Artificial intelligence retail instruments have progressed significantly beyond straightforward automation and data processing. As e-commerce platforms delve into the intricacies of consumer behavior, market fluctuations, and business efficiency – uncovering subtle opportunities that experienced merchants might overlook? What sets these instruments apart is their capacity to process vast amounts of micro-data simultaneously, effortlessly executing tasks such as optimal product placement and precise inventory management to orchestrate a level of retail complexity previously unimaginable.
Discovering innovative AI tools that bring their unique specialized intelligences to tackle complex retail challenges.
Kimonix is a cutting-edge AI-powered merchandising platform that leverages eCommerce intelligence to strategically position products, subsequently boosting overall revenue. The platform’s Advanced Merchandising System utilises its proprietary AMS engine, which simultaneously assesses multiple key performance indicators, including gross sales productivity, inventory levels, and customer behavior patterns, to inform data-driven merchandising decisions with precision and speed.
The AI engine seamlessly integrates with Shopify’s administration interface, eliminating the need for coding expertise and ensuring consistent synchronization with retailer analytics. The AI-powered platform generates dynamic product collections through the analysis of gross sales metrics, inventory levels, and customer data, automatically optimizing product placement to maximize revenue. The system consistently conducts A/B testing on various combination strategies, selecting the most effective approaches based on performance metrics.
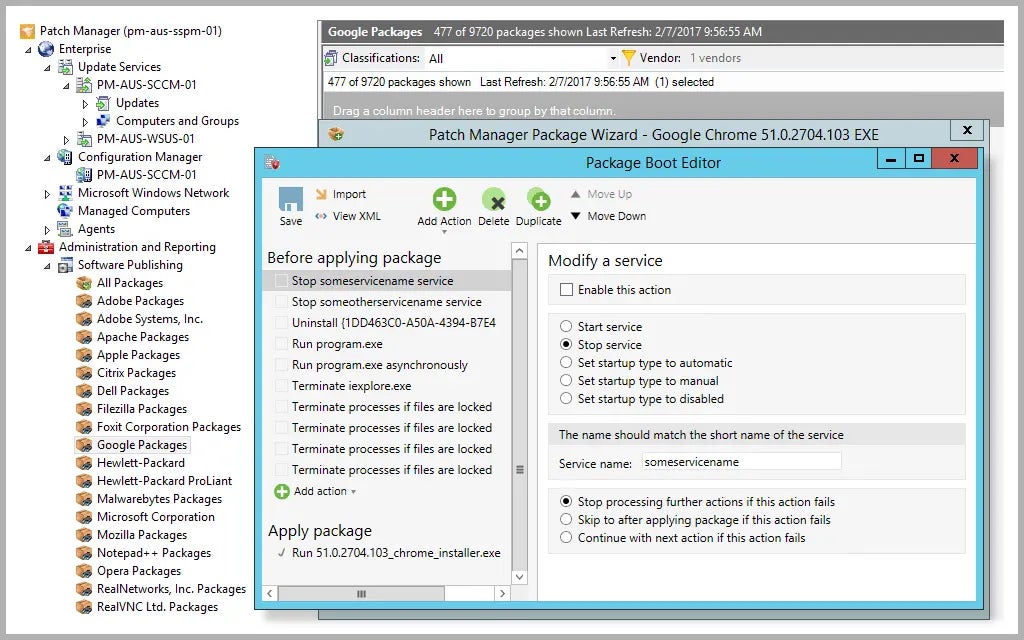
- Artificial Intelligence (AI) Powered Assortment Administration: Real-Time Optimization for Enhanced Retail Performance.
- Sorting products by multiple parameters primarily considering gross sales, inventory levels, and profit margins.
- The power of data-driven decision making: Validating Technique Effectiveness through Automated A/B Testing.
- Personalized product recommendations seamlessly integrated within retailer websites to enhance customer experiences.
- Email-driven lead generation campaigns seamlessly integrated with intelligent touchdown pages that dynamically adapt to user engagement and behavioral patterns.
Stackline is a cutting-edge AI-powered retail intelligence platform, harnessing insights from more than 30 major retailers to revolutionize eCommerce operations and maximize efficiency. The platform leverages insights from shopper behaviour, advertising metrics, and operational expertise across 26 international markets, empowering over 7,000 global brands to inform their retail strategies with data-driven wisdom.
