I like music in WAV information. After I import from a CD, MacOS Music goes to the Gracenote database and updates numerous helpful details about the tracks from the CD. After I purchase music in Bandcamp, MacOS music does not do this. The data is offered, however it’s written into the Bandcamp filenames. Instance filename:
“I Suppose Like Midnight – Microtonal Honkytonk – 02 Spring Seems to be Mint.wav”
The primary half, earlier than “-” is the band title, “I Suppose Like Midnight”. The following half is the album title, “Microtonal Honkytonk”, then the observe quantity, 2, and at last the music title “Spring Seems to be Mint”.
At current, once I purchase music from Bandcamp, I’ve to sort that info into the related Music fields by hand. That is not very nice.
Is there a strategy to drive MacOS Music to replace the information on the songs from the standard Gracenote database with Bandcamp music I’ve already imported?
Is there some form of preparation I can do to the Bandcamp information to make Music deal with the import course of so that it is the similar as when a CD is imported–so that Music goes out to Gracenote to get the metadata?
What format is the metadata that MacOS pulls in? If I do know the format, and there’s a strategy to get Music to learn a file containing the information (an enormous “if), then I can most likely write somewhat code to transform the data in Bandcamp filenames into the information that Music needs to see.
FTC (Federal Commerce Fee) is launching a case towards Adobe resulting from alleged misleading practices associated to the corporate’s subscription providers. In keeping with the FTC, Adobe violates the Restore On-line Consumers’ Confidence Act and the fee highlights a number of key points.
Firstly, Adobe describes its subscription plan as month-to-month however fees cancellation charges when a consumer desires to cancel it sooner than one yr. Moreover, Adobe locations quite a few obstacles throughout the cancellation course of, and infrequently, customers are led to consider they’ve cancelled the plan when, in actuality, month-to-month funds nonetheless happen.
Adobe normally fees 50% of the remaining subscription funds as a cancellation charge. This might be a part of the explanation why Adobe’s subscription providers income ballooned from $7.7 billion in 2019 to $14.2 billion in 2023.
FTC factors out two defendants from Adobe – the Vice President Maninder Sawhney and the President of Digital Media David Wadhwani.
Adobe’s official response states that it could search authorized battle in courtroom and denies FTC’s allegations.
If discovered responsible by the Division of Justice, Adobe could be topic to financial penalties and it must refund clients who had been compelled to pay a cancellation charge.
Final month, The New York Occasions claimed that tech giants OpenAI and Google have waded right into a copyright grey space by transcribing the huge quantity of YouTube movies and utilizing that textual content as further coaching knowledge for his or her AI fashions regardless of phrases of service that prohibit such efforts and copyright regulation that the Occasions argues locations them in dispute. The Occasions additionally quoted Meta officers as saying that their fashions will be unable to maintain up until they comply with OpenAI and Google’s lead. In dialog with reporter Cade Metz, who broke the story, on the New York Occasions podcast The Every day, host Michael Barbaro referred to as copyright violation “AI’s Unique Sin.”
On the very least, copyright seems to be one of many main fronts thus far within the warfare over who will get to revenue from generative AI. It’s under no circumstances clear but who’s on the best aspect of the regulation. Within the exceptional essay Talkin’ ‘Bout AI Technology: Copyright and the Generative-AI Provide Chain, Katherine Lee, A. Feder Cooper, and James Grimmelmann of Cornell word:
Study sooner. Dig deeper. See farther.
“…copyright regulation is notoriously difficult, and generative-AI methods handle to the touch on a fantastic many corners of it. They elevate problems with authorship, similarity, direct and oblique legal responsibility, truthful use, and licensing, amongst a lot else. These points can’t be analyzed in isolation, as a result of there are connections in every single place. Whether or not the output of a generative AI system is truthful use can rely on how its coaching datasets have been assembled. Whether or not the creator of a generative-AI system is secondarily liable can rely on the prompts that its customers provide.”
But it surely appears much less necessary to get into the tremendous factors of copyright regulation and arguments over legal responsibility for infringement, however as a substitute to discover the political economic system of copyrighted content material within the rising world of AI companies: who will get what, and why? And fairly than asking who has the market energy to win the tug of warfare, we must be asking what establishments and enterprise fashions are wanted to allocate the worth that’s created by the “generative AI provide chain” in proportion to the function that numerous events play in creating it? And the way will we create a virtuous circle of ongoing worth creation, an ecosystem by which everybody advantages?
Publishers (together with The New York Occasions itself, which has sued OpenAI for copyright violation) argue that works comparable to generative artwork and texts compete with the creators whose work the AI was skilled on. Particularly, the Occasions argues that AI-generated summaries of reports articles are an alternative choice to the unique articles and harm its enterprise. They wish to receives a commission for his or her work and protect their present enterprise.
In the meantime, the AI mannequin builders, who’ve taken in huge quantities of capital, must discover a enterprise mannequin that may repay all that funding. Occasions reporter Cade Metz offers an apocalyptic framing of the stakes and a binary view of the doable end result. In The Every day interview, he opines that
“…a jury or a decide or a regulation ruling towards OpenAI may basically change the best way this know-how is constructed. The intense case is these corporations are now not allowed to make use of copyrighted materials in constructing these chatbots. And meaning they’ve to start out from scratch. They should rebuild all the things they’ve constructed. So that is one thing that not solely imperils what they’ve right this moment, it imperils what they wish to construct sooner or later.”
And in his unique reporting on the actions of OpenAI and Google and the inner debates at Meta, Metz quotes Sy Damle, a lawyer for Silicon Valley enterprise agency Andreessen Horowitz, who has claimed that “The one sensible method for these instruments to exist is that if they are often skilled on huge quantities of knowledge with out having to license that knowledge. The information wanted is so huge that even collective licensing actually can’t work.”
“The one sensible method”? Actually?
I suggest as a substitute that not solely is the issue solvable, however that fixing it could possibly create a brand new golden age for each AI mannequin suppliers and copyright-based companies. What’s lacking is the best structure for the AI ecosystem, and the best enterprise mannequin.
Unpacking the Drawback
Let’s first break down “copyrighted content material.” Copyright reserves to the creator(s) the unique proper to publish and to revenue from their work. It doesn’t defend information or concepts, however a singular ‘artistic’ expression of these information or concepts. And distinctive artistic expression is one thing that’s basic to all human communication. And people utilizing the instruments of generative AI are certainly typically utilizing it as a option to improve their very own distinctive artistic expression. What is definitely in dispute is who will get to revenue from that distinctive artistic expression.
Not all copyrighted content material is created for revenue. Based on US copyright regulation, all the things printed in any kind, together with on the web, is robotically copyrighted by the creator for the lifetime of its creator, plus 70 years. A few of that content material is meant to be monetized both by promoting, subscription, or particular person sale, however that’s not at all times true. Whereas a weblog or social media put up, YouTube gardening or plumbing tutorial, music or dance efficiency, is implicitly copyrighted by its creators (and might also embody copyrighted music or different copyrighted parts), it’s meant to be freely shared. Even content material that’s meant to be shared freely, although, has an expectation of remuneration within the type of recognition and a focus.
These desiring to commercialize their content material normally point out that in a roundabout way. Books, music, and flicks, for instance, bear copyright notices and are registered with the copyright workplace (which confers further rights to damages within the occasion of infringement). Typically these notices are even machine-readable. Some on-line content material is protected by a paywall, requiring a subscription to entry it. Some content material is marked “noindex” within the HTML code of the web site, indicating that it shouldn’t be spidered by search engines like google and yahoo (and presumably different internet crawlers). Some content material is visibly related to promoting, indicating that it’s being monetized. Search engines like google “learn” all the things they will, however legit companies typically respect alerts that inform them “no” and don’t go the place they aren’t speculated to.
AI builders absolutely acknowledge these distinctions. As The New York Occasions article referenced in the beginning of this piece notes, “Essentially the most prized knowledge, A.I. researchers stated, is high-quality info, comparable to printed books and articles, which have been fastidiously written and edited by professionals.” It’s exactly as a result of this content material is extra beneficial that AI builders search the limitless means to coach on all accessible content material, no matter its copyright standing.
Subsequent, let’s unpack “truthful use.” Typical examples of truthful use are quotations, copy of a picture for the aim of criticism or remark, parodies, summaries, and in newer precedent, the hyperlinks and snippets that assist a search engine or social media person to determine whether or not to devour the content material. Truthful use is mostly restricted to a portion of the work in query, such that the reproduced content material can’t function an alternative choice to the unique work.
As soon as once more it’s essential to make distinctions that aren’t authorized, however sensible. If the long run well being of AI requires the continuing manufacturing of fastidiously written and edited content material—because the forex of AI data actually does—solely essentially the most short-term of enterprise benefit may be discovered by drying up the river AI corporations drink from. Info will not be copyrightable, however AI mannequin builders standing on the letter of the regulation will discover chilly consolation in that if information and different sources of curated content material are pushed out of enterprise.
An AI-generated evaluate of Denis Villeneuve’s Dune or a plot abstract of Frank Herbert’s unique novel isn’t an alternative choice to consuming the unique and won’t hurt the manufacturing of latest novels or motion pictures. However a abstract of a information article or weblog put up may certainly be a ample substitute. If information and different types of top quality, curated content material are necessary to the event of future AI fashions, AI builders must be wanting arduous at how they may affect the longer term well being of those sources.
The comparability of AI summaries with the snippets and hyperlinks offered prior to now by search engines like google and yahoo and social media websites is instructive. Google and others have rightly identified that search drives visitors to websites, which the websites can then monetize as they may, by their very own promoting (or promoting in partnership with Google), by subscription, or simply by the popularity the creators obtain when folks discover their work. The truth that when given the selection to choose out of search, only a few websites select to take action offers substantial proof that, not less than prior to now, copyright house owners have acknowledged the advantages they obtain from search and social media. Actually, they compete for increased visibility by Search Engine Optimization and social media advertising and marketing.
However there may be actually purpose for internet publishers to concern that AI-generated summaries won’t drive visitors to websites in the identical method as extra conventional search or social media snippets. The summaries offered by AI are much more substantial than their search and social media equivalents, and in circumstances comparable to information, product search, or a seek for factual solutions, a abstract might present an inexpensive substitute. When readers see an AI Reply that references sources they belief, they take it as a trusted reply and should properly take it at face worth and transfer on. This must be of concern not solely to the websites that used to obtain the visitors however to those that used to drive it. As a result of in the long run, if folks cease creating prime quality content material to ingest, the entire ecosystem breaks down.
This isn’t a battle that both aspect must be seeking to “win.” As an alternative, it’s a possibility to suppose by the right way to strengthen two public items. Journalism professor Jeff Jarvis put it properly in a response to an earlier draft of this piece: “It’s within the public good to have AI produce high quality and credible (if “hallucinations” may be overcome) output. It’s within the public good that there be the creation of unique high quality, credible, and creative content material. It’s not within the public good if high quality, credible content material is excluded from AI coaching and output OR if high quality, credible content material isn’t created.” We have to obtain each objectives.
Lastly, let’s unpack the relation of an AI to its coaching knowledge, copyrighted or uncopyrighted. Throughout coaching, the AI mannequin learns the statistical relationships between the phrases or photographs in its coaching set. As Derek Slater has identified, a lot like musical chord progressions, these relationships may be seen as “fundamental constructing blocks” of expression. The fashions themselves don’t include a duplicate of the coaching knowledge in any human-recognizable kind. Moderately, they’re a statistical illustration of the chance, based mostly on the coaching knowledge, that one phrase will comply with one other, or in a picture, that one pixel shall be adjoining to a different. Given sufficient knowledge, these relationships are remarkably strong and predictable, a lot in order that it’s doable for generated output to carefully resemble or duplicate parts of the coaching knowledge.
