering users to unlock insights with ease thanks to its adaptable settings.
- The KitikiPlot library is a Python tool that enables users to visualize sequential and time-series categorical data using the Sliding Window approach.
- The time period ‘kitiki‘(కిటికీ) means ‘window‘ in Telugu.
Key Options
- Sliding Window: The visual representation comprises a series of identical rectangular bars, each equivalent to data extracted from a specific moving window.
- Body: Each bar is divided into a series of rectangular cells called “frames,” which are arranged alongside one another, each representing a value from the sequential categorization of information.
- Customization Choices: Customers have a wide range of options to customize their home windows, including the ability to choose from various color schemes, hatching patterns, and alignment settings.
- Versatile Labeling: Customers are permitted by the library to customize labels, titles, tick marks, and legends according to their individual preferences.
What’s your creative vision? With KitikiPlot, you’re just a few steps away from bringing it to life!
Discover the thrilling realm of KitikiPlot with this concise introduction. Let’s guide you seamlessly through every stage of setting up your data, culminating in a stunning visualization that showcases your insights with clarity and precision.
Set up KitikiPlot utilizing pip
pip set up kitikiplotImport “kitikiplot”
import pandas as pd from kitikiplot import KitikiPlotLoad the dataframe
The thought-provoking analysis of ‘weatherHistory.csv’ has begun!
df = pd.read_csv(PATH_TO_CSV_FILE) print(f"Initial form: {df['form'].head(1)}") df = df.iloc[45:65, :] print(f"After filtering form: {df['form'].head(1)}") df.head(3)
ktk = KitikiPlot(information=df['Summary'].tolist()); ktk.plot() 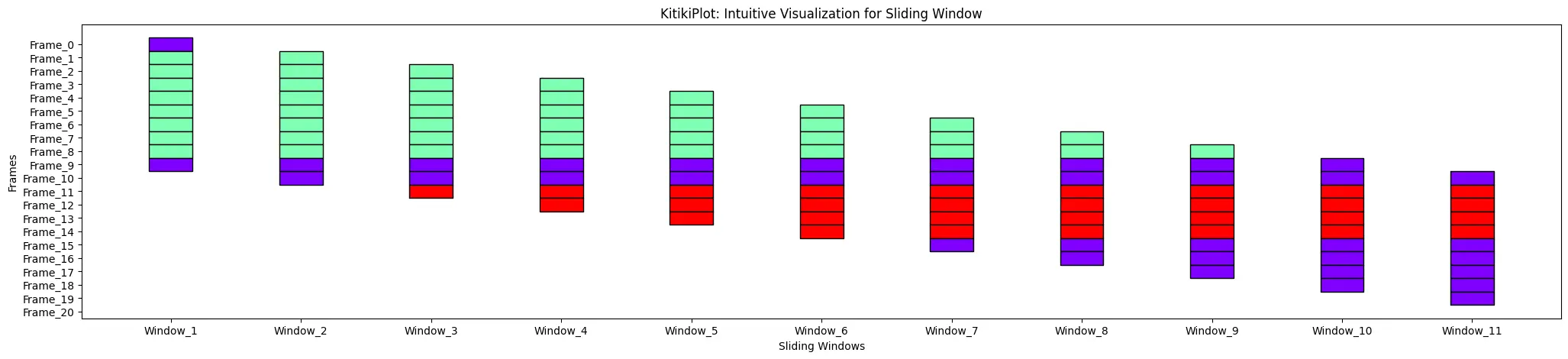
Understanding KitikiPlot Parameters
To fully harness the capabilities of KitikiPlot, it’s crucial to comprehend the diverse settings that govern the visualization of your data. By adjusting these parameters, you can create customized point markers that precisely match your specific window measurements, step intervals, and preferred settings, ensuring your visualizations are meticulously tailored to meet your unique needs. As we delve into the intricacies of these crucial factors, stride and window_length That said, refining your storylines can ultimately lead to more satisfying conclusions and enhanced reader engagement.
stride : int (elective)
- What are the different components involved in converting an inventory into a pandas DataFrame?
- Default is 1.
Index = 0: ktk = KitikiPlot(information=df["Summary"].values.tolist()); ktk.plot(cell_width=2, transpose=True)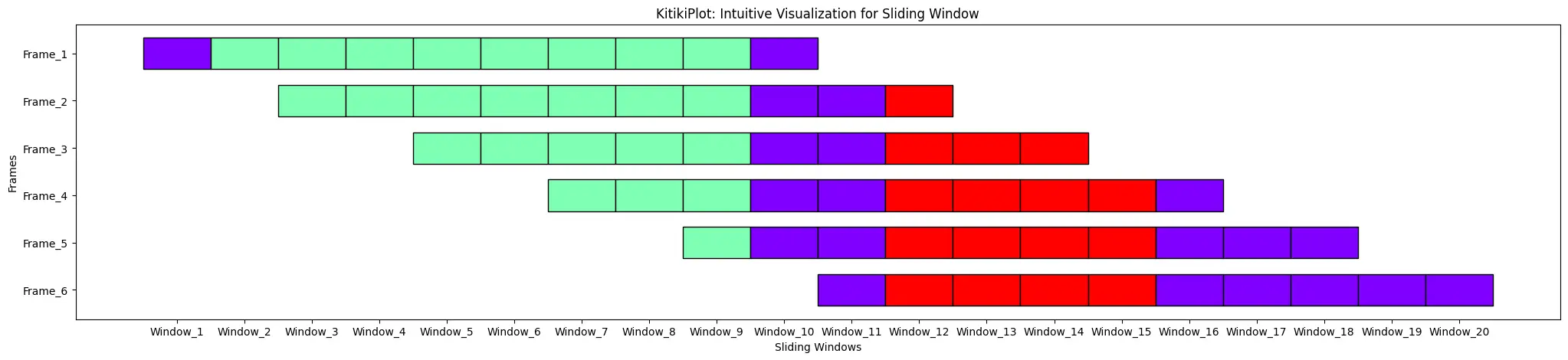
window_length : int (elective)
- What is the ideal size for each window when converting an inventory into a DataFrame?
- Default is 10.
index = 0 KitikiPlot(information=df['Summary'].values.tolist(), window_length=5).plot(transpose=True, xticklabels=["Body" + str(i) for i in range(index+1)], yticklabels=["Window " + str(i) for i in range(1,6)], cell_width=2) 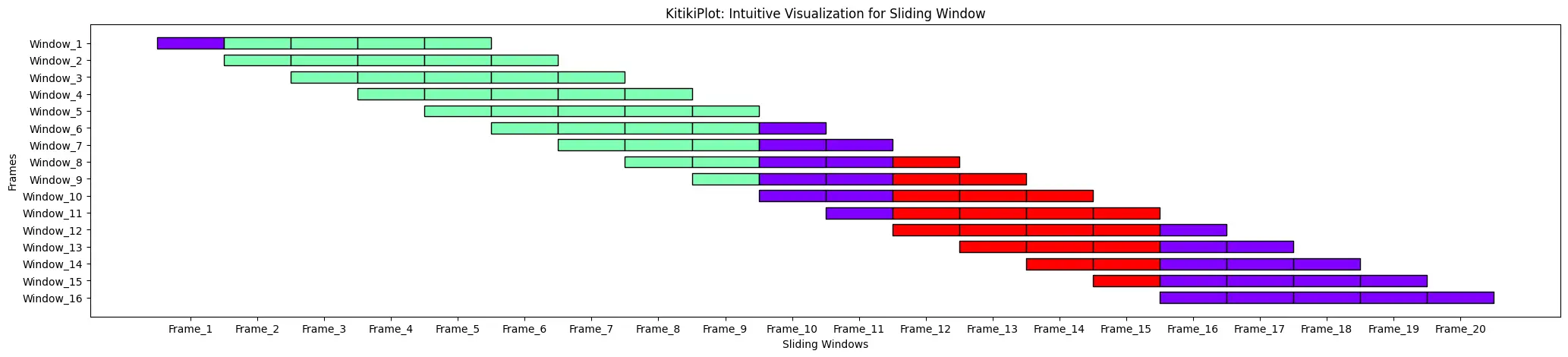
figsize : tuple (elective)
- The scope of determination (width, magnitude).
- Default is (25, 5).
ktk = KitikiPlot(information=df[“Summary”].values.tolist()) ktk.plot(figsize=(20, 8))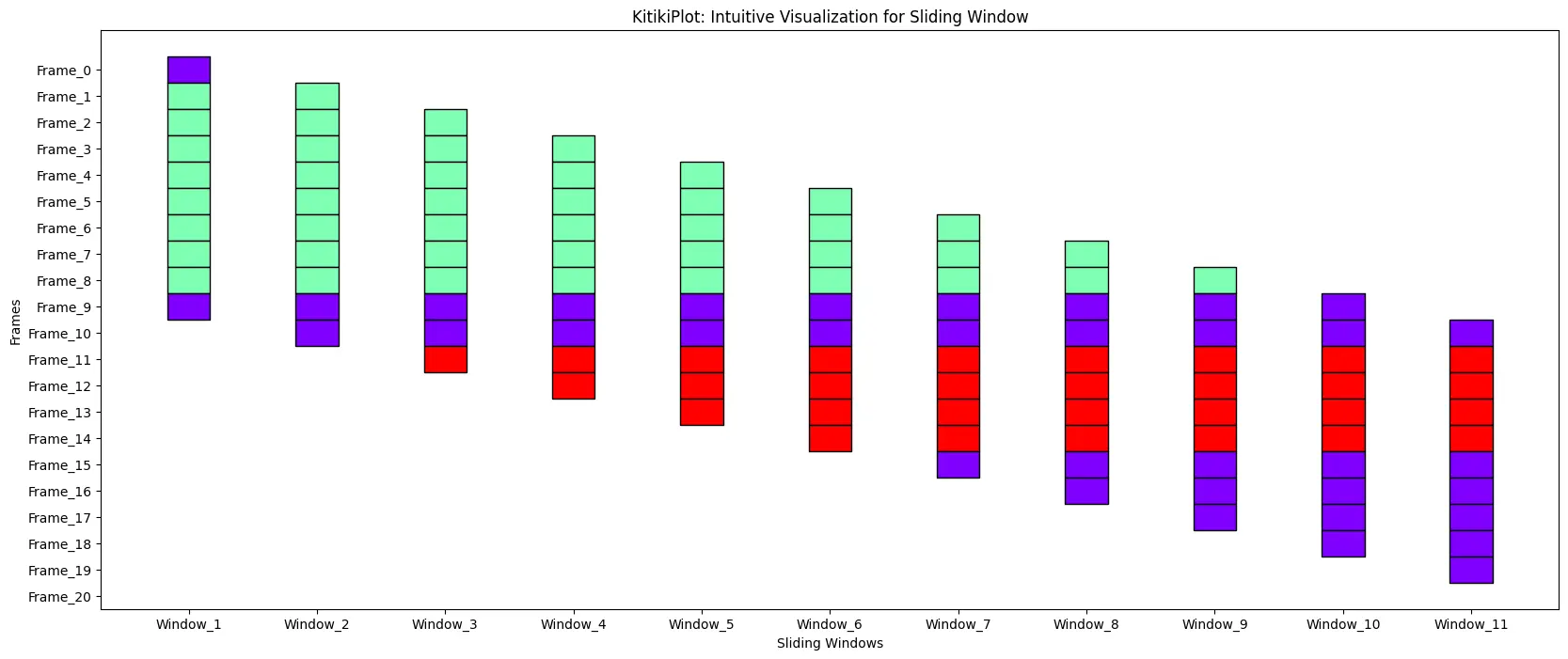
cell_width : float
- The width of each individual cell within the grid.
