A Silicon Valley tech employee was fatally shot by police this week after allegedly stabbing a roommate.
Santa Clara police responded to a disturbance name that shortly escalated to a stabbing earlier this week. A police officer responding to the incident fatally shot the alleged attacker.
The 4 males within the residence have been all “high-tech staff,” although the suspect had been unemployed “for one and a half years already,” the home supervisor for the property claimed in an interview with native information KTVU. It’s not but clear which Bay Space tech firm the roommates labored for.
The incident occurred within the early morning hours on Wednesday on the 1800 block of Eisenhower Drive in Santa Clara, California. The city is on the middle of Silicon Valley, housing the headquarters of main expertise firms like Nvidia, AMD, Intel, and ServiceNow.
The coroner continues to be working to find and notify the following of kin of the suspect, so the identify was being withheld as of Friday, Santa Clara police division chief Corey Morgan stated in a press briefing on Friday afternoon.
The incident was reportedly not the primary time police had been dispatched to the residence. On Aug. 12, police have been referred to as to resolve a disturbance over an air con unit on the family between the identical two males, KTVU reported. The home supervisor allegedly began an eviction course of for the suspect after the Aug. 12 incident, and proceedings had wrapped up final week.
What we all know in regards to the incident
Shortly after 6 a.m. on Wednesday morning, Santa Clara police officer Robert Allsup responded to a 911 name from a Santa Clara space residence.
“As officers have been responding to the situation, they acquired data that the state of affairs had escalated and the suspect was now stabbing the sufferer,” Morgan advised press.
After kicking open the entrance door, the officer says he noticed 4 individuals within the hallway, with the suspect straddling the sufferer, pinning the physique all the way down to the bottom with a knife in his hand, in line with physique cam pictures shared with press at a briefing.
When the suspect raised the knife, the officer responded with 4 gunshots. The police say the suspect fell on the bottom, and was later transported to an area hospital the place he was pronounced useless, Santa Clara police stated.
The stabbing sufferer survived the assault, and was handled for a number of stab wounds to their fingers, chest, lung, and stomach. Primarily based on witness statements, the police stated, the suspect used two knives within the assaults.
Apple is internet hosting an internet streaming occasion for the general public and press on Tuesday, September 9, 2024 at 10:00 a.m. Pacific Time. The corporate is anticipated to announce its new iPhone 17 lineup alongside new Apple Watch fashions, and probably different merchandise through the occasion, dubbed “Awe Dropping.” This is how one can watch it and when, wherever you might be on the planet.
There are a number of methods to look at the September 9 occasion, with particulars listed under. We have additionally included a helpful information on when the occasion will happen in your specific time zone.
Apple Occasions Web site
With the Apple Occasions web site, you may watch the occasion dwell on a Mac, iPhone, iPad, PC, or every other gadget with an internet browser. The Apple Occasions web site works in Safari, Chrome, Firefox, and different essential browsers.
Simply navigate to www.apple.com/apple-events/ utilizing an internet browser on the applicable time to look at. You possibly can go to the positioning now so as to add an occasion reminder to your calendar.
YouTube
Apple additionally plans to stream the occasion dwell on YouTube, which is maybe the simplest and most effective solution to watch as a result of the YouTube dwell stream might be seen on each platform the place YouTube is out there, which is just about all platforms, from smartphones and tablets to consoles and good TVs.
Apple used to have a devoted Apple Occasions app on the Apple TV, however forward of WWDC 2020, it was folded into the Apple TV app. On occasion day, there shall be a outstanding Apple TV app part devoted to the dwell stream, which might be watched on any gadget the place the Apple TV app is out there.
This consists of the Apple TV, iPhones, iPads, and Macs, in addition to choose good TVs, streaming gadgets, and gaming consoles. You probably have an Apple TV, the Apple TV app is without doubt one of the greatest methods to look at the occasion dwell. Apple hasn’t up to date the Apple TV app with the brand new occasion as of but, but it surely ought to be added quickly.
When to Watch the Apple Occasion
Apple’s occasion will happen at 10:00 a.m. Pacific Time, like most Apple occasions. Occasion occasions in different time zones are listed under.
Honolulu, Hawaii — 7:00 a.m. HAST
Anchorage, Alaska — 9:00 a.m. AKDT
Cupertino, California — 10:00 a.m. PDT
Phoenix, Arizona — 10:00 a.m. MST
Vancouver, Canada — 10:00 a.m. PDT
Denver, Colorado — 11:00 a.m. MDT
Dallas, Texas — 12:00 midday CDT
New York, New York — 1:00 p.m. EDT
Toronto, Canada — 1:00 p.m. EDT
Halifax, Canada — 2:00 p.m. ADT
Rio de Janeiro, Brazil — 2:00 p.m. BRT
London, United Kingdom — 6:00 p.m. BST
Berlin, Germany — 7:00 p.m. CEST
Paris, France — 7:00 p.m. CEST
Cape City, South Africa — 7:00 p.m. SAST
Helsinki, Finland — 8:00 p.m. EEST
Istanbul, Turkey — 8:00 p.m. TRT
Dubai, United Arab Emirates — 9:00 p.m. GST
Delhi, India — 10:30 p.m. IST
Jakarta, Indonesia — 12:00 a.m. WIB subsequent day
Shanghai, China — 1:00 a.m. CST subsequent day
Singapore — 1:00 a.m. SGT subsequent day
Perth, Australia — 1:00 a.m. AWST subsequent day
Hong Kong — 1:00 a.m. HKT subsequent day
Seoul, South Korea — 2:00 a.m. KST subsequent day
Tokyo, Japan — 2:00 a.m. JST subsequent day
Adelaide, Australia — 2:30 a.m. ACST subsequent day
Sydney, Australia — 3:00 a.m. AEST subsequent day
Auckland, New Zealand — 5:00 a.m. NZST subsequent day
MacRumors Protection
In the event you’re not capable of watch or simply wish to comply with together with us as we watch the occasion unfold, go to MacRumors.com for our liveblog or comply with us on Twitter at MacRumorsLive for our dwell tweet protection.
Each the MacRumors website and our X (Twitter) account are wonderful methods to debate the brand new bulletins with different Apple fans as Apple unveils its new merchandise. Later within the day and all through the week, we’ll even have way more in-depth protection of all of Apple’s bulletins, so make certain to remain tuned.
9to5Mac Safety Chunk is solely dropped at you by Mosyle, the one Apple Unified Platform.Making Apple units work-ready and enterprise-safe is all we do. Our distinctive built-in strategy to administration and safety combines state-of-the-art Apple-specific safety options for absolutely automated Hardening & Compliance, Subsequent Technology EDR, AI-powered Zero Belief, and unique Privilege Administration with probably the most highly effective and trendy Apple MDM in the marketplace. The result’s a completely automated Apple Unified Platform at the moment trusted by over 45,000 organizations to make tens of millions of Apple units work-ready with no effort and at an inexpensive value. Request your EXTENDED TRIAL at this time and perceive why Mosyle is every little thing you have to work with Apple.
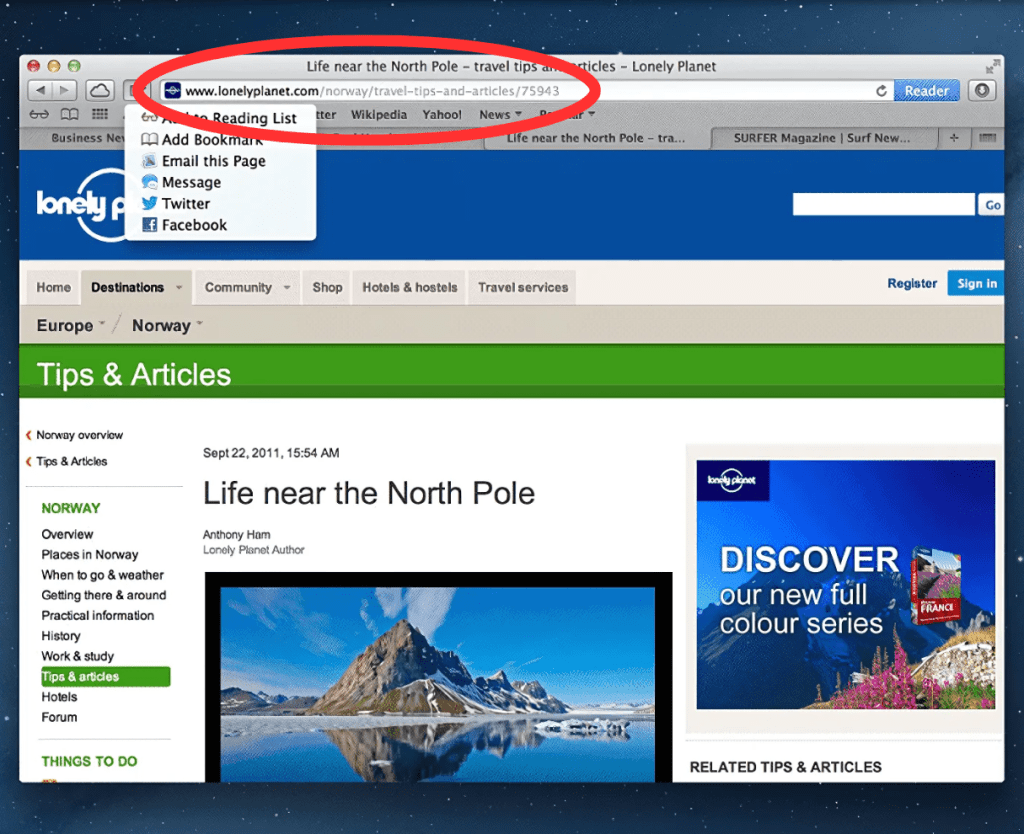
When you’re studying this week’s Safety Chunk in your desktop, look intently at your browser’s tackle bar. Discover how the principle (root) area is bolder, whereas the remainder of the URL is a lighter gray? This isn’t an accident, it’s a purposly applied psychological trick referred to as salience bias. This little design selection has protected customers from phishing assaults for over a decade.
