

{kind=link}
Serving as the backbone for several advanced features, its significance is pivotal. The ability to detect and identify objects within images and videos is revolutionizing numerous sectors globally, from self-driving cars and surveillance technology to medical imaging and augmented reality. TensorFlow’s Object Detection API is a powerful and adaptable tool that streamlines the development of robust object detection models. By harnessing the power of this API, architects can create bespoke designs tailored to specific requirements, significantly streamlining development time and simplifying the process.
Discovering the Step-by-Step Process of Training an Object Detection Model using TensorFlow: Integrating Datasets from a Rich Repository of Annotated Data Designed to Accelerate AI Development.
Studying Goals
- Can we train an environmentally conscious model using the Object Detection API’s settings?
- Can you efficiently leverage TensorFlow’s ability to handle large datasets in the TFRecord format to train models with massive amounts of data?
- Gain expertise in selecting and fine-tuning a pre-trained object detection model to suit specific requirements.
- Master the art of streamlining pipeline setup details and precision-calibrating model parameters to maximize performance.
- Master the coaching process, navigating checkpoints and assessing model performance throughout training.
- Can skilled models be exported for inference and deployment in real-world applications?
Object detection with TensorFlow is a multi-step process that requires defining a custom model architecture, training and optimizing the model using transfer learning, and finally deploying the trained model for object detection in images or videos.
The first step is to define the object detection model architecture. This typically involves using a combination of convolutional neural networks (CNNs) and fully connected layers to extract features from input images, followed by a region proposal network (RPN) to generate proposals for potential objects, and finally a classification branch to predict class probabilities and bounding box coordinates.
Next, you need to prepare the training data. This typically involves collecting a large dataset of labeled images or videos with annotated object instances. The annotations should include the class label, bounding box coordinates, and potentially additional metadata such as object sizes and shapes.
Once you have your training data ready, you can start training the model using transfer learning. Transfer learning is an approach that leverages pre-trained models on large datasets to fine-tune a new model for your specific task. This typically involves starting with a pre-trained CNN backbone, such as ResNet-50 or InceptionV3, and then adding custom layers on top to adapt the model to your specific task.
During training, you need to optimize the model’s weights using backpropagation and stochastic gradient descent (SGD). You also need to implement various regularization techniques, such as dropout and weight decay, to prevent overfitting.
After training, you can evaluate the performance of the model using metrics such as mean average precision (mAP) or intersection over union (IoU). You may need to fine-tune the hyperparameters or experiment with different architectures to achieve the desired level of accuracy.
Finally, you can deploy the trained model for object detection in images or videos. This typically involves writing code to load the pre-trained model and use it to generate proposals and predict class probabilities and bounding box coordinates for input images or videos.
Here is the rewritten text:
In this tutorial, we will take you on a step-by-step journey through the process of implementing object detection using TensorFlow, walking you through every stage from setup to deployment.
Step1: Setting Up the Setting
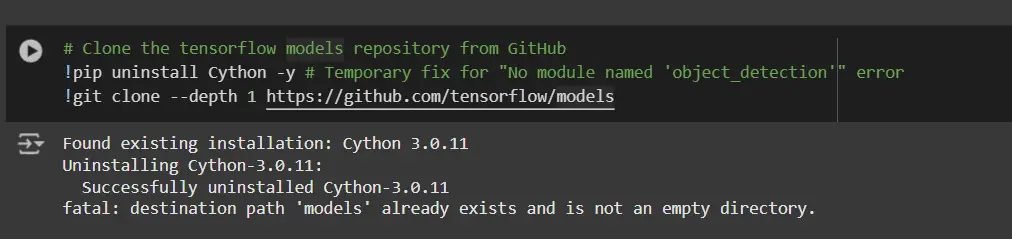
The TensorFlow Object Detection API necessitates diverse dependencies. Clone the TensorFlow Fashion dataset repository.
# Clone the TensorFlow Fashion repository from GitHub !pip uninstall Cython -y !git clone --depth=1 https://github.com/tensorflow/fashion-mnist- This step verifies that there are no conflicts with the Cython library during the setup process to ensure a seamless installation.
- This repository leverages TensorFlow’s official frameworks, including the Object Detection Application Programming Interface (API).
What are the dependencies required for your project?
