Is expected to launch either at the end of this month or in October. The Galaxy S23 Ultra can arrive with a downclocked model of the Exynos 2400 chip, featuring a 6.7-inch FHD+ AMOLED display that boasts a 120Hz refresh rate, an impressive 1,900-nit peak brightness and protective Gorilla Glass Victus+. The device is equipped with a quad-camera setup, comprising a 50MP primary camera, a 12MP ultra-wide-angle lens, an 8MP telephoto lens with 3x optical zoom, and a 10MP front-facing camera for high-quality selfies. A long-lasting 4,565mAh battery powers the entire package. Oh, and a worth hike.
According to a trustworthy source, whispers suggest that the forthcoming Galaxy S24 FE in European markets may incur an additional €100 premium at launch compared to its predecessor. It’s a reasonably exhausting capsule to swallow if this pans out, particularly as you’re not getting any further reminiscence or storage: the budget-friendly S24 FE model will only offer 8GB of RAM and 128GB of storage, mirroring the S23 FE’s specifications.
The Samsung Galaxy S24 FE with 8GB of RAM and 128GB of storage is expected to carry a price tag of €799. The Samsung Galaxy S23 Fan Edition has reached its final year. The vanilla model currently retails in Europe for €799, offering the same RAM and storage configuration. In contrast, the upgraded version costs €899, featuring 12GB of RAM and 256GB of storage. What sets the S24 FE apart from its competitors, making it a compelling choice for some buyers, is its unique blend of affordability, compact size, and decent fuel efficiency. What is the purpose of this inquiry?
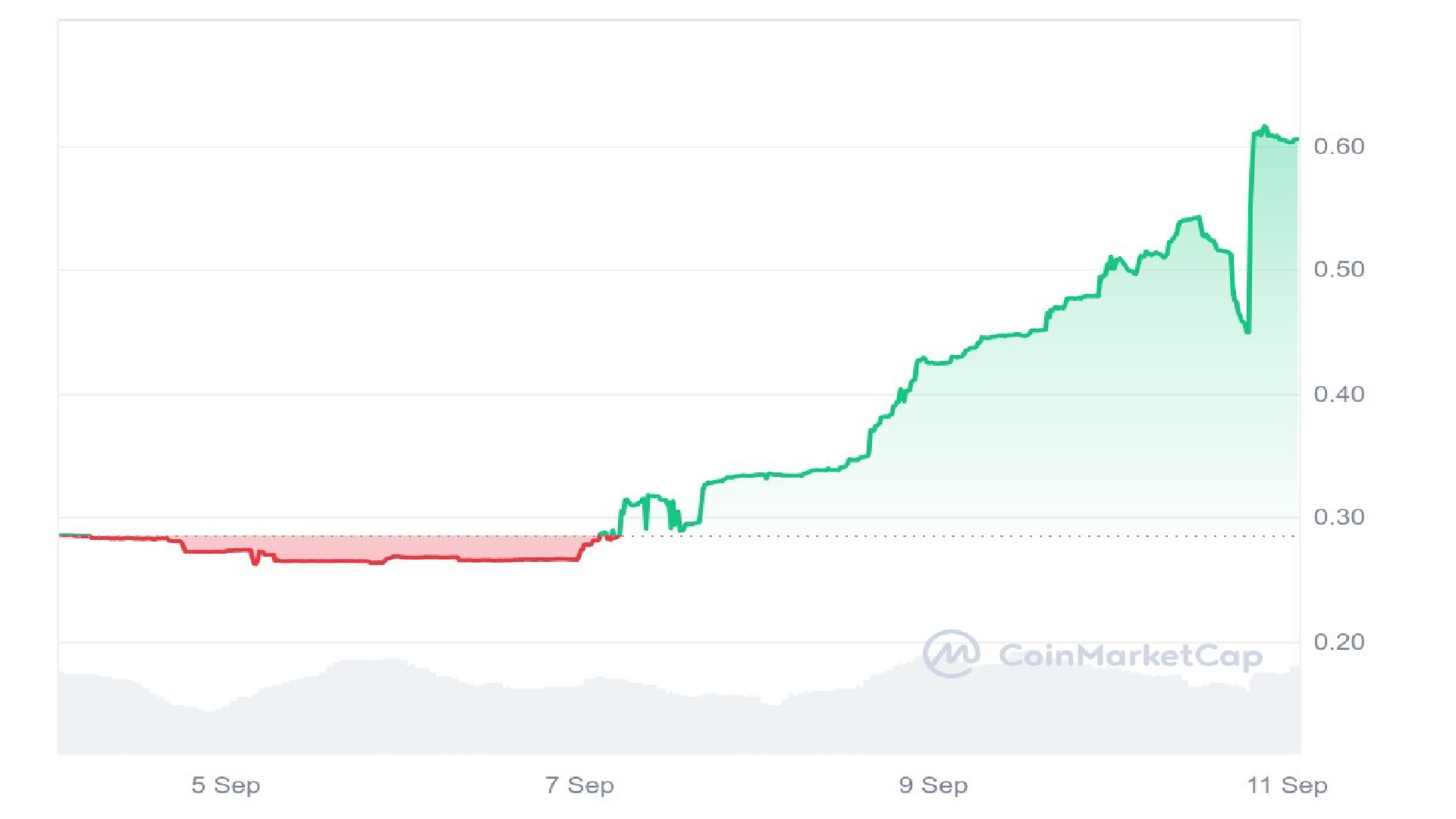
SwissCheese’s value surged by a whopping 20.84% over the past 24 hours, and an astonishing 111.89% in the preceding week, reaching a new height of $0.6051. What’s driving the SWCH rally?
Here’s a comprehensive examination of the factors driving SwissCheese’s recent surge and whether it merits consideration for your investment portfolio.
What’s SwissCheese?
Swiss Cheese distinguishes itself from run-of-the-mill meme tokens by carving out a unique niche within the cryptocurrency landscape. With its successful launch on the Polygon ecosystem, the project has been steadily building momentum. The SWCH token functions as the native cryptocurrency for the SwissCheese Finance platform.
This token enables users to trade in tokenized shares, replicating those of prominent companies like Apple and Netflix, thereby facilitating fractional ownership. SwissCheese Finance’s innovative platform enables seamless, peer-to-peer transactions for coveted assets through a secure and decentralized network.
Furthermore, SWCH offers gateway access to decentralized finance (DeFi) solutions such as staking and participating in non-fungible token (NFT) marketplaces. The innovative options for exercising at SwissCheese have proven to be a magnet for customers, drawing them in with their practical features.
The iconic SwissCheese Finance brand is set to unveil a legendary figure from the realm of international soccer on September 17, when it appoints its newest and most esteemed model ambassador yet. The recent reveal has sparked widespread delight in the community, significantly fueling the token’s upward trajectory. The platform recently announced that an upcoming announcement will be shared on Twitter.
The announcement is expected to significantly enhance the platform’s visibility and attractiveness, thereby drawing in a broader audience. As part of its comprehensive strategy, the venture is poised to establish a prominent collaboration with Bitget, further bolstering its presence in the market. To mark this milestone, it will be hosting a substantial SWCH giveaway, offering a whopping 10,000 units to enthusiasts and supporters alike.
SwissCheese (SWCH) worth evaluation
The SwissCheese token (SWCH) has experienced a significant surge, with a 16% increase in value today, an impressive 71% rise over the week, and a substantial 60% gain for the month. Currently trading at $0.6051, SWCH has experienced a substantial increase from its earlier price of $0.2827 this week, showcasing a notable surge in value. As a result, the market has witnessed an unprecedented rise in trading activity.
