

{kind=link}
In the Reinforcement Learning Hierarchy (RLHF), a critical distinction lies between the reward-studying section, which leverages human preference judgments through comparative evaluations, and the RL fine-tuning segment, which optimizes a solitary, non-comparative reward signal. What if we employed a comparative approach to reinforce our RL endeavour?
Determine 1:
The revised text is: This diagram illustrates the distinction between reinforcement learning and classical conditioning. absolute suggestions and relative suggestions.
A novel element, pairwise coverage gradient, enables seamless unification of the reward modeling and reinforcement learning stages, facilitating direct updates based on pairwise responses.
Massive language models (LLMs) have driven the development of increasingly successful digital assistants, such as Siri, Google Assistant, and Alexa. These cutting-edge techniques are capable of responding to intricate customer inquiries, crafting complex code, and generating artistic poetry with ease. The fundamental methodology driving these sophisticated digital assistants is Reinforcement Learning augmented by Human Feedback (). To achieve alignment with human values and mitigate potential biases from its massive pre-training dataset, RLHF aims to synchronize the model’s behavior with ethical standards, thereby reducing the likelihood of unintended outcomes arising from exposure to voluminous amounts of subpar information during its initial training phase.
Proximal coverage optimization, the dominant reinforcement learning (RL) optimizer in its field, has been documented to demonstrate notable improvements and robustness. Despite its emphasis on comparison-based learning in the training phase, the RLHF course exhibits a persistent anomaly: during fine-tuning, individual responses are optimized independently without any inter-response comparisons being made. The variability in terminology can significantly amplify difficulties, notably within the complex realm of language technology.
Can we develop an RL algorithm that learns through comparative evaluation? To address this challenge, we propose Pairwise Proximal Coverage Optimization (PPCO), a novel approach that synchronises coaching processes in both the reward shaping stage and reinforcement learning (RL) fine-tuning stage of RL-human feedback (RLHF).
Background
Determine 2:
RLHF’s three phases? That’s a fascinating topic! As illustrated on the left side of Figure 1, the third stage is rooted in Reinforcement Learning with Absolute Feedback.
In traditional reinforcement learning (RL) frameworks, the reward function is typically defined by the designer or provided through a pre-specified reward scheme, akin to those used in classic Atari video games. While establishing a clear incentive for a mannequin to elicit helpful and benign replies poses significant challenges. By leveraging human feedback in the form of comparisons, Reinforcement Learning from Humans (RLHF) mitigates the limitations of solely relying on self-generated rewards, instead optimizing a learned reward function through careful consideration of human suggestions.
The RLHF pipeline’s complexity unfolds across distinct phases, characterized by the following nuances:
The pre-trained model is subjected to significant fine-tuning on an exceptionally high-quality dataset, thereby enabling it to mimic responses to human inquiries through imitation.
The SFT mannequin is equipped with a mechanism that receives input prompts (x) and responds by generating paired solution sets (y1, y2) according to the principles of pi[SFT](y| x). These generated responses form a dataset. Human labelers are presented with response pairs and asked to categorize their preference between two options, denoted as “(y_w > y_l)”. A comparative loss function is subsequently employed to train a reward model (r_phi).