- Default is 0.5.
import matplotlib.pyplot as plt ktk = KitikiPlot() ktk.add_information(df["Summary"].tolist()) ktk.plot(cell_width=2)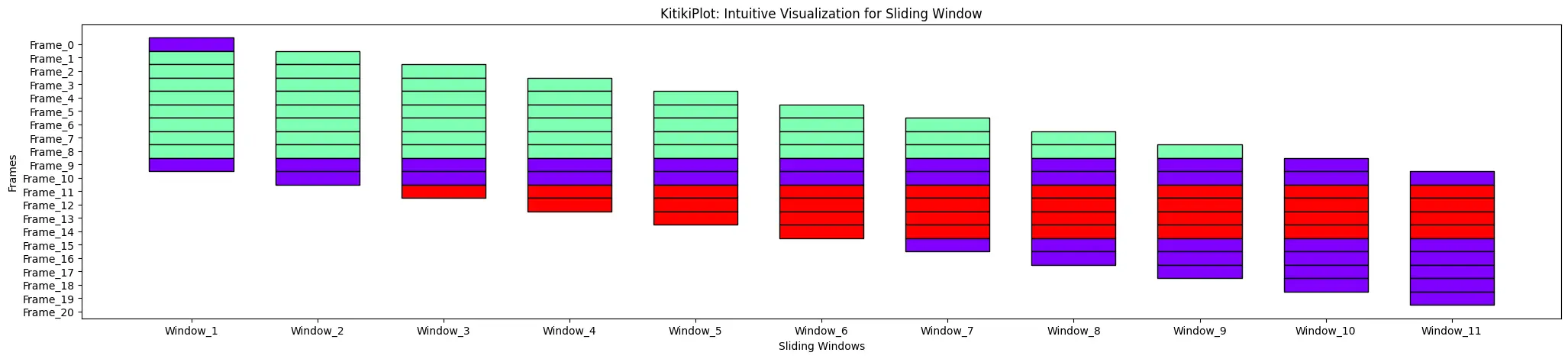
cell_height : float
- What are the peaks of every cell within the grid?
- Default is 2.0.
import matplotlib.pyplot as plt ktk = plt.figure(figsize=(10,6)) ktk.axis('off') ktk.text(0.5, 1.5, '\n'.join(df['Summary'].values.tolist()), ha='center')
transpose : bool (elective)
- IsTransposing?
- Default is False.
ktk = KitikiPlot(information=df["Summary"].tolist())
ktk = KitikiPlot(information=df["Summary"].values.tolist()) ktk.plot(cell_width=2, transpose=True, xtick_prefix="Body", ytick_prefix="Window", xlabel="Frames", ylabel="Sliding Windows")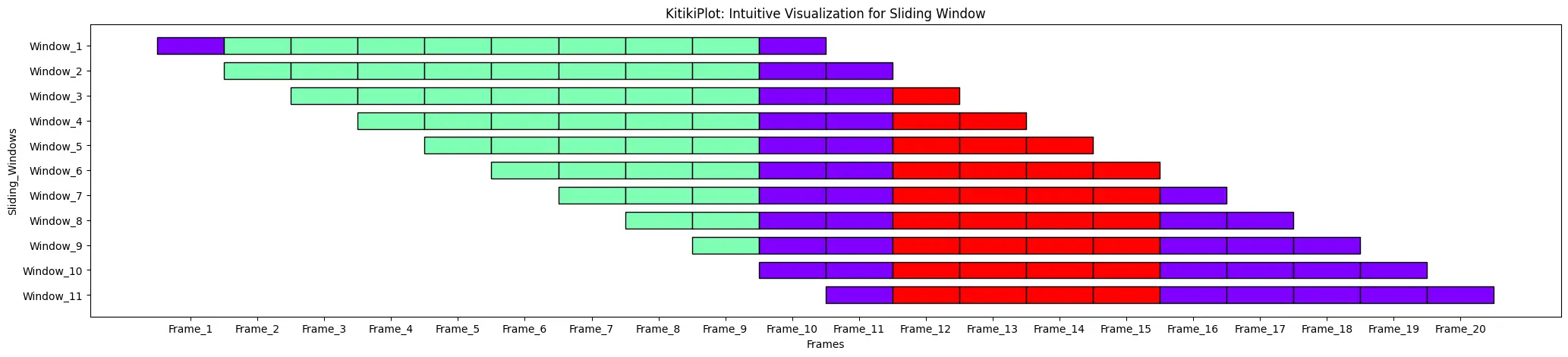
window_gap : float
- The space between cells within a grid.
- Default is 1.0.
kitki = KitikiPlot(information=df['Summary'].tolist()); kitki.plot(window_gap=3)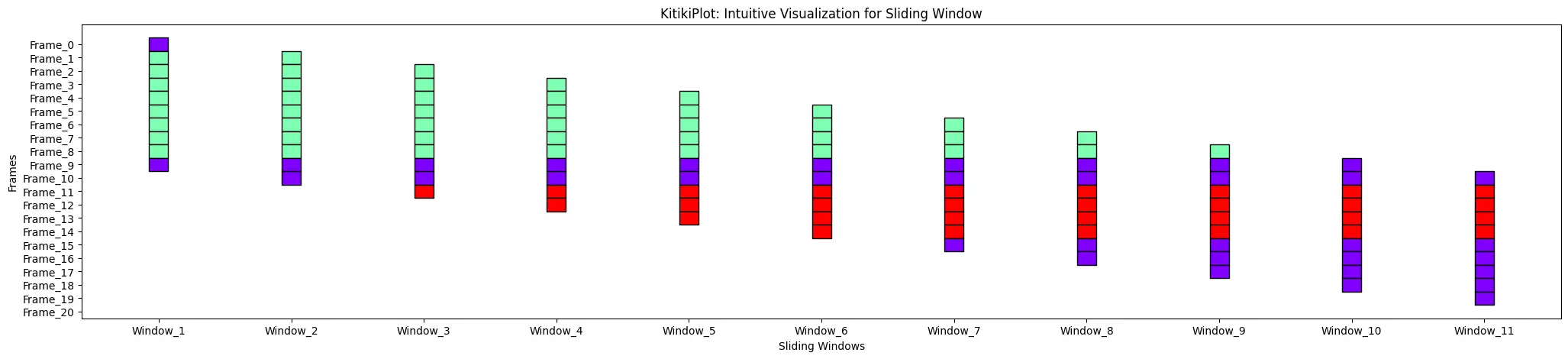
window_range: Optional[str | Tuple]
- The range of home windows to display?
- You can access and manipulate data in multiple cells across an entire worksheet using `all`. For example:
To get the values of all home windows, you can use: `ws[‘A1’: ‘E10’].value_all()`
- Default is “all”.
KTKitiPlot(information=df["Summary"].tolist())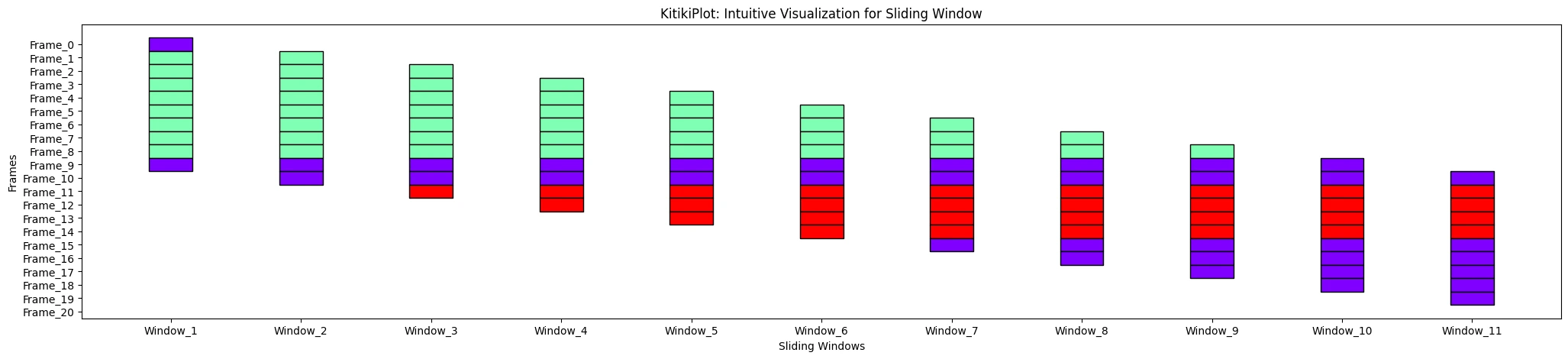
As a professional editor, I'd suggest the following revised text: KitikiPlot(information=df["Summary"].tolist()).plot(window_range=(3, 8))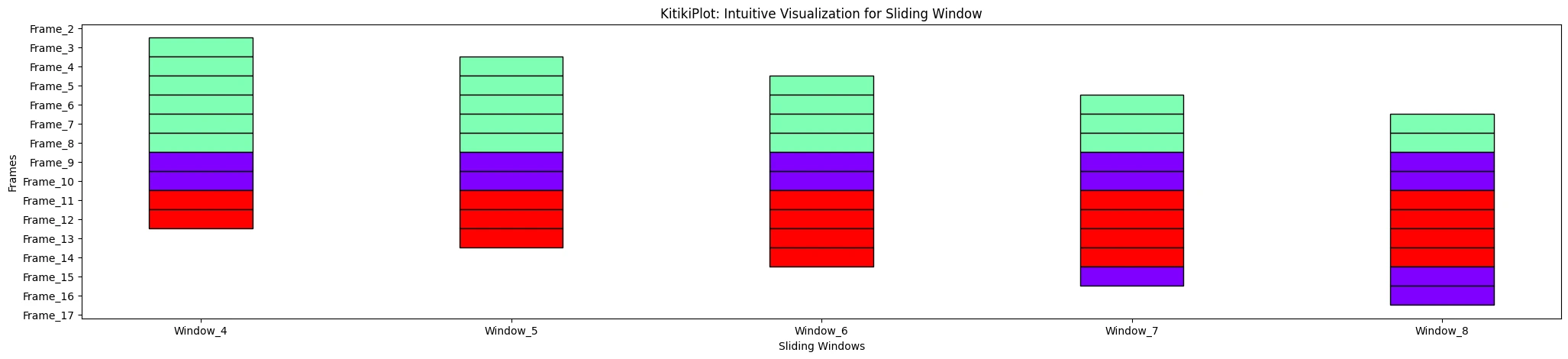
align : bool
- Does the direction of shifting depend on whether transpose is true or false?
- Default is True.
