

{kind=link}
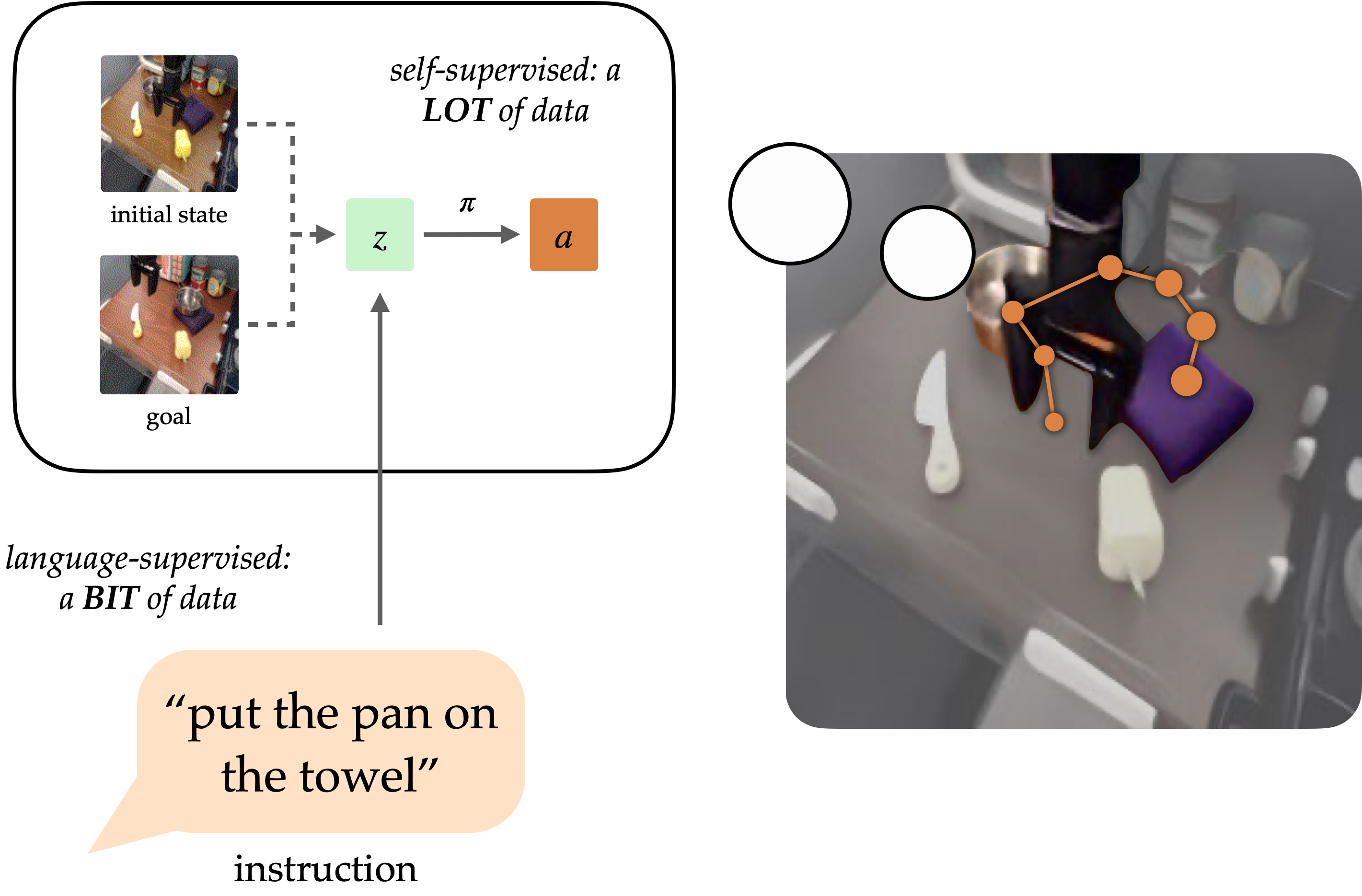
A long-standing goal within the realm of robotics research has been to develop general-purpose agents capable of performing tasks on behalf of humans. While pure language holds promise as a user-friendly interface for defining arbitrary tasks, it remains a challenge to train robots to accurately follow linguistic instructions. While approaches like language-conditioned behavioral cloning (LCBC) can swiftly replicate informed actions by conditioning them on language, they necessitate individuals to annotate every training trajectory, thereby generalizing poorly across scenarios and behaviors. While goal-conditioned methods excel in routine tasks, they hinder straightforward process definition for human users to execute complex operations effectively. Can we harmonize the expediency of task definition using LCBC-style methods with the productivity boosts from goal-conditioned learning?
A robotic system that follows instructions necessitates the possession of two fundamental abilities: To effectively execute its linguistic mandate within the physical environment, the system must first comprehend the instructions provided, and then be able to orchestrate a series of actions to complete the intended process. While these capabilities do not necessarily require end-to-end discovery from human-annotated trajectories, they can also be learned separately from relevant data sources. Information drawn from imaginative and prescient-driven human sources, rather than robotic systems, holds promise for advancing research into language grounding, fostering generalizable insights that can be applied across diverse scenarios and visual contexts. Meanwhile, unlabelled robotic trajectories can be leveraged to train a robot to achieve specific goal states, regardless of whether they are linked to linguistic instructions.
