
Steve Clean Is a $100 Million Sufficient?
![]() This text first appeared in Inc.
This text first appeared in Inc.
Capitalism has been good to me. After serving within the army throughout Vietnam, I got here residence and had a profession in eight startups. I bought to retire once I was 45. During the last quarter century, in my third profession, I helped create the strategies entrepreneurs use to construct new startups, whereas educating 1,000’s of scholars learn how to begin new ventures. It’s been rewarding to see tech entrepreneurship change into an integral a part of the financial system and tech firms change into among the most valued firms on this planet.
What has made this occur is the relentless cycle of innovation and artistic destruction of previous industries pushed by new startups with new tech and new enterprise fashions (community tv changed by streaming companies, Nvidia GPUs versus Intel CPUs, electrical vehicles versus the inner combustion engine, movie cameras versus smartphones, programmers versus AI), all fueled by enterprise capital.
It makes me surprise – are startups nonetheless based by individuals with a ardour for creating one thing new? Or has the motivation modified to accruing the largest pile of money?
Once I was an entrepreneur, what bought me up within the morning was constructing one thing wonderful that folks wished to seize out of my fingers and use. The thought that I would make a $1 million and even $10 million on the way in which was all the time behind my head, however that wasn’t why I did it.
I ponder if it’s totally different for at the moment’s entrepreneurs.
Right here’s a thought experiment: What if we advised each new entrepreneur that no matter how profitable they have been, their whole compensation can be capped at $100 million.
What number of aspiring entrepreneurs would resolve it wasn’t price beginning an organization? Would Steve Jobs, Jeff Bezos, Elon Musk, et al have stop earlier? Have picked different careers?
What number of would resolve it wasn’t price sticking round after their firm was giant and profitable? (Would that be a foul factor?)
Would entrepreneurship undergo? Would we get much less innovation? If that’s the case, why?
Would the most effective and brightest transfer to different international locations?
Then let’s run the identical thought experiment with Enterprise Capitalists. Would they decide different careers? Make investments much less?
At $100 million would capitalism crumble? Would all of us be, heaven forbid, be “Socialists” or worse, to even have this dialog?
Questions
I’m curious what you assume.
Ought to there be any restrict?
If that’s the case, why?
Or why not.
What can be the results?
Filed below: Household/Profession/Tradition, Enterprise Capital |
Nic Cage Thinks His Mysterious Longlegs Monster Is Explosively Horrifying

The weird advertising and marketing for Longlegs has raised the intrigue degree for the summer time horror film sky-high. However one factor audiences have but to catch a great glimpse of is its largest star: Nicolas Cage, who performs the title character. And there’s a cautious cause behind that.
In a brand new interview with Leisure Weekly, Longlegs director Oz Perkins confirmed he’s been intentionally withholding of the titular villain’s design. “It’s driving folks in the direction of a freak present at a circus tent,” in response to Perkins. We’ve acquired the factor behind the scenes, and when there’s sufficient folks gathered ‘spherical, we’re going to pull the curtain.”
Cage bombastically echoed his director’s assertion, claiming his character’s visage is so ghastly, it may doubtlessly incite mass hysteria if not handled delicately sufficient. “It’s the equal of placing a warning label on a jar of nitroglycerin. The monster is a extremely, extremely harmful substance. The best way it’s moved, unveiled, deployed needs to be handled very rigorously,” he stated. “Overlook in regards to the movie show blowing up; the entire metropolis may blow up, nay the nation, perhaps even the world. He’s going to vary your actuality. Your doorways of notion are going to open, and your life just isn’t going to be the identical.”
That’s one hell of a declare for a humble little horror film to stay as much as. Simply what’s the secret of the movie’s serial assassin, solely known as “Longlegs?” Based on EW, the total reveal of Cage’s character doesn’t come till the film’s been underway for awhile.
“Enhancing an image is a virtually psychedelic expertise,” says Perkins. “It truly is as a result of it’s so infinite. The permutations and mixtures you will get from placing this there and that there, you’re in a Rubik’s Dice of prospects. I believe we discovered the candy spot. This man lives simply exterior the consciousness of our protagonist. He’s there, however he’s completely not there, however he’s completely there.”
Whereas we don’t know what the character seems to be like, plot hints recommend Longlegs has each ties to the occult and a “private hyperlink” to Maika Monroe’s character, FBI agent Lee Harker. Whereas we wait on tenterhooks for the movie’s July 12 launch to see for ourselves, you possibly can name the movie’s official hotline within the meantime to at the very least hear Cage’s character rant at you ghoulishly.
Need extra io9 information? Try when to count on the newest Marvel, Star Wars, and Star Trek releases, what’s subsequent for the DC Universe on movie and TV, and the whole lot you have to learn about the way forward for Physician Who.
Apple releases Remaining Reduce Professional updates for iPad and Mac, new iPhone app

Apple on Thursday introduced that Remaining Reduce Professional for iPad 2 and Remaining Reduce Professional for Mac 10.8 at the moment are accessible. Present customers of the software program can get the brand new variations without cost within the App Retailer. The brand new software program consists of options that have been revealed in Might.
Remaining Reduce Professional for iPad 2 and Remaining Reduce Digital camera for iPhone
Listed here are the discharge notes for Remaining Reduce Professional for iPad 2, which lists the brand new options:
- Connect with Remaining Reduce Digital camera on iPad or iPhone to document as much as 4 angles without delay utilizing Reside Multicam.
- Simply create and edit tasks on a related exterior storage system.
- Dial in your publicity with shutter velocity and ISO controls in professional digital camera mode.
- Allow focus peaking to make sure your footage is sharp whereas recording.
- Polish your movies with 12 new colour grading presets, 6 dynamic glitch backgrounds, 20 soundtracks, & fundamental textual content titles, and extra.
Apple has additionally launched Remaining Reduce Digital camera for iPhone (free), which is the companion app required to make use of the Reside MultiCam characteristic in Remaining Reduce for iPad 2. It does work by itself and gives extra skilled controls for adjusting video throughout a shoot than the common Digital camera app.
Remaining Reduce Professional for Mac 10.8
The discharge notes for Remaining Reduce Professional for Mac 10.8 particulars the brand new options and bug fixes:
- Mechanically enhance the colour, colour stability, distinction, and brightness of video or nonetheless photographs utilizing the brand new Improve Gentle and Coloration impact, powered by machine studying.
- Allow Easy Slo-Mo to create wonderful slow-motion visuals with an Al-enhanced algorithm on Mac fashions with Apple silicon.
- Keep organized by renaming colour corrections and video results within the inspector.
- Drag results proper from the inspector to different clips within the timeline or viewer.
- Use new filters within the timeline index to shortly establish clips with audio results, video results, retiming adjustments, lacking media, or lacking results.
- Search within the timeline index by reel, scene, digital camera angle, digital camera identify, customized metadata, or impact identify.
- Seek for clips within the browser utilizing new “Begins With” and “Ends With” search standards.
- Improves timeline scrolling habits throughout reverse playback.
Remaining Reduce Professional for iPad 2 is on the market via a subscription charge of $4.99/£4.99 per thirty days or $49/£49 per yr. Remaining Reduce Professional for Mac 10.8 has a one-time licensing charge of $299.99/£299.99.
Why wait for brand new iPads? Get the ten.9-inch iPad Air for $100 much less proper now

Apple just lately introduced that it’ll maintain a particular occasion in Could, the place we’ll almost definitely see new iPad Professional and iPad Air fashions. Rumors counsel that we are going to obtain the primary iPad Professional with an OLED show and even a bigger model of the iPad Air, giving content material creators a bigger space to work with. Nonetheless, you don’t want to attend till the launch of recent iPads to get your fingers on one, particularly in case you think about that the present fashions are fairly succesful and much more compelling due to the newest reductions out there at Greatest Purchase and Amazon.com.

Apple iPad Air (2022)
$500 $600 Save $100
The iPad Air Fifth era comes with a extra highly effective M1 chip inside, which supplies extra efficiency and effectivity. Although the design stays unchanged, it helps Apple Pencil, comes with an M1 chip, and proves to be a robust machine to suit your whole wants.
We begin at present’s offers with Apple’s 10.9-inch iPad Air, which at the moment sells for as little as $500 due to a really enticing $100 low cost at Greatest Purchase. It will get you a brand new Fifth-generation mannequin with WiFi-only assist and 64GB cupboard space. In fact, you may also half methods with one in all your present tablets and rating as much as $250 in trade-in worth, which can get you a brand new iPad Air for lower than half its unique price ticket. Nonetheless, I strongly counsel you hurry, as shade choices will develop into restricted the nearer we get to the launch of the brand new iPads.
Suppose you need extra cupboard space. In that case, you may additionally wish to try the 256GB storage variant, now coming in at $650 with a 13 p.c low cost at Amazon.com. This selection usually sells for $749, which means you additionally rating $100 in on the spot financial savings for the WiFi-only variant. You can too get your fingers on the newest iteration of the iPad Mini for as little as $400 whenever you go for the 64GB storage choice or pay $550 and get $256GB cupboard space underneath the hood. Both approach, you’ll obtain $100 off.
Nice choices to go together with your new iPad
-1.png?q=70&fit=crop&w=1500&dpr=1)
What’s extra, these offers not solely prevent cash in your new iPad but additionally present ample alternative to boost your expertise with some important equipment. For instance, the second-generation Apple Pencil is now out there for $115, a major 11 p.c low cost, supplying you with an additional $14 off. This accent is an ideal match for any of the iPad fashions talked about above, additional enhancing their performance.
You can too rating 20 p.c financial savings on the AirPods Professional, now out there for $200. If you’d like even higher financial savings, try Skullcandy’s Rail ANC In-Ear Noise canceling Wi-fi Earbuds, which promote for simply $50 after selecting up an insane 50 p.c low cost. TREBLAB’s Z7 Professional are additionally receiving an attention-grabbing worth reduce with an on-page coupon that leaves them up for grabs at $130. If you wish to share your favourite tunes, you may also decide up TREBLAB’s HD77 Wi-fi Bluetooth Speaker for $60, due to a limited-time deal that will provide you with 33 p.c financial savings.
New medical LLM, PathChat 2, can speak to pathologists about tumors, provide diagnoses