It’s actually value realizing what content material has been ingested. Mandating transparency concerning the content material and supply of coaching knowledge units—the generative AI provide chain—would go a great distance in direction of encouraging frank discussions between disputing events. However specializing in examples of inadvertent resemblances to the coaching knowledge misses the purpose.
Usually, whether or not cost is in forex or in recognition, copyright holders search to withhold knowledge from coaching as a result of it appears to them which may be the one option to stop unfair competitors from AI outputs or to barter a payment to be used of their content material. As we noticed from internet search, “studying” that doesn’t produce infringing output, delivers visibility (visitors) to the originator of the content material, and preserves recognition and credit score is mostly tolerated. So AI corporations must be working to develop options that content material builders will see as beneficial to them.
The latest protest by long-time StackOverflow contributors who don’t need the corporate to make use of their solutions to coach OpenAI fashions highlights an extra dimension of the issue. These customers contributed their data to StackOverflow, giving the corporate perpetual and unique rights to their solutions. They reserved no financial rights, however they nonetheless consider they’ve ethical rights. That they had, and proceed to have, the expectation that they may obtain recognition for his or her data. It isn’t the coaching per se that they care about, it’s that the output might now not give them the credit score they deserve.
And eventually, the Author’s Guild strike established the contours of who will get to learn from spinoff works created with AI. Are content material creators entitled to be those to revenue from AI-generated derivatives of their work, or can they be made redundant when their work is used to coach their replacements? (Extra particularly, the settlement stipulated that AI works couldn’t be thought of “supply materials.” That’s, studios couldn’t have the AI do a primary draft, then deal with the scriptwriter as somebody merely “adapting” the draft and thus get to pay them much less.) Because the settlement demonstrated, this isn’t a purely financial or authorized query, however one among market energy.
In sum, there are three components to the issue: what content material is ingested as a part of the coaching knowledge within the first place, what outputs are allowed, and who will get to revenue from these outputs. Accordingly, listed below are some tips for a way AI mannequin builders must deal with copyrighted content material:
Practice on copyrighted content material that’s freely accessible, however respect alerts like subscription paywalls, the robots.txt file, the HTML “noindex” key phrase, phrases of service, and different means by which copyright holders sign their intentions. Take the time to differentiate between content material that’s meant to be freely shared and that which is meant to be monetized and for which copyright is meant to be enforced.
There’s some progress in direction of this objective. Partially due to the EU AI act, it’s probably that inside the subsequent twelve months each main AI developer could have carried out mechanisms for copyright holders to choose out in a machine-readable method. Already, OpenAI permits websites to disallow its GPTbot internet crawler utilizing the robots.txt file, and Google does the identical for its Net-extended crawler. There are additionally efforts just like the DoNotTrain database, and instruments like Cloudflare Bot Supervisor. OpenAI’s forthcoming Media Supervisor guarantees to “allow creators and content material house owners to inform us what they personal and specify how they need their works to be included or excluded from machine studying analysis and coaching.” That is useful, however inadequate. Even on right this moment’s web these mechanisms are fragile, complicated, change steadily, and are sometimes not properly understood by websites whose content material is being scraped.
However extra importantly, merely giving content material creators the best to choose out is lacking the actual alternative, which is to assemble datasets for coaching AI that particularly acknowledge copyright standing and the objectives of content material creators, and thus grow to be the underlying mechanism for a brand new AI economic system. As Dodge, the hyper-successful recreation developer who’s the protagonist of Neal Stephenson’s novel Reamde famous, “you needed to get the entire cash stream system found out. As soon as that was accomplished, all the things else would comply with.”
Produce outputs that respect what may be identified concerning the supply and the character of copyright within the materials.
This isn’t dissimilar to the challenges of stopping many different kinds of disputed content material, comparable to hate speech, misinformation, and numerous different kinds of prohibited info. We’ve all been informed many instances that ChatGPT or Claude or Llama3 isn’t allowed to reply a specific query or to make use of specific info that it might in any other case be capable of generate as a result of they violate guidelines towards bias, hate speech, misinformation, or harmful content material. And, the truth is, in its feedback to the copyright workplace, OpenAI describes the way it offers comparable guardrails to maintain ChatGPT from producing copyright-infringing content material. What we have to know is how efficient they’re and the way extensively they’re deployed.
There are already methods for figuring out the content material most carefully associated to some kinds of person queries. For instance, when Google or Bing offers an AI-generated abstract of an internet web page or information article, you sometimes see hyperlinks under the abstract that time to the pages from which the abstract was generated. That is accomplished utilizing a know-how referred to as retrieval augmented era (RAG), which generates a set of search outcomes which are vectorized, offering an authoritative supply to be consulted by the mannequin earlier than it generates a response. The generative LLM is claimed to have grounded its response within the paperwork offered by these vectorized search outcomes. In essence, it’s not regurgitating content material from the pre-trained fashions however fairly reasoning on these supply snippets to work out an articulate response based mostly on them. In brief, the copyrighted content material has been ingested, however it’s detected in the course of the output part as a part of an total content material administration pipeline. Over time, there’ll probably be many extra such methods.
One hotly debated query is whether or not these hyperlinks present the identical degree of visitors because the earlier era of search and social media snippets. Google claims that its AI summaries drive much more visitors than conventional snippets, however it hasn’t offered any knowledge to again up that declare, and could also be based mostly on a really slender interpretation of click-through price, as parsed in a latest Search Engine Land evaluation. My guess is that there shall be some winners and a few losers as with previous search engine algorithm updates, to not point out additional updates, and that it’s too early for websites to panic or to sue.
However what’s lacking is a extra generalized infrastructure for detecting content material possession and offering compensation in a basic function method. This is among the nice enterprise alternatives of the subsequent few years, awaiting the form of breakthrough that pay-per-click search promoting delivered to the World Huge Net.
Within the case of books, for instance, fairly than coaching on identified sources of pirated content material, how about constructing a e book knowledge commons, with a further effort to protect details about the copyright standing of the works it incorporates? This commons might be used as the premise not just for AI coaching however for measuring the vector similarity to present works. Already, AI mannequin builders use filtered variations of the Widespread Crawl Database, which offers a big share of the coaching knowledge for many LLMs, to scale back hate speech and bias. Why not do the identical for copyright?
Pay for the output, not the coaching. It could appear to be a giant win for present copyright holders once they obtain multi-million greenback licensing charges for the usage of content material they management. First, solely essentially the most deep-pocketed AI corporations will be capable of afford pre-emptive funds for essentially the most beneficial content material, which can deepen their aggressive moat with regard to smaller builders and open supply fashions. Second, these charges are probably inadequate to grow to be the muse of sustainable long run companies and artistic ecosystems. When you’ve licensed the hen, the licensee will get the eggs. (Hamilton Nolan calls it “Promoting your home for firewood.”) Third, the cost is commonly going to intermediaries, and isn’t handed on to the precise creators.
How “cost” works may rely very a lot on the character of the output and the enterprise mannequin of the unique copyright holder. If the copyright house owners want to monetize their very own content material, don’t present the precise outputs. As an alternative, present tips that could the supply. For content material from websites that rely on visitors, this implies both sending visitors, or if not, a cost negotiated with the copyright proprietor that makes up for the proprietor’s decreased means to monetize its personal content material. Search for win-win incentives that may result in the event of an ongoing, cooperative content material ecosystem.
In some ways, YouTube’s Content material ID system offers an intriguing precedent for a way this course of may be automated. Based on YouTube’s description of the system,
“Utilizing a database of audio and visible information submitted by copyright house owners, Content material ID identifies matches of copyright-protected content material. When a video is uploaded to YouTube, it’s robotically scanned by Content material ID. If Content material ID finds a match, the matching video will get a Content material ID declare. Relying on the copyright proprietor’s Content material ID settings, a Content material ID declare ends in one of many following actions:
Blocks a video from being considered
Monetizes the video by working adverts towards it and generally sharing income with the uploader
Tracks the video’s viewership statistics”
(Income is simply generally shared with the uploader as a result of the uploader might not personal the entire monetizable parts of the uploaded content material. For instance, a dance or music efficiency video might use copyrighted music for which cost goes to the copyright holder fairly than the uploader.)
One can think about this type of copyright enforcement framework being operated by the platforms themselves, a lot as YouTube operates Content material ID, or by third social gathering companies. The issue is clearly tougher than the one dealing with YouTube, which solely needed to uncover matching music and movies in a comparatively mounted format, however the instruments are extra subtle right this moment. As RAG demonstrates, vector databases make it doable to seek out weighted similarities even in wildly totally different outputs.
In fact, there’s a lot that may should be labored out. Utilizing vector similarity for attribution is promising however there are regarding limitations. Take into account Taylor Swift. She is so well-liked that there are numerous artists making an attempt to sound like her. This units up a form of adversarial state of affairs that has no apparent answer. Think about a vector database that has Taylor in it together with a thousand Taylor copycats. Now think about an AI generated music that “seems like Taylor.” Who will get the income? Is it the highest 100 nearest vectors (99 of that are low cost copycats of Taylor)? or ought to Taylor herself get many of the income? There are attention-grabbing questions in the right way to weigh similarity—simply as there are attention-grabbing questions in conventional search about the right way to weigh numerous elements to provide you with the “finest” consequence for a search question. Fixing these questions is the revolutionary (and aggressive) frontier.
One possibility may be to retrieve the uncooked supplies for era (vs. utilizing RAG for attribution). Wish to generate a paragraph that seems like Stephen King? Explicitly retrieve some illustration of Stephen King, generate from it, after which pay Stephen King. In the event you don’t wish to pay for Stephen King’s degree of high quality, tremendous. Your textual content shall be generated from decrease high quality bulk-licensed “horror thriller textual content” as your driver. There are some fairly naive assumptions on this splendid, specifically in the right way to scale it to hundreds of thousands or billions of content material suppliers, however that’s what makes it an attention-grabbing entrepreneurial alternative. For a star-driven media space like music, it undoubtedly is sensible.
My level is that one of many frontiers of innovation in AI must be in methods and enterprise fashions to allow the form of flourishing ecosystem of content material creation that has characterised the net and the net distribution of music and video. AI corporations that determine this out will create a virtuous flywheel that rewards content material creation fairly than turning the trade into an extractive useless finish.
An Structure of Participation for AI
One factor that makes copyright appear intractable is the race for monopoly by the big AI suppliers. The structure that a lot of them appear to think about for AI is a few model of “one ring to rule all of them,” “all of your base are belong to us,” or the Borg. This structure isn’t dissimilar to the mannequin of early on-line info suppliers like AOL and the Microsoft Community. They have been centralized and aimed to host everybody’s content material as a part of their service. It was solely a query of who would win essentially the most customers and host essentially the most content material.
The World Huge Net (and the underlying web itself) had a basically totally different concept, which I’ve referred to as an “structure of participation.” Anybody may host their very own content material and customers may surf from one web site to a different. Each web site and each browser may talk and agree on what may be seen freely, what’s restricted, and what have to be paid for. It led to a exceptional enlargement of the alternatives for the monetization of creativity, publishing, and copyright.
Just like the networked protocols of the web, the design of Unix and Linux programming envisioned a world of cooperating packages developed independently and assembled right into a higher complete. The Unix/Linux file system has a easy however highly effective set of entry permissions with three ranges: person, group, and world. That’s, some information are personal solely to the creator of the file, others to a delegated group, and others are readable by anybody.