ktk = KitikiPlot(information=df["Summary"].tolist()); ktk.plot(align=True)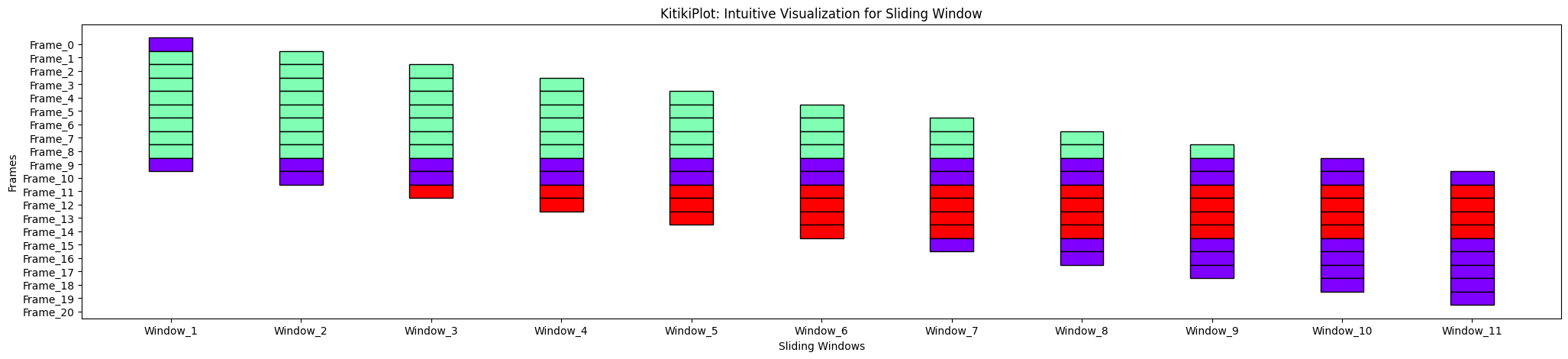
ktk.plot(align=False, display_yticks=None)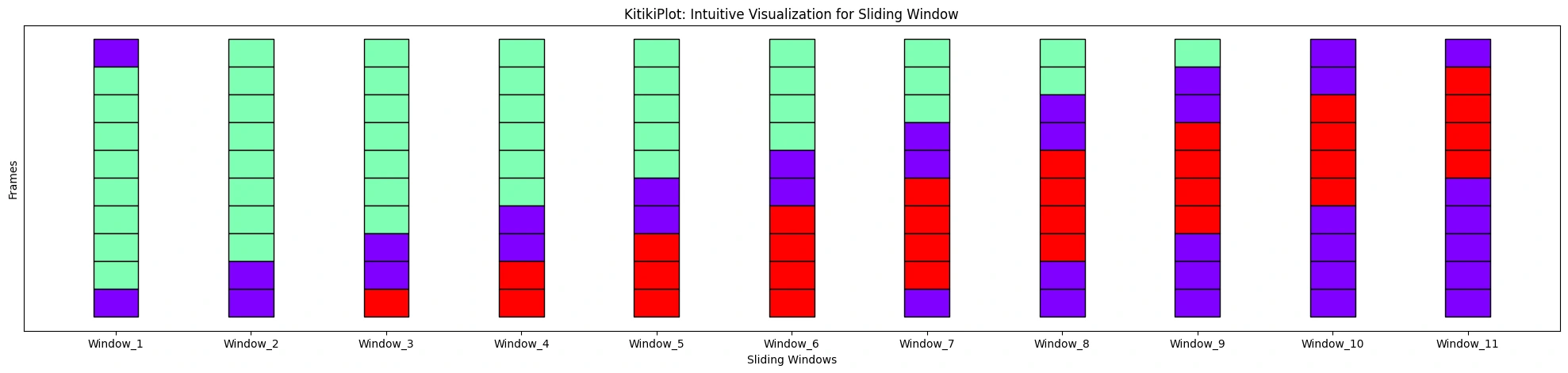
ktk.plot(cell_width=2, align=True, transpose=True, xlabel="Frames", ylabel="Sliding Home Windows", xtick_prefix="Body", ytick_prefix="Window")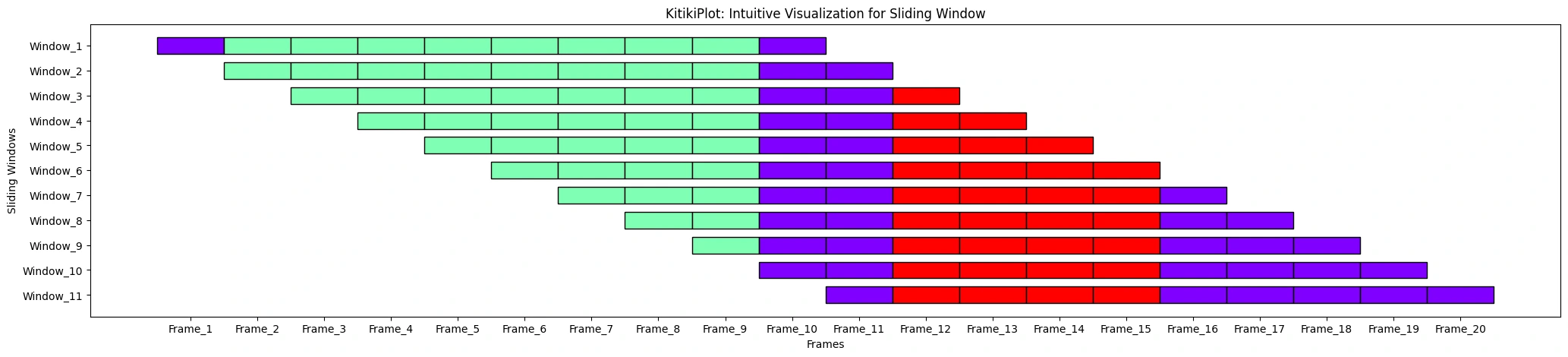
ktk.plot(cell_width=2, align=False, transpose=True, xlabel="Frames", ylabel="Sliding Home Windows", ytick_prefix="Window", display_xticks=False)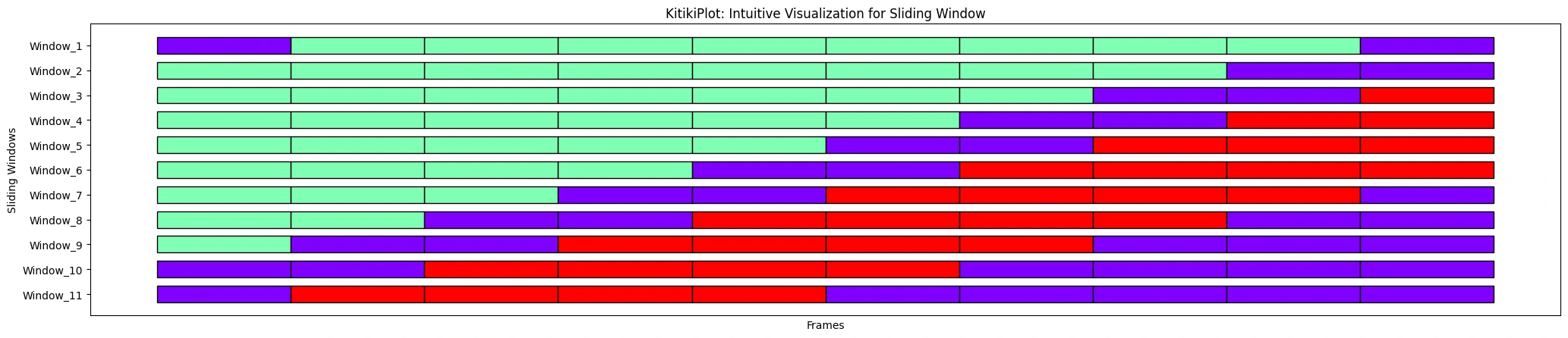
cmap : str or dict
- A string that identifies a colormap must be used to generate colors.
- If a colour mapping dictionary is implemented, it should effectively pair unique values with specific hues.
- Default is ‘rainbow’.
ktk = KitikiPlot(information=df["Summary"].values.tolist()) ktk.plot(cmap="Greens", display_legend=True)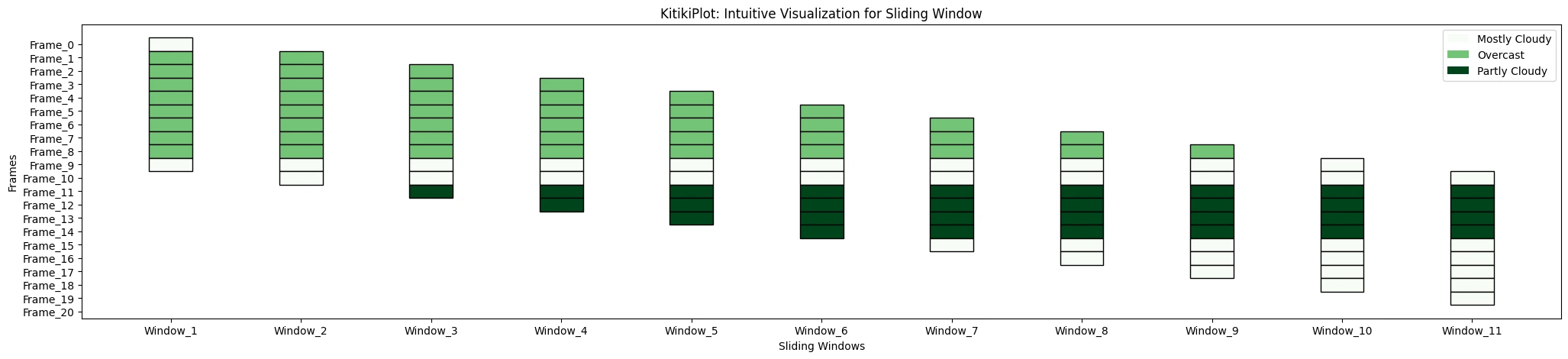
ktk.plot(cmap={"Largely Cloudy": "Inexperienced"}, display_legend=True)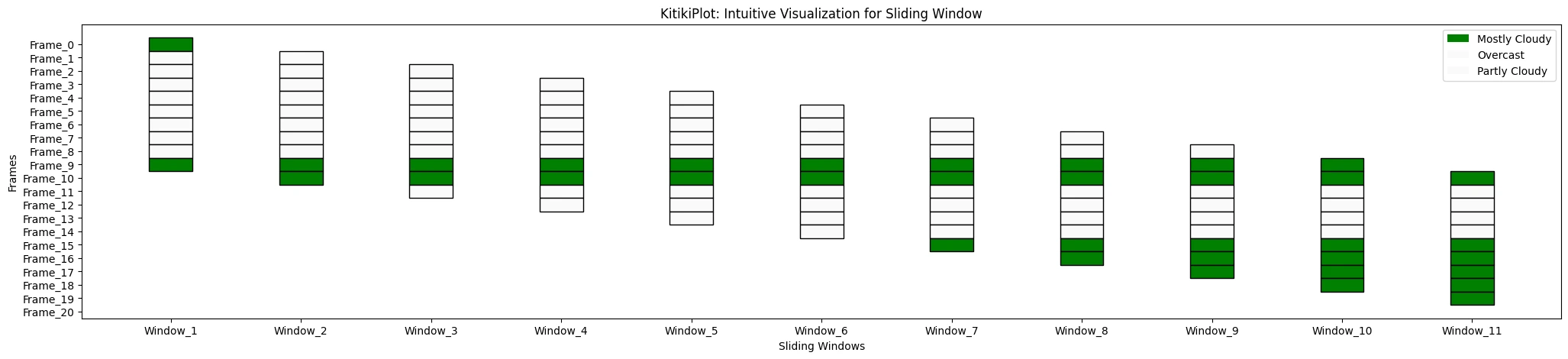
edge_color : str
- What color should be used for the borders of a rectangle?
- Default is ‘#000000’.
ktp.plot( colormap={"Largely Cloudy": "Inexperienced"}, default_color="wheat", outline_color="blue" )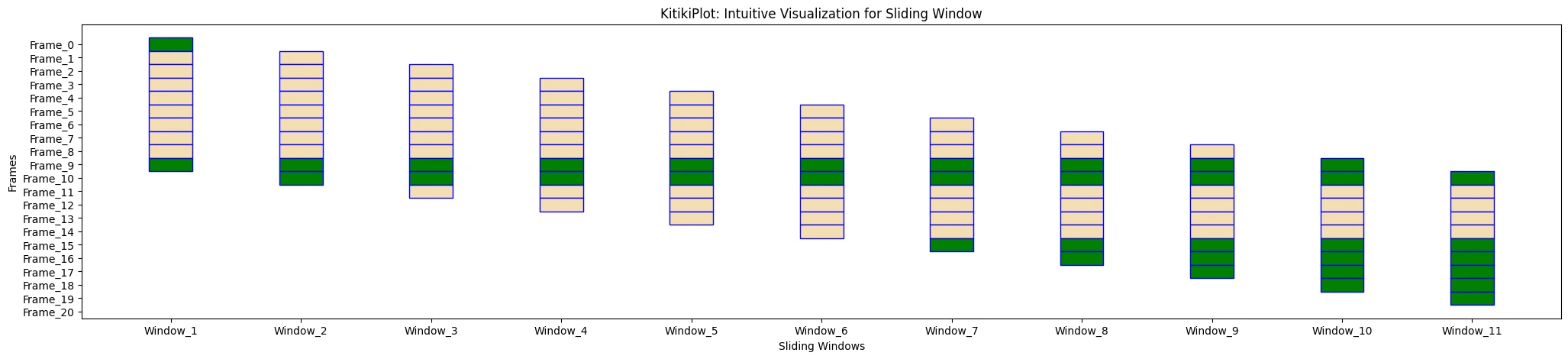
fallback_color : str
- The neutral hue to fall back upon in the absence of a specific colour designation.
- Default is ‘#FAFAFA’.
ktk.plot( cmap={"Largely Cloudy": "#3498db"}, # Inexperienced -> A more specific color code fallback_color="#f7f7f7", # wheat -> A more neutral, common color display_legend=True )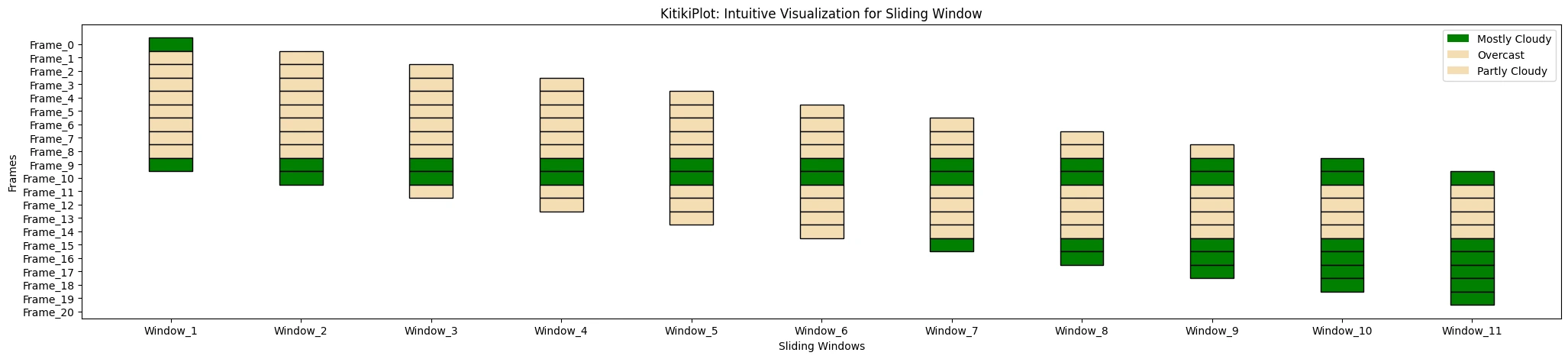
hmap : dict
- A comprehensive dictionary mapping unique values to their respective hatch patterns for efficient data visualization and interpretation.