Don’t miss OpenAI, Chevron, Nvidia, Kaiser Permanente, and Capital One leaders solely at VentureBeat Rework 2024. Achieve important insights about GenAI and develop your community at this unique three day occasion. Be taught Extra
4 state-of-the-art giant language fashions (LLMs) are offered with a picture of what seems to be like a mauve-colored rock. It’s really a probably critical tumor of the attention — and the fashions are requested about its location, origin and potential extent.
LLaVA-Med identifies the malignant development as within the inside lining of the cheek (flawed), whereas LLaVA says it’s within the breast (much more flawed). GPT-4V, in the meantime, presents up a long-winded, imprecise response, and may’t establish the place it’s in any respect.
However PathChat, a brand new pathology-specific LLM, appropriately pegs the tumor to the attention, informing that it may be vital and result in imaginative and prescient loss.
Developed within the Mahmood Lab at Brigham and Ladies’s Hospital, PathChat represents a breakthrough in computational pathology. It will possibly function a marketing consultant, of types, for human pathologists to assist establish, assess and diagnose tumors and different critical circumstances.
Countdown to VB Rework 2024
Be part of enterprise leaders in San Francisco from July 9 to 11 for our flagship AI occasion. Join with friends, discover the alternatives and challenges of Generative AI, and learn to combine AI purposes into your trade. Register Now
PathChat performs considerably higher than main fashions on multiple-choice diagnostic questions, and it might probably additionally generate clinically related responses to open-ended inquiries. Beginning this week, it’s being provided via an unique license with Boston-based biomedical AI firm Modella AI.
“PathChat 2 is a multimodal giant language mannequin that understands pathology photos and clinically related textual content and may mainly have a dialog with a pathologist,” Richard Chen, Modella founding CTO, defined in a demo video.
PathChat does higher than ChatGPT-4, LLaVA and LLaVA-Med
In constructing PathChat, researchers tailored a imaginative and prescient encoder for pathology, mixed it with a pre-trained LLM and fine-tuned with visible language directions and question-answer turns. Questions coated 54 diagnoses from 11 main pathology practices and organ websites.
Every query integrated two analysis methods: A picture and 10 multiple-choice questions; and a picture with extra medical context resembling affected person intercourse, age, medical historical past and radiology findings.
When offered with photos of X-rays, biopsies, slides and different medical assessments, PathChat carried out with 78% accuracy (on the picture alone) and 89.5% accuracy (on the picture with context). The mannequin was capable of summarize, classify and caption; may describe notable morphological particulars; and answered questions that sometimes require background data in pathology and normal biomedicine.
Researchers in contrast PathChat in opposition to ChatGPT-4V, the open-source LLaVA mannequin and the biomedical domain-specific LLaVA-Med. In each analysis settings, PathChat outperformed all three. In image-only, PathChat scored greater than 52% higher than LLaVA and greater than 63% higher than LLaVA-Med. When offered medical context, the brand new mannequin carried out 39% higher than LLaVA and practically 61% higher than LLaVA-Med.
Equally, PathChat carried out greater than 53% higher than GPT-4 with image-only prompts and 27% higher with prompts offering medical context.
Faisal Mahmood, affiliate professor of pathology at Harvard Medical Faculty, informed VentureBeat that, till now, AI fashions for pathology have largely been developed for particular illnesses (resembling prostate most cancers) or particular duties (resembling figuring out the presence of tumor cells). As soon as educated, these fashions sometimes can’t adapt and due to this fact can’t be utilized by pathologists in an “intuitive, interactive method.”
“PathChat strikes us one step ahead in the direction of normal pathology intelligence, an AI copilot that may interactively and broadly help each researchers and pathologists throughout many alternative areas of pathology, duties and situations,” Mahmood informed VentureBeat.
Providing knowledgeable pathology recommendation
In a single instance of the image-only, multiple-choice immediate, PathChat was offered with the situation of a 63-year-old male experiencing persistent cough and unintentional weight reduction over the earlier 5 months. Researchers additionally fed in a chest X-ray of a dense, spiky mass.
When given 10 choices for solutions, PathChat recognized the right situation (lung adenocarcinoma).
In the meantime, within the immediate methodology supplemented with medical context, PathChat was given a picture of what to the layman seems to be like a closeup of blue and purple sprinkles on a bit of cake, and was knowledgeable: “This tumor was discovered within the liver of a affected person. Is it a major tumor or a metastasis?”
The mannequin appropriately recognized the tumor as metastasis (which means it’s spreading), noting that, “the presence of spindle cells and melanin-containing cells additional helps the potential for a metastatic melanoma. The liver is a standard website for metastasis of melanoma, particularly when it has unfold from the pores and skin.”
Mahmood famous that probably the most stunning end result was that, by coaching on complete pathology data, the mannequin was capable of adapt to downstream duties resembling differential analysis (when signs match a couple of situation) or tumor grading (classifying a tumor on aggressivity), regardless that it was not given labeled coaching knowledge for such cases.
He described this as a “notable shift” from prior analysis, the place mannequin coaching for particular duties — resembling predicting the origin of metastatic tumors or assessing coronary heart transplant rejection — sometimes requires “1000’s if not tens of 1000’s of labeled examples particular to the duty with a view to obtain affordable efficiency.”
Providing medical recommendation, supporting analysis
In follow, PathChat may help human-in-the-loop analysis, during which an preliminary AI-assisted evaluation may very well be adopted up with context, the researchers word. As an example, as within the examples above, the mannequin may ingest a histopathology picture (a microscopic examination of tissue), present data on structural look and establish potential options of malignancy.
The pathologist may then present extra details about the case and ask for a differential analysis. If that suggestion is deemed affordable, the human consumer may ask for recommendation on additional testing, and the mannequin may later be fed the outcomes of these to reach at a analysis.
This, researchers word, may very well be notably helpful in circumstances with extra prolonged, complicated workups, resembling cancers of unknown major (when illnesses have unfold from one other a part of the physique). It may be helpful in low-resource settings the place entry to skilled pathologists is proscribed.
In analysis, in the meantime, an AI copilot may summarize options of enormous cohorts of photos and probably help automated quantification and interpretation of morphological markers in giant knowledge cohorts.
“The potential purposes of an interactive, multimodal AI copilot for pathology are immense,” the researchers write. “LLMs and the broader area of generative AI are poised to open a brand new frontier for computational pathology, one which emphasizes pure language and human interplay.”
Implications past pathology
Whereas PathChat presents a breakthrough, there are nonetheless points with hallucinations, which may very well be improved with reinforcement studying from human suggestions (RLHF), the researchers word. Moreover, they advise, that fashions needs to be regularly educated with up-to-date data so they’re conscious of shifting terminology and tips — for example, retrieval augmented technology (RAG) may assist present a constantly up to date data database.
Wanting additional afield, fashions may very well be made much more helpful for pathologists and researchers with integrations resembling digital slide viewers or digital well being data.
Mahmood famous that PathChat and its capabilities may very well be prolonged to different medical imaging specialties and knowledge modalities resembling genomics (the examine of DNA) and proteomics (large-scale protein examine).
Researchers at his lab plan to gather giant quantities of human suggestions knowledge to additional align mannequin conduct with human intent and enhance responses. They will even combine PathChat with current medical databases in order that the mannequin might help retrieve related affected person data to reply particular questions.
Additional, Mahmood famous, “We plan to work with skilled pathologists throughout many alternative specialties to curate analysis benchmarks and extra comprehensively consider the capabilities and utility of PathChat throughout various illness fashions and workflows.”
Researchers Uncover UEFI Vulnerability Affecting A number of Intel CPUs


Cybersecurity researchers have disclosed particulars of a now-patched safety flaw in Phoenix SecureCore UEFI firmware that impacts a number of households of Intel Core desktop and cellular processors.
Tracked as CVE-2024-0762 (CVSS rating: 7.5), the “UEFIcanhazbufferoverflow” vulnerability has been described as a case of a buffer overflow stemming from the usage of an unsafe variable within the Trusted Platform Module (TPM) configuration that would outcome within the execution of malicious code.
“The vulnerability permits an area attacker to escalate privileges and achieve code execution inside the UEFI firmware throughout runtime,” provide chain safety agency Eclypsium stated in a report shared with The Hacker Information.

“This kind of low-level exploitation is typical of firmware backdoors (e.g., BlackLotus) which might be more and more noticed within the wild. Such implants give attackers ongoing persistence inside a tool and sometimes, the power to evade higher-level safety measures working within the working system and software program layers.”
Following accountable disclosure, the vulnerability was addressed by Phoenix Applied sciences in April 2024. PC maker Lenovo has additionally launched updates for the flaw as of final month.
“This vulnerability impacts gadgets utilizing Phoenix SecureCore firmware working on choose Intel processor households, together with AlderLake, CoffeeLake, CometLake, IceLake, JasperLake, KabyLake, MeteorLake, RaptorLake, RocketLake, and TigerLake,” the firmware developer stated.
UEFI, a successor to BIOS, refers to motherboard firmware used throughout startup to initialize the {hardware} elements and cargo the working system through the boot supervisor.
The truth that UEFI is the primary code that is run with the highest privileges has made it a profitable goal for risk actors trying to deploy bootkits and firmware implants that may subvert safety mechanisms and preserve persistence with out being detected.
This additionally implies that vulnerabilities found within the UEFI firmware can pose a extreme provide chain threat, as they’ll impression many various merchandise and distributors without delay.

“UEFI firmware is a number of the most high-value code on trendy gadgets, and any compromise of that code may give attackers full management and persistence on the machine,” Eclypsium stated.
The event comes practically a month after the corporate disclosed the same unpatched buffer overflow flaw in HP’s implementation of UEFI that impacts HP ProBook 11 EE G1, a tool that reached end-of-life (EoL) standing as of September 2020.
It additionally follows the disclosure of a software program assault referred to as TPM GPIO Reset that might be exploited by attackers to entry secrets and techniques saved on disk by different working methods or undermine controls which might be protected by the TPM resembling disk encryption or boot protections.
Stream multi-tenant information with Amazon MSK

Actual-time information streaming has turn into outstanding in at the moment’s world of instantaneous digital experiences. Fashionable software program as a service (SaaS) functions throughout all industries rely increasingly more on repeatedly generated information from completely different information sources similar to internet and cell functions, Web of Issues (IoT) gadgets, social media platforms, and ecommerce websites. Processing these information streams in actual time is vital to delivering responsive and personalised options, and maximizes the worth of information by processing it as near the occasion time as attainable.
AWS helps SaaS distributors by offering the constructing blocks wanted to implement a streaming software with Amazon Kinesis Knowledge Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK), and real-time processing functions with Amazon Managed Service for Apache Flink.
On this put up, we take a look at implementation patterns a SaaS vendor can undertake when utilizing a streaming platform as a way of integration between inside parts, the place streaming information shouldn’t be immediately uncovered to 3rd events. Specifically, we deal with Amazon MSK.
Streaming multi-tenancy patterns
When constructing streaming functions, it’s best to take the next dimensions under consideration:
- Knowledge partitioning – Occasion streaming and storage must be remoted on the acceptable stage, bodily or logical, based mostly on tenant possession
- Efficiency equity – The efficiency coupling of functions processing streaming information for various tenants should be managed and restricted
- Tenant isolation – A stable authorization technique must be put in place to ensure tenants can entry solely their information
Underpinning all interactions with a multi-tenant system is the idea of SaaS id. For extra data, discuss with SaaS Structure Fundamentals.
SaaS deployment fashions
Tenant isolation shouldn’t be non-compulsory for SaaS suppliers, and tenant isolation approaches will differ relying in your deployment mannequin. The mannequin is influenced by enterprise necessities, and the fashions will not be mutually unique. Commerce-offs should be weighed throughout particular person companies to realize a correct steadiness of isolation, complexity, and price. There isn’t a common answer, and a SaaS vendor must rigorously weigh their enterprise and buyer wants towards three isolation methods: silo, pool and bridge (or combos thereof).
Within the following sections, we discover these deployment fashions throughout information isolation, efficiency equity, and tenant isolation dimensions.
Silo mannequin
The silo mannequin represents the best stage of information segregation, but additionally the best working value. Having a devoted MSK cluster per tenant will increase the chance of overprovisioning and requires duplication of administration and monitoring tooling.
Having a devoted MSK cluster per tenant makes certain tenant information partitioning happens on the disk stage when utilizing an Amazon MSK Provisioned mannequin. Each Amazon MSK Provisioned and Serverless clusters assist server-side encryption at relaxation. Amazon MSK Provisioned additional permits you to use a buyer managed AWS Key Administration Service (AWS KMS) key (see Amazon MSK encryption).
In a silo mannequin, Kafka ACL and quotas shouldn’t be strictly required except your corporation necessities require them. Efficiency equity is assured as a result of solely a single tenant can be utilizing the sources of your entire MSK cluster and are devoted to functions producing and consuming occasions of a single tenant. This implies spikes of site visitors on a selected tenant can’t affect different tenants, and there’s no danger of cross-tenant information entry. As a downside, having a provisioned cluster per tenant requires a right-sizing train per tenant, with a better danger of overprovisioning than within the pool or bridge fashions.
You possibly can implement tenant isolation the MSK cluster stage with AWS Id and Entry Administration (IAM) insurance policies, creating per-cluster credentials, relying on the authentication scheme in use.
Pool mannequin
The pool mannequin is the only mannequin the place tenants share sources. A single MSK cluster is used for all tenants with information cut up into subjects based mostly on the occasion kind (for instance, all occasions associated to orders go to the subject orders), and all tenant’s occasions are despatched to the identical matter. The next diagram illustrates this structure.

This mannequin maximizes operational simplicity, however reduces the tenant isolation choices out there as a result of the SaaS supplier received’t have the ability to differentiate per-tenant operational parameters and all tasks of isolation are delegated to the functions producing and consuming information from Kafka. The pool mannequin additionally doesn’t present any mechanism of bodily information partitioning, nor efficiency equity. A SaaS supplier with these necessities ought to take into account both a bridge or silo mannequin. In the event you don’t have necessities to account for parameters similar to per-tenant encryption keys or tenant-specific information operations, a pool mannequin gives decreased complexity and could be a viable choice. Let’s dig deeper into the trade-offs.
A standard technique to implement shopper isolation is to establish the tenant inside every occasion utilizing a tenant ID. The choices out there with Kafka are passing the tenant ID both as occasion metadata (header) or a part of the payload itself as an express area. With this strategy, the tenant ID can be used as a standardized area throughout all functions inside each the message payload and the occasion header. This strategy can scale back the chance of semantic divergence when parts course of and ahead messages as a result of occasion headers are dealt with in a different way by completely different processing frameworks and may very well be stripped when forwarded. Conversely, the occasion physique is usually forwarded as a single object and no contained data is misplaced except the occasion is explicitly remodeled. Together with the tenant ID within the occasion header as nicely could simplify the implementation of companies permitting you to specify tenants that should be recovered or migrated with out requiring the supplier to deserialize the message payload to filter by tenant.
When specifying the tenant ID utilizing both a header or as a area within the occasion, shopper functions won’t be able to selectively subscribe to the occasions of a selected tenant. With Kafka, a shopper subscribes to a subject and receives all occasions despatched to that matter of all tenants. Solely after receiving an occasion will the buyer will have the ability to examine the tenant ID to filter the tenant of curiosity, making entry segregation just about unattainable. This implies delicate information should be encrypted to ensure a tenant can’t learn one other tenant’s information when viewing these occasions. In Kafka, server-side encryption can solely be set on the cluster stage, the place all tenants sharing a cluster will share the identical server-side encryption key.
In Kafka, information retention can solely be set on the subject. Within the pool mannequin, occasions belonging to all tenants are despatched to the identical matter, so tenant-specific operations like deleting all information for a tenant won’t be attainable. The immutable, append-only nature of Kafka solely permits a complete matter to be deleted, not selective occasions belonging to a selected tenant. If particular buyer information within the stream requires the proper to be forgotten, similar to for GDPR, a pool mannequin won’t work for that information and silo ought to be thought-about for that particular information stream.
Bridge mannequin
Within the bridge mannequin, a single Kafka cluster is used throughout all tenants, however occasions from completely different tenants are segregated into completely different subjects. With this mannequin, there’s a matter for every group of associated occasions per tenant. You possibly can simplify operations by adopting a subject naming conference similar to together with the tenant ID within the matter title. This can virtually create a namespace per tenant, and in addition permits completely different directors to handle completely different tenants, setting permissions with a prefix ACL, and avoiding naming clashes (for instance, occasions associated to orders for tenant 1 go to tenant1.orders and orders of tenant 2 go to tenant2.orders). The next diagram illustrates this structure.