Salience bias (generally referred to as perceptual salience) is a cognitive habits that causes one to note issues that stand out extra, like one thing brighter, bolder, and general extra visually placing. Apple’s advertising wing is understood for this. The corporate’s minimalist business adverts, web site pages, and even retail shops are constructed to attract consideration to the topic, not the environment.
Most main browsers started adopting this method across the early 2010s when full URLs had been nonetheless being displayed. Web Explorer 8 was first. Apple adopted in 2012 with the discharge of Safari 6 on OS X Mountain Lion. Notably, the Safari replace launched one thing referred to as “Sensible Search Subject,” which mixed the tackle and search bars into one. It appears foolish, however it was an enormous deal on the time. It was with this launch that Safari additionally began darkening the URL’s major area.
Salience bias launched in Safari 6 on OS X Mountain Lion (2006). Picture by way of BetaNews.
As we speak, desktop Safari makes area salience much more obvious. By default, it solely exhibits the basis area within the tackle bar — it’s important to click on or faucet to see the complete URL. It’s the identical strategy most cellular browsers use, although you may flip it off in Safari’s settings in case you like.
Who stated UI design and safety can’t go hand in hand? That is a kind of apparent options we subconsciously discover however don’t assume twice about. It’s a clear design selection that brilliantly emphasizes probably the most crucial particulars up entrance, permitting potential victims to catch themselves earlier than giving up delicate data.
This little salience trick undoubtedly has saved tens of millions from changing into victims of phishing assaults.
Extra in Apple safety
Thanks for studying Safety Chunk, a security-focused column on 9to5Mac, made potential by Moysle.
As you’ve most likely observed, Google has gotten … bizarre currently. Weirder? It may be onerous to search out the search outcomes you’re on the lookout for. Between AI summaries and algorithm modifications leading to surprising sources, it may be tough to navigate the preferred search engine on the planet. (And publishersarefeeling the pressure, too.)
Earlier this yr, Google up to date its algorithm. That is nothing new—Google updates its algorithms tons of of instances per yr, with anyplace from two to 4 main “core updates” that end in vital modifications. And whereas it is tough to find out precisely what modified, publishers and web sites giant and small observed vital site visitors drops and decrease search rankings—even for content material that had beforehand been doing effectively. “Google Zero” (as Nilay Patel of The Verge first referred to as it) is considered precipitated, at the very least partly, by AI overviews.
Google Search has proven a gradual crawl towards this for a few years, however the latest blow was delivered over the summer time. Whenever you seek for one thing and also you get a neat little abstract of assorted reporting accomplished by journalists, you are much less more likely to go to the web sites that truly did the work. And, in some cases, that abstract incorporates incorrect AI hallucinations or reporting from web sites you may not belief as a lot. It is onerous to say whether or not the subsequent core replace will make your search outcomes present what you anticipate, however within the meantime, there is a tweak that may assist it really feel extra tailor-made to your preferences.
Take again management of your Google search outcomes with the brand new Google “Most popular Sources” device. This can assist you see extra of WIRED, from our rigorous and obsessive Critiques protection to the essential breaking tales on our Politics desk to our Tradition workforce’s “What to Watch” roundups. (And, sure, this works for different publishers you realize and belief, too.)
Most popular Sources are prioritized in High Tales search outcomes, and also you’ll additionally get a devoted From Your Sources part on some search outcomes pages.
To set WIRED as a Most popular Supply, you may click on this hyperlink and test the field to the correct. You can even seek for extra sources you like on this web page and test the respective containers to verify they’re prioritized in your Google searches.
VirusTotal has found a phishing marketing campaign hidden in SVG information that create convincing portals impersonating Colombia’s judicial system that ship malware.
VirusTotal detected this marketing campaign after it added help for SVGs to its AI Code Perception platform.
VirusTotal’s AI Code Perception function analyzes uploaded file samples utilizing machine studying to generate summaries of suspicious or malicious habits discovered within the information.
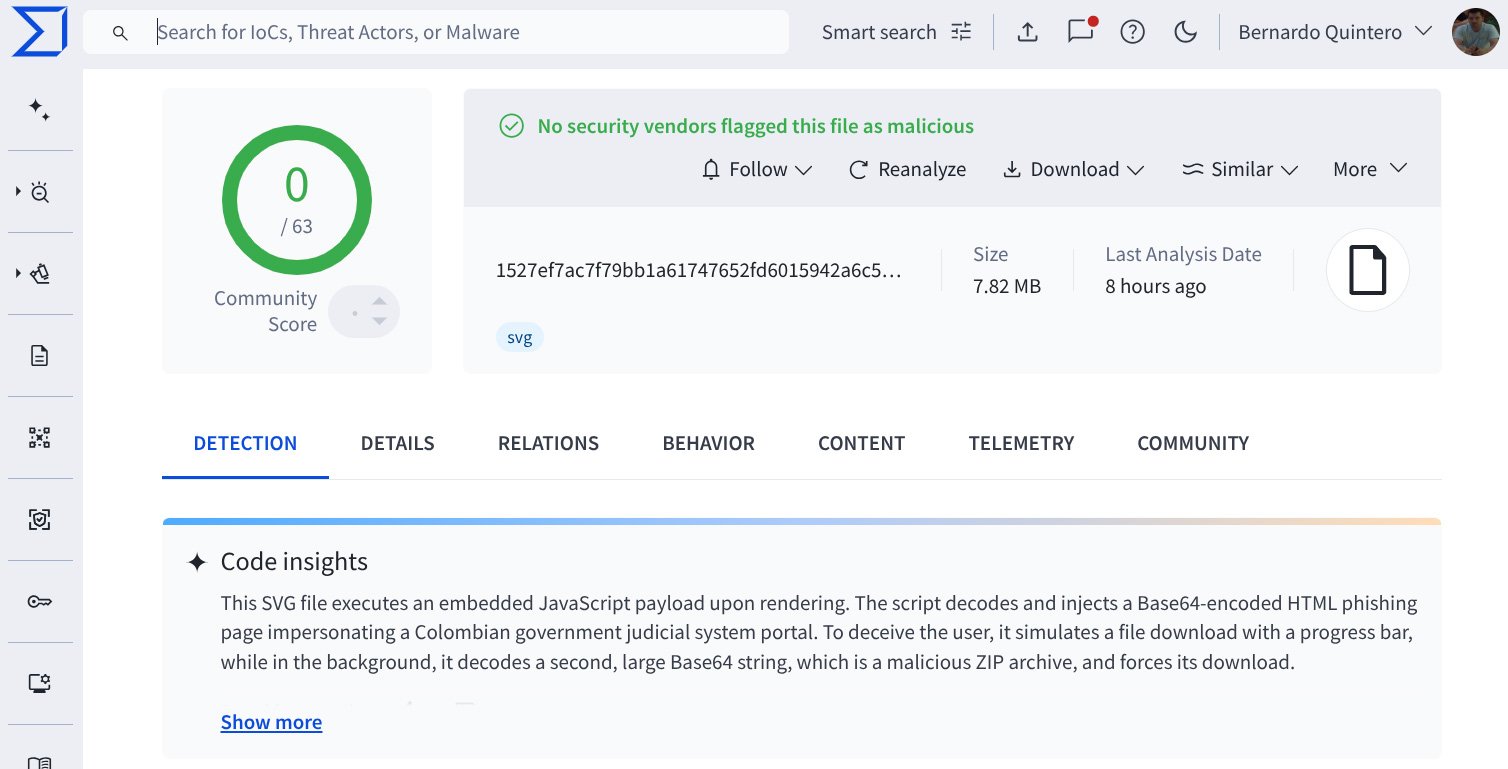
After including help for SVGs, VirusTotal discovered an SVG file that had zero detections by antivirus scans, however whose AI-powered Code Perception function detected utilizing JavaScript to show HTML, impersonating a portal for Colombia’s authorities judiciary system.
VirusTotal Code insights detecting a malicious SVG file Supply: VirusTotal
SVG, or Scalable Vector Graphics, is used to generate pictures of traces, shapes, and textual content via textual mathematical formulation within the file.
Nevertheless, menace actors have begun more and more utilizing SVG information in assaults, as they will also be used to show HTML utilizing the factor and execute JavaScript when the graphic is loaded.
