This provide comes from Woot, an Amazon-owned web site that focuses on sizzling offers. The deal is accessible in a number of configurations. You possibly can choose packs with six, eight, or 12 clips. You can even select from numerous designs. We’re specializing in the 8-pack, however you may pay even much less should you go for a 6-pack, which is simply $3.49.
These little clips solely have one job: holding your cables in place. They’ll do that job very effectively, although. And I occur to consider that organized cable administration really makes a distinction, particularly in your workspace or desk.
The premise is easy. The again has adhesive that may connect to almost any flat floor. Simply set up them the place you like and put your cables in them. The design is magnetic, so including and eradicating cables will likely be a breeze. And so they assist practically all wires, with a thickness of seven.5mm.
I’m really severely contemplating getting a pack of Canisflax Magnetic Cable Clips. I imply, what prices solely $4.99 today? And for one thing that may make your areas tidier, this can be a deal you received’t need to miss. This deal is accessible for just one extra day or “till offered out,” so go get yours as quickly as potential!
Thanks for being a part of our neighborhood. Learn our Remark Coverage earlier than posting.
Generative AI within the Actual World: Context Engineering with Drew Breunig
/
On this episode, Ben Lorica and Drew Breunig, a strategist on the Overture Maps Basis, discuss all issues context engineering: what’s working, the place issues are breaking down, and what comes subsequent. Hear in to listen to why big context home windows aren’t fixing the issues we hoped they may, why firms shouldn’t low cost evals and testing, and why we’re doing the sector a disservice by leaning into advertising and marketing and buzzwords reasonably than making an attempt to leverage what present crop of LLMs are literally able to.
Concerning the Generative AI within the Actual World podcast: In 2023, ChatGPT put AI on everybody’s agenda. In 2025, the problem shall be turning these agendas into actuality. In Generative AI within the Actual World, Ben Lorica interviews leaders who’re constructing with AI. Study from their expertise to assist put AI to work in your enterprise.
Try different episodes of this podcast on the O’Reilly studying platform.
Transcript
This transcript was created with the assistance of AI and has been calmly edited for readability.
00.00: All proper. So right this moment now we have Drew Breunig. He’s a strategist on the Overture Maps Basis. And he’s additionally within the strategy of writing a guide for O’Reilly referred to as the Context Engineering Handbook. And with that, Drew, welcome to the podcast.
00.23: Thanks, Ben. Thanks for having me on right here.
00.26: So context engineering. . . I bear in mind earlier than ChatGPT was even launched, somebody was speaking to me about immediate engineering. I stated, “What’s that?” After which in fact, fast-forward to right this moment, now individuals are speaking about context engineering. And I assume the quick definition is it’s the fragile artwork and science of filling the context window with simply the best data. What’s damaged with how groups take into consideration context right this moment?
00.56: I believe it’s vital to speak about why we want a brand new phrase or why a brand new phrase is smart. I used to be simply speaking with Mike Taylor, who wrote the immediate engineering guide for O’Reilly, precisely about this and why we want a brand new phrase. Why is immediate engineering not adequate? And I believe it has to do with the way in which the fashions and the way in which they’re being constructed is evolving. I believe it additionally has to cope with the way in which that we’re studying the right way to use these fashions.
And so immediate engineering was a pure phrase to consider when your interplay and the way you program the mannequin was perhaps one flip of dialog, perhaps two, and also you may pull in some context to present it examples. You may do some RAG and context augmentation, however you’re working with this one-shot service. And that was actually just like the way in which individuals had been working in chatbots. And so immediate engineering began to evolve as this factor.
02.00: However as we began to construct brokers and as firms began to develop fashions that had been able to multiturn tool-augmented reasoning utilization, instantly you’re not utilizing that one immediate. You have got a context that’s generally being prompted by you, generally being modified by your software program harness across the mannequin, generally being modified by the mannequin itself. And more and more the mannequin is beginning to handle that context. And that immediate may be very user-centric. It’s a consumer giving that immediate.
However after we begin to have these multiturn systematic modifying and preparation of contexts, a brand new phrase was wanted, which is this concept of context engineering. This isn’t to belittle immediate engineering. I believe it’s an evolution. And it reveals how we’re evolving and discovering this house in actual time. I believe context engineering is extra suited to brokers and utilized AI programing, whereas immediate engineering lives in how individuals use chatbots, which is a special discipline. It’s not higher and never worse.
And so context engineering is extra particular to understanding the failure modes that happen, diagnosing these failure modes and establishing good practices for each making ready your context but additionally establishing techniques that repair and edit your context, if that is smart.
03.33: Yeah, and likewise, it looks as if the phrases themselves are indicative of the scope, proper? So “immediate” engineering means it’s the immediate. So that you’re fidgeting with the immediate. And [with] context engineering, “context” may be a whole lot of issues. It may very well be the knowledge you retrieve. It’d contain RAG, so that you retrieve data. You set that within the context window.
04.02: Yeah. And other people had been doing that with prompts too. However I believe at first we simply didn’t have the phrases. And that phrase turned an enormous empty bucket that we stuffed up. You already know, the quote I at all times quote too usually, however I discover it becoming, is certainly one of my favourite quotes from Stuart Model, which is, “If you wish to know the place the longer term is being made, comply with the place the attorneys are congregating and the language is being invented,” and the arrival of context engineering as a phrase got here after the sector was invented. It simply form of crystallized and demarcated what individuals had been already doing.
04.36: So the phrase “context” means you’re offering context. So context may very well be a software, proper? It may very well be reminiscence. Whereas the phrase “immediate” is far more particular.
04.55: And I believe it is also like, it needs to be edited by an individual. I’m an enormous advocate for not utilizing anthropomorphizing phrases round giant language fashions. “Immediate” to me includes company. And so I believe it’s good—it’s a very good delineation.
05.14: After which I believe one of many very fast classes that folks understand is, simply because. . .
So one of many issues that these mannequin suppliers do after they have a mannequin launch, one of many issues they be aware is, What’s the dimensions of the context window? So individuals began associating context window [with] “I stuff as a lot as I can in there.” However the actuality is definitely that, one, it’s not environment friendly. And two, it additionally will not be helpful to the mannequin. Simply because you’ve gotten an enormous context window doesn’t imply that the mannequin treats the complete context window evenly.
05.57: Yeah, it doesn’t deal with it evenly. And it’s not a one-size-fits-all answer. So I don’t know for those who bear in mind final 12 months, however that was the massive dream, which was, “Hey, we’re doing all this work with RAG and augmenting our context. However wait a second, if we are able to make the context 1 million tokens, 2 million tokens, I don’t must run RAG on all of my company paperwork. I can simply match all of it in there, and I can continuously be asking this. And if we are able to do that, we basically have solved all the onerous issues that we had been worrying about final 12 months.” And in order that was the massive hope.
And also you began to see an arms race of everyone making an attempt to amplify and greater context home windows to the purpose the place, you already know, Llama 4 had its spectacular flameout. It was rushed out the door. However the headline function by far was “We shall be releasing a ten million token context window.” And the factor that everyone realized is. . . Like, all proper, we had been actually looking forward to that. After which as we began constructing with these context home windows, we began to appreciate there have been some huge limitations round them.
07.01: Maybe the factor that clicked for me was in Google’s Gemini 2.5 paper. Implausible paper. And one of many causes I like it is as a result of they dedicate about 4 pages within the appendix to speaking in regards to the form of methodology and harnesses they constructed in order that they may educate Gemini to play Pokémon: the right way to join it to the sport, the right way to really learn out the state of the sport, the right way to make decisions about it, what instruments they gave it, all of those different issues.
And buried in there was an actual “warts and all” case examine, that are my favourite while you discuss in regards to the onerous issues and particularly while you cite the issues you’ll be able to’t overcome. And Gemini 2.5 was a million-token context window with, finally, 2 million tokens coming. However on this Pokémon factor, they stated, “Hey, we really observed one thing, which is when you get to about 200,000 tokens, issues begin to disintegrate, and so they disintegrate for a number of causes. They begin to hallucinate. One of many issues that’s actually demonstrable is that they begin to rely extra on the context data than the weights data.
08.22: So inside each mannequin there’s a data base. There’s, you already know, all of those different issues that get form of buried into the parameters. However while you attain a sure degree of context, it begins to overload the mannequin, and it begins to rely extra on the examples within the context. And so this implies that you’re not benefiting from the total energy or data of the mannequin.