Conditioning on visible targets (i.e. Objective photographs provide complementary benefits for coverage studies. While targets’ flexibility in being freely generated and retrospectively labeled makes them appealing for scaling purposes, their inherent ambiguity can lead to inconsistent interpretation and measurement. Through this mechanism, insurance policies can be refined using goal-conditioned behavioral cloning on vast amounts of unlabelled and unorganized data from autonomous sensor-collecting robots, as well as trajectories gathered independently by the robot itself. Incorporating objectives is more straightforward when objects are easily comparable due to their visual representation as photographs, which can be directly contrasted pixel by pixel with other states.
Despite this, targets are significantly more challenging for human consumers to understand than plain language. It’s often easier for consumers to outline the task required rather than provide an objective depiction, as the latter may inadvertently necessitate performing the task itself to create the image. By introducing a language-based interface for goal-conditioned insurance policies, we enable the harmonious fusion of strengths from both goal-oriented and language-driven process specifications, thereby empowering generalist robots to operate under simple command control. By presenting our technique below, we enable the integration of vision-language knowledge to be applied in a wide range of directions and scenarios, thereby amplifying the physical capabilities of robots by processing vast amounts of unstructured data.
Purpose representations for instruction following
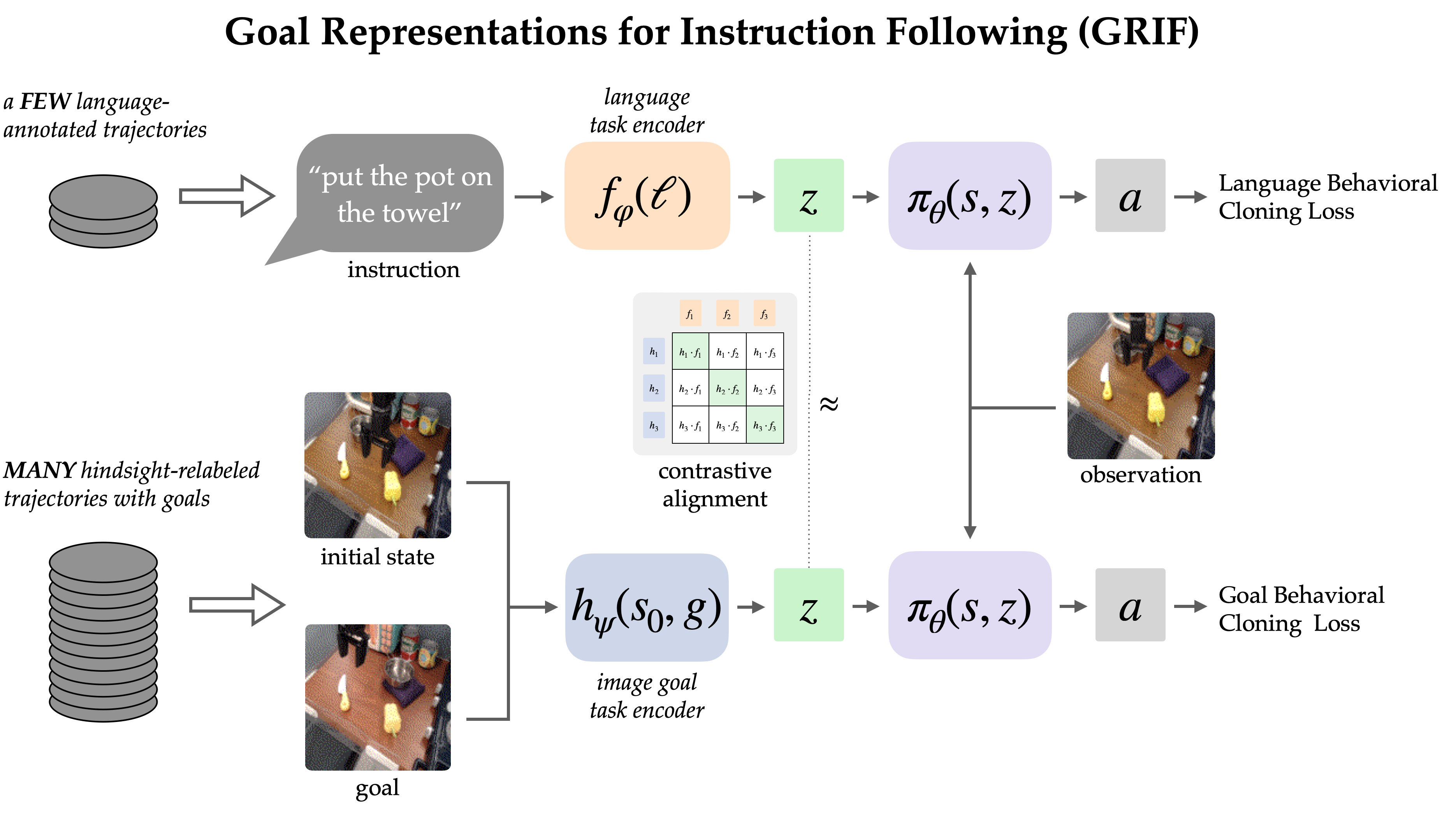
The GRIF mannequin comprises a language encoder, an objective encoder, and a coverage network. The encoders successfully align linguistic directions with objective photographic representations within a shared process illustration space, thereby situating the coverage community to predict actions effectively. While trained to predict actions based on both linguistic inputs and objective photographs, our primary focus lies in leveraging goal-conditioned training to boost the effectiveness of language-conditioned scenarios.
