The Enhancer for YouTube is an essential add-on for anyone seeking comprehensive control over video playback in their browser.
Here’s an improved version of the text: With this extension, you may easily configure and manage the subsequent components:
Theme
Participant video controls: a comprehensive suite of features including loop, quantity increase, data cards, cinema mode, pop-up participants, playback speed, filters, and more.
The place to put controls
Playback high quality
Quantity
Autoplay
Video codecs
Mini participant
Popup participant dimension
Look
And extra
When dealing with frequent adjustments to YouTube video settings. This extension enables customization of default settings, providing users with options to manage aspects they previously didn’t realize they could control.
With the help of Enhancer for YouTube, I have significantly enhanced my video-viewing skills.
Here’s a guide on setting up and using this extension:
Putting in Enhancer for YouTube
One key requirement for this position is having a functional installation of Mozilla Firefox. In fact, setting up this extension can be accomplished across multiple browsers with ease. Let’s set up Firefox together.
To install the Enhancer for YouTube in Firefox, click the “Add to Firefox” button on the Enhancer for YouTube webpage. OK, you’ll then be prompted to confirm your order. The extension is successfully installed when you click OK.
The Enhancer for YouTube is arguably one of the most valuable Firefox add-ons available.
To effortlessly access and customize Enhancer for YouTube settings, simply click the puzzle piece icon in your Firefox toolbar, then select the gear icon from the dropdown menu under “Enhancer for YouTube” and choose ‘Pin to Toolbar’.
While you don’t need to secure the attachment, doing so simplifies entering the Settings webpage by providing a convenient shortcut.
Configuring Enhancer for YouTube
To access settings, simply click on the Enhancer for YouTube icon situated in your browser’s toolbar, which will promptly open the Settings webpage for your consideration. Configure individual settings for each side of this browser extension. To customize your YouTube experience, I suggest selecting which controls you want to add or remove from the participant management toolbar and setting the default playback quality for videos, playlists, and the pop-up player. You’ll have the option to select a resolution ranging from 144p to a stunning 4320p 8K. I am inclined to set playback quality to high definition at 1440p or ultra-high definition at 2160p, depending on the show being watched.
There exist more options on YouTube than you may have initially recognized were available.
All adjustments are saved automatically in real-time, eliminating the need for a separate Save button click. Once you’ve completed all necessary changes, you can close the Settings window.
Utilizing Enhancer for YouTube
Upon opening a YouTube video, users may encounter a newly introduced toolbar situated below the video, showcasing all controls previously customized within the Settings menu. This toolbar offers significantly enhanced control and management options for movie-related activities, surpassing the standard features typically found on YouTube.
The Filters option proves to be a valuable asset in one’s workflow. Once you’ve incorporated the desired effect into the default control set, simply click the designated button while watching a video to access a compact popup menu offering fine-tuned adjustments for Gaussian blur, brightness, contrast, grayscale, hue rotation, color inversion, saturation, and sepia tone. When dealing with poor video quality, these options are particularly useful. You’ll have the flexibility to customize the video to seamlessly integrate with your program and visual preferences.
Adjusting the filters can significantly enhance your viewing experience.
So, here’s what you get with Enhancer for YouTube: Regardless of the browser you choose, you owe it to yourself to install and utilize this extension if you frequently watch YouTube videos.
Japanese researchers , reaching ). This surpasses their . To put this into perspective, 402 terabits per second (Tbps) dwarfs typical residential web speeds, which often lag far behind 1,000 megabits per second (Mbps).
This remarkable speed enables instantaneous downloads of massive files, such as the 18+ GB game Elden Ring, with ease. Researchers have achieved a significant breakthrough by leveraging readily available fibre optic cables and combining them with cutting-edge innovations. These innovations introduce the world’s first O-to-U band transmission system capable of dense wavelength division multiplexing (DWDM) in standard optical fibre, integrated with custom-designed amplification technology.
The graph released by NICT at its press event effectively conveys the significant advancements achieved in this latest study, as well as the specific wavelengths employed by researchers to accomplish these breakthroughs.
The international research team was headed by experts at the National Institute of Information and Communications Technology (NICT) in Tokyo, Japan. Their method focused on optimizing signal boosting to maximize the data transmission capacity of fiber optic cables.
Researchers successfully employed a novel combination of six doped-fiber amplifier types and Raman amplification techniques to access the full range of low-loss transmission bands in silica fibers, thereby achieving an impressive 37.6 terahertz (THz) bandwidth over a distance of 50 kilometers using fiber optic cable.
You cannot obtain this product at your home.
Despite advancements, it’s unlikely that consumers will have access to such blistering speeds anytime soon; current hardware constraints mean that even high-end gaming PCs are unable to handle or process data at such extraordinary velocities. Notwithstanding this, the brand-new transmission system marks a substantial breakthrough in information transfer capacities.
While the near-term implications for shoppers are uncertain, the experimental nature of this analysis holds significant potential to transform the development of faster internet technologies, possibly paving the way for revolutionary advancements in data transmission rates down the line.
Filed in . Discovering the intricacies of syntax, semantics, and pragmatics in natural language processing is crucial for developing sophisticated AI models that can accurately comprehend human communication.
Since Apple discontinued the iPhone mini, I’ve held onto the optimism that they would redirect their attention to revamping the iPhone SE into a device deserving of an upgrade. If the latest whispers are anything to go by, reality might just converge with speculation.
According to reports from Ice Universe, details have emerged about the highly anticipated upcoming launch, expected to take place as early as this autumn. As the iPhone SE’s design stagnation finally comes to an end, Apple has opted to bring its flagship’s sleek aesthetic to this compact powerhouse, mirroring the iPhone 12 series’ modern look with a long-awaited refresh.
If reports prove accurate, I might scale back to the iPhone SE 4.
Rumors surrounding the forthcoming iPhone SE 4 have sparked significant interest among tech enthusiasts. Speculation suggests Apple might revamp the device’s design, potentially adopting a more modern aesthetic similar to the iPhone 14 series. Additionally, there are whispers about the inclusion of new features like a higher-resolution OLED display and improved camera capabilities. Other rumored enhancements include increased storage options, potentially up to 512GB, as well as enhanced water resistance.
The rumoured update for the iPhone SE 4 suggests it will feature a significant design change, potentially adopting a 6-inch OLED display similar to that of the iPhone 15 series. It’s further speculated that the device will operate with a 60Hz refresh rate, similar to the standard iPhone 15, whereas the Pro version allegedly features a higher 120Hz refresh rate. That is fairly anticipated although. Apple’s naming convention for its revolutionary display technology is no coincidence – it stands out as a testament to the company’s dedication to innovation and excellence in every aspect of their products.
The rumoured iPhone upgrade is expected to feature the A18 processor, previously tipped to make its debut in the forthcoming iPhone 16 and iPhone 16 Pro series due out later this year. The phone will also feature 6GB or 8GB of RAM, a relatively modest amount considering it’s an entry-level device. Can this ensure that the iPhone SE 4 will have access to all features Apple’s Intelligent Assistant has to offer once AI capabilities are rolled out in beta?
The rumored rear camera of the forthcoming iPhone SE 4 is expected to boast a significant upgrade with a 48-megapixel lens, marking the first time such a high-resolution sensor has been featured in an iPhone SE model. Will a single camera on the iPhone SE’s rear still be impressive?
The upcoming iPhone SE is expected to feature a sleek aluminum frame, mirroring the design aesthetic of other premium Apple devices. The titanium casing on my iPhone 15 Pro has been a game-changer, and I’m not convinced that switching to aluminum for the iPhone 16 or SE 4 would be a trivial decision.
iMore provides expert guidance and recommendations from our team of seasoned Apple specialists, drawing upon their extensive knowledge of the Apple ecosystem. Study extra with iMore!
As Apple’s annual product refresh cycle continues to evolve, it is logical that the latest iteration of the iPhone SE would adopt the more modern and universally compatible USB-C port, effectively phasing out the Lightning connector in its entirety by 2024. Apple’s decision to drop Contact ID in favour of Face ID signals another step towards a more streamlined experience, making the iPhone SE a compelling entry-level option for the company.
Greatest but? The value. The rumoured price tag for the upcoming iPhone SE 4 is expected to fall within a range of $499 to $549. If the budget-friendly option is under $500, the iPhone SE 4 could potentially dethrone the iPhone 16 as a top choice. Will we have to wait and see if the rumors prove accurate? Despite this uncertainty, I’m thrilled at the prospect of uncovering what innovations Apple has in store for its beleaguered flagship iPhone model. If the iPhone mini’s lackluster performance persists, the least Apple can do is transform the iPhone SE into a tantalizing reality for everyone.
Some helpful widgets available for the Pixel series include the Battery widget. Following the release of beta 4, the final beta iteration preceding the working system’s launch, a minor adjustment was introduced to the Pixel Battery widget. Before proceeding with the transformation, let’s clarify that the widget is available in a standardized format of 4 units wide by 2 units tall. The new, state-of-the-art model will be rolled out next month, providing an unparalleled level of security and stability.