08.43: In order that’s a method it will possibly fail. We name this “context distraction,” although Kelly Hong at Chroma has written an unimaginable paper documenting this, which she calls “context rot,” which is an analogous approach [of] charting when these benchmarks begin to disintegrate.
Now the cool factor about that is which you can really use this to your benefit. There’s one other paper out of, I consider, the Harvard Interplay Lab, the place they have a look at these inflection factors for. . .
09.13: Are you acquainted with the time period “in-context studying”? In-context studying is while you educate the mannequin to do one thing that doesn’t know the right way to do by offering examples in your context. And people examples illustrate the way it ought to carry out. It’s not one thing that it’s seen earlier than. It’s not within the weights. It’s a unique drawback.
Effectively, generally these in-context studying[s] are counter to what the mannequin has realized within the weights. So that they find yourself combating one another, the weights and the context. And this paper documented that while you recover from a sure context size, you’ll be able to overwhelm the weights and you may pressure it to hearken to your in-context examples.
09.57: And so all of that is simply to attempt to illustrate the complexity of what’s occurring right here and the way I believe one of many traps that leads us to this place is that the reward and the curse of LLMs is that we immediate and construct contexts which are within the English language or no matter language you communicate. And in order that leads us to consider that they’re going to react like different individuals or entities that learn the English language.
And the actual fact of the matter is, they don’t—they’re studying it in a really particular approach. And that particular approach can fluctuate from mannequin to mannequin. And so it’s important to systematically method this to grasp these nuances, which is the place the context administration discipline is available in.
10.35: That is fascinating as a result of even earlier than these papers got here out, there have been research which confirmed the precise reverse drawback, which is the next: You could have a RAG system that truly retrieves the best data, however then one way or the other the LLMs can nonetheless fail as a result of, as you alluded to, they’ve weights so that they have prior beliefs. You noticed one thing [on] the web, and they’re going to opine towards the exact data you retrieve from the context.
11.09: So that is true even when the context window’s small really.
11.13: Yeah, and Ben, you touched on one thing that’s actually vital. So in my unique weblog submit, I doc 4 ways in which context fails. I speak about “context poisoning.” That’s while you hallucinate one thing in a long-running process and it stays in there, and so it’s regularly complicated it. “Context distraction,” which is while you overwhelm that delicate restrict to the context window and you then begin to carry out poorly. “Context confusion”: That is while you put issues that aren’t related to the duty inside your context, and instantly they suppose the mannequin thinks that it has to concentrate to these things and it leads them astray. After which the very last thing is “context conflict,” which is when there’s data within the context that’s at odds with the duty that you’re making an attempt to carry out.
A superb instance of that is, say you’re asking the mannequin to solely reply in JSON, however you’re utilizing MCP instruments which are outlined with XML. And so that you’re creating this backwards factor. However I believe there’s a fifth piece that I want to write down about as a result of it retains developing. And it’s precisely what you described.
12.23: Douwe [Kiela] over at Contextual AI refers to this as “context” or “immediate adherence.” However the time period that retains sticking in my thoughts is this concept of combating the weights. There’s three conditions you get your self into while you’re interacting with an LLM. The primary is while you’re working with the weights. You’re asking it a query that it is aware of the right way to reply. It’s seen many examples of that reply. It has it in its data base. It comes again with the weights, and it can provide you an exceptional, detailed reply to that query. That’s what I name “working with the weights.”
The second is what we referred to earlier, which is that in-context studying, which is you’re doing one thing that it doesn’t find out about and also you’re exhibiting an instance, after which it does it. And that is nice. It’s great. We do it on a regular basis.
However then there’s a 3rd instance which is, you’re offering it examples. However these examples are at odds with some issues that it had realized normally throughout posttraining, in the course of the fine-tuning or RL stage. A extremely good instance is format outputs.
13.34: Just lately a good friend of mine was updating his pipeline to check out a brand new mannequin, Moonshots. A extremely nice mannequin and actually nice mannequin for software use. And so he simply modified his mannequin and hit run to see what occurred. And he saved failing—his factor couldn’t even work. He’s like, “I don’t perceive. That is speculated to be one of the best software use mannequin there’s.” And he requested me to have a look at his code.
I checked out his code and he was extracting knowledge utilizing Markdown, basically: “Put the ultimate reply in an ASCII field and I’ll extract it that approach.” And I stated, “When you change this to XML, see what occurs. Ask it to reply in XML, use XML as your formatting, and see what occurs.” He did that. That one change handed each take a look at. Like mainly crushed it as a result of it was working with the weights. He wasn’t combating the weights. Everybody’s skilled this for those who construct with AI: the cussed issues it refuses to do, irrespective of what number of occasions you ask it, together with formatting.
14.35: [Here’s] my favourite instance of this although, Ben: So in ChatGPT’s net interface or their utility interface, for those who go there and also you attempt to immediate a picture, a whole lot of the photographs that folks immediate—and I’ve talked to consumer analysis about this—are actually boring prompts. They’ve a textual content field that may be something, and so they’ll say one thing like “a black cat” or “a statue of a person pondering.”
OpenAI realized this was resulting in a whole lot of unhealthy photos as a result of the immediate wasn’t detailed; it wasn’t a very good immediate. So that they constructed a system that acknowledges in case your immediate is simply too quick, low element, unhealthy, and it arms it to a different mannequin and says, “Enhance this immediate,” and it improves the immediate for you. And for those who examine in Chrome or Safari or Firefox, no matter, you examine the developer settings, you’ll be able to see the JSON being handed forwards and backwards, and you may see your unique immediate getting in. Then you’ll be able to see the improved immediate.
15.36: My favourite instance of this [is] I requested it to make a statue of a person pondering, and it got here again and stated one thing like “An in depth statue of a human determine in a pondering pose just like Rodin’s ‘The Thinker.’ The statue is fabricated from weathered stone sitting on a pedestal. . .” Blah blah blah blah blah blah. A paragraph. . . However under that immediate there have been directions to the chatbot or to the LLM that stated, “Generate this picture and after you generate the picture, don’t reply. Don’t ask comply with up questions. Don’t ask. Don’t make any feedback describing what you’ve carried out. Simply generate the picture.” And on this immediate, then 9 occasions, a few of them in all caps, they are saying, “Please don’t reply.” And the reason being as a result of an enormous chunk of OpenAI’s posttraining is educating these fashions the right way to converse forwards and backwards. They need you to at all times be asking a follow-up query and so they prepare it. And so now they must battle the prompts. They’ve so as to add in all these statements. And that’s one other approach that fails.
16.42: So why I deliver this up—and because of this I want to write down about it—is as an utilized AI developer, you must acknowledge while you’re combating the immediate, perceive sufficient in regards to the posttraining of that mannequin, or make some assumptions about it, as a way to cease doing that and check out one thing completely different, since you’re simply banging your head towards a wall and also you’re going to get inconsistent, unhealthy functions and the identical assertion 20 occasions over.
17.07: By the way in which, the opposite factor that’s fascinating about this entire matter is, individuals really one way or the other have underappreciated or forgotten all the progress we’ve made in data retrieval. There’s an entire. . . I imply, these individuals have their very own conferences, proper? Every thing from reranking to the precise indexing, even with vector search—the knowledge retrieval group nonetheless has rather a lot to supply, and it’s the form of factor that folks underappreciated. And so by merely loading your context window with large quantities of rubbish, you’re really, leaving on the sector a lot progress in data retrieval.
18.04: I do suppose it’s onerous. And that’s one of many dangers: We’re constructing all these things so quick from the bottom up, and there’s an inclination to only throw every little thing into the largest mannequin doable after which hope it types it out.
I actually do suppose there’s two swimming pools of builders. There’s the “throw every little thing within the mannequin” pool, after which there’s the “I’m going to take incremental steps and discover probably the most optimum mannequin.” And I usually discover that latter group, which I referred to as a compound AI group after a paper that was printed out of Berkeley, these are usually individuals who have run knowledge pipelines, as a result of it’s not only a easy forwards and backwards interplay. It’s gigabytes or much more of information you’re processing with the LLM. The prices are excessive. Latency is vital. So designing environment friendly techniques is definitely extremely key, if not a complete requirement. So there’s a whole lot of innovation that comes out of that house due to that form of boundary.
19.08: When you had been to speak to certainly one of these utilized AI groups and also you had been to present them one or two issues that they will do instantly to enhance, or repair context basically, what are a few of the finest practices?