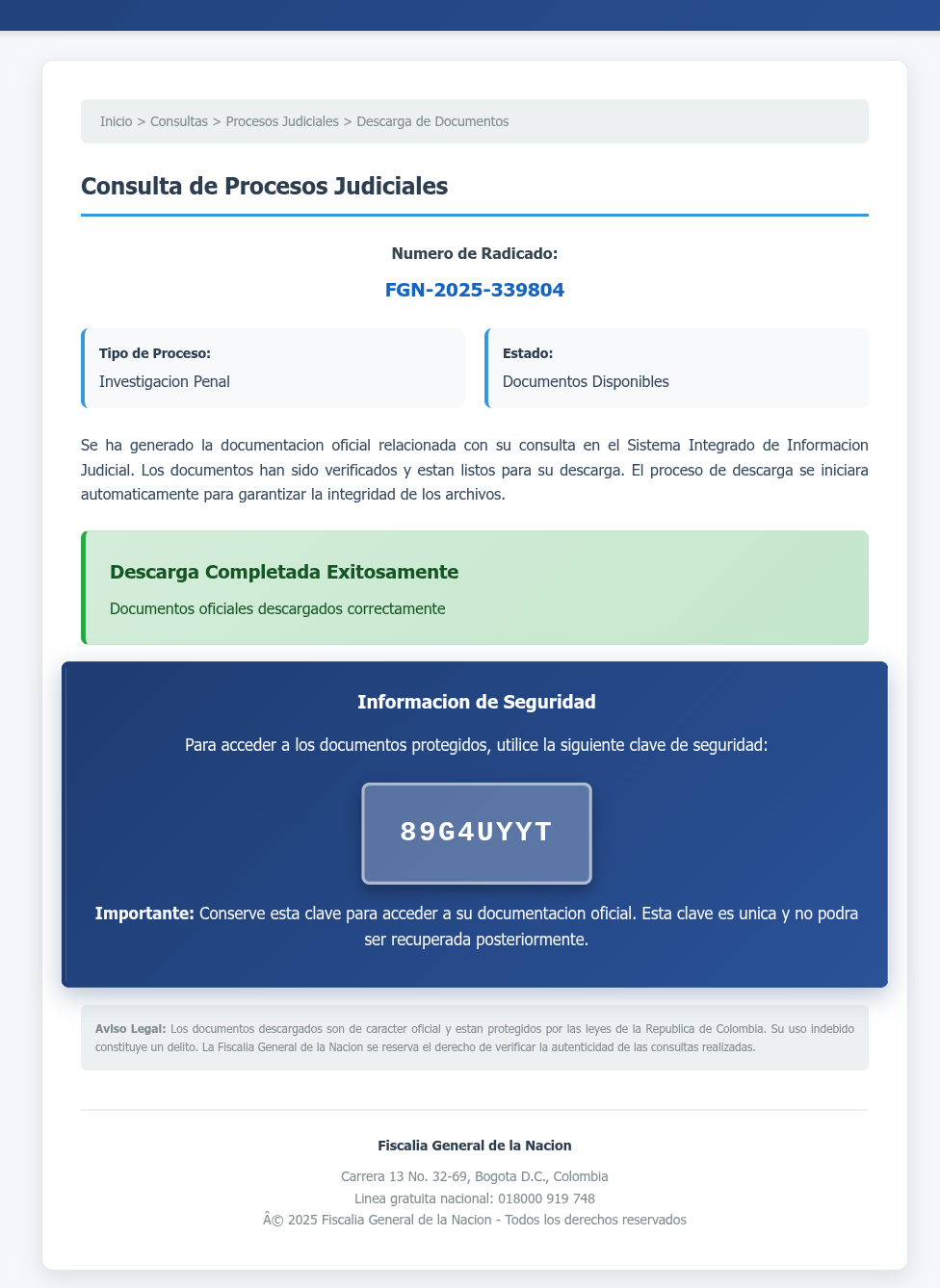
Within the marketing campaign found by Virustotal, SVG picture information are used to render pretend portals that show a phony obtain progress bar, in the end prompting the person to obtain a password-protected zip archive [VirusTotal]. The password for this file is displayed within the pretend portal web page.
“As proven within the screenshots under, the pretend portal is rendered precisely as described, simulating an official authorities doc obtain course of,” explains VirusTotal.
“The phishing web site contains case numbers, safety tokens, and visible cues to construct belief, all of it crafted inside an SVG file.”
Faux portal for Colombia’s judicial system Supply: VirusTotal
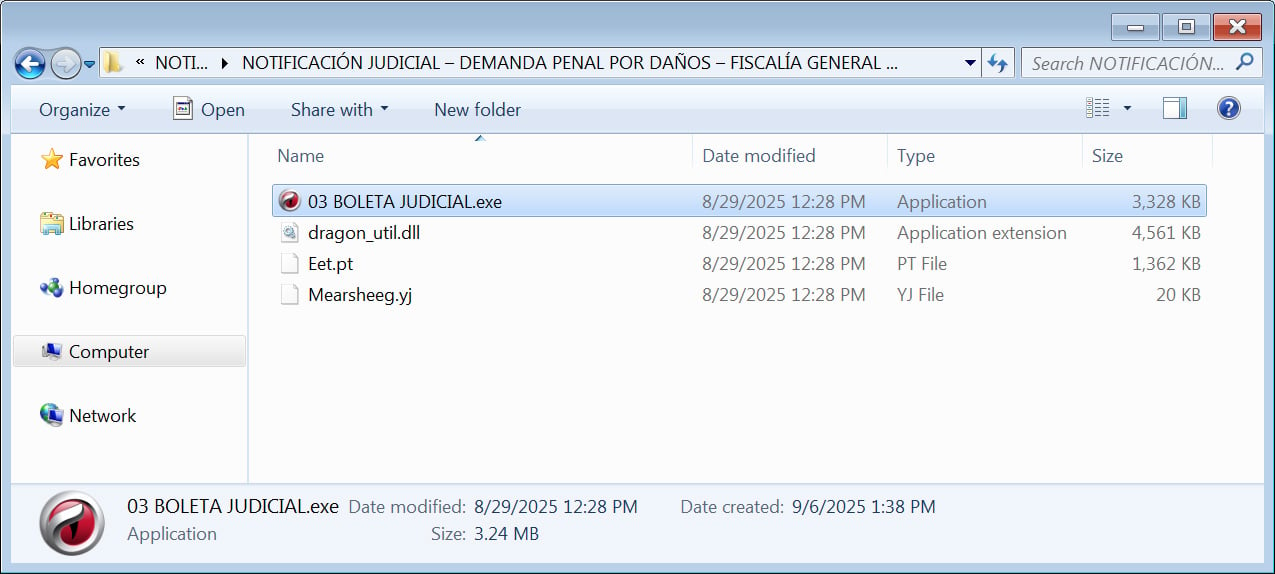
BleepingComputer discovered that the extracted file incorporates 4 information: a reliable executable from the Comodo Dragon internet browser, renamed to be an official judicial doc, a malicious DLL [VirusTotal], and what seems to be two encrypted information.
If the person opens the executable, the malicious DLL will likely be sideloaded to put in additional malware on the system.
After detecting this preliminary SVG, VirusTotal recognized 523 beforehand uploaded SVG information that had been a part of the identical marketing campaign however had evaded detection by safety software program.
The addition of SVG help to AI Code Insights was essential in exposing this explicit marketing campaign, as VirusTotal famous that using AI makes it simpler to determine new malicious campaigns.
“That is the place Code Perception helps most: giving context, saving time, and serving to deal with what actually issues. It isn’t magic, and it will not change professional evaluation, nevertheless it’s another instrument to chop via the noise and get to the purpose quicker,” concludes VirusTotal.
46% of environments had passwords cracked, almost doubling from 25% final 12 months.
Get the Picus Blue Report 2025 now for a complete take a look at extra findings on prevention, detection, and information exfiltration traits.
In Half 1 of this sequence, we mentioned elementary operations to manage the lifecycle of your Amazon Managed Service for Apache Flink utility. If you’re utilizing higher-level instruments comparable to AWS CloudFormation or Terraform, the device will execute these operations for you. Nevertheless, understanding the basic operations and what the service routinely does can present some stage of Mechanical Sympathy to confidently implement a extra strong automation.
Within the first a part of this sequence, we targeted on the blissful paths. In a perfect world, failures don’t occur, and each change you deploy works completely. Nevertheless, the true world is much less predictable. Quoting Werner Vogels, Amazon’s CTO, “Every thing fails, on a regular basis.”
On this submit, we discover failure eventualities that may occur throughout regular operations or whenever you deploy a change or scale the applying, and find out how to monitor operations to detect and get well when one thing goes improper.
The much less blissful path
A sturdy automation should be designed to deal with failure eventualities, specifically throughout operations. To do this, we have to perceive how Apache Flink can deviate from the blissful path. Because of the nature of Flink as a stateful stream processing engine, detecting and resolving failure eventualities requires totally different methods in comparison with different long-running functions, comparable to microservices or short-lived serverless capabilities (comparable to AWS Lambda).
