

{kind=link}
To check the efficiency of various fashions, we use analysis metrics akin to
- Accuracy: The proportion of complete predictions that had been appropriate. Accuracy is highest when lessons are balanced.
- Precision: Of all of the emails the mannequin labeled as a sure class, the proportion that had been appropriate.
- Recall: Of all of the emails that actually belong to a class, the proportion the mannequin accurately recognized.
- F1-score: The harmonic imply of precision and recall. F1 supplies a balanced measure of efficiency, whenever you care about each false positives and false negatives.
- Help: Signifies what number of precise samples there have been for every class. Help is useful in understanding class distribution.
Step 4: Check the classification mannequin and consider efficiency
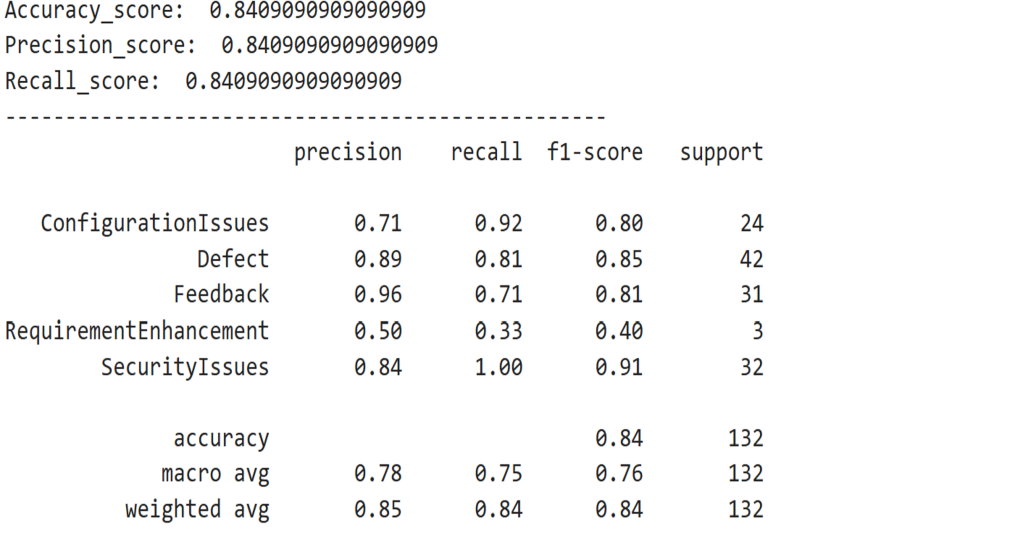
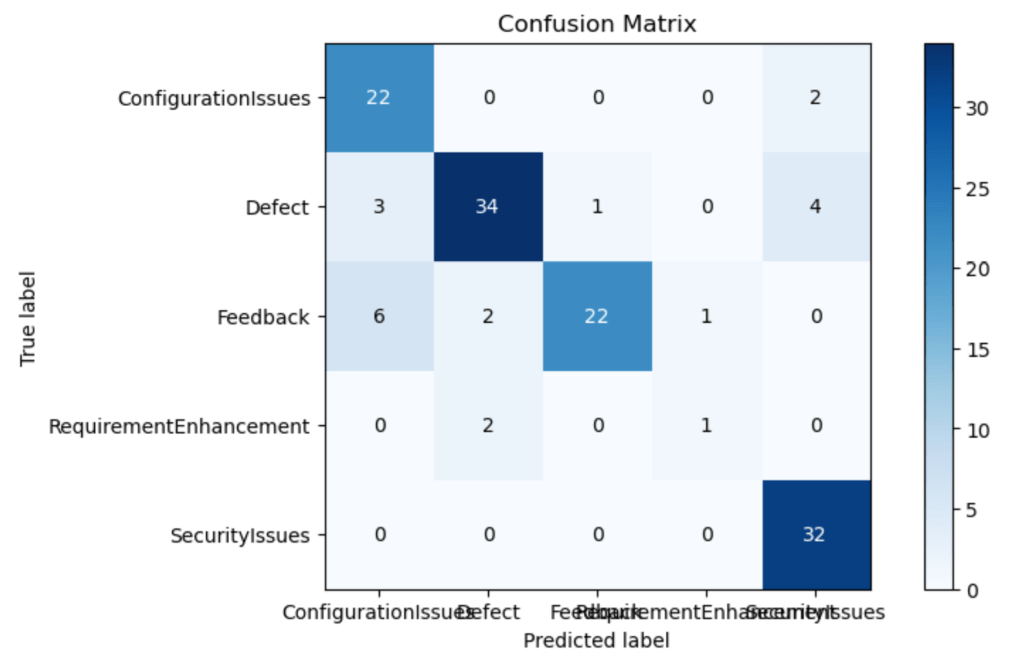
The code itemizing beneath combines a lot of steps—preprocessing the check information, predicting the goal values from the check information, and evaluating the mannequin’s efficiency by plotting the confusion matrix and computing accuracy, precision, and recall. The confusion matrix compares the mannequin’s predictions with the precise labels. The classification report summarizes the analysis metrics for every class.
#Studying Check Information test_df = pd.read_csv(test_Data.txt',delimiter=";",names=['text','label']) # Making use of similar transformation as on Practice Information X_test,y_test = test_df.textual content,test_df.label #pre-processing of textual content test_corpus = text_transformation(X_test) #convert textual content information into vectors testdata = cv.rework(test_corpus) #predict the goal predictions = clf.predict(testdata) #evaluating mannequin efficiency parameters mlp.rcParams['figure.figsize'] = 10,5 plot_confusion_matrix(y_test,predictions) print('Accuracy_score: ', accuracy_score(y_test,predictions)) print('Precision_score: ', precision_score(y_test,predictions,common="micro")) print('Recall_score: ', recall_score(y_test,predictions,common="micro")) print(classification_report(y_test,predictions)) Output –
IDG
IDG
Whereas acceptable thresholds range relying on the use case, a macro-average F1-score above 0.80 is mostly thought of good for multi-class textual content classification. The mannequin’s F1-score of 0.8409 signifies that the mannequin is performing reliably throughout all six e-mail classes.