Since our knowledge of the Pixel Battery widget is now comprehensive, let’s dive into its features and capabilities. It organizes your relevant modules alongside your Pixel in a clear and elevated manner. For Pixel Buds users, you’ll notice that each earbud and the carrying case displays its battery level individually. Prior to this, the battery indicators across the entire widget uniformed in a single color scheme. That may be complicated for Pixel customers quickly glancing at the widget. As a result, we made one minor yet crucial modification: it incorporated Dynamic Shade to the bar depicting the principal device listed within the widget, which can always be the user’s Pixel phone.
Google improves the Pixel Battery widget. | Picture credit-PhoneArena
The new Battery widget on the Pixel provides an intuitive representation of battery levels through a dynamic color-coded bar, accompanied by detailed statistics below. A Pixel user should always be able to gauge whether their battery will last through the next hour or two. Exterior-wise, the design of the widget appears unchanged from its predecessor, maintaining the same precise aesthetic as seen in the earlier model.
To place the Pixel Battery widget in your Pixel’s House Display screen, lengthy press the House Display screen and you will get a popup with three choices: Wallpaper & model, Widgets, and House settings. To add the Pixel Battery widget to your Home Screen: Scroll down to Widgets, then tap Battery; next, tap its icon; finally, press the “+” button. This action enables your Pixel to display battery information on your Home screen.
Stay connected with our daily and weekly newsletters, featuring the latest developments and exclusive insights on pioneering AI security solutions.
We’ve already explored how AI can aid in discovering patterns and uncovering relationships, leading us to naturally infer that a highly trained AI model could leverage prior knowledge of molecular structures to identify novel medications and accelerate treatments for some of the most challenging diseases and medical conditions.
One firm, based mainly in San Francisco, aims to revolutionize pharmaceutical research through its platform, BIOiSIM, which boasts an extensive knowledge lake comprising over 3 million compounds and 5,000 human and animal datasets, all powered by AI models trained on this rich trove of data. This allows researchers to identify, develop, and test new compounds nearly in advance of investing in actual clinical trials.
Last year, VeriSIM introduced a novel feature to its platform, focused on providing organic translation simulations – predictions of a drug’s actual efficacy in the human or animal body. Pharmaceutical researchers can leverage this information to determine not only which novel medications are experiencing price increases in real-time but also which species of animals to test them on effectively.
“We’re pleased to announce that we’ve made significant strides in reducing our reliance on animal testing,” said VeriSIM Life CEO and founder Dr. In an interview with VentureBeat several months ago, Jo Varshney spoke publicly. We can actually optimize these animal studies to eliminate the requirement for large cohorts of 50 animals or more. One might simply reexamine their medication data numerically and verify it more rigorously using computational methods.
Furthermore, this approach not only proves more compassionate towards animals but also yields cost-effective results for researchers, as they can avoid conducting tests on species whose biological makeup precludes a meaningful evaluation of the medication’s effectiveness.
For Varshney, a personal quest unfolds: her father’s involvement in the pharmaceutical industry is merely one aspect, as she has been fascinated by the field since childhood. According to VentureBeat, her interest was piqued from the tender age of two, and she began her career as a veterinarian before pursuing a PhD in genomics and computational sciences at the University of California, San Francisco.
“Prior to embarking on the corporate venture, I dedicated considerable time to machine learning, specifically exploring supervised and unsupervised approaches, and posing the question: ‘Given our existing understanding of medicine, biology, and chemistry, can we leverage this knowledge to make predictions for novel data, novel chemistries, or novel molecules?'”
So far, VeriSIM Life has successfully supported four customers in conducting clinical trials with their medication, as cited by Varshney.
The corporation has received investments from a diverse group of renowned venture capital firms, including Intel Capital, Village Global, SOSV (Susa Ventures), Stage One Ventures, Loup Ventures, and Twin Capital Partners.
The major challenge with current drug analysis and discovery: it is an expensive process with an unacceptably high failure rate.
The global pharmaceutical industry valued around $1.6 trillion, according to the latest market data from a leading research firm. However, a staggering 10-fold increase in R&D spending for new medications has been observed in the United States. The adjusted value of $1 alone in Nineteen Eighties, factoring in inflation, was based on the.
Despite a staggering 90% failure rate in medication testing, as reported by , the typical drug requires and undergoes a lengthy process taking approximately !
According to VeriSIM, its BIOiSIM platform is expected to streamline the process of transitioning from data analysis and growth to securing FDA approval for clinical trials, potentially shrinking the timeframe by approximately 2.5 years.
The AI-powered platform allegedly boasts a remarkable 82% increase in precision when simulating medication outcomes compared to traditional, non-AI approaches.
Beneath the surface of VeriSIM Life’s innovative offerings lies a complex interplay of cutting-edge technologies. The BIOiSIM platform leverages sophisticated computational methods, such as machine learning algorithms and advanced statistical models, to generate accurate and realistic digital representations of biological systems. This enables researchers to simulate complex biological processes in silico, reducing the need for costly and time-consuming wet-lab experiments.
VeriSIM Life’s BIOiSIM platform leverages cutting-edge technology, incorporating multiple AI models and datasets to drive innovation, as posited by Varshney.
“We leverage AI-powered machine learning strategies, including generative adversarial networks (GANs) and generative AI, to efficiently generate new molecules across an astonishingly vast area of 10^63 possibilities, subsequently distilling them down to the optimal molecular structure,” the CEO and founder told VentureBeat.
By leveraging cutting-edge technology, VeriSIM Life has developed a suite of digital replicas, including human subjects, as well as commonly used animal models such as dogs, rats, and pigs, that are regularly employed in pharmaceutical testing to evaluate the efficacy of novel drug candidates.
We integrated data from chemistry, physiology, and various animal models employed in testing, subsequently codifying this information, followed by consolidating patient-based ‘omics knowledge – including genomics, proteomics, and other relevant domains – to derive a comprehensive rating, known as the Translational Index. Impressed by one’s credit score rating.
The rating, a ranking between one and ten, with ten signifying the most effective and one indicating the least, allows pharmaceutical researchers to swiftly determine whether a drug warrants further investigation through clinical trials, while also crucially – selecting which animal models to use to achieve the desired outcomes.
Researchers seeking to validate a novel LDL cholesterol lowering medication might leverage VeriSIM Life’s BiOSIM AtlasGEN tool to identify optimal compounds, followed by the Translational Index to determine scores for the most suitable animal models and predict human performance, thereby providing a streamlined approach to focus their efforts for success?
“When efficacy is demonstrated in animal studies, but fails to translate to humans, the rating typically takes a hit,” said Varshney to VentureBeat.
According to VeriSIM’s website, BIOiSIM and AtlasGEN can simulate more than 800 billion unique scenarios collectively.
Varshney explained to VentureBeat that a team of laptop engineers and certified researchers continually updates the platform and designs animals to suit individual customer needs, tailoring the experience according to specific requirements.
“For instance, when we understand that a drug can be toxic within the liver, our specialists create detailed models of the liver to demonstrate how toxicity would vary between rats, dogs, and humans – this kind of nuance requires significant attention from our team.”
As for monetization, VeriSIM life reportedly takes a percentage of drug income generated on its platform, while also offering a subscription-based software-as-a-service pricing model, either annually or per project basis.
As part of a burgeoning wave of AI-powered healthcare applications and platforms.
AI’s increasing presence within the healthcare sector extends far beyond just drug discovery.
We have also implemented a system that provides personalized cancer screening recommendations to medical professionals based on patient profiles, suggesting tailored approaches for each individual. This comprehensive tool enables healthcare providers to offer precise guidance, streamlining the diagnostic process and improving treatment outcomes.
As VeriSIM strives to leave an indelible mark with its pioneering BIOiSIM platform and innovative Translational Index scores, it aims to revolutionize the pharmaceutical landscape by driving down costs, boosting trial success rates, and ultimately extending and enhancing human life globally.
Keep within the know! Staying informed has never been easier – receive the latest updates daily in your inbox.
Upon subscribing, you will be deemed to have consented to VentureBeat’s
Thanks for subscribing. What does “extra.” refer to?
Securing users’ sensitive data and personal information is a top priority for Android developers. Here’s the improved text: That’s why we invested time in designing a system that leverages a crowdsourced device-locating community to help you quickly locate misplaced or lost items, even when they’re offline and without connectivity. While scrutinizing the implications of device-finding services on individual privacy and security, we exercised prudence to mitigate any foreseeable risks.
As we grew, it was essential that our brand-new Discover My System prioritized safety by default and personalized experiences by design. We initiated the development of a confidential, community-driven device-finding platform by conducting a thorough stakeholder analysis and gathering input from privacy and advocacy organizations, ultimately shaping our approach to prioritize user concerns. Building on this foundation, we subsequently implemented multi-layered protections across three key domains: knowledge safeguard measures, safety-oriented defenses, and personal control mechanisms. This feature provides an additional layer of security for Discover My System users.
