

{kind=link}

(Dragon Claws/Shutterstock)
Final week’s GTC 2025 present might have been agentic AI’s breakout second, however the core expertise behind it has been quietly enhancing behind the scenes. That progress is being tracked throughout a sequence of coding benchmarks, corresponding to SWE-bench and GAIA, main some to consider AI brokers are on the cusp of one thing large.
It wasn’t that way back that AI-generated code was not deemed appropriate for deployment. The SQL code could be too verbose or the Python code could be buggy or insecure. Nevertheless, that state of affairs has modified significantly in latest months, and AI fashions in the present day are producing extra code for patrons on daily basis.
Benchmarks present a great way to gauge how far agentic AI has come within the software program engineering area. One of many extra fashionable benchmarks, dubbed SWE-bench, was created by researchers at Princeton College to measure how effectively LLMs like Meta’s Llama and Anthropic’s Claude can remedy widespread software program engineering challenges. The benchmark makes use of GitHub as a wealthy useful resource of Python software program bugs throughout 16 repositories, and gives a mechanism for measuring how effectively the LLM-based AI brokers can remedy them.
When the authors submitted their paperm, “SWE-Bench: Can Language Fashions Resolve Actual-World GitHub Points?” to the by the Worldwide Convention on Studying Representations (ICLR) in October 2023, the LLMs weren’t acting at a excessive stage. “Our evaluations present that each state-of-the-art proprietary fashions and our fine-tuned mannequin SWE-Llama can resolve solely the best points,” the authors wrote within the summary. “The most effective-performing mannequin, Claude 2, is ready to remedy a mere 1.96% of the problems.”
That modified shortly. At present, the SWE-bench leaderboard exhibits the top-scoring mannequin resolved 55% of the coding points on SWE-bench Lite, which is a subset of the benchmark designed to make analysis less expensive and extra accessible.
