

{kind=link}
In the rapidly evolving landscape of generative AI, selecting the optimal components for your AI response is crucial. With the proliferation of large-scale language models, embedding techniques, and vector databases, selecting the correct approach has significant implications for downstream applications, emphasizing the importance of informed decision-making in this landscape.
Will a pre-trained embedding model tailored to your specific application? Your system’s immediate strategy may inadvertently generate excessive tokens, thereby leading to higher pricing costs. While various threats exist, one often overlooked danger is the risk of becoming obsolete.
As new technologies emerge and innovative tools come online, businesses must prioritize seamless integration to maximize the benefits of these advancements and phase out legacy systems. On this dynamic atmosphere, it is crucial to design flexible options that enable seamless integration and thorough analysis of cutting-edge elements to maintain a competitive edge.
Confidence in the reliability and security of large language models (LLMs) within the manufacturing sector is another essential consideration. Ensuring the reliability of AI systems necessitates proactive strategies to address potential threats like toxicity, safety vulnerabilities, and suboptimal responses, thereby fostering public trust and adherence to regulatory requirements.
Alongside concerns about efficiency, factors such as licensing, management, and safety also influence the choice between open-source and industrial models.
- Industrial designs offer seamless functionality and user-friendly interfaces, particularly in situations requiring rapid setup and implementation.
- Open-source fashion solutions offer greater control and personalization options, rendering them a more attractive choice for nuanced data and specialized usage scenarios.
With these considerations in mind, it’s clear why platforms like Hugging Face have become extremely popular among AI developers. They provide access to cutting-edge fashion trends, technologies, datasets, and tools for AI experimentation.
The robust ecosystem of open-source embeddings has garnered widespread recognition for its adaptability and effectiveness across diverse languages and tasks. Leaderboards are designed to provide valuable insights into the effectiveness of various embedding styles, enabling customers to identify the most suitable options for their needs.
