Editor’s Word: This text relies on Dorota Shortell’s presentation at RoboBusiness 2025. Keep tuned for extra post-show protection and insights from this 12 months’s occasion.
With the quantity of consideration given to robotics, humanoids, and bodily AI, there are lots of new entrants and startups within the discipline. They usually have nice, even industry-changing concepts, however what is going to it take to show a good suggestion into enterprise success? We all know that almost all of recent companies fail, so what did those that succeeded do to get there? Studying from each corporations who’ve developed profitable robotics companies and in addition from those that have failed or needed to pivot, offers newer robotics corporations insights on what actions they need to take to maximise their possibilities of constructing a sustainable enterprise.
Tapping into each the 20+ years’ of {hardware}, mechatronic merchandise, and automatic robotic methods expertise at Simplexity Product Growth and interviews with leaders at over a dozen robotics corporations, I’ve compiled these key classes discovered that I shared throughout my speak at RoboBusiness final week in Santa Clara, Calif. They will greatest be categorized as falling into 5 primary classes:
- Product market match
- Funding
- Growth course of
- Crew
- Scaling
I’ll dive into every one in additional element, beginning with a quote to set the stage.
1. Product market match
“Perceive a very powerful buyer issues first and construct new know-how second. Constructing a brand new robotic ought to solely come after you’ve conviction that it’s going to clear up an issue value fixing. In any other case, you threat constructing one thing attention-grabbing, however in the end ineffective.”
– Christopher Carlson, government vp, analysis, company Growth, and Intuitive Ventures

Carlson and I went to graduate college collectively at Stanford and over the previous 12+ years he’s had a really profitable profession at surgical robotic maker Intuitive. Intuitive has been a robotics chief for 30 years, so studying what they did within the early years and the way they develop robots now could be one thing that aspiring robotics corporations might attempt to emulate. Christopher actually emphasised how product market match is without doubt one of the key distinguishing elements between success and failure, additionally echoed by fairly a couple of of the opposite robotics leaders who I interviewed. The teachings underneath this class are:
Construct your organization round what individuals will purchase: In the event you solely take away one studying, it’s to be laser targeted on growing an answer for a crucial buyer want versus specializing in constructing a robotic. The businesses who needed to do a tough pivot or didn’t make it out there most frequently cited that they had been too targeted on constructing cool robotic know-how and never spending sufficient time understanding buyer wants. The recommendation right here is to construct your organization round understanding your shopper, not simply on attention-grabbing technological advances. A easy answer that solves a crucial want is significantly better than a complicated answer that’s solely a “good to have” for potential shoppers.
Use a quick suggestions cycle – ideate, validate with buyer suggestions, iterate on the design: When you perceive what the crucial want is that your organization shall be addressing, then it’s time to assemble concepts for clear up it and get as a lot suggestions from clients as you may previous to constructing {hardware}. This shall be restricted as most clients might want to see/strive what you’re providing, however doing preliminary interviews helps slim down the issue and outline a product structure that’s extra doubtless to achieve success.
Dusty Robotics did this by interviewing shoppers for a number of months previous to constructing their robotic. Then it is advisable construct {hardware}, collect extra suggestions from clients, and preserve iterating on the design, in quick cycles. Don’t be in stealth mode. Construct in public because you don’t have a number of pictures on objective. It’s important to know there’s a marketplace for what you’re constructing once you go on the market.
Safe a beachhead shopper and co-develop with them: Corporations who had been profitable at specializing in the shopper stated that co-development and having shut collaboration was crucial. Quite than making an attempt to promote a accomplished robotic right into a shopper web site, they might have their engineers on the shopper websites working alongside the shopper to hone the know-how. This was most frequently completed by having a service enterprise mannequin moderately than a product mannequin.
For instance, Dusty Robotics supplied its robotic as a service first, the place they might print the development strains on the brand new building previous to making an attempt to promote the robotic. This allowed them to find unspoken buyer wants resembling that the load of the robotic wanted to be mild sufficient for an individual to hold from ground to ground and to determine account for winds current in open building. In addition they didn’t want the robotic to be good as they might deliver one other robotic to the client web site as a spare in case the primary one had any points.
Don’t underestimate the challenges of know-how adoption: When you hear that there could also be resistance to shoppers adopting new know-how, watch out to not be so enamored along with your concept that you just brush that apart. BioMotum realized this later of their growth cycle. Whereas they knew that an early design with cables was tough for individuals to grasp and placed on, they thought that the truth that individuals would get such superior outcomes from utilizing their robotic ankle help system that the way it regarded was not as vital. Solely later did they notice that the person expertise is crucial to success of the corporate since if individuals don’t know the way or aren’t keen to place it on, then the outcomes don’t matter. BioMotum’s CEO and co-founder, Ray Browning, acknowledged “it’s by no means in regards to the know-how – it’s about utilizing it.”