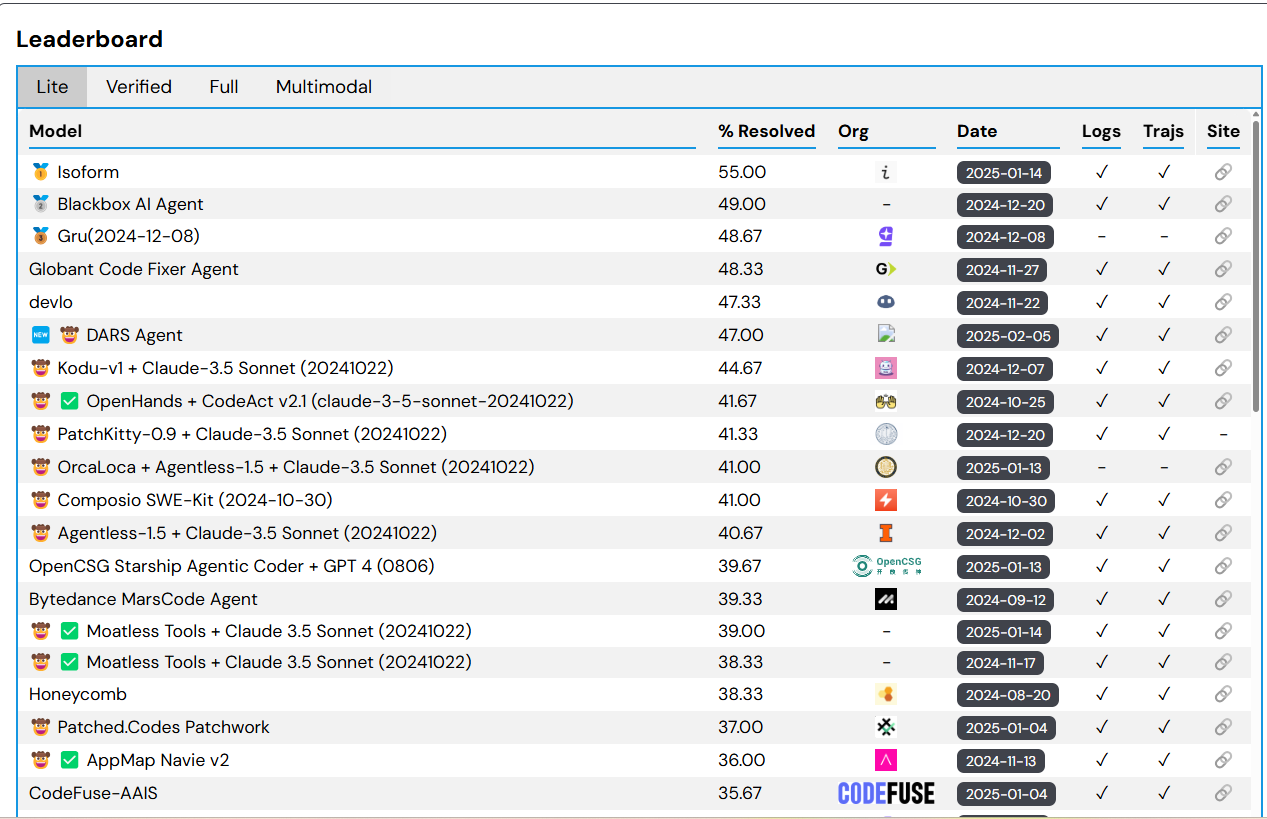
SWE-bench measures AI brokers’ capabilites to resolve GitHub points. You possibly can see the present leaders at https://www.swebench.com/
Huggingface put collectively a benchmark for Normal AI Assistants, dubbed GAIA, that measures a mannequin’s functionality throughout a number of realms, together with reasoning, multi-modality dealing with, Net looking, and usually tool-use proficiency. The GAIA exams are non-ambiguous, and are difficult, corresponding to counting the variety of birds in a five-minute video.
A 12 months in the past, the highest rating on stage 3 of the GAIA check was round 14, in line with Sri Ambati, the CEO and co-founder of H2O.ai. At present, an H2O.ai-based mannequin primarily based on Claude 3.7 Sonnet holds the highest general rating, about 53.
“So the accuracy is simply actually rising very quick,” Ambati mentioned. “We’re not totally there, however we’re on that path.”
H2O.ai’s software program is concerned in one other benchmark that measures SQL technology. BIRD, which stands for BIg Bench for LaRge-scale Database Grounded Textual content-to-SQL Analysis, measures how effectively AI fashions can parse pure language into SQL.
When BIRD debuted in Might 2023, the highest scoring mannequin, CoT+ChatGPT, demonstrated about 40% accuracy. One 12 months in the past, the highest scoring AI mannequin, ExSL+granite-20b-code, was primarily based on IBM’s Granite AI mannequin and had an accuracy of about 68%. That was fairly a bit under the potential of human efficiency, which BIRD measures at about 92%. The present BIRD leaderboard exhibits an H2O.ai-based mannequin from AT&T because the chief, with an 77% accuracy charge.
The fast progress in producing respectable pc code has led some influential AI leaders, corresponding to Nvidia CEO and co-founder Jensen Huang and Anthropic co-founder and CEO Dario Amodei, to make daring predictions about the place we are going to quickly discover ourselves.