[mathcal{L}_R = mathbb{E}_{(x,y_l,y_w)simmathcal{D}}log sigmaleft(r_phi(y_w|x)-r_phi(y_l|x)right)]
The Softmax-based Forecasting (SFT) mannequin initiates this process, with a Reinforcement Learning (RL) algorithm optimizing coverage to maximize rewards while minimizing deviations from the initial forecast. Formally, that is performed via:
[maxπθ E[rsym(D,ysimπθ⋅x) [rφ(ysymx)−βD KL (πθ⋅x || πSFT ⋅x)]]]
A fundamental limitation of this approach lies in its lack of a well-defined and unique reward function. Given a reward function r(y | vert x), a simple perturbation in the reward of the immediate successor to r(y | vert x) + δ(x) yields another legitimate reward function. While two reward features converge on identical losses for any response pair, they exhibit significant disparities when optimized against RL. In cases where excessive noise introduces a broad reward spectrum, reinforcement learning algorithms may be deceived into prioritizing opportunities yielding larger, potentially insignificant, rewards over others, despite their lesser magnitude. The provision of coverage may be compromised by the reward scale data in proximity, neglecting the valuable aspect of the relative preference embodied by the reward disparity? To effectively address this issue, we aim to design a Reinforcement Learning (RL) algorithm that
Derivation of P3O
Our concept is rooted in a fundamental understanding of the traditional coverage gradient (), which we’ve reimagined. VPG, an extensively adopted first-order RL optimizer, stands out for its simplicity, ease of implementation, and widespread adoption. In a contextual bandit setting, the VPG is formulated as: Maximize expected cumulative reward E[∑t=1T r_t] over T time steps, where r_t is the reward at time t and θ is the policy parameter.
[nabla mathcal{L}^{text{VPG}} = mathbb{E}_{ysimpi_{theta}} r(y|x)nablalogpi_{theta}(y|x)]