Flink’s conduct on runtime errors: The fail-and-restart loop
When a Flink job encounters an sudden error at runtime (an unhandled exception), the traditional conduct is to fail, cease the processing, and restart from the most recent checkpoint. Checkpoints enable Flink to assist knowledge consistency and no knowledge loss in case of failure. Additionally, as a result of Flink is designed for stream processing functions, which run constantly, if the error occurs once more, the default conduct is to maintain restarting, hoping the issue is transient and the applying will ultimately get well the traditional processing.In some circumstances, the issue isn’t transient, nonetheless. For instance, whenever you deploy a code change that incorporates a bug, inflicting the job to fail as quickly because it begins processing knowledge, or if the anticipated schema doesn’t match the information within the supply, inflicting deserialization or processing errors. The identical state of affairs may additionally occur should you mistakenly modified a configuration that stops a connector to succeed in the exterior system. In these circumstances, the job is caught in a fail-and-restart loop, indefinitely, or till you actively force-stop it.
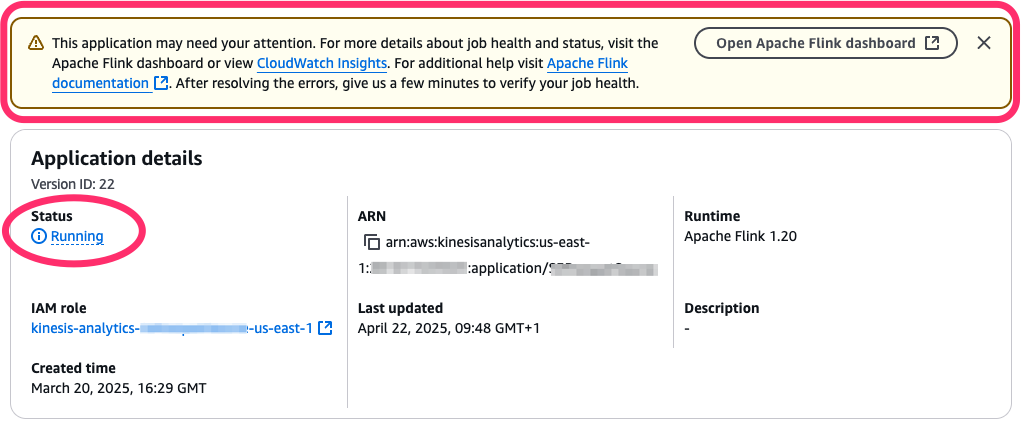
When this occurs, the Managed Service for Apache Flink utility standing could be RUNNING, however the underlying Flink job is definitely failing and restarting. The AWS Administration Console provides you a touch, pointing that the applying may want consideration (see the next screenshot).
Within the following sections, we discover ways to monitor the applying and job standing, to routinely react to this case.
When beginning or updating the applying goes improper
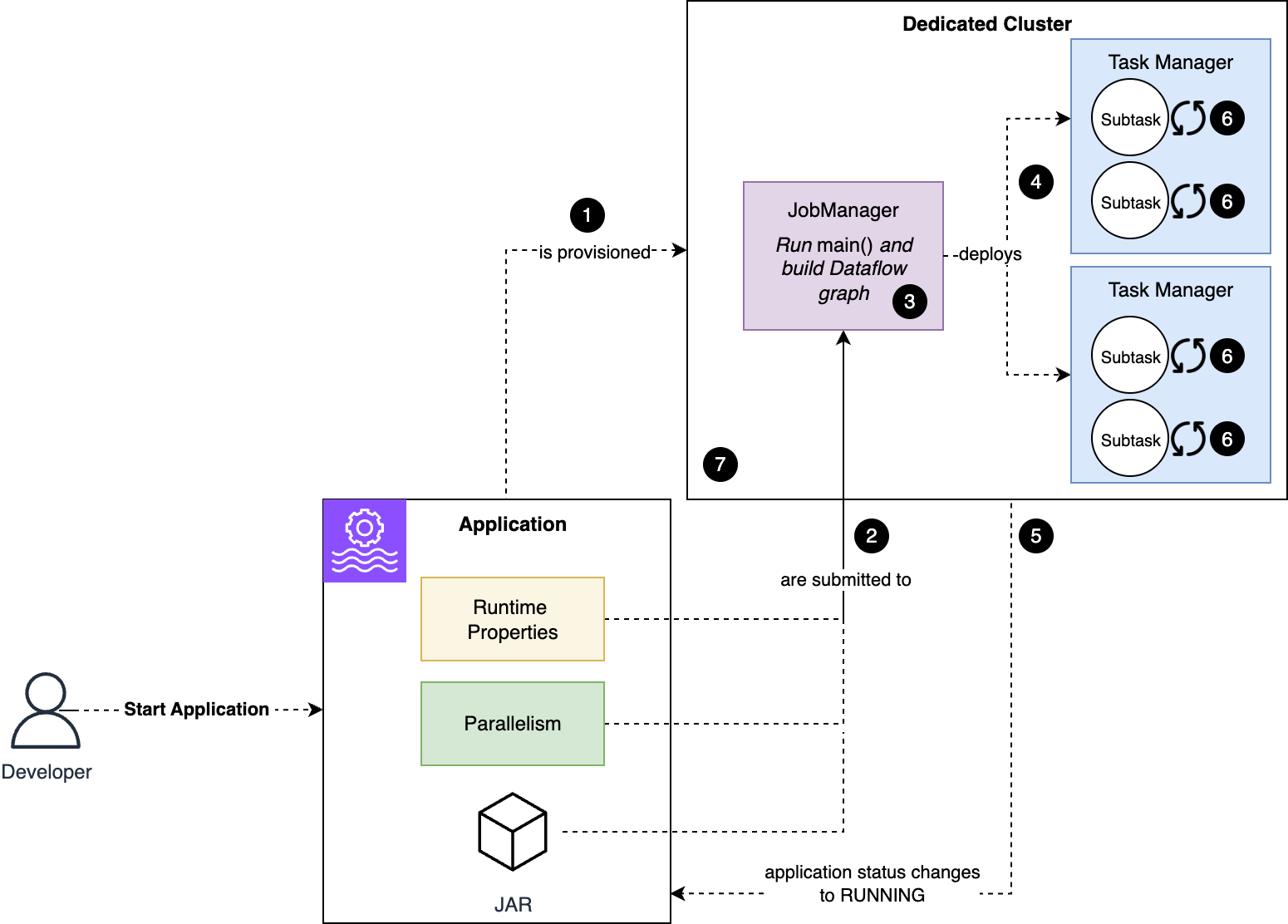
To know the failure mode, let’s overview what occurs routinely whenever you begin the applying, or when the applying restarts after you issued UpdateApplication command, as we explored in Half 1 of this sequence. The next diagram illustrates what occurs when an utility begins.
The workflow consists of the next steps:
Managed Service for Apache Flink provisions a cluster devoted to your utility.
The code and configuration are submitted to the Job Supervisor node.
The code within the principal() technique of your utility runs, defining the dataflow of your utility.
Flink deploys to the Activity Supervisor nodes the substasks that make up your job.
The job and utility standing change to RUNNING. Nevertheless, subtasks begin initializing now.
Subtasks restore their state, if relevant, and initialize any assets. For instance, a Kafka connector’s subtask initializes the Kafka shopper and subscribes the subject.
When all subtasks are efficiently initialized, they alter to RUNNING standing and the job begins processing knowledge.
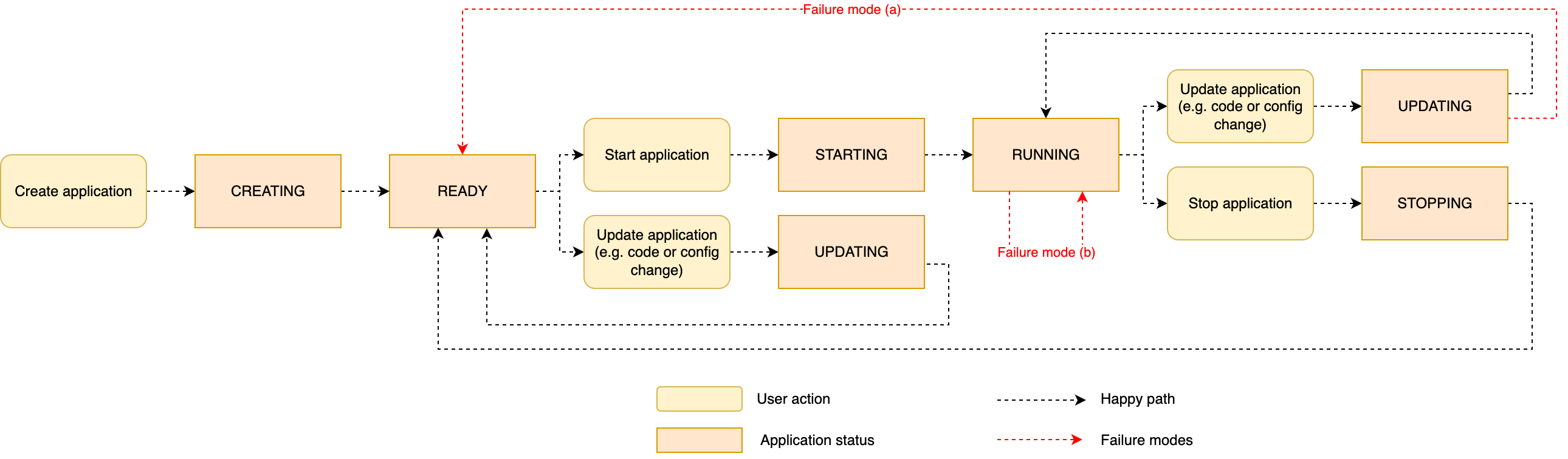
To new Flink customers, it may be complicated {that a} RUNNING standing doesn’t essentially indicate the job is wholesome and processing knowledge.When one thing goes improper through the technique of beginning (or restarting) the applying, relying on the part when the issue arises, you may observe two various kinds of failure modes:
(a) An issue prevents the applying code from being deployed – Your utility may encounter this failure state of affairs if the deployment fails as quickly because the code and configuration are handed to the Job Supervisor (step 2 of the method), for instance if the applying code package deal is malformed. A typical error is when the JAR is lacking a mainClass or if mainClass factors to a category that doesn’t exist. This failure mode may additionally occur if the code of your principal() technique throws an unhandled exception (step 3). In these circumstances, the applying fails to alter to RUNNING, and reverts to READY after the try.
