


Achieving Unparalleled Efficiency through Remote Learning?
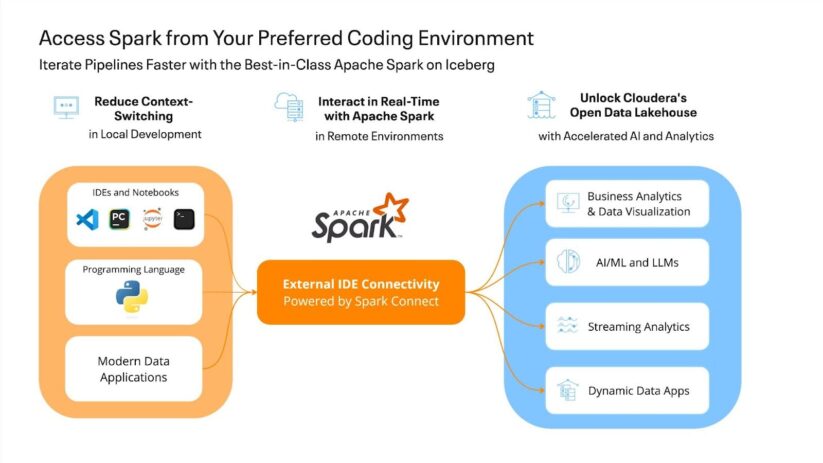
Finest-in-Class Apache Spark on Iceberg
Why Cloudera Information Engineering?
Able to Discover?


As AI and cloud computing continue to evolve at a breakneck pace, the demand for high-performance computing infrastructure has skyrocketed, driving innovation in data centers and sparking unprecedented growth in the industry.
Information centers, the often-overlooked backbone of our digital ecosystem, are currently struggling to reconcile a growing conundrum. While data centers energize online lives, they are also among the biggest energy consumers, significantly contributing to global energy usage. As generative AI technologies continue to gain traction and global workloads expand exponentially, a pressing concern has emerged: the rising environmental impact of our collective digital endeavors.
How can information centers balance AI’s processing demands without sacrificing operational efficiency? That’s the place, where a collaborative venture led by Pink Hat, alongside industry giants Intel, Bloomberg, and IBM, takes shape. Can IT operations achieve optimal power effectiveness by implementing an innovative strategy called energy capping, which strikes a balance between environmental sustainability and operational efficiency?
While energy capping may seem complex, its essence is actually about strategically managing power usage. By leveraging Kubernetes, Prometheus, Kepler, and Customized Resource Definitions (CRDs), Climatik enables real-time monitoring and adjustment of energy usage. The end result? An information center can effortlessly mitigate the pesky power spikes generated by intense AI workloads without compromising efficiency.
Ultimately, it boils down to establishing a budgetary framework for electricity costs. Kubernetes administrators can dynamically adjust these resource constraints to ensure that operations remain sustainable while allowing heavy-duty AI applications to run smoothly and efficiently.
Climatik is more than just a resolution – built upon a robust, cloud-native foundation that seamlessly integrates with existing infrastructure. Here’s a concise overview of the technology that drives everything:
This innovative mixture enables Climatik to reduce power consumption without compromising the high performance required by AI workloads.
Deploying Climatik provides tangible advantages:
As artificial intelligence and cloud computing continue scaling, the imperative for energy-efficient solutions will only intensify. Climatik’s innovative approach to energy capping provides a logical and forward-looking solution for data centers seeking to significantly reduce their carbon emissions while maintaining peak performance.
Looking ahead, Climatik will enhance its capacities by seamlessly integrating with additional monitoring and management tools. What’s the purpose? To build a robust and scalable system capable of adapting to the unique needs of any information center.


With all of the potential advantages promised by means of AI, it’s no surprise corporations are desirous to get in on the motion. However a brand new survey from Capital One reveals a stark disconnect between how assured enterprise leaders are of their firm’s capability to implement AI and the way the know-how professionals really implementing the know-how really feel.
In response to the report — which surveyed virtually 4,000 leaders and know-how professionals — 87% of leaders consider their firm has a knowledge ecosystem geared up to deal with AI, 82% are assured of their capability to mobilize sources for AI, and 78% are assured of their capability to deal with the rising complexity and quantity of knowledge related to AI.
Eighty-four p.c of leaders additionally consider that their firm has the mandatory processes, instruments, and platforms to correctly handle their information.