The Discover My System community locates devices by leveraging Bluetooth proximity data from nearby Android devices. What’s the worst that could happen? You’re enjoying a leisurely dinner at your favorite restaurant when suddenly, in a split second of distraction, your keys slip from your grasp and clatter to the floor. Panic sets in as you frantically scan the bustling dining area, desperate to spot the glinting metal before it disappears forever beneath the tables and chairs. Although the keys lack inherent location capabilities, they can still be equipped with a Bluetooth tag for potential tracking purposes. Close Android devices participating in the Find My network collectively share the location of the Bluetooth device. Upon discovering they’ve misplaced their keys, the owner can log into the Discover My System mobile application and utilize nearby Android devices’ contributions to locate their missing keys.
Let’s explore the intricacies of the comprehensive security measures governing the Discover My System ecosystem.
To ensure the privacy of all participants in our community and the crowdsourced location data that drives it, we have implemented robust safeguards.
When Android devices participating in the community report the location of a Bluetooth-tagged item, this information is transmitted securely via end-to-end encryption, using a unique key accessible only to the tag owner and anyone authorized through the Find My System app. Only the Bluetooth tag owner and those authorized by them can access and view the tag’s location data. With end-to-end encryption of location information, Google is unable to decrypt, view, or utilize the location data in any way.
Contributions to the Discover My System community from these end-to-end encrypted locations are anonymous, preventing Google from determining the owners of nearby Android devices that provide location data. When the Discover My System community shares the location and timestamp of a Bluetooth-tagged item with its owner to help them locate their property, it only provides this specific data without revealing any additional information about nearby Android devices that contributed to the discovery.
. Steadily overwritten minimal buffering occurs for end-to-end encrypted location knowledge. As part of its functionality, the community can also aid in discovering a Bluetooth tag using the owner’s nearby devices, such as if their own phone detects the tag; in this case, the community will disregard crowdsourced data for the tag.
The Discover My System community safeguards against threats such as the unauthorized use of an unknown Bluetooth device to track or locate someone, including:
This innovative security feature renders covert surveillance of personal spaces, such as one’s private residence, increasingly challenging. In standard operation, the Discover My System community relies on a cluster of nearby Android devices to initially detect and subsequently report a tag’s location to its owner. The study found that the Discover My System community is particularly effective in public areas such as coffee shops and terminals, where numerous devices are likely to be present nearby? As the community implements aggregation prior to revealing a tag’s location to its owner, it can harness the power of over a billion Android devices potentially participating, thereby unlocking significant value. This innovation enables homeowners to locate misplaced devices more efficiently in densely populated areas, while ensuring robust security measures protect private spaces from unwanted surveillance. In less crowded regions, utilizing final recognized locations and dependable methods ensures finding objects with ease.
When someone opts out of sharing their home address on their Google account, their Android device is programmed to refrain from contributing to the community-driven location sharing feature known as “Find My Device” whenever it’s in proximity to their residence. This implementation provides enhanced security safeguards over data aggregation by default, thereby preventing unwanted surveillance near private locations.
The Discover My System community constrains the range of situations where a nearby Android device can submit a location report for a specific Bluetooth tag. The community also imposes limits on the frequency at which the owner of a Bluetooth tag can request an updated location for the tag. Objects misplaced during movement are often found to linger in fixed locations. While sipping your morning espresso at the café, you inadvertently misplace your keys, which remain on the desk where you left them. As a growing concern, cybercriminals are increasingly attempting to infiltrate individuals’ lives by engaging in real-time surveillance. While leveraging fee limiting and throttling to regulate updates, the community remains functional in helping users locate misplaced items, such as delayed luggage during travel, while minimizing the risks associated with real-time monitoring.
Can the Discover My System community comply with the requirements for undesirable monitoring? Customers using Android or iOS devices will receive notifications on their phone when an on-device algorithm detects someone may be tracking them without consent through a compatible Find My system tag, implying compliance with the combination model.
Android users always maintain complete control over which devices join the Find My Device community and how they participate. Customers have the autonomy to stick with the default settings, participate in collective location reporting for a comprehensive view, opt out of sharing individual locations, or choose to disconnect entirely. Discover My System also provides the flexibility to
With careful consideration for safety, the innovative Discover My System community has successfully completed internal testing within an Android-based development group. The Discover My System community is now integrated with the Google Play Protect system to leverage Android’s vast global network of security researchers and experts. We’re also partnering with select researchers through our private grant program to foster more targeted research.
By integrating these comprehensive personal protection measures, the system effectively reduces the risk of privacy and security breaches, allowing users to efficiently locate and recover lost devices.
As malicious actors continually seek innovative ways to exploit unsuspecting consumers, our mission to safeguard Android users from harm remains an ongoing imperative. We are committed to continuously improving the protection of individuals on our system, prioritizing their safety above all else.
To learn more about Discover My System on your Android device, simply visit our website. You can learn the Discover My System Community accent specification.
As organizations evolve, they’ve developed separate, cloud-hosted knowledge repositories, often operating independently of one another. A pressing challenge lies in facilitating seamless cross-organizational discovery and access to knowledge across numerous knowledge lakes, each grounded in distinct skill sets. Organizations can utilize Information Mesh’s domain-oriented approach to decentralized knowledge possession and structure by addressing these four key ideas: treating knowledge as a product, offering self-serve knowledge infrastructure as a platform, implementing federated governance, and creating domain-specific frameworks that enable efficient knowledge sharing and collaboration.
In 2019, the company forged a strategic alliance to co-create the Digital Manufacturing Platform (DMP), designed to enhance manufacturing and logistics efficiency by 30% while reducing production costs by an equal percentage. The Data Processing Platform (DPP) was designed to facilitate seamless access to knowledge from shop-floor units and manufacturing processes by addressing integration complexities and providing standardized connections. Notwithstanding advancements in the platform’s functions, a significant challenge arose: sharing knowledge across multiple remote knowledge lakes stored in separate AWS accounts without having to consolidate data into a central repository? One other issue is identifying accessible knowledge saved across various knowledge lakes and facilitating a workflow to request data entry throughout enterprise domains within each plant. The current methodology relies heavily on manual processes, utilizing emails and basic communication, which not only increases overhead but also varies from one use case to another in terms of data governance. This blog post introduces and explores how VW utilized it to build their knowledge mesh, enabling streamlined data entry across multiple knowledge lakes. It prioritizes the key advantage, allowing knowledge providers to seamlessly publish knowledge assets directly to Amazon DataZone, thereby establishing a central knowledge hub for improved discoverability and accessibility. Furthermore, the publication provides code snippets that convey information through practical implementation.
Introduction to Amazon DataZone
As a cloud-based metadata management platform, our solution simplifies the process of discovering, organizing, sharing, and governing data stored across Amazon Web Services (AWS), on-premises infrastructure, and third-party sources. Amazon DataZone’s core features include a comprehensive enterprise knowledge catalog that enables users to search for existing knowledge, request access, and start working on data in days rather than weeks, fostering rapid insights and informed decision-making. The Amazon DataZone portal further features a personalized analytics expertise for knowledge assets through both a web-based application and API. Amazon DataZone streamlines knowledge sharing, providing users with accurate information tailored to their specific needs and goals through a governed process.
What are the key components of a well-designed information administration framework that integrates seamlessly with Amazon DataZone?
1. Governance: Establish clear policies and procedures to ensure data security, compliance, and integrity within the organization.
2. Discovery: Implement automated data discovery capabilities using Amazon SageMaker and Amazon Glue to identify, classify, and catalog data assets across the enterprise.
3. Profiling: Utilize Amazon Comprehend and Amazon Rekognition to create detailed profiles of your data, including metadata, schema, and semantic meaning.
4. Stewardship: Assign ownership and accountability for each data asset, ensuring that data is properly managed, maintained, and updated.
5. Integration: Leverage Amazon DataZone’s integration capabilities to connect with various systems, applications, and data sources, enabling seamless data exchange and processing.
6. Analytics: Utilize Amazon SageMaker, Amazon QuickSight, and other analytics services to analyze and gain insights from your data, driving business value and decision-making.
7. Security: Implement robust security controls, including access control lists (ACLs), encryption, and authentication mechanisms, to safeguard sensitive data and ensure compliance with regulatory requirements.
8. Auditing: Maintain a comprehensive audit trail using Amazon CloudWatch and Amazon S3 bucket logging to monitor data activity, detect potential issues, and address any compliance concerns.
9. Reporting: Generate detailed reports on data usage, access, and compliance status using Amazon QuickSight and Amazon SageMaker, enabling data-driven decision-making and risk mitigation.
10. Compliance: Ensure that your information administration framework complies with relevant regulations, such as GDPR, HIPAA, and CCPA, by implementing controls and monitoring mechanisms to track data handling and processing.
The data zone enables seamless integration with various data sources and provides a unified data catalog. It supports the discovery of data assets within your organization, allowing for effective collaboration across teams. Additionally, the data zone integrates with various data processing services like Amazon SageMaker, making it an ideal choice for machine learning workflows.