The broader cryptocurrency market is exhibiting a marked upswing, with a current increase of 3.36% and an objectively neutral market sentiment index of 41%. While these indicators appear encouraging, SwissCheese distinguishes itself by ranking second on CoinMarketCap’s list.
The market capitalization of SwissCheese has surged 20% to reach $22.7 million, while its daily trading volume has skyrocketed 9.87% to a value of approximately $3.48 million over the past 24 hours? The data suggests a growing interest in SWCH, accompanied by an increase in user engagement on the platform.
The current circulating supply of SwissCheese tokens stands at 38.18 million, with a total cap set at 120 million. The token’s value surged 100% from $0.30 to $0.60 within a remarkably short timeframe, marking a precipitous and potentially significant upward trajectory.
While SwissCheese’s value has experienced a significant surge, it is crucial to exercise caution. Despite its remarkable resilience since listing on CoinMarketCap in August 2023, the latest surge may signal a potential correction in the making.
Before investing in SwissCheese, it’s wise to await potential valuation adjustments. The recent upward momentum has propelled the value to a crucial juncture where a pullback may occur?
Consider employing a dollar-cost averaging approach to enter the market effectively. By consistently investing a fixed amount at regular intervals, you can effectively manage market volatility and reduce the risk of investing a large sum at an inflated price.
Are you seeking alternative funding options that offer potentially high returns and appreciate in value during the next bull market? Learn more about your choices here.
Pepe Unchained: Alternative Funding for the Entrepreneur
Pepe Unchained (PEPU) has continued to demonstrate robust momentum in its presale phase, attracting significant investment from prominent backers. What drives gasoline traders’ and merchants’ fascination with this meme coin are several key factors?
Unlike its precursor, the one-of-a-kind Pepe Coin (PEPE), which debuted on Ethereum, $PEPU leverages Layer 2 expertise to gain an advantage. With this innovative launch, Layer 1 chains such as Ethereum are finally able to overcome their limitations, boasting significantly enhanced speed, lower costs, and increased scalability.
Unlocking the Power of Pepe: Revolutionary Layer 2 Blockchain Innovation
What’s next for meme-based cryptocurrency? 🐸
— Pepe Unchained (@pepe_unchained)
These advancements distinguish $PEPU from PEPE, aligning its design and nomenclature with its elevated stature. The widespread acclaim surrounding this concept, including its nickname as the “Pepe Killer,” is hardly surprising given the original PEPE’s notable lack of practical value.
The $PEPU token serves as the native cryptocurrency for this innovative project. By investing, you gain access to the renowned Pepe flavor and benefits, including smooth bridging capabilities between the Pepe Chain and Ethereum, a dedicated Block Explorer, and other exclusive perks.
The pre-sale has made significant progress in a short period of time, achieving an impressive total of over $12.7 million to date. Currently, $PEPU tokens trade at $0.0096126; with a potential upswing expected within the next 18 hours, prompt action is highly recommended. Tokens can be purchased using various payment methods, including Ethereum (ETH), Binance Coin (BNB), Tether (USDT), or a credit/debit card.
The Pepe Unchained group is pioneering a novel “double staking” protocol, poised to revolutionize the way stakeholders engage with their assets. By leveraging this complex mechanism, PEPU token holders can potentially reap significantly higher returns by adopting a long-term strategy, with estimated annual yields of approximately 161%.
As Pepe Unchained prepares for its highly anticipated open-market launch, the excitement builds around this soon-to-be-released offering. While only time will tell whether $PEPU’s early promise is fulfilled, preliminary signs suggest a promising trajectory.
As climate patterns evolve into a pressing global crisis, swift action and sustained planning are essential to achieve meaningful, long-lasting transformations. Achieving harmony between seemingly disparate goals is often the biggest hurdle in driving meaningful progress; thus, establishing a clear guiding principle – a true north star – becomes crucial for unlocking momentum. Three years ago, Cisco established its guiding principle: a commitment to reducing greenhouse gas (GHG) emissions across our value chain by 2040. In 2022, this goal was validated by the Science-Based Targets initiative (SBTi), further solidifying our pledge to sustainability. In 2023, we unveiled Cisco’s cutting-edge technology innovation. As we strive for success in achieving Internet Zero, a crucial component of our strategy is to drive the accelerated shift towards clean power.
As we celebrate our three-year milestone, it’s essential to highlight the significant progress we’ve achieved so far and gaze forward at the opportunities that can help us – and the planet – reach internet zero.
In line with local meteorological expertise, our internet zero mission encompasses our entire value chain, incorporating not only our own energy usage but also that of our suppliers and customers. Cisco has addressed this issue through various means, including:
We’re enhancing the energy efficiency of our buildings by concentrating on innovative solutions that reduce emissions from our operations. We have also been actively engaged in transitioning our vehicle fleet to electric vehicles (EVs), a key initiative that underscores our commitment to reducing our environmental footprint.
Cisco joins the ranks of companies committed to powering their operations with 100% renewable electrical energy, as part of a collective effort to make a positive impact on the environment. By joining RE100, we leverage the collective strength to pursue our individual goals, while also driving significant progress in renewable energy uptake, ultimately aligning with the private sector’s growing appetite for sustainable solutions.
We have committed to ensuring that at least 80% of our Cisco-supplied element, manufacturing, and logistics partners set publicly disclosed, absolute greenhouse gas emission reduction targets by FY 2025. As of FY23, nearly 92% of the suppliers possess publicly disclosed, absolute greenhouse gas (GHG) emission reduction targets.
Direct operational emissions are Cisco’s scope 1 emissions; indirect operational emissions are Cisco’s scope 2 emissions; value chain emissions are Cisco’s scope 3 emissions, as defined by the Greenhouse Gas Protocol. Studying in-depth about how companies calculate their greenhouse gas (GHG) emissions is crucial for understanding the environmental impact of their operations. To get started, let’s dive into the methodologies used to quantify these emissions.
As we strive to drive progress toward Cisco’s Internet Zero goal, we’re discovering innovative solutions that can undoubtedly benefit other organizations, countries, and individual cities in achieving their own Internet Zero targets alike. Notably, these instances stand out as exceptional cases.
As artificial intelligence adoption accelerates, it offers numerous opportunities for effective local climate change mitigation and adaptation strategies, leveraging the power of predictive analytics, data evaluation, and machine learning. AI-powered systems can significantly reduce energy and water consumption through real-time monitoring and optimization.
Local weather expertise strives to pioneer innovative solutions to climate change, such as smart grids that efficiently monitor and manage the distribution of electricity, and systems capable of capturing CO2 emissions. Sustainability-focused investments have gained significant traction in recent years, with a surge in novel ESG, impact, and affect funds being introduced to the market between 2019 and 2022. Globally, annual clean power technology investments are expected to surpass previous records, fueling innovation and driving progress towards a more sustainable future.
Clean power adoption is surging forward. For the first half of 2024, wind and solar power surpassed fossil fuel energy in the EU, a trend expected to continue through this decade regardless of any future climate policies. Implementing a strategic focus on renewable energy growth, optimizing power efficiency, reducing methane emissions, and accelerating electrification is projected to deliver the required emissions reductions by 2030?
As we strive to achieve internet zero, a collaborative endeavour involving individuals, corporations, and public authorities is essential. We’re honored to lead this crucial effort for Cisco, working in tandem with partners, customers, suppliers, and other stakeholders to bring the vision of a net-zero future to life.