Eighty p.c of them mentioned the information they should do their jobs is simple to seek out, 78% say it’s straightforward to know, and 77% say it’s straightforward to know.
The responses from know-how professionals inform a distinct story, nevertheless. Solely 35% of tech practitioners consider they’ve a powerful information tradition, and people who don’t blame inconsistent assist and schooling.
Seventy p.c of the tech practitioners surveyed mentioned they spend as much as 4 hours per day fixing information points, conducting high quality checks, or correcting errors.
“The period of time tech practitioners spend addressing information points signifies that corporations could also be overlooking key parts of knowledge administration, which might affect their capability to execute on AI methods,” mentioned Terren Peterson, VP of knowledge engineering at Capital One. “AI amplifies the necessity for high-quality, reliable information that’s error-free, has clearly described lineage and metadata, and is barely used the place permitted. As information complexity grows, corporations should spend money on sturdy information governance to make sure accountable and efficient use.”
Moreover, although 78% of tech practitioners and 82% of leaders agree on the significance of getting an AI technique, solely about half of them — 53% of tech practitioners and 55% of leaders — are literally absolutely acquainted with their firm’s AI technique.
The report additionally discovered that 36% of tech practitioners consider their group has the correct expertise for implementing advanced AI tasks, in comparison with 47% of leaders. Additional, solely 33% of tech practitioners and 41% of enterprise leaders really report having efficiently scaled AI.
“In the end, the boldness hole revealed within the survey findings illustrates a big disconnect inside organizations. Whereas leaders report confidence of their information ecosystems, the information administration struggles of tech practitioners, lack of data-driven tradition and lack of readability round AI technique reveal a extra advanced actuality. Recognizing and bridging this disparity is crucial to constructing a basis for AI capabilities and use instances that may result in significant enterprise outcomes in the long run. Firms that shut this hole shall be higher positioned to leverage AI’s full potential and unlock extra sturdy, long-term worth within the years forward,” Capital One wrote in a weblog submit.
For the survey, Capital One teamed up with Morning Seek the advice of to survey enterprise leaders and tech practitioners from July 19-30, 2024. Roughly 2,100 enterprise leaders at corporations with over 500 workers and 1,800 tech practitioners at equally sized corporations had been surveyed.

As the proliferation of artificial intelligence technologies accelerates, our clients are grappling with novel complexities in safeguarding their intellectual property and objectives. As organizations increasingly adopt AI technologies, they are poised to deploy these workloads across a hybrid landscape of cloud, edge, and dedicated infrastructure, where privacy and security concerns assume paramount importance.
With its robust architecture spanning floors to clouds, this cutting-edge enterprise AI-ready database effectively addresses the complexities of data management and intelligence, empowering clients’ knowledge with seamless integration of AI capabilities. The latest release further solidifies SQL Server’s commitment to innovation, building on its three-year legacy of advancements in performance and security, now featuring cutting-edge AI capabilities. With seamless integration of Microsoft Cloths, clients can effortlessly channel their expertise into the cutting-edge realm of information analytics. The Azure-based discharge empowers seamless operations across cloud, on-premises data centers, and edge environments, providing customers with streamlined database management.