The structural diagram (Determine 1) illustrates a high-level design framework, grounded in the principles of the information mesh sample. The framework distinguishes between supply chain mechanisms, knowledge area creators (publishers of intellectual property), knowledge area users (consumers of information), and centralized management to highlight crucial aspects. This cross-account knowledge mesh aims to establish a scalable foundation for knowledge platforms, ensuring seamless collaboration between producers and consumers through robust governance mechanisms?
A knowledge-area producer is situated within an AWS account, leveraging Amazon S3 buckets to store both raw and processed data. Producers integrate knowledge into their Amazon Simple Storage Service (S3) buckets through various pipeline processes they manage, in addition to utilizing personal and functional approaches. Data owners are accountable for the entire lifecycle of the data, from initial collection to a format suitable for external utilization.
A knowledge area producer leverages a bespoke Extract, Transform, Load (ETL) framework, incorporating tools like to process data, utilize data profiling techniques to prepare the information asset (knowledge product), and subsequently catalog it within their designated .
That a knowledge area producer prepares and stores the information asset on a desktop using AWS S3 copy?
Producers of information areas leverage a designated datasource to run processes in Amazon’s DataZone, all managed seamlessly within their Central Governance account. The process effectively standardizes and deploys technical metadata across the entire organization’s knowledge catalog for each knowledge asset. Enterprise metadata can be seamlessly integrated by customers to provide contextual richness, relevant tags, and meaningful knowledge classification for their respective datasets. Producers’ management wants to share its approach, ensuring a seamless collaboration between the team’s lengthy processes and the way customers interact with them.
Producers can catalog entries with AWS Glue from all their Amazon S3 buckets. The central governance account securely disseminates datasets to producers and customers via metadata linking, operating without any inherent understanding beyond the occasional log entry. Ownership of information remains with the creator.
As Amazon DataZone enables seamless sharing, once knowledge is cataloged and published to the DataZone space, it can be easily disseminated to multiple client accounts.
The Amazon DataZone Information Portal provides a customized interface for customers to discover, search, and initiate requests for subscribing to valuable knowledge assets via an online platform. The information area producer receives notifications of subscription requests within the Information Portal and exercises discretion in approving or rejecting these requests accordingly.
As soon as accredited, the patron account can unlock courses teaching various analytics and machine learning concepts, enabling them to apply their newfound knowledge in diverse scenarios.
What are the primary goals and objectives of creating a Handbook course for publishing knowledge belonging to Amazon DataZone?
Developing a comprehensive course on publishing knowledge in Amazon DataZone requires considering the following key aspects:
1. **Defining the scope**: Clearly outline the purpose, target audience, and expected outcomes for the handbook. 2. **Establishing credibility**: Demonstrate expertise and authority in the field of data analytics and publishing through real-world examples or case studies. 3. **Organizing content**: Structure the course into logical modules or sections, focusing on practical applications, best practices, and innovative approaches to sharing knowledge. 4. **Creating engaging materials**: Use visual aids, interactive elements, and storytelling techniques to make complex concepts more accessible and memorable. 5. **Providing hands-on exercises**: Offer practical activities, quizzes, or challenges that allow learners to apply new skills and reinforce understanding. 6. **Incorporating feedback mechanisms**: Encourage participant engagement through discussion forums, surveys, or peer review processes to ensure continuous improvement and refinement of the course.
By addressing these essential elements, the Handbook course will effectively empower Amazon DataZone users with the knowledge and skills necessary to successfully publish their findings and share insights with others.
To successfully publish an information asset from a producer’s account, each asset must first be registered within Amazon DataZone as a viable source of information, making it available for client subscription and utilization. The guide provides comprehensive instructions on how to achieve this goal. In the absence of an automated registration process, all necessary tasks must be performed manually for each knowledge asset.
Can you use AWS Glue’s built-in support for data sharing by configuring a data share in your producer account and then connecting it to Amazon DataZone?
By leveraging the automated registration workflow, the step-by-step guide process can be streamlined and executed seamlessly for any new knowledge asset requiring printing, as well as for existing assets necessitating updates due to changes in their schema.
Streamline AWS Glue table publication to Amazon DataZone by condensing the step-by-step process.
The following structure outlines a framework for automating the publication of knowledge assets:
**Publishing Process**
1. **Validation**: Automated checks ensure that the knowledge asset meets specific criteria (e.g., completeness, relevance).
2. **Approval**: The knowledge asset is routed to relevant stakeholders for review and approval.
3. **Categorization**: The knowledge asset is categorized based on its content, format, or target audience.
4. **Tagging**: Relevant tags are assigned to the knowledge asset for easier discovery.
5. **Metadata Generation**: Automatically generated metadata (e.g., title, summary, keywords) aids searchability and discoverability.
6. **Quality Control**: A quality control check verifies that the published knowledge asset meets desired standards (e.g., formatting, consistency).
7. **Publication**: The validated, approved, categorized, tagged, and metadata-generated knowledge asset is published on a designated platform or repository.
8. **Maintenance**: Scheduled updates and maintenance ensure the knowledge asset remains relevant and accurate over time.
**Key Components**
1. **Knowledge Asset Types**: Define the types of knowledge assets to be published (e.g., articles, whitepapers, case studies).
2. **Validation Rules**: Establish specific criteria for validating knowledge assets (e.g., completeness, relevance).
3. **Approval Hierarchy**: Determine the approval process and hierarchy for knowledge assets.
4. **Categorization Framework**: Develop a framework for categorizing knowledge assets based on content, format, or target audience.
5. **Tagging Guidelines**: Establish guidelines for assigning relevant tags to knowledge assets.
7. **Quality Control Standards**: Define desired standards for published knowledge assets (e.g., formatting, consistency).
Can structured data be used effectively in Amazon DataZone?
In Producer Account B, relevant data is stored within an Amazon S3 bucket. An AWS Glue crawler is configured for the dataset to automatically create the schema using.
As soon as configured, the AWS Glue crawler promptly crawls the specified Amazon S3 bucket and seamlessly updates the associated metadata. When the AWS Glue crawler successfully completes a job, a specific event is triggered and published to the default Amazon EventBridge bus.
When an EventBridge rule is set up to recognize this occurrence, it triggers a dataset-registration operation.
AWS Lambda executes a series of automated steps to register and publish datasets in Amazon DataZone seamlessly.
AWS Lambda function operates to retrieve AWS Glue databases and Amazon S3 data for a dataset, triggered by an event-driven execution of the AWS Glue crawler following a profitable run.
The code assumes the role of an Identity and Access Management (IAM) user in a central governance account, leveraging the account’s credentials to retrieve the Producer account ID, as well as the Amazon DataZone area ID and Challenge ID.
The AWS DataZone Datalake blueprint is enabled within the producer account.
It checks if the . Unless a deliberate decision to the contrary is made, the absence of atmospheric conditions prompts the activation of the atmosphere creation process. If the atmosphere does indeed exist, it will then proceed to the next logical step.
The process successfully registers the Amazon S3 location of the dataset in Lake Formation, ensuring seamless integration within the producer account.
During the Amazon DataZone challenge, the operation generates a comprehensive data supply and visually depicts its successful creation.
The final step ensures that the data supply synchronization job within Amazon DataZone is initiated as needed. When new AWS Glue tables or metadata are created or updated, the information supply sync job is triggered.
Conditions
As part of this response, you’ll publish knowledge assets from a current AWS Glue database in a producer account into an Amazon DataZone region, provided that the following prerequisites must be met:
Deploy?
One AWS account serves as the information repository’s producer account (Account B), housing an AWS Glue dataset to be shared.
The secondary AWS account serves as a centralized governance hub (Account A), where an Amazon DataZone area and challenge can be effectively deployed. The Amazon DataZone account – that’s the hub for data discovery and collaboration within your organization.
Each of the AWS accounts belongs to the same owner.
From the tables for which Amazon DataZone manages permissions effectively.
In every AWS account, verify that the box is unchecked for Default permissions for newly created databases and tables under the Information Catalog settings within Lake Formation.
Can you confirm default permissions are cleared by running `ALTER DEFAULT PERMISSIONS REVOKE ALL ON` and then re-apply the desired permissions to ensure secure data access?
Check into Account A (central governance account), ensuring you have the necessary credentials.
If your Amazon DataZone area is already encrypted using a key, follow these steps to add Account B (the producer account):
{ "Sid": "Permit use of the important thing", "Impact": "Permit", "Principal": { "AWS": "arn:aws:iam::<Account B>:root" }, "Motion": [ "kms:Encrypt", "kms:Decrypt", "kms:ReEncrypt*", "kms:GenerateDataKey*", "kms:DescribeKey" ], "Useful resource": "*" }
The guarantee lies in creating a specific role for Account B, producer account, which assumes the designated Identity and Access Management (IAM) role. The role should possess the following authorizations:
This Identity and Access Management (IAM) position is known as a crucial role within an organization’s security posture. dz-assumable-env-dataset-registration-role on this instance. With this role, you will have the flexibility to manage your workflow effectively and streamline your daily tasks. dataset-registration Lambda operate. Exchange the account-region, account id, and DataZonekmsKey Within the specified scope of this project, utilizing my available information and resources. The provided values determine the location where your Amazon DataZone area is established and the AWS KMS key employed to securely encrypt this sensitive data.
