In this episode of The Drone Radio Podcast, Juan Plaza, CEO of consulting firm XYZ, discusses recent mid-air collisions and their significance for the drone industry and its operators. Hear right here:
Juan Plaza, Chief Executive Officer at Plaza Aerospace, a leading consulting firm headquartered in Boca Raton, Florida, with expertise spanning crewed and uncrewed aviation, Latin American enterprise growth, and GIS consulting. Prior to founding Plaza Aerospace in 2015, Juan accumulated over 26 years as Sales Director for companies such as Autodesk and Trimble Navigation, where he cultivated a network of software and hardware distributors eager to represent new products across Latin America. With over 750 hours of experience in photogrammetry navigation and digital camera operation, Juan possesses impressive credentials, including a business pilot’s license and multi-engine pilot certification.
On December 30, 2023, a helicopter and drone collided mid-air near Daytona Beach International Airport. Initially, the Federal Aviation Administration (FAA) classified the incident as a “collision with an object/terrain,” but it wasn’t until Juan contacted the FAA on behalf of the pilot that the true nature of the collision was revealed?
Missed a current episode? Catch up right here:
As Editor-in-Chief of DRONELIFE and CEO of JobForDrones, the premier platform connecting experts in the drone industry, Miriam McNabb is a keen observer of the burgeoning drone sector and its evolving regulatory landscape. A renowned expert in the industrial drone sector, Miriam has authored more than 3,000 authoritative articles and serves as a prominent global speaker, solidifying her position as a leading figure within the industry. With a degree from the University of Chicago and more than 20 years of experience in high-tech sales and marketing for emerging technologies, Miriam brings unparalleled expertise to her work. What expertise do you offer in the field of drone technology?
Sharifa Alghowiem, an analysis scientist at MIT’s Media Lab’s Private Robots Group, poses with Jibo, a friendly robotic companion designed by Professor Cynthia Breazeal, a renowned expert in human-robot interaction and social robotics.
A child’s quest for emotional intelligence: “As a toddler, I craved a robot that could decode others’ emotions for me,” says Sharifa Alghowinem, an analysis scientist at MIT’s Media Lab’s Private Robots Group. Growing up in Saudi Arabia, Alghowiem’s aspirations were shaped by a desire to one day join the ranks at MIT, driven by a passion for developing Arabic-based applied sciences and creating a robot that could aid her and others in navigating complex environments.
As a child, Alghowinem struggled to decipher the subtleties of human interaction and initially underperformed on standardized tests, but her unwavering determination propelled her forward. Before leaving home to pursue higher education in Australia, she acquired a bachelor’s degree in computing. At the Australian National University, she first discovered affective computing and began working to help AI detect human emotions and moods. However, it wasn’t until she arrived at MIT as a postdoctoral researcher with the Ibn Khaldun Fellowship for Saudi Arabian Women, housed within the MIT Department of Mechanical Engineering, that she was finally able to work on a technology capable of explaining others’ feelings in both English and Arabic? With a childlike sense of wonder, she describes her work as an absolute delight, often referring to the lab as her personal playground.
Despite the risk of failure, Alghowinem is unable to resist a captivating opportunity that sets her heart racing. By collaborating with Jibo, a pioneering robotic companion developed by Cynthia Breazeal, founder of PRG and dean at MIT’s School of Digital Learning, she identified an opportunity to enhance the utility of robots in people’s lives. Breazeal’s analysis delves into the possibility of companion robots transcending simple obedient assistants that respond to transactional directives – tasks such as providing daily weather forecasts, managing shopping lists, and regulating lighting settings. At the MIT Media Lab’s PRG crew, designers are crafting Jibo as a perceptive mentor and friend to drive innovation in social robotics research. Visitors to the MIT Museum can encounter Jibo’s affable personality firsthand.
Alghowinem’s research has primarily focused on mental health care and education, often collaborating with various graduate students and undergraduate researchers through the program. In a landmark study, Jibo employed constructive psychology to guide both younger and older adults through a transformative learning experience. With keen attention to detail, he fashioned his interactions upon the subtle cues, whether verbal or non-verbal, that emerged from the group’s collective dynamics.
By analyzing both verbal and nonverbal cues from a participant’s speech – including prolonged silences and physical gestures such as self-hugging – Jibo can identify patterns and insights that might otherwise remain hidden. When he detects that profound emotions have been shared, Jibo answers with compassionate understanding. When participants remain silent, Jibo poses an inquiring follow-up question: “Can you tell me more?”
Researchers explored whether a robot could facilitate high-quality parent-child interactions while reading a storybook together. Researchers at PRG are collaborating on projects to determine the types of knowledge necessary for robots to understand humans’ social and emotional states.
Saudi-based Analysis Scientist Sharifa Alghowinem collaborates with two visiting college students, Deim Alfozan and Tasneem Burghleh, from Prince Sultan College in Saudi Arabia, as they utilize the cutting-edge technology of Jibo. Gretchen Ertl
“Alghowinem expresses his desire to see Jibo evolve into a comprehensive family companion.” Jibo’s versatility enables it to assume various roles seamlessly, effortlessly transitioning from a trusted companion to remind elderly family members of medication schedules to a playful partner for children, fostering a sense of companionship and connection throughout the household. While Alghowinem is driven to address Jibo’s potential impact on emotional wellness, particularly its role in preventing despair and suicide, it’s unclear how this relates to Jibo’s core function as a social robot. By seamlessly integrating Jibo into daily life, it can identify growing concerns and proactively intervene, serving as a trusted confidant or mental wellness coach.
AlGhowinem’s passion for mentorship can manifest in a desire to guide and educate others, often extending far beyond the realm of artificial intelligence. She takes great care to connect individually with the scholars she mentors each week, fostering meaningful relationships that benefit their academic journeys. Additionally, her efforts were instrumental last year in hosting two visiting undergraduate students from Prince Sultan University in Saudi Arabia, a testament to her commitment to cultural exchange and educational collaboration. With her deep understanding of social-emotional dynamics, she dedicated herself to crafting an opportunity for the two students, together, to attend MIT, where they could mutually support and benefit from each other’s presence. A college student, Tasneem Burghleh, who visited as part of a program, reveals she was driven by a desire to help others after realizing the opportunity to make a difference had fallen outside her reach. Instead, she discovered an “unrelenting passion” that compels her to spread it far and wide, eager to share it with everyone else.
Subsequently, Alghowinem is striving to establish alternatives for children who are refugees from Syria. Despite the challenges, the fundraising strategy aims to empower social robots to teach young learners English language and social-emotional skills, while also providing activities to preserve and promote cultural heritage and Arabic literacy.
Alghowinem notes that they’ve paved the way for Jibo’s linguistic capabilities, having successfully enabled it to engage in conversation in Arabic, as well as multiple other languages. “Now, I’m hopeful that we’ll learn how to empower Jibo to meaningfully assist young learners like myself, as we navigate the complexities of collaborating with our global community.”
Telegram has quietly updated its coverage to enable users to report personal chats to its moderators in response to recent “crimes perpetrated by third parties” on the platform.
The messaging platform, boasting approximately one billion monthly active users, has traditionally fostered an environment of relatively low oversight in regards to user communications.
On Thursday evening, Telegram began rolling out updates to its moderation policy. “All Telegram apps feature ‘Report’ buttons, enabling users to swiftly report suspected unlawful content to our moderators with just a few taps,” the company notes on its updated FAQ page.
To streamline moderation, the platform now provides a dedicated email address for automated takedown requests, guiding users to include links to content in need of moderator attention.
Will this transformation have a discernible impact on Telegram’s ability to respond to inquiries from regulatory bodies? The corporation had previously complied with court-ordered directives to share.
TechCrunch has contacted Telegram seeking comment.
The amendments to the coverage follow Durov’s arrest by French authorities as part of an inquiry into alleged crimes linked to child pornography images, drug trafficking, and fraudulent dealings.
Following his arrest, Pavel Durov issued a statement on his Telegram channel, lamenting the move: “Employing outdated legal frameworks to hold accountable a CEO for misdeeds committed by external parties on the platform he oversees is a misguided approach.”
He posits that a common playbook for nations unhappy with a web service involves taking official action directly against the service, rather than targeting its administrators.