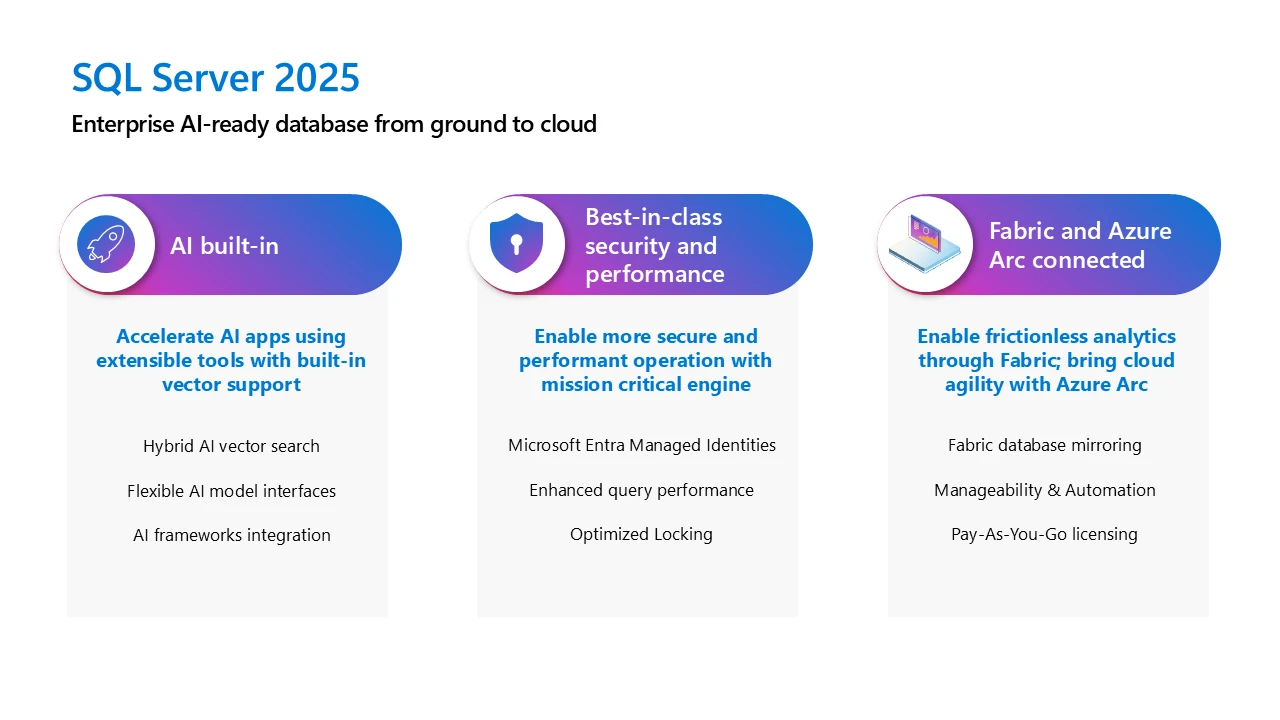
Over time, SQL Server has evolved far beyond its origins as a traditional relational database. With the latest release of SQL Server, we’re empowering clients to build AI capabilities seamlessly integrated with the database engine. Microsoft SQL Server 2025 is undergoing a significant transformation, shifting towards a native vector database, leveraging built-in filtering capabilities and vector search technology to deliver impressive performance, making it readily accessible for developers using T-SQL.
The innovative model integrates AI capabilities, streamlining the enhancement and retrieval of augmented technology (RAG) patterns by providing secure, high-performance, and intuitive vector assistance, seamlessly integrating familiar T-SQL syntax for effortless utilization. By integrating vectors into the system, you’ll have the ability to seamlessly combine SQL expertise with advanced AI-powered vector search capabilities.
SQL Server 2025 is a cutting-edge, enterprise-grade vector database that seamlessly integrates artificial intelligence capabilities, ensuring robust data security and regulatory compliance for sophisticated knowledge management. This innovative solution integrates a native vector retailer and index, fueled by DiskANN’s vector search technology that leverages disk storage to efficiently uncover similar data points within massive datasets. These databases facilitate efficient information retrieval by leveraging semantic search capabilities to accurately extract relevant knowledge. Within the latest SQL Server framework, a cutting-edge AI model management capability is integrated into the engine through RESTful interfaces, empowering users to seamlessly deploy and utilize AI models across diverse environments – from edge to cloud.
Whether clients are actively engaged in knowledge preprocessing, model training, or RAG pattern development, extensible, low-code tools provide adaptable model interfaces within the SQL engine, backed by T-SQL and external REST APIs. These tools enhance developers’ capacity to build diverse AI applications through streamlined integration with cutting-edge AI frameworks, such as LangChain, Semantic Kernel, and Entity Framework Core.
As data-driven applications similar to those in AI development require scalable architecture, developers must prioritize extensibility, framework selection, and knowledge augmentation to maximize their productivity. Our guarantee ensures that SQL provides top-tier expertise for developers by seamlessly integrating features akin to RESTful APIs, GraphQL connectivity via Data API Builder, and robust expression capabilities. Native JSON support enables builders to effectively manage frequently changing schema and complex data hierarchies, thereby simplifying the development of more dynamic applications. We are further refining our SQL enhancement efforts to ensure maximum extensibility, performance, and user-friendliness in their implementation. With robust safety features built into the SQL Server engine, this platform is poised to deliver seamless AI capabilities in an enterprise setting.