With the bridge mannequin, server-side encryption utilizing a per-tenant key shouldn’t be attainable. Knowledge from completely different tenants is saved in the identical MSK cluster, and server-side encryption keys will be specified per cluster solely. For a similar motive, information segregation can solely be achieved at file stage, as a result of separate subjects are saved in separate information. Amazon MSK shops all subjects throughout the identical Amazon Elastic Block Retailer (Amazon EBS) quantity.
The bridge mannequin gives per-tenant customization, similar to retention coverage or max message dimension, as a result of Kafka permits you to set these parameters per matter. The bridge mannequin additionally simplifies segregating and decoupling occasion processing per tenant, permitting a stronger isolation between separate functions that course of information of separate tenants.
To summarize, the bridge mannequin gives the next capabilities:
- Tenant processing segregation – A shopper software can selectively subscribe to the subjects belonging to particular tenants and solely obtain occasions for these tenants. A SaaS supplier will have the ability to delete information for particular tenants, selectively deleting the subjects belonging to that tenant.
- Selective scaling of the processing – With Kafka, the utmost variety of parallel customers is decided by the variety of partitions of a subject, and the variety of partitions will be set per matter, and due to this fact per tenant.
- Efficiency equity – You possibly can implement efficiency equity utilizing Kafka quotas, supported by Amazon MSK, stopping the companies processing a very busy tenant to eat too many cluster sources, on the expense of different tenants. Seek advice from the next two-part collection for extra particulars on Kafka quotas in Amazon MSK, and an instance implementation for IAM authentication.
- Tenant isolation – You possibly can implement tenant isolation utilizing IAM entry management or Apache Kafka ACLs, relying on the authentication scheme that’s used with Amazon MSK. Each IAM and Kafka ACLs mean you can management entry per matter. You possibly can authorize an software to entry solely the subjects belonging to the tenant it’s alleged to course of.
Commerce-offs in a SaaS setting
Though every mannequin supplies completely different capabilities for information partitioning, efficiency equity, and tenant isolation, additionally they include completely different prices and complexities. Throughout planning, it’s vital to establish what trade-offs you’re keen to make for typical clients, and present a tier construction to your consumer subscriptions.
The next desk summarizes the supported capabilities of the three fashions in a streaming software.
| . | Pool | Bridge | Silo |
| Per-tenant encryption at relaxation | No | No | Sure |
| Can implement proper to be forgotten for single tenant | No | Sure | Sure |
| Per-tenant retention insurance policies | No | Sure | Sure |
| Per-tenant occasion dimension restrict | No | Sure | Sure |
| Per-tenant replayability | Sure (should implement with logic in customers) | Sure | Sure |
Anti-patterns
Within the bridge mannequin, we mentioned tenant segregation by matter. An alternate can be segregating by partition, the place all messages of a given kind are despatched to the identical matter (for instance, orders), however every tenant has a devoted partition. This strategy has many disadvantages and we strongly discourage it. In Kafka, partitions are the unit of horizontal scaling and balancing of brokers and customers. Assigning partitions per tenants can introduce unbalancing of the cluster, and operational and efficiency points that can be arduous to beat.
Some stage of information isolation, similar to per-tenant encryption keys, may very well be achieved utilizing client-side encryption, delegating any encryption or description to the producer and shopper functions. This strategy would mean you can use a separate encryption key per tenant. We don’t suggest this strategy as a result of it introduces a better stage of complexity in each the buyer and producer functions. It could additionally stop you from utilizing many of the commonplace programming libraries, Kafka tooling, and most Kafka ecosystem companies, like Kafka Join or MSK Join.
Conclusion
On this put up, we explored three patterns that SaaS distributors can use when architecting multi-tenant streaming functions with Amazon MSK: the pool, bridge, and silo fashions. Every mannequin presents completely different trade-offs between operational simplicity, tenant isolation stage, and price effectivity.
The silo mannequin dedicates full MSK clusters per tenant, providing an easy tenant isolation strategy however incurring a better upkeep and price per tenant. The pool mannequin gives elevated operational and cost-efficiencies by sharing all sources throughout tenants, however supplies restricted information partitioning, efficiency equity, and tenant isolation capabilities. Lastly, the bridge mannequin gives compromise between operational and cost-efficiencies whereas offering vary of choices to create sturdy tenant isolation and efficiency equity methods.
When architecting your multi-tenant streaming answer, rigorously consider your necessities round tenant isolation, information privateness, per-tenant customization, and efficiency ensures to find out the suitable mannequin. Mix fashions if wanted to search out the proper steadiness for your corporation. As you scale your software, reassess isolation wants and migrate throughout fashions accordingly.
As you’ve seen on this put up, there isn’t a one-size-fits-all sample for streaming information in a multi-tenant structure. Fastidiously weighing your streaming outcomes and buyer wants will assist decide the right trade-offs you can also make whereas ensuring your buyer information is safe and auditable. Proceed your studying journey on SkillBuilder with our SaaS curriculum, get hands-on with an AWS Serverless SaaS workshop or Amazon EKS SaaS workshop, or dive deep with Amazon MSK Labs.
In regards to the Authors
 Emmanuele Levi is a Options Architect within the Enterprise Software program and SaaS staff, based mostly in London. Emanuele helps UK clients on their journey to refactor monolithic functions into trendy microservices SaaS architectures. Emanuele is principally considering event-driven patterns and designs, particularly when utilized to analytics and AI, the place he has experience within the fraud-detection trade.
Emmanuele Levi is a Options Architect within the Enterprise Software program and SaaS staff, based mostly in London. Emanuele helps UK clients on their journey to refactor monolithic functions into trendy microservices SaaS architectures. Emanuele is principally considering event-driven patterns and designs, particularly when utilized to analytics and AI, the place he has experience within the fraud-detection trade.
 Lorenzo Nicora is a Senior Streaming Resolution Architect serving to clients throughout EMEA. He has been constructing cloud-native, data-intensive programs for over 25 years, working throughout industries, in consultancies and product corporations. He has leveraged open-source applied sciences extensively and contributed to a number of tasks, together with Apache Flink.
Lorenzo Nicora is a Senior Streaming Resolution Architect serving to clients throughout EMEA. He has been constructing cloud-native, data-intensive programs for over 25 years, working throughout industries, in consultancies and product corporations. He has leveraged open-source applied sciences extensively and contributed to a number of tasks, together with Apache Flink.
 Nicholas Tunney is a Senior Associate Options Architect for Worldwide Public Sector at AWS. He works with International SI companions to develop architectures on AWS for shoppers within the authorities, nonprofit healthcare, utility, and training sectors. He’s additionally a core member of the SaaS Technical Area Neighborhood the place he will get to satisfy shoppers from everywhere in the world who’re constructing SaaS on AWS.
Nicholas Tunney is a Senior Associate Options Architect for Worldwide Public Sector at AWS. He works with International SI companions to develop architectures on AWS for shoppers within the authorities, nonprofit healthcare, utility, and training sectors. He’s additionally a core member of the SaaS Technical Area Neighborhood the place he will get to satisfy shoppers from everywhere in the world who’re constructing SaaS on AWS.
AWS CodeArtifact provides assist for Rust packages with Cargo

 |
Beginning at the moment, Rust builders can retailer and entry their libraries (generally known as crates in Rust’s world) on AWS CodeArtifact.
Trendy software program growth depends closely on pre-written code packages to speed up growth. These packages, which may quantity within the tons of for a single software, sort out frequent programming duties and will be created internally or obtained from exterior sources. Whereas these packages considerably assist to hurry up growth, their use introduces two major challenges for organizations: authorized and safety considerations.
On the authorized aspect, organizations want to make sure they’ve suitable licenses for these third-party packages and that they don’t infringe on mental property rights. Safety is one other threat, as vulnerabilities in these packages might be exploited to compromise an software. A recognized tactic, the availability chain assault, includes injecting vulnerabilities into fashionable open supply tasks.
To deal with these challenges, organizations can arrange non-public package deal repositories. These repositories retailer pre-approved packages vetted by safety and authorized groups, limiting the danger of authorized or safety publicity. That is the place CodeArtifact enters.
AWS CodeArtifact is a completely managed artifact repository service designed to securely retailer, publish, and share software program packages utilized in software growth. It helps fashionable package deal managers and codecs equivalent to npm, PyPI, Maven, NuGet, SwiftPM, and Rubygem, enabling straightforward integration into current growth workflows. It helps improve safety by means of managed entry and facilitates collaboration throughout groups. CodeArtifact helps preserve a constant, safe, and environment friendly software program growth lifecycle by integrating with AWS Id and Entry Administration (IAM) and steady integration and steady deployment (CI/CD) instruments.
For the eighth 12 months in a row, Rust has topped the chart as “probably the most desired programming language” in Stack Overflow’s annual developer survey, with greater than 80 p.c of builders reporting that they’d like to make use of the language once more subsequent 12 months. Rust’s rising reputation stems from its potential to mix the efficiency and reminiscence security of methods languages equivalent to C++ with options that makes writing dependable, concurrent code simpler. This, together with a wealthy ecosystem and a robust give attention to neighborhood collaboration, makes Rust a sexy possibility for builders engaged on high-performance methods and purposes.
Rust builders depend on Cargo, the official package deal supervisor, to handle package deal dependencies. Cargo simplifies the method of discovering, downloading, and integrating pre-written crates (libraries) into their tasks. This not solely saves time by eliminating guide dependency administration, but additionally ensures compatibility and safety. Cargo’s strong dependency decision system tackles potential conflicts between completely different crate variations, and since many crates come from a curated registry, builders will be extra assured concerning the code’s high quality and security. This give attention to effectivity and reliability makes Cargo a necessary software for constructing Rust purposes.
Let’s create a CodeArtifact repository for my crates
On this demo, I take advantage of the AWS Command Line Interface (AWS CLI) and AWS Administration Console to create two repositories. I configure the primary repository to obtain public packages from the official crates.io repository. I configure the second repository to obtain packages from the primary one solely. This twin repository configuration is the advisable strategy to handle repositories and exterior connections, see the CodeArtifact documentation for managing exterior connections. To cite the documentation:
“It is strongly recommended to have one repository per area with an exterior connection to a given public repository. To attach different repositories to the general public repository, add the repository with the exterior connection as an upstream to them.”
I sketched this diagram for instance the setup.

Domains and repositories will be created both from the command line or the console. I select the command line. In shell terminal, I sort:
CODEARTIFACT_DOMAIN=stormacq-test # Create an internal-facing repository: crates-io-store aws codeartifact create-repository --domain $CODEARTIFACT_DOMAIN --repository crates-io-store # Affiliate the internal-facing repository crates-io-store to the general public crates-io aws codeartifact associate-external-connection --domain $CODEARTIFACT_DOMAIN --repository crates-io-store --external-connection public:crates-io # Create a second internal-facing repository: cargo-repo # and join it to upstream crates-io-store simply created aws codeartifact create-repository --domain $CODEARTIFACT_DOMAIN --repository cargo-repo --upstreams '{"repositoryName":"crates-io-store"}' Subsequent, as a developer, I need my native machine to fetch crates from the inner repository (cargo-repo) I simply created.
I configure cargo to fetch libraries from the inner repository as a substitute of the general public crates.io. To take action, I create a config.toml file to level to CodeArtifact inner repository.
# First, I retrieve the URI of the repo REPO_ENDPOINT=$(aws codeartifact get-repository-endpoint --domain $CODEARTIFACT_DOMAIN --repository cargo-repo --format cargo --output textual content) # at this stage, REPO_ENDPOINT is https://stormacq-test-012345678912.d.codeartifact.us-west-2.amazonaws.com/cargo/cargo-repo/ # Subsequent, I create the cargo config file cat << EOF > ~/.cargo/config.toml [registries.cargo-repo] index = "sparse+$REPO_ENDPOINT" credential-provider = "cargo:token-from-stdout aws codeartifact get-authorization-token --domain $CODEARTIFACT_DOMAIN --query authorizationToken --output textual content" [registry] default = "cargo-repo" [source.crates-io] replace-with = "cargo-repo" EOF Word that the 2 atmosphere variables are changed after I create the config file. cargo doesn’t assist atmosphere variables in its configuration.
Any further, on this machine, each time I invoke cargo so as to add a crate, cargo will get hold of an authorization token from CodeArtifact to speak with the inner cargo-repo repository. I should have IAM privileges to name the get-authorization-token CodeArtifact API along with permissions for learn/publish package deal in accordance with the command I take advantage of. In the event you’re operating this setup from a construct machine to your steady integration (CI) pipeline, your construct machine should have correct permissions to take action.
I can now take a look at this setup and add a crate to my native mission.
$ cargo add regex Updating `codeartifact` index Including regex v1.10.4 to dependencies Options: + perf + perf-backtrack + perf-cache + perf-dfa + perf-inline + perf-literal + perf-onepass + std + unicode + unicode-age + unicode-bool + unicode-case + unicode-gencat + unicode-perl + unicode-script + unicode-segment - logging - sample - perf-dfa-full - unstable - use_std Updating `cargo-repo` index # Construct the mission to set off the obtain of the crate $ cargo construct Downloaded memchr v2.7.2 (registry `cargo-repo`) Downloaded regex-syntax v0.8.3 (registry `cargo-repo`) Downloaded regex v1.10.4 (registry `cargo-repo`) Downloaded aho-corasick v1.1.3 (registry `cargo-repo`) Downloaded regex-automata v0.4.6 (registry `cargo-repo`) Downloaded 5 crates (1.5 MB) in 1.99s Compiling memchr v2.7.2 (registry `cargo-repo`) Compiling regex-syntax v0.8.3 (registry `cargo-repo`) Compiling aho-corasick v1.1.3 (registry `cargo-repo`) Compiling regex-automata v0.4.6 (registry `cargo-repo`) Compiling regex v1.10.4 (registry `cargo-repo`) Compiling hello_world v0.1.0 (/residence/ec2-user/hello_world) Completed `dev` profile [unoptimized + debuginfo] goal(s) in 16.60sI can confirm CodeArtifact downloaded the crate and its dependencies from the upstream public repository. I connect with the CodeArtifact console and test the record of packages out there in both repository I created. At this stage, the package deal record must be equivalent within the two repositories.