Durov warned that imposing liability on entrepreneurs for potential misuse of their products would stifle innovation, making it unlikely for any inventor to create a new instrument.
What is the purpose of this device at present? Fueled by LG’s innovative Affectionate Intelligence technology, this cutting-edge hub seamlessly integrates devices and curates personalized experiences by analyzing individual user habits and preferences. The smart home permits customers to enhance comfort and luxury within their residences.
The sleek and minimalist hub features a cylindrical shape in understated hues, allowing it to blend seamlessly into any surrounding. Equipped with an AI-powered speaker, the device enables seamless interactions, effortlessly processing and facilitating a diverse range of audio content. Powered by a cutting-edge AI chipset, the ThinQ ON ensures seamless integration with future upgrades.
permit it to . The system also independently showcases a thriving residential environment, alerting clients whenever tasks are completed or issues arise. Customers can easily experiment with or modify device settings by issuing voice commands, allowing them to streamline processes through automated routines.
ensuring seamless installation and universal integration with diverse systems.
With LG Protect, users’ sensitive information is safely secured through robust encryption and secure storage, effectively preventing unauthorized access or manipulation. The ThinQ On represents a significant leap forward in delivering
At the event, visitors can explore LG’s latest AI Residence offerings, including the innovative ThinQ ON, showcased exclusively at the company’s booth in Berlin.
Filed in . Discover the intricacies of, , and as we delve into their unique characteristics and applications.
Thank you to everyone for their assistance and support. ❤️
Last month, I was interviewed by the police for four consecutive days immediately after arriving in Paris. As previously suggested, I was informed that I could potentially be held personally liable for various individuals’ illegal uses of Telegram, since the French authorities failed to receive responses from Telegram itself.
This was astonishing for multiple reasons:
1. Within the EU, Telegram has designated an official consultant that receives and responds to European Union requests. The email address associated with Telegram’s EU channel for law enforcement has been publicly available for anyone in the EU to find by searching “Telegram EU endpoint for law enforcement” on Google.
2. The French authorities employed various tactics to persuade me to seek assistance. As a French national, I was a regular at the French Consulate in Dubai. At a previous point in time, upon request, I individually assisted in establishing a dedicated hotline via Telegram aimed at addressing the pressing concern of terrorism in France.
3. When a user is dissatisfied with a web-based service, the typical course of action is to initiate legal proceedings against the service provider. Implementing outdated legal precedents to hold a CEO accountable for criminal activities perpetrated by third parties on the platform they oversee is a flawed approach. Constructing knowledge is already a challenge in itself? Without accountability, no innovator will create innovative instruments, fearing personal responsibility for their misuse.
Balancing the delicate equilibrium between privacy and security requires meticulous consideration. Reconciling privacy regulations with law enforcement requirements, as well as local laws with European Union guidelines, is imperative. In consideration of technological constraints, it is essential to acknowledge their influence. As a global platform, maintaining consistent processes worldwide is crucial while simultaneously ensuring that these processes are not exploited or abused in countries with limited regulatory oversight or lax enforcement. We have consistently collaborated with regulatory authorities to identify and implement a stable framework. We steadfastly uphold our convictions: our professional standing has been shaped by our unwavering commitment to protecting clients operating in repressive environments. Despite our history of being closed off, we’ve consistently remained receptive to conversations.
Typically, we struggle to find common ground with rural residents regarding the delicate balance between privacy and security. When circumstances dictate, we’re willing to bid farewell to that country. We’ve finished it many occasions. In response to Russia’s demand that we surrender encryption keys for surveillance purposes, we steadfastly refused, subsequently leading to Telegram being banned within the country. When Iran called on us to silence peaceful protesters’ voices by blocking their communication channels, we stood firm and refused – a decision that ultimately led to Telegram being banned in the country. We’re prepared to exit markets that don’t align with our vision, since we’re not driven by financial gain. Driven by a commitment to uphold human dignity, we strive to protect the fundamental rights of individuals, particularly in areas where these freedoms are compromised.
Not everything about Telegram necessarily makes it perfect. While authorities might be perplexed by shipping requests, it’s crucial that we continuously improve this aspect. While certain media outlets may sensationalize Telegram as an anarchic utopia, this portrayal is fundamentally inaccurate. Every day, our team works tirelessly to identify and remove thousands upon thousands of harmful posts and channels from our platform. We regularly publish detailed transparency reviews akin to those found on or . We have established direct hotlines with non-governmental organizations (NGOs) to facilitate the prompt processing of urgent moderation requests.
Regardless, critics continue to assert that more remains to be done. As Telegram’s user base surged to 950 million, the sudden increase in popularity proved a magnet for malicious actors, making it increasingly easy for them to exploit our platform’s vulnerabilities and wreak havoc. I undertook a personal mission to substantially improve matters in this respect. We have already initiated that process internally, and I will provide additional details on our progress to you shortly.
As the month of August unfolds, I am optimistic that concerted efforts will culminate in bolstering the security and resilience of Telegram and the broader social networking landscape. Thank you again for your love and humor. 🙏
I used to excel quickly after launch, but grew frustrated that Google didn’t prioritize speed equally in its latest updates. Now that I’ve had two weeks of using the device, I must concede that my initial assessment was misguided – Google has implemented numerous changes to the phone’s functionality, which are only apparent when used daily.
Hardwired
AC Senior Editor Harish Jonnalagadda explores a wide range of hardware topics, from smartphones to audio gear, storage servers, and networking devices.
The standout feature that sets this device apart is its exceptional build quality; Google’s adoption of a fresh design language for the Pixel 9 Pro XL results in a phone that, although bearing a resemblance to an iPhone with its flat edges, feels significantly more refined and comfortable to hold compared to its predecessors. The innovative design boasts a well-balanced weight distribution, while its square shape and increased width along the mid-structure combine to deliver impressive structural integrity.
Despite my experience with fragile pixels, I was impressed when the Pixel 9 Pro XL survived multiple drops without sustaining damage, indicating Google’s attention to durability in their design. While past Pixels have featured ports and buttons, the Pixel 9 Pro’s build quality finally matches that of a premium device.
The modern era of internet connectivity begins with a fundamental shift in the modem’s role. The Pixel 9 Pro XL is driven by the Tensor G4 processor, which, while not dramatically faster than its G3 predecessor, benefits from the Exynos 5400 modem’s significantly enhanced connectivity capabilities. Despite occasional connectivity issues with previous devices, the Pixel 9 Pro XL excelled, providing a reliable signal throughout my residence community. Although not as robust as its Qualcomm-powered counterparts, the device’s signal strength proved sufficient for everyday use, with no notable drop-offs or interruptions.
The Pixel 9 Pro XL addresses the overheating issue from last year by incorporating a vapour chamber and implementing strict power throttling measures to prevent excessive heat generation. Google arranged for the G4 to throttle sooner than the G3, which is.
The results show that the Pixel 9 Pro XL falls short of its Snapdragon 8 Gen 3-powered counterparts in terms of gaming performance – it throttles excessively, resulting in noticeable stuttering in demanding games.
Notwithstanding its impressive thermal performance, the Pixel 9 Professional XL boasts the most effective cooling system of any phone I tested in 2024; under full load, it never exceeds a mere 42 degrees Celsius, clearly demonstrating Google’s thoughtful configuration of the Tensor G4 processor to prevent overheating? While the Pixel 9 Professional XL may not be a gaming behemoth, it offers a palpable improvement in fluidity for everyday tasks compared to its predecessor, the Pixel 8 Professional. Without any noticeable lag, I’ve experienced seamless performance while working on tasks such as browsing Chrome or scrolling through Instagram on my 9 Professional XL.
Despite being warned, the Pixel 8 Pro’s multitasking capabilities were marred by its tendency to terminate background applications after several hours of use. On the 9 Professional XL, Google made modifications, allowing multiple background apps to run without consuming any significant processing power. While seemingly minor flaws, these recurring irritations have persisted across earlier Pixel models; it’s refreshing to see Google tackling these deficits in their latest device.
Android’s trusted ally on its digital realm?