By means of algebraic manipulation, the coverage gradient is reconfigured into a comparative form encompassing two identical instant responses. We title it :
[mathbb{E}_{y_1,y_2simpi_{theta}}left(r(y_1vert x)-r(y_2vert x)right)nablaleft(logfrac{pi_theta(y_1vert x)}{pi_theta(y_2vert x)}right)/2]
Unlike Value-Policy Gradients (VPG), which solely relies on the magnitude of the reward, Proximal Policy Gradient (PPG) leverages the reward structure. This allows us to circumvent the issue of reward translation, thereby eliminating a potential hurdle. To further optimize efficiency, our approach incorporates a replay buffer to prevent large gradient updates.
We sample a batch of responses from the replay buffer, comprising outputs derived from π_textual content_{outdated}, and then calculate the importance sampling ratio for each response pair. The gradient is calculated as a weighted average of the gradients derived from each response pair.
While clipping the significance sampling ratio and replacing gradients helps curb overly large update steps? This approach enables the algorithm to strike a balance between minimizing Kullback-Leibler divergence and optimizing reward, thereby achieving more efficient trading-off.
Two alternative approaches exist for implementing the clipping method, differing in their approach to separating or combining clipping processes.
P3O, a pairwise proximal coverage optimization algorithm, has two variants: V1 and V2. You can discover additional details within our exclusive offerings.
Analysis
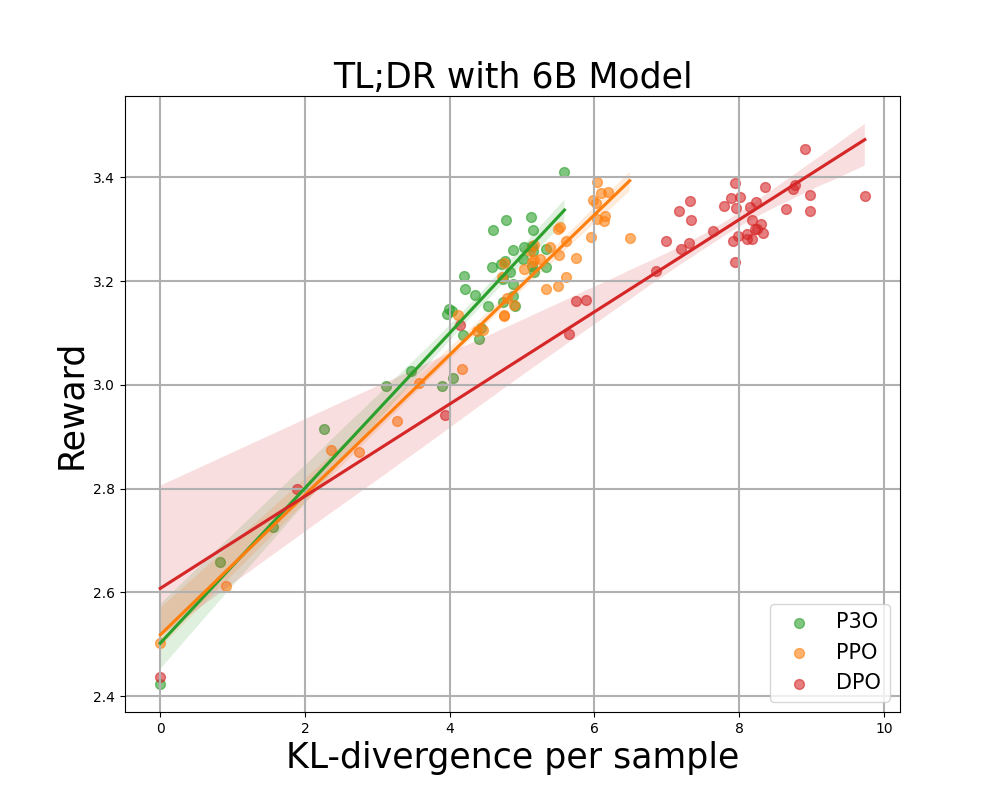
Determine 3:
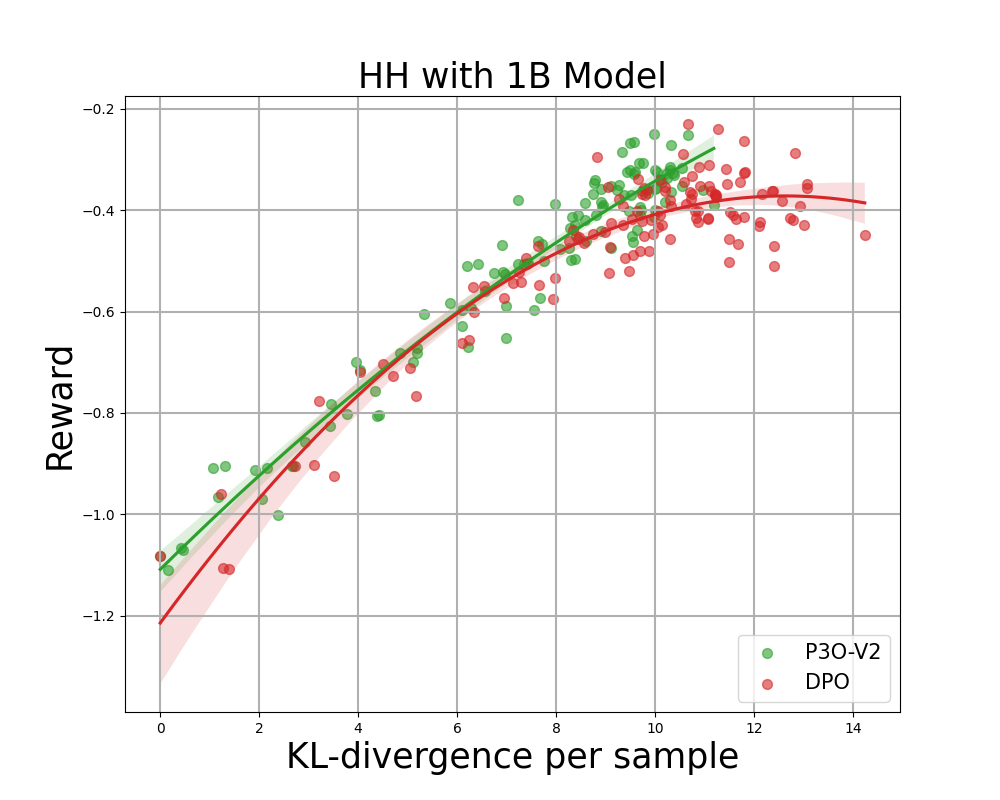
Reward frontiers for TL;DR: Each sequence-wise KL divergence and corresponding reward values are averaged across 200 prompts and calculated every 500 gradient steps. We find that an easy linear operation fits the curve seamlessly. While P3O offers a competitive KL-Reward trade-off among various three-point options,
We identify two distinct open-ended text-based technology tasks.