Publish a personal package deal to the repository
Now that I do know the upstream hyperlink works as supposed, let’s publish a personal package deal to my cargo-repo repository to make it out there to different groups in my group.
To take action, I take advantage of the usual Rust software cargo, similar to typical. Earlier than doing so, I add and commit the mission recordsdata to the gitrepository.
$ git add . && git commit -m "preliminary commit" 5 recordsdata modified, 1855 insertions(+) create mode 100644 .gitignore create mode 100644 Cargo.lock create mode 100644 Cargo.toml create mode 100644 instructions.sh create mode 100644 src/major.rs $ cargo publish Updating `codeartifact` index Packaging hello_world v0.1.0 (/residence/ec2-user/hello_world) Updating crates.io index Updating `codeartifact` index Verifying hello_world v0.1.0 (/residence/ec2-user/hello_world) Compiling libc v0.2.155 ... (redacted for brevity) .... Compiling hello_world v0.1.0 (/residence/ec2-user/hello_world/goal/package deal/hello_world-0.1.0) Completed `dev` profile [unoptimized + debuginfo] goal(s) in 1m 03s Packaged 5 recordsdata, 44.1KiB (11.5KiB compressed) Importing hello_world v0.1.0 (/residence/ec2-user/hello_world) Uploaded hello_world v0.1.0 to registry `cargo-repo` word: ready for `hello_world v0.1.0` to be out there at registry `cargo-repo`. You might press ctrl-c to skip ready; the crate must be out there shortly. Revealed hello_world v0.1.0 at registry `cargo-repo`Lastly, I take advantage of the console to confirm the hello_world crate is now out there within the cargo-repo.

Pricing and availability
Now you can retailer your Rust libraries in the 13 AWS Areas the place CodeArtifact is out there. There isn’t any extra price for Rust packages. The three billing dimensions are the storage (measured in GB monthly), the variety of requests, and the information switch out to the web or to different AWS Areas. Knowledge switch to AWS companies in the identical Area shouldn’t be charged, which means you’ll be able to run your steady integration and supply (CI/CD) jobs on Amazon Elastic Compute Cloud (Amazon EC2) or AWS CodeBuild, for instance, with out incurring a cost for the CodeArtifact information switch. As typical, the pricing web page has the main points.
Now go construct your Rust purposes and add your non-public crates to CodeArtifact!
Knowledge Fetching Patterns in Single-Web page Purposes

At the moment, most purposes can ship lots of of requests for a single web page.
For instance, my Twitter house web page sends round 300 requests, and an Amazon
product particulars web page sends round 600 requests. A few of them are for static
property (JavaScript, CSS, font information, icons, and many others.), however there are nonetheless
round 100 requests for async information fetching – both for timelines, associates,
or product suggestions, in addition to analytics occasions. That’s fairly a
lot.
The principle cause a web page might comprise so many requests is to enhance
efficiency and consumer expertise, particularly to make the applying really feel
sooner to the top customers. The period of clean pages taking 5 seconds to load is
lengthy gone. In fashionable net purposes, customers sometimes see a primary web page with
fashion and different parts in lower than a second, with extra items
loading progressively.
Take the Amazon product element web page for example. The navigation and prime
bar seem virtually instantly, adopted by the product photographs, transient, and
descriptions. Then, as you scroll, “Sponsored” content material, rankings,
suggestions, view histories, and extra seem.Usually, a consumer solely needs a
fast look or to check merchandise (and verify availability), making
sections like “Clients who purchased this merchandise additionally purchased” much less essential and
appropriate for loading through separate requests.
Breaking down the content material into smaller items and loading them in
parallel is an efficient technique, nevertheless it’s removed from sufficient in giant
purposes. There are a lot of different features to contemplate relating to
fetch information accurately and effectively. Knowledge fetching is a chellenging, not
solely as a result of the character of async programming does not match our linear mindset,
and there are such a lot of elements could cause a community name to fail, but in addition
there are too many not-obvious circumstances to contemplate underneath the hood (information
format, safety, cache, token expiry, and many others.).
On this article, I wish to talk about some frequent issues and
patterns you must contemplate relating to fetching information in your frontend
purposes.
We’ll start with the Asynchronous State Handler sample, which decouples
information fetching from the UI, streamlining your software structure. Subsequent,
we’ll delve into Fallback Markup, enhancing the intuitiveness of your information
fetching logic. To speed up the preliminary information loading course of, we’ll
discover methods for avoiding Request
Waterfall and implementing Parallel Knowledge Fetching. Our dialogue will then cowl Code Splitting to defer
loading non-critical software components and Prefetching information based mostly on consumer
interactions to raise the consumer expertise.
I imagine discussing these ideas by way of a simple instance is
one of the best method. I intention to begin merely after which introduce extra complexity
in a manageable approach. I additionally plan to maintain code snippets, significantly for
styling (I am using TailwindCSS for the UI, which may end up in prolonged
snippets in a React part), to a minimal. For these within the
full particulars, I’ve made them out there on this
repository.
Developments are additionally occurring on the server facet, with methods like
Streaming Server-Aspect Rendering and Server Elements gaining traction in
varied frameworks. Moreover, various experimental strategies are
rising. Nonetheless, these subjects, whereas doubtlessly simply as essential, is likely to be
explored in a future article. For now, this dialogue will focus
solely on front-end information fetching patterns.
It is essential to notice that the methods we’re protecting usually are not
unique to React or any particular frontend framework or library. I’ve
chosen React for illustration functions resulting from my intensive expertise with
it in recent times. Nonetheless, rules like Code Splitting,
Prefetching are
relevant throughout frameworks like Angular or Vue.js. The examples I am going to share
are frequent situations you may encounter in frontend improvement, regardless
of the framework you utilize.
That mentioned, let’s dive into the instance we’re going to make use of all through the
article, a Profile display screen of a Single-Web page Utility. It is a typical
software you might need used earlier than, or at the least the situation is typical.
We have to fetch information from server facet after which at frontend to construct the UI
dynamically with JavaScript.
Introducing the applying
To start with, on Profile we’ll present the consumer’s transient (together with
identify, avatar, and a brief description), after which we additionally wish to present
their connections (just like followers on Twitter or LinkedIn
connections). We’ll have to fetch consumer and their connections information from
distant service, after which assembling these information with UI on the display screen.

Determine 1: Profile display screen
The info are from two separate API calls, the consumer transient API
/customers/<id> returns consumer transient for a given consumer id, which is an easy
object described as follows:
{ "id": "u1", "identify": "Juntao Qiu", "bio": "Developer, Educator, Writer", "pursuits": [ "Technology", "Outdoors", "Travel" ] } And the pal API /customers/<id>/associates endpoint returns an inventory of
associates for a given consumer, every checklist merchandise within the response is identical as
the above consumer information. The explanation we have now two endpoints as an alternative of returning
a associates part of the consumer API is that there are circumstances the place one
may have too many associates (say 1,000), however most individuals haven’t got many.
This in-balance information construction might be fairly tough, particularly once we
have to paginate. The purpose right here is that there are circumstances we have to deal
with a number of community requests.
A quick introduction to related React ideas
As this text leverages React as an instance varied patterns, I do
not assume you recognize a lot about React. Slightly than anticipating you to spend so much
of time looking for the appropriate components within the React documentation, I’ll
briefly introduce these ideas we’ll make the most of all through this
article. For those who already perceive what React elements are, and the
use of the
useState and useEffect hooks, you could
use this hyperlink to skip forward to the following
part.
For these searching for a extra thorough tutorial, the new React documentation is a superb
useful resource.
What’s a React Part?
In React, elements are the basic constructing blocks. To place it
merely, a React part is a operate that returns a bit of UI,
which might be as easy as a fraction of HTML. Think about the
creation of a part that renders a navigation bar:
import React from 'react'; operate Navigation() { return ( <nav> <ol> <li>Dwelling</li> <li>Blogs</li> <li>Books</li> </ol> </nav> ); } At first look, the combination of JavaScript with HTML tags may appear
unusual (it is referred to as JSX, a syntax extension to JavaScript. For these
utilizing TypeScript, the same syntax referred to as TSX is used). To make this
code practical, a compiler is required to translate the JSX into legitimate
JavaScript code. After being compiled by Babel,
the code would roughly translate to the next:
operate Navigation() { return React.createElement( "nav", null, React.createElement( "ol", null, React.createElement("li", null, "Dwelling"), React.createElement("li", null, "Blogs"), React.createElement("li", null, "Books") ) ); } Observe right here the translated code has a operate referred to as
React.createElement, which is a foundational operate in
React for creating parts. JSX written in React elements is compiled
right down to React.createElement calls behind the scenes.
The fundamental syntax of React.createElement is:
React.createElement(kind, [props], [...children])
kind: A string (e.g., ‘div’, ‘span’) indicating the kind of
DOM node to create, or a React part (class or practical) for
extra refined buildings.props: An object containing properties handed to the
ingredient or part, together with occasion handlers, kinds, and attributes
likeclassNameandid.youngsters: These optionally available arguments might be extra
React.createElementcalls, strings, numbers, or any combine
thereof, representing the ingredient’s youngsters.
As an illustration, a easy ingredient might be created with
React.createElement as follows:
React.createElement('div', { className: 'greeting' }, 'Hiya, world!'); That is analogous to the JSX model:
<div className="greeting">Hiya, world!</div>
Beneath the floor, React invokes the native DOM API (e.g.,
doc.createElement("ol")) to generate DOM parts as vital.
You possibly can then assemble your customized elements right into a tree, just like
HTML code:
import React from 'react'; import Navigation from './Navigation.tsx'; import Content material from './Content material.tsx'; import Sidebar from './Sidebar.tsx'; import ProductList from './ProductList.tsx'; operate App() { return <Web page />; } operate Web page() { return <Container> <Navigation /> <Content material> <Sidebar /> <ProductList /> </Content material> <Footer /> </Container>; } Finally, your software requires a root node to mount to, at
which level React assumes management and manages subsequent renders and
re-renders:
import ReactDOM from "react-dom/shopper"; import App from "./App.tsx"; const root = ReactDOM.createRoot(doc.getElementById('root')); root.render(<App />); Producing Dynamic Content material with JSX
The preliminary instance demonstrates a simple use case, however
let’s discover how we will create content material dynamically. As an illustration, how
can we generate an inventory of information dynamically? In React, as illustrated
earlier, a part is basically a operate, enabling us to move
parameters to it.
import React from 'react'; operate Navigation({ nav }) { return ( <nav> <ol> {nav.map(merchandise => <li key={merchandise}>{merchandise}</li>)} </ol> </nav> ); } On this modified Navigation part, we anticipate the
parameter to be an array of strings. We make the most of the map
operate to iterate over every merchandise, reworking them into
<li> parts. The curly braces {} signify
that the enclosed JavaScript expression must be evaluated and
rendered. For these curious in regards to the compiled model of this dynamic
content material dealing with:
operate Navigation(props) { var nav = props.nav; return React.createElement( "nav", null, React.createElement( "ol", null, nav.map(operate(merchandise) { return React.createElement("li", { key: merchandise }, merchandise); }) ) ); } As an alternative of invoking Navigation as a daily operate,
using JSX syntax renders the part invocation extra akin to
writing markup, enhancing readability:
// As an alternative of this Navigation(["Home", "Blogs", "Books"]) // We do that <Navigation nav={["Home", "Blogs", "Books"]} /> Elements in React can obtain various information, referred to as props, to
modify their conduct, very similar to passing arguments right into a operate (the
distinction lies in utilizing JSX syntax, making the code extra acquainted and
readable to these with HTML information, which aligns properly with the ability
set of most frontend builders).
import React from 'react'; import Checkbox from './Checkbox'; import BookList from './BookList'; operate App() { let showNewOnly = false; // This flag's worth is often set based mostly on particular logic. const filteredBooks = showNewOnly ? booksData.filter(e book => e book.isNewPublished) : booksData; return ( <div> <Checkbox checked={showNewOnly}> Present New Printed Books Solely </Checkbox> <BookList books={filteredBooks} /> </div> ); } On this illustrative code snippet (non-functional however meant to
display the idea), we manipulate the BookList
part’s displayed content material by passing it an array of books. Relying
on the showNewOnly flag, this array is both all out there
books or solely these which might be newly printed, showcasing how props can
be used to dynamically regulate part output.
Managing Inside State Between Renders: useState
Constructing consumer interfaces (UI) usually transcends the technology of
static HTML. Elements often have to “bear in mind” sure states and
reply to consumer interactions dynamically. As an illustration, when a consumer
clicks an “Add” button in a Product part, it is necessary to replace
the ShoppingCart part to replicate each the entire worth and the
up to date merchandise checklist.
Within the earlier code snippet, making an attempt to set the
showNewOnly variable to true inside an occasion
handler doesn’t obtain the specified impact:
operate App () { let showNewOnly = false; const handleCheckboxChange = () => { showNewOnly = true; // this does not work }; const filteredBooks = showNewOnly ? booksData.filter(e book => e book.isNewPublished) : booksData; return ( <div> <Checkbox checked={showNewOnly} onChange={handleCheckboxChange}> Present New Printed Books Solely </Checkbox> <BookList books={filteredBooks}/> </div> ); }; This method falls brief as a result of native variables inside a operate
part don’t persist between renders. When React re-renders this
part, it does so from scratch, disregarding any adjustments made to
native variables since these don’t set off re-renders. React stays
unaware of the necessity to replace the part to replicate new information.
This limitation underscores the need for React’s
state. Particularly, practical elements leverage the
useState hook to recollect states throughout renders. Revisiting
the App instance, we will successfully bear in mind the
showNewOnly state as follows:
import React, { useState } from 'react'; import Checkbox from './Checkbox'; import BookList from './BookList'; operate App () { const [showNewOnly, setShowNewOnly] = useState(false); const handleCheckboxChange = () => { setShowNewOnly(!showNewOnly); }; const filteredBooks = showNewOnly ? booksData.filter(e book => e book.isNewPublished) : booksData; return ( <div> <Checkbox checked={showNewOnly} onChange={handleCheckboxChange}> Present New Printed Books Solely </Checkbox> <BookList books={filteredBooks}/> </div> ); }; The useState hook is a cornerstone of React’s Hooks system,
launched to allow practical elements to handle inner state. It
introduces state to practical elements, encapsulated by the next
syntax:
const [state, setState] = useState(initialState);
initialState: This argument is the preliminary
worth of the state variable. It may be a easy worth like a quantity,
string, boolean, or a extra complicated object or array. The
initialStateis barely used throughout the first render to
initialize the state.- Return Worth:
useStatereturns an array with
two parts. The primary ingredient is the present state worth, and the
second ingredient is a operate that enables updating this worth. Through the use of
array destructuring, we assign names to those returned objects,
sometimesstateandsetState, although you possibly can
select any legitimate variable names. state: Represents the present worth of the
state. It is the worth that will likely be used within the part’s UI and
logic.setState: A operate to replace the state. This operate
accepts a brand new state worth or a operate that produces a brand new state based mostly
on the earlier state. When referred to as, it schedules an replace to the
part’s state and triggers a re-render to replicate the adjustments.
React treats state as a snapshot; updating it does not alter the
present state variable however as an alternative triggers a re-render. Throughout this
re-render, React acknowledges the up to date state, making certain the
BookList part receives the right information, thereby
reflecting the up to date e book checklist to the consumer. This snapshot-like
conduct of state facilitates the dynamic and responsive nature of React
elements, enabling them to react intuitively to consumer interactions and
different adjustments.
Managing Aspect Results: useEffect
Earlier than diving deeper into our dialogue, it is essential to deal with the
idea of unintended effects. Unintended effects are operations that work together with
the skin world from the React ecosystem. Frequent examples embrace
fetching information from a distant server or dynamically manipulating the DOM,
comparable to altering the web page title.
React is primarily involved with rendering information to the DOM and does
not inherently deal with information fetching or direct DOM manipulation. To
facilitate these unintended effects, React supplies the useEffect
hook. This hook permits the execution of unintended effects after React has
accomplished its rendering course of. If these unintended effects lead to information
adjustments, React schedules a re-render to replicate these updates.
The useEffect Hook accepts two arguments:
- A operate containing the facet impact logic.
- An optionally available dependency array specifying when the facet impact must be
re-invoked.
Omitting the second argument causes the facet impact to run after
each render. Offering an empty array [] signifies that your impact
doesn’t rely on any values from props or state, thus not needing to
re-run. Together with particular values within the array means the facet impact
solely re-executes if these values change.
When coping with asynchronous information fetching, the workflow inside
useEffect entails initiating a community request. As soon as the information is
retrieved, it’s captured through the useState hook, updating the
part’s inner state and preserving the fetched information throughout
renders. React, recognizing the state replace, undertakes one other render
cycle to include the brand new information.
Here is a sensible instance about information fetching and state
administration:
import { useEffect, useState } from "react"; kind Person = { id: string; identify: string; }; const UserSection = ({ id }) => { const [user, setUser] = useState<Person | undefined>(); useEffect(() => { const fetchUser = async () => { const response = await fetch(`/api/customers/${id}`); const jsonData = await response.json(); setUser(jsonData); }; fetchUser(); }, tag:martinfowler.com,2024-05-23:Code-Splitting-in-Single-Web page-Purposes); return <div> <h2>{consumer?.identify}</h2> </div>; }; Within the code snippet above, inside useEffect, an
asynchronous operate fetchUser is outlined after which
instantly invoked. This sample is critical as a result of
useEffect doesn’t straight help async features as its
callback. The async operate is outlined to make use of await for
the fetch operation, making certain that the code execution waits for the
response after which processes the JSON information. As soon as the information is on the market,
it updates the part’s state through setUser.
The dependency array tag:martinfowler.com,2024-05-23:Code-Splitting-in-Single-Web page-Purposes on the finish of the
useEffect name ensures that the impact runs once more provided that
id adjustments, which prevents pointless community requests on
each render and fetches new consumer information when the id prop
updates.
This method to dealing with asynchronous information fetching inside
useEffect is a regular apply in React improvement, providing a
structured and environment friendly strategy to combine async operations into the
React part lifecycle.
As well as, in sensible purposes, managing totally different states
comparable to loading, error, and information presentation is important too (we’ll
see it the way it works within the following part). For instance, contemplate
implementing standing indicators inside a Person part to replicate
loading, error, or information states, enhancing the consumer expertise by
offering suggestions throughout information fetching operations.