# Copy setup information into fashions/analysis folder %%bash cd fashions/analysis/ protoc object_detection/protos/*.proto --python_out=. #cp object_detection/packages/tf2/setup.py . # Modify setup.py file to put in the tf-models-official repository focused at TF v2.8.0 import re with open('/content material/fashions/analysis/object_detection/packages/tf2/setup.py') as f: s = f.learn() with open('/content material/fashions/analysis/setup.py', 'w') as f: # Set fine_tune_checkpoint path s = re.sub('tf-models-official>=2.5.1', 'tf-models-official==2.8.0', s) f.write(s)Why is This Crucial?
- The Object Detection API leverages .proto specifications to define model architectures and data structures. These statements should be compiled into a functional Python program.
- TensorFlow and its dependencies evolve. Utilizing tf-models-official>=2.5.1 might inadvertently set up an incompatible model for TensorFlow v2.8.0.
- Installing a specific version of `tf-models-official`, such as 2.8.0, helps prevent potential model conflicts and fosters a stable environment by explicitly defining the model versions used.
Putting in dependency libraries
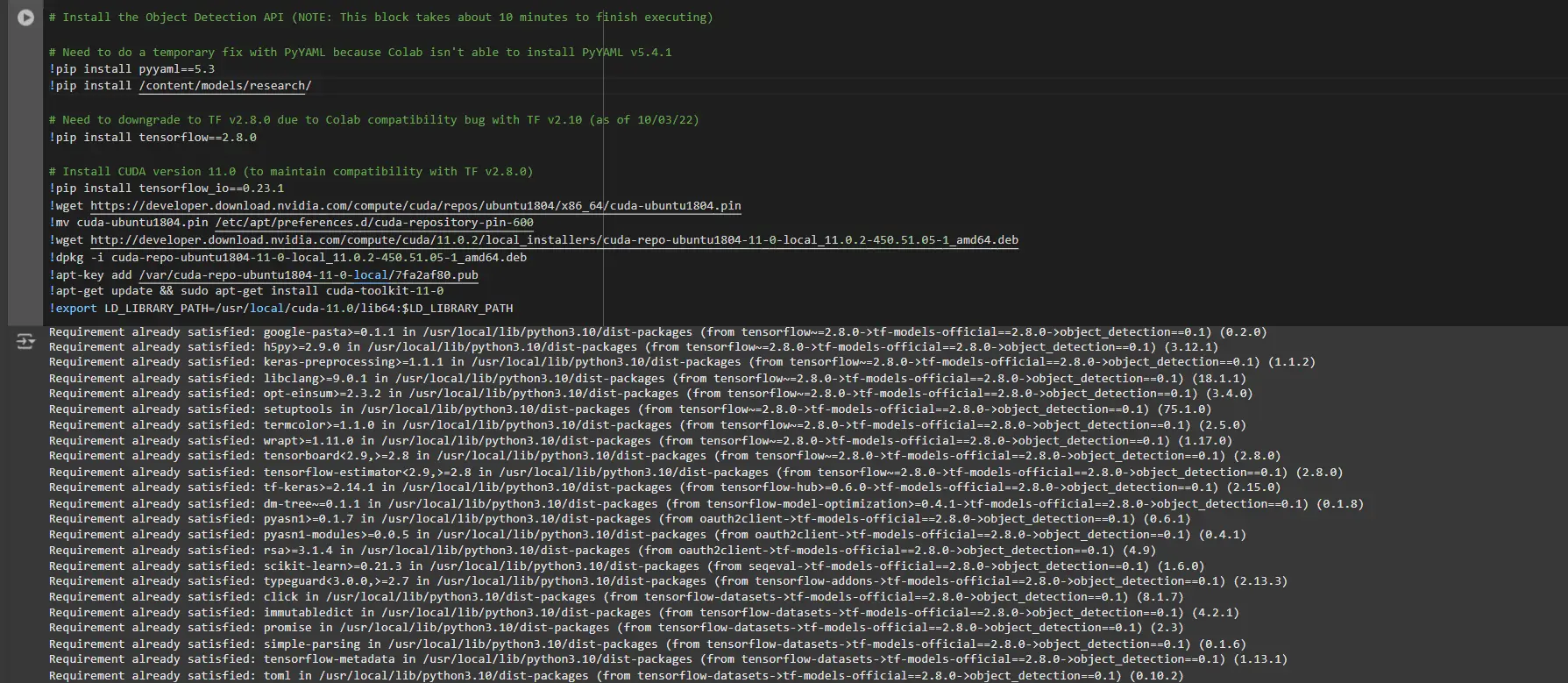
TensorFlow frameworks usually rely on specific library versions. By reconfiguring the TensorFlow model, seamless integration becomes a reality.