There are several issues that Google intends to rectify. The Pixel 9 Professional XL exhibits frustratingly slow storage times for portrait shots, resulting in a noticeable delay before they’re saved to the gallery, whereas shutter lag also compromises the camera’s responsiveness, making it cumbersome to capture multiple portraits consecutively – an issue not seen on other top-tier devices.
Following extensive use of the phone’s camera to capture over 100 images, it appears that Google intends to upgrade or modify its camera hardware. While the Pixel 9 Pro XL excels in software tuning, it falls short of matching the camera prowess of top-tier devices like the Vivo X100 Pro Extreme.
I’ve never experienced any difficulties with Google’s software endeavors; in fact, I’ve always tolerated subpar hardware due to the exceptional software it supported. The Pixel 9 Pro’s expansive space is a haven for enthusiasts, as Google further amplifies its AI-driven innovation. Major telephone manufacturers offer varying levels of AI-driven features, with Google offering notable enhancements that I personally utilize effectively.
The Pixel 9 Pro XL exudes a refined quality, its construction demonstrating a commitment to precision engineering, unlike some flagships that sacrifice build tolerance for the sake of aesthetics – this is no such phone, as it pairs an exceptional camera with top-notch craftsmanship. The balance of the device’s remaining hardware components is impressive, with the Pixel 9 Pro XL standing out for its significant advancements in this area.
The Pixel 9 Pro XL boasts an upgraded construction quality compared to its precursor, featuring a multitude of subtle hardware enhancements that yield tangible benefits in everyday usage.
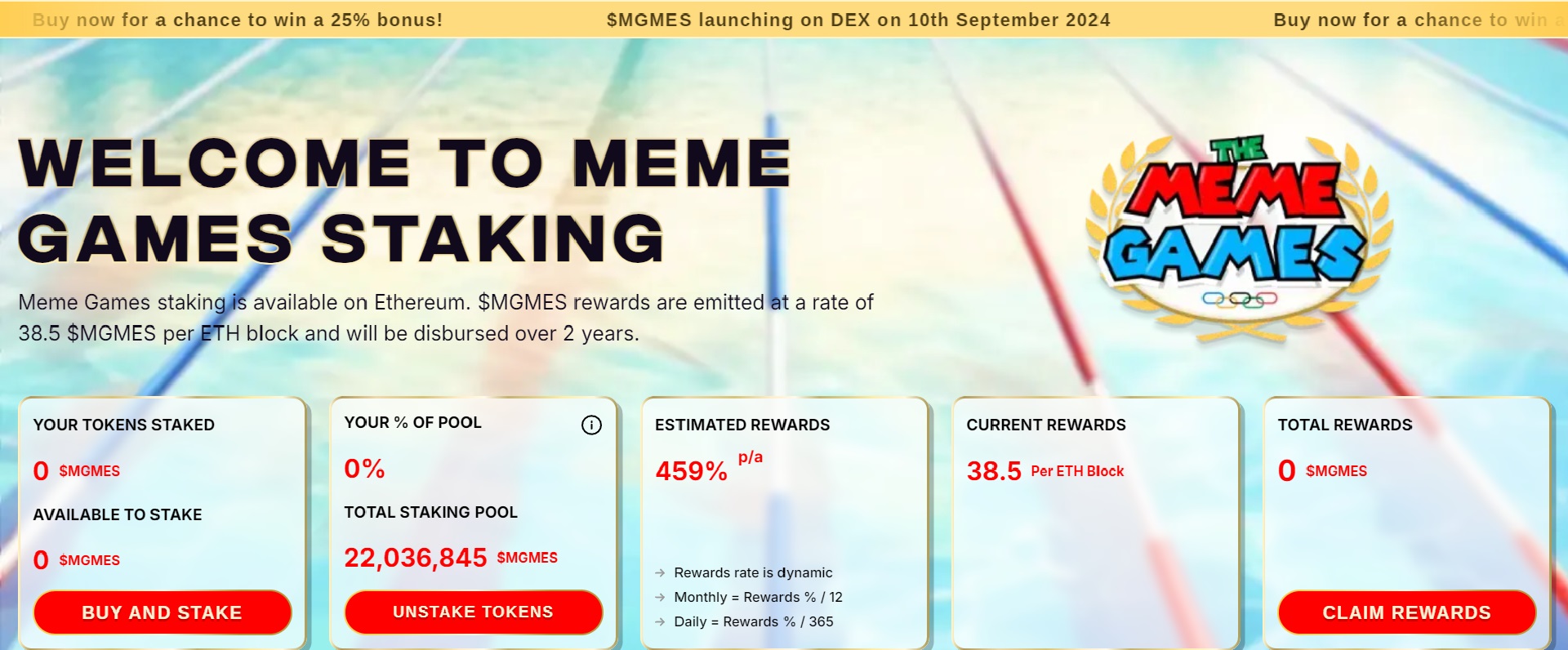
The Meme Games, inspired by the 2024 Olympics, offers a unique opportunity for participants to engage in a presale, where they can select their preferred meme characters to compete for rewards.
By its scheduled September 10th launch date, the ongoing pre-sale has attracted considerable attention, surging past $400,000 in just a short span of time, with only around 7 hours remaining before the next price adjustment takes effect.
Will MGMES’ Exclusive 25% Bonus Opportunity Expire Soon?
With the Memetron Video Games project rapidly garnering attention in the burgeoning cryptocurrency sector, it has successfully secured over $400,000 in funding thus far during its ongoing presale.
This opportunity offers a significant alternative for early investors, leveraging a thriving ecosystem and growing momentum that can yield substantial returns.
At its core, The Meme Video games is a modern play-to-win platform where contributors choose their favourite meme rivals – icons like PEPE, DOGE, BRETT, TURBO, and WIF – and compete them in meme-themed events for an opportunity to win bonuses.
In this unique ecosystem, users can participate by acquiring tokens, selecting a preferred meme-inspired athlete, and competing against other enthusiasts in designated events. When the user’s chosen champion emerges victorious, they receive a 25% boost to their token portfolio, providing an added incentive to engage with the platform.
This gamified construction raises the stakes of the challenge, making it more engaging and participatory than a traditional cryptocurrency fundraising approach, with ongoing opportunities for enthusiastic participants to amplify their returns through active involvement.
The pre-sale portion remains open, allowing contributors to acquire tokens using Ethereum, USDT, bank cards, and Binance Coin (BNB). Early traders are likely to reap a positive return as the campaign strives to reach its funding target of $1.1 million.
Investors currently participating in this opportunity are well-positioned to reap significant benefits from staking rewards, boasting an impressive estimated annual percentage yield (APY) of 459%. This impressive yield-generating opportunity empowers investors to generate significant passive income simply by locking in their tokens.
As the Meme Video Games’ platform stabilizes with deliberate post-launch events, it’s expected to draw in a broader community of participants.
Interested in trading? Visit our comprehensive resource page for more information.
Can Memes Sustain Long-Term Engagement: Lessons from the Meme Video Games’ Innovative Approach to Esports?
Within The Meme Games’ ecosystem, a unique blend of competitive fervor and financial incentives converges, marrying the cutthroat essence of internet memes to the lucrative benefits of cryptocurrency staking.
The “Degen 2024 Olympic Token” cleverly leverages the thrill of competition, infusing an Olympic flair that heightens excitement among customers as they witness their beloved meme characters vying for coveted digital riches.
As the presale advances, the initiative will incorporate regular tournaments where participants can consistently compete, offering expanded opportunities for them to refine their skills and grow their assets.
The leaderboard system is poised to spark intense competition and enthusiasm, further energizing community spirit.
Discover what’s next for The Meme Games with us?
Respected publications such as The Times of India, Watcher.Guru, Benzinga, Cryptopolitan, Binance Blog, TradingView, CoinCodex, and CryptoNewsZ have given attention to Meme Video games.
The degree of media protection surrounding this venture lends significant credibility to its challenge, leading many to anticipate that prominent endorsements will significantly boost the token’s prospects at launch.
The Meme Video Games has allocated 38% of its total supply for the presale, a decision that aligns with strategic business objectives and tokenomics considerations. Approximately 10% of the total availability is allocated for staking rewards, providing an opportunity for early investors to benefit from long-term holding strategies and capitalize on their initial commitment.