Determine 2: Completely different statuses of a
part
This overview gives only a fast glimpse into the ideas utilized
all through this text. For a deeper dive into extra ideas and
patterns, I like to recommend exploring the new React
documentation or consulting different on-line assets.
With this basis, you must now be geared up to hitch me as we delve
into the information fetching patterns mentioned herein.
Implement the Profile part
Let’s create the Profile part to make a request and
render the outcome. In typical React purposes, this information fetching is
dealt with inside a useEffect block. Here is an instance of how
this is likely to be applied:
import { useEffect, useState } from "react"; const Profile = ({ id }: { id: string }) => { const [user, setUser] = useState<Person | undefined>(); useEffect(() => { const fetchUser = async () => { const response = await fetch(`/api/customers/${id}`); const jsonData = await response.json(); setUser(jsonData); }; fetchUser(); }, tag:martinfowler.com,2024-05-23:Code-Splitting-in-Single-Web page-Purposes); return ( <UserBrief consumer={consumer} /> ); }; This preliminary method assumes community requests full
instantaneously, which is commonly not the case. Actual-world situations require
dealing with various community circumstances, together with delays and failures. To
handle these successfully, we incorporate loading and error states into our
part. This addition permits us to supply suggestions to the consumer throughout
information fetching, comparable to displaying a loading indicator or a skeleton display screen
if the information is delayed, and dealing with errors after they happen.
Right here’s how the improved part appears to be like with added loading and error
administration:
import { useEffect, useState } from "react"; import { get } from "../utils.ts"; import kind { Person } from "../sorts.ts"; const Profile = ({ id }: { id: string }) => { const [loading, setLoading] = useState<boolean>(false); const [error, setError] = useState<Error | undefined>(); const [user, setUser] = useState<Person | undefined>(); useEffect(() => { const fetchUser = async () => { strive { setLoading(true); const information = await get<Person>(`/customers/${id}`); setUser(information); } catch (e) { setError(e as Error); } lastly { setLoading(false); } }; fetchUser(); }, tag:martinfowler.com,2024-05-23:Code-Splitting-in-Single-Web page-Purposes); if (loading || !consumer) { return <div>Loading...</div>; } return ( <> {consumer && <UserBrief consumer={consumer} />} </> ); }; Now in Profile part, we provoke states for loading,
errors, and consumer information with useState. Utilizing
useEffect, we fetch consumer information based mostly on id,
toggling loading standing and dealing with errors accordingly. Upon profitable
information retrieval, we replace the consumer state, else show a loading
indicator.
The get operate, as demonstrated beneath, simplifies
fetching information from a particular endpoint by appending the endpoint to a
predefined base URL. It checks the response’s success standing and both
returns the parsed JSON information or throws an error for unsuccessful requests,
streamlining error dealing with and information retrieval in our software. Observe
it is pure TypeScript code and can be utilized in different non-React components of the
software.
const baseurl = "https://icodeit.com.au/api/v2"; async operate get<T>(url: string): Promise<T> { const response = await fetch(`${baseurl}${url}`); if (!response.okay) { throw new Error("Community response was not okay"); } return await response.json() as Promise<T>; } React will attempt to render the part initially, however as the information
consumer isn’t out there, it returns “loading…” in a
div. Then the useEffect is invoked, and the
request is kicked off. As soon as sooner or later, the response returns, React
re-renders the Profile part with consumer
fulfilled, so now you can see the consumer part with identify, avatar, and
title.
If we visualize the timeline of the above code, you will note
the next sequence. The browser firstly downloads the HTML web page, and
then when it encounters script tags and elegance tags, it would cease and
obtain these information, after which parse them to kind the ultimate web page. Observe
that it is a comparatively difficult course of, and I’m oversimplifying
right here, however the primary thought of the sequence is appropriate.
Determine 3: Fetching consumer
information
So React can begin to render solely when the JS are parsed and executed,
after which it finds the useEffect for information fetching; it has to attend till
the information is on the market for a re-render.
Now within the browser, we will see a “loading…” when the applying
begins, after which after a number of seconds (we will simulate such case by add
some delay within the API endpoints) the consumer transient part reveals up when information
is loaded.
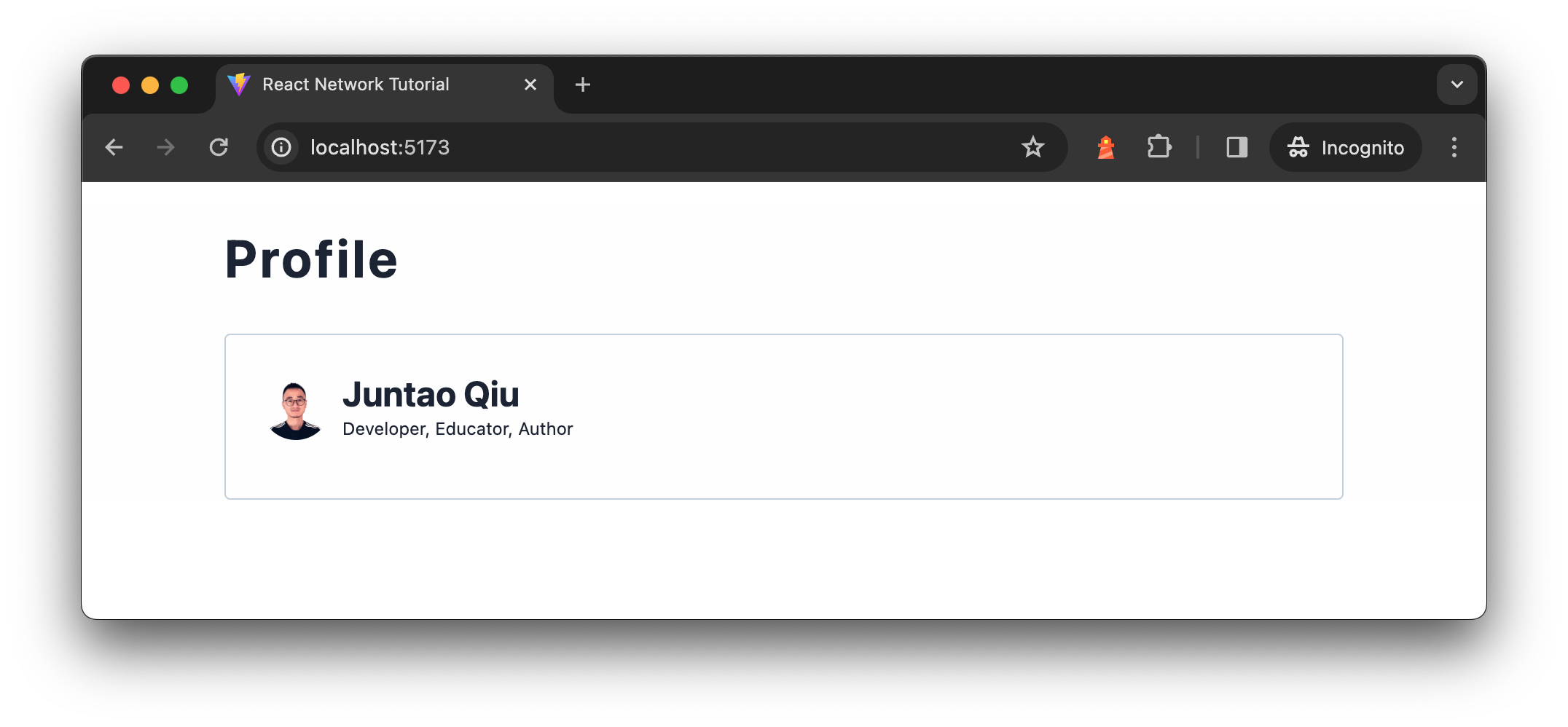
Determine 4: Person transient part
This code construction (in useEffect to set off request, and replace states
like loading and error correspondingly) is
broadly used throughout React codebases. In purposes of standard measurement, it is
frequent to search out quite a few cases of such similar data-fetching logic
dispersed all through varied elements.
Asynchronous State Handler
Wrap asynchronous queries with meta-queries for the state of the
question.
Distant calls might be gradual, and it is important to not let the UI freeze
whereas these calls are being made. Subsequently, we deal with them asynchronously
and use indicators to point out {that a} course of is underway, which makes the
consumer expertise higher – figuring out that one thing is going on.
Moreover, distant calls may fail resulting from connection points,
requiring clear communication of those failures to the consumer. Subsequently,
it is best to encapsulate every distant name inside a handler module that
manages outcomes, progress updates, and errors. This module permits the UI
to entry metadata in regards to the standing of the decision, enabling it to show
different data or choices if the anticipated outcomes fail to
materialize.
A easy implementation might be a operate getAsyncStates that
returns these metadata, it takes a URL as its parameter and returns an
object containing data important for managing asynchronous
operations. This setup permits us to appropriately reply to totally different
states of a community request, whether or not it is in progress, efficiently
resolved, or has encountered an error.
const { loading, error, information } = getAsyncStates(url); if (loading) { // Show a loading spinner } if (error) { // Show an error message } // Proceed to render utilizing the information The idea right here is that getAsyncStates initiates the
community request robotically upon being referred to as. Nonetheless, this won’t
all the time align with the caller’s wants. To supply extra management, we will additionally
expose a fetch operate throughout the returned object, permitting
the initiation of the request at a extra applicable time, in accordance with the
caller’s discretion. Moreover, a refetch operate may
be offered to allow the caller to re-initiate the request as wanted,
comparable to after an error or when up to date information is required. The
fetch and refetch features might be similar in
implementation, or refetch may embrace logic to verify for
cached outcomes and solely re-fetch information if vital.
const { loading, error, information, fetch, refetch } = getAsyncStates(url); const onInit = () => { fetch(); }; const onRefreshClicked = () => { refetch(); }; if (loading) { // Show a loading spinner } if (error) { // Show an error message } // Proceed to render utilizing the information This sample supplies a flexible method to dealing with asynchronous
requests, giving builders the flexibleness to set off information fetching
explicitly and handle the UI’s response to loading, error, and success
states successfully. By decoupling the fetching logic from its initiation,
purposes can adapt extra dynamically to consumer interactions and different
runtime circumstances, enhancing the consumer expertise and software
reliability.
Implementing Asynchronous State Handler in React with hooks
The sample might be applied in numerous frontend libraries. For
occasion, we may distill this method right into a customized Hook in a React
software for the Profile part:
import { useEffect, useState } from "react"; import { get } from "../utils.ts"; const useUser = (id: string) => { const [loading, setLoading] = useState<boolean>(false); const [error, setError] = useState<Error | undefined>(); const [user, setUser] = useState<Person | undefined>(); useEffect(() => { const fetchUser = async () => { strive { setLoading(true); const information = await get<Person>(`/customers/${id}`); setUser(information); } catch (e) { setError(e as Error); } lastly { setLoading(false); } }; fetchUser(); }, tag:martinfowler.com,2024-05-23:Code-Splitting-in-Single-Web page-Purposes); return { loading, error, consumer, }; }; Please notice that within the customized Hook, we haven’t any JSX code –
that means it’s very UI free however sharable stateful logic. And the
useUser launch information robotically when referred to as. Inside the Profile
part, leveraging the useUser Hook simplifies its logic:
import { useUser } from './useUser.ts'; import UserBrief from './UserBrief.tsx'; const Profile = ({ id }: { id: string }) => { const { loading, error, consumer } = useUser(id); if (loading || !consumer) { return <div>Loading...</div>; } if (error) { return <div>One thing went mistaken...</div>; } return ( <> {consumer && <UserBrief consumer={consumer} />} </> ); }; Generalizing Parameter Utilization
In most purposes, fetching various kinds of information—from consumer
particulars on a homepage to product lists in search outcomes and
suggestions beneath them—is a typical requirement. Writing separate
fetch features for every kind of information might be tedious and tough to
keep. A greater method is to summary this performance right into a
generic, reusable hook that may deal with varied information sorts
effectively.
Think about treating distant API endpoints as companies, and use a generic
useService hook that accepts a URL as a parameter whereas managing all
the metadata related to an asynchronous request:
import { get } from "../utils.ts"; operate useService<T>(url: string) { const [loading, setLoading] = useState<boolean>(false); const [error, setError] = useState<Error | undefined>(); const [data, setData] = useState<T | undefined>(); const fetch = async () => { strive { setLoading(true); const information = await get<T>(url); setData(information); } catch (e) { setError(e as Error); } lastly { setLoading(false); } }; return { loading, error, information, fetch, }; } This hook abstracts the information fetching course of, making it simpler to
combine into any part that should retrieve information from a distant
supply. It additionally centralizes frequent error dealing with situations, comparable to
treating particular errors in another way:
import { useService } from './useService.ts'; const { loading, error, information: consumer, fetch: fetchUser, } = useService(`/customers/${id}`); Through the use of useService, we will simplify how elements fetch and deal with
information, making the codebase cleaner and extra maintainable.
Variation of the sample
A variation of the useUser can be expose the
fetchUsers operate, and it doesn’t set off the information
fetching itself:
import { useState } from "react"; const useUser = (id: string) => { // outline the states const fetchUser = async () => { strive { setLoading(true); const information = await get<Person>(`/customers/${id}`); setUser(information); } catch (e) { setError(e as Error); } lastly { setLoading(false); } }; return { loading, error, consumer, fetchUser, }; }; After which on the calling website, Profile part use
useEffect to fetch the information and render totally different
states.
const Profile = ({ id }: { id: string }) => { const { loading, error, consumer, fetchUser } = useUser(id); useEffect(() => { fetchUser(); }, []); // render correspondingly }; The benefit of this division is the flexibility to reuse these stateful
logics throughout totally different elements. As an illustration, one other part
needing the identical information (a consumer API name with a consumer ID) can merely import
the useUser Hook and make the most of its states. Completely different UI
elements may select to work together with these states in varied methods,