Summarizing the dataset, we extract insights from discussions on a Reddit forum where submissions (x) are matched with abstracts (y). We utilize Anthropic’s Useful and Innocent framework for question-answering, where x represents diverse human queries on various topics, and y aims to deliver engaging and informative responses that meet user expectations.
We assess our algorithm’s performance using multiple state-of-the-art and expert-approved methods for large language model alignment. We start by examining the coverage provided by most chances. For reinforcement learning (RL) algorithms, we consider the dominant strategy as well as the newly proposed strategies. The DPO directly optimises the coverage trajectory towards a closed-form solution for the KL-constrained reinforcement learning problem’s resolution. While initially conceived as an offline alignment approach, we successfully adapt it for online use by incorporating a proxy reward function.
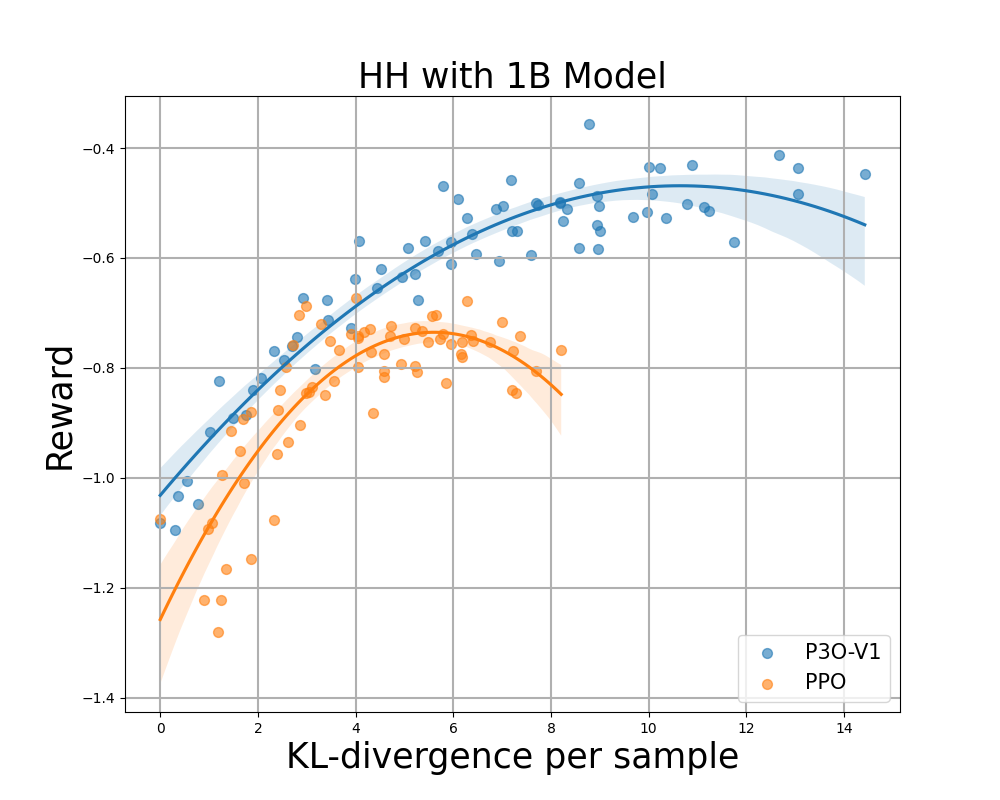
Determine 4:
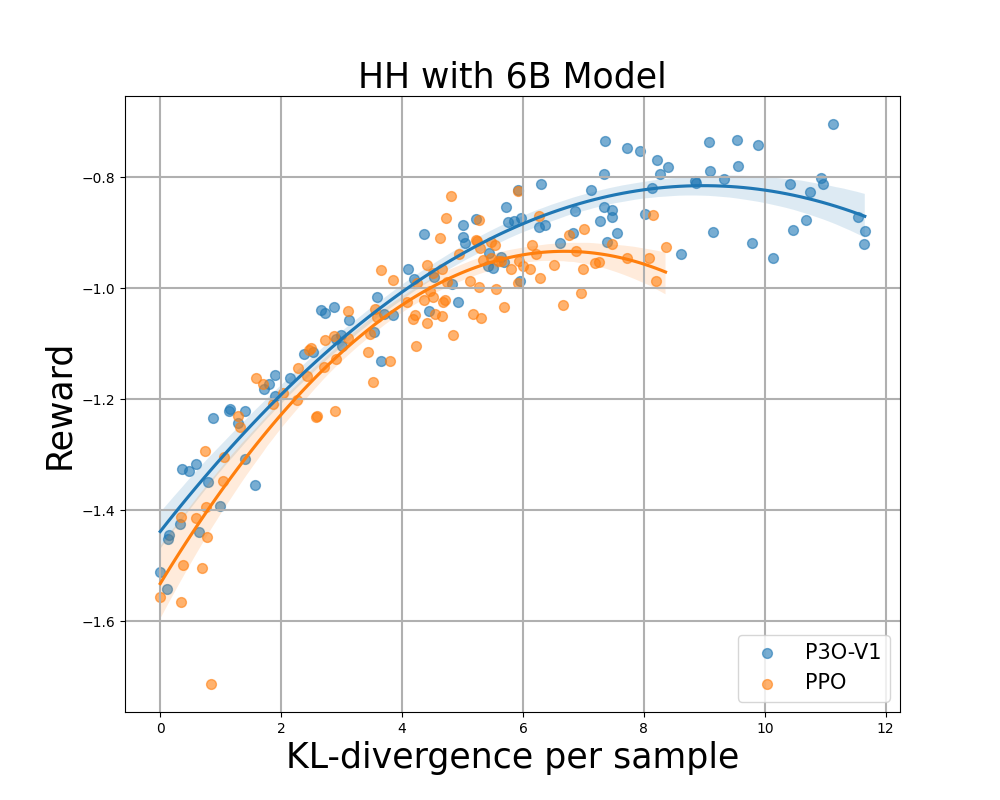
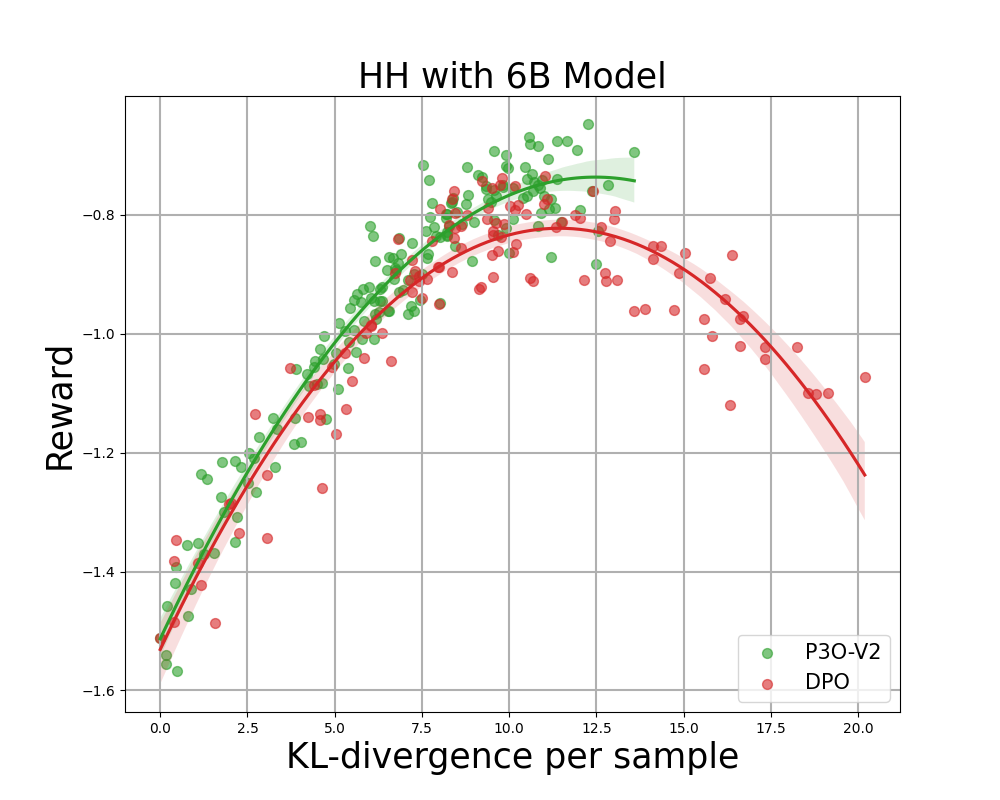
Reward Frontier for Hyperbolic Harmonics: Each level represents the mean outcome after 280 iterations, with calculations based on 500 gradient updates taken across various prompts. Two figures assess the performance of P3O-V1 and PPO with diverse base model sizes, while the other two figures evaluate P3O-V2 and DPO separately. Outcomes reveal that P3O is capable of achieving both increased rewards and superior KL divergence management simultaneously.