SQL Server 2022 is a business leader in database security and performance. Managed identities significantly enhance credential management, minimising the risk of vulnerabilities while providing comprehensive compliance and auditing capabilities. SQL Server 2025 introduces support for outbound authentication using MSI (Managed Service Identity) for SQL Server instances.
We’re also introducing efficiency and availability improvements, thoroughly tested in production environments with Microsoft Azure SQL, to enhance the capabilities of SQL Server. Within the innovative framework, users will be empowered to optimize workload productivity and streamline issue resolution through advanced query refinement and expedited execution.
The Non-Compulsory Parameter Plan Optimization (OPPO) feature enables SQL Server to autonomously select the optimal execution plan, leveraging customer-supplied runtime parameter values and significantly reducing the impact of unhealthy parameter sniffing on complex workloads. Statistics on secondary replicas are continuously updated, ensuring that data remains accurate and complete even in the event of a restart or failover, thus preventing potential efficiency losses. Concerning query execution, SQL Server’s enhancements in batch mode processing and columnstore indexing enable it to be a mission-critical database for demanding analytical workloads.
By leveraging Transaction ID (TID) Locking and Lock After Qualification (LAQ), optimized locking significantly diminishes lock remembrance consumption, thereby minimizing the impact on concurrent transactions. This capability enables clients to prolong downtime and enhance simultaneous user capacity as well as scalability specifically for SQL Server operations.
Occasion streaming in SQL Server enables seamless integration of disparate systems in real-time, facilitates efficient duty segregation, and empowers organizations to make data-driven decisions through real-time analytics. The addition of advanced database engine capabilities enables the seamless publication of incremental changes to knowledge and schema to a designated destination, such as Azure Event Hubs or Kafka, in near real-time.
When creating a knowledge warehouse or lake, effectively integrating diverse knowledge sources involves the design, execution, and management of sophisticated ETL processes, enabling seamless transitions between operational data stored in SQL Server and other systems. Traditional approaches fail to facilitate seamless knowledge transfer in real-time, resulting in a delay that hinders the generation of timely analytics. Companies providing comprehensive, integrated, and AI-powered knowledge analytics solutions that cater to the evolving demands of complex data requirements. Microsoft’s Mirrored SQL Server Database in Cloud is a fully managed and highly available service that simplifies near-real-time replication of SQL Server data to Microsoft Azure Cosmos DB (formerly known as Azure DocumentDB). By leveraging mirroring, customers can seamlessly synchronize knowledge from SQL Server databases running on Azure virtual machines or outside of Azure, enabling real-time replication of online transaction processing (OLTP) and operational retail workloads into OneLake’s unified platform for analytics and insights generation.
Azure remains an integral component of SQL Server’s ecosystem. Azure Arc enables SQL Server 2022 to extend cloud capabilities, empowering customers to manage, secure, and govern their SQL estate at scale across on-premises and cloud environments. The comprehensive suite of capabilities, including automated patching, automated backups, real-time monitoring, and best practices evaluation, empowers clients with the means to efficiently outsource routine tasks and fortify their business resilience. In addition to streamlining SQL Server management with Azure Arc, Microsoft also offers a pay-per-use option for simplified licensing, granting customers greater flexibility and transparency in their database usage.
We are currently onboarding customers and partners for the SQL Server 2025 preview, in preparation for its general availability later this year.
To leverage the advanced features in the SQL Server 2025 Group Expertise Preview (CTP).1 Stay current with the latest advancements in SQL Server 2025 and its capabilities.
Microsoft has just released the first preview of SQL Server Management Studio (SSMS) 21, simplifying the experience for database administrators and developers alike. The upcoming launch seamlessly incorporates Microsoft Copilot features into SQL Server Management Studio (SSMS). The Copilot’s SQL expertise streamlines improvements with real-time recommendations, intelligent code completions, and best-practice-following suggestions. Are you ready to dive in and explore the latest feature? Then, click to get started!
1Not all features announced for this blog will be available in the initial Community Technology Preview (CTP) release.
Asad Khan serves as the Vice President of SQL Merchandise and Partnerships. As the leader of engineering and product administration for both SQL Server and Azure SQL, he oversees the development and delivery of these critical technologies.

