

{kind=link}
Humans possess a remarkable ability to efficiently process and analyze vast amounts of visual data, a skillset that is crucial for the development of artificial general intelligence (AGI). Researchers in artificial intelligence have spent considerable time developing Visible Query Answering (VQA) techniques that enable the interpretation of scenes within individual photographs and provide accurate responses to corresponding queries. While significant advancements have bridged the gap between human and machine visual processing capabilities, traditional Visual Question Answering (VQA) has remained limited to addressing individual images rather than comprehensive collections of visual data.
This constraint presents complexities in even more intricate scenarios. For instance, consider the complexities of identifying patterns in vast collections of medical images, tracking deforestation through satellite imaging, charting urban transformations via autonomous navigation data, dissecting thematic elements across large art collections, or deciphering consumer behavior from retail surveillance footage. Each scenario requires not only the visual analysis of numerous images but also necessitates comprehensive processing across all findings. To effectively address this complex issue, our mission centers on the “Multi-Picture Query Answering” (MIQA) task, significantly outperforming the capabilities of traditional Visual Question Answering (VQA) approaches.

Visible HaystacksThe primary visual-centric Needle-In-A-Haystack benchmark, meticulously crafted to rigorously evaluate the capabilities of models when processing large-scale multimodal data featuring long-range contextual dependencies.
Benchmark VQA Fashions on MIQA?
The “Needle-In-A-Haystack” problem has recently evolved into one of the common paradigms for benchmarking large language models’ ability to process inputs containing lengthy contexts and massive units of input data, such as long documents, videos, or hundreds of images. Within this complex task, crucial data (“the needle”) containing the answer to a specific inquiry is hidden within an extensive amount of irrelevant information (“the haystack”). The systems that then retrieve the related information and reply the query with accuracy will have to incorporate machine learning algorithms.
The primary benchmark for visual reasoning, as measured by the National Institute of All the Surprising (NIAH), was introduced by Google in version 1.5 of their Gemini platform. The team requested that their fashion models retrieve text overlay from a large video and present the information in a unified format for analysis purposes? Current fashion trends seem to excel in this task, largely due to the robust Optical Character Recognition (OCR) retrieval capabilities at their disposal. What if we probe deeper into those ambiguities and explore more nuanced possibilities? Don’t fashion trends still prevail in their own way?
The Visible Haystacks (VHs) benchmark measures the performance of image recognition algorithms in a dataset containing diverse object categories and occluded objects. It assesses an algorithm’s ability to locate objects despite varying levels of visibility and occlusion, with VHs representing the percentage of correctly detected objects out of the total number of objects in the test set.
To assess visual-centric long-context reasoning abilities, we present the Visible Haystacks (VHs) benchmark. This novel benchmark aims to assess Large-scale Multimodal Models’ performance on vast, uncorrelated visual datasets across diverse scenarios. The VHs options consist of approximately 1,000 binary question-answer pairs, each set containing anywhere from 1 to 10,000 photos. Unlike earlier benchmarks focused on textual retrieval and reasoning, Visual Question Answering (VH) tasks centre on identifying specific visual content, such as objects, by leveraging photo and annotation data from the COCO dataset.
The VHs benchmark is divided into two core challenges, each intended to assess a model’s ability to accurately identify and analyze relevant images prior to generating responses. To mitigate the risk of relying solely on common sense or pattern recognition, we have meticulously crafted the dataset to preclude the possibility of achieving more than chance-level performance (>50%) without visually inspecting the images.
-
Among countless photos lies a singular, striking image of a solitary needle. Does the image featuring an anchor contain a distinct target object?
-
Two to five needle-in-a-haystack moments are scattered throughout the vast collection of photographs. Whether for all photographs featuring the anchor object, each one solely comprises the objective subject, or alternatively whether at least one such photo includes that objective focus.