- Default is ‘{}’.
KitikiPlot(information=df["Summary"].values.tolist()).plot(cmap={"Largely Cloudy": "gray"}, fallback_color="white", hatchmarker={}, display_hatch=True)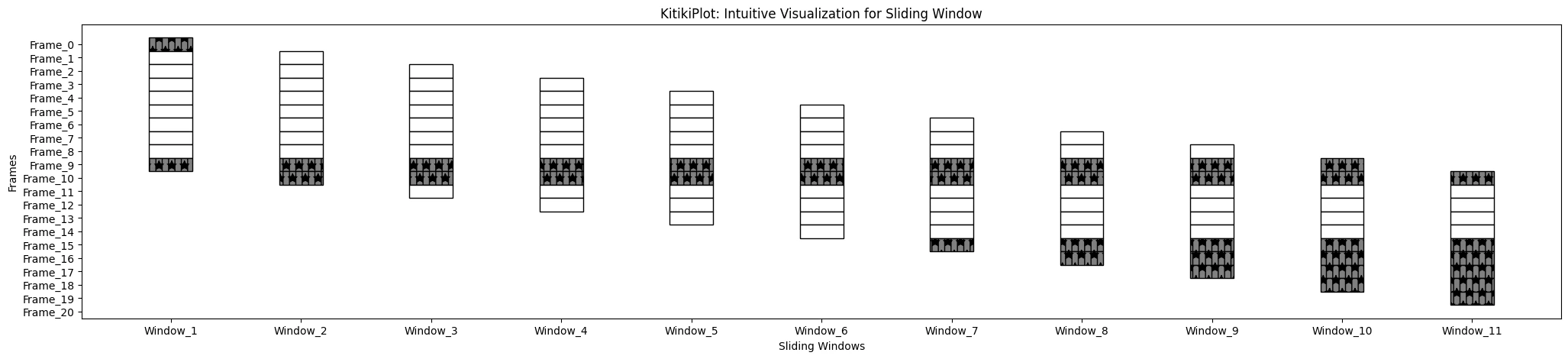
fallback_hatch : str
- A standard hatch sample to use as a fallback when no specific hatch is designated.
- The default is ‘“ “’ (quotation marks with double spaces).
KitikiPlot(information=df["Summary"].values.tolist()).plot(cmap={"Largely Cloudy": "gray"}, fallback_color="white", hatch_map="", fallback_hatch="", display_hatch=True)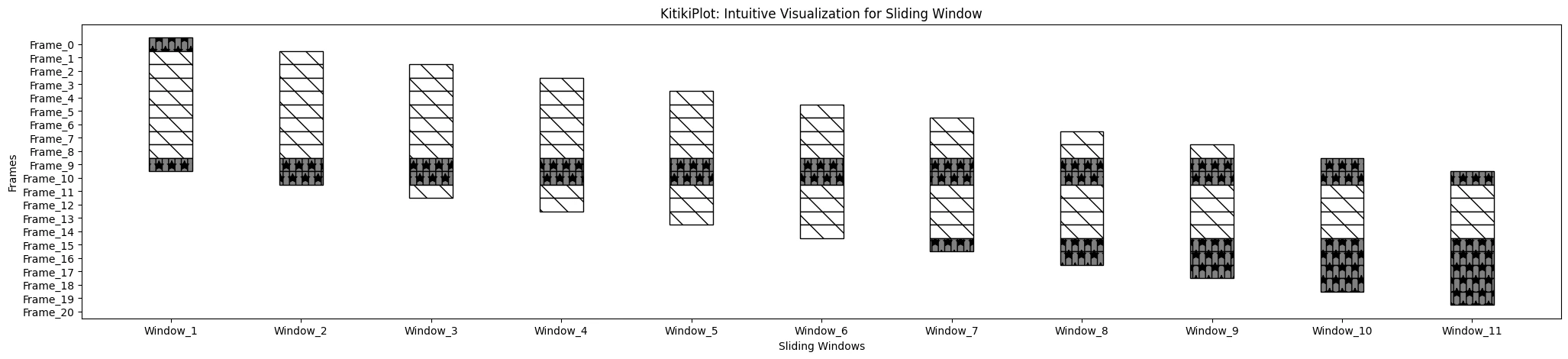
display_hatch : bool
- The option to display hatch patterns on cells?
- Default is False.
ktk = KitikiPlot(information=df['Summary'].values.tolist()) ktk.plot( cmap={"Largely Cloudy": "#FFFFFF"}, fallback_color="#FFFFFF", display_hatch=True, )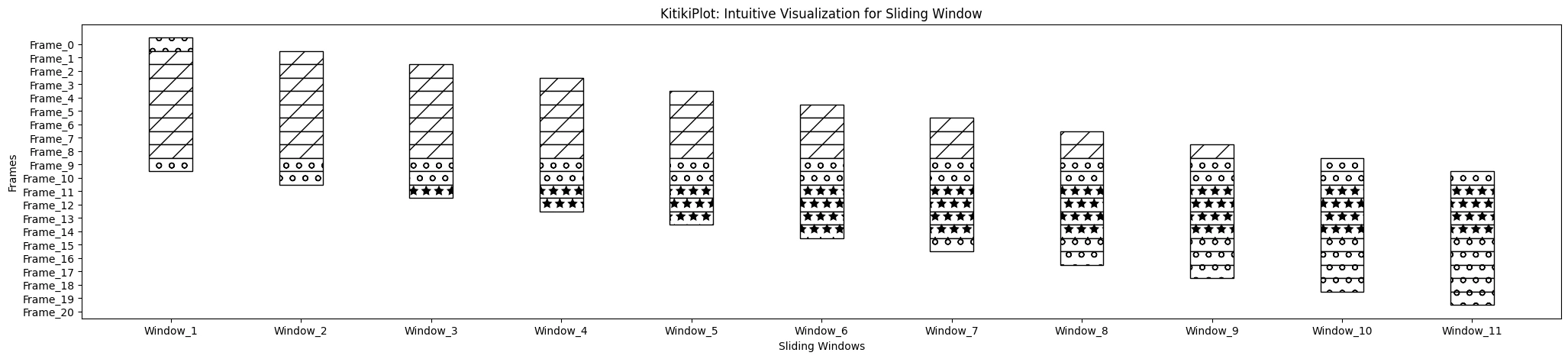
xlabel : str (elective)
- Label for the x-axis.
- Default is “Sliding Home windows”.
KTKitkiPlot(information=df['Summary'].values.tolist()).plot(xlabel='Commentary Window')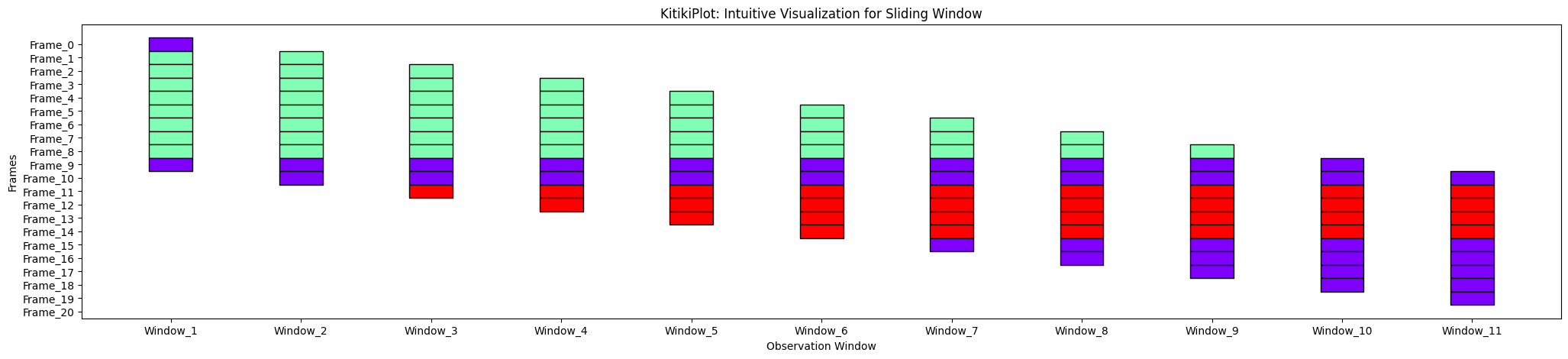
ylabel : str (elective)
- Label for the y-axis.
- Default is “Frames”.
kitki_plot = KitikiPlot(information=df["Summary"].tolist()) kitki_plot.plot(ylabel='Body ID')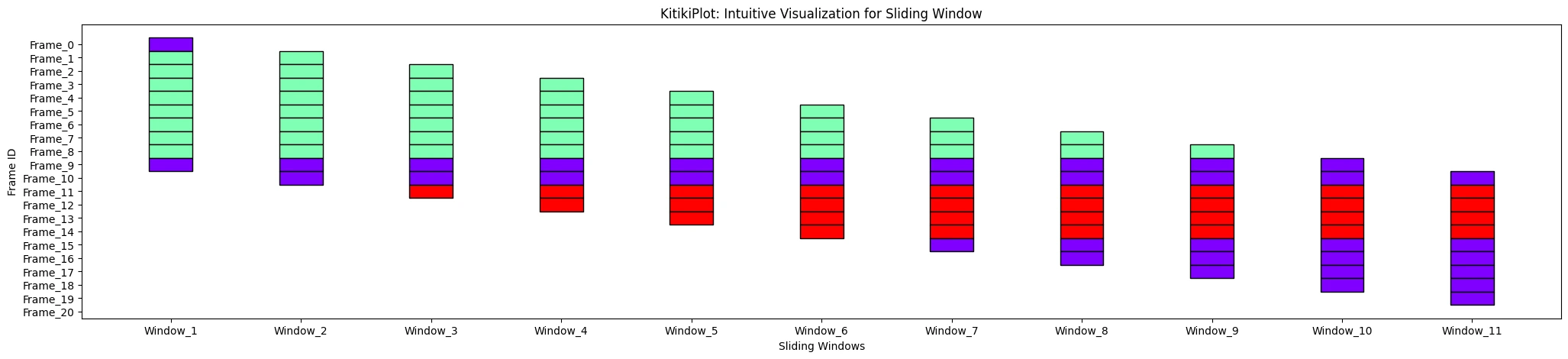
display_xticks : bool (elective)
- Whether to display tick marks along the x-axis?
- Default is True.
KitikiPlot(information=df[“Summary”].values.tolist()).plot(display_xticks=False)
display_yticks : bool (elective)
- show_yticks?
- Default is True
ktk = KitikiPlot(information=df['Summary'].tolist()); ktk.plot(display_y_ticks=False)
xtick_prefix : str (elective)
- Prefix for x-axis tick labels.
- Default is “Window”.
kitki_plot = KitikiPlot(information=df["Summary"].values.tolist()) kitki_plot.plot(xtick_labels=["{} {}".format("Commentary", i) for i in range(len(df))])
ytick_prefix : str (elective)
- Prefix for y-axis tick labels.