Searching for coupons to help you save on your next FPV product purchase? We’ve acquired you coated! Today, we’re shining a light on extraordinary deals and promo codes from prominent remote control (RC) retailers. Bookmark this webpage – we update it frequently with the latest information.
While I haven’t personally verified every coupon’s validity, there’s certainly no harm in trying them out. When you’re in possession of exclusive coupons or attractive deals, feel free to share them with us.
Coming quickly…
Coming quickly…
Coming quickly…
Coming quickly…
Coming quickly…
Coming quickly…
Coming quickly…
Coming quickly…
Black Friday Coupons:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |||||
Black Friday Bargains Unleash Your Inner Racer with Exclusive Deals on FPV-Connected Gear
Accessible on this spreadsheet.
TBC
| 23-Nov | Thu | Up to date Clearance Part | |
| 24-Nov | Fri | BF Exclusive: Unbeatable Savings on BF+ and BFCM Merch! | Lumenier Model Sale Function |
| 24-Nov | Fri | Lumenier Antennas Flash Sale | Xilo Model Sale Function |
| 24-Nov | Fri | Lumenier Lux F4 HD: Unbeatable Flash Sale Opportunity | Tattu Model Sale Function |
| 24-Nov | Fri | Lumenier Propellers Flash Sale | Flywoo Model Sale Function |
| 25-Nov | Sat | Unbeatable Deals on Lumenier Zip V2 Motors: Limited Time Opportunity | Happymodel Model Sale Function |
| 25-Nov | Sat | Unlock Exclusive Offers on Lumenier Energy Solutions | iFlight Model Sale Function |
| 26-Nov | Solar | Lumenier Batteries Flash Sale | GEPRC Model Sale Function |
| 26-Nov | Solar | Limited Time Offer: Lumenier AXII HD 2 Visor – Non-Combo Version | Diatone Improvements Model Sale Function |
| 27-Nov | Mon | Lumenier Visor Flash Sale | EMAX Model Sale Function |
| 27-Nov | Mon | Lumenier Bardwell Body Flash Sale | Axisflying Model Sale Function |
| 27-Nov | Mon | Lumenier AIO Flash Sale |
Promotion element right here:
, a novel framework that empowers agents to create positive change by setting clear goals, fostering collaboration, and cultivating resilience. In this primer, we’ll delve into the evolution of RAG, its core principles, and the benefits it offers for personal and professional growth. By understanding how individuals and teams can leverage Agentic RAG to achieve their objectives, you’ll gain insights into how to apply this framework in various contexts, from personal development to organizational transformation.")
.

For many entrepreneurs, consistently generating revenue and scaling their businesses often proves to be a significant challenge. Typically, people mistakenly assume that driving significant revenue growth hinges on persuasively convincing customers to buy, often through coercion or manipulation. While it may seem intuitive to focus on convincing people to buy, ultimately this approach would backfire.
Typically, numerous small business owners struggle to generate revenue, hindered by a limiting mindset stemming from their own cognitive biases.
This article explores three common mindsets that impede gross sales and provides actionable methods for overcoming them, ultimately driving growth, increasing revenue, and fostering a sustainable online business.
Right here we go…
Over more than a decade of guiding small business owners in refining their strategies, I’ve discovered that the most effective path to securing consistent revenue growth and increasing profitability lies not in aggressive marketing tactics, but rather in building relationships with loyal customers. Indoctrination in this context refers to the process of educating or guiding customers to understand their own needs and desires, ultimately shaping their preferences and purchasing decisions. By adopting this approach, you redirect your emphasis from showcasing your offerings to enlightening prospective clients about the enhancements they must experience.
While the most successful entrepreneurs often recognize that cultivating trust is crucial for driving additional revenue, it’s actually by understanding customers’ needs that they can create a loyal following. This approach cultivates genuine connections among events, thereby establishing an environment where customers feel empowered and confident in their purchasing decisions.
As a responsible business practitioner, you should refrain from putting potential clients under pressure while pitching your services. By focusing their efforts on achieving specific, measurable outcomes, you empower learners to clarify their goals and develop a clear understanding of what they’re striving for. It’s generally most effective to acknowledge customers’ struggles and demonstrate a willingness to guide them towards the solutions they seek. Educating purchasers on this context does not necessarily imply a direct correlation with increased sales. By providing insights into their desires, we empower individuals to make informed choices that align with their aspirations.
