

{kind=link}
Introduction
The bin packing dilemma poses a fundamental challenge in operations research, with significant repercussions for businesses across various sectors. The problem revolves around finding the most environmentally sustainable approach to packing a given set of objects within a finite number of containers, or “bins”, with the aim of optimizing space utilization and reducing waste.
This issue pervades numerous real-world applications, encompassing the optimization of transportation and logistics, as well as the efficient allocation of resources in knowledge hubs, data centers, and cloud computing infrastructures. Organizations facing overwhelming quantities of items and containers can reap significant cost savings and operational improvements by optimizing their packaging strategies.
As a leading $10 billion industrial gear manufacturer, bin packing plays a crucial role in optimizing their supply chain operations. Containers are frequently shipped by this firm to distributors who fill them with purchased components that are subsequently utilized in the production processes of heavy machinery and vehicles. As supply chain intricacy escalates and manufacturing objectives become increasingly varied, packaging engineers sought to optimize meeting trace configurations by combining the widest range of available components while efficiently allocating space.
To ensure a seamless production process, the meeting line requires a sufficient inventory of metal bolts to avoid downtime; nonetheless, storing a full shipping container is an inefficient use of factory floor space since only a small quantity of approximately dozens are needed daily. To overcome this limitation, a crucial first step involves optimizing container utilization through bin packing techniques, effectively simulating the insertion of thousands of components into various container configurations, thereby enabling automation of the container selection process and enhancing overall productivity.
| ❗Wasted area in packaging containers ❗Extreme truck loading & carbon footprint | Streamline Packaging: Minimize Unused Space Maximise truck loading capacity to reduce carbon emissions by optimising logistics efficiency. |
|---|---|
 |  |
Technical Challenges
While the bin packing challenge has been thoroughly investigated in academic settings, its practical application to large-scale, complex real-world datasets remains a persistent issue for many organizations.
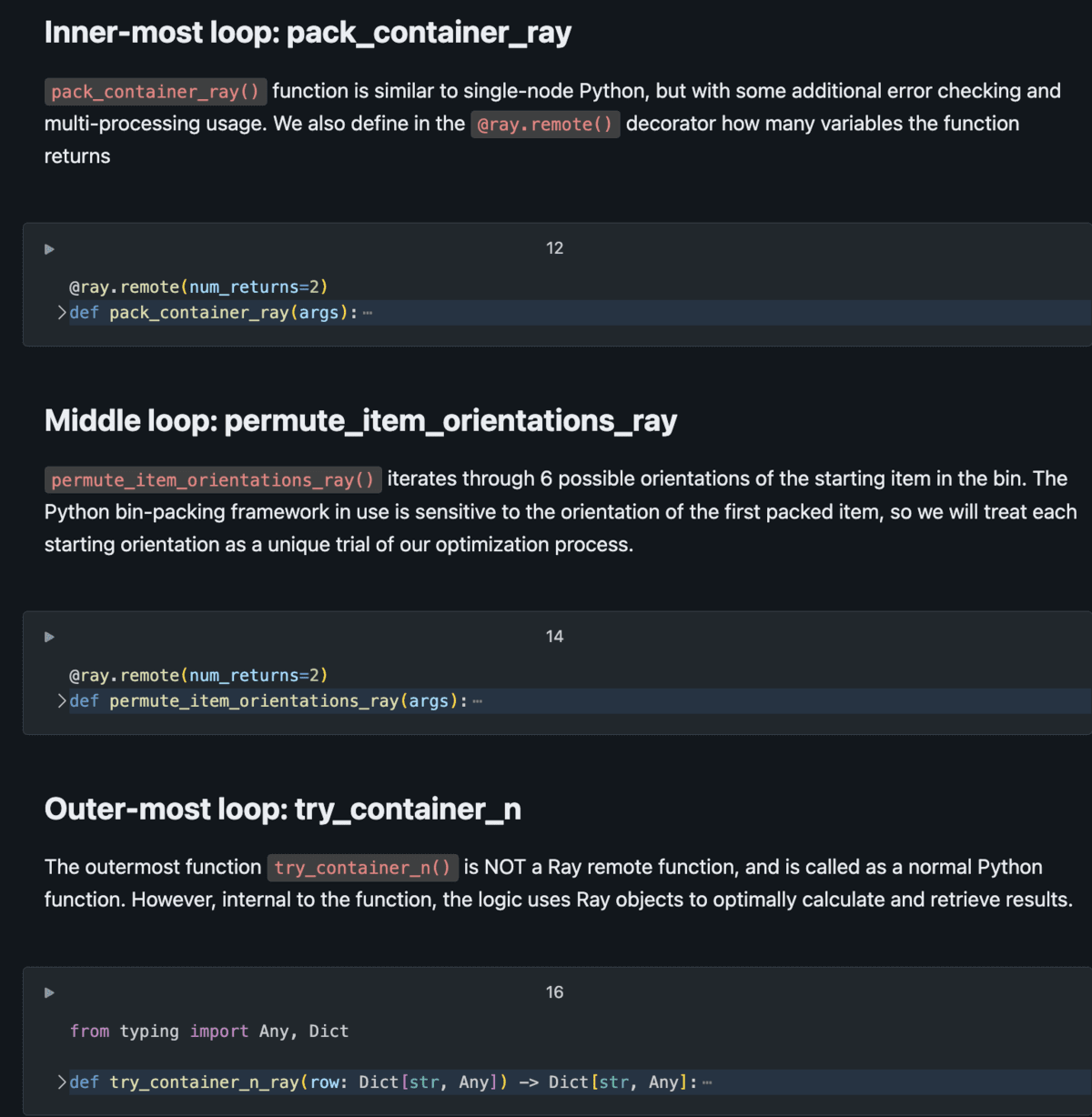
In a fundamental sense, this limitation is easily comprehensible for anyone to understand: fill the field with issues until it’s complete. Despite the significant potential of large-scale computational endeavors, formidable obstacles arise from the sheer magnitude of calculations required. In this Databricks buyer’s bin packing simulation, we utilize an intuitive psychological model for the optimization task. Utilizing pseudocode:
What if we were to run this looping course sequentially using a single node in Python? With thousands upon thousands of iterations, Estimating the number of possible combinations at 2.4 million may prove a daunting task, requiring an extensive amount of time and computational resources, for instance? Approximately 2.4 million combinations multiplied by one every second equals the total for an hour (3600 seconds), which translates to roughly 660 hours, or approximately 27 days. Ready for nearly a month to obtain the desired outcomes, which serve as an entry point for a subsequent modeling step, is unsustainable; we should provide an eco-friendly alternative that enables parallel processing rather than a sequential approach.