The following AWS account has been added to the belief relationship for this position, aligning with the next belief relationship in the organizational hierarchy. Exchange ProducerAccountId With the AWS account ID from Account B (the knowledge area producer’s account).
The necessary instruments for deploying an answer using AWS CDK are sought.
Deployment Steps
Deploying the AWS CDK stack enables automatic registration of knowledge assets in the DataZone area after completing the prerequisites.
Clone the repository from GitHub to your preferred Integrated Development Environment (IDE) by following these steps:
git clone https://github.com/aws-samples/automate-and-simplify-aws-glue-data-asset-publish-to-amazon-datazone.git cd automate-and-simplify-aws-glue-data-asset-publish-to-amazon-datazone
Based on the repository folder, execute the following commands to build and deploy source code to Amazon Web Services (AWS).
Log into AWS account B using the AWS CLI with your designated profile name.
Guarantee you’ve got .
The CDK atmosphere with instructions based on the repository folder exists. Exchange <PROFILE_NAME> With the profile title of your deployment account Account B. Bootstrapping is typically a one-time process and should not be repeated if an AWS account is already configured with the necessary resources.
export AWS_PROFILE=<PROFILE_NAME> npm run cdk bootstrap
Exchange the placeholder parameters (marked with the suffix _PLACEHOLDER) within the file config/DataZoneConfig.ts (Determine 4).
What’s Behind the Curtain: Unlocking Insights in Your Amazon DataZone? who is the best player to have ever played in the nba?
The AWS account identifier and region.
The assumed IAM position, as per the stipulated guidelines.
The deployment position beginning with cfn-xxxxxx-cdk-exec-role-.
Edit the `DataZoneConfig.json` file carefully to ensure that your DataZone is properly configured for use.
From within the AWS Lake Formation console’s navigation pane, select “Determine 5” to access IAM settings crucial for AWS CDK deployment initialization. cfn-xxxxxx-cdk-exec-role- As a result, I am designated as an Administrator for Information Lake Directors. The IAM role requires permissions to create sources within Lake Formation, granting privileges analogous to those of an AWS Glue database. Without explicit grants of these permissions, the AWS CDK stack deployment will inevitably fail.
Can you add cfn-xxxxxx-cdk-exec-role to the Information Lake administrators?
cdk deploy?
Throughout deployment, enter y If you wish to deploy adjustments for specific stacks as soon as possible? Do you want to deploy these adjustments (y/n)?
After a successful deployment, sign in to your AWS Account B (Producer Account) and verify that the newly provisioned infrastructure is correctly set up. You need to see a list of deployed CloudFormation stacks as demonstrated in Section 6.
Determine 6: Deployed CloudFormation stacks
What benefits does automated knowledge registration bring to Amazon DataZone?
We employ the dataset as a template to showcase the automated knowledge registration process.
Data unavailable, please provide the file.
Log in to the producer account’s AWS account and access the Amazon S3 dashboard, locating the DataZone-test-datasource The S3 bucket was configured to securely store sensitive data. A CSV file titled Determine_7 was uploaded to this designated storage location.
The analysis of seven datasets for determining the impact on business performance requires a comprehensive approach.
The AWS Glue crawler is configured to execute on a daily schedule, running at the same specified hour each day. To test the crawler manually, navigate to the AWS Glue console, then select the desired option from the navigation menu. The on-demand crawler is initiated seamlessly. DataZone-. After the crawler has executed, verify that a novel workspace has been established.
Navigate to the Amazon DataZone console within your central governance AWS account A, where the data sources were initially deployed. Select within the Navigation Pane the option labeled Determine 8.
Determine 8: Amazon DataZone domains
Upon opening the Datazone Area, users will have access to the Amazon Datazone knowledge portal URL, located in the Determine 9 section. Choose and .
What are the URLs of Amazon’s DataZone knowledge portal?
Discovering Your Strengths and Weaknesses Select the tab at the top of the window.
What drives innovation in data management?
What innovative discoveries await us in this uncharted territory? We are about to uncover a treasure trove of fresh insights as we venture into the newly created knowledge supply.
Determine what valuable insights and trends can be gleaned from information sources within the Amazon DataZone area of the Amazon Web Services (AWS) portal.
The information supply has been efficiently confirmed as printed.
What drives the determination of 12? The revealed knowledge portion highlights various information sources.
Once the information sources have been printed. The info producer can . Once approved, customers can seamlessly access and utilize the available information through Determine 13, which effectively showcases knowledge discovery within the Amazon DataZone knowledge portal.
What insights can you uncover by analyzing instance data within the Amazon DataZone? Explore how to leverage instance knowledge discovery and unlock hidden patterns in your dataset.
Clear up
Utilize the subsequent procedures to sanitize the resources leveraged through the Cloud Development Kit (CDK).
Delete all data from the two S3 buckets created in conjunction with this rollout to ensure a clean slate for future operations.
What datasets reside in the Amazon DataZone challenge? dataset-registration Lambda operate.
rm -rf *
npm run cdk destroy --all
Conclusion
Organizations can streamline their data governance by leveraging the power of AWS Glue and Amazon DataZone, thereby enabling seamless sharing and collaboration among teams. By mechanically sending AWS Glue insights to Amazon DataZone, organizations can simplify the process while simultaneously ensuring data consistency, security, and governance. Standardize and integrate publishing assets within Amazon DataZone. To streamline your team’s access to shared knowledge and insights using Amazon DataZone, mobilize your AWS professionals promptly.
In regards to the Authors
Serves as a Senior Information Architect at Amazon Internet Services, excelling in the fields of data analysis and knowledge management. She crafts innovative, event-driven knowledge frameworks to empower clients in the effective management of information and informed decision-making processes. With her expertise, she empowers clients in navigating their knowledge management transformation to the cloud effectively.
Serving as a seasoned DevOps Architect at AWS, he leverages his expertise to craft tailored solutions that address the complex needs of clients operating within the automotive sector. He’s passionate about designing robust infrastructures, leveraging automation and data-driven insights to ensure a seamless cloud experience for customers. He prefers to balance his leisure time by pursuing personal interests in studying, acting, language acquisition, and traveling.
Serving as a Senior Options Architect at Amazon Web Services (AWS), he excels in steering automotive companies through their digital transformation initiatives by leveraging the power of the cloud. With expertise in crafting robust platforms and products, she advises organisations on refining their architecture and making informed decisions that drive successful design outcomes. When she’s not busy with other commitments, she relishes exploring new places, delving into intellectual pursuits, and honing her yoga skills through regular practice.
Are skilled providers of Amazon Web Services? She assists clients in designing data-driven applications within Amazon Web Services (AWS).
As globalization and digitization continue to intertwine, the world has become increasingly interconnected, rendering the promise of AI a global phenomenon; in turn, its associated risks are also universal. Cybersecurity is a vital cornerstone for financial stability and development, extending its reach across borders and encompassing every aspect of our global community. Yet, a stark reality emerges: a mere 3% of international organizations possess the necessary expertise to effectively mitigate modern threats across the entire cybersecurity spectrum. Last year, there was a staggering 3,000-plus publicly disclosed data breaches, affecting corporations, households, public services, and more, serving as a stark reminder of the alarming state of cybersecurity awareness.
The yawning chasm in global cybersecurity preparedness poses a profound threat to the entire digital landscape, underscoring the imperative need for collective action to fortify our connected defenses against this existential peril. As we seamlessly integrate cybersecurity into global digital frameworks and cultivate a robust cybersecurity talent pool, the potential of AI will be harnessed to guarantee no one is marginalized from its benefits. As Africa prepares for a profound digital metamorphosis, nowhere is the imperative for cyber resilience more glaringly apparent.
Knowledge has proven itself to be a potent driver of economic growth in Africa, where GDP has skyrocketed more than fivefold over the past two decades? The rapid proliferation of technological advancements is driven by increased online usage, mobile banking, and artificial intelligence-powered innovations that span a wide range of applications, from forecasting climate changes to enhancing maternal healthcare outcomes? Africa’s economic growth trajectory is expected to propel its GDP to exceed $4 trillion by 2027, as continued development takes hold. Despite the reality, however, it is a stark truth that nearly 60 percent of Africans remain disconnected from the global economy, with many developments being out of reach for most.
As nations and entities worldwide embark on the arduous path toward bolstering their cyber resilience, collaboration becomes the cornerstone of this endeavour, with Africa at the forefront of this global quest? As we connect with over a billion individuals worldwide, we urge governments, corporations, and civil organizations to engage with the findings presented in the report “_____” by the Entry Partnership and the Centre for Human Rights at the University of Pretoria.