Think about with me, for a second, a world of AI that works very similar to the World Huge Net or open supply methods comparable to Linux. Basis fashions perceive human prompts and may generate all kinds of content material. However they function inside a content material framework that has been skilled to acknowledge copyrighted materials and to know what they will and may’t do with it. There are centralized fashions which were skilled on all the things that’s freely readable (world permission), others which are grounded in content material belonging to a selected group (which may be an organization or different group, a social, nationwide or language group, or some other cooperative aggregation), and others which are grounded within the distinctive corpus of content material belonging to a person.
It could be doable to construct such a world on prime of ChatGPT or Claude or any one of many massive centralized fashions, however it’s much more prone to emerge from cooperating AI companies constructed with smaller, distributed fashions, a lot as the net was constructed by cooperating internet servers fairly than on prime of AOL or the Microsoft Community. We’re informed that open supply AI fashions are riskier than massive centralized ones, but it surely’s necessary to make a transparent eyed evaluation of their advantages versus their dangers. Open supply higher allows not solely innovation however management. What if there was an open protocol for content material house owners to open up their repositories to AI Search suppliers however with management and forensics over how that content material is dealt with and particularly monetized?
Many creators of copyrighted content material shall be joyful to have their content material ingested by centralized, proprietary fashions and used freely by them, as a result of they obtain many advantages in return. That is very similar to the best way right this moment’s web customers are joyful to let centralized suppliers acquire their knowledge, so long as it’s used for them and never towards them. Some creators shall be joyful to have the centralized fashions use their content material so long as they monetize it for them. Different creators will wish to monetize it themselves. However it is going to be a lot more durable for anybody to make this selection freely if the centralized AI suppliers are capable of ingest all the things and to output doubtlessly infringing or competing content material with out compensation, or compensation that quantities to pennies on the greenback.
Are you able to think about a world the place a query to an AI chatbot may generally result in a direct reply, generally to the equal of “I’m sorry, Dave, I’m afraid I can’t do this” (a lot as you now get informed while you attempt to generate prohibited speech or photographs, however on this case, resulting from copyright restrictions), and at others, “I can’t do this for you, Dave, however the New York Occasions chatbot can.” At different instances, by settlement between the events, a solution based mostly on copyrighted knowledge may be given straight within the service, however the rights holder shall be compensated.
That is the character of the system that we’re constructing for our personal AI companies at oreilly.com. Our on-line know-how studying platform is a market for content material offered by a whole lot of publishers and tens of 1000’s of authors, trainers, and different consultants. A portion of person subscription charges is allotted to pay for content material, and copyright holders are compensated based mostly on utilization (or in some circumstances, based mostly on a set payment).
We’re more and more utilizing AI to assist our authors and editors generate content material comparable to summaries, translations and transcriptions, take a look at questions, and assessments as a part of a workflow that entails editorial and subject material skilled evaluate, a lot as after we edit and develop the underlying books and movies. We’re additionally constructing dynamically generated user-facing AI content material that additionally retains monitor of provenance and shares income with our authors and publishing companions.
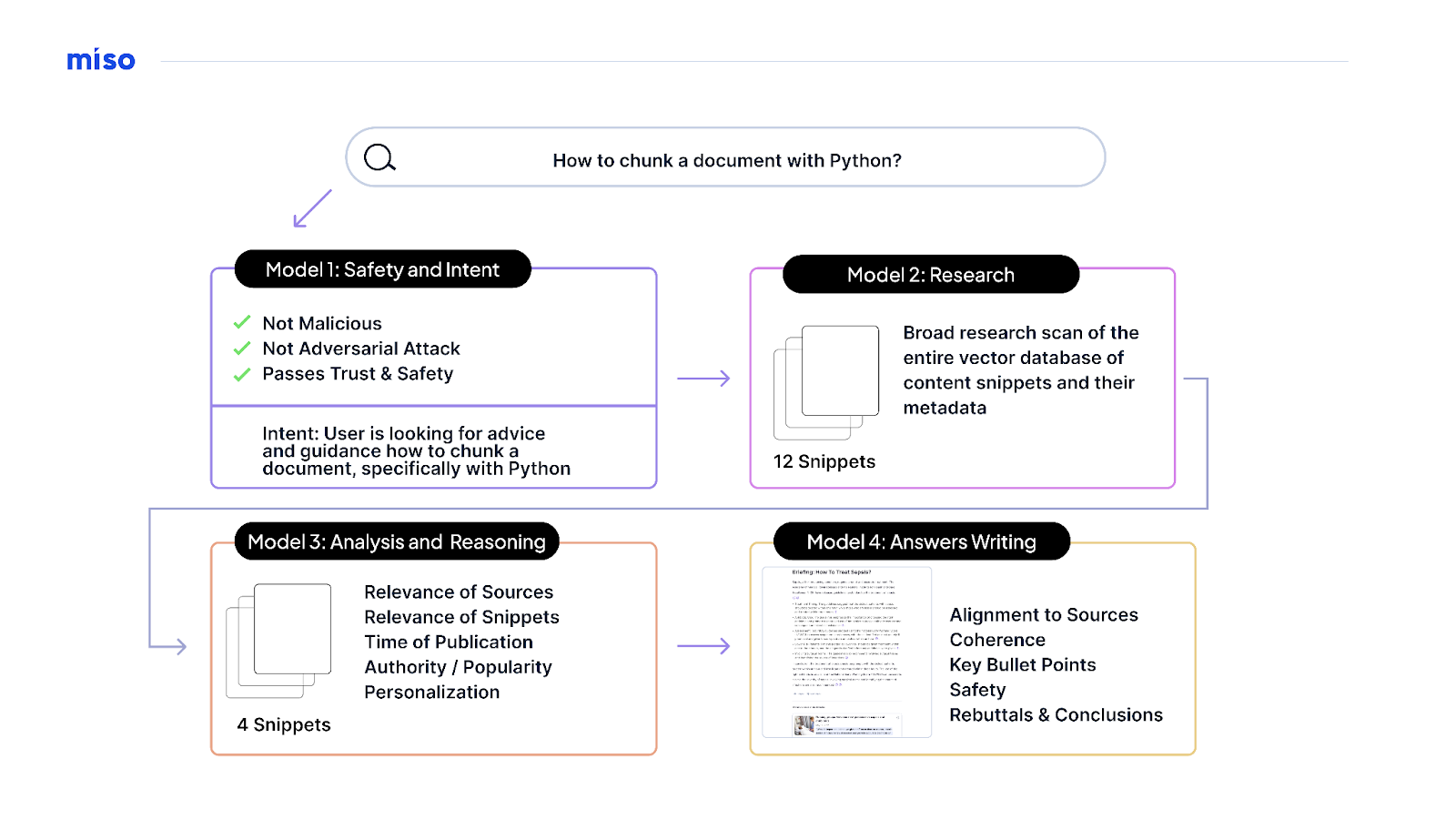
For instance, for our “Solutions” function (in-built partnership with Miso Applied sciences), we’ve used a RAG structure to construct a analysis, reasoning, and response mannequin that searches throughout content material for essentially the most related outcomes (much like conventional search) after which generates a response tailor-made to the person interplay based mostly on these particular outcomes.
As a result of we all know what content material was used to supply the generated reply, we’re not solely capable of present hyperlinks to the sources used to generate the reply, however to pay authors in proportion to the function of their content material in producing it. As Fortunate Gunasekara, Andy Hsieh, Lan Li, and Julie Baron write in “The R in ‘RAG’ Stands for ‘Royalties’”:
“In essence, the most recent O’Reilly Solutions launch is an meeting line of LLM employees. Every has its personal discrete experience and ability set, they usually work collectively to collaborate as they absorb a query or question, purpose what the intent is, analysis the doable solutions, and critically consider and analyze this analysis earlier than writing a citation-backed grounded reply…. The web result’s that O’Reilly Solutions can now critically analysis and reply questions in a a lot richer and extra immersive long-form response whereas preserving the citations and supply references that have been so necessary in its unique launch….
The most recent Solutions launch is once more constructed with an open supply mannequin—on this case, Llama 3…. The advantage of establishing Solutions as a pipeline of analysis, reasoning, and writing utilizing right this moment’s main open supply LLMs is that the robustness of the questions it could possibly reply will proceed to extend, however the system itself will at all times be grounded in authoritative unique skilled commentary from content material on the O’Reilly studying platform.”
When somebody reads a e book, watches a video, or attends a stay coaching, the copyright holder will get paid. Why ought to spinoff content material generated with the help of AI be any totally different? Accordingly, we’ve got constructed instruments to combine AI generated merchandise straight into our cost system. This strategy allows us to correctly attribute utilization, citations, and income to content material and ensures our continued recognition of the worth of our authors’ and lecturers’ work.
And if we are able to do it, we all know that others can too.
Im Falle einer Datenverschlüsselung durch Ransomware müssen „Incident Responder“ und Process-Forces schnell und effizient vorgehen, um möglichst alle Daten beispielsweise von einer verschlüsselten virtuellen Maschine zu extrahieren. Wie wichtig das Fachwissen und die richtige Vorgehensweise sind, unterstreicht einmal mehr der aktuelle Sophos-Report State of Ransomware 2024: 58 Prozent der deutschen Unternehmen waren im letzten Jahr von Ransomware betroffen und 79 Prozent der Angriffe führten dazu, dass Daten verschlüsselt wurden.
Incident Responder sollten daher über verschiedene Techniken und Instruments verfügen, um die Daten aus einer verschlüsselten virtuellen Festplatte extrahieren zu können. Die Knowledgeable:innen von Sophos empfehlen sechs potenziell erfolgversprechende Instruments zur Wiederherstellung von Daten, die mit Standardmethoden nicht wiederhergestellt werden können. Zwar ist ein Erfolg nicht garantiert, es gibt jedoch eine Vielzahl an positiven Erfahrungen beim Einsatz dieser Methoden, beispielsweise im Zusammenhang mit LockBit, Faust Phobos, Rhysida oder Akira.
Bitte keine Rettungsversuche mit Originaldaten Damit eine prekäre Scenario nicht zur Katastrophe wird, gilt grundsätzlich und unabhängig von den Extraktionsmethoden, alle Wiederherstellungsversuche mit Arbeitskopien und nicht mit den Originalen durchzuführen. Nur so ist garantiert, dass eine fehlgeschlagene Rettungsmethode, welche die Daten und VM-Systeme vielleicht zusätzlich geschädigt hat, Versuche mit anderen erfolgversprechenden Instruments unmöglich macht.
6 bewährte Methoden und Instruments Es gibt eine Vielzahl an Methoden, die bei der Extraktion von Daten aus einer verschlüsselten Home windows-VM eingesetzt werden können. Einige dieser Techniken sind sogar für Wiederherstellungsversuche unter Linux anwendbar. Sechs dieser Methoden haben sich besonders bewährt:
Methode 1: Einfaches „mounten“ des Laufwerks Diese Methode klingt einfach, funktioniert vielfach und spart ungeheuer viel Zeit. Wenn es nicht klappt, sind nur wenige Minuten verloren. Wenn die Methode jedoch erfolgreich ist und das Laufwerk gemountet, additionally fester Bestandteil des Betriebssystems geworden ist, kann auf die Datei(en) zugegriffen werden. Da lediglich die VM gemounted wird, sollte der Endpoint-Schutz keine bösartigen Dateien erkennen oder entfernen, um weitere forensische Erkenntnisse daraus zu gewinnen.
Methode 2: RecuperaBit RecuperaBit ist ein automatisiertes Software, das alle NTFS-Partitionen wiederherstellen kann, die in der verschlüsselten VM gefunden werden. Wenn es eine NTFS-Partition findet, erstellt es die Ordnerstruktur dieser Partition neu. Bei einem Erfolg können die Knowledgeable:innen dann auf die Datei(en) zugreifen und sie wie gewünscht aus der neu erstellten Verzeichnis-/ Ordnerstruktur kopieren und einfügen. RecuperaBit wird wahrscheinlich den Endpunktschutz nicht auslösen, sofern ransom.exe oder andere bösartige Dateien vorhanden sind. Daher sollte RecuperaBit beispielsweise in einer Sandbox ausgeführt werden.