Organizations we’ve engaged with are currently exploring the potential of AI-powered personalization, suggesting, semantic search, and anomaly detection. Recent breakthroughs in the accuracy and accessibility of massive language models (LLMs), particularly those leveraging BERT and OpenAI, have compelled companies to reassess how they build integrated search and analytics experiences.
This blog post features insights from five pioneering companies – Pinterest, Spotify, eBay, Airbnb, and DoorDash – that have successfully integrated artificial intelligence (AI) into their services. Here is the rewritten text:
We envision that these stories will prove valuable for engineering teams contemplating the comprehensive journey of vector search, encompassing every stage from generating embeddings to deploying solutions.
What’s vector search?
Vector search enables efficient retrieval of similar objects from large datasets by leveraging representations in a high-dimensional space, thereby facilitating the discovery of comparable data. In this context, objects may encompass a broad range of entities, akin to documents, images, or audio files, which are represented through vector embeddings. Similarity between objects is calculated using distance metrics akin to cosine or Minkowski similarities, which measure the proximity of two vector embeddings.
The vector search course typically encompasses:
Producing embeddings: Relevant features are extracted from raw data to generate vector representations using models such as Word2Vec, GloVe, or BERT.
Indexing: By organizing the vector embeddings into a structured information architecture, we enable efficient search capabilities through the application of algorithms such as
Vector Search: Leveraging the concept of most similar objects to a query vector, vector search algorithms retrieve top matches by utilizing a chosen distance metric, such as cosine similarity or Euclidean distance.
To better visualize vector searches, consider a three-dimensional space where each axis represents a characteristic. The location and duration of a specific scope within a particular region are determined by the selection of relevant choices. In this zone, analogous items are clustered closer together, while disparate elements occupy greater distances from one another.
Given a query, we are able to identify the most analogous objects within the dataset. The inquiry is projected onto a shared vector embedding space alongside the product embeddings, subsequently computing the distance between the question embedding and each product embedding. Merchandise embeddings with the shortest distance to the question embedding are thus considered the most analogous.
In its most fundamental form, this visualization represents a reduced representation of the complex processes involved in vector search algorithms operating within high-dimensional spaces.
This article will synthesize insights from five prominent engineering blogs on vector search, with a focus on highlighting critical implementation challenges. Total engineering blogs may potentially be found below.
Pinterest: Curiosity search and discovery
Pinterest utilizes advanced image recognition technology to facilitate seamless picture search and discovery across various facets of its platform, including the home feed, related pins, and search functionality powered by a cutting-edge multitask learning model.
PIN-Vector Embeddings for User Profiling: A Novel Approach.
Professional editors may improve the text as follows:
PIN-Vector Embeddings for User Profiling: A novel approach leverages diverse user interactions and multivariate information factors to generate rich semantic representations, enabling accurate modeling of Pinterest users’ preferences and behaviors.
A multiskilled mannequin excels at executing numerous tasks in parallel, leveraging shared underlying representations or architectures that can boost generalisation and efficiency across related tasks. On Pinterest, a team leveraged a consistent model to push high-quality content onto the home feed, relevant pins, and search results.
Pinterest trains the model by linking a customer’s search query (q) to the relevant content they engaged with, such as the pins they clicked on or saved (p). Pinterest developed a sophisticated algorithm to generate precise (q,p) pairings for each activity by leveraging natural language processing and machine learning techniques.
Associated Pins: The phrase embeddings are generated from a combination of the user’s query (q) and their interaction with specific pins (p), specifically those they’ve clicked on or saved.
Phrase embeddings are generated from the search query’s textual content (q) and the relevant item clicked or saved by the user (p).
Homefeed: The primary factors influencing the generation of phrase embeddings include the user’s curiosity (q) and their interactions with content, specifically the pins they click on or save (p).
To obtain a comprehensive entity representation, Pinterest computes the mean of phrase embeddings corresponding to relevant Pins across search results and the Home feed.
Pinterest developed and assessed the performance of its novel personal supervised Pintext-MTL model against unsupervised learning models such as GloVe, word2vec, and a single-task learning model, PinText-SR, in terms of precision. PintText-MTL demonstrated greater precision compared to opposing embedding methods, indicating a higher percentage of accurate positive predictions among all positive predictions.
Evaluating the Precision of Diverse Embedding Techniques: A Study by Pinterest. The outcomes table is derived from the blog post “PinText: A Multitask Textual content Embedding System in Pinterest”.
Pinterest found that users who employed multitasking learning strategies exhibited higher recall rates, accurately identifying a larger proportion of relevant instances, thereby making them a more effective match for search and discovery.
By integrating its algorithm across multiple platforms, Pinterest enables seamless data streaming from its home feed, search, and related pin interfaces in manufacturing settings. Once the mannequin is adequately trained, large-scale vector embeddings are generated through a batch processing job, leveraging either a Kubernetes-Docker combination or a scalable MapReduce framework. The platform constructs a comprehensive search index based on vector embeddings and leverages an Okay-Nearest Neighbors algorithm to efficiently identify the most relevant content for users, thereby providing personalized results. Caching outcomes enables Pinterest to meet its efficiency requirements.
What drives vector search on Pinterest’s info stack?
Spotify: Podcast search
Spotify leverages key phrases and natural language processing to deliver relevant podcast episode suggestions to users. Despite the presence of relevant podcast episodes on Spotify, the crew encountered limitations in querying “electrical vehicles’ weather influence”, resulting in a surprising zero hits, despite the existence of applicable content. To boost recall, the Spotify team leveraged Approximate Nearest Neighbor (ANN) technology for rapid, relevant podcast discovery.
What’s the impact of local weather conditions on electrical vehicle performance and efficiency?
Utilizing its multilingual capabilities, the crew generates vector embeddings that support a vast world library of podcasts, producing high-quality results. Various fashion evaluations have also been conducted along with training a model on a large corpus of text data; however, it was found that BERT excelled at phrase embeddings over sentence embeddings, and its pre-training was limited to the English language only?
Spotify constructs vector representations by combining the input embedding from user queries with a concatenated representation of textual metadata, including titles and summaries, to create podcast episode embeddings. Spotify calculated the cosine similarity between the question and episode vectors to determine their degree of similarity.
Spotify employed constructive pairs of profitable podcast searches and episodes to train its bottom-up Common Sense Encoder CMLM model. They incorporated in-batch negative samples, as described in relevant research papers, by combining them with random positive examples to create adversarial pairing instances. Further testing was conducted using both artificial queries and manually crafted queries.
To integrate vector search into suggesting podcasts based on users’ preferences within the manufacturing industry, Spotify employed innovative approaches and cutting-edge technologies.
Spotify indexes episode vectors offline in batches using a search engine that natively supports Artificial Neural Networks (ANN). The selection of Vespa as one potential solution is partly due to its ability to apply metadata filtering after search results, allowing for further refinement by factors such as episode reputation.
Online inference: Spotify leverages language models to generate a query vector. Vertex AI was selected for its assistance in accelerating GPU-based inference, particularly with large-scale transformer models used to produce embeddings at a lower cost, as well as its innovative question caching feature. Following the generation of the question vector embedding, it facilitates retrieval of the top 30 podcast episodes from the Vespa index.
While semantic search effectively identifies relevant podcast episodes, its limitations mean that traditional keyword search remains a valuable complementary tool. This limitation arises from the fact that semantic search struggles to accurately match precise time periods when customers search for an exact episode or podcast title. Spotify leverages a cutting-edge search approach that combines the power of semantic search through Vespa with keyphrase search, followed by a decisive re-ranking phase to ensure users are presented with relevant episode suggestions.
Spotify’s Vector Search Workflow: A Harmonious Blend of Techniques and Scalability.