Throughout the second quarter of 2023, Africa experienced its highest incidence of common cyberattacks per week, representing a 23% surge compared to the same period in 2022.
In 2023, statistics revealed that malicious actors leveraged malware in a staggering four out of every five successful attacks on corporate entities, while approximately half of all reported security breaches involved sophisticated social engineering tactics.
Despite progress, a paltry 28% of African countries have ratified the Malabo Conference’s cybersecurity protocol, underscoring the continent’s ongoing struggle to safeguard its digital landscape. Integrating existing frameworks and standardising risk-driven methodologies would significantly boost the potency of cybersecurity strategies.
In various regions across Africa where data protection regulations are limited or non-existent, applied sciences such as encryption and cryptography take on a crucial role in safeguarding sensitive information?
Cloud computing, by allowing for the consolidation of cybersecurity controls across functions and networks, offers significant advantages in terms of scalability for restricted resources.
Can a digital divide that separates over 700 million Africans from the global online community continue to hold back the continent’s enormous potential? It’s not enough to simply participate; meaningful engagement requires a deeper commitment. We should additionally shield. By seamlessly integrating human ingenuity with cutting-edge AI and robust cybersecurity solutions, we can confidently shift the balance in favour of those safeguarding our digital realms, ultimately creating a future where technology and infrastructure are naturally secure. To seize this opportunity, let us also invest in people.
Across Africa, a shared entrepreneurial fervor drives innovation, and similarly, there is a pressing need to strengthen cybersecurity across the diverse economies of this vast continent. The emergence of a cutting-edge cybersecurity expertise enables the development of sophisticated tools for identifying cybercriminal methods, tracing perpetrator activities, and designing proactive safeguards to significantly enhance the reliability and security of our digital defenses. By leveraging the vast reservoir of underutilized talent across Africa, it is possible to cultivate a diverse and inclusive workforce that harmoniously combines technical proficiency with creative problem-solving aptitudes.
Can a paradigm shift in African cybersecurity spark a domino effect of innovation and resilience? It’s not just about job creation; it’s about unlocking pathways to meaningful, long-term careers that offer vital opportunities for economic growth while empowering individuals to stay and thrive within their communities. It is imperative that we prioritize empowering and supporting African girls, as they experience profound digital divide and subsequent marginalization within the digital economy, necessitating urgent intervention to bridge these inequalities. As of 2021, only 9% of cybersecurity professionals on the continent are women, a stark contrast to the global average of 25%. This underscores the pressing need to create and nurture inclusive development opportunities.
Recently, I had the privilege of amplifying Cisco’s commitment to Africa on a grand scale through the launch of our. It is an esteemed honor to witness the entire Cisco Networking Academy in Africa achieve this remarkable milestone – empowering 1.5 million learners across the continent, including over 460,000 girls, and striving to educate three million more. Skilling is a vital component of digital transformation, serving as a gateway to meaningful participation.
Across this endeavour, I have consistently found that one truth echoes through my discussions with African leaders and communities: cybersecurity is no longer a discretionary indulgence but rather a fundamental prerequisite for a stable and thriving economy. It protects our most valued assets: our knowledge, privacy, and way of life, thereby enabling us to innovate and thrive without the constant threat of cyber attacks looming over us. As we navigate our path forward and support clients, communities, and global entities in doing so – digital resilience is vital for comprehensive participation in the global economy, being an essential cornerstone of an inclusive future for everyone?
In the scientific community, the Fourier transform has far-reaching applications and is ubiquitous across various disciplines. When converting knowledge between formats, the goal is typically to maintain the integrity of the information, ensuring that no vital details are lost in the process – as long as it’s done correctly, that is. If you apply torchWith just one step to go. torch_fft_fft() goes a technique, torch_fft_ifft() the opposite. To those who are resourceful, understanding the correct approach to analyzing results is essential. I’m here to help, let’s get started. We start by examining an instance of an operation’s name, followed by a circular exploration of its output, before attempting to grasp the underlying mechanics at play.
Understanding the output of torch_fft_fft()
As we prioritize precision, our analysis commences with the most fundamental instance signal: a pure cosine function that completes a single rotation across its entire sampling duration.
A signal with a cosine component of frequency 1 Hz.
The optimal approach to setting up issues involves dividing them into 64 distinct samples. As a result, the corresponding sampling interval is equivalent to N = 64. The content material of frequency()The beneath helper operates used to assemble the signs, demonstrating how we signify the cosine values. Particularly:
The value of progress over time or area is measured by a cosine function, which is periodic with an interval. Therefore, if we want the function to repeat its initial state after sixty-four samples, then the phase, denoted as, must be equal to. We will regain our initial momentum and revisit the starting point once again.
We need to quickly confirm whether this system performed its intended function.
Cosine function that completes a single full cycle of 360 degrees over the duration of 64 samples.
Now that we’ve acquired the enter key, torch_fft_fft() Calculates the Fourier coefficients, determining the relative importance of diverse frequency components present in the signal. The diversity of frequencies considered is equivalent to the number of sampling rates; therefore, it will be of a size equivalent to sixty-four as well.
In this case, you’ll find that the magnitude of the second half of coefficients is identical to the first. It is a fact that this holds true for every real-valued sign. When determining the ideal candidate for a particular role, you can name specific qualities and characteristics that align with the job requirements. torch_fft_rfft() To obtain nicer, i.e., shorter, vectors to operate with. Right here, however, I want to clarify the overarching context, as it’s where most discussions on this topic actually unfold.)
Although the sign is actual, the Fourier coefficients remain complex numbers. Four methodologies exist for evaluating these entities. The primary objective is to extract the precise midpoint.
At this level, it’s axiomatic that there exists a sole frequency current within the sign; namely, that at 0. This alignment precisely matches our design: namely, a solitary rotation encompassing the entire sampling period.
Since each coefficient may potentially possess both non-zero real and imaginary parts, it is typically more informative to present the modulus or magnitude of the coefficient, which is calculated as the square root of the sum of its squared real and imaginary components. Magnetic field strength (expressed as the root of the sum of squared actual and imaginary components).
Notably, these values mirror their corresponding actual components with precision.
Finally, we consider the section that highlights the feasible adjustment of the sign, where a pure cosine remains unchanged. In torch, we’ve got torch_angle() complementing torch_abs()However, we must consider the potential impact of rounding errors on our calculations. In every scenario, the true and imaginary components are theoretically zero; yet, due to the limitations of floating-point representation on computers, these values typically deviate from exact zeros. The substitutes will be extremely compact. When calculating angles involving “pretend non-zeroes”, a simple division operation between two of them can lead to enormous values emerging. To prevent this issue, we incorporate a customised solution that rounds each input value before performing the division operation.
As expected, there is no part shift evident within the sign.
Let’s visualize what we discovered.
Actual components: [1], imaginary components: [0], magnitudes: [√2/2], phases: [π/2]. The imaginary components of any complex number in addition to its phase are all zero.
There is no need to harbour any reservations about the fact that torch_fft_fft() has executed. Without the complexity of a non-sinusoidal signal, we can accurately grasp what’s happening by calculating the Discrete Fourier Transform (DFT) manually. This exercise will significantly benefit us in the long run when we’re crafting our code.
Reconstructing the magic
One caveat about this part. As a renowned authority on the Fourier Reboot, addressing an audience that spans the spectrum of mathematical and scientific education, my likelihood of meeting your expectations, dear reader, is virtually nil. Despite everything, I’m willing to give it a try. If you’re a professional in this field, you’ll likely be quickly scanning the text, looking for instances of torch code. If you’re reasonably conversant with Discrete Fourier Transform (DFT), a refresher on its inner mechanisms is likely welcome. And, most importantly, for those just beginning to explore this subject, take away at least one insight: that what initially appears as one of humanity’s greatest enigmas – assuming there is an equivalent in our universe – can be understood, yet it neither relies on magic nor is exclusive to the initiated.
A mathematical technique that decomposes signals into their constituent frequencies and amplitudes. Within the context of the DFT – the discrete Fourier transform – where time and frequency representations exist as finite vectors rather than features, the novel framework appears thus:
Here, as earlier, is the range of samples (64, in our case), indicating that there exist fundamental vectors. With working based on premise vectors, these are typically formulated:
{#eq-dft-1}
The route, like a winding river, stretches from sunrise to sunset. To understand the role of these foundation vectors, consider temporarily reducing the sampling interval to gain insight into their behavior. If we successfully accomplish this, we will have four foundational vector components: one, two, three, and four. What are you referring to?
The second, like so:
That is the third:
And eventually, the fourth:
We categorize these four foundational vectors based on their velocity – the rate at which they traverse the unit circle. To achieve this, one simply examines the rightmost column vectors, where the final calculation results are displayed. Values within that column align with distinct positions pinpointed by the revolving foundation vector across various closing dates. By examining a solitary “replacement point”, we observe the rapid shift of the vector over a single time-step.
