

{kind=link}
Can a large language model truly grasp an unseen image’s essence if its vocabulary has never been exposed to visual representations?
Since models trained solely on written text appear to possess a profound comprehension of the physical realm? To create sophisticated visualizations of intricate settings, complete with captivating objects and arrangements, developers will craft image-rendering code – a task where even if the generated data is misinterpreted, Large Language Models (LLMs) can iteratively fine-tune their artistic renderings. A team of researchers at MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) observed that, when prompting language models to revise their coding for various images, the algorithms exhibited rapid improvement in their simplistic drawing capabilities with each iteration.
Data on linguistic trends becomes apparent through the online representation of concepts such as shapes and colors, regardless of whether they’re articulated in natural language or coding frameworks. Given a prompt such as “draw a parrot within the jungle,” users encourage the LLM to recall relevant information gleaned from previous descriptions. Researchers at CSAIL developed a “visual diagnostic tool” to assess the visual data capacity of language models (LLMs): by leveraging their “Visual Aptitude Dataset,” they tested the models’ ability to recognize, correct, and generate this information. Researchers successfully accumulated all final drafts of those illustrations by developing a computer vision system capable of identifying the content of real-life photographs.
“We don’t directly utilize visual knowledge in our imaginative and prescriptive system,” notes Tamar Rott Shaham, co-lead author and MIT EECS postdoc at CSAIL. Our team investigated various language styles to develop a code that could create visual representations of information, subsequently training an AI-powered vision system to evaluate genuine images. Have we ever stopped to consider how vividly concepts manifest themselves through various channels, including written word? To accurately represent their visible data, LLMs can leverage code as a standardized interface between textual content and vision.
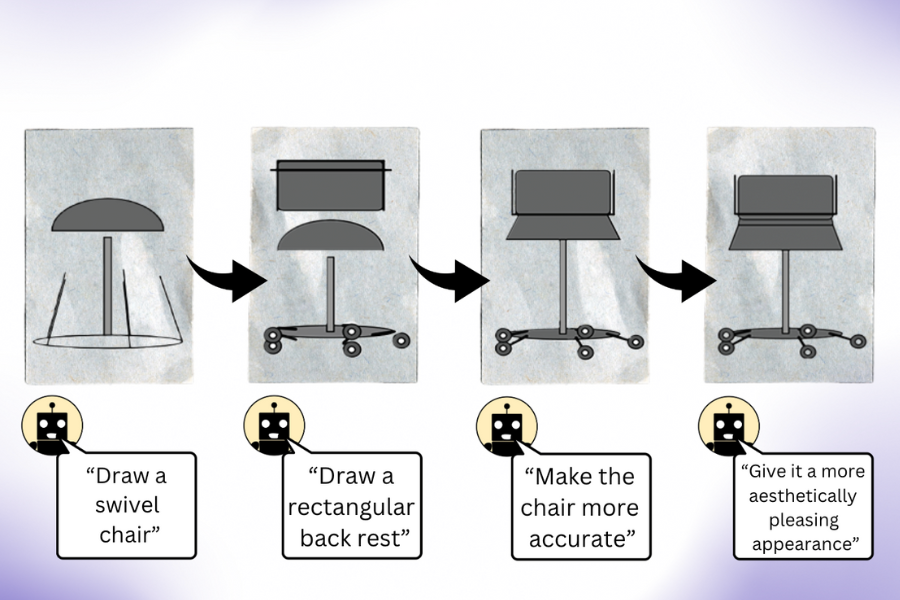
Researchers initially queried fashion datasets to generate code for diverse shapes, objects, and scenarios. They compiled this code to generate simple digital drawings, such as a line of bicycles, demonstrating that large language models effectively grasp spatial relationships and can arrange the two-wheelers horizontally with precision. The mannequin surprisingly crafted a car-shaped cake, successfully merging two seemingly disparate concepts into a unique creation. The Language Mannequin also produced a radiant light bulb, exemplifying its capacity to generate tangible outcomes.
“According to co-lead author and CSAIL researcher Pratyusha Sharma, who earned her doctorate in Electrical Engineering and Computer Science, their findings suggest that when you prompt a large language model without multimodal pre-training to generate an image, it actually possesses more insight than initially meets the eye.” Here is the improved version: Let’s imagine you asked for something that would help you attract a chair. With its advanced knowledge of various aspects surrounding this piece of furniture, the mannequin is able to discern nuances that would be impossible for human intuition to grasp immediately, thereby allowing customers to engage in a dialogue with the mannequin to refine and improve the visual representation with each successive iteration. In a remarkable turn of events, the mannequin demonstrates its capacity to significantly enhance the drawing through iterative improvements to the rendering code.
Researchers collected the illustrations, leveraging them to train a computer vision system capable of identifying objects within real-life images, regardless of prior exposure. With this artificially generated knowledge serving as its sole benchmark, the system excels over various procedurally generated image datasets trained on authentic visuals.
By integrating the latent visible features of large language models (LLMs) with the innovative capacities of diverse AI tools, such as diffusion models, the CSAIL team posits that synergies can be achieved. Artificial intelligence programs like Midjourney often struggle to fine-tune subtle details in images, hindering their ability to fulfill complex requests, such as reducing the number of vehicles depicted or placing an object behind another? If a large language model (LLM) had pre-visualized the desired modification to the diffusion model beforehand, the subsequent revision would likely be more successful.
Despite Rott Shaham and Sharma’s recognition of irony, large language models (LLMs) often neglect to credit the same concepts they will subsequently build upon. As the models struggled to distinguish between original images and their artificially generated counterparts within the dataset, it became apparent that the fashion recognition algorithms were flawed. Diverse depictions of the physical realm likely gave rise to the language arts’ misunderstandings.
Despite fashion’s difficulties in grasping the essence of these condensed summaries, designers showed remarkable adaptability by consistently drawing inspiration from similar concepts. Researchers repeatedly asked Large Language Models to generate ideas related to strawberries and arcades, prompting them to produce images from diverse angles, shapes, and colors, suggesting that these LLMs require precise visual representations of abstract concepts rather than simply recalling previous examples.
The CSAIL team posits that this process could serve as a benchmark for assessing the capacity of generative AI models to train computer vision systems effectively. Furthermore, researchers strive to refine their approach by developing duties based on problem-solving languages. As part of their ongoing research, the MIT team faces a challenge in further investigating the source of their dataset due to lack of access to the training sets of the large language models (LLMs) utilized, hindering efforts to delve deeper into the origins of their findings. At some point, their plan is to develop a superior AI framework by allowing the large language model to collaborate directly with it.
Sharma and Rott Shaham are joined by a distinguished group of researchers, including Stephanie Fu ’22, MNG ’23, a former CSAIL affiliate, as well as PhD students Manel Baradad, Adrián Rodríguez-Muñoz ’22, and Shivam Duggal, all of whom are CSAIL associates; in addition to MIT Affiliate Professor Phillip Isola and Professor Antonio Torralba. The researchers’ endeavors were underpinned in part by grants from the esteemed MIT-IBM Watson AI Lab, as well as fellowships from the prestigious LaCaixa Foundation, the Zuckerman STEM Management Program, and the Viterbi Fellowship. They are currently presenting their paper this week at the IEEE/CVF Conference on Laptop Vision and Pattern Recognition.