The initiative has allocated a dedicated 9.3% to sporting victories, thereby ensuring the play-to-win dynamic remains robust and enduring. In addition, a significant 15% of our overall capacity is allocated to promoting our brand through targeted advertising and marketing initiatives, potentially encompassing collaborations with social media influencers and other strategic outreach endeavours.
This strategic allocation sets the stage for significant media attention, crucial for the long-term viability and prosperity of this cryptocurrency endeavour. A significant 15% allocation for advertising and marketing speaks volumes about the company’s commitment to driving growth and expanding its customer base.
The Meme Video Games are poised to prioritise influencer endorsements and strategic partnerships, undoubtedly allowing the challenge to grow in visibility and attract even more contributors.
As influential key opinion leaders become increasingly involved, the challenge’s appeal is expected to increase significantly, thereby amplifying the likelihood of achieving tangible value and operational efficiency once the pre-sale period concludes?
To participate in the MGMES token presale, visit
Conclusion
The Meme Video Games offers a tantalizing opportunity for those looking to capitalize on this emerging trend, seamlessly blending meme culture with lucrative rewards and a user-friendly gaming experience that leverages social interaction.
As the challenge advances, it’s now within striking distance of its ambitious $1.1 million target, providing initial investors with a coveted opportunity to get in on the ground floor at a favorable valuation.
As the presale persists, the token’s value is likely to surge, rendering this a pivotal moment for those seeking to optimize their returns? The Meme Games could well emerge as a standout project in 2024, bolstered by its robust neighborhood support and captivating ecosystem.
Seeking substantial returns on your investments and capital appreciation during the next market upswing? Explore our comprehensive guide to uncover lucrative funding options and maximise your wealth potential.
Cisco’s advocacy network fosters collaboration among its audience, providing a platform for meaningful connections, the expansion of professional and personal networks, and knowledge-sharing opportunities with leading industry experts in their field? One key goal in our advocacy neighbourhood is to foster stronger ties with potential customers. Our Q&A collection permits us to shine a highlight on a few of our most passionate advocates as we study extra about their tales and backgrounds.
Recently, we had the opportunity to sit down with Mateusz Frąk, exploring his path in community engineering and his passion for knowledge-sharing through his blog.
Thank you for joining us today. As a seasoned senior community automation engineer, I’m Mateusz. DSV is a leading global provider of transportation and logistics services. I oversee the design, maintenance, resolution of issues, and optimization of our community’s automated systems. In a corporation that specializes in providing and managing supply-chain solutions to thousands of customers. As a key player, I proactively tackle business challenges, empowering our team of network engineers to craft innovative solutions that minimize manual labor and maximize efficiency. Our team provides a range of tools for the operations crew to swiftly isolate common network issues, thereby accelerating the troubleshooting process.
After turning 18, my professional path began at a technical college where I enrolled as a student. As a novice, I was exposed to various specializations such as programming, databases, and networks, ultimately gravitating towards networks due to my fascination with the intricacies that occur behind the scenes when loading a webpage like Google.
Throughout my career, I evolved from a novice community administrator to a skilled community engineer, ultimately becoming a distinguished community architect. As a community architect, I spearheaded the modernization of our organization’s community by leveraging software-defined networks (SDN) to revitalize core and campus environments, relying on Cisco’s innovative products to drive this transformative initiative. Three years ago, I took the strategic step of transitioning into community automation, capitalizing on the expertise I had developed over time. As this transition seamlessly merged my profound comprehension of community engineering with automation capabilities, I was empowered to develop innovative, eco-friendly, and efficient solutions.
In 2024, I attended the Insider Advocates booth at an industry gathering in Amsterdam, seeking to strengthen connections within my professional network. Following discussions with the neighborhood managers, I have decided to revitalize the community by making targeted improvements.
Cisco Expert Mateusz Frąk reflects on the key takeaways from his DevNet Skilled experience.
The best worth of the neighborhood, for my part, is the power to ask questions on to subject material consultants (SMEs) throughout unique Q&A periods. The insights gathered during these timeframes have been particularly valuable, enabling me to refine my skills and tackle professional hurdles more effectively. I have also established connections with several subject matter experts, leveraging their expertise and applying their insights to the projects I’m currently working on. What’s more, meeting people from diverse parts of the world has proven to be an unforgettable experience. The convenience of my neighbourhood is what allows me to appreciate the challenges of preparing for certification and tackling complex assignments. The Cisco DevNet Skilled certification verifies expertise in designing and implementing community automation solutions throughout the entire life cycle, encompassing ideation, development, deployment, operation, and optimization.
Professionals who freely impart their expertise have long fascinated me, including individuals like John Capobianco, who shares his knowledge on his publicly available GitHub repository, where the book can be found, stating, “I believe in open-source software.” People should have a straightforward gateway to understanding Linux. Here is the rewritten text:
“I believe that open-source tools like Ansible should remain free and accessible. This sentiment inspired me to take it further by advocating for universal access to knowledge.”
I’ve also been impressed by a technical options architect at Cisco, whose engaging and informative technical blogs showcase her expertise and passion for the field. With unwavering determination, he takes on even the most daunting challenges, effortlessly breaking down complex issues into easy-to-understand concepts.
I spend hours each day devoting myself to exploring novel topics and applying scientific principles. As I benefit from the wealth of free resources provided by esteemed organizations like Cisco, as well as talented individuals such as John and Conor, and numerous other technical writers, I am compelled by a strong sense of gratitude to reciprocate by sharing my own knowledge and insights with others.
I hope that my blog will serve as an indispensable asset for anyone embarking on their DevNet Professional odyssey. I aim to support individuals in genuinely feeling less anxious during their preparation and ultimately, the examination itself. Understanding how challenging it must be to maintain poise under such intense pressure. Anyone can achieve this certification with consistent dedication.
By maintaining a weblog, I can effectively hone my technical writing skills, refine my English proficiency, and most importantly, expand my knowledge of the technical field itself. Crafting compelling blog posts demands a thoughtful approach, often necessitating meticulous research to craft pieces that educate as much as inspire readers to reexamine perspectives and explore fresh insights. By doing so, it may prompt them to consider alternative solutions they had not previously considered.
Somewhere, I still have a vision of crafting a comprehensive and informative technical e-book in the future. I envision that my blogging approach will help me cultivate the skills necessary to turn this dream into reality.
As my DevNet-skilled journey persists, I’m committed to documenting my exam attempts, including insights and strategies for overcoming the challenges of a CCIE-level certification. My goal is to empower others by alleviating their sense of being overwhelmed as they prepare for the rigorous demands of this certification.
Upon embarking on my journey, I found a scarcity of resources thoroughly examining these crucial aspects. My initial attempt was hindered by unforeseen factors rather than a lack of comprehension, resulting in a decrease in productivity. Paying close attention to these minute yet crucial details can empower job seekers to manage their anxiety levels more effectively, especially when they’ve gained insight into someone’s experience who has navigated a similar scenario.
As time progresses, I look forward to sharing valuable takeaways from my daily experiences in the IT field, providing readers with a realistic and relatable glimpse into the world of technology. While numerous blogs cater to IT professionals’ introductory needs for specific tools, my objective is to delve deeper, addressing the hurdles practitioners encounter and offering solutions that extend beyond the basics.
If you’re eager to follow along on my professional development journey, particularly my progress in the DevNet Skilled certification program, I’ll be sharing updates and insights on my blog at [insert link]. I frequently share in-depth reflections, innovative concepts, and comprehensive articles on the obstacles and alternatives I face. Whether seeking certification or simply seeking to expand knowledge of community automation, this blog aims to serve as a valuable reference source for readers.
Learn extra advocate interviews.
Join the ranks of innovative thinkers who shape the future of networking as a Cisco Insider Advocate.
A warm welcome awaits your fellow neighbors: Say hello to Mateusz, even if you’ve never had the pleasure of meeting him yet! If you’re a Cisco buyer but not yet a community member, consider joining. You’ll have the ability to:
Experience virtual community building with friends through engaging online neighborhoods.
Can you envision yourself effortlessly captivating Cisco’s executives?
What insights do we gain from sharing our experiences, asking probing questions, and adhering to best practices in our professional lives?
Gain privileged access to exclusive insights, expert analysis, and actionable advice through our ‘Insider’ portal.