(b) The appliance is began, the job is caught in a fail-and-restart loop – An issue may happen later within the course of, after the applying standing has modified RUNNING. For instance, after the Flink job has been deployed to the cluster (step 4 of the method), a element may fail to initialize (step 6). This may occur when a connector is misconfigured, or an issue prevents it from connecting to the exterior system. For instance, a Kafka connector may fail to connect with the Kafka cluster due to the connector’s misconfiguration or networking points. One other attainable state of affairs is when the Flink job efficiently initializes, however it throws an exception as quickly because it begins processing knowledge (step 7). When this occurs, Flink reacts to a runtime error and may get caught in a fail-and-restart loop.
The next diagram illustrates the sequence of utility standing, together with the 2 failure eventualities simply described.
Troubleshooting
We now have examined what can go improper throughout operations, specifically whenever you replace a RUNNING utility or restart an utility after altering its configuration. On this part, we discover how we will act on these failure eventualities.
Roll again a change
While you deploy a change and notice one thing isn’t fairly proper, you usually wish to roll again the change and put the applying again in working order, till you examine and repair the issue. Managed Service for Apache Flink supplies a sleek technique to revert (roll again) a change, additionally restarting the processing from the purpose it was stopped earlier than making use of the fault change, offering consistency and no knowledge loss.In Managed Service for Apache Flink, there are two sorts of rollbacks:
Automated – Throughout an automated rollback (additionally known as system rollback), if enabled, the service routinely detects when the applying fails to restart after a change, or when the job begins however instantly falls right into a fail-and-restart loop. In these conditions, the rollback course of routinely restores the applying configuration model earlier than the final change was utilized and restarts the applying from the snapshot taken when the change was deployed. See Enhance the resilience of Amazon Managed Service for Apache Flink utility with system-rollback function for extra particulars. This function is disabled by default. You may allow it as a part of the applying configuration.
Handbook – A handbook rollback API operation is sort of a system rollback, however it’s initiated by the person. If the applying is operating however you observe one thing not behaving as anticipated after making use of a change, you possibly can set off the rollback operation utilizing the RollbackApplication API motion or the console. Handbook rollback is feasible when the applying is RUNNING or UPDATING.
Each rollbacks work equally, restoring the configuration model earlier than the change and restarting with the snapshot taken earlier than the change. This prevents knowledge loss and brings you again to a model of the applying that was working. Additionally, this makes use of the code package deal that was saved on the time you created the earlier configuration model (the one you might be rolling again to), so there isn’t a inconsistency between code, configuration, and snapshot, even when within the meantime you might have changed or deleted the code package deal from the Amazon Easy Storage Service (Amazon S3) bucket.
Implicit rollback: Replace with an older configuration
A 3rd technique to roll again a change is to easily replace the configuration, bringing it again to what it was earlier than the final change. This creates a brand new configuration model, and requires the right model of the code package deal to be accessible within the S3 bucket whenever you situation the UpdateApplication command.
Why is there a 3rd possibility when the service supplies system rollback and the managed RollbackApplication motion? As a result of most high-level infrastructure-as-code (IaC) frameworks comparable to Terraform use this technique, explicitly overwriting the configuration. It is very important perceive this chance though you’ll in all probability use the managed rollback should you implement your automation primarily based on the low-level actions.
The next are two essential caveats to think about for this implicit rollback:
You’ll usually wish to restart the applying from the snapshot that was taken earlier than the defective change was deployed. If the applying is at present RUNNING and wholesome, this isn’t the most recent snapshot (RESTORE_FROM_LATEST_SNAPSHOT), however moderately the earlier one. You need to set the restart from RESTORE_FROM_CUSTOM_SNAPSHOT and choose the right snapshot.
UpdateApplication solely works if the applying is RUNNING and wholesome, and the job might be gracefully stopped with a snapshot. Conversely, if the applying is caught in a fail-and-restart loop, you should force-stop it first, change the configuration whereas the applying is READY, and later begin the applying from the snapshot that was taken earlier than the defective change was deployed.
Drive-stop the applying
In regular eventualities, you cease the applying gracefully, with the automated snapshot creation. Nevertheless, this may not be attainable in some eventualities, comparable to if the Flink job is caught in a fail-and-restart loop. This may occur, for instance, if an exterior system the job makes use of stops working, or as a result of the AWS Identification and Entry Administration (IAM) configuration was erroneously modified, eradicating permissions required by the job.
When the Flink job will get caught in a fail-and-restart loop after a defective change, your first possibility ought to be utilizing RollbackApplication, which routinely restores the earlier configuration and begins from the right snapshot. Within the uncommon circumstances you possibly can’t cease the applying gracefully or use RollbackApplication, the final resort is force-stopping the applying. Drive-stop makes use of the StopApplication command with Drive=true. You can even force-stop the applying from the console.
While you force-stop an utility, no snapshot is taken (if that have been attainable, you’d have been in a position to gracefully cease). While you restart the applying, you possibly can both skip restoring from a snapshot (SKIP_RESTORE_FROM_SNAPSHOT) or use a snapshot that was beforehand taken, scheduled utilizing Snapshot Supervisor, or manually, utilizing the console or CreateApplicationSnapshot API motion.
We strongly advocate organising scheduled snapshots for all manufacturing functions that you may’t afford restarting with no state.
Monitoring Apache Flink utility operations
Efficient monitoring of your Apache Flink functions throughout and after operations is essential to confirm the end result of the operation and permit lifecycle automation to boost alarms or react, in case one thing goes improper.
The primary indicators you need to use throughout operations embrace the FullRestarts metric (accessible in Amazon CloudWatch) and the applying, job, and job standing.
Monitoring the end result of an operation
The only technique to detect the end result of an operation, comparable to StartApplication or UpdateApplication, is to make use of the ListApplicationOperations API command. This command returns a listing of the latest operations of a selected utility, together with upkeep occasions that pressure an utility restart.
For instance, to retrieve the standing of the latest operation, you need to use the next command:
OperationStatus will observe the identical logic as the applying standing reported by the console and by DescribeApplication. This implies it may not detect a failure through the operator initialization or whereas the job begins processing knowledge. As we have now realized, these failures may put the applying in a fail-and-restart loop. To detect these eventualities utilizing your automation, you should use different methods, which we cowl in the remainder of this part.
Detecting the fail-and-restart loop utilizing the FullRestarts metric
The only technique to detect whether or not the applying is caught in a fail-and-restart loop is utilizing the fullRestarts metric, accessible in CloudWatch Metrics. This metric counts the variety of restarts of the Flink job after you began the applying with a StartApplication command or restarted with UpdateApplication.
In a wholesome utility, the variety of full restarts ought to ideally be zero. A single full restart could be acceptable throughout deployment or deliberate upkeep; a number of restarts usually point out some situation. We advocate to not set off an alarm on a single restart, and even a few consecutive restarts.
The alarm ought to solely be triggered when the applying is caught in a fail-and-restart loop. This suggests checking whether or not a number of restarts have occurred over a comparatively quick time frame. Deciding the interval isn’t trivial, as a result of the time the Flink job takes to restart from a checkpoint relies on the scale of the applying state. Nevertheless, if the state of your utility is decrease than a number of GB per KPU, you possibly can safely assume the applying ought to begin in lower than a minute.
The objective is making a CloudWatch alarm that triggers when fullRestarts retains rising over a time interval ample for a number of restarts. For instance, assuming your utility restarts in lower than 1 minute, you possibly can create a CloudWatch alarm that depends on the DIFF math expression of the fullRestarts metric. The next screenshot exhibits an instance of the alarm particulars.
This instance is a conservative alarm, solely triggering if the applying retains restarting for over 5 minutes. This implies you detect the issue after no less than 5 minutes. You may think about lowering the time to detect the failure earlier. Nevertheless, watch out to not set off an alarm after only one or two restarts. Occasional restarts may occur, for instance throughout regular upkeep (patching) that’s managed by the service, or for a transient error of an exterior system. Flink is designed to get well from these circumstances with minimal downtime and no knowledge loss.