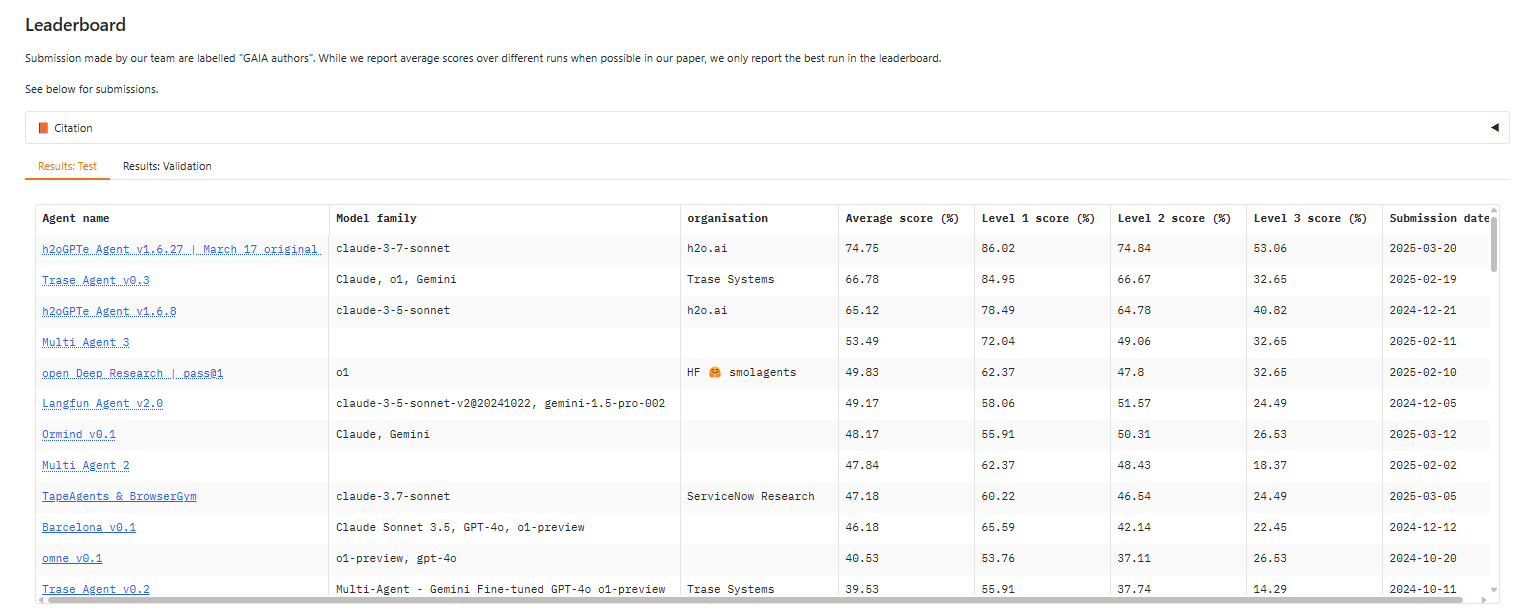
GAIA measures AI brokers’ functionality to deal with a variety of duties. You possibly can see the present leaders board at https://huggingface.co/areas/gaia-benchmark/leaderboard
“We’re not removed from a world–I feel we’ll be there in three to 6 months–the place AI is writing 90 % of the code,” Amodei mentioned earlier this month. “After which in twelve months, we could also be in a world the place AI is writing basically the entire code.”
Throughout his GTC25 keynote final week, Huang shared his imaginative and prescient about the way forward for agentic computing. In his view, we’re quickly approaching a world the place AI factories generate and run software program primarily based on human inputs, versus people writing software program to retrieve and manipulate knowledge.
“Whereas previously we wrote the software program and we ran it on computer systems, sooner or later, the computer systems are going to generate the tokens for the software program,” Huang mentioned. “And so the pc has grow to be a generator of tokens, not a retrieval of information. [We’ve gone] from retrieval-based computing to generative-based computing.”
Others are taking a extra pragmatic view. Anupam Datta, the principal analysis scientist at Snowflake and lead of the Snowflake AI Analysis Workforce, applauds the development in SQL technology. As an example, Snowflake says its Cortex Agent’s text-to-SQL technology accuracy charge is 92%. Nevertheless, Datta doesn’t share Amodei’s view that computer systems will probably be rolling their very own code by the tip of the 12 months.