Our method, Can representations for instruction following (GRIF) effectively facilitate learning outcomes by providing students with a framework to understand and complete complex tasks?Collectively trains a language-conditioned and goal-conditioned coverage model with aligned process representations. By integrating representations from various linguistic and objective modalities, we can effectively combine the benefits of goal-conditioned learning with those of language-conditioned coverage. The discovered insurance policies are able to generalize across languages and scenarios following training on primarily unlabeled demonstration data.
We trained GRIF using a comprehensive dataset comprising 7,000 labelled demonstration trajectories and 47,000 unlabelled ones, all situated within a kitchen manipulation context. With manual annotation required for each trajectory in this dataset, leveraging the unannotated 47,000-plus trajectories can significantly enhance efficiency.
To integrate knowledge from diverse sources, GRIF is trained in conjunction with language-conditioned behavioural cloning (LCBC) and goal-conditioned behavioural cloning (GCBC). The labelled dataset, encompassing language and objective process specifications, enables us to monitor the language- and goal-conditioned predictions, thereby ensuring that. LCBC and GCBC). The unlabeled dataset exclusively comprises target data and serves as a foundation for Generalized Cross-Entropy Boundary Correction (GCBC). While the distinction between Local Control Behavior Code (LCBC) and Global Control Behavior Code (GCBC) lies primarily in selecting the suitable duty illustration from its respective encoder, this difference ultimately feeds into a shared risk assessment framework designed to anticipate future actions.
By leveraging shared coverage communities, we can reasonably expect enhancements from utilizing unlabeled datasets for goal-conditioned training. Notwithstanding GRIF’s ability to facilitate a more significant shift between the two modalities lies in its recognition of the identical habits specified by some language directions and objective photographs alike, thereby permitting a stronger switch. We leverages this concept by enforcing the comparability of linguistic and goal-oriented representations to facilitate a coherent semantic processing mechanism. Unlabelled data can significantly enhance language-conditioned coverage since objective illustrations closely approximate the lack of explicit instructions.