As the proliferation of cutting-edge technologies, such as Smaug and DeepSeek, and innovative open-source vector databases, including Weaviate and Qdrant, continues to gain momentum.
With such a daunting array of options, effective approaches to selecting suitable instruments and LLMs for your group involve immersing yourself within the live environment of these models, directly experiencing their capabilities to determine whether they align with your objectives before committing to deployment. With the combination of DataRobot’s capabilities and HuggingFace’s extensive library of generative AI elements, you can easily achieve this.
To successfully integrate large language models (LLMs) into production workflows, it’s essential to effectively arrange endpoint configurations, explore and examine these powerful tools, and securely deploy them while empowering robust model monitoring and maintenance capabilities throughout the manufacturing process.
You will be able to complete the entire course of step-by-step instructions using both DataRobot and HuggingFace seamlessly.
To begin, we need to develop the necessary mannequin endpoints within HuggingFace and establish a fresh. The instances function as a comprehensive atmosphere, encompassing diverse artifacts intricately linked to the specific endeavor. From datasets and vector databases to large language model (LLM) playgrounds facilitating manifold comparisons and accompanying notebooks.
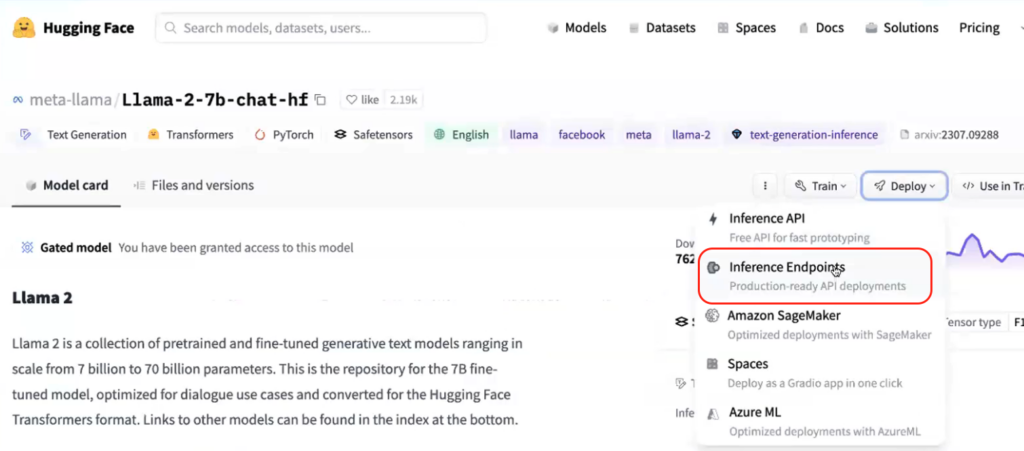
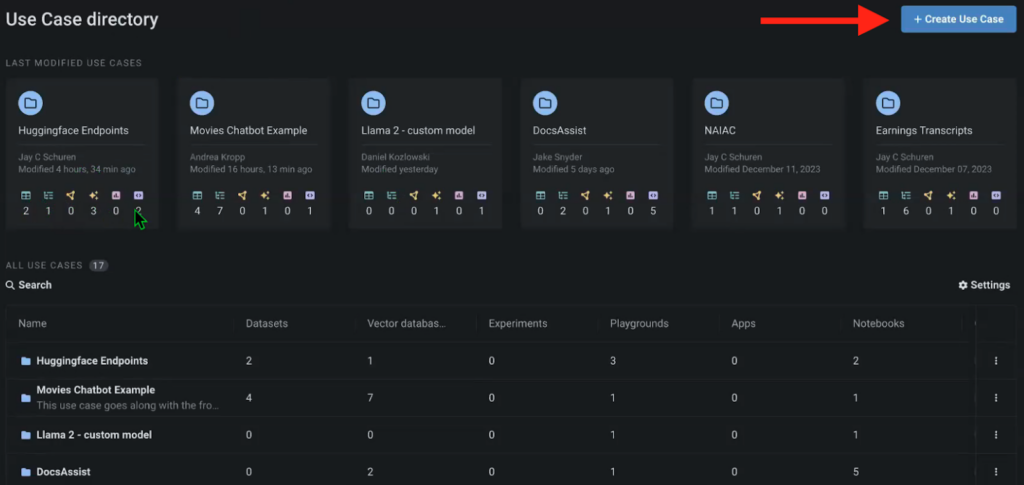
To explore diverse model outputs from the HuggingFace library, we’ve developed a test scenario.
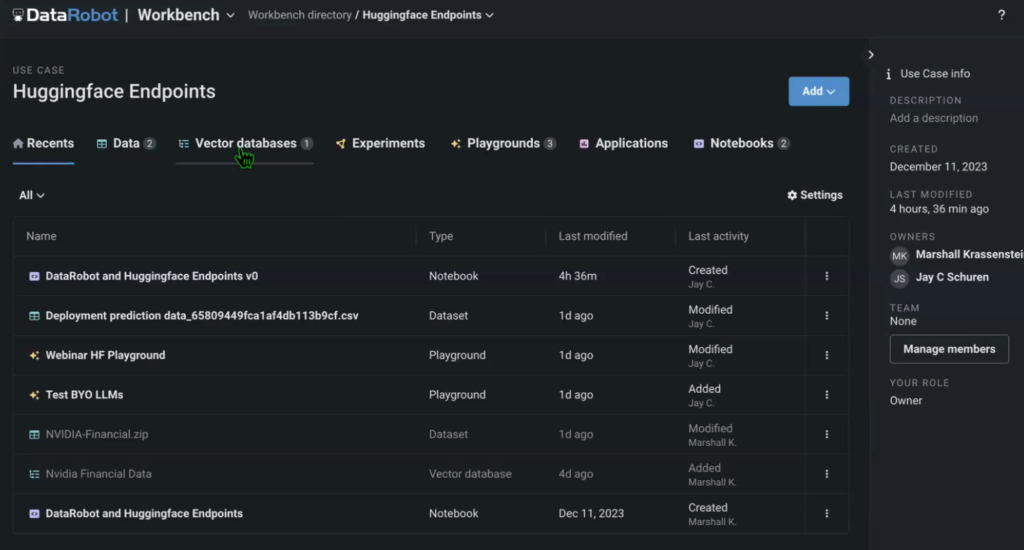
The case study incorporates knowledge, specifically leveraging an NVIDIA earnings call transcript as the source data, which is combined with a vector database created using HuggingFace’s embedding model, the LLM Playground for model examination, and the source notebook responsible for executing the solution.
Constructing a use case is feasible within a DataRobot Pocket book, leveraging both default and HuggingFace capabilities. This can be achieved through importing and customizing existing Jupyter notebooks.