Methode 3: bulk_extractor Der automatisierte bulk_extractor ist ein Software für Home windows- oder Linux-Umgebungen. Es kann sowohl Systemdateien wie Home windows-Ereignisprotokolle (.EVTX) als auch Mediendateien wiederherstellen. Wie bei RecuperaBit wird bulk_extractor wahrscheinlich Erkennungen des Endpunktschutzes deaktivieren, wenn ransom.exe oder andere bösartige Dateien vorhanden sind. Daher sollte der Extraktions-Versuch mit bulk_extractor ebenfalls in einer Sandbox durchgeführt werden.
Methode 4: EVTXtract Dieses automatisierte Linux-Software durchsucht einen Datenblock beziehungsweise eine verschlüsselte VM nach vollständigen oder teilweisen .evtx-Protokolldateien. Wenn es solche findet, werden diese in ihre ursprüngliche Struktur, das heißt XML, zurückverwandelt. XML-Dateien sind bekanntermaßen schwierig zu bearbeiten. In diesem Fall besteht die Datei aus fehlerhaft eingebetteten EVTX-Fragmenten, so dass die Ausgabe etwas unhandlich sein kann.
Methode 5: Scalpel, Foremost und weitere Instruments zur Dateiwiederherstellung Zu den Instruments, die für die Wiederherstellung anderer Dateitypen entwickelt wurden, gehören Scalpel und Foremost. Obwohl es sich bei beiden um ältere Technologien handelt, hat das Sophos IR-Crew bei seinen Untersuchungen gute Ergebnisse mit diesen beiden Instruments erzielt. Beide stellen hauptsächlich Medien- und Dokumentdateien wieder her und bei beiden kann die Konfiguration geändert werden, um sich auf bestimmte Dateitypen zu konzentrieren.
Methode 6: Manuelles Zerlegen der NTFS-Partition Im Gegensatz zu den beschriebenen Instruments und Techniken erfordert das manuelle Carving eine gründliche Vorbereitung und ein genaueres Verständnis der verfügbaren Optionen. Für das korrekte manuelle Carving müssen die Ermittler:innen drei Switches auf dd setzen – bs (Bytes professional Sektor), skip (der Offset-Wert des NTFS-Sektors, den Sie neu erstellen wollen) und depend – bevor das Dienstprogramm ausgeführt wird. Schlussendlich wird die neue, ge-carvte Datei gemounted, um das wiederherzustellen, was benötigt wird.
Schlussfolgerung Verschlüsselte Daten oder VMs sind eine große Bedrohung für Unternehmen und deren Enterprise. Daher ist es wichtig, die Handlungsfähigkeit des Unternehmens so schnell und umfassend wie möglich wiederherzustellen, wobei die vorgestellten Techniken helfen können.
Der beste Weg zur Wiederherstellung von verschlüsselten Daten besteht allerdings darin, eine Kopie von einem sauberen, nicht betroffenen Backup zur Verfügung zu haben. Und noch wichtiger ist es, durch Prävention mit wirkungsvoller Safety einen solchen Fall möglichst zu verhindern.
For those who’re somebody who works with knowledge, I’m certain you usually use Structured Question Language (SQL). Be it in knowledge science, database administration, or backend improvement, SQL is a vital software that everybody wants. Though most of us are conversant in the language, there’s usually some confusion about what it truly is. Is it a scripting language? Is it a programming language? Or is it each? Effectively, if these questions have ever popped up in your thoughts and stored you questioning, now’s the time to search out out the solutions! On this article, we’re going to interrupt down what SQL is all about. We’ll take a look at what makes a language a programming language versus a scripting language, and eventually determine the place SQL matches in.
Targets
Perceive what programming languages and scripting languages are.
Perceive what SQL is.
Study the advantages of utilizing it, and extra importantly, the place to make use of it and the place to not.
Decode if SQL is a programming language or a scripting language.
What’s a Programming Language?
A programming language is a proper language made up of a set of directions meant to supply totally different sorts of output. These languages are used to implement algorithms, management gadgets, and create functions that may run independently.
What Can Programming Languages Do?
Carry out advanced computations: Involving arithmetic, logical, and management buildings.
Manipulate knowledge buildings: Together with arrays, lists, and objects.
Allow management circulate: Supporting constructs like loops, conditionals, and capabilities.
Create standalone functions: Growing software program that may function independently of different functions.
Widespread programming languages: Python, Java, C++, and JavaScript.
What’s a Scripting Language?
A scripting language is a kind of programming language designed to speak with different programming languages. Scripts are sometimes used to automate mundane, time-consuming, and repetitive duties which might be in any other case performed manually. Scripting languages are often interpreted relatively than compiled. Since they combine with different languages, scripting languages are sometimes embedded inside different functions.
Traits of Scripting Languages
Ease of use: Simplified syntax and semantics for speedy improvement.
Activity automation: Automating repetitive duties like file manipulation, system administration, and internet web page technology.
Integration with different software program: Typically used to script the habits of different software program functions.
Interactivity: Executing one command at a time and sometimes used for brief duties.
Widespread scripting languages: Python, Perl, Ruby, and Bash.
What’s SQL?
SQL stands for Structured Question Language. It’s a domain-specific language used for managing and manipulating relational databases. Utilizing SQL, you possibly can carry out numerous operations like querying knowledge, updating information, creating tables, and setting permissions. The most effective use of SQL is for knowledge retrieval, insertion, updating, deletion, and related duties.
In contrast to general-purpose programming languages, SQL is primarily declarative. Which means that it focuses on what must be performed relatively than find out how to do it. For instance, if you put in an SQL question to search out all information the place the age is bigger than 30, it doesn’t inform the database engine find out how to discover these information.
Is SQL a Programming Language or a Scripting Language?
Now let’s delve into the primary a part of this text!
Is SQL a Programming Language?
Programming languages are principally basic objective, in contrast to SQL, which is domain-specific in nature. It’s designed for a really particular area: interacting with relational databases. You should utilize SQL to carry out different duties similar to advanced queries and transactions as effectively. Nonetheless, it doesn’t have the complete set of options that programming languages do. It lacks in depth management circulate constructs, advanced knowledge buildings, and the flexibility to create standalone functions.
That being stated, SQL does have extensions like PL/SQL (Procedural Language/SQL) for Oracle and T-SQL (Transact-SQL) for Microsoft SQL Server. These give the language, procedural programming capabilities. These extensions let it create capabilities, procedures, and triggers, including a layer of programming-like performance inside the database context.
Is SQL a Scripting Language?
Most programming and scripting languages are crucial, that means they’ve specified step-by-step directions as to find out how to do a sure process. SQL, nonetheless, is a declarative language. It solely specifies what outcomes to get and never find out how to get them. This makes SQL basically totally different in its strategy.
Talking of scripting, SQL can be utilized inside scripts to automate database duties. For instance, a Python script may execute a sequence of SQL queries to generate a report or replace information. Though which means SQL capabilities may be part of a scripting resolution, it doesn’t make SQL a scripting language by itself.
The Verdict
So, is SQL a programming language or a scripting language? The reply is each or neither on the similar time! SQL is finest described as a declarative question language specialised for database interactions. It has options of each programming and scripting languages however doesn’t totally match into both class. As a substitute, it stands aside as an necessary auxiliary software in knowledge administration and manipulation.
Advantages of Utilizing SQL
Simplicity: SQL is a straightforward and easy program. It’s fairly simple to study and use, particularly you probably have a background in knowledge administration.
Effectivity: SQL is environment friendly in querying and manipulating knowledge in massive datasets. This makes it a vital software for database administration.
Standardization: Organizations like ANSI and ISO have licensed and standardized SQL. Therefore, this system stays constant throughout totally different database programs.
Integration: SQL is a flexible program that integrates effectively with numerous programming languages and instruments.
When to Use SQL
Database Administration: SQL is right for managing and manipulating relational databases.
Information Evaluation: It’s nice for querying and analyzing massive datasets.
Automation: SQL scripts can automate repetitive database duties.
Reporting: SQL is beneficial for producing studies from databases.
When To not Use SQL
Basic-Objective Programming: For duties exterior database administration, use a general-purpose programming language.
Advanced Procedural Logic: SQL lacks superior management circulate options; think about a language with procedural capabilities.
Non-Relational Information: For non-relational databases, use languages or instruments designed for these programs.
Conclusion
SQL stands out amongst pc languages as a devoted language for database queries. Whereas it shares some traits with programming and scripting languages, it doesn’t totally belong to both class. Therefore, it’s basically tagged as a declarative question language designed for managing relational databases. Its specialised nature and highly effective capabilities make it a must-know software for knowledge professionals. It’s thus necessary so that you can understand how and when to make use of SQL, and the place to not. To study extra concerning the makes use of of SQL in knowledge science, do learn this text on our weblog.
Often Requested Questions
Q1. Can SQL be used for programming?
A. SQL has procedural extensions like PL/SQL for Oracle and T-SQL Microsoft SQL Server, that give it some programming-like capabilities. Nonetheless, it’s primarily used for querying and managing databases relatively than general-purpose programming.
Q2. Is studying SQL troublesome?
A. SQL is taken into account comparatively simple to study, particularly for these conversant in databases. Its syntax is easy and extremely readable in comparison with many different languages. Right here’s a learners information on SQL to get you began.
Q3. What are the primary makes use of of SQL?
A. SQL is used for querying databases, updating information, creating and modifying database buildings, and managing database permissions. It’s therefore important for knowledge retrieval, manipulation, and administration.
This fall. Can SQL be used with different programming languages?
A. Sure, SQL is usually used with different programming languages. For instance, a Python script can execute SQL queries to work together with a database, combining the strengths of each languages.
Terraform VMware Cloud Director Supplier v3.12.0 is obtainable, introducing many new options and enhancements.
Introducing the Container Service Extension (CSE) Kubernetes Cluster useful resource and information supply
In the course of the previous releases of the supplier, we gathered an excellent quantity of suggestions from the group, and we understood that utilizing Runtime Outlined Entities to create, replace and handle a Kubernetes cluster was generally difficult and never trivial, because it required a deep understanding of the CSE inside workings.
Readers will observe that the obtainable arguments of this useful resource are pretty much like the choices obtainable in UI when making a Kubernetes cluster with the wizard. All of the RDE schemas, RDE Sorts, and YAML information aren’t used explicitly anymore.
Likewise, customers will expertise a extra snug mechanism to replace their clusters, as they received´t want to control JSON information both. The useful resource helps all of the updateable parts which are additionally achievable utilizing the UI: Resize the management aircraft, the employee swimming pools, allow/disable the node well being examine, and switch off the “auto-repair” flag (4.1.0 solely).
This new useful resource is obtainable for CSE variations 4.2.1, 4.2.0, 4.1.1(a) and 4.1.0. It additionally helps importing current clusters, for those that had been utilizing the generic strategy emigrate their current ones, and customers may also learn current clusters with the information supply.
Including assist for Container Service Extension (CSE) 4.2.0 and 4.2.1
This model of the supplier updates the set up information to assist the latest variations of CSE, 4.2.0 and 4.2.1.
As talked about within the earlier part, the Kubernetes Cluster administration information is now deprecated in favor of the brand new vcd_cse_kubernetes_cluster useful resource and information supply.
The supplier repository incorporates now all of the RDE Kind schemas required for CSE 4.2.x and a few instance configurations for each 4.2.0 and 4.2.1 (as they differ in configuration values akin to CAPVCD model, CPI model and CSI model).