Excessive deviations from the reference coverage can lead to the web coverage compromising on the reward model, resulting in incoherent continuations, as previous studies have demonstrated. Here is the rewritten text: We’re excited to consider not just the well-established metric in RL literature – the reward – but also the extent to which the discovered coverage diverges from its initial state, quantified through KL-divergence measures. Subsequently, we evaluate the performance of each algorithm based on its best possible reward and the similarity to the reference coverage, measured by KL-divergence. Throughout various model sizes, Determine 4 and Determine 5 reveal that P3O boasts distinctly superior frontiers compared to PPO and DPO.
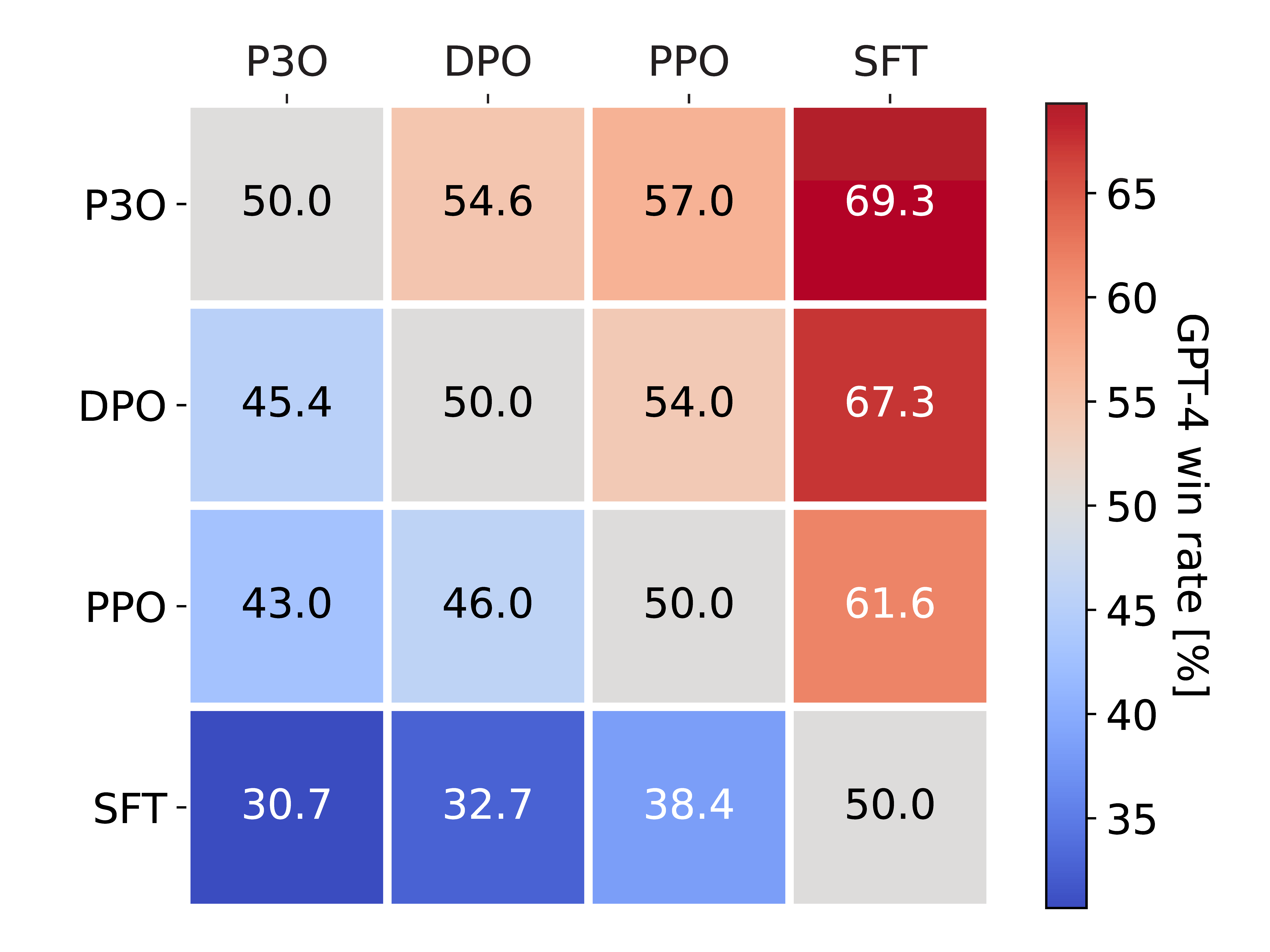
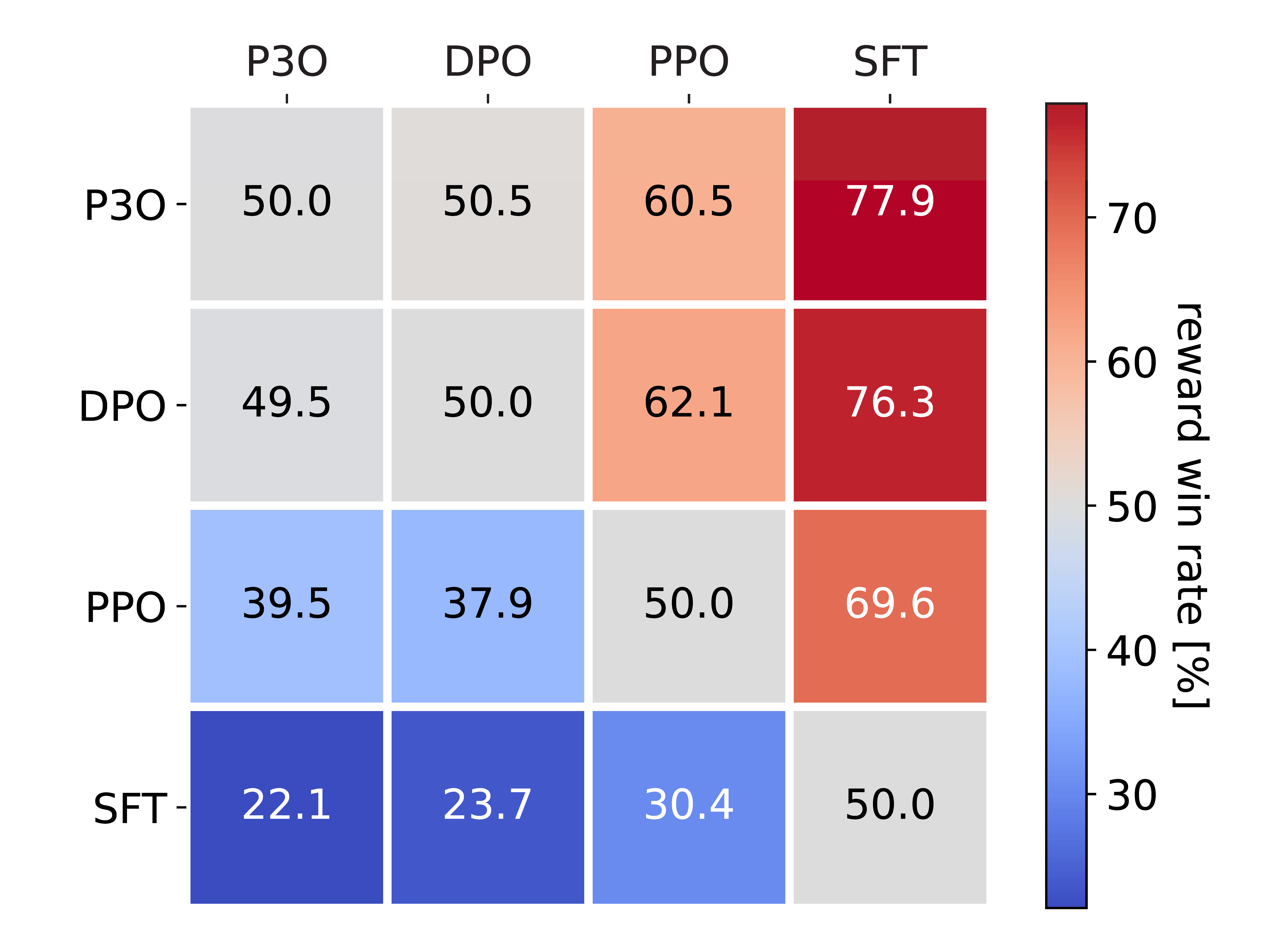
Determine 5:
Determining the winning bid fee assessed by GPT-3. Determines presentation fees primarily based on a direct comparison of the proxy reward. We observed that the relationship between the two metrics is substantial, necessitating an adjustment to the reward win fee in tandem with the Kullback-Leibler divergence to harmonize it with the GPT-4 win fee.