- Default is “Body”.
ktk = KitikiPlot(information=df[\"Summary\"].tolist()) ktk.plot(yticks=[f"Time {i+1}" for i in range(len(df))])
xticks_values : checklist (elective)
- ?{‘xticks’: [(0.0, ‘Zero’), (1.0, ‘One’), (2.0, ‘Two’), (3.0, ‘Three’), (4.0, ‘Four’), (5.0, ‘Five’)]}
- Default is []
KitikiPlot(information=df["Summary"].values.tolist()).plot(xticks=xtick_values)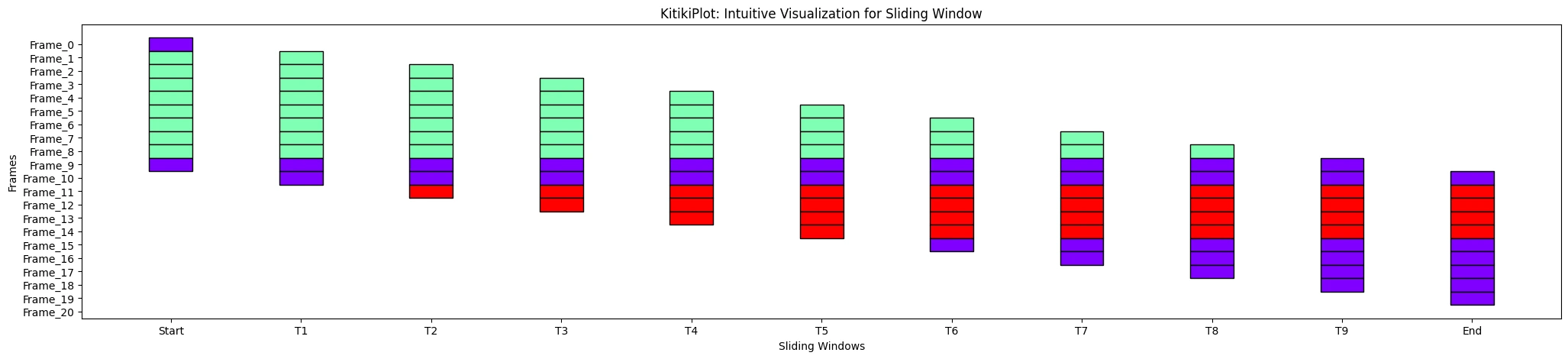
yticks_values : checklist (elective)
- yvalues = [0.00, 5.00, 10.00, 15.00, 20.00]
- Default is []
ktk = KitikiPlot(information=df["Summary"].values.tolist()) yticks_values = [f"{i.hour} {i.strftime('%p').lower()}" for i in pd.to_datetime(df["Formatted Date"])] ktk.plot(yticks=yticks_values)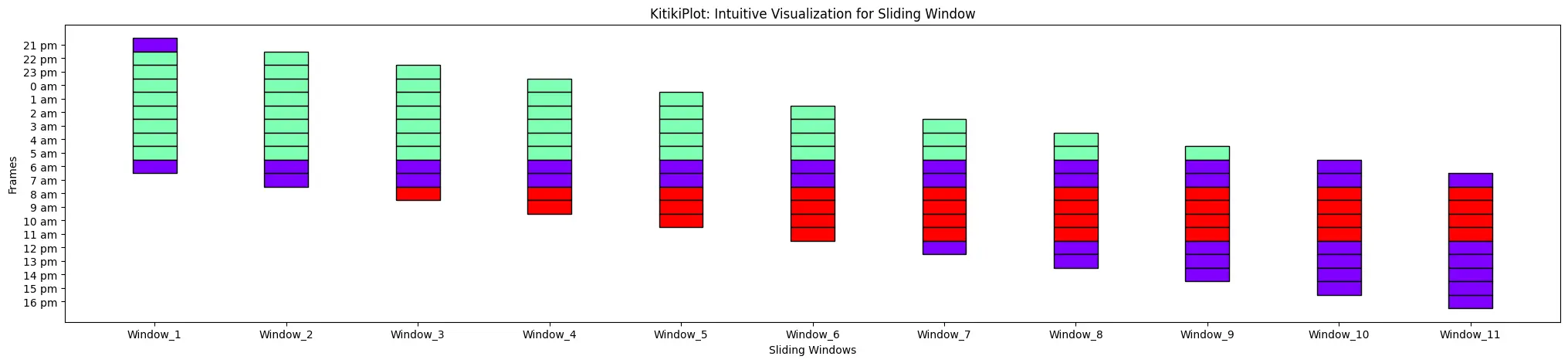
xticks_rotation : int (elective)
- Rotation angle for x-axis tick labels? 45
- Default is 0.
ktk = KitikiPlot(information=df['Summary'].values.tolist()); ktk.plot(xticks_rotation=45)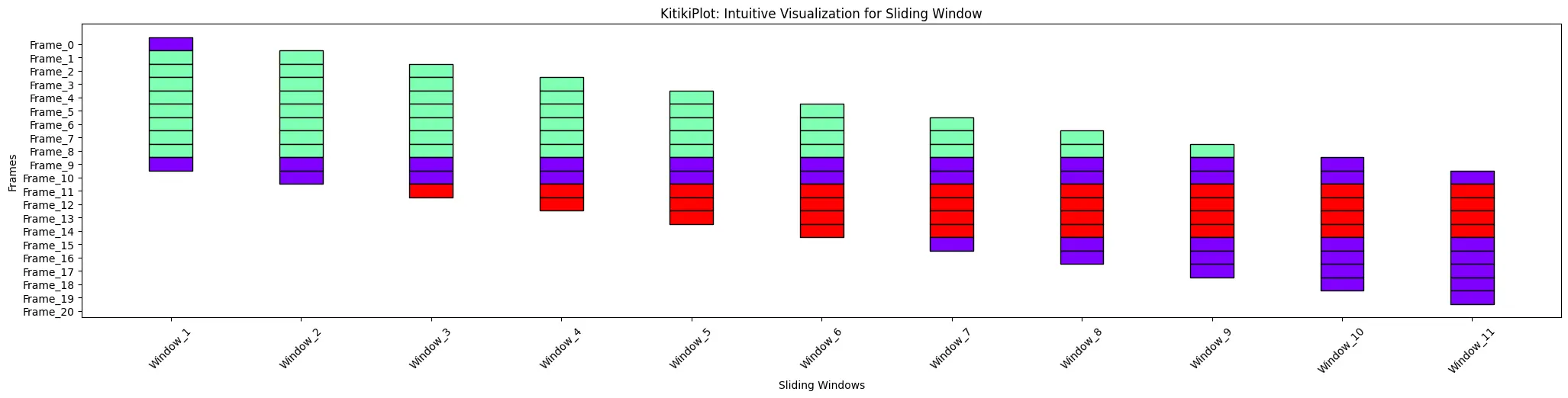
yticks_rotation : int (elective)
- Rotation angle for y-axis tick labels?
- Default is 0.
ktk = KitikiPlot(information=df['Summary'].values.tolist()); ktk.plot(figsize=(15,5), yticks_rotation=45)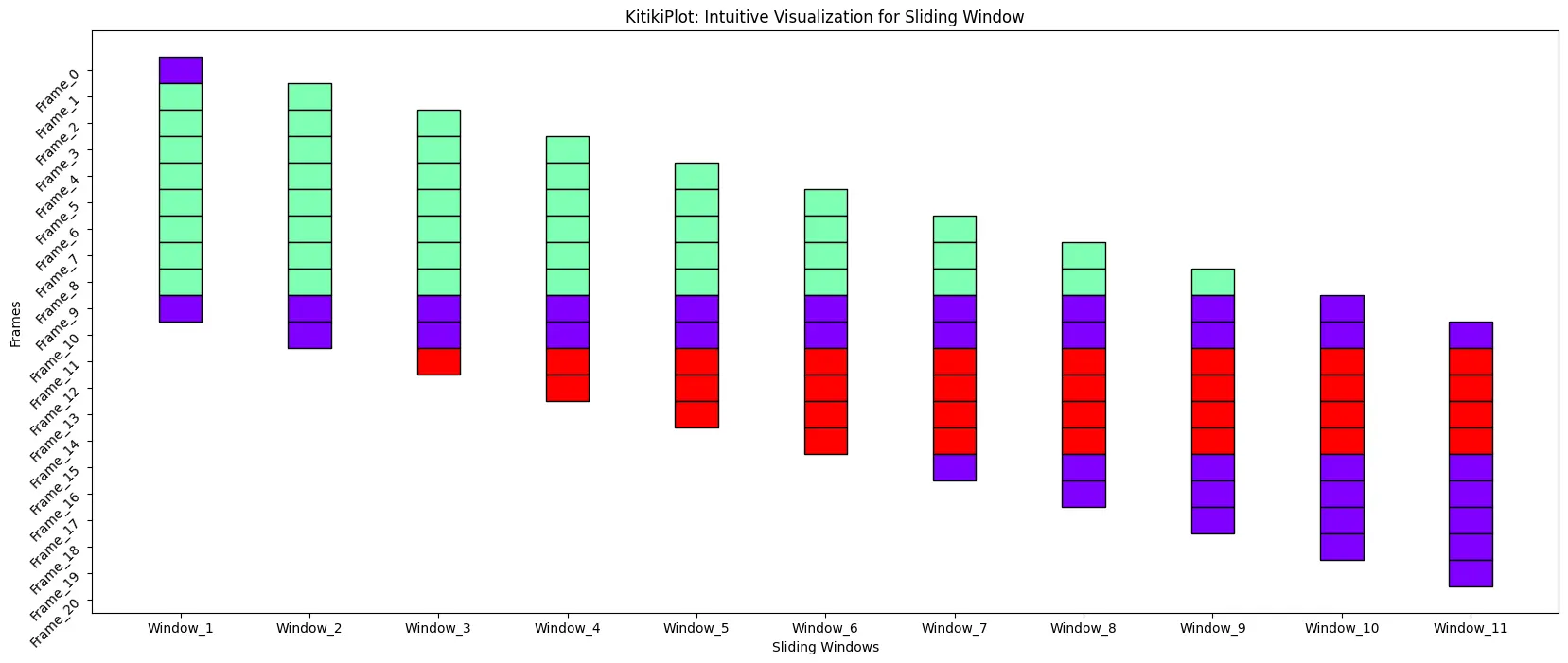
title : str (elective)
- The title of the plot.
- KitikiPlot: An Intuitive Visualization Solution for Effective Sliding Window Analysis.
ktk = KitikiPlot(information=df[“Summary”].values.tolist()) ktk.plot(title="Climate Dataset: KitikiPlot Insights")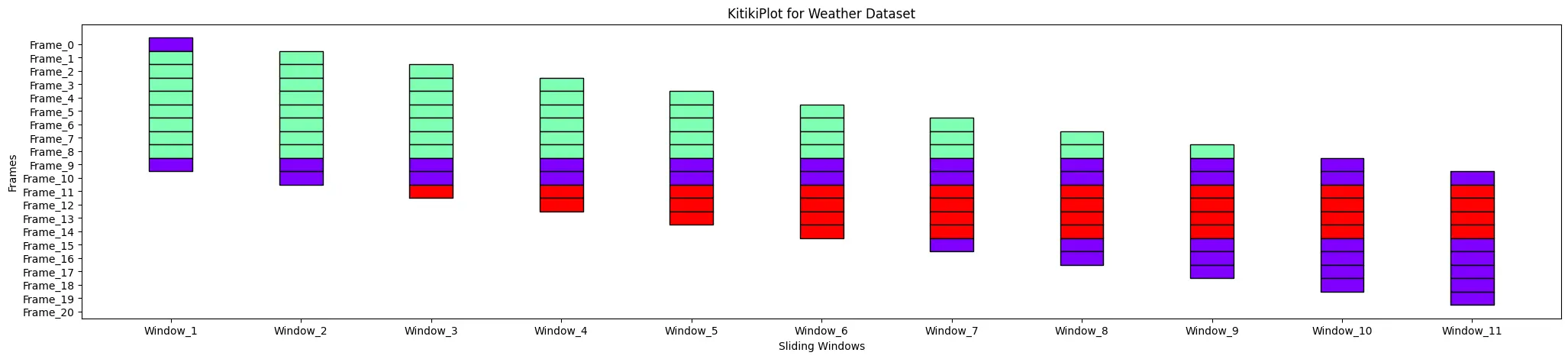
display_grid : bool (elective)
- Whether a grid should be displayed on the plot, as indicated by this toggleable flag.