Three Essential Findings from VHs
The Visible Haystacks benchmark poses significant challenges for contemporary Large-Scale Multimodal Models, highlighting their limitations in processing complex visual data. In our experiments Across both single and multi-needle settings, we examined various open-source and proprietary approaches in conjunction with state-of-the-art techniques from, , and. We establish a foundational “Captioning” standard, leveraging a dual-stage approach where images are initially annotated with LLaVA, followed by querying using the captions’ textual content. Under are three pivotal insights:
-
As single-needle settings transitioned to accommodate increased visual data, a noticeable drop in performance occurred, despite maintaining high oracle accuracy – a stark contrast to previous text-based benchmarks, which lacked this visual complexity. Current fashion trends are challenged by visual interference, especially when dealing with distracting stimuli. Despite its importance, attention should also be paid to the limitations of open-source Large Language Models (LMMs), such as LLaVA, that are currently restricted to processing only up to three images due to a maximum 2K context size constraint. Although proprietary styles like Gemini-v1.5 and GPT-4o boast extended context capabilities, they often struggle to process requests when the image count surpasses 1K due to payload size limitations inherent in using the API call.
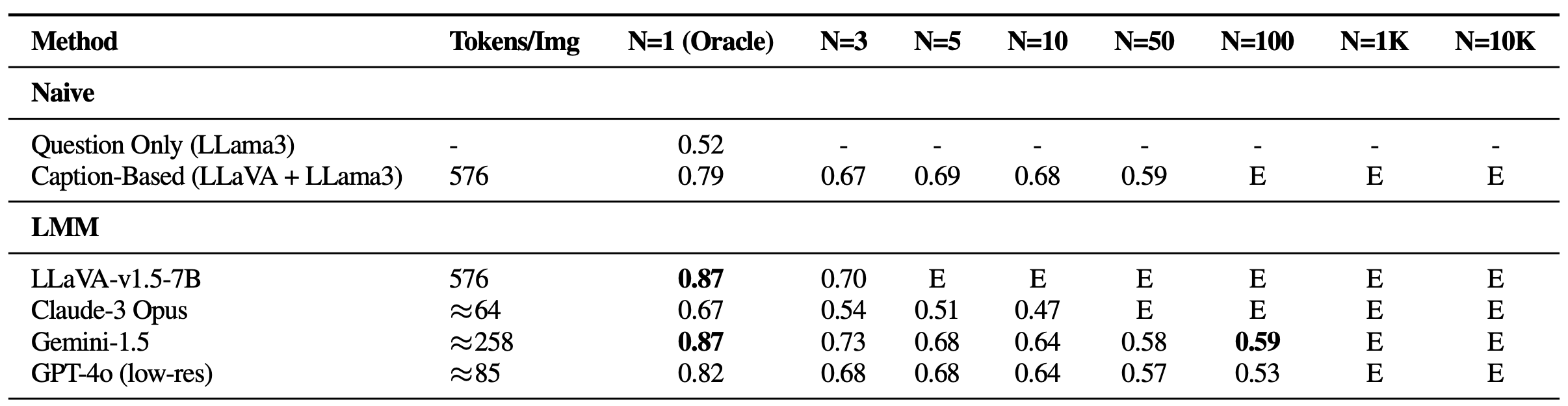
Efficiencies on Visual Histograms (VHs) for Single-Needle Questions are optimally achieved when data is accurately and precisely processed, thereby minimizing errors and maximizing the efficacy of clinical decision-making processes. As fashion expertise wanes in proportion to the magnitude of the haystack (N), implying that none can withstand conspicuous distractors with any tenacity. E: Exceeds context size.
-
All LMM-based approaches demonstrate subpar performance when utilizing five or more images for single-image question-answering, compared to the fundamental strategy combining a captioning model (LLaVA) with a large language model aggregator (Llama3). This inconsistency highlights the contrast between large language models’ ability to seamlessly integrate lengthy captions and the limitations of existing LMM-based solutions in handling information across multiple images. The performance noticeably falters when dealing with multiple images, as Claude-3 Opus struggles to produce reliable results with a single oracle photo, while Gemini-1.5 and GPT-4o experience a significant drop in accuracy, plummeting to 50%, which is equivalent to making random guesses, when processing larger sets of fifty images?

Outcomes on Virtual Humans (VHs) for Multi-Needle Questions: A Review of the Evidence? Visually-oriented fashion trends consistently underperform, suggesting a fundamental struggle to effectively integrate visual cues in their design.