“My view is that coding brokers in sure areas, like text-to-SQL, I feel are getting actually good,” Datta mentioned at GTC25 final week. “Sure different areas, they’re extra assistants that assist a programmer get quicker. The human will not be out of the loop simply but.”
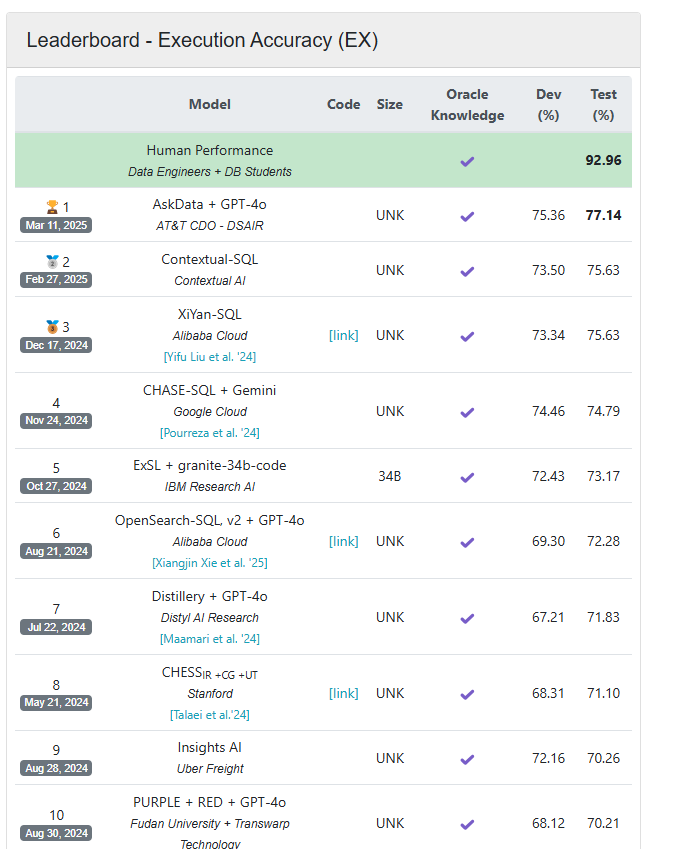
BIRD measures the text-to-SQL functionality of AI brokers. You possibly can entry the present leaderbord at https://bird-bench.github.io/
Programmer productiveness would be the large winner because of coding copilots and agentic AI techniques, he mentioned. We’re not removed from a world the place agentic AI will generate the primary draft, he mentioned, after which the people will are available and refine and enhance it. “There will probably be enormous beneficial properties in productiveness,” Datta mentioned. “So the affect will very vital, simply with copilot alone.”
H2O.ai’s Ambati additionally believes that software program engineers will work carefully with AI. Even one of the best coding brokers in the present day introduce “delicate bugs,” so folks nonetheless want to take a look at it the code, he mentioned. “It’s nonetheless a reasonably vital ability set.”
One space that’s nonetheless fairly inexperienced is the semantic layer, the place pure language is translated into enterprise context. The issue is that the English language may be ambiguous, with a number of meanings from the identical phrase.
“A part of it’s understanding the semantics layer of the client schema, the metadata,” Ambati mentioned. “That piece continues to be constructing. That ontology continues to be a little bit of a website data.”
Hallucinations are nonetheless a difficulty too, as is the potential for an AI mannequin to go off the rails and say or do unhealthy issues. These are all areas of concern that corporations like Anthropic, Nvidia, H2O.ai, and Snowflake are all working to mitigate. However because the core capabilities of Gen AI get higher, the variety of causes to not put AI brokers into manufacturing decreases.
Associated Gadgets:
Accelerating Agentic AI Productiveness with Enterprise Frameworks
Nvidia Preps for 100x Surge in Inference Workloads, Because of Reasoning AI Brokers
Reporter’s Pocket book: AI Hype and Glory at Nvidia GTC 2025