19.29: Effectively you’re going to chuckle, Ben, as a result of the reply relies on the context, and I imply the context within the workforce and what have you ever.
19.38: However for those who had been to only go give a keynote to a basic viewers, for those who had been to record down one, two, or three issues which are the bottom hanging fruit, so to talk. . .
19.50: The very first thing I’m gonna do is I’m going to look within the room and I’m going to have a look at the titles of all of the individuals in there, and I’m going to see if they’ve any subject-matter specialists or if it’s only a bunch of engineers making an attempt to construct one thing for subject-matter specialists. And my first bit of recommendation is you must get your self a subject-matter knowledgeable who’s trying on the knowledge, serving to you with the eval knowledge, and telling you what “good” seems like.
I see a whole lot of groups that don’t have this, and so they find yourself constructing pretty brittle immediate techniques. After which they will’t iterate properly, and in order that enterprise AI venture fails. I additionally see them not desirous to open themselves as much as subject-matter specialists, as a result of they wish to maintain on to the ability themselves. It’s not how they’re used to constructing.
20.38: I actually do suppose constructing in utilized AI has modified the ability dynamic between builders and subject-matter specialists. You already know, we had been speaking earlier about a few of just like the previous Net 2.0 days and I’m certain you bear in mind. . . Keep in mind again firstly of the iOS app craze, we’d be at a cocktail party and somebody would discover out that you just’re able to constructing an app, and you’d get cornered by some man who’s like “I’ve received a fantastic thought for an app,” and he would simply discuss at you—normally a he.
21.17: Sure, approach again when. And that is somebody who loves Goal-C. So that you’d get cornered and also you’d attempt to discover a approach out of that awkward dialog. These days, that dynamic has shifted. The topic-matter experience is so vital for codifying and designing the spec, which normally will get specced out by the evals that it leads itself to extra. And you’ll even see this. OpenAI is arguably creating and on the forefront of these things. And what are they doing? They’re standing up applications to get attorneys to come back in, to get docs to come back in, to get these specialists to come back in and assist them create benchmarks as a result of they will’t do it themselves. And in order that’s the very first thing. Started working with the subject-matter knowledgeable.
22.04: The second factor is that if they’re simply beginning out—and that is going to sound backwards, given our matter right this moment—I might encourage them to make use of a system like DSPy or GEPA, that are basically frameworks for constructing with AI. And one of many parts of that framework is that they optimize the immediate for you with the assistance of an LLM and your eval knowledge.
23.02: Yeah, these issues are actually vital. And the rationale I say they’re vital is. . .
23.08: I imply, Drew, these are form of superior subjects.
23.12: I don’t suppose they’re that superior. I believe they will seem actually intimidating as a result of everyone is available in and says, “Effectively, it’s really easy. I might simply write what I would like.” And that is the reward and curse of prompts, in my view. There’s a whole lot of issues to love about.
23.33: DSPy is ok, however I believe TextGrad, GEPA, and Regolo. . .
23.41: Effectively. . . I wouldn’t encourage you to make use of GEPA instantly. I might encourage you to make use of it via the framework of DSPy.
23.48: The purpose right here is that if it’s a workforce constructing, you’ll be able to go down basically two paths. You possibly can handwrite your immediate, and I believe this creates some points. One is as you construct, you are inclined to have a whole lot of hotfix statements like, “Oh, there’s a bug over right here. We’ll say it over right here. Oh, that didn’t repair it. So let’s say it once more.” It would encourage you to have one one who actually understands this immediate. And so you find yourself being reliant on this immediate magician. Despite the fact that they’re written in English, there’s form of no syntax highlighting. They get messier and messier as you construct the applying as a result of they begin to develop and change into these rising collections of edge circumstances.
24.27: And the opposite factor too, and that is actually vital, is while you construct and also you spend a lot time honing a immediate, you’re doing it towards one mannequin, after which in some unspecified time in the future there’s going to be a greater, cheaper, simpler mannequin. And also you’re going to must undergo the method of tweaking it and fixing all of the bugs once more, as a result of this mannequin capabilities otherwise.
And I used to must attempt to persuade folks that this was an issue, however all of them form of came upon when OpenAI deprecated all of their fashions and tried to maneuver everybody over to GPT-5. And now I hear about it on a regular basis.
25.03: Though I believe proper now “brokers” is our sizzling matter, proper? So we discuss to individuals about brokers and also you begin actually moving into the weeds, you understand, “Oh, okay. So their brokers are actually simply prompts.”
25.19: So agent optimization in some ways means injecting a bit extra software program engineering rigor in the way you keep and model. . .
25.30: As a result of that context is rising. As that loop goes, you’re deciding what will get added to it. And so it’s important to put guardrails in—methods to rescue from failure and determine all these items. It’s very troublesome. And it’s important to go at it systematically.
25.46: After which the issue is that, in lots of conditions, the fashions are usually not even fashions that you just management, really. You’re utilizing them via an API like OpenAI or Claude so that you don’t even have entry to the weights. So even for those who’re one of many tremendous, tremendous superior groups that may do gradient descent and backprop, you’ll be able to’t try this. Proper? So then, what are your choices for being extra rigorous in doing optimization?
Effectively, it’s exactly these instruments that Drew alluded to, which is the TextGrads of the world, the GEPA. You have got these compound techniques which are nondifferentiable. So then how do you really do optimization in a world the place you’ve gotten issues that aren’t differentiable? Proper. So these are exactly the instruments that may mean you can flip it from considerably of a, I assume, black artwork to one thing with a bit of extra self-discipline.
26.53: And I believe a very good instance is, even for those who aren’t going to make use of immediate optimization-type instruments. . . The immediate optimization is a superb answer for what you simply described, which is when you’ll be able to’t management the weights of the fashions you’re utilizing. However the different factor too, is, even for those who aren’t going to undertake that, you must get evals as a result of that’s going to be the 1st step for something, which is you must begin working with subject-matter specialists to create evals.
27.22: As a result of what I see. . . And there was only a actually dumb argument on-line of “Are evals value it or not?” And it was actually foolish to me as a result of it was positioned as an either-or argument. And there have been individuals arguing towards evals, which is simply insane to me. And the rationale they had been arguing towards evals is that they’re mainly arguing in favor of what they referred to as, to your level about darkish arts, vibe transport—which is that they’d make modifications, push these modifications, after which the one who was additionally making the modifications would go in and kind in 12 various things and say, “Yep, feels proper to me.” And that’s insane to me.
27.57: And even for those who’re doing that—which I believe is an efficient factor and you could not go create protection and eval, you’ve gotten some style. . . And I do suppose while you’re constructing extra qualitative instruments. . . So a very good instance is like for those who’re Character.AI otherwise you’re Portola Labs, who’s constructing basically customized emotional chatbots, it’s going to be more durable to create evals and it’s going to require style as you construct them. However having evals goes to make sure that your entire factor didn’t disintegrate since you modified one sentence, which sadly is a danger as a result of these are probabilistic software program.
28.33: Truthfully, evals are tremendous vital. Primary, as a result of, mainly, leaderboards like LMArena are nice for narrowing your choices. However on the finish of the day, you continue to must benchmark all of those towards your personal utility use case and area. After which secondly, clearly, it’s an ongoing factor. So it ties in with reliability. The extra dependable your utility is, meaning almost certainly you’re doing evals correctly in an ongoing trend. And I actually consider that eval and reliability are a moat, as a result of mainly what else is your moat? Immediate? That’s not a moat.
29.21: So first off, violent settlement there. The one asset groups really have—except they’re a mannequin builder, which is just a handful—is their eval knowledge. And I might say the counterpart to that’s their spec, no matter defines their program, however principally the eval knowledge. However to the opposite level about it, like why are individuals vibe transport? I believe you will get fairly far with vibe transport and it fools you into pondering that that’s proper.
We noticed this sample within the Net 2.0 and social period, which was, you’d have the product genius—everyone needed to be the Steve Jobs, who didn’t maintain focus teams, didn’t ask their clients what they needed. The Henry Ford quote about “All of them say quicker horses,” and I’m the genius who is available in and tweaks these items and ships them. And that usually takes you very far.
30.13: I additionally suppose it’s a bias of success. We solely know in regards to the ones that succeed, however one of the best ones, after they develop up and so they begin to serve an viewers that’s approach greater than what they may maintain of their head, they begin to develop up with AB testing and ABX testing all through their group. And a very good instance of that’s Fb.