As you empathetically uncover your prospects’ desires, you naturally synchronize your goals with theirs. By positioning yourself as a reliable confidant, you establish a strong foundation for trust, thereby amplifying your authority and subsequently enhancing the likelihood of securing additional revenue streams.
Purchasers often arrive at the market with preconceived notions that they know exactly what they require, when in reality, they may be unaware of their true needs. In reality, customers’ desires are often explicitly articulated. Promoting responsibly means encouraging customers to acquire products they truly require and can realistically afford, without pressuring them into unwanted purchases. Serving to help them reach a well-informed decision about their existing requirements is crucial.
This misconception is surprisingly prevalent among consultants and other skilled services professionals who refer to themselves as “consultants.” They often mistakenly believe they have a deeper understanding of their clients’ businesses than their clients themselves, which empowers them to dictate what those clients require.
While many customers have a clear idea of their needs, they often require help refining their expectations or identifying the ideal solution? As a matchmaker, you’re the one who helps individuals discover their perfect matches. Rather than assuming customers’ ignorance, consider adopting a more consultative tone that empowers them to make informed decisions; this approach will likely resonate more positively with your target audience, fostering trust and loyalty.
The starting point is reframing one’s thought processes to assume that customers inherently grasp their own requirements? Despite this, individuals require your support in clarifying and achieving their goals. To consider implementing changes.
(SUMMARIZED TEXT) By doing so, this approach enables you to demonstrate a genuine understanding of the individual’s needs and desires.
Let’s confront a crucial reality: millions of people worldwide desire exactly what you’re offering right now. Because they’re unaware of your existence, individuals aren’t searching for what you offer – not because they don’t crave your services or products, but due to their lack of knowledge about your brand. They are oblivious to the fact that you have the solution to their problems waiting for them.
To effectively tackle this challenge, what’s crucial is unobstructed visibility. By showcasing your skills and expertise to your target audience, you can effectively position yourself as a thought leader in your field. Regardless of location or profession, when you demonstrate an understanding of others’ challenges and a willingness to help overcome them, people will find you.
The most effective way to increase your visibility is to position yourself prominently within your target market. Interval! I find that these two methods are particularly effective in constructing visibility:
It’s not about aggressively pitching services or products to unwilling customers. By recalibrating your mental approach, you can tap into your target customer’s desires and establish a strong presence in the marketplace. By leveraging these methodologies, entrepreneurs may establish a lasting and valuable business. Profitable entrepreneurs empower others to achieve their goals, which fosters natural sales opportunities.

As you’ve established a functional habitat for your smart home ecosystem or are starting from the ground up, it’s an excellent opportunity to explore discounted IoT devices during the Black Friday shopping period. One such machine is the portable printer, which you may acquire for $70 right now. The stock has plummeted by 30% below its average value and is hovering near a historic nadir. The sale features a trio of colorways, paired with snow, fog, and linen hues.
The second-generation wired camera, designed specifically for indoor use, excels at capturing crisp 1080p High Dynamic Range (HDR) video footage. The object detection system employs subtle movements and leverages AI-driven cleverness to skillfully distinguish between people, creatures, and vehicles. The digital camera features built-in evening vision and can record up to an hour of footage locally on its device, making it a valuable asset in the event of a Wi-Fi disruption.
The camera features a two-way audio operation, equipped with both a microphone and a speaker for seamless communication. Users can activate the integrated Google Home app to initiate a conversation. The app also permits instant dispatch of emergency services should the conversation fail to progress as intended; however, this feature is exclusive to users with a Nest Conscious subscription.
Although this caveat arises frequently with many modern safety cameras. Much of the content is inaccessible due to the Nest Conscious paywall in place.
This plan grants subscribers 60 days of video archives and the ability to watch live streams on smart devices, including smart TVs. Subscribers will receive notifications when familiar faces are detected by the digital camera.

Restoring community connectivity requires every detail to be meticulously addressed. Even in such rare cases, there may exist edge instances where the script would fail to function properly, requiring a reboot of my machine. If some of a higher resolution were available, please let us know.