To deliver seamless music discovery experiences, Spotify’s vector search workflow relies on a synergy of cutting-edge technologies and meticulous engineering. The journey commences with the collection of diverse audio features from millions of songs, carefully extracted using state-of-the-art signal processing techniques.
These feature vectors are then aggregated into a robust database, meticulously maintained to ensure the highest accuracy. As users engage with Spotify’s vast music library, the system efficiently processes their preferences and listening habits, generating personalized recommendations.
To power this operation, Spotify leverages an array of advanced algorithms, including dense neural networks and matrix factorization. These techniques enable the platform to effectively capture complex patterns in user behavior and song attributes, fostering a deep understanding of musical affinity and taste.
The workflow’s crowning achievement lies in its ability to efficiently index and query vast amounts of audio data, leveraging highly optimized indexing and retrieval algorithms. This enables Spotify to deliver lightning-fast search results, even for the most discerning users.
Throughout this endeavor, Spotify’s workflow is fueled by a relentless pursuit of innovation, with constant refinement and optimization ensuring the highest level of performance and scalability. As the music landscape continues to evolve, this workflow remains poised to meet the ever-changing demands of music lovers worldwide.
eBay: Picture search
Traditionally, search engine results pages (SERPs) have showcased relevant information by matching search queries with descriptive summaries of documents or items. This technique relies heavily on linguistic cues to infer preferences, but its effectiveness diminishes when applied to aspects of fashion or aesthetics, where other factors come into play. eBay launches a feature designed to help users find relevant, comparable items that match their search query.
EBay leverages a sophisticated multimodal architecture that seamlessly integrates data from diverse sources, including text, images, audio, and video, to generate accurate predictions and execute tasks efficiently. On eBay, the platform combines visual and textual data by feeding images and descriptions into a model. A Convolutional Neural Network (CNN) generates image embeddings, while a text-based model produces title embeddings. The itemizing vectors are constructed through a combination of image and title representations, where each is embedded into a shared latent space.
The multimodal embedding model employed by eBay showcases a complex architecture for processing diverse data types.
Once the multimodal manikin has been trained on a substantial dataset of image-title pairs and recently published listings, it’s ready for deployment in the website search experience. To accommodate the vast array of listings on eBay, data is processed in bulk and stored in HDFS, the company’s central repository for information. eBay leverages Apache Spark to collect and store image data alongside relevant metadata for further processing, as well as generating listing embeddings. The itemized embeddings are printed to a column-store database akin to HBase, ideal for aggregating and processing large-scale data sets. Cassini, a search engine developed by eBay, leverages HBase to serve and list itemized embeddings.
The company’s cutting-edge approach to vector search optimizes efficiency and scalability within its vast databases.
The pipeline is managed using Apache Airflow, capable of handling large volumes and complex workflows with ease. This comprehensive platform further extends its support to include Spark, Hadoop, and Python, effectively empowering machine learning teams to seamlessly adopt and maximize their capabilities.
Customers can discover analogous products and tastes through visible search, a feature that allows them to explore categories of furniture and home decor where style and aesthetics play a crucial role in purchasing decisions. In the near future, eBay intends to enhance its visual search capabilities across all product categories, enabling customers to easily discover complementary items and curate a cohesive look and feel throughout their home.
AirBnb: Actual-time customized listings
Search and comparable listings options are responsible for driving 99% of bookings on the Airbnb website. Airbnb developed an algorithm to improve comparable listing suggestions and provide real-time personalization in search results.
By recognizing the potential for applications beyond straightforward phrase representations, Airbnb pioneersed embedding innovations to incorporate user behavior, click patterns, and booking data in tandem.
To improve their embedding models, Airbnb leveraged more than 4.5 million active listings and 800 million search queries to identify similarities based on users’ click-through behavior within a single session. Listings with identical engagement from the same user within a session are clustered together, while those with low or no interaction are progressively relegated to the periphery. The team ultimately decided on a 32-dimensional inventory embedding, weighing the benefits of offline efficiency against the need for effective recall in online serving.
Airbnb found that certain listing attributes don’t necessitate manual input, as they can be readily extracted from metadata, much like property values. While attributes such as structure, model, and ambiance may be more challenging to extract from metadata alone.
Before scaling up production, Airbnb refined its model by verifying its accuracy through experiments that demonstrated how well-recommended listings matched actual bookings made by users. The team also conducted an A/B test comparing the existing listings algorithm to one based on vector embeddings. The team found that the algorithm incorporating vector embeddings led to a significant 21% increase in click-through rates (CTR) and a notable 4.9% boost in customers finding available inventory they had previously reserved.
The team also discovered that vector embeddings could be leveraged as a component within their model for delivering real-time personalized search results. To track individual user behavior, they aggregated and stored real-time data on clicks and skips over the past fortnight using Kafka to maintain a concise, short-term history. Each time a user initiates a query, their system automatically runs two iterative similarity searches.
Primarily focused on the geographic markets that have recently been searched,
What are the key factors in common among candidate profiles matched with those the user has interacted with?
Embeddings have been extensively evaluated in both offline and online experiments, solidifying their role as a core component of real-time personalization strategies.
Doordash: Customized retailer feeds
DoorDash features a diverse range of partner shops, allowing customers to browse and select their preferred options. By enabling users to filter results based on personalized preferences, the platform enhances search functionality and facilitates seamless discovery.
DoorDash aimed to harness the power of retailer feed algorithms through the application of vector embeddings. By leveraging this feature, DoorDash can uncover previously unknown patterns and correlations between seemingly disparate shops, thereby gaining valuable insights on aspects such as product offerings (e.g., presence of candies), aesthetic appeal (style), and dietary considerations (vegetarian options).
DoorDash leveraged Store2Vec, a customized version of Word2Vec, a widely-used natural language processing tool, to analyze existing data. The team treated each retailer uniformly, constructing coherent sentences by leveraging the shop history observed within a single user session, capping it at five stores per sentence. To generate person-centric vector representations, DoorDash aggregated the embeddings of shops from which customers placed orders over the past six months or up to a maximum of 100 orders.
DoorDash leverages vector search technology to recommend similar dining establishments based on users’ recent orders from trendy eateries like 4505 Burgers and New Nagano Sushi in San Francisco, tailoring the suggestions to their exact tastes. DoorDash generates a list of comparable eateries by calculating the cosine distance between the individual’s persona embedding and restaurant embeddings in a shared space, ranking establishments based on their proximity to the user’s preferences. As observed, the establishments most proximal in terms of cosine distance include Kezar Pub and Picket Charcoal Korean Village BBQ.
A vector search instance at DoorDash leveraged from the Customized Retailer Feed utilizing vector embeddings.
DoorDash incorporated Store2Vec distance characteristics as just one of numerous options within its larger suggestion and personalization framework. Vector search enabled DoorDash to boost its click-through-rate by a notable 5%. While the crew is experimenting with innovative styles, they might consider refining their approach by integrating cutting-edge techniques such as optimizing mannequins and leveraging customer-provided feedback in real-time to create a truly immersive shopping experience.
Key concerns for vector search
Pinterest, Spotify, eBay, Airbnb, and DoorDash elevate their users’ search and discovery journeys by harnessing the power of vector search technology. Several groups initially employed textual content search, only to discover the drawbacks of fuzzy searching or searches restricted by specific styles or preferences. When applied in such contexts, incorporating vector search into one’s expertise streamlines the process of discovering relevant and occasionally tailored podcasts, as well as restaurants, pillows, pins, and leases.
Corporations often make several strategic choices that are worthy of scrutiny when incorporating vector search capabilities.