With the comprehensive supply paperwork, vector database, and manifold endpoints in hand, it’s now possible to establish corresponding pipelines within the LLM Playground.
Traditionally, the comparison could be performed manually in a spreadsheet, with results displayed directly within the sheet. While this expertise may be suboptimal for examining distinct fashion styles and their corresponding parameters.
This intuitive interface enables simultaneous execution of multiple models, allowing for real-time questioning and output retrieval while also permitting adjustments to model settings and result exploration. Here is the rewritten text:
Another opportunity for experimentation lies in exploring alternative embedding styles, which can significantly impact the performance of the model depending on the language employed for both prompting and output generation.
This course simplifies numerous manual steps required in a workbook to execute complex model comparisons. The Playground arrives pre-configured with various styles, including Open AI GPT-4, Titan, and Bison, among others, allowing for comparative evaluation of your custom models against these established benchmarks.
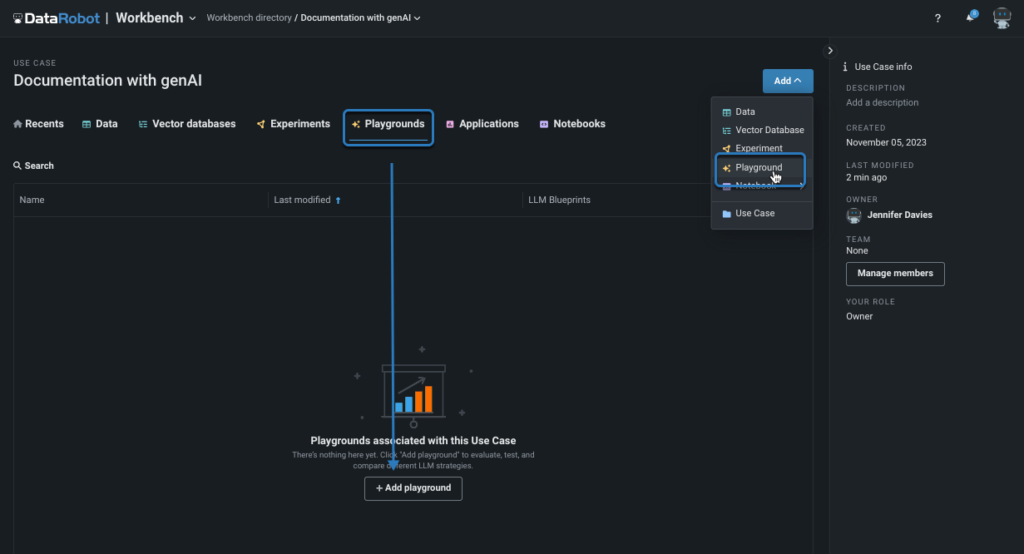
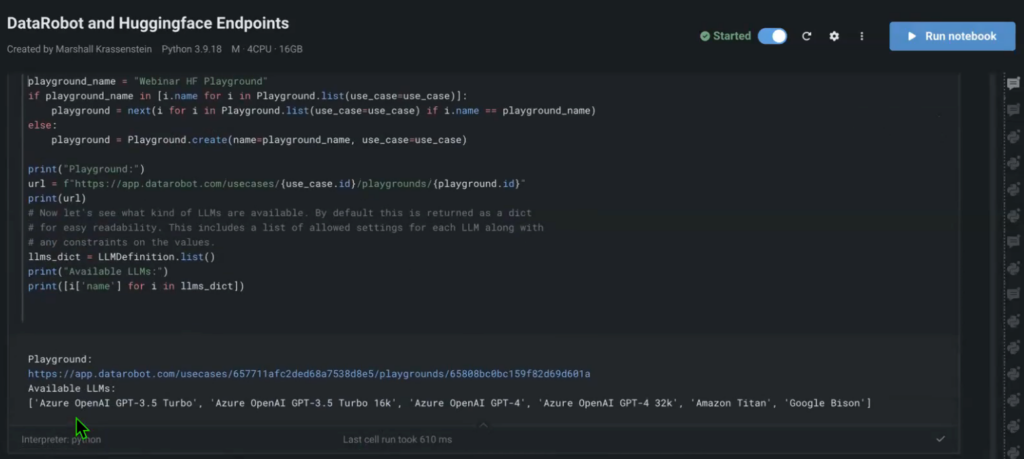
You’ll effortlessly integrate all HuggingFace endpoints into your project with mere lines of code.