Fb stopped being just a few decisions and began having to do testing and ABX testing in each facet of their enterprise. Examine that to Snap, which once more, was form of the final of the nice product geniuses to come back out. Evan [Spiegel] was heralded as “He’s the product genius,” however I believe they ran that too lengthy, and so they saved transport on vibes reasonably than transport on ABX testing and rising and, you already know, being extra boring.
31.04: However once more, that’s the way you get the worldwide attain. I believe there’s lots of people who most likely are actually nice vibe shippers. And so they’re most likely having nice success doing that. The query is, as their firm grows and begins to hit more durable occasions or the expansion begins to gradual, can that vibe transport take them over the hump? And I might argue, no, I believe it’s important to develop up and begin to have extra accountable metrics that, you already know, scale to the dimensions of your viewers.
31.34: So in closing. . . We talked about immediate engineering. After which we talked about context engineering. So placing you on the spot. What’s a buzzword on the market that both irks you otherwise you suppose is undertalked about at this level? So what’s a buzzword on the market, Drew?
31.57: [laughs] I imply, I want you had given me a while to consider it.
32.02: We’re at all times in a hype cycle. I don’t like anthropomorphosizing LLMs or AI for an entire host of causes. One, I believe it results in unhealthy understanding and unhealthy psychological fashions, that signifies that we don’t have substantive conversations about these items, and we don’t discover ways to construct rather well with them as a result of we expect they’re clever. We expect they’re a PhD in your pocket. We expect they’re all of these items and so they’re not—they’re basically completely different.
I’m not towards utilizing the way in which we expect the mind works for inspiration. That’s effective with me. However while you begin oversimplifying these and never taking the time to elucidate to your viewers how they really work—you simply say it’s a PhD in your pocket, and right here’s the benchmark to show it—you’re deceptive and setting unrealistic expectations. And sadly, the market rewards them for that. So that they maintain going.
However I additionally suppose it simply doesn’t show you how to construct sustainable applications since you aren’t really understanding the way it works. You’re simply form of lowering it all the way down to it. AGI is a kind of issues. And superintelligence, however AGI particularly.
33.21: I went to highschool at UC Santa Cruz, and certainly one of my favourite lessons I ever took was a seminar with Donna Haraway. Donna Haraway wrote “A Cyborg Manifesto” within the ’80s. She’s form of a tech science historical past feminist lens. You’ll simply sit in that class and your thoughts would explode, after which on the finish, you simply have to sit down there for like 5 minutes afterwards, simply selecting up the items.
She had a fantastic time period referred to as “energy objects.” An influence object is one thing that we as a society acknowledge to be extremely vital, consider to be extremely vital, however we don’t know the way it works. That lack of knowledge permits us to fill this bucket with no matter we wish it to be: our hopes, our fears, our desires. This occurred with DNA; this occurred with PET scans and mind scans. This occurs all all through science historical past, all the way down to phrenology and blood sorts and issues that we perceive to be, or we believed to be, vital, however they’re not. And massive knowledge, one other one which may be very, very related.
34.55: Yeah, there you go. So prefer it’s, you already know, I fill it with Ben Lorica. That’s how I fill that energy object. However AI is unquestionably that. AI is unquestionably that. And my favourite instance of that is when the DeepSeek second occurred, we understood this to be actually vital, however we didn’t perceive why it really works and the way properly it labored.
And so what occurred is, for those who appeared on the information and also you checked out individuals’s reactions to what DeepSeek meant, you can mainly discover all of the hopes and desires about no matter was vital to that individual. So to AI boosters, DeepSeek proved that LLM progress will not be slowing down. To AI skeptics, DeepSeek proved that AI firms don’t have any moat. To open supply advocates, it proved open is superior. To AI doomers, it proved that we aren’t being cautious sufficient. Safety researchers apprehensive in regards to the danger of backdoors within the fashions as a result of it was in China. Privateness advocates apprehensive about DeepSeek’s net providers accumulating delicate knowledge. China hawks stated, “We want extra sanctions.” Doves stated, “Sanctions don’t work.” NVIDIA bears stated, “We’re not going to want any extra knowledge facilities if it’s going to be this environment friendly.” And bulls stated, “No, we’re going to want tons of them as a result of it’s going to make use of every little thing.”
35.44: And AGI is one other time period like that, which suggests every little thing and nothing. And when the purpose we’ve reached it comes, isn’t. And compounding that’s that it’s within the contract between OpenAI and Microsoft—I overlook the precise time period, but it surely’s the assertion that Microsoft will get entry to OpenAI’s applied sciences till AGI is achieved.
And so it’s a really loaded definition proper now that’s being debated forwards and backwards and making an attempt to determine the right way to take [Open]AI into being a for-profit company. And Microsoft has a whole lot of leverage as a result of how do you outline AGI? Are we going to go to courtroom to outline what AGI is? I virtually stay up for that.
36.28: So as a result of it’s going to be that factor, and also you’ve seen Sam Altman come out and a few days he talks about how LLMs are simply software program. Some days he talks about the way it’s a PhD in your pocket, some days he talks about how we’ve already handed AGI, it’s already over.
I believe Nathan Lambert has some nice writing about how AGI is a mistake. We shouldn’t speak about making an attempt to show LLMs into people. We must always attempt to leverage what they do now, which is one thing basically completely different, and we should always maintain constructing and leaning into that reasonably than making an attempt to make them like us. So AGI is my phrase for you.
37.03: The best way I consider it’s, AGI is nice for fundraising, let’s put it that approach.
37.08: That’s mainly it. Effectively, till you want it to have already been achieved, or till you want it to not be achieved since you don’t need any regulation or for those who need regulation—it’s form of a fuzzy phrase. And that has some actually good properties.
37.23: So I’ll shut by throwing in my very own time period. So immediate engineering, context engineering. . . I’ll shut by saying take note of this boring time period, which my good friend Ion Stoica is now speaking extra about “techniques engineering.” When you have a look at significantly the agentic functions, you’re speaking about techniques.
37.55: Can I add one factor to this? Violent settlement. I believe that’s an underrated. . .
38.00: Though I believe it’s too boring a time period, Drew, to take off.
38.03: That’s effective! The explanation I like it’s as a result of—and also you had been speaking about this while you speak about fine-tuning—is, trying on the approach individuals construct and looking out on the approach I see groups with success construct, there’s pretraining, the place you’re mainly coaching on unstructured knowledge and also you’re simply constructing your base data, your base English capabilities and all that. After which you’ve gotten posttraining. And basically, posttraining is the place you construct. I do consider it as a type of interface design, regardless that you might be including new expertise, however you’re educating reasoning, you’re educating it validated capabilities like code and math. You’re educating it the right way to chat with you. That is the place it learns to converse. You’re educating it the right way to use instruments and particular units of instruments. And you then’re educating it alignment, what’s secure, what’s not secure, all these different issues.
However then after it ships, you’ll be able to nonetheless RL that mannequin, you’ll be able to nonetheless fine-tune that mannequin, and you may nonetheless immediate engineer that mannequin, and you may nonetheless context engineer that mannequin. And again to the techniques engineering factor is, I believe we’re going to see that posttraining during to a remaining utilized AI product. That’s going to be an actual shades-of-gray gradient. It’s going to be. And this is without doubt one of the the explanation why I believe open fashions have a reasonably large benefit sooner or later is that you just’re going to dip down the way in which all through that, leverage that. . .
39.32: The one factor that’s conserving us from doing that now’s we don’t have the instruments and the working system to align all through that posttraining to transport. As soon as we do, that working system goes to vary how we construct, as a result of the space between posttraining and constructing goes to look actually, actually, actually blurry. I actually just like the techniques engineering sort of method, however I additionally suppose you can too begin to see this yesterday [when] Pondering Machines launched their first product.
40.04: And so Pondering Machines is Mira [Murati]. Her very hype factor. They launched their very first thing, and it’s referred to as Tinker. And it’s basically, “Hey, you’ll be able to write a quite simple Python code, after which we’ll do the RL for you or the fine-tuning for you utilizing our cluster of GPU so that you don’t must handle that.” And that’s the sort of factor that we wish to see in a maturing form of improvement framework. And also you begin to see this working system rising.