Many individuals started by utilising an off-the-shelf model and then customised it with their unique data. Moreover, they recognised that language trends such as word2vec can potentially be leveraged by exchanging phrases and their descriptions with objects and analogous objects that have been recently interacted with. Companies such as Airbnb found that leveraging derivatives of linguistic patterns, rather than visual patterns, can still effectively capture visual similarities and differences.
By leveraging vast amounts of historical data and machine learning capabilities, many corporations have chosen to refine their forecasting approaches through data-driven coaching processes.
By contrast, while many corporations leveraged ANN search, Pinterest was uniquely positioned to combine metadata filtering with K-Nearest Neighbor (KNN) search for scalability and effectiveness.
Hybrid searches often augment traditional textual content searches rather than replacing them entirely. On various instances, such as with Spotify’s implementation, a ranking algorithm is employed to determine which outcome – either that generated by vector search or textual content search – is most pertinent.
While some organizations leverage batch-based approaches to generate vector embeddings, a major caveat is that these representations often remain static and infrequently updated. They leverage a unique architecture, frequently employing Elasticsearch, to calculate the question vector embedding in real-time while incorporating relevant metadata for enhanced search capabilities.
Rockset, a real-time search and analytics database, has recently incorporated support for. Experience real-time personalization, suggestions, and anomaly detection with vector search on Rockset, starting with a generous $300 credit today!
This innovative feature empowers customers to seamlessly manage HyperPod clusters on EKS, leveraging Amazon’s robust infrastructure and trusted environment optimized for large-scale model training. Amazon SageMaker HyperPod enables efficient scaling across over 1,000 artificial intelligence (AI) accelerators, resulting in up to a 40% reduction in training time.
Amazon SageMaker HyperPod now enables customers to manage their clusters using a Kubernetes-inspired interface. This integration enables effortless transitions between Slurm and Amazon EKS to streamline the management of multiple workloads, inclusive of training, tuning, testing, and prediction processes. The CloudWatch Observability EKS add-on provides comprehensive monitoring capabilities, offering real-time insights into critical metrics such as CPU usage, network traffic, disk performance, and other low-level node metrics, all accessible from a single, intuitive dashboard. This elevated observability encompasses a comprehensive view of resource utilisation across the entire cluster, nodes, pods, and containers, empowering efficient troubleshooting and optimisation through granular insights.
Hugging Face’s Transformers library has grown to become a go-to solution for AI startups and enterprises seeking to efficiently implement and deploy large-scale models. These tools are perfectly suitable, providing and facilitating software program optimizations that significantly reduce training time by up to 20%. SageMaker HyperPod automates the detection and remediation of defects, allowing data scientists to train models without interruption over extended periods. This allows data scientists to focus on modeling and growth, rather than managing underlying infrastructure.
Combining Amazon EKS with Amazon SageMaker HyperPod leverages the advantages of Kubernetes, which has gained popularity in machine learning (ML) workloads due to its scalability and extensive open-source ecosystem. Organisations standardise on Kubernetes to construct functions required for generative AI use cases, as it enables the reuse of capabilities across environments while meeting assembly compliance and governance requirements. The latest announcement enables customers to efficiently scale and optimize resource utilization across more than 1,000 AI accelerators. This flexibility amplifies developers’ skillsets, streamlines containerized application management, and enables scalable resources for complex FM coaching and inference tasks.
Amazon EKS helps strengthen the resilience of Amazon SageMaker HyperPods through rigorous health checks, automated node recovery, and job resume capabilities, ensuring uninterrupted training for large-scale or long-running jobs? Job administration may be streamlined using a non-compulsory, Kubernetes-environment-designed tool, which clients can also utilize via their own command-line interfaces. By integrating with our platform, you gain unparalleled visibility into cluster performance, uncovering valuable insights that highlight efficient resource allocation, optimal system health, and real-time usage trends. While information scientists can leverage tools such as Kubeflow to streamline their machine learning processes, The mixing also features Amazon SageMaker managed MLflow, providing a robust solution for experiment tracking and model management.
To create an Amazon SageMaker HyperPod cluster at an exceptional level of scalability, a cloud administrator uses the intuitive interface and leverages the fully managed service, thereby eliminating the tedious tasks associated with building and optimizing machine learning infrastructure. Amazon Elastic Container Service for Kubernetes (EKS) manages and automates the deployment of HyperPod nodes, providing customers with trusted Kubernetes management capabilities and expertise.
I establish the scenario’s foundation, verifying all prerequisites are met, and create an Amazon EKS cluster with a single control plane node, strictly adhering to best practices as outlined in the official documentation, while configuring the cluster with a secure VPC setup and sufficient storage resources.
You can create and manage Amazon SageMaker HyperPod clusters using either the AWS Management Console or the AWS CLI? Using the AWS CLI, I define my cluster configuration within a JSON file. I selected the previously created Amazon EKS cluster as the orchestrator for my SageMaker HyperPod Cluster. I will improve the text in a different style as a professional editor.
I then created clusters of employee nodes named “worker-group-1”, with a non-public IP address. Subnet,NodeRecovery set to Computerized to enable seamless computerized node restoration and further OnStartDeepHealthChecks I add InstanceStress and InstanceConnectivity To enable comprehensive wellness assessments.
You’ll be able to add storage to provision and seamlessly mount an additional drive on HyperPod nodes.
To create a cluster using the Karpenter API, I run the following AWS CLI command:
AWS SageMaker creates a cluster with the specified configuration. To initiate this process, I'll provide the command in a revised style: aws sagemaker create-cluster --cli-input-file "file:///path/to/eli-cluster-config.json"
The AWS command returns the Amazon Resource Name (ARN) of the newly created HyperPod cluster.
I verify that the HyperPod cluster stands at the desired configuration, waiting for the standing adjustments to take effect. InService.
Alternatively, you can test the cluster’s stability using the AWS CLI by operating the command “aws emr describe-cluster” and checking the state of the nodes. describe-cluster command:
As soon as the cluster is prepared, I can enter the SageMaker HyperPod cluster nodes. For numerous operations, one can utilize kubectl
To efficiently manage assets and jobs within your growth environment, you can leverage the comprehensive capabilities of Kubernetes orchestration, while also capitalizing on the benefits of SageMaker HyperPod’s managed infrastructure. Using SSM, I gain access to individual nodes for advanced troubleshooting or direct node entry, adhering to instructions provided on the webpage.
To deploy jobs on a SageMaker HyperPod cluster managed by Amazon Elastic Kubernetes Service (EKS), I follow the instructions provided. What are you trying to accomplish with the HyperPod CLI and the native network? Are you configuring a Kubernetes deployment or validating a network policy? Can you provide more context so I can assist you better? kubectl The following command searches for available HyperPod clusters and submits coaching jobs (Pods):
“` pods –search-availability “` To streamline machine learning experiment management and accelerate coaching runs, consider leveraging tools like Weights & Biases, MLflow, and Hyperopt.
Within the SageMaker Console, I can instantly access a detailed overview of newly added EKS clusters, providing a comprehensive snapshot of my SageMaker HyperPod environment.
I can monitor cluster efficiency and wellness metrics using advanced analytics tools.
Identifying key considerations for leveraging Amazon EKS support in Amazon SageMaker HyperPod requires a deeper dive into the benefits and best practices.
This integration provides a more robust coaching environment featuring comprehensive health checks, automatic node recovery, and seamless job resume functionality. SageMaker HyperPod automatically detects, diagnoses, and recovers from faults, enabling you to repeatedly train machine learning models for weeks or months without interruption. The innovative technology has the potential to significantly reduce coaching hours by up to 40 percent.