Reboot the machine and establish a connection to the hotspot; thereafter, ensure the correct community configuration persists through the execution of the following Python script. Will you be able to easily modify and tailor this content to suit your specific needs? WIFI_DEVICE_NAME To retain and subsequently restore iPhone USB tethering community settings.
import subprocess import re import json WIFI_DEVICE_NAME = "Wi-Fi" def get_network_info(): hardware_ports = subprocess.check_output( ["networksetup", "-listallhardwareports"], textual content=True ) wifi_match = re.search( f"{Hardware} Port: {WIFI_DEVICE_NAME}nDevice: (w+)", hardware_ports ) if not wifi_match: elevate Exception("No Wi-Fi interface discovered") interface = wifi_match.group(1) ifconfig_output = subprocess.check_output( f"ifconfig {interface}", shell=True ).decode().splitlines() ipv4_address = None ipv6_addresses = [] for line in ifconfig_output: if "inet " in line: ipv4_address = line.break up()[1] elif "inet6 " in line: ipv6_addresses.append(line.break up()[1].break up("%")[0]) netstat_output = subprocess.check_output( f"netstat -nr | grep default | grep {interface}", shell=True ).decode().splitlines() ipv4_router = ipv6_router = None for line in netstat_output: elements = line.break up() if len(elements) > 1: if ":" not in elements[1]: ipv4_router = elements[1] else: ipv6_router = elements[1].break up("%")[0] config = { "network_service_name": WIFI_DEVICE_NAME, "network_interface_id": interface, "ipv4_address": ipv4_address or "Unknown", "ipv4_subnet_mask": "255.255.255.0", "ipv4_router": ipv4_router or "Unknown", "ipv6_primary_address": ipv6_addresses[0] if ipv6_addresses else "Unknown", "ipv6_temporary_address": ipv6_addresses[1] if ipv6_addresses[1:] else "Unknown", "ipv6_clat46_address": ipv6_addresses[2] if ipv6_addresses[2:] else "Unknown", "ipv6_prefix_length": "64", "ipv6_router": ipv6_router or "Unknown", } config_filename = f"network_settings_{interface}.json" with open(config_filename, "w") as f: json.dump(config, f, indent=2) print(f"Saved config for {WIFI_DEVICE_NAME} ({interface}) to {config_filename}") if __name__ == "__main__": get_network_info() The Python script will produce a JSON file containing functional IPv4 and IPv6 configurations within the same directory.
Create one other Python script. Operating your Mac? As a result of altering most community settings on the device, you cannot complete this process without sudo privileges.
import subprocess import json import time def run_cmd(cmd, ignore_errors=False): try: subprocess.run(cmd, check=True) print(f"Success: {' '.join(cmd)}") return True except subprocess.CalledProcessError as e: if not ignore_errors: print(f"Failed: {' '.join(cmd)}: {e}") return False def test_network(config_file): with open(config_file) as f: config = json.load(f) print("Setting up IP configuration...") # Configure IPv4 settings run_cmd(['sudo', 'networksetup', '-setmanual', config['network_service_name'], config['ipv4_address'], config['ipv4_subnet_mask'], config['ipv4_router']]) # Replace IPv4 routing run_cmd(['sudo', 'route', 'delete', 'default']) run_cmd(['sudo', 'route', 'add', 'default', config['ipv4_router']]) # Configure IPv6 settings run_cmd(['sudo', 'networksetup', '-setv6manual', config['network_service_name'], config['ipv6_primary_address'], config['ipv6_prefix_length'], config['ipv6_router']]) # Add further IPv6 addresses run_cmd(['sudo', 'ifconfig', config['network_interface_id'], 'inet6', 'add', config['ipv6_temporary_address'], 'prefixlen', config['ipv6_prefix_length']]) run_cmd(['sudo', 'ifconfig', config['network_interface_id'], 'inet6', 'add', config['ipv6_clat46_address'], 'prefixlen', config['ipv6_prefix_length']]) # Replace IPv6 routing run_cmd(['sudo', 'route', '-inet6', 'delete', 'default'], ignore_errors=True) run_cmd(['sudo', 'route', '-inet6', 'add', 'default', f"{config['ipv6_router']}%{config['network_interface_id']}"]) print("Wait for 1 second before resetting to auto/DHCP configuration... ") time.sleep(1) print("Resetting to automatic configuration...") # Remove all configured IP addresses output = subprocess.check_output(f"ifconfig {config['network_interface_id']}", shell=True).decode().splitlines() for line in output: if "inet " in line: run_cmd(['sudo', 'ifconfig', config['network_interface_id'], 'inet', line.split()[1], 'remove']) elif "inet6 " in line: run_cmd(['sudo', 'ifconfig', config['network_interface_id'], 'inet6', 'del', line.split()[1]]) # Reset to automatic configuration run_cmd(['sudo', 'networksetup', '-setdhcp', config['network_service_name']]) run_cmd(['sudo', 'networksetup', '-setv6automatic', config['network_service_name']]) if __name__ == "__main__": import sys test_network(sys.argv[1]) When tethering ceases to function, initiate the script and feed in the configuration file produced, thereby troubleshooting the issue.
python3 load_working_network_settings.py network_settings_en0.json Voila! Your website should hopefully be restored now.