Simplify to solely crucial product options: It’s a giant mistake to attempt to get each potential function into the primary launch of your product. Quite, it is advisable be laser targeted on the only incarnation of your product that folks will purchase. A course of that Camino Robotics, a developer of robotic help walkers for the aged, used is to jot down down all of the potential product options after which to have potential customers select which certainly one of simply two options at a time they might select. In addition they had customers stroll by their day, which regularly revealed unmet wants. That helped slim down the record to these options that had been crucial versus nice-to-have.
Additionally, one other firm, Civ Robotics, which is designing surveying robots for outside terrain, beneficial having a value related to doing a pilot with a buyer moderately than doing it at no cost. Individuals are most critical when cash is concerned. Ensure the issue you’re fixing is vital sufficient to the client, even when it’s technologically easy. Attempt to get income as quick as potential.
2. Funding
“It’s powerful to work with the entrepreneur that is aware of every part. Straightforward to take a position if they’ve an open mindset and know the place they may use assist”
– David Chessler, Chessler Holdings
Chessler is a profitable investor, nonetheless in about 22 working corporations. He’s invested tens of hundreds of thousands in capital through the years and is at the moment operating a program referred to as HUSTLE on entrepreneurship in College of South Florida, which incubates scholar concepts.

It at all times prices extra and takes longer than you assume: A typical purpose corporations fail is that they run out of cash or can’t safe their subsequent spherical of funding previous to operating out of money. New entrepreneurs are sometimes stunned by how a lot extra prices the enterprise finally ends up having past what was modeled of their first marketing strategy. In spite of everything, you’re inventing one thing new and disruptive that the market hasn’t seen earlier than, so you may’t have an ideal prediction of how a lot it should value. What you may have although is estimates based mostly on earlier comparable initiatives which mentors and firms who’ve beforehand introduced merchandise to market may also help estimate. Pay attention and be taught and add contingencies to your funds for the unknown areas that would take longer than you assume. It’s additionally simpler to boost more cash in case you have chosen your buyers correctly and they’re keen to maintain investing in you for future rounds.
Develop a sustainable enterprise mannequin: Will you make cash by promoting your product or promoting a service that your product can do? What number of do it is advisable promote to breakeven? What are the continued prices when you do begin promoting them (guarantee, continued growth, achievement, stock, and so forth)? How a lot money will you want for up-front stock prices? How will tariffs and provide chain disruptions have an effect on your prices and timelines? What phrases will you supply your shoppers? How will opponents react to your providing? What pricing pressures will you see? What are shoppers truly going to pay versus what they are saying they may pay? These are simply a number of the questions you need to be answering. What founders additionally generally don’t notice is that the enterprise mannequin will doubtless reshape the structure of your product. So getting that functionality inside your organization early on is crucial to constructing the services or products providing that may enable your organization to flourish for years.
Select buyers correctly: It’s tempting to take the primary time period sheet that’s supplied to you however bear in mind that you’re interviewing for a long-term relationship. One of many robotics startups that I interviewed commented that it might have been way more useful if their buyers had automation, {hardware}, and manufacturing experience. It was at all times a problem to clarify these components of the enterprise they usually didn’t have significant connections to leverage to assist the entrepreneur of their enterprise.
An investor that I talked with additionally mirrored that sentiment from the opposite perspective. If he doesn’t have the power to stack the deck in his and the entrepreneur’s favor by introducing them to key shoppers or huge gamers out there, then he doesn’t really feel his cash will create a large enough impression to take a position. Your main buyers will doubtless even have a seat in your board of administrators so be certain they’ll make introductions for you in your discipline and, in flip, be certain to be clear with them in your progress.
What buyers search for:
- Is it disruptive?
- What’s the market measurement of the chance?
- Can we (the buyers) add worth?
- Is the crew there to execute?
- How lengthy will it take to get to implementation?
Strive inventive advertising to preserve money: When you obtain funding, you need to stretch it so far as potential. There are two nice examples of this that emerged from the interviews. The primary is from Clayton Wooden, former CEO of Picnic Works, the place moderately than getting a sales space at CES, which prices tens of 1000’s of {dollars}, they obtained a spot within the space the place meals was served to show their pizza making robotic. They ended up on three “better of CES” lists in January 2020 with out incurring the traditional expense that will take.