And it jogs my memory of the early days of O’Reilly, the place it’s like I needed to arise an internet server, I needed to keep an internet server, I needed to do all of these items, and now I don’t must. I can spin up a Docker picture, I can ship to render, I can ship to Vercel. All of those shared difficult issues now have frameworks and tooling, and I believe we’re going to see an analogous evolution from that. And I’m actually excited. And I believe you’ve gotten picked a fantastic underrated time period.
Menace actors exploited a not too long ago patched distant code execution vulnerability (CVE-2025-20352) in older, unprotected Cisco networking units to deploy a Linux rootkit and acquire persistent entry.
The safety problem leveraged within the assaults impacts the Easy Community Administration Protocol (SNMP) in Cisco IOS and IOS XE and results in RCE if the attacker has root privileges.
In accordance with cybersecurity firm Pattern Micro, the assaults focused Cisco 9400, 9300, and legacy 3750G collection units that didn’t have endpoint detection response options.
Within the unique bulletin for CVE-2025-20352, up to date on October 6, Cisco tagged the vulnerability as exploited as a zero day, with the corporate’s Product Safety Incident Response Crew (PSIRT) saying it was “conscious of profitable exploitation.”
Pattern Micro researchers observe the assaults below the identify ‘Operation Zero Disco’ as a result of the malware units a common entry password that incorporates the phrase “disco.”
The report from Pattern Micro notes that the risk actor additionally tried to use CVE-2017-3881, a seven-year-old vulnerability within the Cluster Administration Protocol code in IOS and IOS XE.
The rootkit planted on weak techniques includes a UDP controller that may hear on any port, toggle or delete logs, bypass AAA and VTY ACLs, allow/disable the common password, disguise working configuration objects, and reset the final write timestamp for them.
UDP controller features Supply: Pattern Micro
In a simulated assault, the researchers confirmed that it’s doable to disable logging, impersonate a waystation IP by way of ARP spoofing, bypass inner firewall guidelines, and transfer laterally between VLANs.
Overview of the simulated assault Supply: Pattern Micro
Though newer switches are extra resistant to those assaults resulting from Handle House Structure Randomization (ASLR) safety, Pattern Micro says that they aren’t immune and chronic concentrating on might compromise them.
After deploying the rootkit, the malware “installs a number of hooks onto the IOSd, which leads to fileless elements disappearing after a reboot,” the researchers say.
The researchers had been capable of get well each 32-bit and 64-bit variants of the SNMP exploit.
Pattern Micro notes that there at present exists no software that may reliably flag a compromised Cisco swap from these assaults. If there may be suspicion of a hack, the advice is to carry out a low-level firmware and ROM area investigation.
Be a part of the Breach and Assault Simulation Summit and expertise the way forward for safety validation. Hear from prime consultants and see how AI-powered BAS is remodeling breach and assault simulation.
Do not miss the occasion that can form the way forward for your safety technique
Over the previous twenty years, scientists have sequenced nearly every part they’ll entry—bacterial genomes from soil, viral samples from hospitals, intestine microbiomes from folks around the globe, even the RNA inside single human cells. All of that sequencing output will get funneled into large archives which have quietly change into a few of the largest information collections on the planet.
By way of quantity, these repositories now comprise extra uncooked genetic information than Google has webpages. It ought to be a goldmine for scientific discovery, and perhaps it’s. Nevertheless, most of it’s virtually unreachable as a result of the information is fragmented and almost unimaginable to look in its uncooked kind.
That’s why a brand new device referred to as MetaGraph, not too long ago revealed in Nature, is getting numerous consideration. As a substitute of treating genomic information like one thing that must be cleaned and arranged first, it takes the other strategy by embracing the chaos.
MetaGraph was developed by a crew of computational biologists and informatics researchers led by Gunnar Rätsch and André Kahles, together with a number of collaborators who specialise in large-scale sequence indexing and graph algorithms.
Their purpose was to not construct one other reference genome or annotation database, however to make uncooked sequencing information itself searchable at petabase scale. In sensible phrases, they wished a system that works instantly on the unassembled reads saved in international archives and nonetheless returns correct organic solutions—with out reshaping the information to suit present instruments.
(Credit:Nature.com)
“It’s an enormous achievement,” says Rayan Chikhi, a biocomputing researcher on the Pasteur Institute in Paris. “They set a brand new customary” for analyzing uncooked organic information — together with DNA, RNA and protein sequences — from databases that may comprise tens of millions of billions of DNA letters, amounting to ‘petabases’ of knowledge, extra entries than all of the webpages in Google’s huge index.
MetaGraph is described as “Google for DNA”, however Chikhi argues it’s really nearer to YouTube’s search engine, the place it doesn’t simply match key phrases, it analyzes the content material itself. It searches instantly by uncooked DNA and RNA reads and may detect patterns or variants that have been by no means annotated and even identified to exist, making it potential to uncover indicators conventional instruments would utterly miss.
To do that, MetaGraph arranges uncooked sequencing reads right into a graph that represents how small fragments of DNA or RNA overlap throughout many datasets. It doesn’t attempt to assemble full genomes. As a substitute, it captures the relationships between tens of millions of brief items, which permits the system to trace the place a specific sequence seems—even when it’s solely a tiny fragment shared between distant species or environments.
The graph itself is saved in a compressed format, however stays instantly searchable. When a researcher runs a question, MetaGraph doesn’t reprocess whole datasets. It navigates by the graph construction to find areas the place comparable patterns have already been noticed. This strategy makes it potential to look very giant collections of uncooked information in an inexpensive period of time, whereas nonetheless working on the stage of the unique reads somewhat than counting on annotations or pre-built references.
The researchers put MetaGraph to a real-world check with antibiotic resistance. They took 241,384 human intestine microbiome samples collected from completely different components of the world and requested a easy query: the place in these samples are resistance genes hiding? Usually, answering that might imply assembling every dataset, constructing references, and operating separate pipelines throughout hundreds of recordsdata.
That form of handbook work might take weeks or months. MetaGraph did it in about an hour on a high-performance machine. Because the device is constructed to look the uncooked reads instantly, it was capable of spot resistance genes even after they appeared solely as tiny fragments or in species with no reference genome in any respect. The system additionally uncovered geographic patterns that lined up with identified variations in antibiotic use.
(PopTika/Shutterstock)
MetaGraph isn’t the one try to make large sequencing archives searchable. Chikhi himself, along with Artem Babaian, has developed a separate platform referred to as Logan that tackles the issue from a unique angle. As a substitute of indexing uncooked reads, Logan stitches them into longer stretches of DNA, which permits it to rapidly establish full genes and their variants throughout large datasets.
That strategy led to the invention of greater than 200 million pure variations of a plastic-degrading enzyme. Nevertheless, assembly-based instruments like Logan are optimized for particular targets, they usually can miss indicators that don’t kind clear, full sequences. MetaGraph is constructed to look uncooked information instantly, providing higher scope and probably extra flexibility to researchers.
If instruments like MetaGraph change into broadly obtainable, researchers anyplace might mine international datasets with out large infrastructure or customized pipelines. That would speed up drug discovery, environmental monitoring and personalised medication.
Maybe an important shift is that future scientific breakthroughs might not require new experiments in any respect. They may come from information that has been sitting in archives for years, information we already collected however are solely now capable of actually search and perceive.
.NET Aspire’s present Redis shopper will work with Valkey; all you must do is be sure that you’re utilizing the proper connectionName. Microsoft offers Aspire implementation particulars for 3 totally different Valkey situations: normal cache, distributed cache, and output cache. The documentation isn’t fairly full, because it typically refers to Redis moderately than Valkey, however Aspire treats the 2 interchangeably so it’s not too obscure what to do and when.
One other benefit to utilizing Valkey with Aspire: You may benefit from Aspire’s observability instruments, well being checks, logging, and its built-in developer dashboard to observe operations—together with your cache. Having instruments that handle software well being is essential, particularly when constructing the distributed, cloud-native purposes that depend on providers like Valkey.
As Valkey continues to diverge from Redis, it’s value maintaining a tally of each tasks, as every will tackle totally different use instances and help totally different software architectures. For now, nonetheless, due to RESP, they can be utilized comparatively interchangeably, permitting you to decide on one or the opposite and swap to whichever works greatest for you and your challenge. With fundamental help in each AKS and .NET Aspire, and a significant new launch of Valkey across the nook, it’s an appropriate time to provide it a attempt.
Twilio in the present day introduced new options to assist corporations create and keep buyer experiences which might be based mostly on trusted knowledge.