What specific skills and characteristics do you wish to cultivate in your personal growth journey?
Unlock the full potential of your business with a powerful partnership – Amplifying Your Organization’s Success Story through Expertise in Action.
Rockset is a cloud-based, real-time search and analytics database that enables users to query large volumes of data in seconds. Rockset empowers our customers to achieve optimal price-performance ratios by dynamically adjusting compute and storage resources according to their unique needs. This approach enhances efficiency and flexibility, but its implementation in a real-time system poses significant challenges. Real-time programs have been developed to leverage instantaneously connected storage, enabling rapid data entry in response to dynamic updates. Here is the rewritten text:
This blog post explores how Rockset achieves compute-storage separation while providing real-time access to data for querying purposes.
Attaining Compute-Storage Separation without Efficiency Deterioration?
Traditionally, database design has focused on working seamlessly with applications that feature immediate access to storage resources. The revised text is: This streamlined system enables effortless access to information, offering substantial bandwidth and swift data entry at critical moments. Modern solid-state drives (SSDs) boast impressive capabilities in handling numerous small random read operations, thereby facilitating seamless index performance. This architecture is particularly well-suited for on-premise infrastructure, where resources are already allocated and workloads are naturally constrained by available capacity. In a cloud-first environment, the capabilities and infrastructure must flexibly respond to changing workloads.
When leveraging a tightly coupled architecture for real-time search and analytics, numerous complexities arise.
Inefficient resource utilisation occurs when scaling compute and storage assets separately, leading to overprovisioning of assets that cannot be scaled independently.
Scaling gradually: To ensure seamless delivery of services, businesses should factor in the time required to spin up additional resources and bring them online, necessitating careful planning for peak demand.
Replicating identical datasets across multiple compute clusters necessitates duplicating the data to ensure each node has access to the same underlying information, thereby facilitating efficient computation.
What if we could centralize all data in a single, universally accessible repository, thereby achieving SSD-like performance? This approach would seemingly address all aforementioned concerns.
By decoupling scalability from data requirements, our compute clusters can adapt to changing workloads more efficiently, without necessitating the retrieval of entire datasets with each scaling event. With advancements in technology, we can now handle larger datasets by simply upgrading our storage capacity. This allows multiple compute nodes to access the same dataset without increasing the number of underlying data copies. A significant advantage lies in the ability to provision cloud infrastructure tailored to optimize compute or storage performance specifically.
What’s the Core of Rockset’s Cloud-Native Architecture?
Rockset’s cloud-native structure is built from the ground up to take advantage of the scalability and flexibility offered by cloud computing. At its core lies a microservices architecture, which enables seamless integration with other services and allows for easy scaling of individual components. This approach also fosters a culture of innovation, as each service can be developed, tested, and deployed independently.
Rockset separates compute from storage. Virtual instances (VIS) are assignments of compute and memory resources responsible for processing and analyzing large datasets through information ingestion, transformation, and querying. Rockset boasts an impressive storage layer comprising numerous nodes connected to high-performance SSDs, fostering exceptional operational speed and efficiency.
Below the surface, its embedded storage engine is designed with mutability in mind. Rockset built upon RocksDB to leverage the advantages of cloud-native architectures. RocksDB-Cloud ensures data resilience in the event of machine failures by seamlessly integrating with cloud providers such as Amazon S3. Here is the rewritten text:
Rockset’s architecture enables a tiered storage structure, where hot data is efficiently stored with one copy on SSDs, while replicas are maintained in S3 for added durability. This innovative, tiered storage architecture significantly enhances the value proposition for Rockset customers by providing unparalleled price-performance.
Following our innovative storage layer design, we internalized the subsequent guidelines.
Efficiently comparable performance to tightly integrated compute-storage architectures?
No noticeable efficiency degradation occurs throughout deployments or when scaling up or down.
Fault tolerance
We leverage RocksDB to power our column-store indexing mechanism at Rockset. This choice allows us to store and query large amounts of data efficiently.
By utilizing RocksDB as an underlying storage engine, we can take advantage of its features like efficient write amplification reduction, which enables faster data ingestion and retrieval. Additionally, RocksDB’s support for in-place updates and snapshots helps ensure data consistency and fault tolerance within our system.
In particular, we use RocksDB to store our column-store indexes, which enables fast querying and aggregation on large datasets.
RocksDB is a popular Log-Structured Merge Tree (LSM) storage engine specifically optimized for handling high volumes of writes. New write operations are initially logged to an in-memory memtable within the LSM tree structure, where data is temporarily stored until it reaches a predetermined capacity threshold. Once this limit is reached, the memtable is automatically flushed and its contents are converted into immutable Sorted Strings Table (SST) records for permanent storage. To mitigate the latency associated with replacing data in a RocksDB database, Rockset leverages fine-grained replication of the memtable, decoupling the real-time update process from the slower SST file creation and distribution workflow?
SST record data are compressed into uniform storage blocks to optimize storage efficiency. Whenever an update occurs, RocksDB erases the existing SST file and generates a fresh one reflecting the latest data. This periodic compaction process, akin to efficient garbage collection in programming languages, systematically eliminates outdated data versions and prevents database sprawl, thereby maintaining optimal performance.
Newly processed SST (Synthetic Source Table) records are securely uploaded to Amazon Simple Storage Service (S3), ensuring the data’s integrity and durability. The newly implemented storage layer efficiently retrieves records data from Amazon S3. Given the immutability of records data, the introduction of a new storage layer is simplified, requiring only the identification and storage of newly generated SST files while discarding previously stored ones.
RocksDB retrieves data in fixed-size chunks, denoted by their offset and size within a file, utilizing the underlying storage layer’s capabilities when processing query requests. RocksDB also caches recently accessed blocks within the compute node to facilitate rapid retrieval.
RocksDB stores both data and metadata files, including manifest files, which maintain a record of the current database state and track the version number of the database. These metadata records are a fixed quantity per database instance, being small in size. Metadata recordsdata being mutable and up-to-date as new SST files are created, but infrequently read and never accessed during query execution.
Unlike SST files, metadata files are stored locally on compute nodes and in S3 for durability, but not on the new storage layer? As metadata records data is typically small and read-only from S3, its storage on compute nodes has a negligible impact on both scalability and efficiency. Therefore, the storage layer is significantly streamlined since it only needs to handle immutable data records.
Rockset efficiently stores information in S3 and accesses data rapidly by reading from high-performance SSDs, ensuring swift query execution.
Data optimally organized within scorching storage layers are strategically situated to facilitate expedient retrieval and processing.
At an exceptionally high level, Rockset’s blazingly fast storage layer is an Amazon S3 cache. Once information is written to Amazon’s Simple Storage Service (S3), it is considered durable and can be retrieved on-demand by downloading it from S3 into a new storage layer. Unlike a traditional cache, Rockset’s cutting-edge storage layer leverages a diverse array of techniques to achieve an extraordinary cache hit rate of nearly 100%.
RocksDB, a high-performance open-source database, seamlessly integrates with the blazing-fast storage layer to empower data-driven applications. By harnessing the power of both worlds, developers can now construct robust and efficient data storage architectures that cater to the most demanding use cases.
Each Rockset collection, or a table within the relational domain, is partitioned into distinct slices, each comprising a subset of SST files. The slice comprises all blocks affiliated with these SST record data. The new storage layer enables granular control over data placement by selecting slices as the unit of information organization.
Used to map slices to their corresponding storage nodes, this mechanism is typically employed between a primary and secondary proprietor storage node. The hash can be leveraged by compute nodes to identify and connect with storage nodes, enabling the retrieval of necessary information. The Rendezvous hashing algorithm operates by employing a unique combination of cryptographic techniques and mathematical formulas to efficiently distribute data across a network.
Each assortment slice and storage node is assigned a unique identifier. These IDs remain static and do not undergo any changes.
Each storage node hashes the concatenation of its own ID with the slice ID to produce a unique identifier.
The ensuing hashes are sorted
The top two storage nodes in the ordered Rendezvous Hashing list are the primary and secondary storage owners of the slice.
Here is the rewritten text:
Rendezvous hashing is a distributed hash table (DHT) implementation used in Rockset to enable efficient data retrieval and manipulation. The algorithm operates by first generating a unique identifier, or key, for each piece of data. This key is then hashed to produce an output that corresponds to a specific node in the DHT.