The Platform’s Shopper OS functions as the primary evaluation hub for the AI, seamlessly processing vast amounts of first-party customer data from multiple retailers in real-time. The AI system tracks real-time metrics, including gross sales patterns and product rankings, while linking buyer behavior to marketing campaigns through its Amazon partnership. This retailer-agnostic attribution platform provides manufacturers with actionable insights into the impact of their marketing initiatives on overall revenue across various distribution networks.
The Beacon platform leverages the foundation of Stackline’s artificial intelligence capabilities, integrating data flows from four distinct domains: shopper understanding, advertising optimization, operational performance indicators, and competitive intelligence. The AI processes data to generate automated forecasts and scenario planning, simultaneously monitoring digital shelf presence and optimizing retail media campaigns across marketplaces.
- Real-time Insights Buyer Knowledge Processing System with Intelligent Messaging Capabilities
- Real-time analytics engine tracks overall sales and search effectiveness.
- What are the key drivers of our cross-channel attribution system’s success? We’ve found that seamless integration with Amazon is crucial to accurately measuring campaign effectiveness. By linking customer interactions across email, social media, and Amazon Advertising, we’re able to gauge the impact of each touchpoint on conversions.
- Artificial intelligence-driven predictive analytics and strategic situation assessment tools.
- Advanced AI-driven content generation solutions enable seamless creation of high-quality product listings that optimize online sales and customer engagement. By leveraging machine learning algorithms and natural language processing capabilities, these innovative tools can quickly produce detailed, accurate, and SEO-friendly descriptions that drive conversions and boost brand reputation.

Picture: Crisp
The Crisp Knowledge Platform leverages AI technology to aggregate retail intelligence from a vast network of over 40 retailers and distributors, empowering CPG manufacturers with unparalleled control over their retail strategies. The artificial intelligence aggregates and harmonizes diverse data flows – encompassing inventory levels to consumer transactions – to provide a comprehensive perspective on retail performance.
The platform’s artificial intelligence commences by refining and harmonising knowledge derived from multiple sources into consistent frameworks. This feature allows for in-depth evaluations of individual store owners as well as comprehensive nationwide perspectives. The system leverages specialized commerce APIs to facilitate processing of diverse knowledge sets, encompassing chargeback disputes, buy order technologies, and more, while maintaining rigorous knowledge governance through controlled access to specific categories, products, and retailers.
The AI’s knowledge processing capabilities extend into advanced analytics, empowering manufacturers to track shoppers’ purchasing habits across multiple channels and accurately link them to specific marketing initiatives. The system regularly synchronizes this data with existing knowledge reservoirs and repositories, empowering advanced AI algorithms to generate richer market intelligence. With seamless integrations to Microsoft Azure, Databricks, and a plethora of business intelligence tools, the AI establishes robust connections to third-party applications, streamlining forecasting and financial planning capabilities.
- Advanced Retail Integration Platform seamlessly consolidates insights from over 40 major retailers, empowering data-driven decision making.
- Revolutionizing Retail Operations: A Scalable Commerce API Framework
- A comprehensive framework for measuring cross-channel attribution across multiple marketing campaigns and initiatives.
- Real-time intelligence platform empowering data-driven decision-making through tailored visualizations.
- Artificial intelligence-driven knowledge consolidation synergizes seamlessly with inventory management systems to accelerate decision-making and optimize supply chain logistics?
Scanning Unlimited is a pioneering AI-driven evaluation platform capable of processing a staggering 300,000 Amazon products in mere hours, empowering sellers to uncover hidden gems and optimize their inventory selection. The AI swiftly processes vast product databases, analyzing up to 30,000 distinct items in a single scan, utilizing various data formats including UPC, ASIN, EAN, and ISBN codes.
The AI’s core evaluation engine uses a proprietary algorithm to estimate gross sales, specifically calibrated for the US Amazon market. The system simultaneously handles multiple key performance indicators: current market prices, competitor positioning, project expenses, and foreign exchange rate fluctuations across over 200 global currencies. The system conducts ongoing monitoring of restrictions, proactively flagging potential IP compliance issues before inventory allocation.
The platform’s advanced analytics engine interprets historical market trends through a trio of intuitive Keepa charts, revealing valuable insights into 30-, 90- and 365-day price fluctuations. For every product, the AI analyzes aggressive dynamics, together with Purchase Field possession and market positioning, whereas figuring out particular stock issues like Small & Mild eligibility and hazmat necessities.