In response to Twilio, getting access to correct and dependable knowledge is essential for buyer engagement, however knowledge groups usually face delay and missed alternatives on account of an incapability to hint, diagnose and resolve knowledge points. Moreover, these groups usually need to work throughout a number of altering mechanisms, which may result in essential alerts getting missed, additionally leading to downtime or different reputational harm.
New observability and alerting capabilities are designed to assist tackle these challenges and eradicate the time-consuming work of monitoring down points in knowledge.
The brand new Granular Observability functionality supplies entry particulars for every occasion ID to make it simpler to hint, diagnose, and resolve points, whereas the brand new Altering Hub supplies a centralized location for configuring, viewing, and managing alerts.
The corporate additionally up to date its APIs to make them extra customizable and supply higher entry and suppleness for knowledge groups.
The Viewers and Vacation spot Configuration API permits groups to programmatically create, preview, and handle audiences, and the Profile API permits groups to leverage Twilio Section’s Knowledge Graph and unified profiles to question entities, replace identifiers, and masks PII.
New auto-instrumentation capabilities may even allow groups to create and modify occasion triggers on net and cell with out growth experience.
“With in the present day’s updates, we’re giving companies a wise and intuitive management tower for each sign throughout the shopper journey,” mentioned Inbal Shani, chief product officer and head of R&D at Twilio. “By bringing collectively full observability, proactive alerting, seamless instrumentation, and API-first workflows, we’re unlocking platform-wide capabilities designed to assist our prospects construct engagement that isn’t solely trusted, however really transformative.”
Say an individual takes their French Bulldog, Bowser, to the canine park. Figuring out Bowser as he performs among the many different canines is straightforward for the dog-owner to do whereas onsite.
But when somebody desires to make use of a generative AI mannequin like GPT-5 to watch their pet whereas they’re at work, the mannequin may fail at this fundamental job. Imaginative and prescient-language fashions like GPT-5 typically excel at recognizing common objects, like a canine, however they carry out poorly at finding customized objects, like Bowser the French Bulldog.
To deal with this shortcoming, researchers from MIT and the MIT-IBM Watson AI Lab have launched a brand new coaching methodology that teaches vision-language fashions to localize customized objects in a scene.
Their methodology makes use of rigorously ready video-tracking information during which the identical object is tracked throughout a number of frames. They designed the dataset so the mannequin should deal with contextual clues to determine the customized object, slightly than counting on information it beforehand memorized.
When given a number of instance photographs exhibiting a customized object, like somebody’s pet, the retrained mannequin is best capable of determine the placement of that very same pet in a brand new picture.
Fashions retrained with their methodology outperformed state-of-the-art programs at this job. Importantly, their method leaves the remainder of the mannequin’s common talents intact.
This new strategy may assist future AI programs monitor particular objects throughout time, like a baby’s backpack, or localize objects of curiosity, corresponding to a species of animal in ecological monitoring. It may additionally help within the improvement of AI-driven assistive applied sciences that assist visually impaired customers discover sure objects in a room.
“Finally, we would like these fashions to have the ability to study from context, identical to people do. If a mannequin can do that effectively, slightly than retraining it for every new job, we may simply present a number of examples and it could infer how one can carry out the duty from that context. This can be a very highly effective capability,” says Jehanzeb Mirza, an MIT postdoc and senior writer of a paper on this method.
Mirza is joined on the paper by co-lead authors Sivan Doveh, a graduate scholar at Weizmann Institute of Science; and Nimrod Shabtay, a researcher at IBM Analysis; James Glass, a senior analysis scientist and the pinnacle of the Spoken Language Techniques Group within the MIT Pc Science and Synthetic Intelligence Laboratory (CSAIL); and others. The work will likely be offered on the Worldwide Convention on Pc Imaginative and prescient.
An surprising shortcoming
Researchers have discovered that enormous language fashions (LLMs) can excel at studying from context. In the event that they feed an LLM a number of examples of a job, like addition issues, it could study to reply new addition issues based mostly on the context that has been offered.
A vision-language mannequin (VLM) is actually an LLM with a visible element related to it, so the MIT researchers thought it could inherit the LLM’s in-context studying capabilities. However this isn’t the case.
“The analysis neighborhood has not been capable of finding a black-and-white reply to this explicit drawback but. The bottleneck may come up from the truth that some visible info is misplaced within the technique of merging the 2 elements collectively, however we simply don’t know,” Mirza says.
The researchers got down to enhance VLMs talents to do in-context localization, which includes discovering a particular object in a brand new picture. They targeted on the information used to retrain present VLMs for a brand new job, a course of known as fine-tuning.
Typical fine-tuning information are gathered from random sources and depict collections of on a regular basis objects. One picture may include vehicles parked on a avenue, whereas one other features a bouquet of flowers.
“There isn’t any actual coherence in these information, so the mannequin by no means learns to acknowledge the identical object in a number of photographs,” he says.
To repair this drawback, the researchers developed a brand new dataset by curating samples from present video-tracking information. These information are video clips exhibiting the identical object shifting via a scene, like a tiger strolling throughout a grassland.
They reduce frames from these movies and structured the dataset so every enter would include a number of photographs exhibiting the identical object in several contexts, with instance questions and solutions about its location.
“Through the use of a number of photographs of the identical object in several contexts, we encourage the mannequin to persistently localize that object of curiosity by specializing in the context,” Mirza explains.
Forcing the main target
However the researchers discovered that VLMs are inclined to cheat. As a substitute of answering based mostly on context clues, they’ll determine the article utilizing information gained throughout pretraining.
For example, for the reason that mannequin already realized that a picture of a tiger and the label “tiger” are correlated, it may determine the tiger crossing the grassland based mostly on this pretrained information, as an alternative of inferring from context.
To unravel this drawback, the researchers used pseudo-names slightly than precise object class names within the dataset. On this case, they modified the identify of the tiger to “Charlie.”
“It took us some time to determine how one can forestall the mannequin from dishonest. However we modified the sport for the mannequin. The mannequin doesn’t know that ‘Charlie’ is usually a tiger, so it’s pressured to have a look at the context,” he says.
The researchers additionally confronted challenges to find one of the simplest ways to organize the information. If the frames are too shut collectively, the background wouldn’t change sufficient to supply information variety.
In the long run, finetuning VLMs with this new dataset improved accuracy at customized localization by about 12 % on common. Once they included the dataset with pseudo-names, the efficiency beneficial properties reached 21 %.
As mannequin measurement will increase, their method results in higher efficiency beneficial properties.
Sooner or later, the researchers wish to research attainable causes VLMs don’t inherit in-context studying capabilities from their base LLMs. As well as, they plan to discover extra mechanisms to enhance the efficiency of a VLM with out the necessity to retrain it with new information.
“This work reframes few-shot customized object localization — adapting on the fly to the identical object throughout new scenes — as an instruction-tuning drawback and makes use of video-tracking sequences to show VLMs to localize based mostly on visible context slightly than class priors. It additionally introduces the primary benchmark for this setting with stable beneficial properties throughout open and proprietary VLMs. Given the immense significance of fast, instance-specific grounding — typically with out finetuning — for customers of real-world workflows (corresponding to robotics, augmented actuality assistants, inventive instruments, and so on.), the sensible, data-centric recipe provided by this work may also help improve the widespread adoption of vision-language basis fashions,” says Saurav Jha, a postdoc on the Mila-Quebec Synthetic Intelligence Institute, who was not concerned with this work.
Further co-authors are Wei Lin, a analysis affiliate at Johannes Kepler College; Eli Schwartz, a analysis scientist at IBM Analysis; Hilde Kuehne, professor of laptop science at Tuebingen AI Middle and an affiliated professor on the MIT-IBM Watson AI Lab; Raja Giryes, an affiliate professor at Tel Aviv College; Rogerio Feris, a principal scientist and supervisor on the MIT-IBM Watson AI Lab; Leonid Karlinsky, a principal analysis scientist at IBM Analysis; Assaf Arbelle, a senior analysis scientist at IBM Analysis; and Shimon Ullman, the Samy and Ruth Cohn Professor of Pc Science on the Weizmann Institute of Science.
This analysis was funded, partially, by the MIT-IBM Watson AI Lab.
The nation’s first business UAS park is constructing a $100M counter-drone testing heart as drone threats escalate. That’s GrandSKY, the nation’s first business unmanned plane enterprise park.