maybe utilizing different loading indicators (a smaller spinner that
matches to the calling part) or error messages, but the basic
logic of fetching information stays constant and shared.
When to make use of it
Separating information fetching logic from UI elements can typically
introduce pointless complexity, significantly in smaller purposes.
Holding this logic built-in throughout the part, just like the
css-in-js method, simplifies navigation and is less complicated for some
builders to handle. In my article, Modularizing
React Purposes with Established UI Patterns, I explored
varied ranges of complexity in software buildings. For purposes
which might be restricted in scope — with only a few pages and a number of other information
fetching operations — it is usually sensible and in addition really useful to
keep information fetching inside the UI elements.
Nonetheless, as your software scales and the event staff grows,
this technique might result in inefficiencies. Deep part timber can gradual
down your software (we’ll see examples in addition to tips on how to tackle
them within the following sections) and generate redundant boilerplate code.
Introducing an Asynchronous State Handler can mitigate these points by
decoupling information fetching from UI rendering, enhancing each efficiency
and maintainability.
It’s essential to stability simplicity with structured approaches as your
venture evolves. This ensures your improvement practices stay
efficient and conscious of the applying’s wants, sustaining optimum
efficiency and developer effectivity whatever the venture
scale.
Implement the Pals checklist
Now let’s take a look on the second part of the Profile – the pal
checklist. We are able to create a separate part Pals and fetch information in it
(by utilizing a useService customized hook we outlined above), and the logic is
fairly just like what we see above within the Profile part.
const Pals = ({ id }: { id: string }) => { const { loading, error, information: associates } = useService(`/customers/${id}/associates`); // loading & error dealing with... return ( <div> <h2>Pals</h2> <div> {associates.map((consumer) => ( // render consumer checklist ))} </div> </div> ); }; After which within the Profile part, we will use Pals as a daily
part, and move in id as a prop:
const Profile = ({ id }: { id: string }) => { //... return ( <> {consumer && <UserBrief consumer={consumer} />} <Pals id={id} /> </> ); }; The code works high-quality, and it appears to be like fairly clear and readable,
UserBrief renders a consumer object handed in, whereas
Pals handle its personal information fetching and rendering logic
altogether. If we visualize the part tree, it could be one thing like
this:
Determine 5: Part construction
Each the Profile and Pals have logic for
information fetching, loading checks, and error dealing with. Since there are two
separate information fetching calls, and if we take a look at the request timeline, we
will discover one thing fascinating.
Determine 6: Request waterfall
The Pals part will not provoke information fetching till the consumer
state is ready. That is known as the Fetch-On-Render method,
the place the preliminary rendering is paused as a result of the information is not out there,
requiring React to attend for the information to be retrieved from the server
facet.
This ready interval is considerably inefficient, contemplating that whereas
React’s rendering course of solely takes a number of milliseconds, information fetching can
take considerably longer, usually seconds. Because of this, the Pals
part spends most of its time idle, ready for information. This situation
results in a typical problem referred to as the Request Waterfall, a frequent
prevalence in frontend purposes that contain a number of information fetching
operations.
Parallel Knowledge Fetching
Run distant information fetches in parallel to reduce wait time
Think about once we construct a bigger software {that a} part that
requires information might be deeply nested within the part tree, to make the
matter worse these elements are developed by totally different groups, it’s onerous
to see whom we’re blocking.
Determine 7: Request waterfall
Request Waterfalls can degrade consumer
expertise, one thing we intention to keep away from. Analyzing the information, we see that the
consumer API and associates API are impartial and might be fetched in parallel.
Initiating these parallel requests turns into essential for software
efficiency.
One method is to centralize information fetching at the next stage, close to the
root. Early within the software’s lifecycle, we begin all information fetches
concurrently. Elements depending on this information wait just for the
slowest request, sometimes leading to sooner total load occasions.
We may use the Promise API Promise.all to ship
each requests for the consumer’s primary data and their associates checklist.
Promise.all is a JavaScript technique that enables for the
concurrent execution of a number of guarantees. It takes an array of guarantees
as enter and returns a single Promise that resolves when the entire enter
guarantees have resolved, offering their outcomes as an array. If any of the
guarantees fail, Promise.all instantly rejects with the
cause of the primary promise that rejects.
As an illustration, on the software’s root, we will outline a complete
information mannequin:
kind ProfileState = { consumer: Person; associates: Person[]; }; const getProfileData = async (id: string) => Promise.all([ get<User>(`/users/${id}`), get<User[]>(`/customers/${id}/associates`), ]); const App = () => { // fetch information on the very begining of the applying launch const onInit = () => { const [user, friends] = await getProfileData(id); } // render the sub tree correspondingly } Implementing Parallel Knowledge Fetching in React
Upon software launch, information fetching begins, abstracting the
fetching course of from subcomponents. For instance, in Profile part,
each UserBrief and Pals are presentational elements that react to
the handed information. This fashion we may develop these part individually
(including kinds for various states, for instance). These presentational
elements usually are simple to check and modify as we have now separate the
information fetching and rendering.
We are able to outline a customized hook useProfileData that facilitates
parallel fetching of information associated to a consumer and their associates by utilizing
Promise.all. This technique permits simultaneous requests, optimizing the
loading course of and structuring the information right into a predefined format identified
as ProfileData.
Right here’s a breakdown of the hook implementation:
import { useCallback, useEffect, useState } from "react"; kind ProfileData = { consumer: Person; associates: Person[]; }; const useProfileData = (id: string) => { const [loading, setLoading] = useState<boolean>(false); const [error, setError] = useState<Error | undefined>(undefined); const [profileState, setProfileState] = useState<ProfileData>(); const fetchProfileState = useCallback(async () => { strive { setLoading(true); const [user, friends] = await Promise.all([ get<User>(`/users/${id}`), get<User[]>(`/customers/${id}/associates`), ]); setProfileState({ consumer, associates }); } catch (e) { setError(e as Error); } lastly { setLoading(false); } }, tag:martinfowler.com,2024-05-23:Code-Splitting-in-Single-Web page-Purposes); return { loading, error, profileState, fetchProfileState, }; }; This hook supplies the Profile part with the
vital information states (loading, error,
profileState) together with a fetchProfileState
operate, enabling the part to provoke the fetch operation as
wanted. Observe right here we use useCallback hook to wrap the async
operate for information fetching. The useCallback hook in React is used to
memoize features, making certain that the identical operate occasion is
maintained throughout part re-renders until its dependencies change.
Much like the useEffect, it accepts the operate and a dependency
array, the operate will solely be recreated if any of those dependencies
change, thereby avoiding unintended conduct in React’s rendering
cycle.
The Profile part makes use of this hook and controls the information fetching
timing through useEffect:
const Profile = ({ id }: { id: string }) => { const { loading, error, profileState, fetchProfileState } = useProfileData(id); useEffect(() => { fetchProfileState(); }, [fetchProfileState]); if (loading) { return <div>Loading...</div>; } if (error) { return <div>One thing went mistaken...</div>; } return ( <> {profileState && ( <> <UserBrief consumer={profileState.consumer} /> <Pals customers={profileState.associates} /> </> )} </> ); }; This method is also referred to as Fetch-Then-Render, suggesting that the intention
is to provoke requests as early as doable throughout web page load.
Subsequently, the fetched information is utilized to drive React’s rendering of
the applying, bypassing the necessity to handle information fetching amidst the
rendering course of. This technique simplifies the rendering course of,
making the code simpler to check and modify.
And the part construction, if visualized, can be just like the
following illustration
Determine 8: Part construction after refactoring
And the timeline is far shorter than the earlier one as we ship two
requests in parallel. The Pals part can render in a number of
milliseconds as when it begins to render, the information is already prepared and
handed in.
Determine 9: Parallel requests
Observe that the longest wait time depends upon the slowest community
request, which is far sooner than the sequential ones. And if we may
ship as many of those impartial requests on the similar time at an higher
stage of the part tree, a greater consumer expertise might be
anticipated.
As purposes broaden, managing an growing variety of requests at
root stage turns into difficult. That is significantly true for elements
distant from the foundation, the place passing down information turns into cumbersome. One
method is to retailer all information globally, accessible through features (like
Redux or the React Context API), avoiding deep prop drilling.
When to make use of it
Operating queries in parallel is beneficial each time such queries could also be
gradual and do not considerably intervene with every others’ efficiency.
That is often the case with distant queries. Even when the distant
machine’s I/O and computation is quick, there’s all the time potential latency
points within the distant calls. The principle drawback for parallel queries
is setting them up with some form of asynchronous mechanism, which can be
tough in some language environments.
The principle cause to not use parallel information fetching is once we do not
know what information must be fetched till we have already fetched some
information. Sure situations require sequential information fetching resulting from
dependencies between requests. As an illustration, contemplate a situation on a
Profile web page the place producing a personalised advice feed
depends upon first buying the consumer’s pursuits from a consumer API.
Here is an instance response from the consumer API that features
pursuits:
{ "id": "u1", "identify": "Juntao Qiu", "bio": "Developer, Educator, Writer", "pursuits": [ "Technology", "Outdoors", "Travel" ] } In such circumstances, the advice feed can solely be fetched after
receiving the consumer’s pursuits from the preliminary API name. This
sequential dependency prevents us from using parallel fetching, as
the second request depends on information obtained from the primary.
Given these constraints, it turns into essential to debate different
methods in asynchronous information administration. One such technique is
Fallback Markup. This method permits builders to specify what
information is required and the way it must be fetched in a approach that clearly
defines dependencies, making it simpler to handle complicated information
relationships in an software.
One other instance of when arallel Knowledge Fetching just isn’t relevant is
that in situations involving consumer interactions that require real-time
information validation.
Think about the case of an inventory the place every merchandise has an “Approve” context
menu. When a consumer clicks on the “Approve” possibility for an merchandise, a dropdown
menu seems providing decisions to both “Approve” or “Reject.” If this
merchandise’s approval standing might be modified by one other admin concurrently,
then the menu choices should replicate probably the most present state to keep away from
conflicting actions.