One other instance is from Aadeel Akhtar, CEO and founder at PSYONIC, who has invented and developed a sophisticated bionic arm. Quite than paying for tradeshow cubicles, he walks round reveals holding a reside demo of his arm. He additionally will get in contact with YouTube influencers to function the arm doing inventive duties like bottle methods and flaming board breaking. Every of these movies ended up getting 2 to 4 million views, primarily at no cost.
Paint the longer term moderately than explaining your product: One of many serial entrepreneurs whom I interviewed has been fairly profitable at elevating cash at a number of startups that he’s led through the years. I requested him what his secret is to having the ability to elevate cash repeatedly. He stated that it’s all about storytelling, not explaining the product that you’ve got. You’re not promoting the product you’ve nor the place you’re at. You’re promoting what your product can allow sooner or later. How will your robotic assist handle profound labor shortages or deliver higher instruments which can be easy to make use of that may prolong the capability of the labor? Paint an image that your buyers can see and really feel.
3. Growth course of
“Early on it’s exhausting to get significant buyer suggestions about your concept with out constructing it. Make one thing fast & soiled to be taught from the client as early as potential. Nonetheless, in the event you construct one thing too prototype-y at a later stage, the client could reject it.”
– Philipp Herget, co-founder, Dusty Robotics
Dusty Robotics’ autonomous cell robotic prints building drawings immediately on the flooring of recent buildings. Dusty Robotics has been round since 2018 and raised over $69 million in funding.
Use off-the-shelf {hardware} and open-source software program to your MVP: The robotics corporations who’ve been profitable discovered intelligent and fast methods of making prototypes to indicate potential shoppers rapidly. They cited utilizing off-the-shelf growth kits, open-source software program, and parts of merchandise already available on the market to get a prototype that works properly sufficient to begin gathering real-world information and buyer suggestions. Solely invent what you want. Civ Robotics is an efficient instance of this who was capable of begin testing early variations of their land surveying robotic inside 4 months.
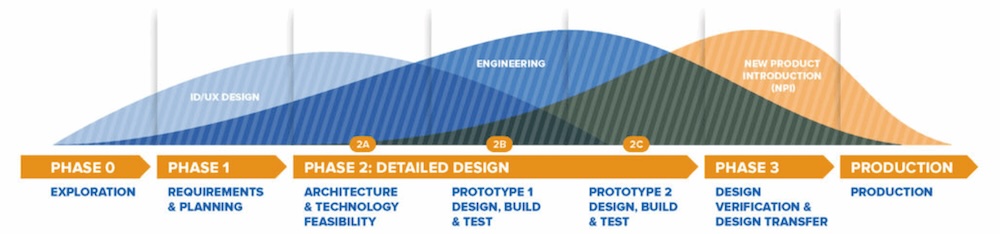
Embrace necessities, Gantt charts, and product course of rigor on the proper stage: There was a particular correlation between these corporations who had formally written down their necessities after which adopted a structured product growth course of and their success. The businesses who struggled probably the most did the design in an ad-hoc method. Whereas this may be acceptable at first once you’re in experimentation mode (Section 0 Exploration within the course of chart beneath), it was inefficient and detrimental to success through the core growth phases. Creating {hardware} is totally different than software program. One of many feedback I heard was that they need to have gone sluggish to go quick. Slowing down, writing down necessities, planning, and following a confirmed growth course of for {hardware} saves time in the long term because you don’t find yourself redoing as a lot work. Beneath is an instance of the product growth course of we use at Simplexity.
Create testbeds to check key performance in parallel: One of many different errors that much less skilled corporations make when growing {hardware} is to construct the complete product unexpectedly after which take a look at it. Subsystem testbeds allow you to take a look at and iterate on the difficult subsystems with out the distraction of interactions with different subsystems which can have their very own points. The extra skilled corporations interviewed construct testbeds to dial in efficiency of a subsystem. For instance, you may take the motor meeting mounted on a bench and take a look at the top effector independently, permitting the engineering crew engaged on the tremendous construction to run in parallel. Don’t attempt to do the important thing science/invention concurrently whereas making an attempt to develop the product. Establish key dangerous core know-how gadgets first and de-risk them on properly managed testbeds.
Use digital twins and simulations: Digital twins or simulation can considerably pace up your growth cycles. For instance, you may simulate the dynamics of movement in seconds in a simulation versus doing it in {hardware} which might take days. However last testing and debugging are at all times carried out on the {hardware}.