| Specs | Value: ranging in price from $4.99 for a 1GB plan with a 7-day validity period to … Gadgets: Android, iOS Protection: 180 international locations |
| Today’s most compelling deals | |
| Causes to purchase |
|
| Causes to keep away from | No telephone quantity |
What’s Saily?
A top pick for globe-trotters, this provider offers robust coverage in over 180 countries worldwide, with affordable data plans starting at just $1.99 per gigabyte. Developed by Nord Safety, the same company behind NordVPN, Sailly offers dependable connectivity and personalized data options, featuring region-specific plans tailored to Europe, the Americas, and other parts of the world? Organizing is effortless with a seamless one-time setup, and round-the-clock buyer assistance ensures timely support is always available. Sailly offers a cost-effective and stress-free way to stay connected on-the-go.

Make the most of ! For a limited time, from November 21st to December 2nd, upgrade your mobile experience with our special offer. Enjoy 2GB of additional data for free with our 5GB plan, or get an extra 5GB of data on our 10GB and 20GB plans. Don’t forget to take advantage of their vacation package from December 2, 2024, to January 2, 2025? What unique details are there to explore?
:
Can we also offer numerous limited-time gifts, such as exclusive deals on our Black Friday sale from November 21st to December 2nd and a special winter getaway package available from December 2nd to January 2nd, ideal for first-time customers? Enjoy 2GB of complimentary storage when you opt for our 5GB plan, or take advantage of 5GB free with the purchase of our 10GB or 20GB packages. Switching to an eSIM can make traveling much more convenient in the long run.
Provide Date:
Black Friday: A Limited-Time Shopping Event – November 26-30?
Winter Vacation Promotion: Book from December 2, 2024 to January 2, 2025
Why Saily?
Sailly offers affordable eSIM solutions across a broad spectrum of European markets, ensuring comprehensive coverage and reliability. Provided by the same company behind NordVPN, a renowned digital private network (VPN) application. With a presence spanning over 180 international locations, Saily operates globally. The European plan encompasses a comprehensive network of 35 locations, including Turkey and Gibraltar.
Like Airalo, Saily exclusively assists in managing information plans without involving phone calls or SMS. Given the appeal of its affordable pricing and comprehensive coverage, we opted for this option, which offers a range of plans starting at just $4.99 for 1GB of data valid for seven days. Three plans are available: 3GB of data for 30 days at $12.49, 5GB of data for 30 days at $19.49, or 10GB of data for 30 days at $35.99? Or opt for a longer commitment with 50GB of data for 90 days at $95.99 or 100GB of data for 180 days at $179.99. That’s why we wholeheartedly recommend Saily’s versatile plans to our discerning audience. Whether embarking on a brief sojourn or a more extensive European summer adventure, Saily has got you covered for all your short-term and long-term travel needs.
The eSIM provides fast and reliable 4G or 5G wireless connectivity as you travel across Europe. Eliminating the need for purchasing local SIM cards and phone plans each time you visit a new destination. Acquiring an eSIM profile on your Sail device is effortlessly straightforward. To get started quickly, simply purchase a plan, download the app, and follow the straightforward on-screen instructions to expedite your setup process. If you encounter an activation issue, you may be entitled to a refund. We found Saily’s customer support to be genuinely commendable, offering a high level of assistance and responsiveness. By offering 24/7 buyer support through live chat, you may benefit greatly. Alternatively, customers can electronically mail their basic inquiries to assist@saily.com.
Sailly offers a budget-friendly option for first-time eSIM users seeking an affordable solution.
!
It is a sponsored publish. Sponsorships serve as a form of promotional marketing. The views and opinions expressed in this article are those of the sponsor, which may differ from our own perspectives.