Scientific Computing With Ray
As a computing platform, Databricks has consistently supported scientific computing use cases; however, scaling these applications proves challenging due to the limitations of traditional optimization and simulation libraries, which are typically designed for single-node processing environments. To successfully scale these libraries with Spark, one often requires expertise in using instruments such as Pandas User-Defined Functions (UDFs)?
As Ray’s is set to launch in early 2024, clients will gain access to a cutting-edge software tool that empowers them to tackle complex optimization challenges at scale. While enhancing advanced AI functionalities, including reinforcement learning and distributed machine learning, this blog prioritizes optimizing custom Python workflows that necessitate intricate nesting, sophisticated orchestration, and seamless communication between tasks.
Modeling a Bin Packing Drawback
For successful scaling of scientific computing using Ray, the problem must be naturally parallelizable in a logical sense. Wouldn’t it be beneficial to model complex issues as a series of concurrent simulations or trials, enabling Ray to seamlessly scale the process? Given the diverse nature of items being packed into containers of varying sizes and orientations, bin packing presents an ideal fit to efficiently optimize storage capacity while minimizing waste. By incorporating Ray, this limitation can be effectively modelled as a hierarchical array of remote functions, enabling thousands of concurrent evaluations to operate simultaneously, with the level of parallelization constrained only by the number of available cores within a cluster.
The illustration below illustrates the fundamental configuration of this modeling issue.

The Python script features nested responsibilities, wherein outer tasks assign multiple occurrences to inner duties within each iteration. With the capability to utilize distant duties as an alternative to standard Python features, we can efficiently distribute computationally intensive tasks across a cluster, leveraging Ray Core’s management of the execution graph to return timely results. For comprehensive details on the implementation of the Databricks Resolution Accelerator, please refer to See the Databricks Resolution Accelerator.
Efficiency & Outcomes
Utilizing the techniques outlined on this blog and effectively illustrated throughout its content, the customer was able to:
- The implementation of the 3D bin packing algorithm represents a significant breakthrough, yielding not only highly accurate results but also a substantial reduction in processing time – a 40-fold decrease compared to traditional methods – thus expediting container selection.
- With Ray, the time to complete the modeling course would scale linearly with the number of cores in our cluster. To complete the task within a single day’s 12-hour time frame, approximately 56 cores would be required; for a three-hour timeframe, around 220 cores are necessary. On Databricks, this is easily managed via a cluster configuration.
- Ray simplifies complex code by offering an intuitive alternative for optimized jobs created with Python’s multiprocessing and threading libraries. The earlier implementation was hampered by the need for in-depth knowledge of those libraries, due to the complex nested logic structures employed. In contrast, Ray’s approach streamlines the codebase, thereby increasing its accessibility to skilled professionals. This ensuing code is not merely simpler to comprehend, but also adheres more closely to idiomatic Python conventions, thereby improving overall maintainability and efficiency.
Extensibility for Scientific Computing
The combination of automation, batch processing, and strategic container selection has yielded tangible benefits for the industrial producer, including a substantial reduction in transportation and packaging costs, as well as a significant boost to operational efficiency. As the bin packing limitation is overcome, professionals in the knowledge workforce are shifting their focus to other areas of scientific computing, such as optimization and linear-programming-based applications that require their expertise? The capabilities of Databricks’ Lakehouse platform provide an opportunity not only to model new business problems for the first time, but also to significantly enhance legacy scientific computing methods that have been in place for years.
While collaborating with Spark to handle parallel data processing tasks, Ray can also optimize logic-parallel limitations in a more effective manner. Companies can benefit from powerful software that leverages computational resources to model processes dependent solely on quantity, enabling the creation of data-driven organizations.
Discover the Databricks Resolution Accelerator, a powerful tool that streamlines complex data processing and accelerates your analytics workflow.