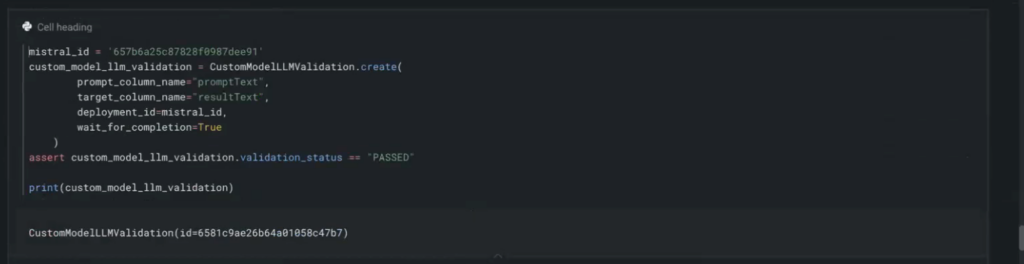
(Please note that if the original text cannot be improved, I’ll return “SKIP” only)
Once the playground is deployed and you’ve integrated your custom HuggingFace endpoints, you can revisit the playground, craft a fresh blueprint, and incorporate each of your tailored HuggingFace models. You may as well configure the system immediately and choose a popular vector database like NVIDIA’s monetary knowledge in this case.
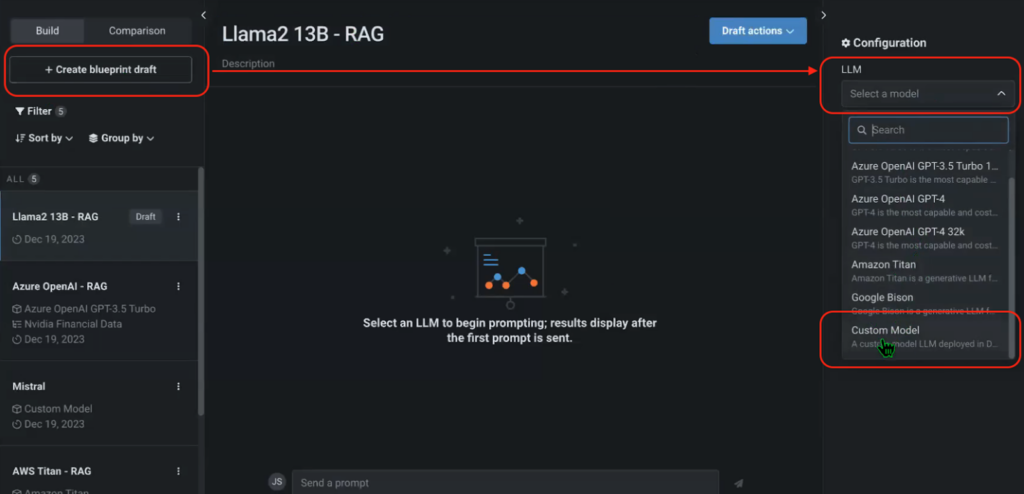
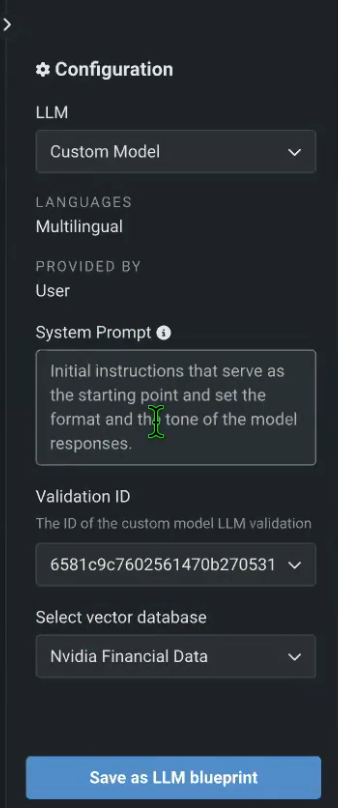
Figures 6, 7. What would happen if we seamlessly integrated Hugging Face’s pre-trained language models into our Large Language Model (LLM) playground? By incorporating their extensive array of endpoints, we could unlock a treasure trove of capabilities, from text classification to sentiment analysis.
To begin with, let us configure and include these powerful endpoints in our LLM playground.