Rendezvous hashing was selected for information dissemination due to its unique combination of intriguing characteristics, including the ability to.
When the configuration of storage nodes changes, it typically produces limited effects. If a node is added to or removed from the new storage layer, the ownership of assortment slice sets may shift while rebalancing will occur proportionally to 1/N, where N represents the number of nodes in the hot storage layer. This rapid scaling enables the new storage layer to quickly adapt to growing demands.
It accelerates the recovery of the new storage layer after a node failure by distributing the restoration duties across all remaining nodes, allowing them to work in parallel.
When adding a fresh storage node and forcing the owner of a slice to adapt, calculating which node was previously in charge is straightforward. The ordered Rendezvous hashing list will simply shift by one component. That method enables newly provisioned nodes to retrieve blocks from a previous owner while the fresh storage node is brought online.
Each component within the system autonomously determines a file’s location without direct interaction. Minimal metadata required for data retrieval solely includes the slice ID and the IDs of available storage nodes. While that is particularly useful when generating fresh data sets, a centralised placement strategy could actually exacerbate latency issues and compromise system reliability.
While storage nodes operate at the slice and SST file level, consistently fetching all SST records for their assigned slices, compute nodes selectively retrieve only the required blocks per query. As a result, storage nodes exclusively seek limited information about the physical layout of the database, enabling them to identify which SST files belong to a particular slice, while relying on compute nodes to define block boundaries in their RPC requests.
Designing Systems with Reliability, Efficiency, and Storage Effectiveness
A primary objective for all essential distributed applications, aligned with the advent of a novel storage layer, is to remain consistently accessible and exhibit optimal performance at all times. Real-time analytics built on Rockset require rock-solid reliability and ultra-low latency, translating directly to stringent requirements for the underlying storage layer. Given our ability to adapt and learn from S3, we prioritize reliability in our new storage layer, ensuring we can deliver read requests with disk-like latency.
Sustaining efficiency with compute-storage separation
To ensure Rockset’s compute-storage separation remains high-performing, the architecture is optimized to minimize the impact of community calls and reduce latency in retrieving data from disk. That’s due to block requests undergoing processing by the community, which may slow down performance compared to native disk read operations. To mitigate performance bottlenecks, compute nodes for numerous real-time applications store datasets in connected storage configurations to minimize inefficient data retrieval. Rockset leverages caching, read-ahead, and parallelization techniques to mitigate the impact of community calls.
By introducing an additional caching layer, Rockset significantly increases the amount of available cache space on compute nodes through the implementation of an SSD-backed persistent secondary cache (PSC), thereby effectively supporting large-scale processing of extensive data sets. The compute nodes, comprising both an in-memory block cache and a parallel scalable coordinate (PSC). The Persistent Storage Component (PSC) allocates a designated amount of cupboards space on compute nodes for storing RocksDB blocks that have recently been ejected from the in-memory block cache. Unlike the in-memory block cache, the Persistent Storage Cache (PSC) preserves data across restart cycles, ensuring consistent performance by eliminating the need for the application to retrieve cached information from a newly initialized storage layer.
RockSet enhances the capacity of available caching space on compute nodes through its integration with PSC and block-level caching mechanisms.
Question execution has been deliberately engineered to minimize the performance impact of requests traversing the network by leveraging prefetching and parallelism capabilities. In-parallel, blocks are swiftly retrieved to support computational demands, while compute nodes concurrently process existing data, effectively masking latency resulting from the round-trip time required for inter-node communication within a distributed system? Multiple blocks are retrieved in a single request, thereby reducing the number of RPCs and increasing data transfer efficiency. Can Compute nodes simultaneously retrieve blocks from both the native PSC, potentially overwhelming SSD bandwidth, and the novel storage layer, concurrently stressing community bandwidth.
Retrieving blocks obtainable within the sizzling storage layer is 100x quicker than learn misses to S3, a distinction of <1ms to 100ms. In a real-time system such as Rockset, it is imperative to exclude S3 downloads from the workflow path.
When a compute node seeks a block associated with an undetected file in the caching tier, it is essential that the storage node procures the required SST file from Amazon S3 before retransmitting the block to the compute node. To meet the low-latency requirements of our customers, it is crucial that we ensure all necessary data blocks are readily available in the hot storage layer prior to compute nodes requesting them. The novel storage architecture realizes its benefits through a trifecta of innovative mechanisms:
When a newly generated SST file is produced, compute nodes dispatch a synchronous prefetch request directly to the innovative storage layer in real-time. During memtable flushes and compactions, this phenomenon arises. RocksDB ensures the timely availability of a committed memtable flush or compaction by coordinating with the new storage layer to download the file, thereby guaranteeing that the file is accessible before a compute node can request blocks from it.
Upon detection of a novel slice, triggered by a compute node’s submission of either a prefetch or learn block request for a file affiliated with that slice, the storage node takes proactive measures to scan S3 and retrieve the remaining data records for said slice. Records data for each slice shares the same prefix in S3, simplifying the process.
Storage nodes intermittently perform scans of S3 to ensure the slices they manage remain synchronised. Records from regions with gaps in the data are downloaded to fill those gaps, while outdated locally accessible files that are no longer relevant are removed.
Replicas for Reliability
To ensure high availability and reliability, Rockset stores redundant copies of data, typically up to two instances, across distinct storage nodes within its scalable storage layer. Rendezvous hashing is employed to determine the primary and secondary storage nodes for an information slice’s initial placement. As the initial owner, the individual promptly retrieves the datasets for each portion through prefetch remote procedure calls (RPCs) initiated by compute nodes and by examining Amazon’s Simple Storage Service (S3). The secondary proprietor exclusively retrieves the file once it has been processed by a compute node. In order to ensure seamless continuity during a scaling-up process, the original owner typically preserves a duplicate until the new proprietors successfully download the relevant data. During this interval, compute nodes leverage the prior owner as a fallback location for block requests, ensuring uninterrupted operations.
By designing the new storage layer, we discovered that we could potentially reduce storage costs without compromising resiliency by merely duplicating only part of the data. To guarantee that desired information remains accessible despite the potential loss of any copy, we employ a Last Recently Used (LRU) information construction approach. We designate a specific amount of disk space within the scorching storage layer as a last-recently-used (LRU) cache for secondary data copies. Following thorough analysis of manufacturing testing data, it was revealed that maintaining secondary copies for approximately 30-40% of stored information in conjunction with the in-memory block cache and PSC on compute nodes is sufficient to prevent unnecessary S3 retrievals, even in the event of a storage node failure.
By leveraging dynamically resizable last recently used (LRU) caches for secondary data replicas, Rockset minimizes the required disk storage capacity. In various data processing systems, a buffer’s primary function is to facilitate the efficient ingestion and downloading of fresh data into the underlying storage mechanism. We successfully developed a cutting-edge storage layer that prioritizes environmental sustainability by leveraging native disk capabilities and optimizing buffer performance through dynamic Last-Recently-Used (LRU) resizing. As the Local Replication Units’ dynamics evolve, they adapt to shifting demands by reducing the allocation of space for secondary data copies in response to increased requirements for ingesting and downloading information. Rockset leverages the available disk capacity on its storage nodes by effectively employing spare buffering capabilities to store data efficiently.
To accommodate instances where demand grows faster than inventory storage capabilities, we decided to stockpile primary products in Local Rapid Unloading areas (LRUs). If the cumulative ingestion rate exceeds the scalability of the underlying storage layer, it is theoretically possible that Rockset could eventually run out of disk space, necessitating the use of Least Recently Used (LRU) algorithms to prevent ingestion from halting. By caching primary data within the least-recently-used (LRU) cache, Rockset can efficiently evict stale main copy information that hasn’t been recently accessed, thereby freeing up space to ingest and serve fresh queries.
By compressing data storage and utilizing available disk space more efficiently, we were able to significantly reduce the operational costs associated with our new storage layer.
The least recently used (LRU) ordering for all records data is persisted to disk, ensuring its survival across deployments and process restarts. To ensure secure deployment and scaling of the cluster without duplicating the entire dataset.