Wishing to examine this matter closely, we find that there is no transfer involved whatsoever? Circles within circles unfold, transitioning seamlessly from one phase to the next, with no discernible beginning or end. That’s one revolution in four steps, or a step measurement of 90 degrees. The orbiting satellite then increases its speed by a factor of two, traversing a greater distance as it revolves around the circular trajectory. That’s a significant milestone, as it effectively wraps up two complete turns. Lasting several minutes, it accomplishes three complete rotations, measuring progress in increments of .
What allows these foundation vectors to be particularly valuable is their mutual orthogonality. As vectors that are orthogonal to each other, their dot product is zero?
{#eq-dft-2}
Let’s compare different types of fruit: apples and oranges. Indeed, the dot product between these two vectors equals zero.
Here is the rewritten text in a different style:
The orthogonal structure of the Fourier basis significantly streamlines the computation of the Discrete Fourier Transform (DFT). Were you able to identify the parallelism between those fundamental vectors and the method used for annotating instances? Right here it’s once more:
When handling premise vectors, we can signify this operation by having the interior product between the operation and each basis vector equal to either zero (the default) or one if the operation has an element matching the corresponding premise vector. Fortunately, sines and cosines can be effortlessly converted into more sophisticated exponential functions. In our instance, that’s how things go.
Right away, two key outcomes emerge from Euler’s system. The first reveals the fundamental nature of the Fourier coefficients, which are periodic in their behavior, with frequencies repeating every 64 units, where -1 equals 63, -2 equals 62, and so on.
The Fourier coefficient is acquired through the process of projecting the signal onto a foundation vector.
Since the premise vectors are orthogonal, only one coefficient will be non-zero: that corresponding to x. The interior product is computed by summing over the dot product of the operation and premise vectors. Throughout the interval, we’ve garnered a cumulative sum of, resulting in a residual total of for each coefficient. For instance, for :
And analogously for .
Now, wanting again at what torch_fft_fft() Have given us an opportunity to realize that we have been able to achieve a similar outcome. We’ve uncovered a crucial insight along with the most effective approach.
As long as we remain committed to utilizing indicator sets comprised of multiple foundation vectors, we will successfully compute the discrete Fourier transform in this manner. Before concluding this chapter, we’ll create code applicable to any indicator; but first, let’s delve further into the intricacies of the Discrete Fourier Transform. Three key matters we will endeavour to uncover:
If frequencies were modified by singing a melody at the next pitch, the harmonics of the new frequency would likely clash with the existing harmonic structure of the original tone, resulting in a dissonant and potentially unpleasant sound.
What about amplitude adjustments – when the music is played twice as loudly, does that change its overall character and impact on listeners?
There are instances where a part has had an offset earlier than when the piece commenced, effectively setting the tone for what is to come.
In all instances, we’ll name torch_fft_fft() As soon as we have collectively determined the outcome.
As technology advances, we will discover that sophisticated sinusoids, comprising multiple components, can still be effectively analyzed by expressing them in terms of the frequencies that comprise their foundation.
Various frequency
Assuming we had quadrupled the frequency, it would give rise to a signal that resembles
We will specify it accordingly.
We already observe that nonzero coefficients are ensured solely for frequency indices 0 and 1. Choosing the previous, we receive
For the latter, we would arrive at a similar consequence.
Let’s double-check our assessment to ensure its accuracy. The revised text reads: The provided code snippet merely regenerates the sign, computes the discrete Fourier transform (DFT), and visualizes both results without introducing any innovative concepts or techniques.
A signal that oscillates four times within a sampling interval, along with its discrete Fourier transform. The imaginary components of all complex numbers, including their phases, are indeed zero.
This confirmation verifies our calculations with precision.
When the sign frequency reaches its optimal value, meaning it is detectable without aliasing issues. In most instances, that would be the scenario for half the array of sampling factors. The then. The sign will appear thusly.
Subsequently, we discover a solitary coefficient corresponding to a frequency of 32 revolutions per pattern interval, whose magnitude is doubled to 64. The signal and its Discrete Fourier Transform (DFT):
A pure cosine signal oscillating 32 times within a sampling interval, along with its discrete Fourier transform (DFT). At this frequency, the place offers optimal performance with 64 pattern factors, ensuring zero aliasing occurs. The magnitude of imaginary components remains unchanged at zero.
Various amplitude
As amplitude is scaled up, a plethora of consequences unfold. The new sign will amplify its noise output by a factor of two, effectively doubling its volume. The result of the interior product may be doubled by taking out a factor of two. Consequently, the sole adjustment is a modification in the scale of the coefficients’ values.
Let’s confirm this. Based on the previous instance, we modified the data with four cycles within the given timeframe.
The pure cosine waveform features four full revolutions within the sampling interval, accompanied by a doubling of its amplitude. Components imaginary and phase notwithstanding, are still zero.
So far, we’ve encountered no coefficients having a non-zero imaginary component. When we wish to transform something into another form, we incorporate additional elements.
Including part
Time-shifting a portion of a sign is equivalent to adjusting its temporal placement. Our instance sign is a cosine, an operation whose value is always 1 at π. That was the arbitrary starting point of the sign.
Now assume we shift the sign ahead by ? The height we’ve observed at zero shifts abruptly over; yet, if we initiate recording from zero, we’ll find a value of zero there. The fundamental nature of reality is encapsulated within this mathematical formula. For optimal comfort, we stipulate a sampling interval of ?, and ?, thereby ensuring that the instance simplifies to a straightforward cosine.
The initial appearance of the minus sign might raise a few eyebrows. Notwithstanding its logic, this text still requires refinement for clarity and precision.
Despite what has been achieved, we intend to acquire the price of one by then, implying that we should contemplate setting it to zero. To future generations, a seemingly insignificant event today will appear as a significant milestone.
Now, let’s compute the discrete Fourier transform (DFT) for a shifted version of our instance signature. If you happen to like it, take a look at the phase-shifted model of the time-domain image instead? You’ll notice that a cosine, delayed by π/2, is simply a sine starting from 0.
To compute the discrete Fourier transform (DFT), we employ a well-known method that has become second nature to us. The sign now appears thus.
We specifically define foundation vectors when it comes to foundations.
As we’ve seen previously, non-zero coefficients exist solely for frequencies 0 and . Although they have evolved significantly, each coefficient no longer shares a uniform identity. The substitute, being the advanced conjugate of the opposite, assumes a nuanced role in facilitating harmonious exchange between seemingly disparate entities. First, :
And right here, :
As a standard practice, we verify our calculations using torch_fft_fft().
Delays in a pure cosine wave by π/2 (90 degrees) yield a pure sine wave. Now the actual constituents of all coefficients are zero; in their place, non-zero imaginary values emerge. The part-shift at these positions is minimal.
For a pure sine wave, all non-zero Fourier coefficients are purely imaginary numbers? The part-shift within the coefficients, reported as ∆, effectively conveys the time delay we encountered in interpreting the sign.
Ultimately, before we venture into coding, let’s synthesize the collective elements and examine a waveform comprising multiple sinusoidal components.
Superposition of sinusoids
While the sign of the assembled sign remains relevant for premise vectors, it no longer manifests as a pristine sinusoidal expression. As a substitute, it’s a linear combination of these:
I won’t delve into the calculation in detail, but it’s essentially identical to previous ones. You compute the discrete Fourier transform (DFT) for each of the three segments, then combine the results. Despite the lack of calculations, several problems arise nonetheless.
Since a Fourier series representation of a periodic function involves sums of trigonometric functions, it is likely that you are referring to the harmonic analysis of a sign function which alternates between +1 and -1. In this case, the Fourier series expansion would consist of sine and cosine terms with coefficients determined by the even and odd parts of the function. The proposed advancements will yield conjoined derivatives that are reciprocally related.
Accordingly, the straightforward method of examining the sign yields direct access to the corresponding frequencies: All-real coefficients are associated with frequency indices 2, 8, 56, and 62, while all-imaginary coefficients correspond to indices 4 and 60.
Consequently, amplitudes will result from multiplying the obtained scaling factors by each individual sinusoid.
Let’s test:
Superposition of pure sinusoids, and its DFT.
How can we efficiently compute the discrete Fourier transform (DFT) for a larger number of less convenient indicators?
Coding the DFT
Fortunately, our understanding of what needs to be implemented is well-established. We aim to project the sign onto each of the premises’ vectors. We will calculate various interior products using distinct formulations.
While maintaining logical consistency, there is a notable difference in that it will typically be unfeasible to identify the signature when dealing with only a few fundamental vectors, as we previously demonstrated. All projections must therefore be accurately computed. Isn’t automation of tedious tasks precisely what computers are designed to handle?
The foundation of our process starts with defining input, output, and core functionality of the algorithm we’re about to execute. Throughout this chapter, our exploration remains confined to a solitary dimension. The entry thus is a one-dimensional tensor, representing a binary sign. The output is a one-dimensional array of Fourier coefficients, each element corresponding to a specific frequency component, providing details on its magnitude and phase. To successfully obtain a coefficient, carefully project the sign onto its corresponding foundation vector.