Don’t begin the FDA course of too quickly for regulated merchandise: A couple of of the businesses I interviewed had robotics merchandise that had been additionally medical in nature and controlled by the FDA. One warning they’d was to not begin the FDA course of too early. When you present your design to the FDA, then there’s resistance in altering it, which will not be greatest for the product. When growing a product, you’ve 3 unknowns:
- Desirability: does your product fulfill an unmet want out there?
- Feasibility: are you able to technically obtain the unmet want?
- Viability: is your small business mannequin viable sufficient to be aggressive out there?
To learn extra about these unknowns, take a look at Christopher Carlson’s article on a Sustainable Product Framework.
Within the early stage, you need to bounce between assumptions on these three actually quick. Solely after you have confirmed that it’s a good suggestion, then you definately transfer to a extra commonplace section gate course of that goes into the regulatory framework. Corporations who had FDA regulated merchandise cited how tough it was to make the pivot to the product that will be wanted to achieve success out there since they already had medical trial information with their preliminary design.
4. Crew
“Teamwork and management are advanced character traits which can be usually referenced by many individuals however are extensively ailing outlined regardless of the mountain of books and out there courses.”
– George Linscott, previously of Visicon Applied sciences
Linscott turned a commodity enterprise right into a extremely profitable product line. He grew the corporate right into a worthwhile entity with over 100 workers after which had a really profitable exit.
Founders, keep humble: As cited within the Investor part above, it’s acceptable, and even most well-liked, to confess that you just don’t know every part as a founder. It’s a lot simpler to put money into founders who’ve an open mindset and know the place they’ll use assist. In fact, it is advisable be assured and enthusiastic about your concept, however to not the purpose of getting a giant ego. Startups who’ve technically succesful leaders who’re additionally humble and worth their crew are probably the most profitable.
Search a powerful technical co-founder with {hardware} growth expertise: One of many corporations who shut down acknowledged that they had been lacking a powerful technical co-founder with {hardware} growth expertise. Having the suitable management internally, who understands develop merchandise was a key differentiator. You want somebody in your crew who understands the nuances between totally different time constants of growing mechanical and electrical {hardware} versus software program and optimize the interaction between them. It must also be famous that corporations have been profitable in outsourcing their engineering growth to product growth companies like Simplexity and even impartial contractors, however having somebody internally who helps drive the structure and imaginative and prescient for the product may be very useful.
Rent the suitable individuals: When asking corporations about their failure areas, a standard pattern famous was the issue of hiring and generally hiring the incorrect individual. This was normally on account of hiring too quick, however even with the very best interview course of, with sufficient development, a couple of dangerous hires can sneak in. Purple flags to look out for are individuals with big egos, who’re poisonous, and who are usually not coachable. You need to rent individuals with a development mindset who’re keen to be taught. That stated, you additionally need to rent probably the most skilled individuals which you could afford. Despite the fact that new faculty graduates are tremendous sensible and price much less in wage, the errors they’ll make on account of lack of expertise can value the businesses greater than if they’d simply employed a extra senior individual. One individual additionally famous to rent people who find themselves “cussed ” sufficient to completely end a product. Comply with-through and tenacity are crucial in a difficult atmosphere like a startup.
Develop your management & administration abilities: Being a founder and supervisor are two totally different talent units. You is usually a nice technologist, however not essentially an incredible CEO. Whereas it’s actually potential for one particular person to do each successfully, management and administration enhance with coaching, teaching, and follow. If your organization is profitable, then your crew will develop and it is advisable determine develop and encourage them in a constructive vogue (or rent somebody who can). These delicate abilities can generally be dismissed by gifted technical founders, but the leaders who’ve many years of expertise commented that these abilities are what enable an organization to flourish and proceed hiring glorious workers.
Search a number of mentors: You’d be stunned by how many individuals are keen to present freely of their time to assist. Most people who find themselves profitable additionally need to see others have success and are keen to offer recommendation and mentorship when requested. It was additionally famous by one of many entrepreneurs that they benefited from totally different mentors for various levels of their firm. Your organization and your journey will preserve evolving, so preserve looking for mentors who proceed to problem your mind-set and who’re good on the subsequent portion of your small business. At first you might want somebody who is sweet at getting funding, however then later you might want somebody who has efficiently scaled into excessive quantity manufacturing.
5. Scaling
“Scaling is the toughest half, not engineering.”
– Matt Frost, senior {hardware} supervisor, Amazon Robotics
Frost works on Amazon Robotics’ Vulcan bin selecting robotic. They’ve deployed Alpha methods and are actually scaling up.