To objectively evaluate the quality of generated responses, we also conduct pairwise comparisons among all algorithms in the HH dataset.
To evaluate our approach, we utilize two key performance indicators: firstly, the optimized goal achievement in online reinforcement learning; secondly, the devoted proxy for human assessment of response helpfulness. The correlation between GPT-4 and human judgments is strikingly strong, with GPT-4 often exhibiting similar or even greater agreement rates compared to those between humans themselves.
Determines five outstanding examples of pairwise comparable results. The typical KL-divergence and reward rating of those fashions is DPO > P3O > PPO > SFT. While DPO yields slightly higher rewards than P3O, its substantial KL-divergence poses a significant threat to technological standards? Consequently, DPO boasts a reward-win fee of 49.5%, distinguishing it from P3O, yet only 45.4% according to the evaluation of GPT-4. Notably, while various approaches diverge, P3O’s GPT-4 performance yields a winning rate of 57.0% compared to PPO, and an impressive 69.3% against SFT. The results are consistent with our previous findings from the KL-Reward frontier metric, further supporting the notion that P3O has a higher alignment with human preferences compared to earlier benchmarks.
Conclusion
We present novel findings on harmonizing massive language models with human inclinations via reinforcement learning techniques. Here are our proposed improvements: We introduced the Reinforcement Learning with Relative Recommendations framework, as illustrated in Figure 1. Below this framework, we introduce a novel coverage gradient algorithm called P3O. This approach harmonizes the fundamental concepts of reward modeling and reinforcement learning (RL) refinement through collaborative guidance. Notable results indicate that our P3O approach outperforms previous methods in both KL-Reward frontier and GPT-4 win-rate metrics, showcasing its effectiveness.
BibTex
This blog relies heavily on our latest and greatest articles. If you find inspiration in our content, consider acknowledging its influence by citing us as a source.
@article{Wu2023Pairwise, title={Optimizing Pairwise Proximal Coverage for Large Language Model Alignment using Relative Suggestions}, author={Tianhao Wu and Banghua Zhu and Ruoyu Zhang and Zhaojin Wen and Kannan Ramchandran and Jiantao Jiao}, journal={arXiv preprint arXiv:2310.00212}, year={2023} }