To actualize this idea, we must first generate premise vectors and then calculate their inner products with the signum. This code may execute in a loop. Surprisingly, minimal code is needed to achieve this objective.
We will take the final sign we analyzed, and examine it against the output. torch_fft_fft().
No you didn’t. Actually, a loop is precisely what’s desired. To streamline processing, we’ll concatenate premise vectors into a single matrix. Each row will maintain the conjugate of a foundation vector, and there will be n of them. What are the positions for? As such, the matrix would likely query
{#eq-dft-3}
Or, evaluating the expressions:
The revised text is: With this modification, the code appears significantly more refined.














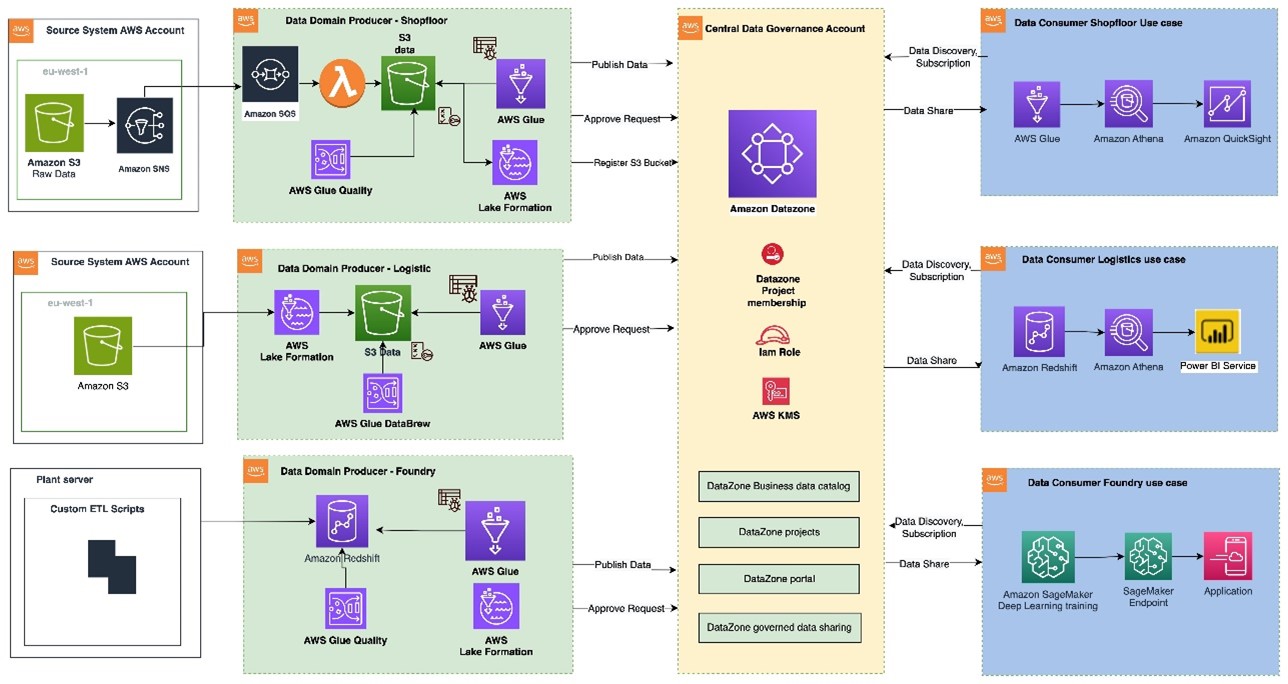
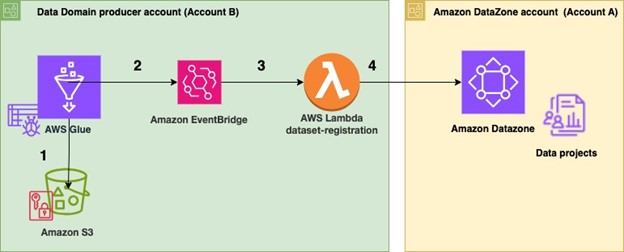
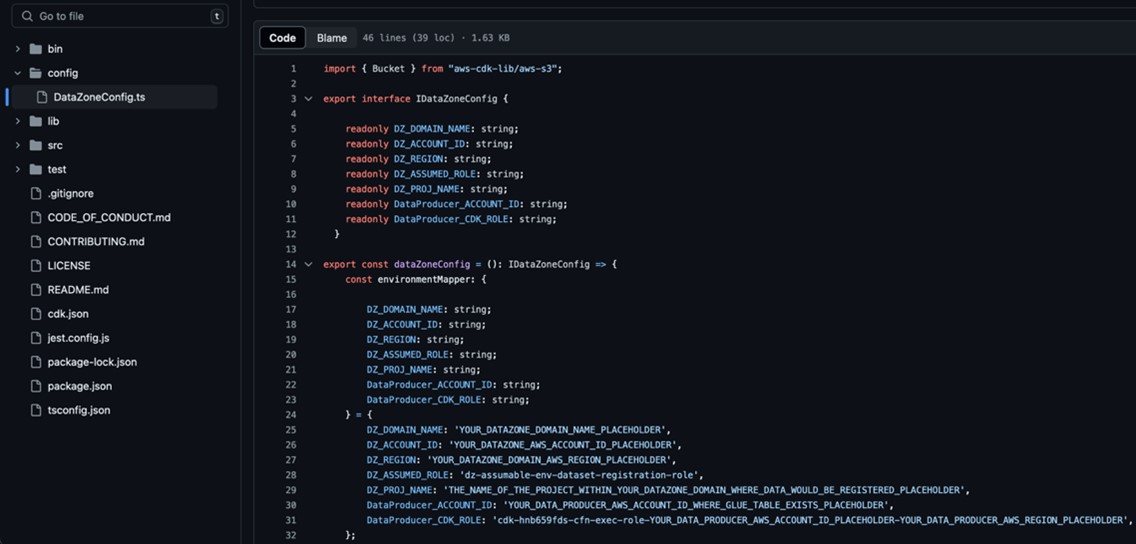
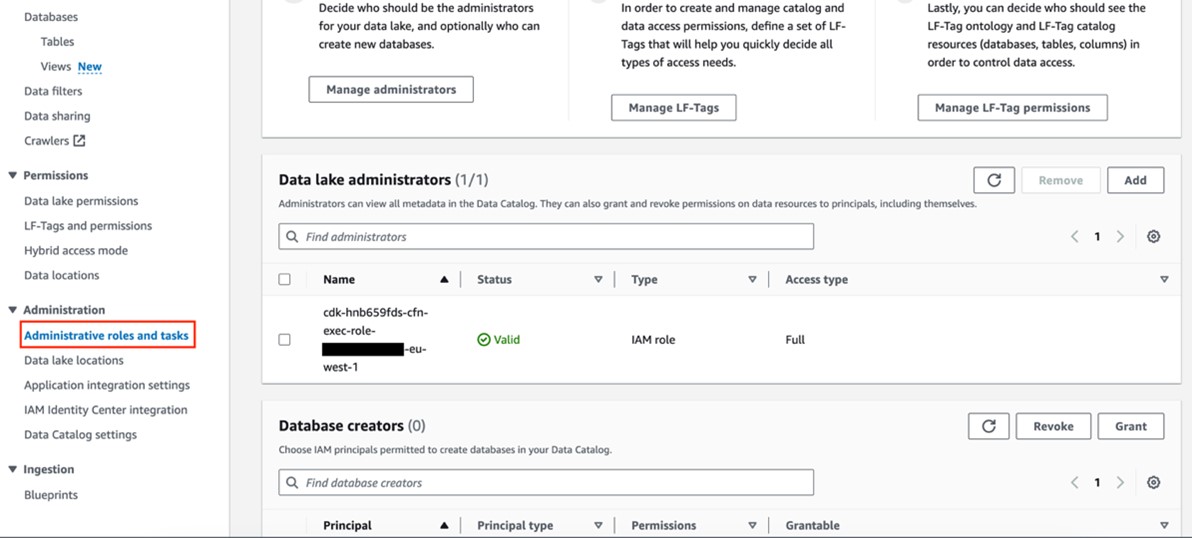






 Serving as a seasoned DevOps Architect at AWS, he leverages his expertise to craft tailored solutions that address the complex needs of clients operating within the automotive sector. He’s passionate about designing robust infrastructures, leveraging automation and data-driven insights to ensure a seamless cloud experience for customers. He prefers to balance his leisure time by pursuing personal interests in studying, acting, language acquisition, and traveling.
Serving as a seasoned DevOps Architect at AWS, he leverages his expertise to craft tailored solutions that address the complex needs of clients operating within the automotive sector. He’s passionate about designing robust infrastructures, leveraging automation and data-driven insights to ensure a seamless cloud experience for customers. He prefers to balance his leisure time by pursuing personal interests in studying, acting, language acquisition, and traveling.
 and its inverse are essential tools in many scientific disciplines, including signal processing, image analysis, and time series forecasting.")