- Default is False.
ktk= KitikiPlot( information= df["Summary"].values.tolist()[:15] ) ktk.plot( display_grid= True )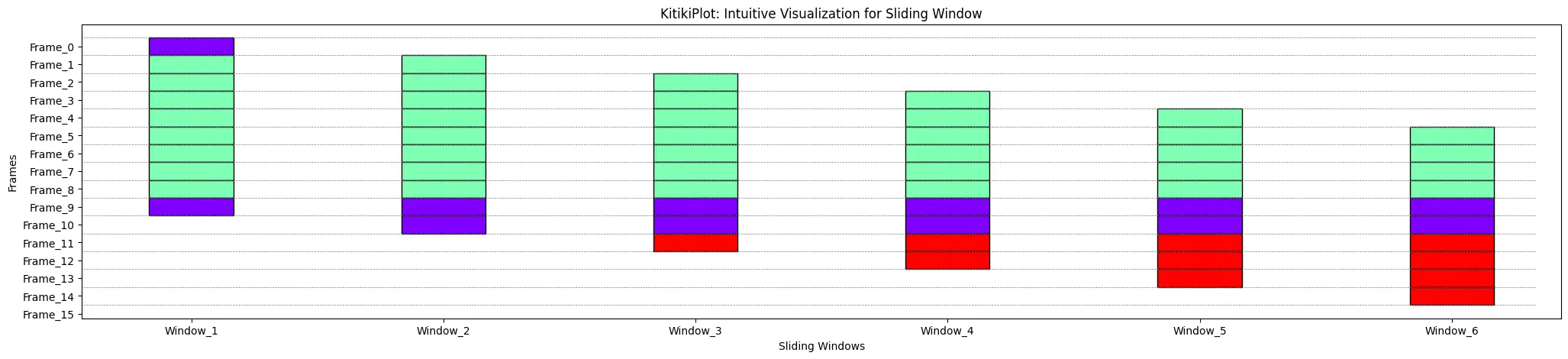
KitikiPlot(information=df["Summary"].values.tolist()[:15]).plot(cell_width=2, transpose=True, xlabel="Frames", ylabel="Windows", ytick_prefix="Window", display_xticks=False, display_grid=True)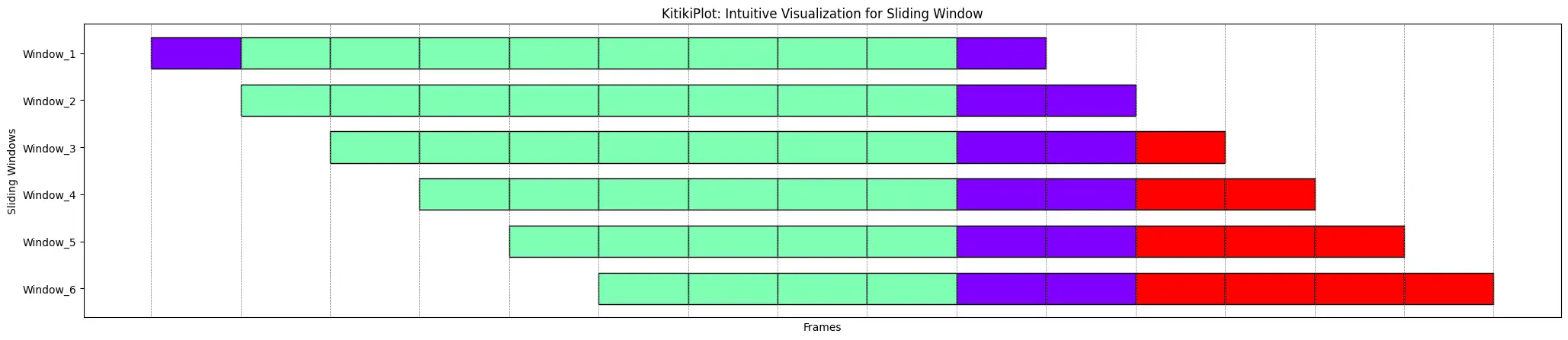
display_legend : bool (elective)
- Whether to display a legend on the plot.
- Default is False.
ktk = KitikiPlot(information=df[“Summary”].values.tolist()); ktk.plot(display_legend=True)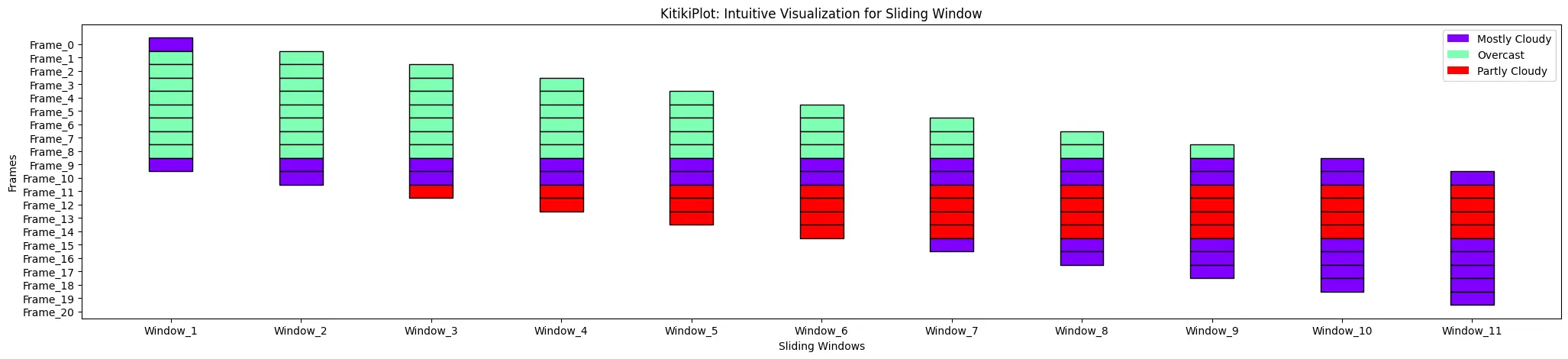
legend_hatch : bool (elective)
- The option to include hatch patterns in the legend?
- Default is False.
KitikiPlot(information=df["Summary"].values.tolist()).plot(cmap={"Largely Cloudy": "#ffffff"}, fallback_color="white", display_hatch=True, display_legend=True, legend_hatch=True)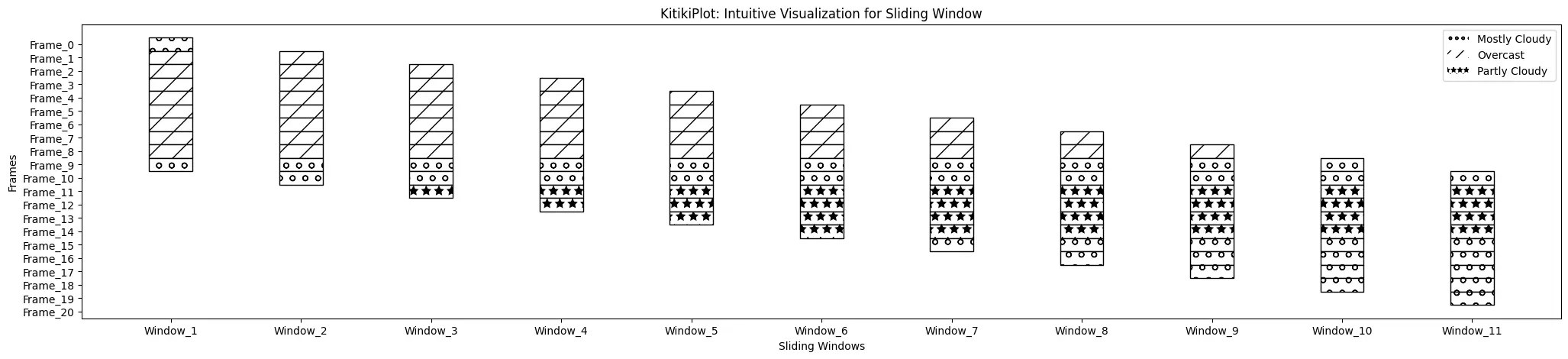
legend_kwargs : dict (elective)
- Customized legend arguments received with supplementary key phrases.
- Default is {}.
The landscape unfolded before them, a canvas of tumbled boulders and scrubby foliage stretching towards the horizon.
KitikiPlot(information=df["Summary"].values.tolist()[:15]).plot(figsize=(15, 5), display_legend=True, legend_kwargs={"bbox_to_anchor": (1, 1.0), "loc": "upper right"})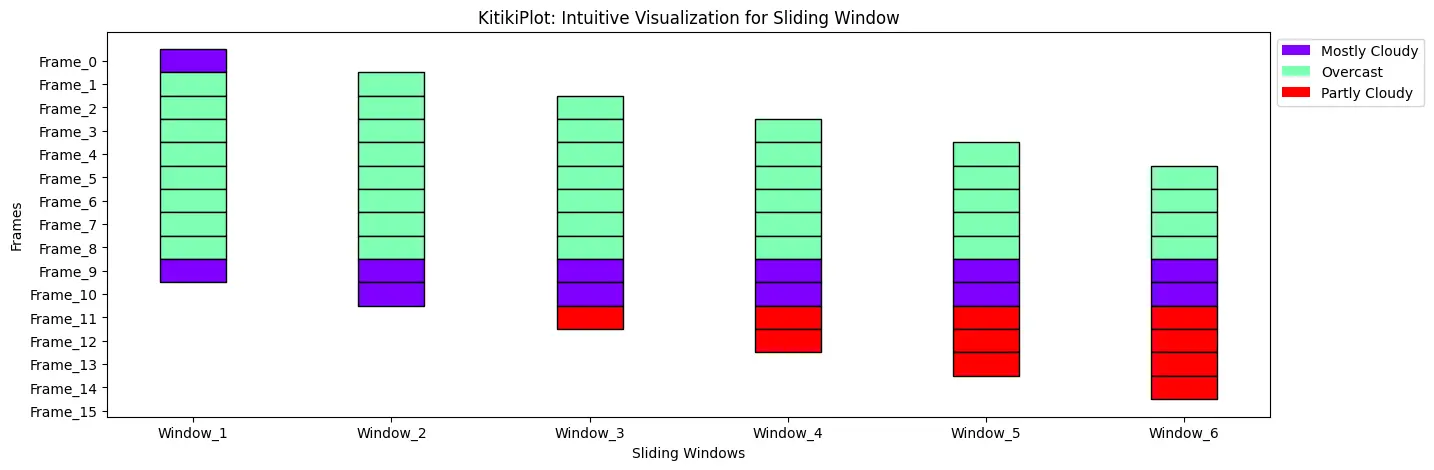
Set title for the legend————————————
KitikiPlot(information=df["Summary"].values.tolist()[:15]).plot(figsize=(15, 5), display_legend=True, legend_kwargs={"title": "Climate Circumstances"})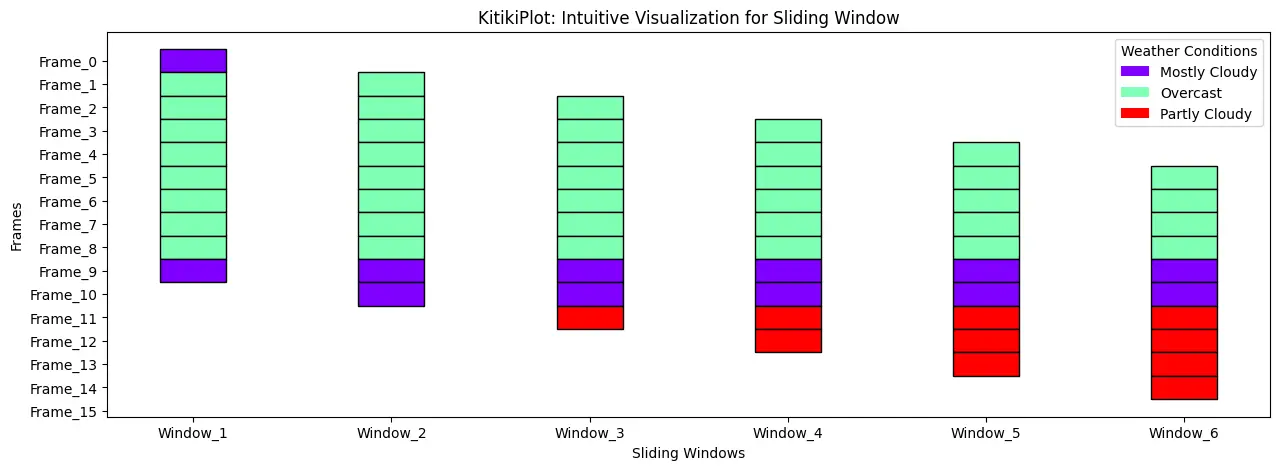
Change edgecolor of the legend
ktk = KitikiPlot(information=df[“Summary”].values.tolist()[:15]) ktk.plot(figsize=(15,5),display_legend=True,legend_kwargs={"edgecolor":"lime"},title="Kitiki Plot",xlabel="Index",ylabel="Values")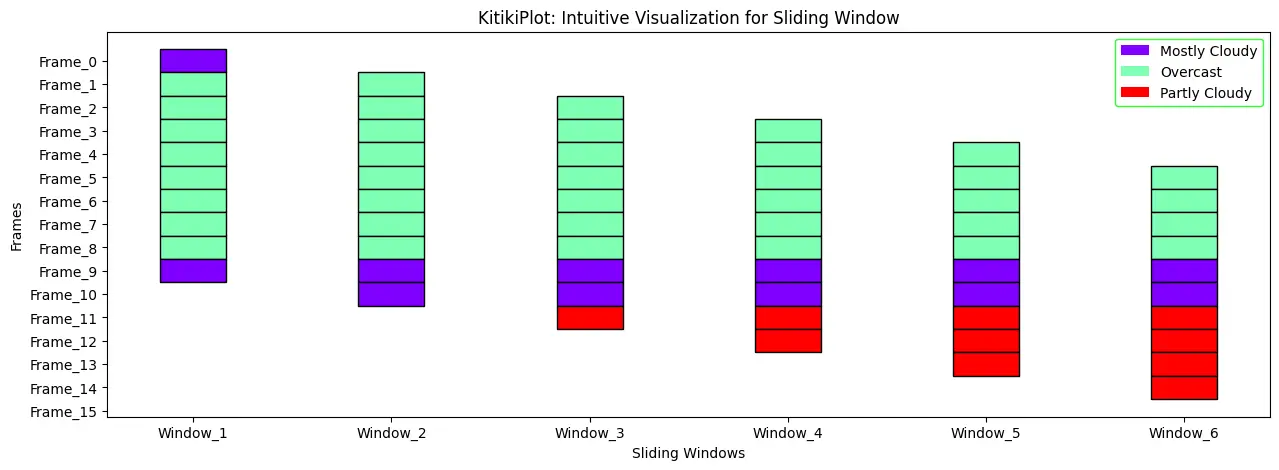
kitiki_cell_kwargs : dict (elective)
- Customizable key phrase arguments are handed to specific individual cells for tailored processing.