It’s simpler to go from zero to prototype than from prototype to manufacturing: Even with preliminary success, companies underestimate the trouble it takes from constructing tens of models to tons of/1000’s. Design for manufacturing, meeting, service, take a look at, and security together with creating correctly dimensioned GD&T manufacturing drawings, writing work directions, qualifying manufacturing companions, and different New Product Introduction (NPI) actions take a number of time and price. One firm stated that the prototyping stage over 3 years value lower than 1 12 months of making an attempt to get to manufacturing ramp. The design isn’t full with the proof-of-concept prototype. That’s when the actual work begins. One other one stated that the money hit for ramping up stock was a lot larger than they anticipated. These are the varieties of prices that may sink an organization and trigger them to fail at scale, even after they’ve splendidly practical prototypes and market match.
Plan for & take a look at your product: Planning for testing your product needs to be began initially of your growth as you write down the necessities. If it’s a real requirement, then there needs to be a manner of testing it to verify that the robotic will meet it. This generally means placing in design options to make testing simpler, resembling take a look at factors on a customized PCBA design. Be sure to have a plan for a way you’ll take a look at particular person subsystems after which your complete product coming off the manufacturing line early within the design course of, not as an afterthought. Linscott acknowledged that constructing testbeds in cooperation with their clients helped them keep away from most main points when doing acceptance testing. One other suggestion from a profitable robotics firm was to do extremely accelerated life testing. Overload the system and over-cycle it to seek out the failure factors early.
Automate for manufacturing: As you scale into larger volumes, you need to search for methods to automate or no less than semi-automate the manufacturing of your robotic. Semi-automated manufacturing could also be an incredible match for prime amount sub assemblies that require off-the-shelf decide and place, gluing or fastening applied sciences. Think about customized automation if essential to manufacture your product and thoroughly analyze the fee profit in all scaling phases.
Tariffs & multi-sourcing: Within the current political local weather, a number of of the businesses interviewed associated that tariffs turned unpredictable. They needed to have a method for multi-sourcing their product manufacturing in numerous geographic areas. This isn’t easy to arrange accurately, so working with a agency who may also help you qualify contract producers and have a design and manufacturing package deal prepared handy off to them for quoting is crucial. In the event you need assistance, Simplexity does do that as a part of our NPI course of. A warning right here is to be cautious of contract producers who’re keen to do the design work for “free”. They accomplish that with the stipulation that you’ll have them do all of the manufacturing to your product and because you didn’t pay for the design, you don’t personal it. It’s then very tough to maneuver to a different producer or have a number of ones since then it is advisable pay somebody to reverse engineer your product to get the design package deal it is advisable get a number of quotes.
Search the flywheel impact: Upon getting efficiently scaled into quantity, search for flywheel results of making a robotic system that may be utilized to a couple of buyer want. For instance, Intuitive was capable of leverage the core mechatronic drive that they used for one utility after which standardized it as a core functionality for different adjoining functions. Their system that would reliably reduce, sew, and retract created a flywheel impact as soon as it was leveraged into functions past laparoscopy. This success allowed them to draw nice technologists, retain them, after which make higher merchandise. Success breeds success.
Conclusion
I’m grateful that over a dozen corporations had been keen to have a candid dialog with me about their failures and successes. Whereas I had hypothesized that corporations who confirmed their prototypes to potential shoppers sooner could be extra profitable, there was not a direct correlation. Even the businesses who in the end needed to shut their doorways confirmed their know-how early and obtained suggestions. The important thing differentiator was those who had been capable of get income early from shoppers. Those that had clients keen to pay whereas nonetheless in growth and co-develop with them had been those with continued success. I encourage you to be taught from all these classes, be fanatical about understanding your clients’ ache factors, construct a powerful crew, and comply with a confirmed course of that will help you obtain your targets. And in the event you want engineering assist alongside the best way, Simplexity is right here for you.
Concerning the Creator
 Dorota Shortell is the CEO of Simplexity Product Growth, an engineering design agency specializing within the design of {hardware}, robotics, and mechatronics. Dorota holds a BSME from Loyola Marymount College, earned her MSME at Stanford College underneath an NSF Fellowship, and has accomplished the Govt Management Program at Stanford’s Graduate Faculty of Enterprise.
Dorota Shortell is the CEO of Simplexity Product Growth, an engineering design agency specializing within the design of {hardware}, robotics, and mechatronics. Dorota holds a BSME from Loyola Marymount College, earned her MSME at Stanford College underneath an NSF Fellowship, and has accomplished the Govt Management Program at Stanford’s Graduate Faculty of Enterprise.
She is a US patent holder and has over 20 years of recent product growth expertise. She was acknowledged by the Portland Enterprise Journal as a Forty underneath 40 Award winner and an Govt to Watch.