Different notable modifications and enhancements
Consolidating VM disks on creation to assist overriding template disks
A frequent person requested lacking performance was overriding disk sizes in quick provisioned VDCs. Terraform supplier v3.12.0 provides new area consolidate_disks_on_create in each assets vcd_vapp_vm and vcd_vm. When enabled, it can consolidate disks throughout VM creation. It might be helpful by itself, nevertheless it additionally permits overriding template disks when creating VMs in quick provisioned VDCs.
# Quick provisioned VDCs require disks to be consolidated
# if their measurement is to be modified
consolidate_disks_on_create=true
override_template_disk{
bus_type=“paravirtual”
size_in_mb=“22384”
bus_number=0
unit_number=0
iops=0
storage_profile=“*”
}
}
VM Copy assist
Each VM assets vcd_vapp_vm and vcd_vm get new area copy_from_vm_id that can be utilized to create a VM from already current one as a substitute of counting on catalog template or an empty VM.
information“vcd_vapp_vm”“current”{
vapp_name=information.vcd_vapp.internet.title
title=“web1”
}
useful resource“vcd_vapp_vm”“vm-copy”{
org=“org”
vdc=“vdc”
copy_from_vm_id=information.vcd_vapp_vm.current.id# supply VM ID
Creating vApp templates from vApps or standalone VMs
The final bit that ranges up VM management is that useful resource vcd_catalog_vapp_template introduces an choice to seize vApp templates from current vApps or standalone VMs. One can use a brand new capture_vapp block that accepts supply vApp ID. Moreover, the vcd_vapp_vm and vcd_vm assets and information sources expose vapp_id attributes that may be specified as a supply in capture_vapp.source_id. That is particularly helpful for standalone VMs which have hidden vApps.
# Utilizing dependency to make sure that all VMs are current in vApp that
# is being captured
depends_on=[vcd_vapp_vm.emptyVM]
}
Route commercial configuration for routed Org VDC networks
Route commercial toggle area route_advertisement_enabled in useful resource vcd_network_routed_v2 that enables customers to allow route commercial per routed community, which works along with IP House route commercial
Listing of recent assets and information sources
1 new useful resource:
2 new information sources:
There are extra options and enhancements, which you’ll be able to see within the mission’s changelog. And, as all the time, we’re awaiting your suggestions and ideas in GitHub Points and #vcd-terraform-dev Slack channel (vmwarecode.slack.com).
Developer.com content material and product suggestions are editorially unbiased. We might become profitable whenever you click on on hyperlinks to our companions. Study Extra.
The Joint Software Improvement methodology is a software program improvement method that goals to convey stakeholders, builders, and customers collectively in joint periods. These joint periods are workshops the place venture necessities and design are outlined. We check out the JAD methodology in nice element, exploring its benefits and drawbacks, greatest practices, and the function it performs in software program creation.
Soar to:
What’s Joint Software Design (JAD)?
JAD (an acronym for Joint Software Design) is a methodology utilized in software program improvement to assemble and outline software program necessities quickly. Its objective is to convey all stakeholders within the design course of to a typical consensus so far as the necessities for the venture is worried and to foster efficient and environment friendly communication between all these concerned.
JAD was created by IBM within the late Nineteen Seventies as a way for faster improvement timeframes and higher shopper satisfaction when in comparison with extra conventional practices, comparable to Waterfall. A major tenant of this method is involving the shopper from the start of the software program improvement life cycle (SDLC) and maintaining them engaged till product launch.
The JAD methodology is simplest when used for well-defined issues the place all stakeholders can take part, and when there’s a expert and skilled facilitator to information the method.
What are the Completely different Phases of JAD?
The JAD methodology sometimes entails the next phases:
Preparation: The venture sponsor, stakeholders, and facilitator are recognized and a JAD session is scheduled. The agenda and goals of the session are outlined, and the contributors are invited and ready.
Session: The JAD session is a structured workshop by which the consultants take part in interactive discussions and decision-making actions to outline the necessities and design for the software program software.
Documentation: The result of the JAD session is documented, together with detailed notes, sketches, and different supplies generated through the session. The documentation is used to create a remaining specification for the software program software.
Implementation: The software program improvement workforce makes use of the specification created through the JAD session to construct the appliance. Common conferences between the stakeholders and builders are held to make sure that the implementation meets their expectations.
Instance of a Flowchart instrument, Miro, which can be utilized to plan a venture in a JAD session.
What’s a JAD Session?
As famous, a JAD session is a structured workshop that brings collectively venture managers, stakeholders, builders, and consultants to outline and refine the necessities for a software program software. Specifically, a JAD session has the next traits:
A JAD session sometimes lasts one to a few days, and is facilitated by a JAD facilitator who’s educated in regards to the software program improvement course of and may handle the session successfully.
JAD periods ought to have a transparent agenda and outlined goals. You need to make sure that the important thing individuals representing the technical and enterprise worlds can be found throughout these conferences.
Questions and agenda gadgets are what get individuals speaking throughout conferences. Due to this fact, we must always not anticipate fast resolutions from them. To make sure the workforce is on the identical web page, ask pertinent questions, make notes, and delegate duties.
JAD periods goal to advertise revolutionary concepts and productive dialogue amongst staff from completely different departments. Workforce members ought to present enter to at least one one other as they work by issues.
Scheduled JAD periods, also called JAD workshops, should be held if the groups can not attain a consensus. Most JAD conferences happen through the venture’s early phases of improvement.
In the course of the session, contributors have interaction in interactive discussions, decision-making actions, and brainstorming workout routines to outline and refine the necessities and design for the software program software.
The result of the JAD session is an in depth doc that might be used to create the ultimate specification for the venture, together with notes, sketches, and different supplies generated through the session.
JAD periods may be efficient in conditions the place there’s a clear, well-defined downside to be solved and the place all stakeholders can take part within the session. The success of a JAD session will depend on the preparation, participation, and facilitation by all concerned events.
In a typical JAD course of, there are a number of key stakeholders concerned, together with:
Mission sponsor: The particular person or group that’s accountable for the venture and who has the authority to make choices and allocate assets.
Facilitator: The JAD facilitator is accountable for guaranteeing that the session runs easily, that each one contributors have an opportunity to contribute, and that the result is documented and used to create a remaining specification for the software program software.
Topic Matter Specialists: Material consultants are people who’ve experience in particular areas associated to the venture, such because the enterprise processes, expertise, or authorized necessities.
Finish-users: Finish-users are the people who will use the system or product being developed. They supply their enter through the JAD periods to make sure that the system meets their wants and is user-friendly.
Builders: The software program improvement workforce who might be accountable for constructing the appliance primarily based on the necessities and design outlined within the JAD session.
Observers: It’s the duty of a JAD observer to watch every JAD session and to assemble data concerning end-user wants, assessing JAD session choices, and interacting with JAD contributors outdoors of the scheduled JAD periods.
Methods to Conduct a JAD Session
Conducting a profitable Joint Software Design session requires cautious preparation, facilitation, and follow-up. To conduct a JAD session, observe these steps:
Establish the venture necessities and decide the scope of the JAD session.
Choose the stakeholders collaborating within the JAD session and invite them to attend.
Verify that each one contributors can be found on the time scheduled for the JAD assembly.
Present all contributors with pre-session supplies, comparable to venture paperwork, necessities paperwork, and different related data.
Assessment the agenda of the session and introduce the facilitator firstly.
Establish and doc the necessities utilizing collaborative strategies, comparable to brainstorming, group discussions, and visible aids.
Guarantee the necessities are correct and full all through the session by constantly reviewing and refining them.
Summarize the session’s outcomes and guarantee all contributors agree on the necessities.
After the session, doc the outcomes and distribute them to all stakeholders for assessment and suggestions.
Advantages of JAD
Under is a listing of some the advantages that JAD software program improvement affords each programmers and venture managers:
Improved Necessities Gathering: JAD periods convey collectively stakeholders, builders, and consultants to outline and refine the necessities for a software program software.
Elevated Collaboration: JAD periods encourage collaboration between stakeholders, builders, and consultants all through the venture life cycle.
Lowered Misunderstandings: JAD periods present a chance to make clear necessities and design choices, which helps to cut back misunderstandings and the necessity for rework.
Accelerated Improvement Cycles: JAD periods are designed to be fast-paced and centered, and may also help to speed up the software program improvement cycle by decreasing the time spent on necessities gathering and design.
Improved Communication: JAD periods present a discussion board for stakeholders, builders, and consultants to speak and trade concepts, which may also help you construct belief and enhance the general high quality of your software.
Higher Documentation: The result of a JAD session is documented intimately, which supplies a whole and correct specification for the software program software.
Regardless of its benefits, JAD additionally has some disadvantages price mentioning, together with:
Useful resource Intensive: JAD periods may be useful resource intensive, each by way of time and personnel, as they require the participation of a number of stakeholders, builders, and consultants. Brief-staffed or time-constrained organizations might discover this difficult.
Restricted Participation: JAD periods are simplest when all stakeholders can take part, however this isn’t all the time doable. If some stakeholders are unable to take part, the result of the JAD session could also be restricted, and there could also be a danger of misunderstandings or errors within the necessities and design.
Dependence on the Facilitator: The success of a JAD session relies upon largely on the standard of the facilitator, and a poor facilitator can undermine the effectiveness of the session.
Potential for Groupthink: JAD periods may be weak to groupthink, the place contributors are extra involved with reaching a consensus than with exploring completely different views and options.
Potential for Battle: JAD periods can even result in battle, significantly when there are completely different opinions and views amongst stakeholders. This could be a problem for the facilitator to handle and may undermine the effectiveness of the session if not dealt with correctly.
Dependence on Face-to-Face Interplay: JAD periods are designed to be face-to-face, however this isn’t all the time doable, significantly in a distant or distributed surroundings. This can be a problem that may restrict the effectiveness of the JAD method.
Greatest Practices for Conducting JAD Periods
With a purpose to get probably the most out of your JAD periods, we suggest following the very best practices under:
Invite Related Folks: JAD periods ideally have 10 or fewer contributors. Of these, you must all the time have a facilitator, key government, end-user consultant, developer, note-taker, and related specialists.
Set Clear Targets: Every session you conduct ought to have clearly outlined objectives and outcomes. Outline what you’ll talk about and any deliverables that might be anticipated.
Conduct Conferences Offsite: To make sure assembly contributors can focus and usually are not pulled away for different duties, conduct conferences outdoors of the office.
Restrict periods: You need to maintain not more than 10 JAD periods or workshops to make sure the venture will get outlined in an inexpensive time interval.
Use Acceptable Instruments: Throughout periods you’ll want to make sure members have entry to the required instruments, which might embody venture administration software program, prototyping instruments, and flowcharts.
Create Deliverables: On the finish of your periods, the facilitator ought to stroll away with a transparent venture definition, system prototypes, user-interface designs, timeframe estimates, funds and useful resource wants, and any database schema this system would require.
Ultimate Approvals: On the finish of your JAD periods you will want to acquire approval from the important thing government, in addition to the end-user consultant.
Instance of a venture administration instrument, Monday, which can be utilized to plan and monitor tasks.
There are lots of instruments that may be helpful for a venture supervisor utilizing a JAD method. Some instruments will foster communication and collaboration, whereas others may be helpful for design paperwork, venture planning, and useful resource allocation. Under are a number of forms of instruments you should use when conducting JAD periods:
Mission Administration: PM instruments assist venture managers plan and monitor venture progress and handle duties.
Communication and Collaboration: Collaboration instruments assist groups work collectively and talk on frequent duties. Builders even have collaboration software program that lets them work on code and share code adjustments in real-time.
Flowchart and Diagramming: Flowchart software program helps groups and programmers design, plan, and structure the construction of an software. This could embody consumer interfaces, workflows, enter/output processes, and any performance this system ought to have.