- Enhanced High-Speed Product Scanning Engine Supporting Multi-Format Compatibility
- Estimation of Gross Sales Algorithm: A Revenue Calculation System
This algorithm estimates gross sales by analyzing historical data, seasonality patterns, and trends in the market. It takes into account factors such as product mix, pricing, and customer behavior to provide an accurate prediction.
Gross Sales Estimation Formula:
Gross Sales = (Average Daily Sales x Number of Days) + (Seasonal Adjustment x Average Monthly Sales)
Where:
* Average Daily Sales: The average daily sales for the past year
* Number of Days: The number of days in the target period
* Seasonal Adjustment: A factor that accounts for fluctuations in demand due to seasonal trends
* Average Monthly Sales: The average monthly sales for the past yearRevenue Calculation System:
1. Collect Historical Data: Gather data on previous sales, including dates, quantities, and prices.
2. Analyze Trends: Identify patterns and trends in the data, including seasonality and anomalies.
3. Calculate Gross Sales: Use the estimation formula to calculate gross sales based on historical data and seasonal adjustments.
4. Apply Discounts: Calculate any discounts or promotions that may affect revenue.
5. Determine Net Revenue: Subtract costs from gross sales to determine net revenue.By using this algorithm and revenue calculation system, businesses can make informed decisions about inventory management, pricing, and marketing strategies to drive growth and profitability.
- Real-time restrictions on content access are enforced through geographic-based IP blocking, coupled with automated alerts for non-compliance.
- Multi-timeframe historic evaluation instruments
- Enhanced Surveillance: Proactive Purchase Field Monitoring
Here is the rewritten text:
Triple Whale is an AI-powered knowledge evaluation platform that consolidates disparate Shopify retailer data streams, including advertising metrics and inventory levels, into a unified intelligent system. Triple Whale’s AI seamlessly integrates data from multiple sources, including Shopify, Google Analytics, and marketing platforms, to provide retailers with comprehensive insights that empower informed decision-making.
At the heart of Triple Whale lies its innovative Triple Pixel technology, utilizing first-party customer data to meticulously map the entire buying process, providing unparalleled insights into consumer behavior. The AI assesses every touchpoint throughout the buyer journey, leveraging a comprehensive Impact Attribution model to quantify the distinct effects of various marketing channels on sales. Allowing retailers to accurately track how their advertising investments translate into tangible revenue.
By leveraging past advertising trends, Willy, the platform’s AI-powered assistant, continuously monitors retailer performance, detecting unusual anomalies and potential issues before they impact revenue. The system processes real-time stock activity, integrates with logistics partners such as ShipBob and ShipStation, and notifies retailers of impending inventory depletion for promotional items.
- Real-time analytics-driven fusion of diverse information sources for enhanced decision-making.
- Triple Pixel: A Comprehensive Monitoring System for Seamless Buyer Journey Evaluation?
(The original text has been improved to add a question mark at the end and changed the title to a more engaging and informative format.)
- Detecting Anomalies in AI-Generated Data: Automated Alert System
- Real-time inventory tracking seamlessly integrated with logistics platforms ensures optimal supply chain management, minimizing delays and costs.
- A buyer-centric predictive analytics platform for real-time customer profiling and personalized marketing initiatives.
Syndigo is a leading AI-powered content creation platform that ensures the accuracy and appeal of product information across various retail touchpoints. The platform’s AI technology scrutinizes and enhances product information – encompassing fundamental specifications alongside rich multimedia assets – thereby guaranteeing that customers consistently access engaging, accurate data regardless of their browsing location.
The AI’s product data management system surpasses simple knowledge storage capabilities. Utilizing the innovative capabilities of SmartPrompts in tandem with ChatGPT, the artificial intelligence seamlessly reconfigures fundamental product information into comprehensive, search engine optimization-enhanced descriptions that subsequently stimulate sales. When new content is ready to update, the system seamlessly synchronizes changes across all connected platforms, ensuring a consistent brand presence regardless of where customers shop – be it Amazon, Walmart, or niche retailers.
The VendorSCOR device serves as the artificial intelligence’s central processing unit, continuously scrutinizing the quality of product information across the digital sales landscape. The system assesses each product webpage, identifying deficiencies and opportunities before automatically guiding manufacturers on targeted improvements. This innovative auditing course guarantees that product content not only satisfies technical requirements but also resonates with customers through engaging visuals and immersive experiences.
