As the global community strives to combat climate change, today’s influential energy industry leaders are increasingly seeking innovative solutions to propel sustainability and efficiency, driving transformative progress. With a pressing sense of urgency, as rapidly growing energy needs and the persistent reliance on fossil fuels threaten to propel greenhouse gas emissions even higher by 2035.1 As global leaders strive to reduce greenhouse gas emissions, the carbon capture and storage (CCS) industry has emerged as a crucial component in this effort. This encompasses various technologies designed to capture, transport, and store carbon dioxide (CO2), offering a promising solution for mitigating climate change by capturing and utilizing the emissions from power plants, industrial processes, and even direct air capture.2The contaminated waste was buried underground to prevent its entry into the environment. Microsoft is actively collaborating with major power companies to develop innovative industrial carbon management solutions. The partnership between the Norwegian authorities and energy companies Equinor, Shell, and TotalEnergies has successfully gone live as one notable instance of this collaboration. As part of a comprehensive strategy to accelerate decarbonization and combat emissions, this pioneering program aims to propel humanity towards a more sustainable tomorrow.
Microsoft for power and assets
Unlock unparalleled insights and decision-making capabilities within the power and assets sector by leveraging trusted knowledge and cutting-edge AI solutions.
Transforming the global energy landscape requires a monumental effort, fueled by collaborative endeavors and innovative advancements. Standardized knowledge models and secure knowledge sharing, combined with operations knowledge management, empowered by Azure AI, can accelerate innovation across the entire carbon capture and storage value chain. As the Copilot and Azure Information Supervisor for Power, advanced knowledge and AI capabilities are leveraged, seamlessly integrating diverse business datasets, functions, and multiple cloud providers to efficiently manage complex workloads at an international scale, and rapidly ingest data for real-time analytics and informed decision-making. These advanced capabilities ultimately enable power companies to accelerate their shift towards more sustainable operations by reducing costs, risks, and timelines associated with their intricate operational requirements.
Elevating Power Operations through Contemporary Knowledge Management Strategies
Modernization of information systems plays a crucial role in promoting sustainable development and effective carbon capture and storage (CCS) initiatives within the power industry. By harnessing the capabilities of Azure Information Supervisor for Power, energy companies can efficiently process and analyse massive datasets, yielding more accurate and comprehensive simulations of subsurface reservoirs. What specific parameters define this optimum condition?2 Storage facilities are designed to ensure the secure and environmentally responsible injection and storage of carbon dioxide.
The platform’s robust, scalable, and secure knowledge management capabilities enable seamless integration of real-time insights and continuous model updates, fostering informed decision-making and risk mitigation. Moreover, the Azure Information Supervisor for Power enables high-performance computing that accelerates simulations, significantly reducing the time needed to plan research and optimize reservoir efficiency. By leveraging these cutting-edge capabilities, energy companies can accelerate their shift towards more sustainable practices, ultimately reducing costs, risks, and timelines associated with their complex operational requirements.
Will AI-driven collaboration revolutionize coding? With GitHub’s latest innovation – Copilot, developers are questioning whether machine learning can truly augment their creative process.
With the convergence of knowledge modernization and advanced analytics capabilities, Azure Information Manager for Power users can leverage Copilot to collaborate seamlessly with intelligent knowledge. The Azure Information Supervisor for Power enables organisations to aggregate and govern domain-specific expertise from across the corporate information landscape, thereby enhancing knowledge ingestion, assessment, and application interoperability. Developed in conformance with OSDU requirements, Azure Information Supervisor for Power optimizes knowledge organization within workflows while providing a reliable data foundation that enables accelerated and timely insights.
Despite this, the enterprise knowledge landscape may extend beyond domain-specific knowledge types, necessitating experience with diverse file formats, including images, data, and information stored across various databases, spreadsheets, and shared folders. The comprehensive value chain encompasses knowledge from operations, supply chain, health, safety, security, and environment (HSE), enterprise resource planning (ERP), legal and compliance, and social media – some of which are hosted on external platforms.