Detecting whether or not the job is up and operating: Monitoring utility, job, and job standing
We now have mentioned how you might have totally different statuses: the standing of the applying, job, and subtask. In Managed Service for Apache Flink, the applying and job standing change to RUNNING when the subtasks are efficiently deployed on the cluster. Nevertheless, the job isn’t actually operating and processing knowledge till all of the subtasks are RUNNING.
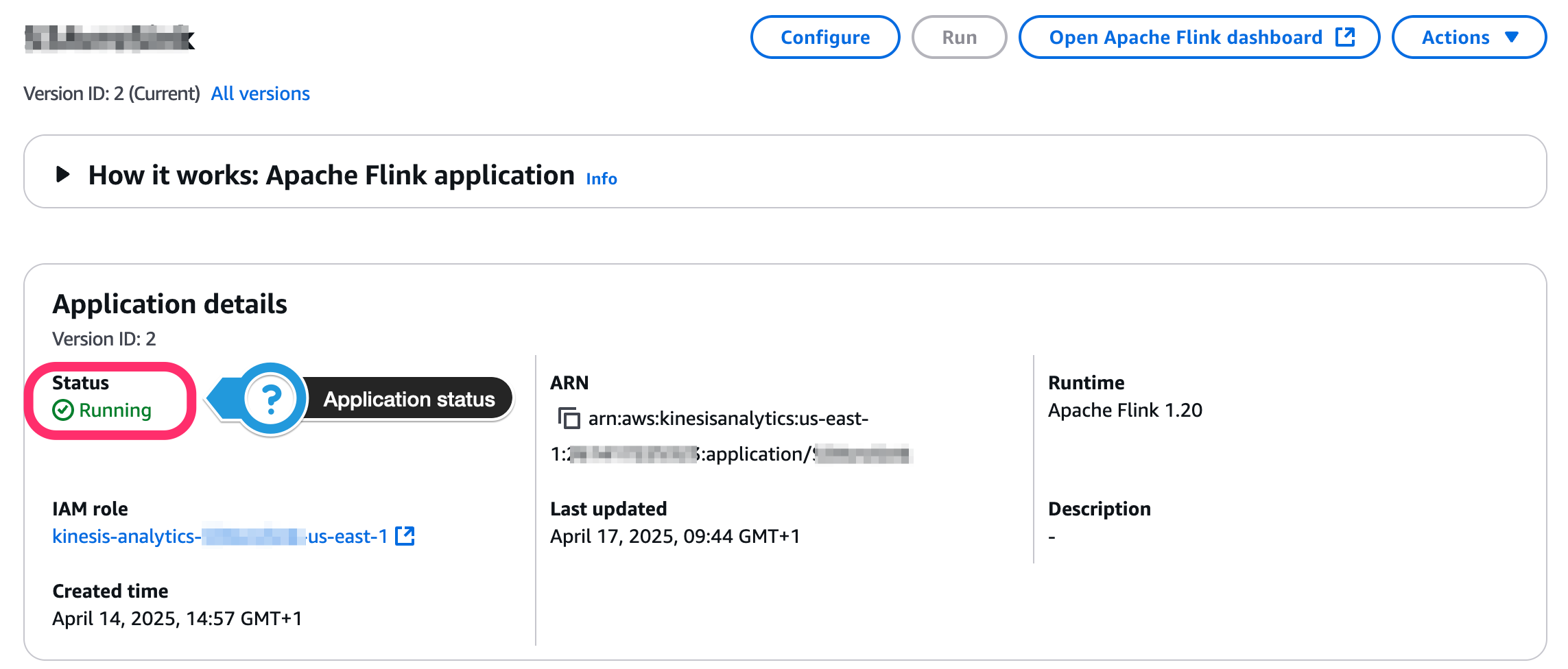
Observing the applying standing throughout operations
The appliance standing is seen on the console, as proven within the following screenshot.
In your automation, you possibly can ballot the DescribeApplication API motion to look at the applying standing. The next command exhibits find out how to use the AWS Command Line Interface (AWS CLI) and jq command to extract the standing string of an utility:
Managed Service for Apache Flink provides you entry to the Flink Dashboard, which supplies helpful data for troubleshooting, together with the standing of all subtasks. The next screenshot, for instance, exhibits a wholesome job the place all subtasks are RUNNING.
Within the following screenshot, we will see a job the place subtasks are failing and restarting.
In your automation, whenever you begin the applying or deploy a change, you wish to be certain the job is ultimately up and operating and processing knowledge. This occurs when all of the subtasks are RUNNING. Observe that ready for the job standing to turn into RUNNING after an operation isn’t utterly secure. A subtask may nonetheless fail and trigger the job to restart after it was reported as RUNNING.
After you execute a lifecycle operation, your automation can ballot the substasks standing ready for certainly one of two occasions:
All subtasks report RUNNING – This means the operation was profitable and your Flink job is up and operating.
Any subtask reviews FAILING or CANCELED – This means one thing went improper, and the applying is probably going caught in a fail-and-restart loop. You should intervene, for instance, force-stopping the applying after which rolling again the change.
If you’re restarting from a snapshot and the state of your utility is kind of large, you may observe subtasks will report INITIALIZING standing for longer. Through the initialization, Flink restores the state of the operator earlier than altering to RUNNING.
The Flink REST API exposes the state of the subtasks, and can be utilized in your automation. In Managed Service for Apache Flink, this requires three steps:
Make a GET request to the /jobs endpoint of the Flink REST API to retrieve the job ID.
Make a GET request to the /jobs/ endpoint to retrieve the standing of the subtasks.
The next GitHub repository supplies a shell script to retrieve the standing of the duties of a given Managed Service for Apache Flink utility.
Monitoring subtasks failure whereas the job is operating
The strategy of polling the Flink REST API can be utilized in your automation, instantly after an operation, to look at whether or not the operation was ultimately profitable.
We strongly advocate to not constantly ballot the Flink REST API whereas the job is operating to detect failures. This operation is useful resource consuming, and may degrade efficiency or trigger errors.
To observe for suspicious subtask standing modifications throughout regular operations, we advocate utilizing CloudWatch Logs as a substitute. The next CloudWatch Logs Insights question extracts all subtask state transitions:
fields , message | parse message /^(?.+) switched from (?[A-Z]+) to (?[A-Z]+)./ | filter ispresent(job) and ispresent(fromStatus) and ispresent(toStatus) | show , job, fromStatus, toStatus | restrict 10000
How Managed Service for Apache Flink minimizes processing downtime
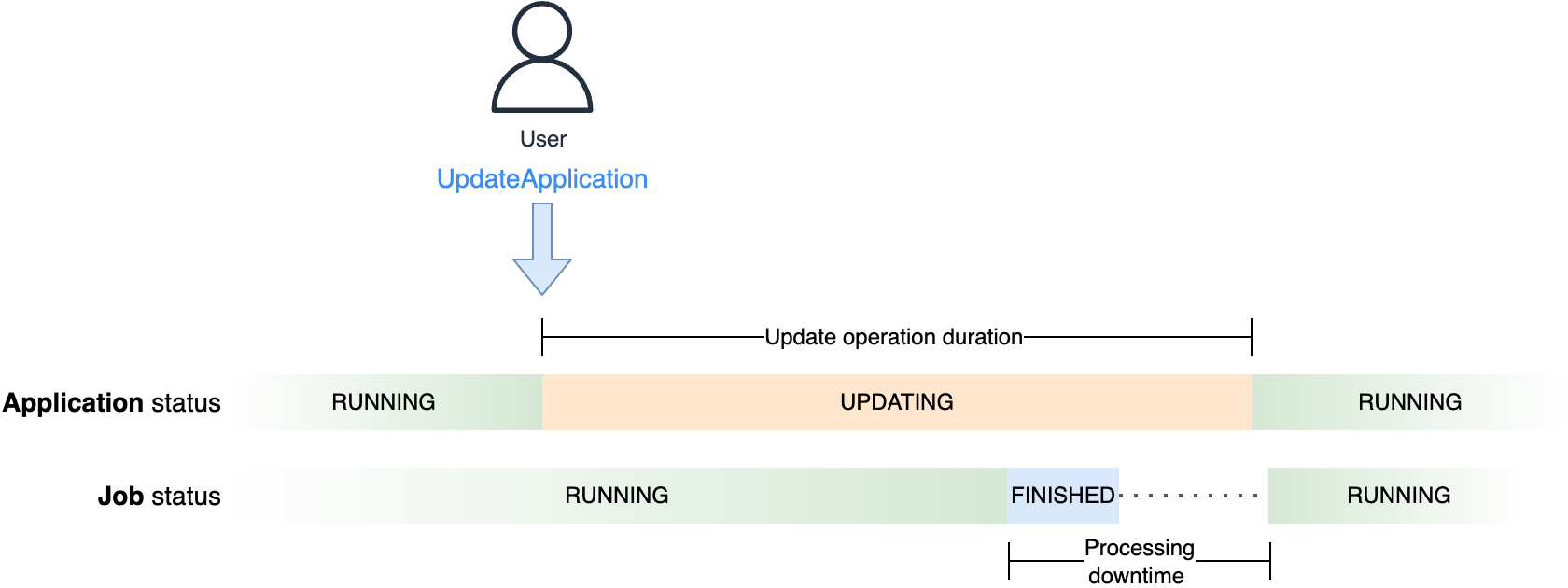
We now have seen how Flink is designed for robust consistency. To ensure exactly-once state consistency, Flink quickly stops the processing to deploy any modifications, together with scaling. This downtime is required for Flink to take a constant copy of the applying state and reserve it in a savepoint. After the change is deployed, the job is restarted from the savepoint, and there’s no knowledge loss. In Managed Service for Apache Flink, updates are totally managed. When snapshots are enabled, UpdateApplication routinely stops the job and makes use of snapshots (primarily based on Flink’s savepoints) to retain the state.