- AI-powered Content Creation Platform seamlessly integrating with ChatGPT capabilities.
- Industry-leading multi-format syndication engine compliant with GDSN, ACES, and PIES standards.
- Automated Content Material Grading: Enhancing Feedback Directions
To streamline educational evaluation, institutions are increasingly relying on AI-powered platforms to assess student performance. These automated systems provide instant feedback, freeing instructors from tedious grading tasks and allowing them to focus on more important aspects of teaching. However, the quality of this feedback remains a subject of concern, as it may not accurately reflect students’ understanding of complex concepts or nuanced thinking processes.
To address these limitations, educational institutions must carefully design and implement AI-driven grading tools that provide actionable insights rather than simplistic scores. By integrating AI-powered platforms with human expertise, educators can develop more comprehensive assessment models that account for individual learning styles, cultural backgrounds, and linguistic abilities.
Key considerations for enhancing automated content material grading include:
1. **Contextual understanding**: AI-driven grading systems must be able to contextualize student responses within the broader framework of the assignment or course.
2. **Domain-specific knowledge**: AI algorithms should be trained on large datasets specific to the subject matter being assessed, enabling them to recognize subtle differences in student thinking and writing styles.
3. **Human judgment**: Educators must actively engage with AI-generated feedback, providing nuance and depth to the grading process by incorporating their own expertise and pedagogical insights.
4. **Student engagement**: To promote active learning, AI-powered platforms should incorporate interactive elements that encourage students to explore concepts through hands-on activities, simulations, and real-world applications.By prioritizing these considerations, educational institutions can harness the power of AI-driven grading systems to provide more accurate, informative, and actionable feedback that supports student growth and development.
- A comprehensive digital asset management (DAM) platform for storing, organizing, and sharing multimedia content.
- Real-time analytics engine for instantaneous product performance optimization.

Picture: Trendalytics
Here is the rewritten text:
Trendalytics leverages its cutting-edge AI technology to decipher retail trends by processing vast amounts of data from social media, search patterns, and market intelligence. By identifying significant trends before they reach the mass market, manufacturers can leverage the Internet of Consumer Behavior to uncover hidden patterns and convert complex data into practical decision-making tools.
The AI’s pattern-evaluation capabilities delve profoundly into complex structures. Through concurrent analysis of visible content, social discourse, and purchasing behaviors, the system crafts complex models of behavioral lifecycles. By monitoring every potential pattern, retailers gain valuable foresight into what’s to come.
As a sophisticated market intelligence platform, the AI excels at identifying trends with ease and precision. The text scrutinizes rival strategies through a comprehensive examination of their products, pricing structures, and promotional tactics. By integrating an aggressive market perception with in-depth consumer behavior analysis, a comprehensive understanding is formed that not only identifies what’s selling but also uncovers the underlying reasons behind its appeal to customers.
- Effective multi-channel pattern detection systems with comprehensive lifecycle monitoring are crucial for identifying and analyzing complex patterns across various data streams. By leveraging advanced analytics and machine learning techniques, these systems can detect anomalies, predict trends, and provide real-time insights to drive informed decision-making. With a robust lifecycle monitoring framework in place, organizations can proactively identify and address potential issues before they escalate, ultimately reducing costs, improving efficiency, and enhancing overall performance.
- AI-powered Product Evaluation Platform?
- High-performance cognitive analytics for strategic decision-making and risk assessment.
- Shopper conduct evaluation framework
- Predictive analytics engines harness machine learning algorithms to forecast patterns in vast datasets, empowering businesses to make informed decisions. By analyzing historical trends and correlations, these sophisticated tools identify subtle relationships and anticipate future outcomes with remarkable accuracy.
RetailAI360 is a cutting-edge analytics platform that leverages real-time retail data streams to drive operational efficiencies and accurately forecast market shifts. The AI continuously synthesizes real-time insights on stock levels, sales patterns, and customer behavior to empower retailers with timely and informed decision-making.