- Default is {}.
Set the road model
ktk = KitikiPlot(information=df["Summary"].head(15)) ktk.plot(figsize=(15, 5), kitiki_cell_kwargs={"linestyle": "--"})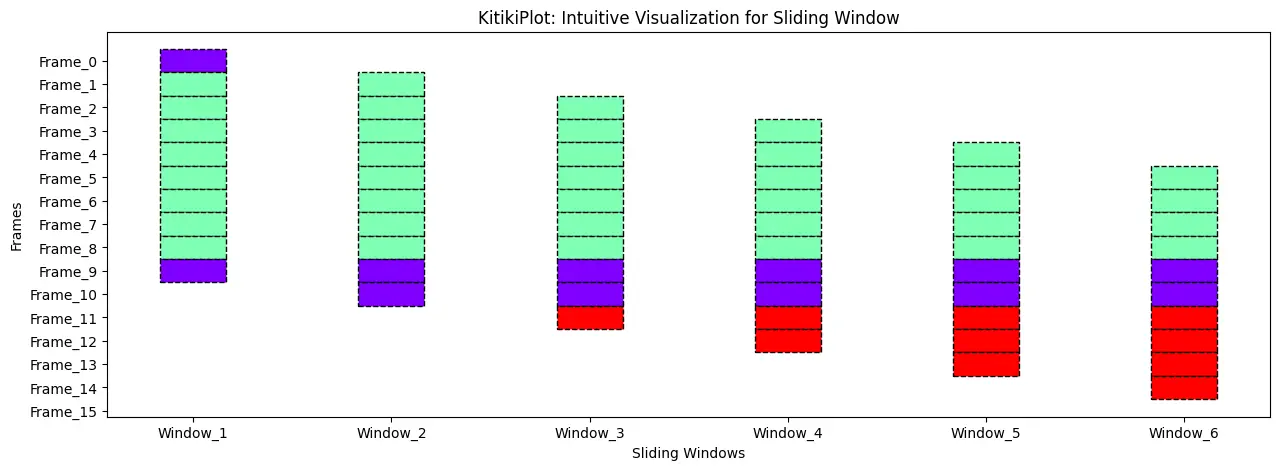
Modify the road width
kitki = KitikiPlot(information=df["Summary"].head(15).tolist()) kitki.plot(figsize=(15, 5), kitiki_cell_kwargs={"linewidth": 3})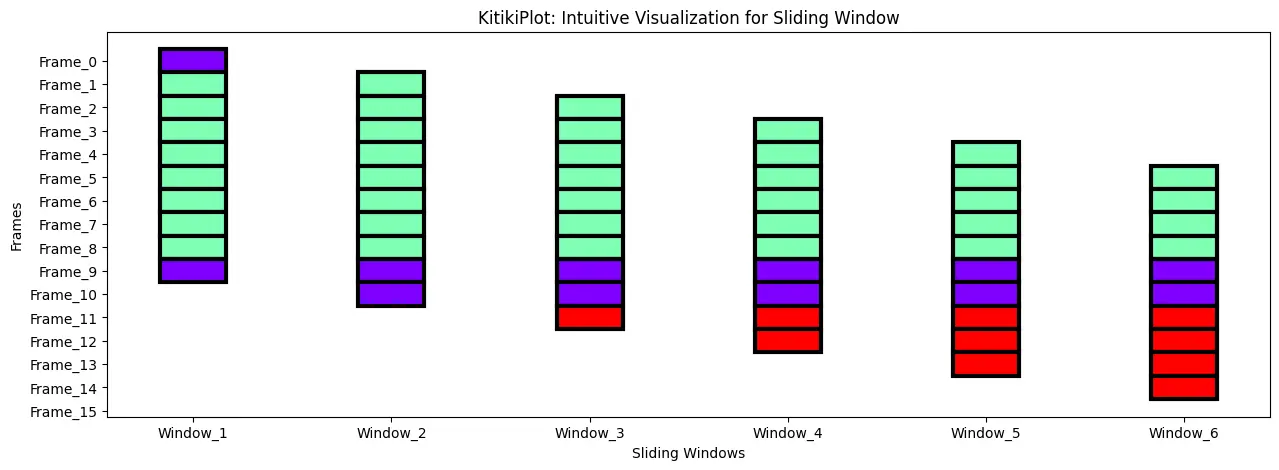
Modify the alpha
KitikiPlot(information=df[“Summary”].head(15)).plot(figsize=(15, 5), kitiki_cell_kwargs={"alpha": 0.4})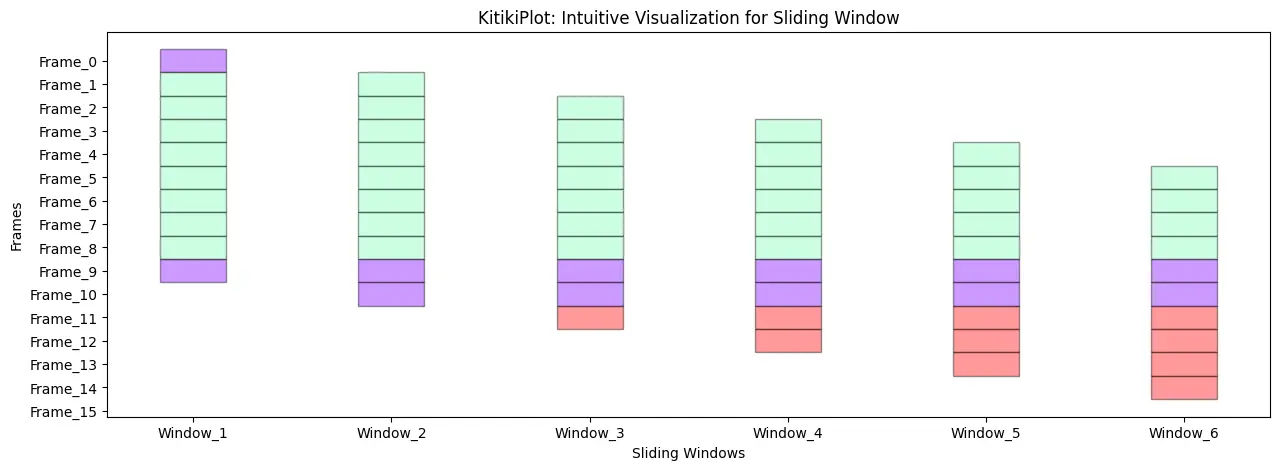
Actual-World Purposes of KitikiPlot
KitikiPlot excels in various domains where data visualization is crucial for uncovering complex patterns and trends. KitikiPlot enables customers to transform complex data into lucid, decision-making intelligence across a wide spectrum of industries, including genomics, environmental monitoring, finance, and predictive modeling. Whether analysing massive datasets, monitoring air quality over time, or visualising trends in inventory costs, KitikiPlot offers the flexibility and customisation needed to meet the unique demands of various industries.
Genomics
- The KitikiPlot tool enables researchers to effectively visualize gene sequences, facilitating the identification of patterns and motifs crucial for their work.
- This technology enables the assessment of genomic structural aberrations, crucial for grasping the molecular underpinnings of hereditary disorders.
- Visualising complex genomic data enables accurate interpretation, thereby facilitating breakthroughs in personalized medicine.
Dataset URL:
import pandas as pd from kitikiplot import KitikiPlot # Load dataset data = pd.read_csv('datasets/molecular+biology+splice+junction+gene+sequences/splice.information', header=None) data.columns = ['Label', 'Instance_Name', 'Nucleotide_Sequence'] # Select 3 random gene sequences random_samples = data.sample(3, random_state=1) # Clean Nucleotide Sequences by removing leading/trailing whitespaces random_samples['Nucleotide_Sequence'] = random_samples['Nucleotide_Sequence'].str.strip() random_samples
index = 0 ktk = KitikiPlot(information=[i for i in df.iloc[index, 2]], stride=1, window_length=len(df.iloc[index, 2])) ktk.plot(figsize=(20, 0.5), cell_width=2, cmap={'A': '#007FFF', 'T': '#fffc00', "G": "#00ff00", "C": "#960018"}, transpose=True, xlabel="Nucleotides", ylabel="Sequence", display_yticks=False, xtick_prefix="Nucleotide", xticks_rotation=90, title=f"Genome Visualization: {df.iloc[index, 1].strip()}", Label: f"{df.iloc[index,0].strip()}", display_legend=True, legend_kwargs={"bbox_to_anchor": (1.01, 1), "loc":'higher left', "borderaxespad": 0})
Climate Forecasting
- The library effectively visualizes temporal climate data, correlating temperature and humidity patterns across consecutive time intervals, enabling the identification of characteristics.
- This visualisation enables the identification of patterns and variations in climatic conditions, thereby improving the precision of predictions.
- By providing accurate and reliable historical climate data, this tool facilitates the assessment of past weather patterns, enabling more informed forecasting and strategic planning for mitigating weather-related impacts.