Essential Path Evaluation: CPA instruments are used to visualise venture timelines and dependencies. They permit venture managers to establish vital duties, allocate assets extra successfully, and scale back venture delays.
SWOT Evaluation: SWOT Evaluation frameworks assist groups establish strengths, weaknesses, alternatives, and threats in a corporation and venture.
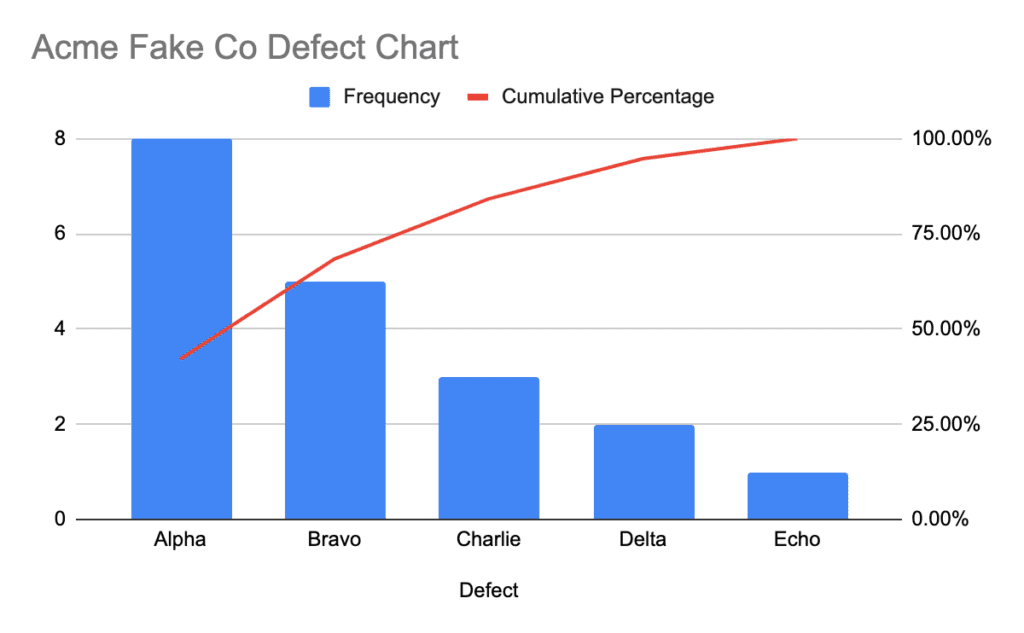
Pareto Charts: Pareto charts assist venture managers establish mission vital points that can have the best influence on the event course of.
Instance of a Pareto chart that ca be used to establish dangers in a venture.
Ultimate Ideas on JAD Software program Improvement
The JAD methodology entails a collaborative effort between enterprise customers, builders, and different stakeholders to brainstorm concepts, make clear assumptions, prioritize wants, develop consensus on proposed options, and consider progress.
With its demonstrated success at eliminating redundant processes whereas capturing important necessities shortly and precisely, the JAD methodology has turn out to be integral to many organizations’ improvement methods.
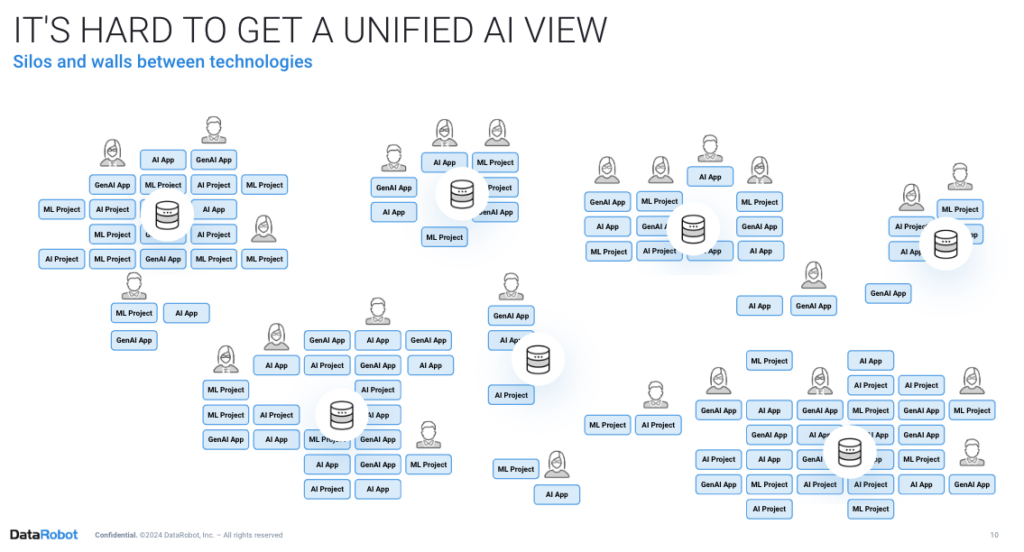
Many organizations begin off with good intentions, constructing promising AI options, however these preliminary functions usually find yourself disconnected and unobservable. As an example, a predictive upkeep system and a GenAI docsbot may function in several areas, resulting in sprawl. AI Observability refers back to the means to observe and perceive the performance of generative and predictive AI machine studying fashions all through their life cycle inside an ecosystem. That is essential in areas like Machine Studying Operations (MLOps) and significantly in Massive Language Mannequin Operations (LLMOps).
AI Observability aligns with DevOps and IT operations, making certain that generative and predictive AI fashions can combine easily and carry out properly. It allows the monitoring of metrics, efficiency points, and outputs generated by AI fashions –offering a complete view via a company’s observability platform. It additionally units groups as much as construct even higher AI options over time by saving and labeling manufacturing information to retrain predictive or fine-tune generative fashions. This steady retraining course of helps preserve and improve the accuracy and effectiveness of AI fashions.
Nonetheless, it isn’t with out challenges. Architectural, consumer, database, and mannequin “sprawl” now overwhelm operations groups because of longer arrange and the necessity to wire a number of infrastructure and modeling items collectively, and much more effort goes into steady upkeep and replace. Dealing with sprawl is unimaginable with out an open, versatile platform that acts as your group’s centralized command and management heart to handle, monitor, and govern the whole AI panorama at scale.
Most corporations don’t simply stick to at least one infrastructure stack and may swap issues up sooner or later. What’s actually essential to them is that AI manufacturing, governance, and monitoring keep constant.
DataRobot is dedicated to cross-environment observability – cloud, hybrid and on-prem. When it comes to AI workflows, this implies you may select the place and learn how to develop and deploy your AI tasks whereas sustaining full insights and management over them – even on the edge. It’s like having a 360-degree view of every little thing.
DataRobot presents 10 most important out-of-the-box elements to realize a profitable AI observability apply:
Metrics Monitoring: Monitoring efficiency metrics in real-time and troubleshooting points.
Mannequin Administration: Utilizing instruments to observe and handle fashions all through their lifecycle.
Visualization: Offering dashboards for insights and evaluation of mannequin efficiency.
Automation: Automating constructing, governance, deployment, monitoring, retraining levels within the AI lifecycle for clean workflows.
Information High quality and Explainability: Guaranteeing information high quality and explaining mannequin selections.
Superior Algorithms: Using out-of-the-box metrics and guards to boost mannequin capabilities.
Person Expertise: Enhancing consumer expertise with each GUI and API flows.
AIOps and Integration: Integrating with AIOps and different options for unified administration.
APIs and Telemetry: Utilizing APIs for seamless integration and gathering telemetry information.
Apply and Workflows: Making a supportive ecosystem round AI observabilityand taking motion on what’s being noticed.
AI Observability In Motion
Each trade implements GenAI Chatbots throughout numerous capabilities for distinct functions. Examples embrace growing effectivity, enhancing service high quality, accelerating response instances, and plenty of extra.
Let’s discover the deployment of a GenAI chatbot inside a company and focus on learn how to obtain AI observability utilizing an AI platform like DataRobot.
Step 1: Accumulate related traces and metrics
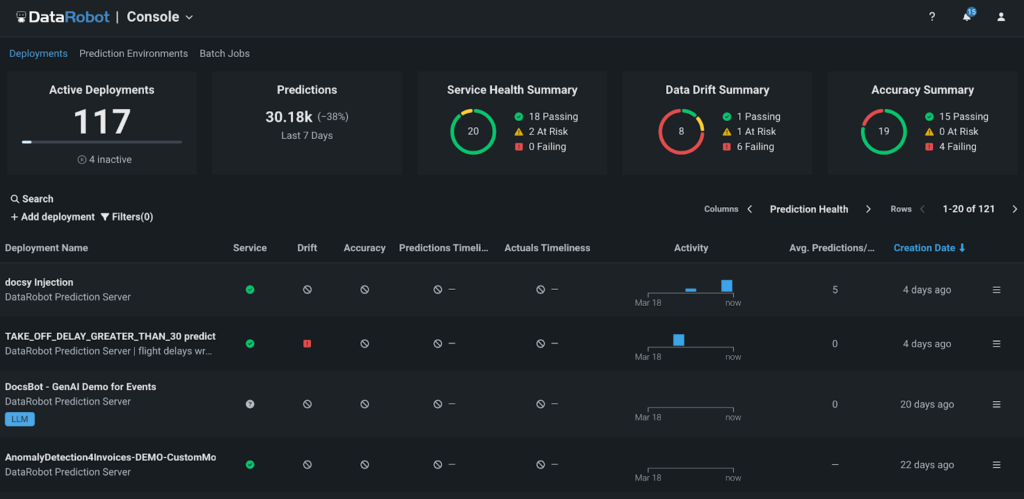
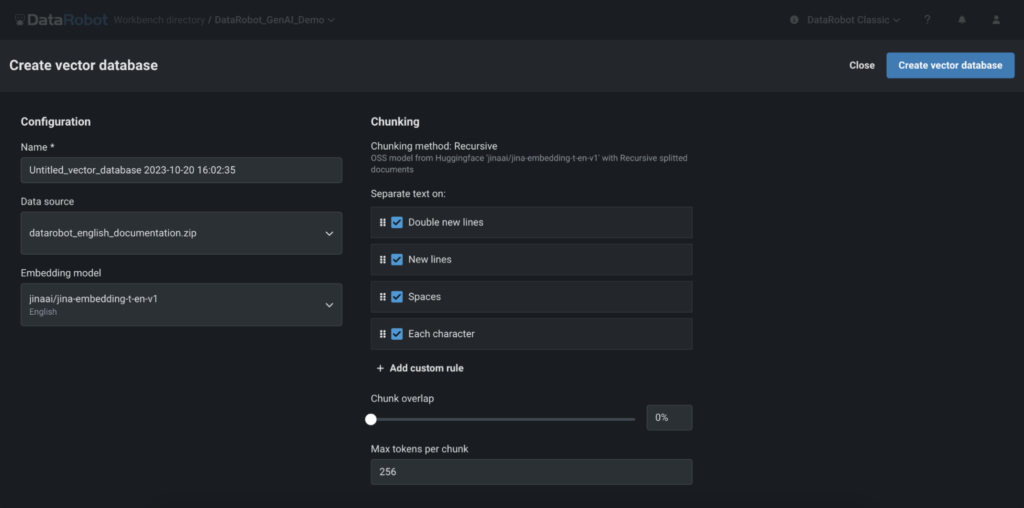
DataRobot and its MLOps capabilities present world-class scalability for mannequin deployment. Fashions throughout the group, no matter the place they have been constructed, might be supervised and managed underneath one single platform. Along with DataRobot fashions, open-source fashions deployed outdoors of DataRobot MLOps will also be managed and monitored by the DataRobot platform.