Studying through contrasting forces drives alignment.
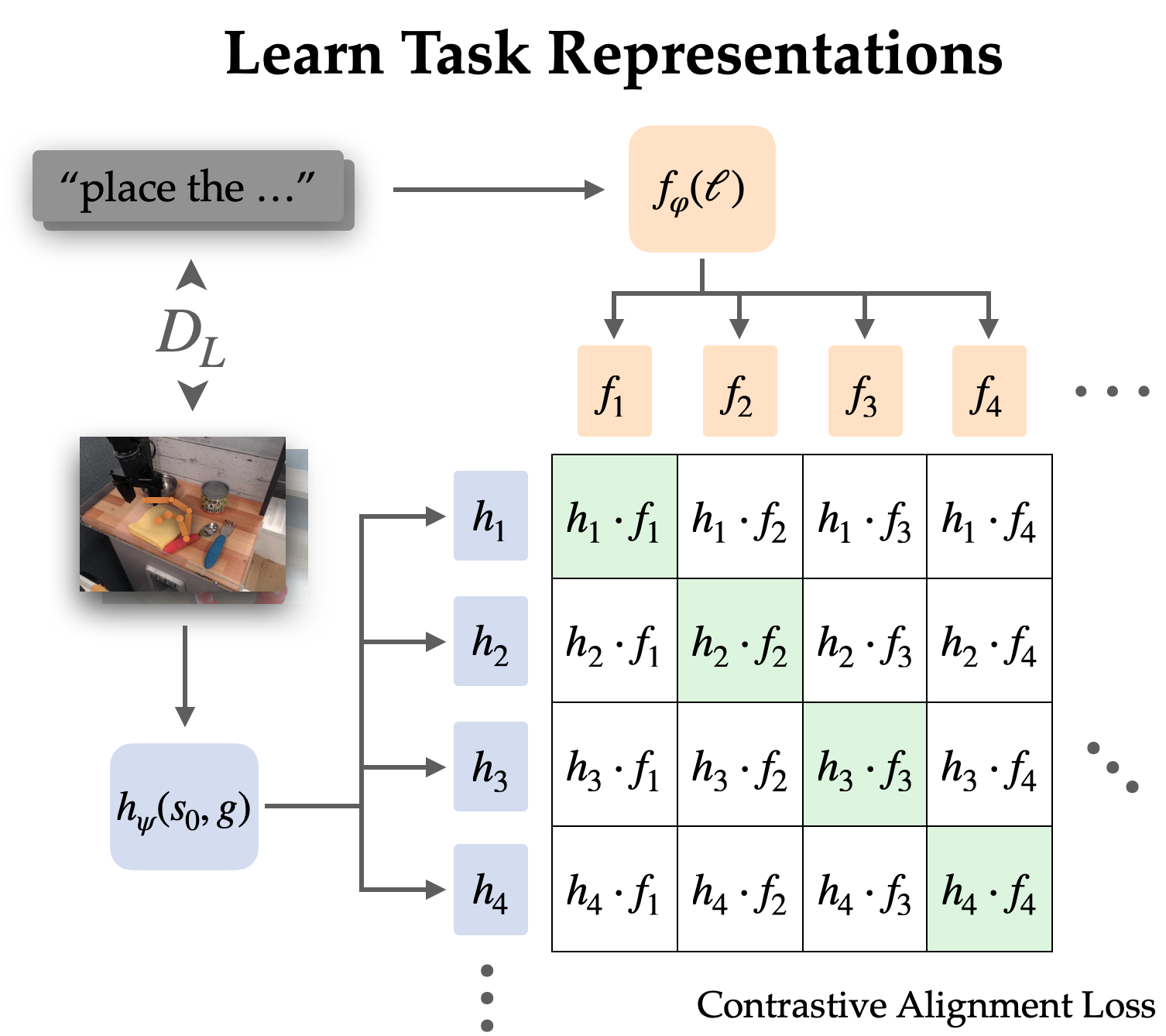
We explicitly align representations between goal-conditioned and language-conditioned duties within a labelled dataset through contrastive learning.
To accurately describe language’s inherent focus on relative changes, we opt to synchronize representations of state-goal pairs with linguistic instructions rather than merely associating objectives with language. Empirically, this simplification of representations leads to easier analysis as it disregards most details in images and focuses on the transition from subjective to objective states.
We investigate this alignment protocol through optimization of an infoNCE objective using the labelled dataset’s directions and images. We develop twin encoders for pictures and textual content by conducting contrastive learning on paired representations of languages and objectives. The target fosters an unwholesome affinity between depictions of identical processes, whereas exhibiting a dearth of similarity when referencing distinct ones, often drawing from varied trajectories to illustrate these contrasting scenarios.
When employing naive uniform sampling from the remaining dataset, the learned representations often overlook specific processes and straightforwardly align with directions and targets referencing the same scenes. To effectively utilize real-world coverage, it is more beneficial to decouple language from a specific scene, as we typically require disambiguation among distinct tasks within the same context. By employing an unconventional sampling method, we intentionally select up to 50% of our negative samples from distinct trajectories within the same scene.
In fact, this distinctive contrastive learning framework tantalizes the potential of pre-trained vision-language models such as CLIP, suggesting a synergistic fusion of visual and linguistic understanding.