GrandSKY introduced this week that it has deployed a foundational counter-drone structure at Grand Forks Air Drive Base in North Dakota. To construct it, it’s partnering with protection big AeroVironment. Officers have mentioned they hope their mannequin may turn out to be a nationwide heart of excellence for counter-UAS operations.
The deployment, which incorporates AeroVironment’s AV_Halo COMMAND software program and Titan-SV radio frequency-based counter-UAS system, represents the primary part of a complete, layered protection system targeted on detecting, figuring out and monitoring unmanned aerial threats. The initiative is a part of what’s known as Mission ULTRA. Mission ULTRA is a $100 million public-private effort to place Grand Forks because the nation’s proving floor for superior counter-drone protection.
“We’re constructing the way forward for air protection proper right here in North Dakota,” mentioned GrandSKY President Thomas Swoyer Jr in a ready assertion. “This deployment displays the strategic evolution of GrandSKY because it endeavors to create a nationwide counter-UAS heart of excellence.”
The announcement comes as navy and safety officers worldwide grapple with the quickly evolving menace of small drones. From business quadcopters weaponized in Ukraine to swarms threatening navy installations, the proliferation of drones has created what protection consultants describe as one of the urgent tactical challenges of recent warfare.
The AeroVironment issue
AeroVironment has emerged as a significant participant in either side of the drone equation. It’s the U.S. navy’s prime provider of small drones, and it’s additionally more and more as a supplier of programs to counter them. The Virginia-based protection contractor, which trades on NASDAQ below the ticker AVAV, has seen its inventory surge over 160% previously six months, pushed by hovering demand for its unmanned programs and an enormous NATO protection spending dedication introduced earlier this yr.
AeroVironment has reworked from what analysts as soon as described as a distinct segment drone maker into an built-in protection expertise powerhouse. By way of strategic acquisitions, together with the $405 million buy of Arcturus UAV in 2021 and the newer BlueHalo acquisition, AeroVironment has expanded past primary reconnaissance drones into loitering munitions, counter-UAS programs, directed vitality weapons and cyber capabilities.
Its Switchblade loitering munitions — primarily kamikaze drones — have gained specific prominence. The programs are available two configurations: the Switchblade 300 for attacking personnel and the bigger Switchblade 600 for taking out armored autos. In 2023, Israel requested 200 Switchblade 600 items from the U.S. Division of Protection.
But it surely’s the counter-drone facet of AeroVironment’s enterprise that’s more and more attracting consideration. With drones proliferating globally and turning into cheaper and extra succesful, the marketplace for programs to detect and defeat them has exploded. NATO’s pledge to extend protection spending to five% of GDP by 2035 (that’s up from the earlier 2% goal) has created what one analyst known as a “$2.7 trillion enhance” for protection contractors, with drone and counter-drone programs positioned as main beneficiaries.
The counter-drone problem
The deployment at GrandSKY addresses a important vulnerability in fashionable air protection. Conventional radar and air protection programs have been designed to detect massive, fast-moving plane, not small drones that may value as little as just a few hundred {dollars} however require million-dollar missiles to shoot down.
The answer as applied at Grand Forks entails layered defenses combining a number of detection strategies equivalent to radio frequency sensors, radar and optical programs. AeroVironment can be leaning into AI-powered software program to handle threats.
For North Dakota, the GrandSKY initiative represents a strategic play to place the state on the forefront of drone expertise, one thing it has lengthy sought to do. The 217-acre facility already provides industry-leading facilities together with over 11,000 sq. miles of beyond-visual-line-of-sight functionality and 24/7 operations, leveraging its partnership with Grand Forks Air Drive Base.
Senator John Hoeven, who introduced the deployment, emphasised each the financial and safety dimensions.
“Grand Forks continues to play a significant position in strengthening each North Dakota’s economic system and America’s nationwide safety,” he mentioned. “By leveraging these confirmed applied sciences at GrandSKY, we’re guaranteeing our state stays on the forefront of innovation.”
The deployment builds on a memorandum of understanding signed between GrandSKY and AeroVironment in March 2025, which formalized their cooperation on Mission ULTRA. The initiative envisions Grand Forks turning into a hub the place authorities, navy, and personal sector companions can take a look at, develop and validate counter-drone applied sciences in real-world situations.
AeroVironment CEO Wahid Nawabi known as the Grand Forks deployment “an vital step towards constructing a layered protection system for the nation in opposition to continuously evolving drone threats.”
GrandSky’s tech accelerator grows
Picture courtesy of GrandSky
The information comes on the heels of one other current announcement: GrandSKY, and its affiliate GFHive Administration LLC, have received a five-year contract to handle and function The HIVE, a expertise accelerator and shared workspace devoted to rising the area’s UAS ecosystem.
“Collectively, Grand Forks and GrandSKY have constructed world-class infrastructure that helps an ecosystem that leads the nation in autonomous programs and helps the protection of our nation,” Grand Forks Mayor Brandon Bochenski mentioned. “This partnership with Grand Sky and the city-owned Hive in downtown Grand Forks, will proceed to draw prime firms main innovation in aerospace, UAS, and edge-processing to safe long-term financial advantages for the group and state.”
Associated
Uncover extra from The Drone Lady
Subscribe to get the most recent posts despatched to your e-mail.
RoboBusiness 2025 continues with one other thrilling day on the Santa Clara Conference Heart. The occasion will embody over 60 audio system, a startup workshop, the annual Pitchfire competitors, and over 100 exhibitors.
Day 2 kicks off at 10:00 a.m. PT with our first keynote and the opening of the RoboBusiness present flooring. The ground will likely be open till 3:00 p.m., and it contains the Engineering Theater, a networking lounge, the Startup Showcase, the MassRobotics Startup Alley, and the KAIST Korean Pavilion. In case you’re all in favour of selecting up lunch, you could find the meals courtroom behind the expo corridor.
Our first keynote at the moment will cowl the state of the robotics business and can happen in the principle theater. Sanjay Aggarwal, a enterprise associate at F-Prime; Jon Battles, vice chairman of know-how technique at Cobot; Amit Goel, the director of product administration for autonomous machines at NVIDIA; and Brian Gaunt, the North American vice chairman of digital transformation at DHL Provide Chain, could have a candid dialog with Eugene Demaitre, editorial director of The Robotic Report, concerning the business, grounded in actual expertise and market insights.
This will likely be adopted by one other keynote, “Closing the Robotics Hole With China,” at 11:00 a.m. This panel will embody Jeff Burnstein, the president of the Affiliation for Advancing Automation (A3); Georg Stieler, the pinnacle of robotics and automation at Stieler Expertise & Market Advistory; and Eric Truebenbach, the managing director at Teradyne Robotics. These business leaders will focus on with moderator Demaitre what methods the U.S., Europe, and different areas can use to shut the hole with China.
Day 2 breakout periods
Breakout periods will kick off at 12:00 p.m. Right now’s RoboBusiness breakout discuss schedule is:
5 Keys to Deploying AI-Powered Robots in Manufacturing: SK Gupta, the co-founder and chief scientist at GrayMatter Robotics, will begin this session at 12:00 p.m. in Room 203/204.
A Sensible Information to Constructing Out of doors Robots: Illia Baranov, the co-founder and chief know-how officer of Polymath Robotics, will current at 12:00 p.m. in Room 212.
International Implications of China’s Robotics Push: This session, led by Georg Stieler, the pinnacle of robotics and automation at Stieler Expertise & Market Advisory, can even be at midday in Room 206.
Scaling Robotic Deployments: from 5 to 5M: This dialogue will begin at 12:00 p.m. in Room 207. The panel contains Jordan Bryan, the director of operations at Bear Robotics; Saman Farid, the founder and CEO of Formic; Florian Pestoni, the founder and CEO of InOrbit.AI; Richard Petrazzini, the co-founder and CEO at Robotic Crew; and Joe Wieciek, the director of high quality assurance and technical operations at Agtonomy.
UX For Robotics Builders: Orchestrating AI With Habits Bushes: Dave Coleman, the founder and chief product officer at PickNik Robotics, will communicate at 12:00 p.m. in Room 201.
AI for Dexterity & Adaptation in Excessive-Stakes Environments: Vivian Chu, the co-founder and Chief Innovation Officer at Diligent Robotics, will discuss at 1:30 p.m. in Room 203/204.
Amazon Robotics’ Strategy to DfX and Scaling: Kunal Patil, the senior technical program supervisor at Amazon Robotics, will begin at 1:30 p.m. in Room 201.