After completing the deployment of customized fashions within the HuggingFace ecosystem, you will then be able to accurately assess their performance.
Navigate to the Comparability menu in the Playground and select the fashion options you wish to explore. Here is the rewritten text:
In this instance, we are assessing the performance of two tailored fashion models delivered via Hugging Face APIs, leveraging a default OpenAI GPT-3.5 Turbo architecture.
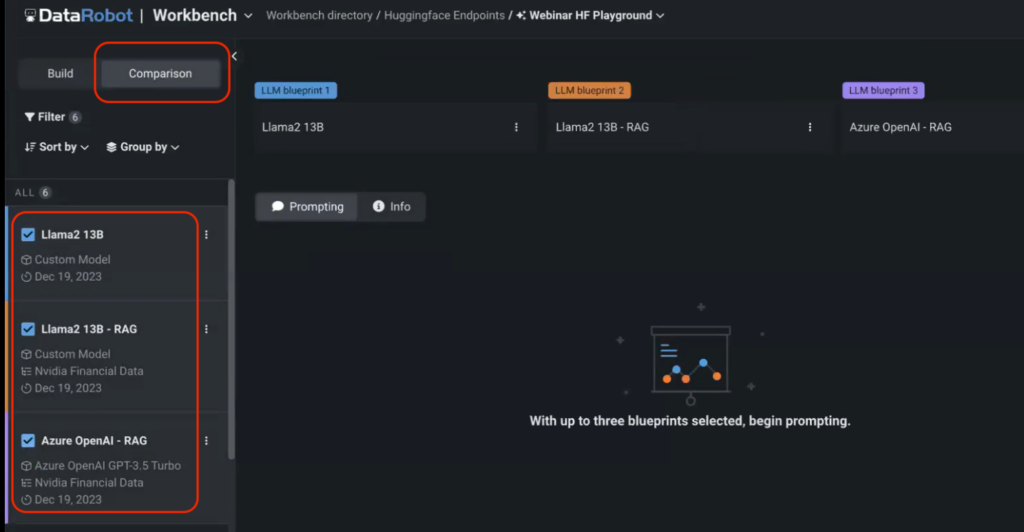
Without specifying the vector database for one of our many fashion models, we were unable to match the model’s performance against its RAG counterpart? As you’ll soon have the capability to start engaging with fashions and scrutinize their real-time responses.
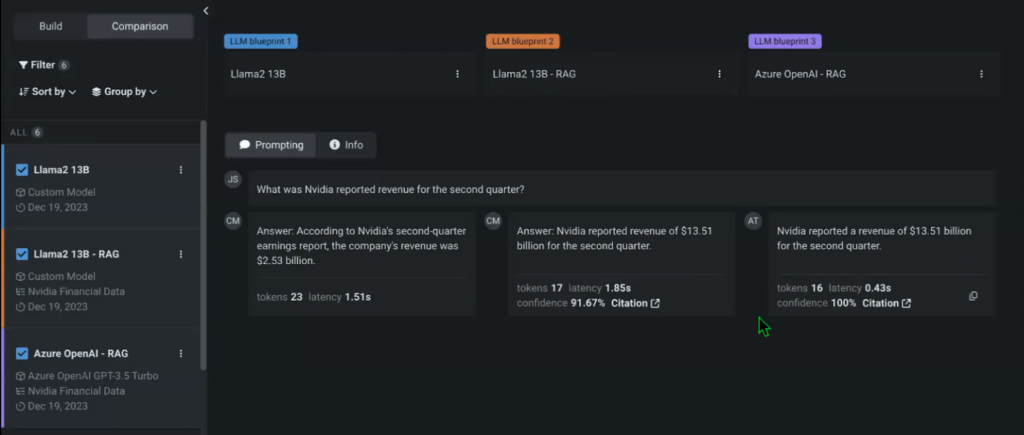
By leveraging the Playground’s vast array of settings and iterations, including Temperature, maximum completion tokens, and more, you can significantly enhance the versatility and customization options for any experiment. The non-RAG mannequin without access to the NVIDIA financial data vector database yields an inaccurate response, readily discernible to anyone.
Upon completing experimentation, you can register the selected model in the portal, serving as the central hub for all your model deployments.