-
Ultimately, our research revealed that the positioning of the needle image within the input sequence has a profound impact on the accuracy of Longest Matching Modules (LMMs). When the needle picture is placed immediately before the query, LLaVA exhibits significantly improved efficiency, with a notable 26.5% reduction in performance degradation if positioned at any other time. While proprietary designs tend to perform better when introduced at the outset, they can see a notable decline of up to 28.5% if not placed first. The sample illustrates a well-known phenomenon in Pure Language Processing, where information situated at the outset or terminus of the context significantly impacts model performance. The lack of apparent difficulty in previous Gemini-style National Institute for Astrophysics (NIAH) analyses, reliant on straightforward textual content retrieval and reasoning, highlights the distinct challenges presented by our Verification and Hypothesis (VHs) benchmark.
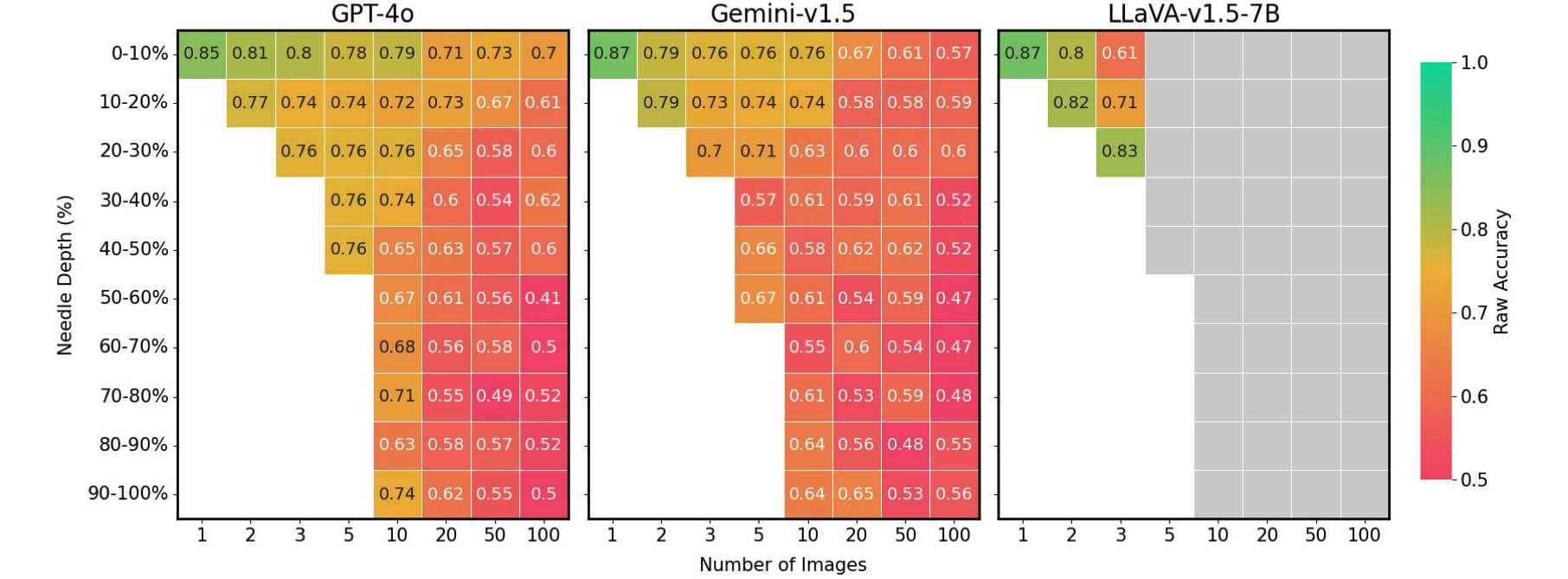
Needle place vs. Optimizing Efficiency of Variable-Hue Displays for Varying Picture Settings Current Linear Magnetic Motors (LMMs) experience a significant performance degradation of up to 41% in efficiency whenever the needle is not optimally aligned. Grey containers: Exceeds context size.
MIRAGE: An Innovative Framework for Enhanced VHs Performance
Based on the experimental outcomes above, it’s evident that the primary hurdles of contemporary MIQA approaches stem from the inability to (1) precisely relate disparate images from an unlimited pool without positional biases and (2) effectively connect visual information in these images to provide accurate responses to queries. We introduce MIRAGE, a novel, open-source, single-stage coaching paradigm that seamlessly extends our existing framework to tackle MIQA tasks. Here’s a glimpse of our mannequin design displayed below.