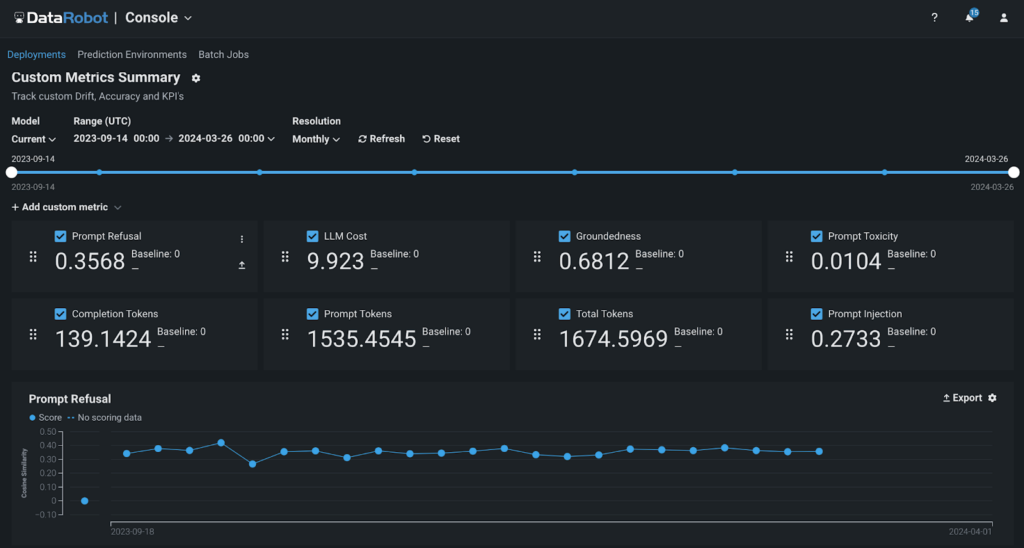
AI observability capabilities throughout the DataRobot AI platform assist be sure that organizations know when one thing goes improper, perceive why it went improper, and may intervene to optimize the efficiency of AI fashions constantly. By monitoring service, drift, prediction information, coaching information, and customized metrics, enterprises can maintain their fashions and predictions related in a fast-changing world.
Step 2: Analyze information
With DataRobot, you may make the most of pre-built dashboards to observe conventional information science metrics or tailor your personal customized metrics to deal with particular points of your corporation.
These customized metrics might be developed both from scratch or utilizing a DataRobot template. Use these metrics for the fashions constructed or hosted in DataRobot or outdoors of it.
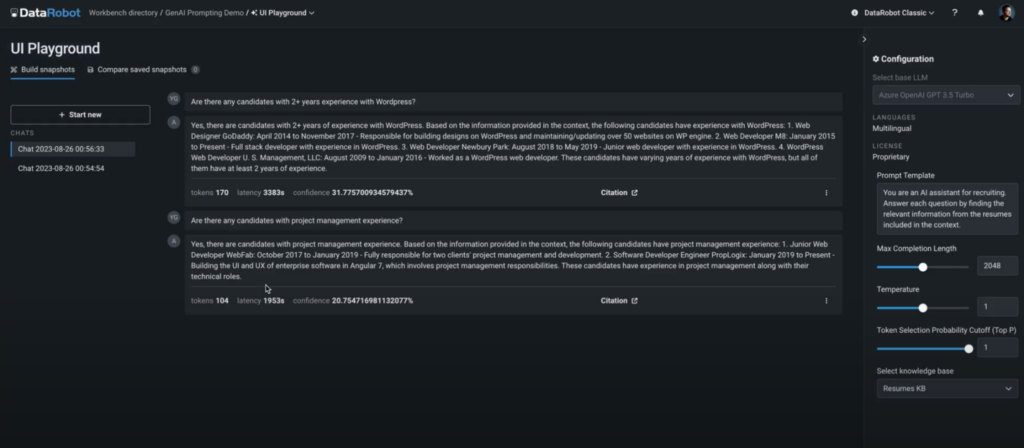
‘Immediate Refusal’ metrics symbolize the share of the chatbot responses the LLM couldn’t tackle. Whereas this metric gives helpful perception, what the enterprise actually wants are actionable steps to reduce it.
Guided questions: Reply these to supply a extra complete understanding of the components contributing to immediate refusals:
Does the LLM have the suitable construction and information to reply the questions?
Is there a sample within the forms of questions, key phrases, or themes that the LLM can not tackle or struggles with?
Are there suggestions mechanisms in place to gather consumer enter on the chatbot’s responses?
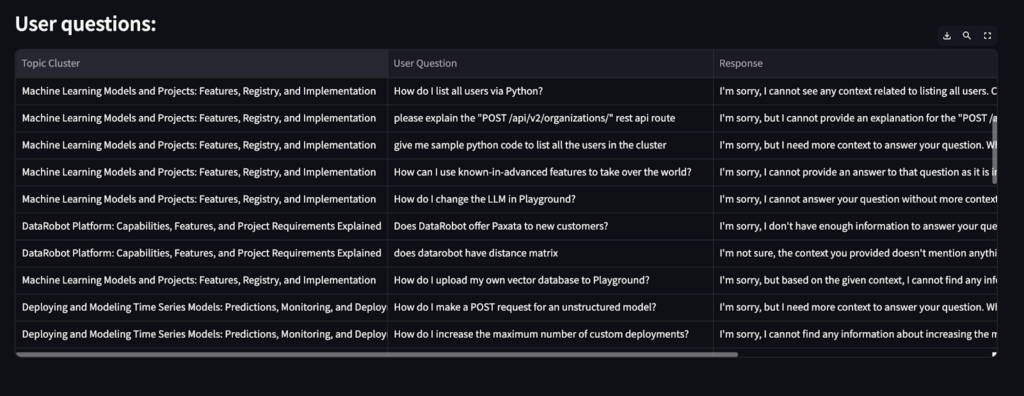
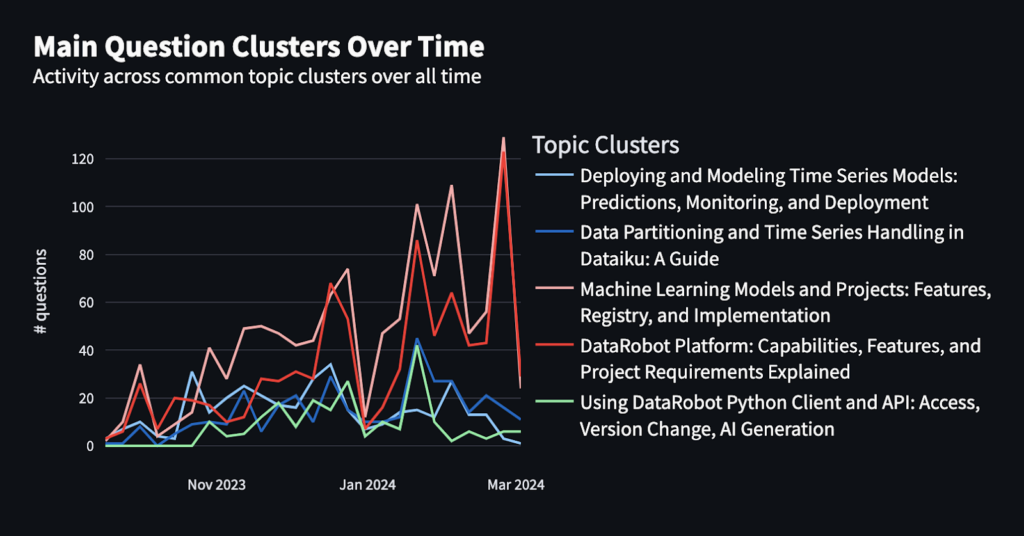
Use-feedback Loop: We will reply these questions by implementing a use-feedback loop and constructing an utility to seek out the “hidden info”.
Beneath is an instance of a Streamlit utility that gives insights right into a pattern of consumer questions and matter clusters for questions the LLM couldn’t reply.
Step 3: Take actions primarily based on evaluation
Now that you’ve got a grasp of the info, you may take the next steps to boost your chatbot’s efficiency considerably:
Modify the immediate: Attempt completely different system prompts to get higher and extra correct outcomes.
Enhance Your Vector database: Determine the questions the LLM didn’t have solutions to, add this info to your information base, after which retrain the LLM.
Nice-tune or Exchange Your LLM: Experiment with completely different configurations to fine-tune your current LLM for optimum efficiency.
Alternatively, consider different LLM methods and evaluate their efficiency to find out if a substitute is required.
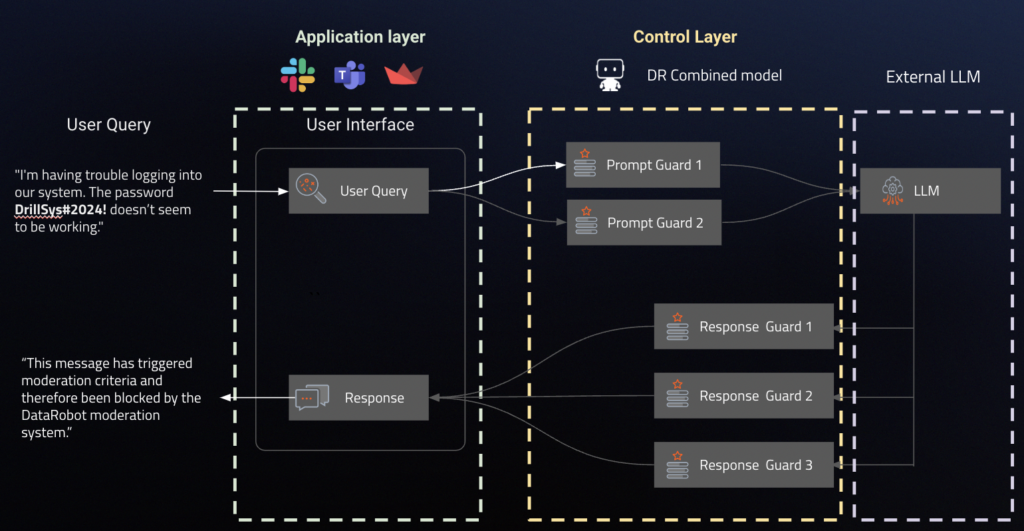
Reasonable in Actual-Time or Set the Proper Guard Fashions: Pair every generative mannequin with a predictive AI guard mannequin that evaluates the standard of the output and filters out inappropriate or irrelevant questions.
This framework has broad applicability throughout use circumstances the place accuracy and truthfulness are paramount. DR gives a management layer that permits you to take the info from exterior functions, guard it with the predictive fashions hosted in or outdoors Datarobot or NeMo guardrails, and name exterior LLM for making predictions.
Following these steps, you may guarantee a 360° view of all of your AI property in manufacturing and that your chatbots stay efficient and dependable.
Abstract
AI observability is important for making certain the efficient and dependable efficiency of AI fashions throughout a company’s ecosystem. By leveraging the DataRobot platform, companies preserve complete oversight and management of their AI workflows, making certain consistency and scalability.
Implementing strong observability practices not solely helps in figuring out and stopping points in real-time but additionally aids in steady optimization and enhancement of AI fashions, finally creating helpful and protected functions.
By using the fitting instruments and techniques, organizations can navigate the complexities of AI operations and harness the total potential of their AI infrastructure investments.
DataRobot AI Platform
Get Began with Free Trial
Expertise new options and capabilities beforehand solely obtainable in our full AI Platform product.
Concerning the writer
Atalia Horenshtien
AI/ML Lead – Americas Channels, DataRobot
Atalia Horenshtien is a World Technical Product Advocacy Lead at DataRobot. She performs an important position because the lead developer of the DataRobot technical market story and works carefully with product, advertising and marketing, and gross sales. As a former Buyer Going through Information Scientist at DataRobot, Atalia labored with clients in several industries as a trusted advisor on AI, solved advanced information science issues, and helped them unlock enterprise worth throughout the group.