They exhibit impressive zero-shot and few-shot generalization capabilities for vision-language tasks, providing a pathway to leverage large-scale pre-trained models and web-sourced data. Despite their versatility, many vision-language models are primarily designed for matching a solitary image with its description without accommodating environmental changes, which hinders their ability to focus on a specific object amidst complex backgrounds and perform subpar when tasked with concentrating on a single entity within cluttered scenes.
To effectively address these requirements, we develop a mechanism that enables the fine-tuning of CLIP for optimizing process representations in alignment. We adapt the CLIP architecture to accommodate a pair of images processed through early fusion, where channels are concatenated. The proposed approach appears to facilitate successful initialization for encoding pairs of state and objective photographs, leveraging its ability to retain pre-training benefits from CLIP with particular effectiveness.
Robotic coverage outcomes
We assess the overall effectiveness of GRIF by evaluating its performance in the real-world setting across 15 tasks spread across three scenarios. Directions are selected as a blend of those thoroughly represented in coaching materials and others that necessitate moderate creative extrapolation. The scene offers a unique combination of disparate elements.
We compare our proposed model, GRIF, with a baseline of plain LCBC, as well as more advanced models inspired by previous research, such as and. LLfP corresponds collectively to coaching with both LCBC and GCBC. In this context, BC-Z represents a tailored application of the underlying methodology to our distinct environment, specifically designed for the unique characteristics of LCBC, GCBC, and accelerated alignment periods. The algorithm optimises the cosine distance loss between duty cycle representations, without leveraging image-language pre-training.
Two primary fault lines had existed within the insurance policies. Without proper linguistic guidance, they will inevitably struggle, resorting to alternative methods or taking no constructive action at all. In situations where language grounding is insufficient, insurance policies may inadvertently trigger a chain reaction following completion of the proper protocol, as a singular instruction lacks contextual relevance.
Examples of grounding failures