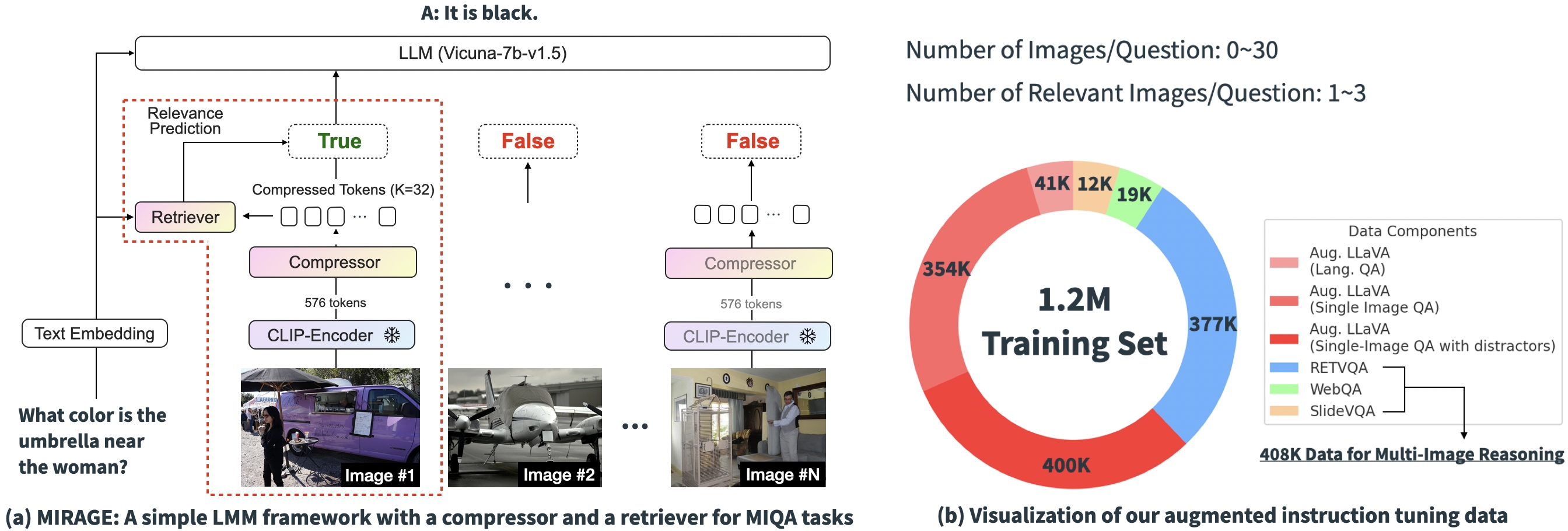
Our proposed paradigm comprises various components, each carefully crafted to address critical aspects within the MIQA activity.
-
The Mirage paradigm capitalizes on a query-aware compression framework, reducing the visible encoder tokens by an order of magnitude (to 1/10th their original size), thereby enabling the storage and processing of more images within the same contextual constraints.
-
MIRAGE leverages a trained retriever aligned with LLM fine-tuning to predict whether an image is relevant and dynamically filters out non-relevant photographs.
-
Merging Innovative Reasoning Architectures Globally (MIRAGE) elevates existing single-image instruction fine-tuning capabilities by incorporating multi-image reasoning expertise and artificial intelligence-driven insights.
Outcomes
Revisiting the VHs benchmark using MIRAGE’s capabilities.
MIRAGE excels in handling vast photo collections – from 1K to 10K images – and achieves exceptional efficiency on most single-needle tasks, despite its relatively modest 32-token single-image quality assessment framework.