Whether or not chatting with clients and companions or presenting at trade occasions, she helps with advocating the DataRobot story and learn how to undertake AI/ML throughout the group utilizing the DataRobot platform. A few of her talking periods on completely different subjects like MLOps, Time Collection Forecasting, Sports activities tasks, and use circumstances from numerous verticals in trade occasions like AI Summit NY, AI Summit Silicon Valley, Advertising and marketing AI Convention (MAICON), and companions occasions corresponding to Snowflake Summit, Google Subsequent, masterclasses, joint webinars and extra.
Atalia holds a Bachelor of Science in industrial engineering and administration and two Masters—MBA and Enterprise Analytics.
Senior Product Advertising and marketing Supervisor, AI Observability, DataRobot
Aslihan Buner is Senior Product Advertising and marketing Supervisor for AI Observability at DataRobot the place she builds and executes go-to-market technique for LLMOps and MLOps merchandise. She companions with product administration and improvement groups to determine key buyer wants as strategically figuring out and implementing messaging and positioning. Her ardour is to focus on market gaps, tackle ache factors in all verticals, and tie them to the options.
Kateryna Bozhenko is a Product Supervisor for AI Manufacturing at DataRobot, with a broad expertise in constructing AI options. With levels in Worldwide Enterprise and Healthcare Administration, she is passionated in serving to customers to make AI fashions work successfully to maximise ROI and expertise true magic of innovation.
DJI has entered the moveable energy station area with two extremely compelling choices which might be adequate to already make our information to the greatest moveable energy stations for drone pilots. The corporate identified for making drones in April 2024 dropped two merchandise which might be comparable to one another — however which have enchantment for not simply drone pilots however a far broader inhabitants. These are the DJI Energy 1000 and DJI Energy 500. However between the DJI Energy 1000 vs Energy 500, which is healthier for you?
In brief, the DJI Energy 1000 is about twice as highly effective because the DJI Energy 500. It’s additionally twice the associated fee. For some customers, that doubling of energy is crucial. However for others, you may find yourself paying twice as a lot for energy storage that you just may ever faucet into.
If cash is completely no object, then certain, you may want the DJI Energy 1000. However even that’s not all the time the case. Given its higher-power storage, it’s additionally about 12 kilos heavier. It is available in at 28.6 kilos versus simply 16.06 kilos for the DJI Energy 500. Actually pilots may want the DJI Energy 500. This information will show you how to examine these new DJI stations and determine which most accurately fits your aerial adventures.
The last word information to DJI’s moveable energy stations
So what, precisely are moveable energy stations for? Contemplate them the longer term that’s progressed past turbines or automobile chargers. Automobile chargers simply aren’t that highly effective, which means you received’t have the ability to cost power-sucking merchandise. Or in the event you can, it’ll be a gradual course of.
However, turbines could be highly effective. However they’re usually huge, they emit gross fumes, and they are often noisy.
Contemplate moveable energy stations just like the DJI Energy 1000 or DJI Energy 500 to supply the very best of each worlds. Even the bigger of the 2, the Energy 1000, weighs lower than 30 kilos. They recharge units inside roughly an hour. And, they’re tremendous quiet. To show it, the DJI Energy 1000 generates simply 23 dB, for instance. That’s quieter than most family fridges.
Energy stations like these actually profit drone pilots who have to recharge out within the discipline, however they’re additionally tremendous helpful to campers, who need to preserve telephones and lights recharged with out the blaring noise of a generator disrupting their peace out in nature. They’ll even have sensible operate at dwelling — serving as backup energy within the case of an influence outage.
So with that, right here’s a information to among the greatest moveable energy station choices from DJI:
And let’s say you’re inquisitive about variety of instances every moveable energy charger can recharge particular gadgets. Right here’s a desk evaluating recharge instances on widespread merchandise. After all, in the event you may recharge, say, a cell phone twice, a laptop computer as soon as and a drone 3 instances, you’d want to contemplate some mixture of those charging figures:
Variety of costs that widespread tech merchandise could be recharged, per energy station
Now what about recharging the DJI Energy stations themselves? Each units can recharge totally inside 70 minutes. If you happen to don’t have that a lot time, you possibly can no less than get to an 80% cost inside 50 minutes.
Who the DJI Energy 1000 is greatest for
A real powerhouse, the Energy 1000 boasts a large 1000Wh capability. This interprets to a number of drone battery recharges, making it ideally suited for prolonged journeys or supporting a number of drones on knowledgeable shoot. It’s additionally anticipated to supply fast-charging capabilities, getting you again within the air rapidly.
The disadvantage? It’s pretty heavy at greater than 28 kilos. You don’t need to lug this round whenever you’re out mountain climbing. Provided that, this isn’t ideally suited for backpacking or conditions the place portability is a serious concern.
Who the DJI Energy 500 is greatest for
With a 500Wh capability, the Energy 500 is extra compact and moveable than its greater brother. Whereas not fairly a powerhouse, it nonetheless presents sufficient juice for a number of drone battery costs, making it good for shorter outings or weekend adventures. It prioritizes quick charging as effectively.
At simply 16 kilos, I’m not calling it mild. However, it’s among the many lightest moveable energy stations you’ll discover. Contemplate it an incredible alternative for drone pilots who prioritize simple carrying and need a station that matches comfortably in a backpack.
Kinds of supported ports
Utilizing a normal energy socket, the Energy 1000 helps each 1200W Quick Recharge Mode and 600W Customary Recharge Mode. In the meantime, the Energy 500 helps each 540W Quick Recharge Mode and 270W Customary Recharge Mode.
It’s an identical story with USB-C, the place the Energy 500 is much less highly effective versus the Energy 1000. Although each have two USB-C output ports, the Energy 1000 is 140W with a complete energy output of as much as 280W. The Energy 500 is simply 100W with a complete enter energy of 200W.
What about solar energy?
Right here’s the place the 2 are virtually the identical. Each merchandise can connect with photo voltaic panels by both the DJI Energy Photo voltaic Panel Adapter Module (MPPT) or the DJI Energy Automobile Energy Outlet to SDC Energy Cable.
DJI Energy 1000 vs Energy 500: the right way to determine
With their spectacular capacities and give attention to quick charging, these stations are certain to be game-changers for drone pilots. So which must you select? The best DJI Energy Station for you relies on your drone and total wants. Right here’s a fast breakdown that can assist you determine:
Select the DJI Energy 1000 if: You want most capability for prolonged journeys, a number of drone batteries, or skilled shoots. Quick charging and the flexibility to energy a number of units are additionally priorities. Portability could be a secondary concern.
Select the DJI Energy 500 if: You prioritize portability and a lighter weight for backpacking or frequent journey. The Energy 500 nonetheless presents sufficient energy for a number of drone costs and a number of gadget charging, making it good for shorter adventures. Quick charging is one other profit.
Irrespective of which DJI Energy Station you select, you’ll be effectively in your method to retaining your drone, and your total exploration equipment (together with laptops, lights and telephones), powered for unforgettable adventures.
Montreal/Berlin, 5. Juni 2024. Das Technologieunternehmen Vention hat in einer Studie analysiert, wie Unternehmen ihre Produktion selbstständig automatisieren. Kleine Unternehmen sind Trendsetter in der Do-it-yourself (DIY)-Automatisierung, doch große Unternehmen holen auf. Die Studie basiert auf anonymisierten Daten von weltweit über 1.400 Firmennutzern der Manufacturing Automation Platform (MAP) von Vention.
Zum zweiten Mal veröffentlicht Vention die jährliche Studie „The State of DIY Industrial Automation“. Der Fokus liegt auf der Do-it-yourself (DIY)-Automatisierung, die es Herstellern unterschiedlicher Größe ermöglicht, ihre Produktion mithilfe modernster Technologien selbstständig zu automatisieren.
Für die Studie hat Vention das Nutzerverhalten seiner Firmenkunden auf der Vention Cloud Plattform MAP von Januar bis Dezember 2023 ausgewertet. Ziel warfare es, den aktuellen Stand der DIY-Automatisierung in Unternehmen zu erfassen und zu erläutern, wie sie den DIY Ansatz für die Konzeption, Integration und den Betrieb von Automatisierungskomponenten, wie z.B. Roboterzellen oder Cobot-Palettierern, nutzen.
„Der Pattern zur DIY-Automatisierung setzt sich in diesem Jahr fort“, sagt Etienne Lacroix, CEO von Vention. „Ein Treiber ist der Fachkräftemangel, der sich zunehmend bemerkbar macht. Die Frage, wie die Produktion schnell und kostengünstig automatisiert werden kann, beschäftigt aktuell viele Unternehmen. Wir sehen, dass insbesondere kleine Unternehmen selbstständig automatisieren. Doch im Vergleich zum letzten Jahr steigt die Zahl der großen Unternehmen, die DIY-Automatisierung einsetzen, deutlich.“
Die wichtigsten Erkenntnisse der Studie:
1. Kleine („Small“, < 200 Mitarbeiter (MA)) und mittlere Unternehmen („Medium“, < 2.000 MA) waren im Jahr 2023 mit einem Anteil von 48 % bzw. 17 % die führenden Nutzer von Automatisierungssystemen auf MAP. Allerdings sahen sich kleine Unternehmen im Jahr 2023 mit schwierigeren wirtschaftlichen Bedingungen konfrontiert. Infolgedessen kam es in diesem Phase zu einem Rückgang von 12 % im Vergleich zum Vorjahr (s. Studie, S. 8).
2. Große Unternehmen („Massive“, < 10.000 MA) sowie der akademische und staatliche Forschungssektor („Academia & Gov Analysis“) haben bei der Nutzung des DIY-Ansatzes auf MAP deutlich zugelegt (+ 10 % bzw. + 4 %). Die Plattformtechnologie machte im vergangenen Jahr erhebliche Fortschritte und bietet dadurch mehr Möglichkeiten für Hochdurchsatzprojekte, die herkömmlicherweise mit größeren Herstellern bzw. Nutzern verbunden sind (s. Studie, S. 8).
3. Im Jahr 2023 haben sehr große Unternehmen („Enterprise“, > 10.000 MA) den DIY-Ansatz häufiger in ihren Fabrikhallen genutzt als jeder andere Sektor. Entsprechend ist die Anzahl der mit MAP realisierten Projekte in diesem Phase gestiegen – von durchschnittlich 4,1 im Jahr 2022 auf 4,9 Projekte im Jahr 2023 (s. Studie, S. 11).
4. Projekte mit Maschinenbedienungsanwendungen wurden im Jahr 2023 auf MAP am schnellsten realisiert. Dies ist wahrscheinlich darauf zurückzuführen, dass es angesichts des anhaltenden Arbeitskräftemangels für die Unternehmen schwierig ist, Private zu rekrutieren. Da die CNC-Integration durch die jüngsten Innovationen leichter zugänglich geworden ist, sind Hersteller mehr denn je bestrebt, schnell automatisierte Maschinenbedienungsanwendungen einzuführen (s. Studie, S. 24).
5. Nach zwei Jahren mit Rekordverkäufen (2021 und 2022) meldete die Affiliation for Advancing Automation (A3) für 2023 einen deutlichen Rückgang der Roboterverkäufe in Nordamerika um 30 %. Demgegenüber verzeichneten die Robotereinsätze auf MAP sowohl 2022 als auch 2023 einen bemerkenswerten Anstieg. Im Jahr 2023 wuchsen die Robotereinsätze auf MAP um etwa 40 % (s. Studie, S. 26).
Die vollständige Studie in Englisch finden Sie hier.