Dataset URL:
import pandas as pd from kitikiplot import KitikiPlot weather_data = pd.read_csv('datasets/weatherHistory/weatherHistory.csv') print(f"Data shape: {weather_data.shape}") # Subset data for visualization subset_data = weather_data.iloc[45:65, :] print(f"Subset shape: {subset_data.shape}") subset_data.head(3)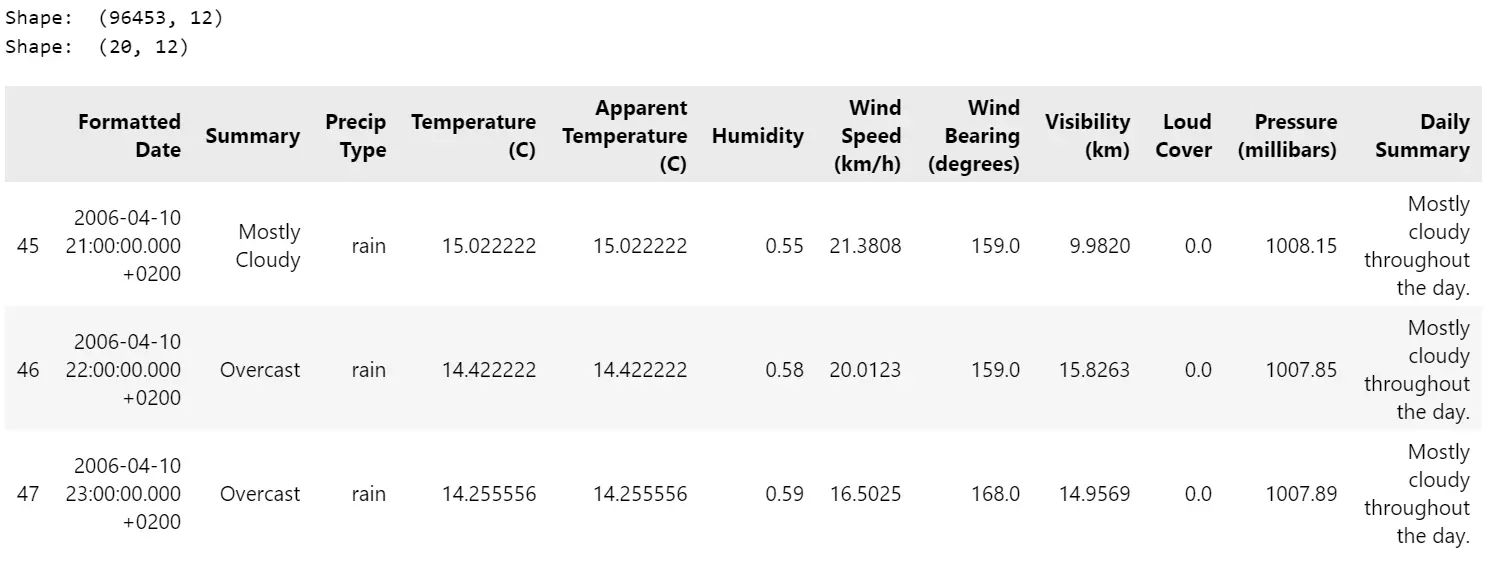
index = 0 weather_data = ['Mostly Cloudy', 'Overcast', 'Overcast', 'Overcast', 'Overcast', 'Overcast', 'Overcast', 'Overcast', 'Overcast', 'Mostly Cloudy', 'Mostly Cloudy', 'Partly Cloudy', 'Partly Cloudy', 'Partly Cloudy', 'Partly Cloudy', 'Mostly Cloudy', 'Mostly Cloudy', 'Mostly Cloudy', 'Mostly Cloudy', 'Mostly Cloudy'] time_period = ['21:00 pm', '22:00 pm', '23:00 pm', '00:00 am', '01:00 am', '02:00 am', '03:00 am', '04:00 am', '05:00 am', '06:00 am', '07:00 am', '08:00 am', '09:00 am', '10:00 am', '11:00 am', '12:00 pm', '13:00 pm', '14:00 pm', '15:00 pm', '16:00 pm'] ktk = KitikiPlot(information=weather_data, stride=1, window_length=10) ktk.plot(figsize=(20, 5), cell_width=2, transpose=False, xlabel="Window", ylabel="Time", yticks_values=time_period, xticks_rotation=90, cmap={'Largely Cloudy': 'brown', 'Partly Cloudy': '#a9cbe0', 'Overcast': '#fdbf6f'}, legend_kwargs={'bbox_to_anchor': (1.01, 1), 'loc':'higher left', 'borderaxespad': 0}, display_legend=True, title="Climate Sample on 10-04-2006")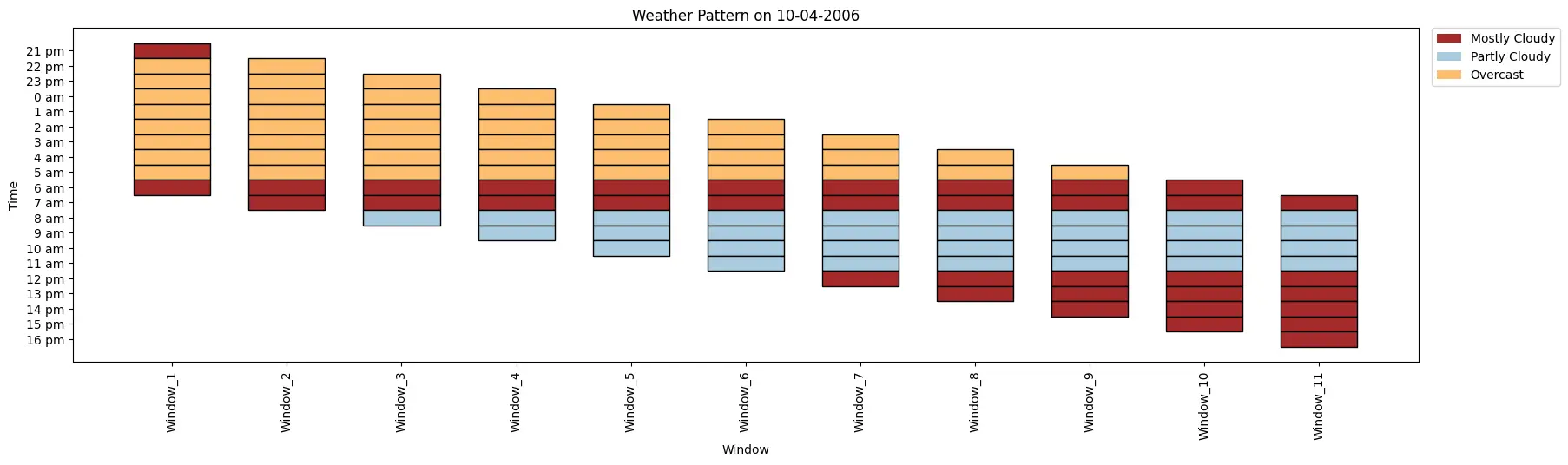
Air High quality Monitoring
- By utilising KitikiPlot, customers can gain insights into pollutant ranges over time, enabling them to identify subtle variations and correlations within environmental data that may not be immediately apparent.
- This feature enables the detection of characteristics in air quality, fostering a more nuanced comprehension of how diverse pollutants interact and vary due to multiple factors.
- In addition, this research enables the examination of temporal linkages between atmospheric pollution metrics and specific pollutants, thereby optimising the efficacy of air quality surveillance initiatives.
Dataset URL:
from kitikiplot import KitikiPlot import pandas as pd # Load Excel dataset dataset = pd.read_excel("datasets/air+high quality/AirQualityUCI.xlsx") # Filter data for a specific date (2004-11-01) filtered_df = dataset[dataset['Date'] == '2004-11-01'] print("Form:", filtered_df['form'].values[0]) # assuming form is a column filtered_df.head(3) # Convert CO(GT) column to integer type filtered_df["CO(GT)"] = filtered_df["CO(GT)"].astype(int)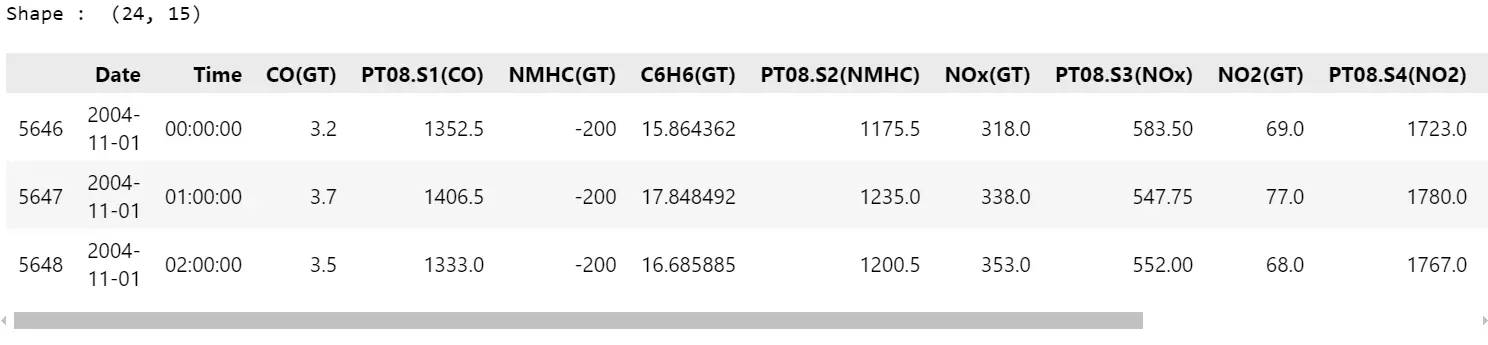
ktk.plot(figsize=(20,5),cell_width=2,cmap={-200:"cornflowerblue",1:"#ffeaea",2:"#feb9b9",3:"#ff7070",4:"#b00"},transpose=True,xlabel="Time",ylabel="Sliding Home windows of CO(GT) values (in mg/m³)",display_xticks=True,xticks_values=time_period,ytick_prefix="Window",xticks_rotation=90,display_legend=True,title="CO(GT) Development in Air",legend_kwargs={"bbox_to_anchor":(1.01,1),"loc":"upper left","borderaxespad":0})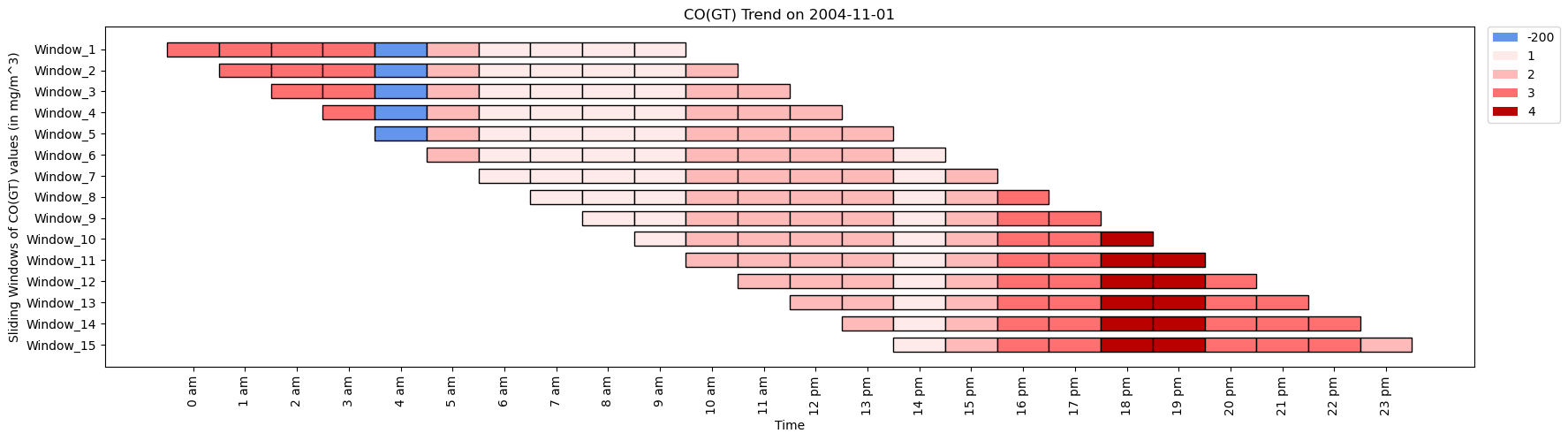
Conclusion
KitikiPlot streamlines the visual representation of sequential and time-series categorical data, rendering complex patterns more discernible and easily interpreted. Its versatility encompasses a range of applications, from genomics to climate assessment and air quality monitoring, underscoring its far-reaching value in both research and industry. With a focus on maximizing readability and value, KitikiPlot revolutionizes the extraction of actionable insights from complex categorical data. As a free and accessible library, it enables information scientists and researchers to effectively navigate complex challenges.
Key Takeaways
- KitikiPlot is a versatile Python library engineered to provide precise and intuitive sliding window data visualizations.
- The advanced customization options enable users to craft tailored visualizations that accurately convey insights from their unique datasets, allowing for unparalleled understanding and decision-making capabilities.
- The library plays a crucial role in various real-world applications across multiple analytical and trading disciplines.
- As a freely available device, KitikiPlot guarantees universal access to its features for both information science professionals and researchers.
- Clear and insightful visualizations enable the seamless identification of trends within sequential categorical data.
Assets
Quotation
@software { author = {Boddu Sri Pavan and Boddu Swathi Sree}, title = {{KitikiPlot: A Python Library for Visualizing Categorical Sliding Window Information}}, year = {2024}, version = {0.1.2}, url = {https://github.com/BodduSriPavan-111/kitikiplot}, doi = {10.5281/zenodo.14293030}, howpublished = {\url{https://github.com/BodduSriPavan-111/kitikiplot}} }Often Requested Questions
A. KitikiPlot excels at visualizing complex sequential and time-series categorical data by applying a sliding window methodology to effectively convey insights.
A. While initially designed for categorical data, KitikiPlot can be adapted to accommodate various information types through innovative preprocessing techniques, such as discretization.
A. KitikiPlot effortlessly harmonizes with industry-standard libraries such as Pandas and Matplotlib to streamline data preprocessing and unlock advanced visualization capabilities.