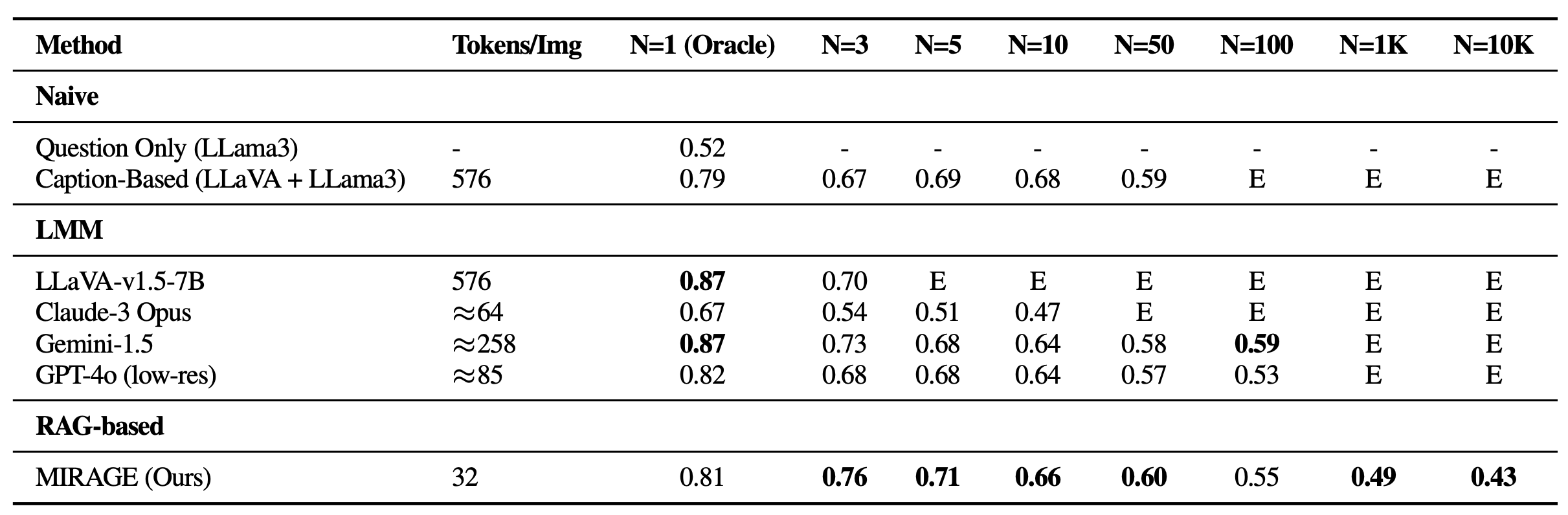
Additionally, we comprehensively evaluate the performance of MIRAGE alongside other LMM-based models on a diverse spectrum of visual question-answering tasks. On multi-image duties, Mirage demonstrates a strong capacity for recalling and accurately processing multiple images, surpassing even the most advanced language models such as GPT-4, Gemini-v1.5, and others. The model’s aggressive focus on a single image yields impressive QA performance.
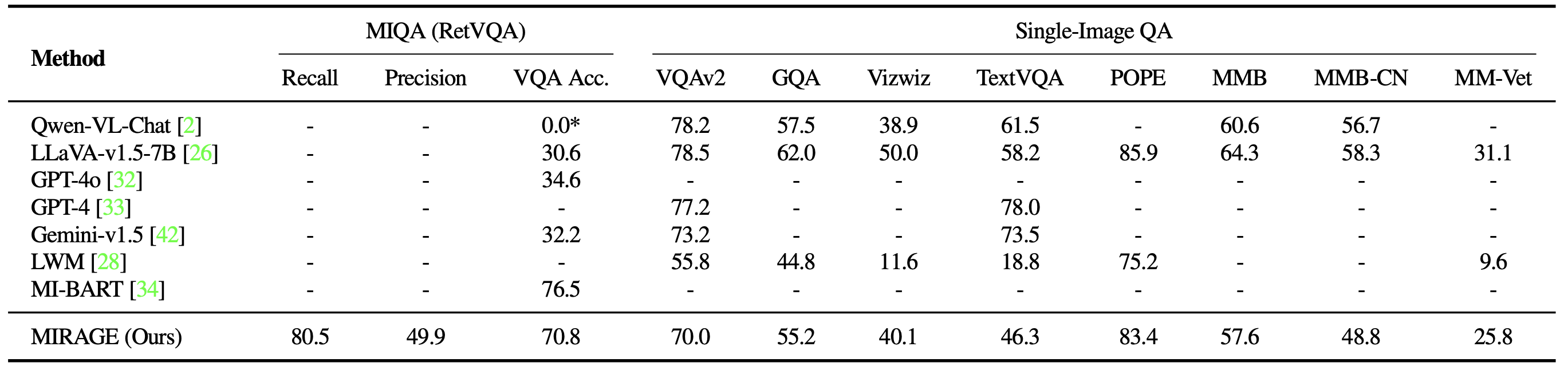
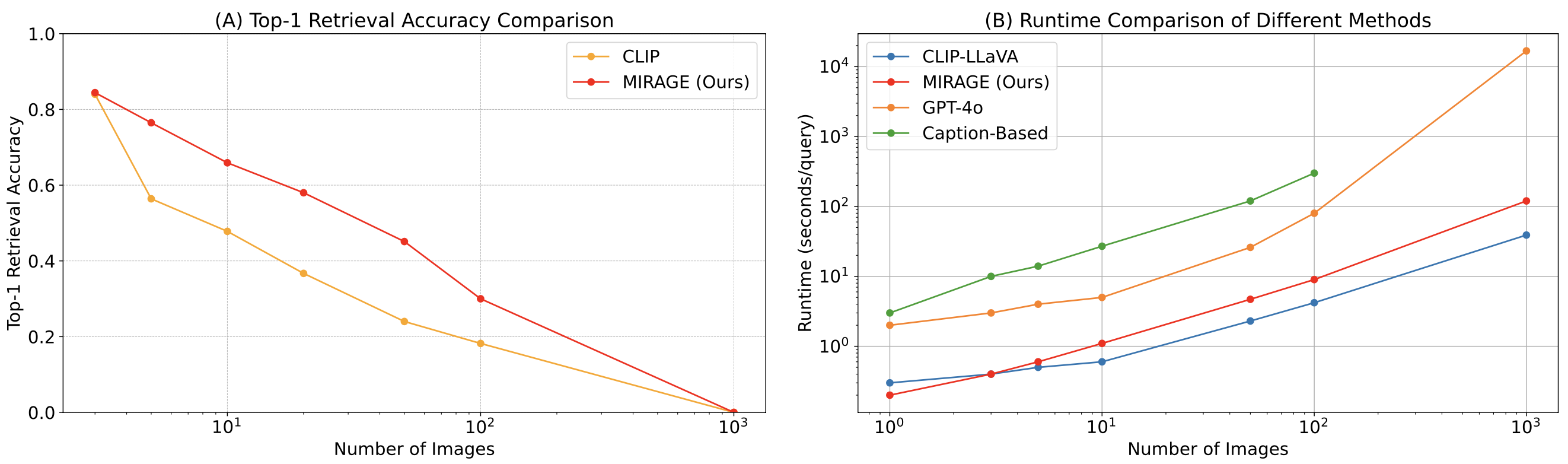
Lastly, we scrutinize MIRAGE’s co-trained retriever in detail. Our retriever significantly outperforms CLIP in terms of non-shedding effectiveness. While CLIP models excel at retrieving images with open-ended prompts, their performance may falter when confronted with question-like text queries.
To develop a more robust evaluation framework, we introduce the Visible Haystacks (VHs) benchmark, identifying three key shortcomings in existing Large-Scale Multimodal Models (LMMs).
-
As single-needle operations scale up, Large Memory Machines (LMMs) experience a pronounced drop-off in efficiency due to the surging volume of photographs, thereby highlighting a critical issue in effectively screening out non-relevant visual data.
-
While multi-needle settings often rely on straightforward captioning strategies borrowed from language-based question answering methods, surprisingly, these approaches consistently outshine existing Longitudinal Memory Models (LMMs) in processing information across multiple images, underscoring the limitations of LMMs in efficiently navigating complex visual data.
-
As various proprietary and open-source formats display distinct sensitivities towards the positioning of needle information within image sequences, a “loss-in-the-middle” phenomenon becomes apparent in the visual realm.
Here is the rewritten text:
Introducing Mirage, a groundbreaking visual Retriever-Augmented Generator framework that pioneers innovative solutions. MIRAGE tackles these hurdles with a groundbreaking visible token compressor, a collaboratively trained retriever, and finely tuned knowledge for multi-image instructions augmented by expertise.
Following the exploration of this blog post, it is recommended that all future Large Model Management (LMM) tasks utilize the Visual Haystacks framework to identify and address potential weaknesses prior to deployment. We strongly advocate for neighbourhoods to explore the vast potential of multi-image query answering, thereby accelerating the development of genuinely advanced Synthetic General Intelligence (AGI).
Please explore our services, discover our expertise, and click on the star button in our app.
@article{wu2024visual, title={Answering Complex Questions About Image Units}, author={Wu, Tsung-Han and Biamby, Giscard and Quenum, Jerome and Gupta, Ritwik and Gonzalez, Joseph E. and Darrell, Trevor and Chan, David M.}, journal={arXiv preprint arXiv:2407.13766}, year={2024} }