Bringing Intelligence to Movement: Combining AI, 3D, and Edge Computing: Freya Ma, a product supervisor at Teledyne, will begin this session at 1:30 p.m. in Room 207.
Case Research: Growing Robots For Difficult Environments: This panel will start at 1:30 p.m. in Room 212. It can function insights from Lou Bojarski, an autonomy workers engineer at Caterpillar; Spencer Krause, the president and CEO at SKA Robotics; Sean Harrington, an engineering supervisor at Caterpillar; and Brianna Wessling, an affiliate editor at The Robotic Report.
State of Robotics Investments: Sanjay Aggarwal, a enterprise associate at F-Prime, and Betsy Mulé, an investor at F-Prime, will converse at 1:30 p.m. in Room 206.
Breaking the $1M–$5M Barrier – What Each Robotics Founder Must Know: This panel at 2:30 p.m. in Room 206 will function Chase Olle, co-founder and CEO of Robotic on Rails;, Parna Sarkar-Basu, founder and CEO of B&B Consulting; Jayiesh Singh, an government officer at Ready Improvements; and Jay Wong, the founding father of Luminous.
Crash Course on Drive/Torque Sensors for Subject Robotics: Robert Brooks, the founder and CEO of ForceN, will start talking at 2:30 p.m. in Room 212.
Dexterous Robots within the Age of Embodied AI: Mihai Jalobeanu, the founder and CEO of Dexman AI, will current at 2:30 p.m. in Room 203/204.
Novel Approaches to Actuation: This panel will begin at 2:30 p.m. in Room 207. It can embody Wes Brown, co-founder and CEO of Pressure Dynamics; Stuart Diller, co-founder and CEO of ESTAT Actuation, and Hiten Sonpal, the CEO of Rise Robotics, with moderator Demaitre.
What’s occurring within the Engineering Theater?
The Engineering Theater schedule for Day 2 is:
Danger-Conscious AI Fashions: The Key to Deploying and Scaling Basic Function Robotics Intelligence: Ali Agha, the founder and CEO of Subject AI, will begin this session at 11:45 a.m.
Robotic MCP: Bridging AI and Present Robots Utilizing Mannequin Context Protocol: Rohit John Varghese, the director of Techniques Engineering and Product at Contoro Robotics, will begin this session at 12:30 p.m.
Pitchfire: The annual startup competitors will begin at 1:45 p.m. Attendees will hear from Katie Bradford, the founder and CEO of Rotate8; Kevin Hays, co-founder and CTO of Morelle; Dominic Lindsay, the founder and CEO at Nexobot; Roby Lynn, the founder and CEO at R2 Labs; Toshi Quides, the chair of the board at Smart Robotics; and Lakshay Sharma, co-founder and CEO at Cerulion.
Attend the Ladies in Robotics Lunch
At 12:45 p.m. in Room 209/210, we’ll be holding the Ladies in Robotics Lunch. Attendees will hear an unique dialog between Tessa Lau, co-founder of Dusty Robotics, and Joyce Sidopoulos, co-founder of MassRobotics. They may focus on Lau’s journey in robotics and her present work constructing robots for the development business.
This occasion requires pre-registration and an extra price. Tickets should still be obtainable on-site.
Day 2 to shut with a joint keynote
RoboBusiness 2025, which is co-located with DeviceTalks West, will wrap up with a remaining keynote at 3:30 p.m. within the Theater. Throughout this session, Iman Jeddi, the senior vice chairman and normal supervisor of da Vinci platforms and product operations at Intuitive Surgical, will focus on the way forward for surgical robotics.
She’s going to supply a uncommon look contained in the redesign and launch of the da Vinci 5, the corporate’s next-generation surgical robotics system. With da Vinci 5, Intuitive has targeted on implementing foundational computing energy to unlock a brand new era of capabilities—from power suggestions and superior devices to machine imaginative and prescient that powers the surgeon’s interface and delivers deeper case insights.
Medal, a platform for importing and sharing online game clips, has spun out a brand new frontier AI analysis lab that’s utilizing its trove of gaming movies to coach and construct basis fashions and AI brokers that may perceive how objects and entities transfer by area and time – an idea generally known as spatial-temporal reasoning.
Referred to as Basic Instinct, the startup is betting that Medal’s dataset – which consists of two billion movies per yr from 10 million month-to-month energetic customers throughout tens of 1000’s of video games – surpasses options like Twitch or YouTube for coaching brokers.
“While you play video video games, you primarily switch your notion, often by a first-person view of the digital camera, to totally different environments,” Pim de Witte, CEO of Medal and Basic Instinct, instructed TechCrunch. He famous that players who add clips are inclined to submit very adverse or optimistic examples, which function actually helpful edge circumstances for coaching. “You get this choice bias in the direction of exactly the type of knowledge you truly need to use for coaching work.”
This knowledge moat is what reportedly attracted the eye of OpenAI, which late final yr tried to amass Medal for $500 million, per The Data. (Neither OpenAI nor Basic Instinct would touch upon the report.)
It’s additionally what has led to Basic Instinct’s elevating a whopping $133.7 million in seed funding, led by Khosla Ventures and Basic Catalyst with participation from Raine.
The startup intends to make use of the funds to develop its staff of researchers and engineers targeted on coaching a common agent that may work together with the world round it, aiming for preliminary purposes in gaming, and search and rescue drones.
De Witte says the founding staff has already made strides: Basic Instinct’s mannequin can perceive environments it wasn’t skilled on and appropriately predict actions inside them. It’s in a position to do that purely by visible enter; brokers solely see what a human participant would see, they usually transfer by area by following controller inputs. This strategy, the corporate says, can switch naturally to bodily methods like robotic arms, drones, and autonomous automobiles, which are sometimes manipulated by people utilizing online game controllers.
Techcrunch occasion
San Francisco | October 27-29, 2025
Basic Instinct’s subsequent milestone is two-fold: producing new simulated worlds for coaching different brokers, and autonomously navigating solely unfamiliar bodily environments.
That technical strategy is shaping how the corporate plans to commercialize its expertise, and units it other than rivals constructing world fashions.
Whereas Basic Instinct can be constructing world fashions on which to coach its brokers, such fashions aren’t the product. In contrast to different world mannequin makers like DeepMind and World Labs, that are promoting their world fashions Genie and Marble for coaching brokers and content material creation, Basic Instinct is specializing in different use circumstances to keep away from copyright points.
“Our purpose is to not produce fashions that compete with recreation builders,” de Witte mentioned.
As an alternative, the startup’s gaming purposes focus on creating bots and non-player characters that may surpass conventional “deterministic bots,” or preprogrammed characters that produce the identical output each time.
“[The bots] can scale to any stage of issue,” Moritz Baier-Lentz, a founding member of Basic Instinct and accomplice at Lightspeed Ventures, instructed TechCrunch. “It’s not compelling to create a god bot that beats everybody, however for those who can scale steadily and fill in liquidity for any participant scenario in order that their win price is all the time round 50%, that can maximize their engagement and retention.”
De Witte additionally has a background in humanitarian work, which informs the startup’s deal with powering search and rescue drones, that generally should navigate unfamiliar environments and extract data with out GPS.
In the end, de Witte and Baier-Lentz see Basic Instinct’s core performance – spatial-temporal reasoning — as an important piece within the race towards synthetic common intelligence (AGI). Whereas main AI labs deal with constructing ever extra highly effective giant language fashions, Basic Instinct believes true AGI requires one thing LLMs basically lack.
“As people, we create textual content to explain what’s happening in our world, however in doing so, you lose lots of data,” de Witte mentioned. “You lose common instinct round spatial-temporal reasoning.”






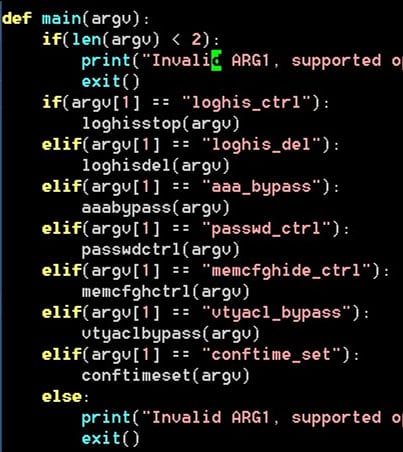
.jpg)


