Position the mushroom delicately inside the steel cooking vessel.

Put the spoon onto the towel.

Can you place the yellow bell pepper on the table?

Place the yellow bell pepper on the cutting board.
While avoiding catastrophic consequences from uncontrolled objects is crucial, This lack of coordination may be due to a poor understanding, uncertain timing, or inconsistent release of objects. Despite potential limitations of the robotic framework, a comprehensive GCBC coverage informed by your entire dataset can consistently achieve manipulation capabilities. While this failure mode typically indicates a lack of effective utilization of goal-conditioned data,
Examples of manipulation failures

“Move the bell pepper to the desk’s left side.”

Place the sliced bell pepper into the hot skillet.

Transfer the towel afterwards the microwave.
While evaluating the baselines, each one consistently struggled with two primary failure modes to varying degrees. Despite being heavily reliant on a small, labelled trajectory dataset, LCBC’s limited ability to manipulate data hinders its capacity to complete tasks effectively. The LLfP demonstrates a significant enhancement in its ability to learn from both labelled and unlabelled data, thereby showcasing a notable improvement in its capacity for manipulation compared to the LCBC. The algorithm consistently yields cost-effective results for straightforward instructions, but struggles to deliver comparable success with more intricate guidance. BC-Z’s alignment technique enhances manipulation capabilities, likely due to its ability to seamlessly transition between modalities. Despite lacking external visual and linguistic data, the model still faces challenges in extrapolating to novel scenarios.
GRIF showcases exceptional generalisation abilities, coupled with a robust capacity for manipulation. Is ready to fulfill its linguistic mandates, executing multiple tasks seamlessly within the given scope. Below are presented several rollout options along with their respective instructions.
Coverage Rollouts from GRIF

Transfer the pan to the entrance of the oven.

Place the sliced bell pepper into the hot skillet.

Put the knife onto the purple fabric.

Put the spoon onto the towel.
Conclusion
The Generalized Robust Information Fusion (GRIF) framework empowers robots to leverage vast amounts of unlabeled trajectory data to learn goal-conditioned insurance policies, thereby providing a “language interface” for seamless interaction with these policies via aligned linguistic and goal-oriented process representations. Compared to previous approaches linking language and images, our innovative framework successfully maps changes in visual states to linguistic descriptions, yielding substantial improvements over traditional CLIP-based methods for image-language matching. Our experimental findings demonstrate that by harnessing unlabeled robotic trajectories, our approach achieves significant boosts in efficiency compared to baseline methods and those relying exclusively on language-annotated data.
While our technique shows promise, it also exhibits several limitations that will likely need to be overcome in subsequent research. While GRIF might not be ideal for tasks that involve detailed instructions on how to perform a task, such as “pour the water slowly”, it’s possible that alternative methods could adapt to accommodate these qualitative directions by incorporating intermediate process execution steps and alignment losses. The language grounding assumptions made by GRIF hinge on the presence of fully annotated data segments within our dataset or leveraging pre-trained Visual Language Models. A potential avenue for further exploration lies in escalating our alignment loss to maximize the exploitation of rich semantic insights from vast online data reserves, thereby fostering a deeper understanding of complex concepts.
The method could leverage this information to improve linguistic understanding beyond its initial training data, thereby enabling more widely applicable and compliant robotic insurance policies that can accurately follow consumer instructions.
The study upon which this publication is based is:
The official blog of the Berkeley Artificial Intelligence Research (BAIR) Lab.

BAIR Weblog
The official blog of the Berkeley Synthetic Intelligence Analysis (BAIR) Lab.