The system’s core engine simultaneously handles three fundamental knowledge categories: stock metrics, buyer interactions, and gross sales channel performance metrics. The AI system monitors stock levels, automatically detecting when inventory falls outside predetermined parameters and triggering timely reorders to maintain optimal quantities. The buyer evaluation system meticulously monitors search patterns and purchase histories to uncover emerging trends and preferences. The system seamlessly integrates data from brick-and-mortar stores, online platforms, and mobile applications to generate comprehensive performance insights.
The AI’s processing capabilities extend to predictive analytics, harnessing historical patterns to forecast future trends and demands. This enables retailers to transition from reactive to proactive management, particularly with regards to inventory optimization and customer interaction strategies.
- Real-time analytics engine equipped with instant alert functionality.
- Multi-channel conduct evaluation system
- AI-powered stock optimization instruments
- Predictive pattern detection framework
- Real-time Analytics Platform: Transparency Unlocked
LEAFIO AI is a retail operations platform that streamlines inventory management, optimizes store layouts, and connects retailers through intelligent automation. Throughout its retail scope, the AI seamlessly integrates with individual store shelves, warehouse distribution networks, and more, establishing a cohesive framework for optimizing retail operations.
The platform’s stock intelligence shines with self-adjusting algorithms that learn and adapt in real-time, providing unparalleled insights. As market conditions evolve, the AI’s replenishment patterns adjust dynamically to maintain optimal inventory levels, ensuring resilience in the face of uncertainty. The dynamic inventory management system seamlessly integrates with retailers’ camera feeds, leveraging AI-powered image recognition to rapidly detect and alert for low stock levels in display cases, subsequently triggering automated replenishment procedures.
With its unparalleled accuracy, the AI optimizes retail store designs. Its proprietary planogram optimisation system scrutinizes customer flow patterns and product interdependencies, proposing store layouts that boost revenue while preserving operational efficiency. The system efficiently organizes each macro retailer’s layout and micro-shelf arrangements to ensure every product is perfectly situated in its optimal location.
- Self-learning demand forecasting engine
- Real-time Shelf Monitoring with Visual Recognition.
- Multi-level provide chain optimization system
- Dynamic planogram administration instruments
- Cloud-based analytics dashboard
ContactPigeon is a cutting-edge AI-powered buyer engagement platform, utilizing advanced analytics to uncover valuable insights from customers’ purchasing behavior across multiple touchpoints, thereby fostering more meaningful relationships between retailers and their loyal clientele. The system aggregates diverse knowledge flows, including website interactions and purchase histories, to create detailed customer profiles that power targeted marketing efforts.
The AI’s mind persistently scrutinizes and adjusts to buyer notifications. As users engage with merchandise, open emails, and interact with chat messages, the AI algorithm absorbs these behaviors to refine its understanding. This fosters a dynamic suggestion loop where each buyer interaction propels subsequent communications to become increasingly tailored and captivating. The system executes automated workflows in response to specific buyer actions, ranging from cart abandonment notifications to targeted post-purchase follow-up communications.
The platform’s omnichannel communication system seamlessly integrates personalized messaging across email, SMS, push notifications, and Facebook Messenger. The AI optimizes timing and channel selection for each communication, while a dedicated retail chatbot handles customer service requests.
- Real-time Conduct Evaluation Engine with Predictive Capabilities
- Multi-modal communication network featuring AI-driven inventory management?
- Streamlined Buyer Journey Orchestrator
- Retail AI powered conversational assistant seamlessly resolves customer inquiries and concerns.
- Dynamic Segmentation Instruments for Behavior-Based Focusing on High-Value Customers
Reworking Retail Administration By AI
Innovative AI-powered retail management platforms usher in a transformative shift in the way businesses approach their daily operations. Devices excel in distinct domains: Kimonix masterfully places products, Stackline unlocks market insights, Crisp streamlines CPG processes, and Trendalytics accurately forecasts future trends. Collectively, these solutions form a comprehensive toolkit enabling retailers to process and respond to data at unparalleled velocities and scopes.
As the retail landscape continues to evolve, it is clear that those who harness the power of AI’s analytical capabilities will hold a significant advantage in shaping its future trajectory. As e-commerce platforms continue to advance, we can expect to witness seamless fusion of disparate retail functionalities – encompassing inventory management to customer interaction. As retailers seamlessly integrate AI tools into their operations, they’re not just keeping pace with technological advancements – they’re proactively forging a new path in e-commerce.












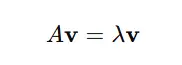

")