As unforeseen circumstances arise, advanced generative AI capabilities will empower customers to refine their understanding and extract valuable insights more efficiently. One instance of a simple way to access the method that integrates seamlessly with an end-to-end analytics and knowledge platform. By integrating data from Azure Information Supervisor for Power with complementary knowledge sources, you’ll ultimately prepare it for analysis and interaction with AI and Copilot through various evaluations. Customers are empowered to leverage conventional AI-powered workflows, akin to automated data interpretation or event prediction, driven by machine learning algorithms. They will also utilize Copilot to engage in conversations about data or execute sophisticated searches, domain-specific intelligent assistants, and cross-domain advisory services.
By leveraging Microsoft’s Azure Information Manager for Energy, geoscientists and petrophysicists can streamline their workflow, fostering collaboration and accelerating knowledge sharing across the organization, both within and beyond the platform. Knowledge engineers and knowledge scientists have a solid foundation to build comparable solutions for their end-users. The Copilot’s capabilities simplify analysis processes and unlock invaluable knowledge insights, empowering enterprise leaders, knowledge scientists, and geophysicists to make more informed decisions and achieve greater efficiencies in reservoir management?
Enhance Carbon Sequestration and Storage Capabilities while Optimizing Reservoir Management.
Building on the strengths of Copilot and Azure Information Supervisor for Power, we will further optimize CCS to drive progress towards a more sustainable future. Reservoir modeling plays a crucial role in modern power management, occupying a pivotal position in the subsurface storage of carbon dioxide.2. This interdisciplinary field combines geological, geophysical, thermal, and engineering expertise to develop precise models of subsurface reservoirs. Reservoir engineers design complex simulations that accurately replicate fluid behavior within a reservoir, enabling predictions of future performance and optimal implementation of injection and production strategies. As global energy requirements are forecasted to surge a staggering 47% by 2050,2 The imperative for sustainable energy solutions and carbon capture and storage (CCS) technologies has never been more pressing.
Microsoft is collaborating with partners to deliver the efficiency, predictive power, and speed of reservoir simulations and optimisations. Built atop the robust foundation of Azure Information Manager for Power, users can now capitalize on Azure’s formidable enterprise-grade strengths in security, scalability, and dependability while tapping into its domain-specific features and maintaining seamless control over their data.
Historically, figuring out optimum CO2 Storage areas necessitate extensive research, typically extending over multiple months and even years. Microsoft’s collaboration with companions revolutionizes this field by providing scalable and environmentally sustainable simulations. This could enable engineers to concurrently execute multiple configurations using high-performance computing to expedite the analysis of large data sets and identify the optimal storage locations quickly. The capability to conduct rapid and large-scale simulations significantly shortens the timeframe necessary for planning and conducting research.
Unlock Hidden Energies: Tap into Fresh Resources
As a leader in digital transformation, Microsoft is driven by an unwavering commitment to accelerating the global shift towards carbon-free energy sources, fueled by the collaborative power of our partner ecosystem and the seamless exchange of knowledge that enables it all. With Azure Information Governance for Power, businesses can seamlessly connect to a thriving ecosystem of integrated solutions from independent software vendors (ISVs) and the Microsoft suite of productivity tools. Through strategic integration of Microsoft’s capabilities and partner solutions, business leaders can unlock value across their entire organization while driving progress towards sustainable goals.
Able to dive deeper? Explore innovative methods to enhance your learning experience.
1 .
2 .
Uwa Airhiavbere
Lead Global Enterprise for Power and Energy Acquisition Strategies.
Uwa Airhiavbere is the Chief Business Officer of Microsoft’s Worldwide Power & Sources Business group, overseeing industrial technique and development initiatives. He beforehand had a profitable profession at Basic Electrical within the Oil & Gasoline Division. Uwa possesses a Government Master of Business Administration (MBA) from Cornell University, a Master’s degree in International Relations from Johns Hopkins University, and a Bachelor’s degree in Business Economics from Brown University.
Sverre Brandsberg Dahl
What are the key benefits of using Microsoft Power Apps with Microsoft Cloud for Business?
Microsoft Power Apps and Microsoft Cloud for Business offer a powerful combination for businesses. With this integration, users can easily create custom apps to streamline workflows, increase productivity, and enhance collaboration across the organization.