Provides granular insights into performance and activity within containerized applications and microservices through comprehensive metrics and logging. This feature enables comprehensive monitoring of cluster performance and overall health.
This launch introduces a tailored HyperPod CLI for streamlined job management, integrates Kubeflow’s Coaching Operators for scalable training, leverages Kueue for efficient scheduling, and enhances collaboration through seamless integration with SageMaker Managed MLflow for comprehensive experiment tracking. The platform also seamlessly integrates with SageMaker’s distributed training libraries, leveraging Model Parallel and Data Parallel optimization techniques to significantly accelerate the training process. These libraries, combined with auto-resumption of jobs, enable environmentally friendly and uninterrupted training of massive models.
This integration amplifies developers’ proficiency and flexibility in handling FM workloads, thereby empowering them to tackle complex projects with confidence. Information scientists can seamlessly share computing capabilities across both training and inference tasks. You must leverage your existing Amazon EKS clusters or establish and integrate new ones with HyperPod compute, utilize your custom tools for job submission, queueing, and monitoring.
Before getting started with Amazon SageMaker HyperPod on Amazon EKS, you’ll find valuable resources available, including the documentation, tutorials, and the GitHub repository. The launch of this service is primarily available within AWS regions where Amazon SageMaker HyperPod is available, excluding Europe (London). Visit our website for detailed pricing information.
The weblog post was a joint endeavour. We would like to extend our gratitude to Manoj Ravi, Adhesh Garg, Tomonori Shimomura, Alex Iankoulski, Anoop Saha, and the entire staff for their invaluable efforts in collecting and fine-tuning the information presented here. The cumulative expertise of these individuals proved pivotal in crafting a comprehensive piece.
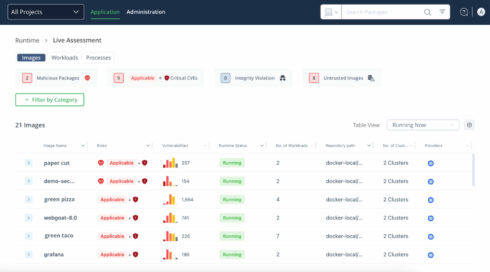
At its annual consumer convention, swampUp, the DevOps firm JFrog introduced new options and integrations with corporations like GitHub and NVIDIA to allow builders to enhance their DevSecOps capabilities and convey LLMs to manufacturing shortly and safely.
JFrog Runtime is a brand new safety answer that enables builders to find vulnerabilities in runtime environments. It screens Kubernetes clusters in actual time to establish, prioritize, and remediate safety incidents primarily based on their threat.
It gives builders with a way to trace and handle packages, arrange repositories by surroundings sorts, and activate JFrog Xray insurance policies. Different advantages embody centralized incident consciousness, complete analytics for workloads and containers, and steady monitoring of post-deployment threats like malware or privilege escalation.
“By empowering DevOps, Information Scientists, and Platform engineers with an built-in answer that spans from safe mannequin scanning and curation on the left to JFrog Runtime on the proper, organizations can considerably improve the supply of trusted software program at scale,” stated Asaf Karas, CTO of JFrog Safety.
Subsequent, the corporate introduced an enlargement to its partnership with GitHub. New integrations will present builders with higher visibility into challenge standing and safety posture, permitting them to handle potential points extra quickly.
JFrog prospects now get entry to GitHub’s Copilot chat extension, which may help them choose software program packages which have already been up to date, authorized by the group, and secure to be used.
It additionally gives a unified view of safety scan outcomes from GitHub Superior Safety and JFrog Superior Safety, a job abstract web page that reveals the well being and safety standing of GitHub Actions Workflows, and dynamic challenge mapping and authentication.
Lastly, the corporate introduced a partnership with NVIDIA, integrating NVIDIA NIM microservices with the JFrog Platform and JFrog Artifactory mannequin registry.
In accordance with JFrog, this integration will “mix GPU-optimized, pre-approved AI fashions with centralized DevSecOps processes in an end-to-end software program provide chain workflow.” The tip outcome might be that builders can deliver LLMs to manufacturing shortly whereas additionally sustaining transparency, traceability, and belief.
Advantages embody unified administration of NIM containers alongside different property, steady scanning, accelerated computing by means of NVIDIA’s infrastructure, and versatile deployment choices with JFrog Artifactory.
“As enterprises scale their generative AI deployments, a central repository may help them quickly choose and deploy fashions which are authorized for improvement,” stated Pat Lee, vice chairman of enterprise strategic partnerships at NVIDIA. “The mixing of NVIDIA NIM microservices into the JFrog Platform may help builders shortly get absolutely compliant, performance-optimized fashions shortly working in manufacturing.”
Recent claims suggest that the output from generative AI programs, such as GPT and Gemini, is significantly less impressive than it was previously. While it’s not my first encounter with this criticism, I’m still unclear about its widespread acceptance. However, I’m left questioning whether this approach is truly effective. And in that case, why?
The artificial intelligence landscape appears to be plagued by several concerns. Developers of artificial intelligence systems strive to elevate the performance and efficacy of their algorithms. It appears they’re prioritizing large-scale business opportunities over individual users, focusing on securing lucrative deals rather than catering to subscribers willing to pay a modest $20 monthly. If I were tailoring my approach to craft more professional business writing, I might calibrate my dummy to generate additional formal corporate language. While the phrase “that’s not good prose” is aptly used, the underlying statement itself requires refinement. We can freely caution against mindlessly incorporating AI-generated content into reports, but this warning doesn’t guarantee people won’t do it—and it does imply that AI developers will strive to provide what they demand.
Study sooner. Dig deeper. See farther.
Artificial Intelligence developers are actively striving to design fashions that are increasingly accurate. The error fee has decreased significantly, yet remains non-zero. Tuning a mannequin primarily involves curtailing its ability to offer unorthodox solutions that exceed our expectations of being sensible, insightful, or remarkable? That’s helpful. Cutting back on usual deviations cuts off the tail ends. The value lies in minimizing “bad” outliers, reducing hallucinations and errors by embracing the inherent diversity. While I won’t argue that builders shouldn’t reduce hallucinations, one must consider the cost.
The phenomenon of the “AI Blues” has also been linked to. While I find the concept of mannequin collapse intriguing, it may still be premature to observe this phenomenon in our current large language models, which I’ve not yet personally experienced. The AI models aren’t frequently enough retrained, with their training data comprising a relatively limited amount of AI-generated content, especially when their creators engage in large-scale copyright infringement?
Despite this, another risk is very real and stems from a more fundamental aspect of human nature, having no relation whatsoever to language trends. ChatGPT has been around for nearly two years now. As soon as it arrived, we were all astonished by its exceptional quality. One individual cited Samuel Johnson’s prescient remark from the 18th century: “ChatGPT’s output, like that of a dog walking on its hind legs, is remarkable not so much for what it achieves as for the fact that it achieves it at all.” It’s rarely accomplished with success; yet, surprisingly, it can be found to be accomplished after all.1 We were all astonished, despite the errors, hallucinations, and uncertainties that surrounded us. We were startled to discover that a PC could engage in a conversation – remarkably fluently, even for those familiar with GPT-2’s capabilities.
Two years on, however, it’s a different story. We’ve grown accustomed to the likes of ChatGPT and its companions: Gemini, Claude, Llama, Mistral, and their ilk. As we start leveraging GenAI for real-world applications, the initial awe has given way to practical experience. We’ve grown increasingly intolerant of its verbose nature, finding it insufferable; we no longer find it thoughtful or genuine, though we’re unsure whether it ever truly was. While it’s possible that language model output standards may have deteriorated slightly over the past two years, I posit that our tolerance for imperfections has actually diminished significantly.