Flink ensures no knowledge loss. Nevertheless, your enterprise necessities or Service Stage Goals (SLOs) may additionally impose a most delay for the information obtained by downstream methods, or end-to-end latency. This delay is affected by the processing downtime, or the time the job doesn’t course of knowledge to permit Flink deploying the change.With Flink, some processing downtime is unavoidable. Nevertheless, Managed Service for Apache Flink is designed to attenuate the processing downtime whenever you deploy a change.
We now have seen how the service runs your utility in a devoted cluster, for full isolation. While you situation UpdateApplication on a RUNNING utility, the service prepares a brand new cluster with the required quantity of assets. This operation may take a while. Nevertheless, this doesn’t have an effect on the processing downtime, as a result of the service retains the job operating and processing knowledge on the unique cluster till the final attainable second, when the brand new cluster is prepared. At this level, the service stops your job with a savepoint and restarts it on the brand new cluster.
Throughout this operation, you might be solely charged for the variety of KPU of a single cluster.
The next diagram illustrates the distinction between the period of the replace operation, or the time the applying standing is UPDATING, and the processing downtime, observable from the job standing, seen within the Flink Dashboard.
You may observe this course of, holding each the applying console and Flink Dashboard open, whenever you replace the configuration of a operating utility, even with no modifications. The Flink Dashboard will turn into quickly unavailable when the service switches to the brand new cluster. Moreover, you possibly can’t use the script we offered to examine the job standing for this scope. Although the cluster retains serving the Flink Dashboard till it’s tore down, the CreateApplicationPresignedUrl motion doesn’t work whereas the applying is UPDATING.
The processing time (the time the job isn’t operating on both clusters) relies on the time the job takes to cease with a savepoint (snapshot) and restore the state within the new cluster. This time largely relies on the scale of the applying state. Information skew may additionally have an effect on the savepoint time as a result of barrier alignment mechanism. For a deep dive into the Flink’s barrier alignment mechanism, confer with Optimize checkpointing in your Amazon Managed Service for Apache Flink functions with buffer debloating and unaligned checkpoints, holding in thoughts that savepoints are at all times aligned.
For the scope of your automation, you usually wish to wait till the job is again up and operating and processing knowledge. You usually wish to set a timeout. If each the applying and job don’t return to RUNNING inside this timeout, one thing in all probability went improper and also you may wish to elevate an alarm or pressure a rollback. This timeout ought to think about the complete replace operation period.
Conclusion
On this submit, we mentioned attainable failure eventualities whenever you deploy a change or scale your utility. We confirmed how Managed Service for Apache Flink rollback functionalities can seamlessly carry you again to a secure place after a change went improper. We additionally explored how one can automate monitoring operations to look at utility, job, and subtask standing, and find out how to use the fullRestarts metric to detect when the job is in a fail-and-restart loop.
You must know what you’re spending, the place your cash is being spent, and methods to plan for the longer term. No person needs a shock invoice—and that’s the place Microsoft Value Administration is available in.
Whether or not you’re a brand new pupil, a thriving startup, or the most important enterprise, you’ve monetary constraints. You must know what you’re spending, the place your cash is being spent, and methods to plan for the longer term. No person needs a shock invoice—and that’s the place Microsoft Value Administration is available in. We’re at all times searching for methods to study extra about your challenges and assist you do extra with much less.
Listed here are a couple of of the newest enhancements and updates (July 2025):
Let’s dig into the main points.
Service Principal help for Companion Admin Reader position (EA oblique companions)
We’re excited to announce that Azure now helps assigning the Companion Admin Reader position to Service Principals. This enhancement empowers Enterprise Settlement oblique companions (CSPs who handle buyer Azure prices) to programmatically entry value information throughout their prospects’ enrollments below their Companion Buyer Quantity (PCN) through Azure Lively Listing purposes—with out counting on interactive person accounts.
Why this issues:
Managing cloud prices throughout a number of prospects is complicated and may be error-prone when counting on guide exports or shared credentials. Companions want safe, scalable, and automatic entry to value information to combine insights into their instruments and optimize spend in actual time.
With these enhancements, companions can now:
Automate value information retrieval securely utilizing Azure Lively Listing service principals (no shared person credentials).
Combine Value Administration information into accomplice billing instruments, dashboards, or workflows utilizing APIs.
Preserve robust governance and management entry to billing scopes with Azure Function-Based mostly Entry Management.
Allow close to real-time monitoring, bill reconciliation, and proactive value optimization throughout a number of prospects.
When working with estimates within the Azure Pricing Calculator—that embody a number of companies—scrolling via all the main points can grow to be overwhelming. To simplify your view, click on the collapse button in your estimate. This immediately minimizes the detailed configuration for all companies in your estimate, leaving simply the abstract line seen.
Why this helps:
Reduces pointless scrolling when managing massive estimates.
Makes it simpler to concentrate on the companies you wish to evaluate or alter.
Retains your workspace clear and arranged, particularly when sharing estimates with others.
Attempt collapsing companies the subsequent time you construct a fancy estimate. It’s a small trick that makes a giant distinction in navigating your pricing situations!
New methods to save cash with Microsoft Cloud
Listed here are new and up to date provides you may be all in favour of for value financial savings and optimization from July and August 2025:
Public preview: Azure Storage Mover–free Amazon Internet Companies S3-to-Azure Blob migration. Now you may transfer information from Amazon Internet Companies S3 to Azure Blob Storage securely and at no extra value utilizing Azure Storage Mover. This totally managed service simplifies multi-cloud or full migration situations with out third-party instruments, decreasing complexity and bills.
New movies and studying alternatives
We added a number of new movies on your viewing and studying. Whether or not you’re new to Value Administration or require a refresher, these movies will show to be extremely helpful:
Documentation updates
The Value Administration and Billing documentation continues to evolve. Listed here are some our new and up to date paperwork from July and August:
Handle Azure Reservations: Up to date on July 8 to make clear reservation scope adjustments, splitting reservations, and limitations on billing subscription adjustments.
Cost again Azure saving plan prices: Revealed on July 9 to elucidate chargeback/showback for financial savings plans utilizing amortized value and API queries.
Handle Azure prices with automation: Up to date on July 10 so as to add greatest practices for Value Particulars API, automation workflows, and dealing with massive datasets.
Permissions to view and handle Azure reservations: Up to date on August 21 to develop steering on Function-Based mostly Entry Management roles, billing roles, and delegation for reservation entry.
Need to keep watch over all documentation updates? Try the change historical past of the Value Administration and Billing documentation within the Azure Docs repository on GitHub. In case you see one thing lacking, choose Edit on the prime of the doc and submit a fast pull request. You can too submit a GitHub problem. We welcome and admire all contributions!
What’s subsequent for Value Administration
These are just some of the updates from the final two months. Don’t neglect to take a look at earlier Microsoft Value Administration updates for extra ideas and options. We’re at all times listening and making steady enhancements based mostly in your suggestions—please maintain it coming!
Comply with the staff, share your concepts, and become involved:
Keep tuned for extra in subsequent month’s replace.
Associate Viewers:#AllPartners #PartnersMakeMorePossible Related to: #Becomingfrontier #AI #MicrosoftCopilot
There’s a brand new class of group rising—Frontier Companies. These business leaders are utilizing AI to counterpoint worker experiences, reinvent buyer engagement, reshape enterprise processes, and picture the following huge leap in innovation. They’re shifting sooner, adapting faster, and attaining extra—all whereas setting the usual for what’s attainable within the period of AI.
At Microsoft, we all know that Frontier Companies mix world-class expertise and human ambition. Meaning pairing the ability of Microsoft AI applied sciences like Microsoft Copilot and Azure AI Foundry with the creativity, curiosity, and collaboration of individuals. It’s this mix that transforms concepts into influence, driving development and scale.
Adopting a Buyer Zero mindset to steer by instance
At Microsoft, we imagine in being the primary and finest clients of personal merchandise—or “Buyer Zero.” That fundamental tenet has guided our method to Copilot, with profound outcomes. Put merely, top-of-the-line methods to show the ability of AI is to expertise it.
My crew and I’ve absolutely embraced the Buyer Zero mindset, utilizing and experimenting with the very expertise we advocate to our clients. AI has change into a every day a part of our workstream, with crew members utilizing it for vital duties like creating brokers in Copilot Studio, leveraging M365 Copilot throughout our workflows, and sharing finest practices overtly.
Being Buyer Zero delivers a plethora of advantages for our clients, together with:
Confirmed ROI by means of lived expertise: By utilizing our personal expertise, we are able to monitor tangible outcomes, from value financial savings and elevated productiveness to stronger worker engagement and share these insights immediately with clients. Our personal information turns into the proof factors, making us dwelling case research.