Benefits include:
The ability to create custom apps without extensive coding knowledge
Improved data management through seamless integration with Microsoft 365 services
Enhanced collaboration and workflow automation
Increased agility in responding to changing business needs
Sverre serves as the Basic Supervisor for Microsoft’s Cloud for Business and Power teams. He collaborates with multiple engineering teams to bring cutting-edge advancements in Cloud Computing and Artificial Intelligence to the energy industry, driving innovation and growth. With unbridled enthusiasm for technological advancements and innovation, he is diligently working to position Microsoft at the forefront of accelerating the global adoption of cloud technology, while simultaneously prioritizing the crucial transition to sustainable energy and effective emissions management strategies.
Neeraj Joshi
Vice President of Technical Fellows, Energy and Sustainability Group, Microsoft
Neeraj Joshi serves because the Chief Know-how Officer for WW Power & Sources in IPS, the place he leads in-depth technical collaborations to drive digital transformation inside the Power sector. With a rich legacy spanning over two decades at Microsoft, he has developed an insatiable passion for innovation and a steadfast commitment to empowering forward-thinking organizations as they navigate the complexities of digital transformation. Mr. Joshi holds a Master of Business Administration (MBA) degree from the University of Washington and a Master of Science (MS) in Computer Engineering from the University of Texas at Austin.










 Despite the questionable ethics, individuals willing to compromise their privacy are prepared to pay for this sensitive information, only to see it potentially resold or compromised further once posted on a darknet criminal platform for the highest bidder. Utilizing the provided data, authorized individuals may employ logins and personally identifiable information to:
Despite the questionable ethics, individuals willing to compromise their privacy are prepared to pay for this sensitive information, only to see it potentially resold or compromised further once posted on a darknet criminal platform for the highest bidder. Utilizing the provided data, authorized individuals may employ logins and personally identifiable information to: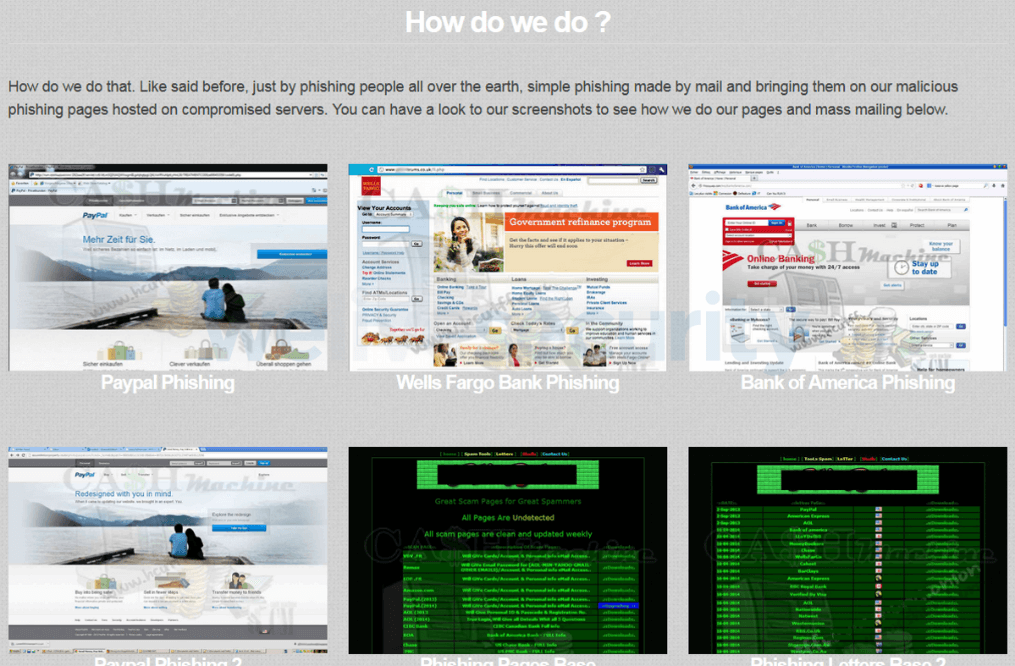








 issued a Part 107 rule governing commercial drone use, effectively clearing the skies for widespread adoption.")


