

{kind=link}
Lakeflow Declarative Pipelines is now Typically Out there, and momentum hasn’t slowed since DAIS. This publish rounds up every part that’s landed prior to now few weeks – so that you’re totally caught up on what’s right here, what’s coming subsequent, and the way to begin utilizing it.
DAIS 2025 in Assessment: Lakeflow Declarative Pipelines Is Right here
At Information + AI Summit 2025, we introduced that we’ve contributed our core declarative pipeline expertise to the Apache Spark™ mission as Spark Declarative Pipelines. This contribution extends Spark’s declarative mannequin from particular person queries to full pipelines, letting builders outline what their pipelines ought to do whereas Spark handles the way to do it. Already confirmed throughout hundreds of manufacturing workloads, it’s now an open customary for your entire Spark neighborhood.
We additionally introduced the Basic Availability of Lakeflow, Databricks’ unified resolution for information ingestion, transformation, and orchestration on the Information Intelligence Platform. The GA milestone additionally marked a serious evolution for pipeline improvement. DLT is now Lakeflow Declarative Pipelines, with the identical core advantages and full backward compatibility together with your present pipelines. We additionally launched Lakeflow Declarative Pipelines’ new IDE for information engineering (proven above), constructed from the bottom as much as streamline pipeline improvement with options like code-DAG pairing, contextual previews, and AI-assisted authoring.
Lastly, we introduced Lakeflow Designer, a no-code expertise for constructing information pipelines. It makes ETL accessible to extra customers – with out compromising on manufacturing readiness or governance – by producing actual Lakeflow pipelines beneath the hood. Preview coming quickly.
Collectively, these bulletins signify a brand new chapter in information engineering—easier, extra scalable, and extra open. And within the weeks since DAIS, we’ve saved the momentum going.
Smarter Efficiency, Decrease Prices for Declarative Pipelines
We’ve made vital backend enhancements to assist Lakeflow Declarative Pipelines run quicker and extra cost-effectively. Throughout the board, serverless pipelines now ship higher price-performance because of engine enhancements to Photon, Enzyme, autoscaling, and superior options like AutoCDC and Information High quality expectations.
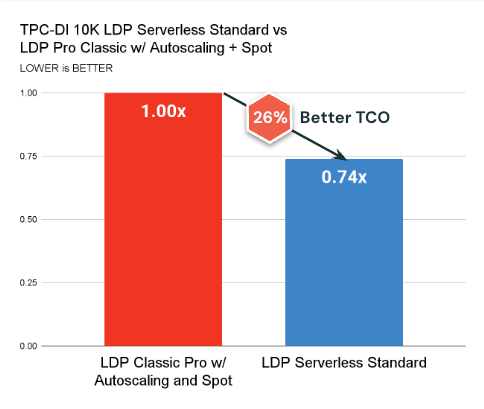
Listed below are the important thing takeaways:
- Serverless Commonplace Mode is now accessible and constantly outperforms traditional compute by way of value (26% higher TCO on common) and latency.
- Serverless Efficiency Mode unlocks even quicker outcomes and is TCO aggressive for tight SLAs.
- AutoCDC now outperforms conventional MERGE in lots of workloads, whereas making it simpler to implement SCD1 and SCD2 patterns with out complicated logic, particularly when paired with these optimizations.
These adjustments construct on our ongoing dedication to make Lakeflow Declarative Pipelines probably the most environment friendly choice for manufacturing ETL at scale.
What Else is New in Declarative Pipelines
Because the Information + AI Summit, we’ve delivered a sequence of updates that make pipelines extra modular, production-ready, and simpler to function—with out requiring further configuration or glue code.
Operational simplicity
Managing desk well being is now simpler and less expensive:
- Predictive Optimization now manages desk upkeep – like OPTIMIZE and VACUUM – for all new and present Unity Catalog pipelines. As a substitute of operating on a hard and fast schedule, upkeep now adapts to workload patterns and information structure to optimize value and efficiency routinely. This implies:
- Much less time spent tuning or scheduling upkeep manually
- Smarter execution that avoids pointless compute utilization
- Higher file sizes and clustering for quicker question efficiency
- Deletion vectors at the moment are enabled by default for brand new streaming tables and materialized views. This reduces pointless rewrites, enhancing efficiency and reducing compute prices by avoiding full file rewrites throughout updates and deletes. If in case you have strict bodily deletion necessities (e.g., for GDPR), you may disable deletion vectors or completely take away information.
Extra modular, versatile pipelines
New capabilities give groups better flexibility in how they construction and handle pipelines, all with none information reprocessing:
- Lakeflow Declarative Pipelines now helps upgrading present pipelines to benefit from publishing tables to a number of catalogs and schemas. Beforehand, this flexibility was solely accessible when creating a brand new pipeline. Now, you may migrate an present pipeline to this mannequin with no need to rebuild it from scratch, enabling extra modular information architectures over time.
- Now you can transfer streaming tables and materialized views from one pipeline to a different utilizing a single SQL command and a small code change to maneuver the desk definition. This makes it simpler to separate giant pipelines, consolidate smaller ones, or undertake completely different refresh schedules throughout tables with no need to recreate information or logic. To reassign a desk to a unique pipeline, simply run:
After operating the command and shifting the desk definition from the supply to the vacation spot pipeline, the vacation spot pipeline takes over updates for the desk.
New system tables for pipeline observability
A brand new pipeline system desk is now in Public Preview, supplying you with an entire, queryable view of all pipelines throughout your workspace. It consists of metadata like creator, tags, and lifecycle occasions (like deletions or config adjustments), and will be joined with billing logs for value attribution and reporting. That is particularly helpful for groups managing many pipelines and seeking to observe value throughout environments or enterprise models.
A second system desk for pipeline updates – overlaying refresh historical past, efficiency, and failures – is deliberate for later this summer season.
Get hands-on with Lakeflow
 New to Lakeflow or seeking to deepen your abilities? We’ve launched three free self-paced coaching programs that can assist you get began:
New to Lakeflow or seeking to deepen your abilities? We’ve launched three free self-paced coaching programs that can assist you get began:
- Information Ingestion with Lakeflow Join – Learn to ingest information into Databricks from cloud storage or utilizing no-code, totally managed connectors.
- Deploy Workloads with Lakeflow Jobs – Orchestrate manufacturing workloads with built-in observability and automation.
- Construct Information Pipelines with Lakeflow Declarative Pipelines – Go end-to-end with pipeline improvement, together with streaming, information high quality, and publishing.
All three programs can be found now without charge in Databricks Academy.