Skilling and constructing expertise: Our first-hand use of our personal instruments means we deepen our personal AI abilities and may information clients with in depth, sensible information throughout varied use instances.
Sparking innovation: By experimenting internally, we uncover new concepts and floor potential challenges early, serving to clients transfer sooner with confidence.
Microsoft + companions: Accelerating the frontier
The time is now for AI management. Microsoft’s 2025 Work Development Index confirms what many people already really feel: 2025 is the yr AI sparks our potential.
82% of leaders say now’s the time to rethink technique and operations.
81% count on AI brokers to be embedded of their methods inside the subsequent 12–18 months.
Frontier Companies are pulling forward. Amongst their information employees:
71% say their firm is flourishing.
55% report doing extra significant work.
93% really feel optimistic concerning the future.
So how will we gas the spark?
Scalable AI capability fused with human ingenuity is now not elective. It’s the brand new baseline for aggressive benefit.
Companions driving frontier outcomes
Among the best perks of my job is seeing the unimaginable innovation taking place throughout the Americas, and the way our companions are serving to organizations throughout the area and the globe flip AI potential into measurable outcomes with Microsoft applied sciences.
Listed below are only a handful of examples:
Accenture (by means of the deployment of the Azure AI Foundry):
Achieved a 50% discount in time to construct AI purposes.
Delivered a 30% effectivity increase and 20% value discount.
Deployed greater than 75 generative AI use instances, with 16 in full manufacturing.
EY(utilizing Microsoft Copilot in Energy Platform):
Elevated cleared automated funds by 50%.
Saved 230,000 hours yearly from extra environment friendly processes.
Decreased coaching time from two weeks to simply two days.
Strengthened crew experience, focus, and accuracy.
These tales aren’t simply spectacular stats. They’re proof that Frontier Companies are usually not a distant imaginative and prescient. They’re right here right now.
Companions’ function in constructing Frontier Companies
As a Microsoft accomplice, you’re the important spark that helps clients assess their AI readiness, discover high-impact use instances, and set up facilities of excellence. It’s by means of your management that organizations transfer from early adopters to true Frontier Companies, delivering breakthrough influence and development for all of us.
Now could be the time to maneuver from concepts to influence. Right here’s how one can cleared the path:
Be your individual finest case examine: act as Buyer Zero by using the options you advocate, constructing your individual brokers, and embedding AI throughout your operations. Your metric-backed journey turns into a strong story you possibly can share.
Degree up by means of the Microsoft AI Cloud Associate Program (MAICP): by investing in your skilling, attaining designations, deepening specializations, and maximizing advantages and incentives, you not solely speed up your individual transformation, you additionally mannequin what Frontier Companies seem like in follow.
We’re standing at a turning level. Frontier Companies are already proving what’s attainable. Collectively, we will help put together our clients to steer their industries into the longer term.
The LiDAR sensor is predicated on the success of the TrueView 540, contained in a extra light-weight and accessible package deal.
Las Vegas, Nevada – Stay, from the 2025 Business UAV Expo, GeoCue, a worldwide chief in aerial mapping {hardware} and software program options, broadcasts the launch of the TrueView 539—a compact, light-weight LiDAR and imaging system that delivers engineering-grade accuracy at a extra accessible worth level.
Constructed upon the confirmed success of the TrueView 540, the brand new TrueView 539 retains the expertise, precision, and reliability of its predecessor whereas providing a extra streamlined, reasonably priced resolution for geospatial professionals.
“We added the TrueView 539 to fulfill the wants of aerial surveyors who require engineering-grade efficiency in a lighter and extra accessible package deal,” mentioned Frank Darmayan, CEO of GeoCue. “By balancing highly effective {hardware} with our LP360 software program, we’re making it simpler for professionals to seize high-quality knowledge and generate dependable deliverables.”
Weighing simply 1.45 kg, the TrueView 539 integrates seamlessly with most business UAV platforms, that may carry the payload. The system features a cutting-edge LiDAR sensor with as much as 6 returns, a 26MP world shutter full-frame digital camera, and delivers accuracy within the 2 to five cm vary.
A Excessive-Efficiency System Designed for Accessibility
In line with Vivien Heriard-Dubreuil, CEO of mdGroup, GeoCue’s dad or mum firm, “The TrueView 539 is a direct response to the rising want for engineering-grade LiDAR that’s each light-weight and accessible. Many geospatial professionals have been searching for a system that meets technical necessities with out exceeding challenge budgets. That’s the place the brand new TrueView 539 is ideal.”
The LiDAR sensor is designed to penetrate dense vegetation utilizing superior multi-target capabilities, supporting as much as 6 returns per pulse, permitting customers to create correct DEMs and DSMs even in complicated environments. With long-range scanning as much as 600 meters and 500,000 factors per second, the system ensures wealthy, high-resolution knowledge seize throughout all kinds of terrain.
Seamless Integration with LP360 and GeoCue’s Increasing Portfolio
The TrueView 539 additionally comes with LP360 Drone processing software program, enabling customers to rapidly course of, visualize, and extract worthwhile knowledge in an intuitive, GIS-based workflow. Non-compulsory software program add-ons like Strip Align for Drone, Photograph, 3D Accuracy, and extra can be found to additional refine knowledge.
“The introduction of the TrueView 539 strengthens our rising product line of LiDAR mapping options,” mentioned Vincent Legrand, Vice President of International Gross sales at GeoCue. “From high-end UAV sensors to handheld and cellular methods, GeoCue is dedicated to delivering high-quality options backed by seamless {hardware} integration, cutting-edge software program, and the trusted help our prospects depend on.”
The TrueView 539 is now obtainable by means of GeoCue and its community of licensed distributors. This launch continues GeoCue’s mission to empower geospatial professionals with sensible, exact, and scalable instruments to deal with real-world challenges in surveying, engineering, forestry, infrastructure, and past.
About GeoCue
GeoCue brings geospatial consultants the easiest in drone, cellular and land surveying gear, geospatial level cloud software program, workflow, coaching, and help for high-accuracy LiDAR and Imagery 3D mapping to assist civil engineering and surveying professionals obtain profitable knowledge assortment, processing, and administration.
With TrueView LiDAR/Imaging sensors and LP360 level cloud knowledge processing software program, we’re the chief in LiDAR mapping processing in North America capable of meet prospects the place they’re when it comes to expertise, adoption, finances, and sources.
Former president of Teradyne Robotics Ujjwal Kumar (left) and his successor Jean-Pierre Hathout (proper).
Ujjwal Kumar introduced on LinkedIn yesterday that it was his final day as president of Teradyne Robotics Group. He’ll stay with the corporate by means of September 2025 to assist his successor, Jean-Pierre Hathout, transition into the position.
“Within the final 2+ years at Teradyne Robotics, I’ve been pleased with working with an unbelievable world staff in increasing the product & buyer portfolios throughout Common Robots and Cell Industrial Robots, extending our world footprint, championing the unbelievable potential of Bodily AI, and above all serving to clients to remodel the way in which they work,” Kumar wrote.
Kumar stated he’ll proceed to pursue his ardour for enterprise transformation, bodily AI, trade 5.0, and automation, however didn’t share the place he can be heading subsequent.
The Robotic Report reached out to each Kumar and Teradyne president and CEO Greg Smith. Kumar stated he’ll communicate to us after he broadcasts his subsequent transfer. Smith stated he can speak subsequent week when he’s again from touring.
Teradyne Robotics contains collaborative robotic (cobot) arm chief Common Robots (UR) and autonomous cellular robotic (AMR) developer Cell Industrial Robots (MiR). The firm has struggled this yr to match earlier years’ income. For instance, the group generated $75 million within the second quarter of 2025, representing a 17% year-over-year decline.
Earlier this yr, Teradyne Robotics laid off about 10% of its workforce, citing the necessity to align operations with market circumstances. The group has additionally undergone management transitions at each UR and MiR, strikes the firm stated are aimed toward sharpening strategic focus and enhancing execution throughout each companies.
In December 2024, UR introduced it was establishing manufacturing capabilities in Nantong, China. This was the primary abroad manufacturing facility for Denmark-based UR, which stated on the time it was trying to considerably develop its presence in China, the world’s largest marketplace for industrial robots. To satisfy growing Chinese language demand, is producing two cobots particularly for China: the UR7e and UR12e.
“I’m excited to have the ability to step into this position the place I can mix my expertise of and keenness for each cobot and AMR automation,” stated Hathout. “This can be a additional alternative to leverage the numerous technical and business synergies between the 2 manufacturers at a time of fast innovation and rising market potential.”
Hathout brings over 20 years of worldwide administration expertise, together with 17 years at Bosch, and most just lately led MiR to strengthen its product portfolio and world place. He’ll proceed to steer UR in his new place.
“We’re thrilled for JP to step into this new position of main the Robotics group,” stated Greg Smith, President and CEO of Teradyne. “The robotics trade is fast-changing, and I’m assured in JP’s potential to navigate the challenges and lead Teradyne Robotics to attain its progress objectives within the years to come back.”






")