Determine 10: The approval checklist that require in-time
states
To deal with this, a service name is initiated every time the context
menu is activated. This service fetches the newest standing of the merchandise,
making certain that the dropdown is constructed with probably the most correct and
present choices out there at that second. Because of this, these requests
can’t be made in parallel with different data-fetching actions for the reason that
dropdown’s contents rely totally on the real-time standing fetched from
the server.
Fallback Markup
Specify fallback shows within the web page markup
This sample leverages abstractions offered by frameworks or libraries
to deal with the information retrieval course of, together with managing states like
loading, success, and error, behind the scenes. It permits builders to
deal with the construction and presentation of information of their purposes,
selling cleaner and extra maintainable code.
Let’s take one other take a look at the Pals part within the above
part. It has to keep up three totally different states and register the
callback in useEffect, setting the flag accurately on the proper time,
organize the totally different UI for various states:
const Pals = ({ id }: { id: string }) => { //... const { loading, error, information: associates, fetch: fetchFriends, } = useService(`/customers/${id}/associates`); useEffect(() => { fetchFriends(); }, []); if (loading) { // present loading indicator } if (error) { // present error message part } // present the acutal pal checklist }; You’ll discover that inside a part we have now to take care of
totally different states, even we extract customized Hook to scale back the noise in a
part, we nonetheless have to pay good consideration to dealing with
loading and error inside a part. These
boilerplate code might be cumbersome and distracting, usually cluttering the
readability of our codebase.
If we consider declarative API, like how we construct our UI with JSX, the
code might be written within the following method that lets you deal with
what the part is doing – not tips on how to do it:
<WhenError fallback={<ErrorMessage />}> <WhenInProgress fallback={<Loading />}> <Pals /> </WhenInProgress> </WhenError> Within the above code snippet, the intention is easy and clear: when an
error happens, ErrorMessage is displayed. Whereas the operation is in
progress, Loading is proven. As soon as the operation completes with out errors,
the Pals part is rendered.
And the code snippet above is fairly similiar to what already be
applied in a number of libraries (together with React and Vue.js). For instance,
the brand new Suspense in React permits builders to extra successfully handle
asynchronous operations inside their elements, enhancing the dealing with of
loading states, error states, and the orchestration of concurrent
duties.
Implementing Fallback Markup in React with Suspense
Suspense in React is a mechanism for effectively dealing with
asynchronous operations, comparable to information fetching or useful resource loading, in a
declarative method. By wrapping elements in a Suspense boundary,
builders can specify fallback content material to show whereas ready for the
part’s information dependencies to be fulfilled, streamlining the consumer
expertise throughout loading states.
Whereas with the Suspense API, within the Pals you describe what you
wish to get after which render:
import useSWR from "swr"; import { get } from "../utils.ts"; operate Pals({ id }: { id: string }) { const { information: customers } = useSWR("/api/profile", () => get<Person[]>(`/customers/${id}/associates`), { suspense: true, }); return ( <div> <h2>Pals</h2> <div> {associates.map((consumer) => ( <Buddy consumer={consumer} key={consumer.id} /> ))} </div> </div> ); } And declaratively if you use the Pals, you utilize
Suspense boundary to wrap across the Pals
part:
<Suspense fallback={<FriendsSkeleton />}> <Pals id={id} /> </Suspense> Suspense manages the asynchronous loading of the
Pals part, exhibiting a FriendsSkeleton
placeholder till the part’s information dependencies are
resolved. This setup ensures that the consumer interface stays responsive
and informative throughout information fetching, enhancing the general consumer
expertise.
Use the sample in Vue.js
It is price noting that Vue.js can be exploring the same
experimental sample, the place you possibly can make use of Fallback Markup utilizing:
<Suspense> <template #default> <AsyncComponent /> </template> <template #fallback> Loading... </template> </Suspense>
Upon the primary render, <Suspense> makes an attempt to render
its default content material behind the scenes. Ought to it encounter any
asynchronous dependencies throughout this part, it transitions right into a
pending state, the place the fallback content material is displayed as an alternative. As soon as all
the asynchronous dependencies are efficiently loaded,
<Suspense> strikes to a resolved state, and the content material
initially meant for show (the default slot content material) is
rendered.
Deciding Placement for the Loading Part
You might surprise the place to position the FriendsSkeleton
part and who ought to handle it. Sometimes, with out utilizing Fallback
Markup, this resolution is simple and dealt with straight throughout the
part that manages the information fetching:
const Pals = ({ id }: { id: string }) => { // Knowledge fetching logic right here... if (loading) { // Show loading indicator } if (error) { // Show error message part } // Render the precise pal checklist }; On this setup, the logic for displaying loading indicators or error
messages is of course located throughout the Pals part. Nonetheless,
adopting Fallback Markup shifts this duty to the
part’s client:
<Suspense fallback={<FriendsSkeleton />}> <Pals id={id} /> </Suspense> In real-world purposes, the optimum method to dealing with loading
experiences relies upon considerably on the specified consumer interplay and
the construction of the applying. As an illustration, a hierarchical loading
method the place a guardian part ceases to point out a loading indicator
whereas its youngsters elements proceed can disrupt the consumer expertise.
Thus, it is essential to rigorously contemplate at what stage throughout the
part hierarchy the loading indicators or skeleton placeholders
must be displayed.
Consider Pals and FriendsSkeleton as two
distinct part states—one representing the presence of information, and the
different, the absence. This idea is considerably analogous to utilizing a Speical Case sample in object-oriented
programming, the place FriendsSkeleton serves because the ‘null’
state dealing with for the Pals part.
The secret is to find out the granularity with which you wish to
show loading indicators and to keep up consistency in these
choices throughout your software. Doing so helps obtain a smoother and
extra predictable consumer expertise.
When to make use of it
Utilizing Fallback Markup in your UI simplifies code by enhancing its readability
and maintainability. This sample is especially efficient when using
commonplace elements for varied states comparable to loading, errors, skeletons, and
empty views throughout your software. It reduces redundancy and cleans up
boilerplate code, permitting elements to focus solely on rendering and
performance.
Fallback Markup, comparable to React’s Suspense, standardizes the dealing with of
asynchronous loading, making certain a constant consumer expertise. It additionally improves
software efficiency by optimizing useful resource loading and rendering, which is
particularly useful in complicated purposes with deep part timber.
Nonetheless, the effectiveness of Fallback Markup depends upon the capabilities of
the framework you might be utilizing. For instance, React’s implementation of Suspense for
information fetching nonetheless requires third-party libraries, and Vue’s help for
comparable options is experimental. Furthermore, whereas Fallback Markup can cut back
complexity in managing state throughout elements, it could introduce overhead in
easier purposes the place managing state straight inside elements may
suffice. Moreover, this sample might restrict detailed management over loading and
error states—conditions the place totally different error sorts want distinct dealing with may
not be as simply managed with a generic fallback method.
Introducing UserDetailCard part
Let’s say we want a function that when customers hover on prime of a Buddy,
we present a popup to allow them to see extra particulars about that consumer.
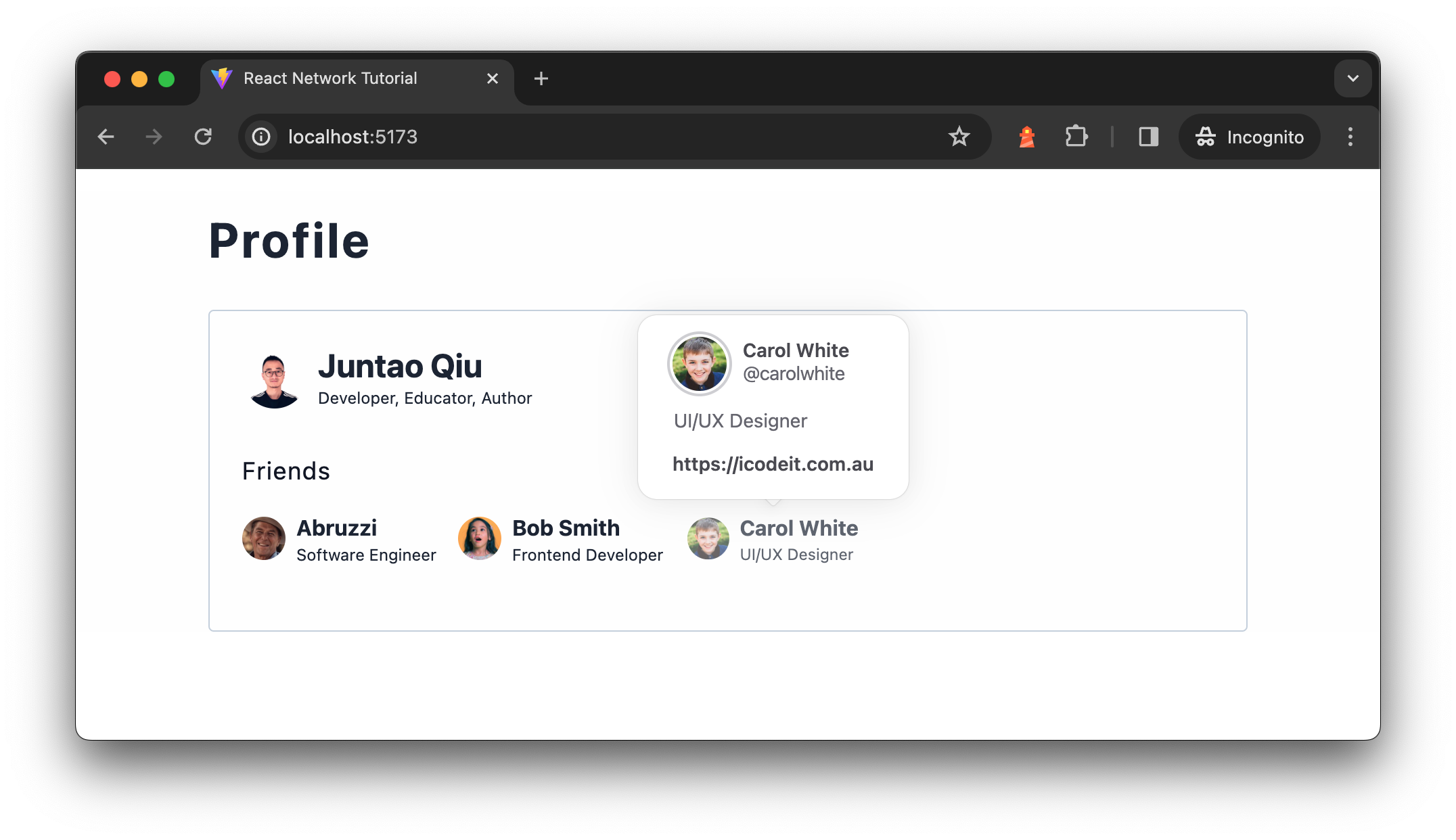
Determine 11: Displaying consumer element
card part when hover
When the popup reveals up, we have to ship one other service name to get
the consumer particulars (like their homepage and variety of connections, and many others.). We
might want to replace the Buddy part ((the one we use to
render every merchandise within the Pals checklist) ) to one thing just like the
following.
import { Popover, PopoverContent, PopoverTrigger } from "@nextui-org/react"; import { UserBrief } from "./consumer.tsx"; import UserDetailCard from "./user-detail-card.tsx"; export const Buddy = ({ consumer }: { consumer: Person }) => { return ( <Popover placement="backside" showArrow offset={10}> <PopoverTrigger> <button> <UserBrief consumer={consumer} /> </button> </PopoverTrigger> <PopoverContent> <UserDetailCard id={consumer.id} /> </PopoverContent> </Popover> ); }; The UserDetailCard, is fairly just like the
Profile part, it sends a request to load information after which
renders the outcome as soon as it will get the response.
export operate UserDetailCard({ id }: { id: string }) { const { loading, error, element } = useUserDetail(id); if (loading || !element) { return <div>Loading...</div>; } return ( <div> {/* render the consumer element*/} </div> ); } We’re utilizing Popover and the supporting elements from
nextui, which supplies a whole lot of stunning and out-of-box
elements for constructing fashionable UI. The one drawback right here, nonetheless, is that
the bundle itself is comparatively large, additionally not everybody makes use of the function
(hover and present particulars), so loading that further giant bundle for everybody
isn’t splendid – it could be higher to load the UserDetailCard
on demand – each time it’s required.
Determine 12: Part construction with
UserDetailCard
Code Splitting
Divide code into separate modules and dynamically load them as
wanted.
Code Splitting addresses the problem of huge bundle sizes in net
purposes by dividing the bundle into smaller chunks which might be loaded as
wanted, slightly than abruptly. This improves preliminary load time and
efficiency, particularly essential for big purposes or these with
many routes.
This optimization is often carried out at construct time, the place complicated
or sizable modules are segregated into distinct bundles. These are then
dynamically loaded, both in response to consumer interactions or
preemptively, in a way that doesn’t hinder the essential rendering path
of the applying.
Leveraging the Dynamic Import Operator
The dynamic import operator in JavaScript streamlines the method of
loading modules. Although it could resemble a operate name in your code,
comparable to import("./user-detail-card.tsx"), it is essential to
acknowledge that import is definitely a key phrase, not a
operate. This operator permits the asynchronous and dynamic loading of
JavaScript modules.
With dynamic import, you possibly can load a module on demand. For instance, we
solely load a module when a button is clicked:
button.addEventListener("click on", (e) => { import("/modules/some-useful-module.js") .then((module) => { module.doSomethingInteresting(); }) .catch(error => { console.error("Didn't load the module:", error); }); }); The module just isn’t loaded throughout the preliminary web page load. As an alternative, the
import() name is positioned inside an occasion listener so it solely
be loaded when, and if, the consumer interacts with that button.
You should use dynamic import operator in React and libraries like
Vue.js. React simplifies the code splitting and lazy load by way of the
React.lazy and Suspense APIs. By wrapping the
import assertion with React.lazy, and subsequently wrapping
the part, as an example, UserDetailCard, with
Suspense, React defers the part rendering till the
required module is loaded. Throughout this loading part, a fallback UI is
introduced, seamlessly transitioning to the precise part upon load
completion.
import React, { Suspense } from "react"; import { Popover, PopoverContent, PopoverTrigger } from "@nextui-org/react"; import { UserBrief } from "./consumer.tsx"; const UserDetailCard = React.lazy(() => import("./user-detail-card.tsx")); export const Buddy = ({ consumer }: { consumer: Person }) => { return ( <Popover placement="backside" showArrow offset={10}> <PopoverTrigger> <button> <UserBrief consumer={consumer} /> </button> </PopoverTrigger> <PopoverContent> <Suspense fallback={<div>Loading...</div>}> <UserDetailCard id={consumer.id} /> </Suspense> </PopoverContent> </Popover> ); }; This snippet defines a Buddy part displaying consumer
particulars inside a popover from Subsequent UI, which seems upon interplay.
It leverages React.lazy for code splitting, loading the
UserDetailCard part solely when wanted. This
lazy-loading, mixed with Suspense, enhances efficiency
by splitting the bundle and exhibiting a fallback throughout the load.
If we visualize the above code, it renders within the following
sequence.
Determine 13: Dynamic load part
when wanted
Observe that when the consumer hovers and we obtain
the JavaScript bundle, there will likely be some further time for the browser to
parse the JavaScript. As soon as that a part of the work is finished, we will get the