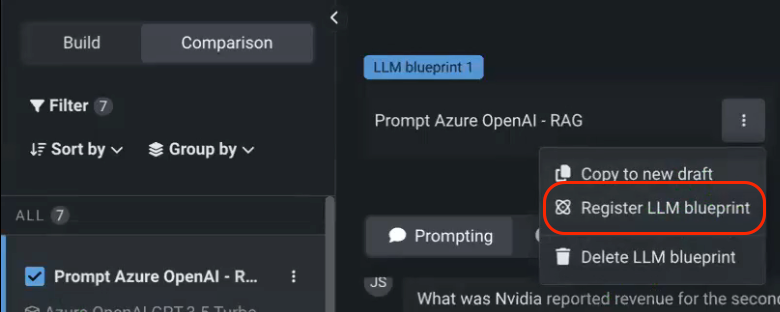
The origins of the mannequin are traceable to its registration, which involves recording the exact date of construction, purpose, and creator, thereby enabling accurate monitoring of its history. Instantly, the Console allows you to start monitoring a range of out-of-the-box metrics without additional setup, enabling you to track the performance and efficiency of your specific use case, with relevant insights readily available for analysis.
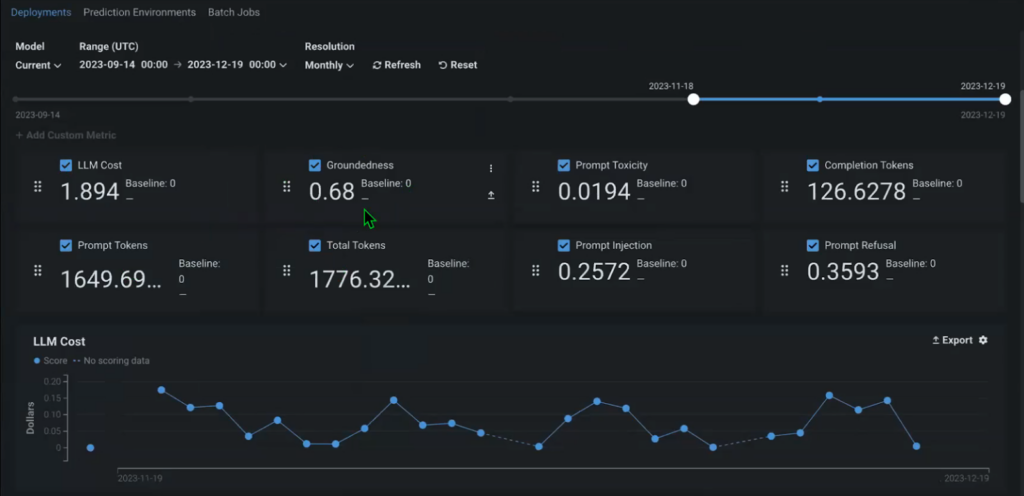
Groundedness is a crucial long-term metric that enables tracking of how well the presented context, including source materials, aligns with the model’s capabilities, measured by the proportion of source materials utilized in generating responses. This feature allows you to determine whether the information used in your response is accurate and relevant, replacing it if necessary.
By tracking the entire pipeline, including each query and response, along with the contextual information retrieved and passed through as the model’s output. Additionally, this includes a supply document that each individual response originated from.
Evaluating Large Language Models (LLMs) for suitability in a specific application necessitates a comprehensive approach, entailing deliberate examination of various interdependent factors. Significant adjustments will be made to each large language model (LLM), leading to substantial improvements in its performance.
This highlights the crucial role of experimentation and iterative refinement in ensuring the reliability and maximum impact of implemented solutions. Through rigorous testing against real-world scenarios, customers can identify potential constraints and opportunities for refinement before a solution goes into production.
To leverage the full potential of generative AI solutions, a robust infrastructure combining seamless user interactions, meticulous backend settings, and real-time monitoring is crucial, thereby ensuring the timely delivery of accurate and relevant outputs that meet users’ diverse needs.
By seamlessly integrating the extensive library of generative AI components from HuggingFace with a pre-built framework for modeling experimentation and deployment within DataRobot environments, organizations can quickly prototype and deploy robust generative AI solutions ready for real-world applications.
In regards to the writer

Nathaniel Daly serves as Senior Product Supervisor of AutoML and Time Sequence Products at DataRobot. He prioritizes harnessing breakthroughs in knowledge science to empower clients, enabling them to tackle pressing real-world business challenges effectively. He has earned a degree in Arithmetic from the University of California, Berkeley.