While I’m aware that many have studied this phenomenon more extensively, I’ve conducted my own in-depth examinations of linguistic styles from their inception.
Writing a Petrarchan sonnet. A Petrarchan sonnet’s structure is distinct from its Shakespearean counterpart.
Implementing a widely known yet complex algorithm precisely in Python. I typically employ the Miller-Rabin primality test to verify the prime status of numbers.
Surprisingly, a correlation exists between the results of individual exams. Prior to recent months, leading LLMs were incapable of crafting a competent Petrarchan sonnet; while they could lucidly describe its characteristics, upon being tasked with writing one, they would invariably falter on the rhyme scheme, often substituting it with a Shakespearian sonnet instead. They faltered despite including the traditional Petrarchan rhyme scheme within their work. Even attempting to execute it in Italian, as one of my colleagues did in an experiment, they still managed to fail. In a sudden and unexpected turn of events, during the era of King Charles III, fashion experts unexpectedly discovered the secrets to interpreting Petrarch’s works with precision. It seems that on this contrary day, I am resolved to tackle two more challenging forms of poetry: the sestina and the villanelle. Contain subtle nuances within intelligent methods, alongside harmonious rhymes that gently sway Will they successfully reuse the same rhyming phrases? Whoever they are, they’ve surprisingly succeeded in this endeavour, rivaling the artistry of a Provençal troubadour.
I obtained the same results by asking the fashion designers to develop a program implementing the Miller-Rabin algorithm to verify whether large numbers were prime. When GPT-3 initially emerged, its performance was met with disappointment: although it could produce error-free code, it would also incorrectly classify numbers like 21 as prime. Despite numerous attempts, Gemini ultimately attributed its failure to Python’s numerical computation libraries, which it deemed unable to handle large numbers. I refrain from collecting data from customers who repeatedly apologize for their mistakes, saying, “Sorry, that’s incorrect once more.” What are you doing that’s incorrect? Now, they successfully implement the algorithm with precision, a far cry from their previous errors, at the very least, during my last observation. (Your mileage could differ.)
Despite achieving success, I’m still capable of feeling frustrated. You’ve asked for tips on how to refine packages that performed correctly but still flagged concerns. At times, I was aware of both the problem and its solution; occasionally, I grasped the issue but lacked insight into rectifying it. When attempting to optimize your code for the first time, you’re likely to be pleasantly surprised: rather than simply “adding more complexity to the system through features and using more descriptive variable names”, you’ll discover a much more effective approach. As you go through your second or third experience, it becomes clear that the constant stream of advice, though initially well-intentioned, ultimately fails to provide meaningful insights. “Surprised by its limited success, the phrase quickly degenerated into ‘it’s not being executed well’.”
This apparent simplicity may reveal a fundamental constraint in linguistic patterns. Despite all circumstances, they lack a certain cleverness. Until we have definitive proof, they’re merely making predictions about future outcomes by extrapolating from the training data. According to some studies and experts in software development, surprisingly few pieces of open-source code on platforms like GitHub and Stack Overflow demonstrate best practice. In fact, many examples showcase questionable design choices, inefficient algorithms, and even security vulnerabilities. How much of it is slightly pedestrian, like my own coding style? It’s likely that the latter group prevails, which is reflected in the output of language models like LLMs. While assessing Johnson’s canine research, I am genuinely surprised by its success, albeit not for the reasons most people might expect. Clearly, much online content is not entirely inaccurate. Despite some notable achievements, much of the rest falls short of its full potential, which is hardly surprising. It’s unfortunate that a language model’s output often defaults to “fairly good, yet inferior” content, which can be unimpressive and lacking in originality.
The predicament faced by artificial intelligence developers specializing in natural language processing is quite pronounced. What innovative approaches can we employ to generate groundbreaking insights that surpass the mediocrity prevailing online, thereby providing a refreshing and unparalleled experience for our audience? The initial jolt has subsided, and artificial intelligence is now being evaluated on its merits. Will AI truly deliver on its lofty promises, or will we collectively shrug and label it “boring” as its presence permeates every aspect of our lives? In reality, there may well be some merit to the notion that we’re trading off pleasing solutions for reliable ones, and that’s not necessarily a bad thing. Despite our desire for excitement and experience, we also crave satisfaction and understanding. How will AI ship that?
Footnotes
Boswell’s treatise, published in 1791, remains largely unaltered since its initial release.
This week, I navigated Banggood’s extensive FPV product catalog and curated a selection of products that caught my attention, specifically requesting special coupons and offers to share with all of you. I hope you find these gross sales beneficial. This content is proudly presented in partnership with Banggood.
Among the links on this webpage are affiliate links. Here is the improved text in a different style:
You will receive a commission (without any additional benefit to you) should you choose to place an order after clicking on one of these affiliate links, which are designed to provide valuable connections between interested parties. This feature assists in fostering a collaborative environment by providing valuable resources and content for the online community on our website. Learn about our company for extra information?
Coupon Code: BG8240f9
Code Value: $56.99
Exp: thirtieth September
The Hawkeye Thumb 4K Digicam, engineered specifically for small-scale micro FPV drones in the budget-friendly realm, offers a compact and affordable alternative to larger action cameras like GoPro. With its 4K resolution and integrated gyro for precise stabilization, this camera stands as a formidable rival to the renowned Runcam Thumb Professional. This versatile accessory seamlessly incorporates a plastic mounting bracket, streamlining setup by obviating the need for separate support; its removable UV lens also allows for easy swap-outs of a neutral density filter.
While delivering satisfactory image quality and stabilization commensurate with its price point, the digital camera’s dynamic range and audio quality remain somewhat limited compared to more advanced models. While the Hawkeye Thumb 4K is capable of impressive performance, its lack of a built-in battery means it relies on external power sources, thereby restricting its autonomy and versatility. Despite its limitations, the drone’s affordability and versatility make it an attractive choice for cost-conscious FPV enthusiasts.
What features make this digital camera truly stand out?
Coupon Code: BG6f69b0
Code Value: $239.99
Exp: thirtieth September
For just $199, the Walksnail Goggles L deliver exceptional stability, combining top-notch quality, efficiency, and affordability to make digital First-Person View (FPV) more accessible to a broader audience. While Goggles X’s superior options may be lacking, its latency benefits are commendable, rendering it a robust alternative for those entering the digital FPV realm without breaking the bank? What is the context surrounding this statement?
Coupon Code: BGcf1df4
Code Value: $229.99
Exp: thirtieth September
When space constraints limit your ability to pack a standard-sized FPV drone, the compact and innovative FoldApe4 offers a tantalizing solution for enthusiasts seeking portability and performance. This compact 4-inch long-range FPV drone excels in portability, performance, and value, making it an attractive option within the category. While it may lack flashy features, its thoughtful design, robust construction, and impressive flight capabilities create a persuasive package that appeals to pilots of all skill levels? See my evaluate:
Coupon Code: BG79905f
Code Value: Two for $47.99
Exp: thirtieth September
The HGLRC Zeus Nano VTX is an ultra-compact and highly flexible video transmitter, specifically designed for micro-sized quadcopters that require reliable transmission of high-quality video signals. At just 3 grams or less, this component is specifically designed for use in lightweight drone constructions. This versatile mounting solution offers multiple flight controller stack options (25.5×25.5mm, 20x20mm, 16x16mm), allowing for the removal of mounting tabs to conserve space and reduce weight.