In a standard rolling code deployment, the process involves gradually phasing out an existing model by shutting it down before introducing and running a newly designed one. With this downtime between courses, we’re faced with an inconvenient interval where the previous course has drained and the new one hasn’t yet been prepared, leaving us to choose between two imperfect options.
Records stored in the storage node will be inaccessible during this period? Can efficient data retrieval persist in such instances, where various storage nodes may need to access SST record sets upon request from compute nodes before the storage node is reactivated?
While executing data replication, redistribute responsibility for stored data from one storage node to another. While this approach maintains efficiency in the new storage layer during deployments, it unfortunately gives rise to significant information movement, thereby prolonging deployment times significantly. The revised text would read: “This feature would also lead to an increase in our S3 pricing due to the sheer volume of GetObject requests.”
The deployment strategies designed for stateless applications are rendered ineffective when applied to stateful programmes such as the newly introduced storage layer. We implemented a zero-downtime deployment strategy that eliminates information drift while maintaining the availability of all related data. Here’s how it operates:
As an incremental upgrade process commences on each storage node, the existing methodology for the preceding code model remains operational concurrently. With its seamless integration onto identical hardware, this course also gains access to all existing SST files stored on that node.
New processes seamlessly assume control from their predecessors, handling block requests efficiently on compute nodes.
Once newly implemented procedures are fully operational, the responsibility for old processes may dwindle.
Courses of operations on the same storage node always fall into the same position in the Rendezvous Hashing ordered list. This allows for a doubling of processing capacity without any data transfer. The “Energetic Model” world configuration parameter allows the system to determine which energy-efficient proprietor is optimal for each storage node. Nodes leverage this information to decide which route to dispatch requests.
Since deployment has occurred without any unavailability, this course has yielded significant operational benefits. Companies can initiate fresh launches with novel twists, while the point at which these newer versions start addressing customer demands is a separable milestone. We plan to introduce new processes, gradually increase traffic to these updates, and swiftly revert back to prior versions without introducing fresh processes, nodes, or data transfer if issues arise. A speedy rollback reduces the probability of any points being awarded.
Scalable Storage Layer Redundancy Optimizations for Enhanced Performance
The new storage layer guarantees ample capacity to store replicas of every file. As the system approaches its capacity limits, additional nodes are automatically added to the cluster to ensure optimal performance. Current nodes rapidly transfer data segments that now reside on the newly established storage node, freeing up space for additional data records.
Despite potential changes by the owner of a knowledge slice, the search protocol guarantees that compute nodes can still locate information blocks. When adding N storage nodes simultaneously, the initial owner of a slice will be no more than the (N+1)st node in the Rendezvous hashing process. If subsequent computation nodes encounter issues, they can always locate a block by concurrently querying the second, third, up to the (N+1)th server on the list, provided the block exists within the scorching storage layer.
When the newly implemented storage layer recognizes that it is operating at an overprovisioned capacity, it will subsequently reduce the number of nodes in use to minimize costs. When removing a single node from the cluster, it will inevitably result in data loss and inconsistencies, as the remaining nodes are left with outdated information previously held by the decommissioned node, which is stored in S3. To avoid being drained, the node to be eliminated transitions into a “pre-draining” state initially.
As data reaches the end of its lifespan, the designated storage node initiates a process by transmitting segments of information to the subsequent storage node in sequence. The storage node is configured using Rendezvous hashing’s in-line setting.
Once all slices are replicated to the next available storage node, the designated delete node moves away from the Rendezvous hash table. Does this ensure that the data remains accessible and queryable at all times, even in scenarios where storage nodes are reduced or optimized?
This innovative design enables Rockset to boast a remarkable 99.9999% cache hit rate for its blazing-fast storage layer, eliminating the need for redundant data replicas. This design enables Rockset to rapidly scale its infrastructure up or down as needed, thereby ensuring optimal performance and responsiveness.
To prevent compute nodes from accessing Amazon S3 during question periods, they must obtain required data blocks from nearby storage nodes that likely possess the necessary information on their local disks. Computing nodes obtain this through an optimistically implemented search protocol.
The compute node initiates a disk-only block retrieval via a TryReadBlock Remote Procedure Call (RPC), targeting the primary proprietor. When attempting to retrieve data from a storage node’s native disk, the RPC will return an empty end result if the requested block is not readily available. The compute node concurrently sends a verification request to the secondary proprietor via the BlockExists method, which returns a boolean indicator specifying whether the block is readily available on the secondary proprietor.
When the initial proprietor returns the specified block within the TryReadBlock response, the learning objective is satisfied. When neither the primary nor the secondary proprietor possesses the required data, yet the secondary proprietor is aware of its existence according to the BlockExists response, the compute node initiates a ReadBlock RPC call to the secondary proprietor, thereby satisfying the learning process.
Rockset leverages an optimistic search protocol to minimize S3 access during query execution. The initial proprietor typically possesses the sought-after file and promptly provides relevant data segments.
When neither proprietor is able to provide instant access to the required data, the compute node initiates a request to the failover location designated for the information slice by sending a BlockExists RPC. Here is the rewritten text: The proposed design features a next-generation storage node grounded in Rendezvous Hashing principles. If the failover indicates regional accessibility of the block, the compute node will read from that location.
The primary and secondary house owners typically lack access to this information, which is instead obtained from the failover location.
If certainly one of these three storage nodes had the file regionally, then the learn might be happy shortly (<1ms). In rare instances where an entire cache miss occurs, the ReadBlock RPC initiates a synchronous data retrieval process from Amazon’s S3 storage system, which typically takes between 50 and 100 milliseconds to complete. While this approach preserves question availability, it may inadvertently introduce a delay in question latency.
In rare instances, when the file cannot be accessed in the scorching hot storage layer, it must be retrieved from Amazon’s S3 repository.
Objectives of this protocol:
To minimize the need for simultaneous S3 downloads, utilize the existing cache in the blazing-fast storage tier when the required blocks are already present and up-to-date. To maximize the probability of detecting the available information block, the compute node may potentially engage with a multitude of failover storage nodes in excess of one.
Reduce load on storage nodes. Disk I/O bandwidth is a highly valued and valuable resource on storage nodes. The storage node responsible for fulfilling the request is the one that should acquire knowledge from the native disk. The block exists; this lightweight operation does not necessitate any disk interaction.
Reduce community site visitors. To conserve unnecessary network resources, a single storage node responds with the requested data. Sending two TryReadBlock requests to the primary and secondary house owners initially could potentially save a single round-trip journey under certain circumstances, thereby streamlining the communication process. If the primary property owner lacks access to this information, but the secondary property holder is aware of it. However, this would effectively quadruple the amount of data transmitted through the network per block transaction. In the vast majority of cases, the initial owner promptly supplies the required blocks, making it unnecessary to invest in redundant data transmission.
To ensure seamless collaboration on Software as a Service (SaaS) project S3, the primary homeowner and secondary homeowners must share identical expectations regarding their respective roles and responsibilities within this digital framework. The TryReadBlock and BlockExists RPCs trigger an asynchronous retrieval from S3 when the underlying file is not locally accessible, initiating a fetch operation to ensure data integrity. The underlying file will remain accessible for any subsequent inquiries.
As the course of recalls prior search results, it optimizes subsequent queries by having compute nodes transmit a solitary TryReadBlock RPC to the previously accessed reliable storage node, thereby leveraging existing knowledge. The revised text is: This optimizes the process by eliminating unnecessary BlockExists RPC queries to the secondary proprietor.
By leveraging the Scorching Storage Layer, organizations can experience a significant reduction in data access times, with latency decreasing by up to 3x compared to traditional storage solutions. This is achieved through the layer’s proprietary caching mechanism, which intelligently identifies and prioritizes frequently accessed data sets.
As a result, businesses can improve their overall operational efficiency, allowing them to better respond to changing market conditions and customer demands. With faster access times, organizations can make more informed decisions in real-time, ultimately driving revenue growth and improved competitiveness.
Additionally, the Scorching Storage Layer provides enhanced security features, including advanced encryption and secure data replication capabilities, ensuring that sensitive information remains protected from unauthorized access or malicious attacks.