consumer particulars by calling /customers/<id>/particulars API.
Ultimately, we will use that information to render the content material of the popup
UserDetailCard.
When to make use of it
Splitting out further bundles and loading them on demand is a viable
technique, nevertheless it’s essential to contemplate the way you implement it. Requesting
and processing an extra bundle can certainly save bandwidth and lets
customers solely load what they want. Nonetheless, this method may also gradual
down the consumer expertise in sure situations. For instance, if a consumer
hovers over a button that triggers a bundle load, it may take a number of
seconds to load, parse, and execute the JavaScript vital for
rendering. Although this delay happens solely throughout the first
interplay, it won’t present the best expertise.
To enhance perceived efficiency, successfully utilizing React Suspense to
show a skeleton or one other loading indicator may also help make the
loading course of appear faster. Moreover, if the separate bundle is
not considerably giant, integrating it into the primary bundle might be a
extra easy and cost-effective method. This fashion, when a consumer
hovers over elements like UserBrief, the response might be
instant, enhancing the consumer interplay with out the necessity for separate
loading steps.
Lazy load in different frontend libraries
Once more, this sample is broadly adopted in different frontend libraries as
properly. For instance, you should use defineAsyncComponent in Vue.js to
obtain the samiliar outcome – solely load a part if you want it to
render:
<template> <Popover placement="backside" show-arrow offset="10"> <!-- the remainder of the template --> </Popover> </template> <script> import { defineAsyncComponent } from 'vue'; import Popover from 'path-to-popover-component'; import UserBrief from './UserBrief.vue'; const UserDetailCard = defineAsyncComponent(() => import('./UserDetailCard.vue')); // rendering logic </script> The operate defineAsyncComponent defines an async
part which is lazy loaded solely when it’s rendered identical to the
React.lazy.
As you might need already seen the seen, we’re operating right into a Request Waterfall right here once more: we load the
JavaScript bundle first, after which when it execute it sequentially name
consumer particulars API, which makes some further ready time. We may request
the JavaScript bundle and the community request parallely. Which means,
each time a Buddy part is hovered, we will set off a
community request (for the information to render the consumer particulars) and cache the
outcome, in order that by the point when the bundle is downloaded, we will use
the information to render the part instantly.
Prefetching
Prefetch information earlier than it could be wanted to scale back latency whether it is.
Prefetching includes loading assets or information forward of their precise
want, aiming to lower wait occasions throughout subsequent operations. This
method is especially useful in situations the place consumer actions can
be predicted, comparable to navigating to a unique web page or displaying a modal
dialog that requires distant information.
In apply, prefetching might be
applied utilizing the native HTML <hyperlink> tag with a
rel="preload" attribute, or programmatically through the
fetch API to load information or assets upfront. For information that
is predetermined, the best method is to make use of the
<hyperlink> tag throughout the HTML <head>:
<!doctype html> <html lang="en"> <head> <hyperlink rel="preload" href="https://martinfowler.com/bootstrap.js" as="script"> <hyperlink rel="preload" href="https://martinfowler.com/customers/u1" as="fetch" crossorigin="nameless"> <hyperlink rel="preload" href="https://martinfowler.com/customers/u1/associates" as="fetch" crossorigin="nameless"> <script kind="module" src="https://martinfowler.com/app.js"></script> </head> <physique> <div id="root"></div> </physique> </html>
With this setup, the requests for bootstrap.js and consumer API are despatched
as quickly because the HTML is parsed, considerably sooner than when different
scripts are processed. The browser will then cache the information, making certain it
is prepared when your software initializes.
Nonetheless, it is usually not doable to know the exact URLs forward of
time, requiring a extra dynamic method to prefetching. That is sometimes
managed programmatically, usually by way of occasion handlers that set off
prefetching based mostly on consumer interactions or different circumstances.
For instance, attaching a mouseover occasion listener to a button can
set off the prefetching of information. This technique permits the information to be fetched
and saved, maybe in an area state or cache, prepared for instant use
when the precise part or content material requiring the information is interacted with
or rendered. This proactive loading minimizes latency and enhances the
consumer expertise by having information prepared forward of time.
doc.getElementById('button').addEventListener('mouseover', () => { fetch(`/consumer/${consumer.id}/particulars`) .then(response => response.json()) .then(information => { sessionStorage.setItem('userDetails', JSON.stringify(information)); }) .catch(error => console.error(error)); }); And within the place that wants the information to render, it reads from
sessionStorage when out there, in any other case exhibiting a loading indicator.
Usually the consumer experiense can be a lot sooner.
Implementing Prefetching in React
For instance, we will use preload from the
swr bundle (the operate identify is a bit deceptive, nevertheless it
is performing a prefetch right here), after which register an
onMouseEnter occasion to the set off part of
Popover,
import { preload } from "swr"; import { getUserDetail } from "../api.ts"; const UserDetailCard = React.lazy(() => import("./user-detail-card.tsx")); export const Buddy = ({ consumer }: { consumer: Person }) => { const handleMouseEnter = () => { preload(`/consumer/${consumer.id}/particulars`, () => getUserDetail(consumer.id)); }; return ( <Popover placement="backside" showArrow offset={10}> <PopoverTrigger> <button onMouseEnter={handleMouseEnter}> <UserBrief consumer={consumer} /> </button> </PopoverTrigger> <PopoverContent> <Suspense fallback={<div>Loading...</div>}> <UserDetailCard id={consumer.id} /> </Suspense> </PopoverContent> </Popover> ); }; That approach, the popup itself can have a lot much less time to render, which
brings a greater consumer expertise.
Determine 14: Dynamic load with prefetch
in parallel
So when a consumer hovers on a Buddy, we obtain the
corresponding JavaScript bundle in addition to obtain the information wanted to
render the UserDetailCard, and by the point UserDetailCard
renders, it sees the present information and renders instantly.
Determine 15: Part construction with
dynamic load
As the information fetching and loading is shifted to Buddy
part, and for UserDetailCard, it reads from the native
cache maintained by swr.
import useSWR from "swr"; export operate UserDetailCard({ id }: { id: string }) { const { information: element, isLoading: loading } = useSWR( `/consumer/${id}/particulars`, () => getUserDetail(id) ); if (loading || !element) { return <div>Loading...</div>; } return ( <div> {/* render the consumer element*/} </div> ); } This part makes use of the useSWR hook for information fetching,
making the UserDetailCard dynamically load consumer particulars
based mostly on the given id. useSWR gives environment friendly
information fetching with caching, revalidation, and computerized error dealing with.
The part shows a loading state till the information is fetched. As soon as
the information is on the market, it proceeds to render the consumer particulars.
In abstract, we have already explored essential information fetching methods:
Asynchronous State Handler , Parallel Knowledge Fetching ,
Fallback Markup , Code Splitting and Prefetching . Elevating requests for parallel execution
enhances effectivity, although it isn’t all the time easy, particularly
when coping with elements developed by totally different groups with out full
visibility. Code splitting permits for the dynamic loading of
non-critical assets based mostly on consumer interplay, like clicks or hovers,
using prefetching to parallelize useful resource loading.
When to make use of it
Think about making use of prefetching if you discover that the preliminary load time of
your software is changing into gradual, or there are numerous options that are not
instantly vital on the preliminary display screen however might be wanted shortly after.
Prefetching is especially helpful for assets which might be triggered by consumer
interactions, comparable to mouse-overs or clicks. Whereas the browser is busy fetching
different assets, comparable to JavaScript bundles or property, prefetching can load
extra information upfront, thus getting ready for when the consumer truly must
see the content material. By loading assets throughout idle occasions, prefetching makes use of the
community extra effectively, spreading the load over time slightly than inflicting spikes
in demand.
It’s clever to observe a basic guideline: do not implement complicated patterns like
prefetching till they’re clearly wanted. This is likely to be the case if efficiency
points change into obvious, particularly throughout preliminary hundreds, or if a big
portion of your customers entry the app from cell gadgets, which usually have
much less bandwidth and slower JavaScript engines. Additionally, contemplate that there are different
efficiency optimization techniques comparable to caching at varied ranges, utilizing CDNs
for static property, and making certain property are compressed. These strategies can improve
efficiency with easier configurations and with out extra coding. The
effectiveness of prefetching depends on precisely predicting consumer actions.
Incorrect assumptions can result in ineffective prefetching and even degrade the
consumer expertise by delaying the loading of really wanted assets.
Selecting the best sample
Deciding on the suitable sample for information fetching and rendering in
net improvement just isn’t one-size-fits-all. Usually, a number of methods are
mixed to satisfy particular necessities. For instance, you may have to
generate some content material on the server facet – utilizing Server-Aspect Rendering
methods – supplemented by client-side
Fetch-Then-Render for dynamic
content material. Moreover, non-essential sections might be break up into separate
bundles for lazy loading, probably with Prefetching triggered by consumer
actions, comparable to hover or click on.
Think about the Jira problem web page for example. The highest navigation and
sidebar are static, loading first to provide customers instant context. Early
on, you are introduced with the problem’s title, description, and key particulars
just like the Reporter and Assignee. For much less instant data, comparable to
the Historical past part at a problem’s backside, it hundreds solely upon consumer
interplay, like clicking a tab. This makes use of lazy loading and information
fetching to effectively handle assets and improve consumer expertise.
Determine 16: Utilizing patterns collectively
Furthermore, sure methods require extra setup in comparison with
default, much less optimized options. As an illustration, implementing Code Splitting requires bundler help. In case your present bundler lacks this
functionality, an improve could also be required, which might be impractical for
older, much less steady techniques.
We have coated a variety of patterns and the way they apply to varied
challenges. I notice there’s fairly a bit to absorb, from code examples
to diagrams. For those who’re searching for a extra guided method, I’ve put
collectively a complete tutorial on my
web site, or if you happen to solely need to take a look on the working code, they’re
all hosted on this github repo.
Conclusion
Knowledge fetching is a nuanced facet of improvement, but mastering the
applicable methods can vastly improve our purposes. As we conclude
our journey by way of information fetching and content material rendering methods inside
the context of React, it is essential to spotlight our most important insights:
- Asynchronous State Handler: Make the most of customized hooks or composable APIs to
summary information fetching and state administration away out of your elements. This
sample centralizes asynchronous logic, simplifying part design and
enhancing reusability throughout your software. - Fallback Markup: React’s enhanced Suspense mannequin helps a extra
declarative method to fetching information asynchronously, streamlining your
codebase. - Parallel Knowledge Fetching: Maximize effectivity by fetching information in
parallel, decreasing wait occasions and boosting the responsiveness of your
software. - Code Splitting: Make use of lazy loading for non-essential
elements throughout the preliminary load, leveraging Suspense for swish
dealing with of loading states and code splitting, thereby making certain your
software stays performant. - Prefetching: By preemptively loading information based mostly on predicted consumer
actions, you possibly can obtain a clean and quick consumer expertise.
Whereas these insights had been framed throughout the React ecosystem, it is
important to acknowledge that these patterns usually are not confined to React
alone. They’re broadly relevant and useful methods that may—and
ought to—be tailored to be used with different libraries and frameworks. By
thoughtfully implementing these approaches, builders can create
purposes that aren’t simply environment friendly and scalable, but in addition provide a
superior consumer expertise by way of efficient information fetching and content material
rendering practices.