The device features an integrated microphone, a standard 5-volt input voltage, four power output options, and support for up to five bands and 40 channels. Despite its compact size, the device features a heatsink and consistently outperforms expectations in energy tests, frequently surpassing specified output capacities.
The Zeus Nano VTX offers exceptional value, boasting enhanced energy efficiency that outperforms many competitors, making it an attractive option for drone enthusiasts seeking a lightweight, reliable unit with diverse mounting options.
What’s behind the veil of innovation? Discover the fascinating story of VTX technology.
Coupon Code: BG8906fc
Code Value: $25.99
Exp: thirtieth September
With its impressive track record of garnering widespread acclaim over time, the Caddx Ratel 2 FPV digital camera has earned a reputation for excellence. Given its price point, this budget-friendly analog digital camera surprisingly offers impressive performance. The Ratel 2 is praised for its exceptional stability in effortlessly handling a wide range of dynamics with remarkable clarity and nuance. Without introducing any digital imperfections, it produces authentic, unaltered duplicates.
The DarwinFPV CineApe35 debuts as an affordable, high-performance 3.5-inch cinewhoop that seamlessly balances price and productivity. With its design emulating premium models featuring durable carbon fibre and inverted motors, the drone boasts impressive sturdiness and crash resilience.
Flight exams demonstrate exceptional performance and impressive aerial experiences, especially when unencumbered by the constraints of filming equipment. While minor details like antenna quality and sensor precision can be refined, the CineApe35 uniquely offers tremendous value, positioning itself as an excellent choice for beginner and intermediate FPV enthusiasts seeking a budget-friendly cinewhoop that prioritizes performance without compromising on quality. What do you need to know about evaluating?
The SkyZone Cobra X stands out as a top-tier field goggle that effectively rivals premium binocular-style goggles in terms of performance and capabilities.
The latest V2 model features Skyzone’s innovative RapidMix module, leveraging expertise gained from ImmersionRC’s RapidFire and TBS Fusion, resulting in exceptional performance.
The Cobra X features a singular, large-format LCD display screen boasting a resolution of 1280×720 pixels and a 50-degree field of view. The device features a familiar user-friendly interface identical to that of the Sky04X, and is equipped with an HDMI input, ensuring seamless connectivity with devices such as HDZero and Walksnail. Despite the added latency associated with digital FPV systems through an additional HDMI interface, I strongly recommend using the Cobra X only with analog connectivity. See my review for more details:
Discover these game-changing sales strategies that drive results. Are there specific items you’d like to purchase at a discounted rate? If so, I’ll explore options for the next opportunity.
Image from paper ““. What initiatives has AADS implemented to promote inclusive education in STEM fields?
Recently, we had the opportunity to sit down with Jean-Pierre Sleiman, the brilliant mind behind the groundbreaking paper “Versatile Multicontact Planning and Management for Legged Locomotion-Manipulation,” which was published just a short while ago.
The system typically relies on hardcoded state-machines that dictate a sequence of sub-goals, such as grasping the door handle, opening the door to a desired angle, maintaining the door with one foot, moving the arm to the other side of the door, crossing through while closing it, and so forth. By leveraging advanced robotics and artificial intelligence, a skilled individual could potentially overcome this challenge by remotely controlling the robot, capturing its movements, and training it to replicate the observed behavior through machine learning algorithms.
Despite the potential for a slow and laborious process, there is a risk that the methodology could lead to incremental progress, albeit one that is prone to the pitfalls of engineering design flaws. To alleviate the burden of defining behavior requirements for each new task, the analysis proposed a standardized framework in the form of a single planner capable of automatically identifying the necessary actions for various locomotion-based tasks without necessitating detailed guidance for any of them?
By adopting this approach, we were able to formulate a unified bi-level optimization problem that incorporates all our responsibilities, leveraging domain-specific knowledge rather than task-specific information. Through the integration of established planning methodologies (trajectory optimisation, informed graph search, and sampling-based planning), we have successfully developed a highly effective search technique capable of resolving complex optimisation challenges.
The primary technical novelty in our work resides in the innovative framework, meticulously detailed throughout the paper’s methodology section. The setup entails defining various robotic end-effectors (such as left foot, proper foot, gripper, etc.), along with object affordances, which detail how the robot interacts with an item. This leads to the initiation of a discrete state that comprehensively captures the array of contact pairings. Given a start and goal state, such as navigating to a position behind a door, the multi-contact planner resolves a specific problem by iteratively constructing a decision tree via a hierarchical search that explores both feasible contact configurations and smooth robot-object paths. A comprehensive plan emerges through the integration of a single, far-reaching trajectory optimization process, leveraged by the previously discovered contact sequence.
By integrating our planner with data-driven approaches akin to deep reinforcement learning (DRL), we can significantly enhance robustness against modeling discrepancies. One compelling avenue for further investigation lies in developing robust DRL coverages through reliable expert demonstrations, rapidly created by our locomotion manipulation planner, to tackle a suite of challenging tasks with minimal reward engineering?
Concerning the creator
Jean-Pierre Sleiman obtained the B.E.
Diploma in Mechanical Engineering from the American University of Beirut, earned in 2016, followed by a Master’s degree. Bachelor’s degree in Automation and Management from Politecnico di Milano, Italy, conferred in 2018. He currently holds a Ph.D. Candidate for the Robotic Programs Laboratory at ETH Zurich in Switzerland. His current research focuses on developing optimization-based planning and management strategies for the effective control of legged robotic systems in cellular environments.
Received his PhD in swarm robotics from the Bristol Robotics Laboratory in 2020. By perpetuating the concept of “scientific agitation”, he enables a dialogue-driven exchange between researchers and societal stakeholders, fostering a collaborative approach.
Daniel Carrillo-Zapata Received his PhD in swarm robotics from Bristol Robotics Laboratory in 2020. He continues to champion the spirit of “scientific agitation”, leveraging this concept to facilitate dynamic dialogues between academia and society at large.
Apple showcased innovative new wellbeing options at its annual event, with a notable highlight being M.I.A.’s involvement as a prominent partner. The Blood Oxygen feature, introduced with the Collection 6 device, will not initially be available in the United States. The rest of the world will gain access to cutting-edge technology through the innovative new smartwatch.
The absence of a vital feature like blood oxygen monitoring is glaring, particularly given the company’s emphasis on wellness-focused wearables. The company’s collaboration with Masimo, a renowned medical technology firm, has yielded a notable exclusivity to their function. The controversy surrounding a feature prompted Apple to suspend its functionality on the Apple Watch Series 9 and Extreme 2 models towards the end of last year.
Apple hasn’t disclosed whether the feature’s removal was a hardware modification in Series 10 or simply disabled via software, akin to what occurred with Series 9. Will we learn more about its specifications when the smartwatch hits the market and teardown experts get to work? If it’s a hardware repair issue, Apple would have had to develop distinct models tailored to each region’s specific requirements.
Apple has been actively countering Masimo’s suit since its inception. Following a brief hiatus, Apple worked diligently to re-implement its vital ban in January.
On Monday, Apple unveiled a slew of new Health features in Collection 10, which will be available globally.





**: NLP applications such as sentiment analysis, topic modeling, and text classification can leverage vector search to find similar texts or analyze semantic relationships between words and phrases. 4. **Product recommendations**: E-commerce platforms use vector search to recommend products based on user preferences, purchase history, and browsing behavior. This technology helps personalize the shopping experience and increase customer satisfaction. 5. **Time-series forecasting**: Vector search can be applied to time-series data to forecast future values based on historical patterns and trends. This is particularly useful in applications such as stock market analysis, weather forecasting, or energy consumption prediction.")