Furthermore, the layer’s scalable architecture enables seamless integration with existing infrastructure, allowing organizations to easily adapt their storage needs as business demands evolve. With its proven track record of reliability and performance, the Scorching Storage Layer is an attractive option for businesses seeking a robust and efficient data management solution.
RockSet disentangles compute and storage, thereby achieving performance parity with tightly integrated applications through its blazingly fast storage tier. The novel storage layer is a caching mechanism built upon Amazon S3, designed for optimal performance by significantly reducing the overhead of block requests through efficient community-driven interactions with S3. To ensure optimal performance while maintaining a competitive edge in terms of pricing, this innovative storage solution is engineered to efficiently manage data duplication, maximize available capacity, and seamlessly scale up or down as needed. With the introduction of zero-downtime deploys, we have ensured that the deployment of new binaries does not result in a loss of efficiency.
Because Rockset decouples compute and storage, enabling the execution of numerous functions on live, shared data in real-time. Digital cases can be quickly scaled up or down in response to changing demands and query volumes, without requiring data migration, due to the absence of any information dependencies. Storage and compute resources will be scaled and sized separately to optimize costs by reducing unnecessary expenses, ultimately rendering this approach more cost-effective compared to traditional, monolithic solutions like Elasticsearch.
The introduction of compute-storage separation marked a significant milestone in our journey to optimize the processing of real-time, streaming workloads by isolating distinct compute types – streaming ingest compute and query compute – thereby enabling seamless data flow and efficient resource utilization. As of this blog’s publication, Rockset stands out as a unique real-time database, distinct for its ability to isolate compute-storage and compute-compute operations.
Explore in-depth learning opportunities about our utilization of RocksDB at Rockset by examining these informative blogs:
Authors: Yashwanth Nannapaneni, a software program engineer at Rockset, and Esteban Talavera, another software program engineer at Rockset.
In Australia, the Peter MacCallum Cancer Centre, in collaboration with the John Holland Group, has leveraged Databricks’ cloud-based information and artificial intelligence (AI) platform to overcome key challenges associated with data fragmentation, thereby enabling more effective insights extraction from enterprise data.
Tech leaders from various organisations gathered at Databricks’ Information + AI World Tour in Sydney, Australia last month, sharing their experiences of grappling with familiar challenges: siloed data, competing business domains, integration hotspots, and legacy architectures, ultimately driving the need to seek a cloud-based data solution.
Peter MacCallum Cancer Centre leverages artificial intelligence to streamline data consolidation.
Despite Peter Mac’s robust infrastructure, its ability to effectively harness vast amounts of data was hindered by the complexity of its medical and analytical operations. The organization’s legacy expertise posed a significant risk to its goal of improving cancer patients’ lives, including leveraging AI to accelerate medical decision-making, organic insights, and drug discovery.
Issues with information infrastructure
During the conference, Jason Li, head of the bioinformatics core facility within Peter Mac’s cancer research division, noted that:
Peter Mac struggled to navigate a complex landscape of fragmented data and outdated methods.
Throughout the operations of numerous cancer centers, the sheer volume and intricacy of medical and analytical data presented significant hurdles in realms such as information management and data interpretation.
The moral, privacy, and security implications have been pivotal factors in governing Peter Mac’s data and informing decisions surrounding the deployment of future AI applications.
The integration between medical and analytics departments proves challenging due to vastly differing information requirements in each, thereby exacerbating the issue of info governance.
Li revealed that Peter Mac chose Databricks to streamline data consolidation across its healthcare center, leveraging AI-driven analytics while ensuring compliance with stringent information security and privacy regulations in the healthcare industry.
The emergence of new AI-driven applications holds tremendous potential for transforming various industries and aspects of our lives.
Peter Mac initially assessed the AI capabilities of the Databricks platform through a pioneering AI transformation pilot project.
The centre developed a comprehensive AI lifecycle that leveraged deep learning to analyze and evaluate high-resolution, gigapixel-sized whole-slide images, ultimately quantifying a novel biomarker for accurate breast cancer diagnosis.
Databricks facilitated the entire AI lifecycle – from initial data ingestion to model deployment and monitoring – thereby streamlining the mission’s timeline and value proposition.
The findings of this mission hold promising implications for improving breast cancer diagnosis.
Throughout the mission, Li highlighted pace as a game-changing advantage: “By leveraging Databricks, we’ve accelerated our event timeline by a remarkable fivefold, while concurrently reducing communication overheads among stakeholders by an impressive tenfold, ultimately empowering us to deliver improvements to the market sooner and benefit customers more quickly.”
AI techniques are evolving with a focus on future innovations.
As AI has increasingly become an integral component of Peter Mac’s creative process, its impact on his work is undeniable. Databricks is collaborating with a leading cancer center to deploy its cloud-based analytics platform across three key areas: genomics, radiation oncology, and cancer imaging. Moreover, Peter Mac is:
Enhancing the AI program to integrate mainstream bioinformatics, encompassing inhabitants’ genetic endeavors featuring colossal patterns and vast amounts of genomic data.
Utilizing the latest advancements in Giant Language Models and Retrieval-Augmented Technology to efficiently extract valuable insights from vast collections of medical and radiological case studies?
Intending to leverage Large Language Models (LLMs) in the near future to accelerate advancements in genomics and transcriptomics research, specifically targeting the analysis of RNA and transcriptomes to maintain a competitive edge in cancer research.
John Hollander aims to harmonize knowledge across development projects?
By mid-2023, John Holland successfully delivered 80 major infrastructure projects with a combined value of approximately AUD $13.2 billion. Despite this, Travis Rousell, the corporation’s chief of information and analytics, noted that their legacy information warehouse setup was disjointed and challenging to integrate.
“We’ve overcome the traditional challenges associated with information warehousing and management,” Rousell stated. Our legacy information warehouse has evolved incrementally over a span of two decades. Slowly evolved and fragmented over time, we’ve inadvertently built a complex network of isolated knowledge repositories.
Rousell stated: “While we’ve created BI and experiences at individual touchpoints, aggregating this information to derive actionable insights into customer journeys and behavioral patterns has proven particularly challenging for our organization, hindering our ability to drive meaningful change.”
A centralized intelligence hub providing actionable knowledge.
John Holland established a comprehensive digital hub to facilitate seamless access and sharing of valuable data across the organization, unlocking new levels of productivity and insight. The initiative was designed to foster creativity and accelerate business benefits through the strategic integration of cutting-edge digital technologies and data-driven insights, ultimately driving a comprehensive digital transformation across the organization.
The organisation has sought to:
Integrate disparate data sources to present a seamless and comprehensive view of organizational information across the entire enterprise.
Ensure effective management of information across distinct, self-governed projects.
Focus on data information engineering rather than platform engineering?
Pricing financial savings stem from optimized information management.
To date, John Holland has successfully implemented various core enterprise processes within Databricks’ data lake, including mission administration, mission operations, mission control, security, and fleet analytics.
Because he utilized Databricks, Rousell noted that John Holland had.
Realized a 46% reduction in platform infrastructure costs for comparable workflows compared to traditional environments.
Streamlined information engineering processes, achieving a 30% reduction in time and effort, through the creation of innovative new products and formats.
Transferred more than 600 clients to data-driven offerings utilizing the scalable and secure capabilities of the Databricks Lakehouse for storing, processing, and sharing large datasets.
As IT systems became increasingly sophisticated, they were slowly transforming into an enabler for John Holland’s enterprise operations.
Roussel noted that Databricks eliminates barriers between technology expertise and business innovation, thereby allowing enterprises to advance unhindered by IT limitations.
“According to Rousell, the key takeaway from their approach is establishing a culture of certainty within John Holland, which he believes is a significant achievement.” Traditionally, provisioning innovative products required cumbersome, slow-moving projects that often fell short of meeting business expectations.
“Now, when an enterprise conceives an idea, we’ll confirm with enthusiasm. We’ll assign them a dedicated knowledge workspace, giving them seamless access to all necessary skills, tools, and resources, empowering them to bring their vision to life at their own pace.”










/cdn.vox-cdn.com/uploads/chorus_asset/file/25589996/STK207_STK085__PAVEL_DUROV_TELEGRAM_C.jpg?w=768&resize=768,0&ssl=1 "Telegram CEO Pavel Durov vows to increase revenue after arrest in France?")