# Set up the Object Detection API # Have to do a short lived repair with PyYAML as a result of Colab is not capable of set up PyYAML v5.4.1 !pip set up pyyaml==5.3 !pip set up /content material/fashions/analysis/ # Have to downgrade to TF v2.8.0 on account of Colab compatibility bug with TF v2.10 (as of 10/03/22) !pip set up tensorflow==2.8.0 # Set up CUDA model 11.0 (to keep up compatibility with TF v2.8.0) !pip set up tensorflow_io==0.23.1 !wget https://developer.obtain.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin !mv cuda-ubuntu1804.pin /and so on/apt/preferences.d/cuda-repository-pin-600 !wget http://developer.obtain.nvidia.com/compute/cuda/11.0.2/local_installers/cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb !dpkg -i cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb !apt-key add /var/cuda-repo-ubuntu1804-11-0-local/7fa2af80.pub !apt-get replace && sudo apt-get set up cuda-toolkit-11-0 !export LD_LIBRARY_PATH=/usr/native/cuda-11.0/lib64:$LD_LIBRARY_PATHTo establish dependencies effectively, it is crucial to restart the classes and re-run the code after completing this block. The automated setup process will ensure all dependencies are configured effectively.
What do you think is the best way to resolve the dependency points for your project?
!pip set up protobuf==3.20.1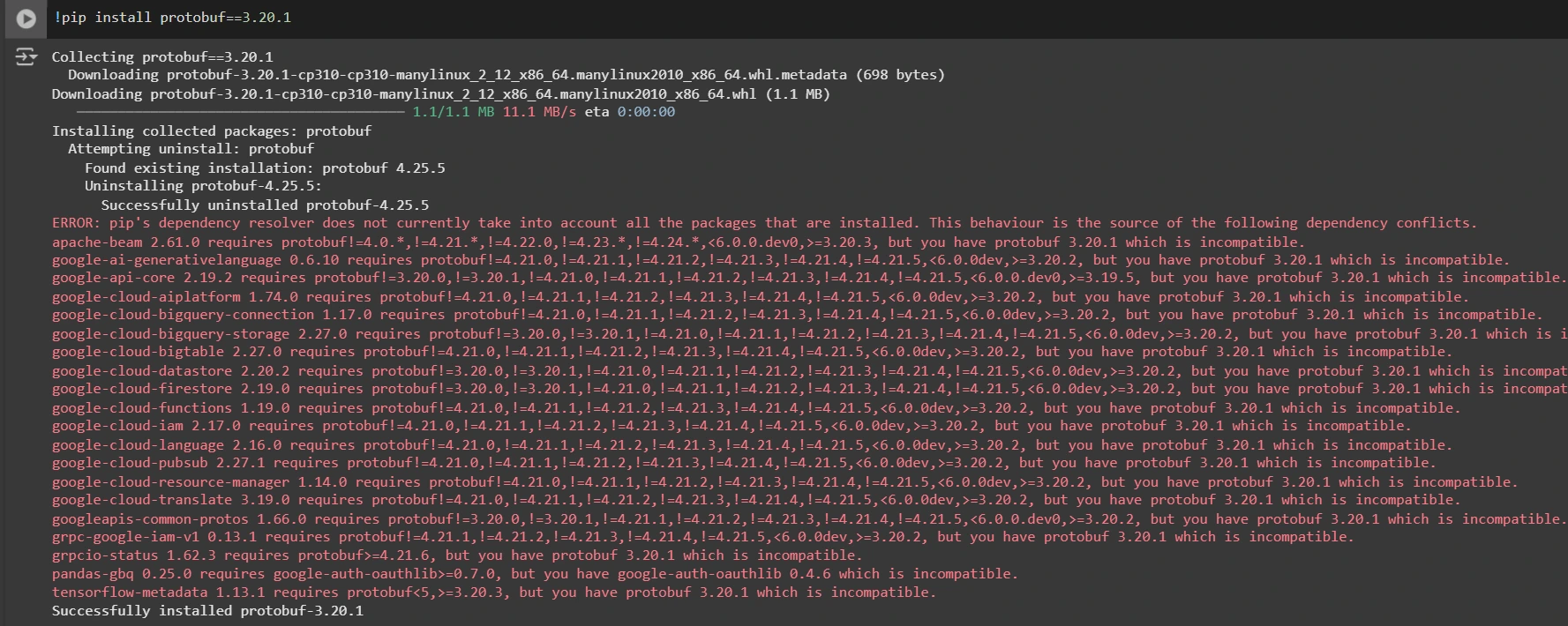
Step2: Confirm Setting and Installations
To confirm that the setup is functioning correctly, please examine:
Here is the rewritten text in a professional style: Execute Model Builder Script for Object Detection !python /content/models/analysis/object_detection/builders/model_builder_tf2_test.py 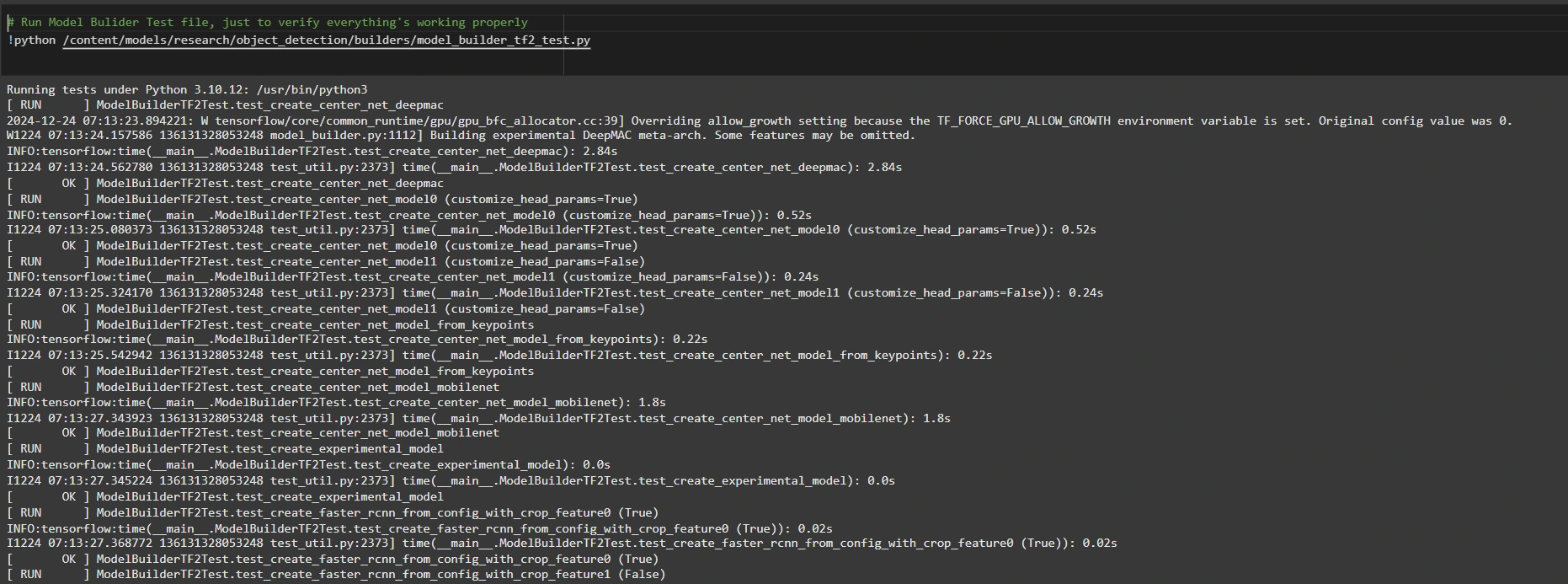
If no errors appear, your setup is complete. Now that we have set up efficiently, we move forward.
Coaches must harmonize their expertise to deliver exceptional results. To do this, they should focus on their strengths and combine them in a way that showcases their unique value proposition.
We’ll utilize the provided dataset for this tutorial. Arrange what?
Visit our comprehensive dataset webpage.

Load the dataset forked into your workspace to facilitate personalized manipulation.
What specific configuration settings are you referring to in your dataset?
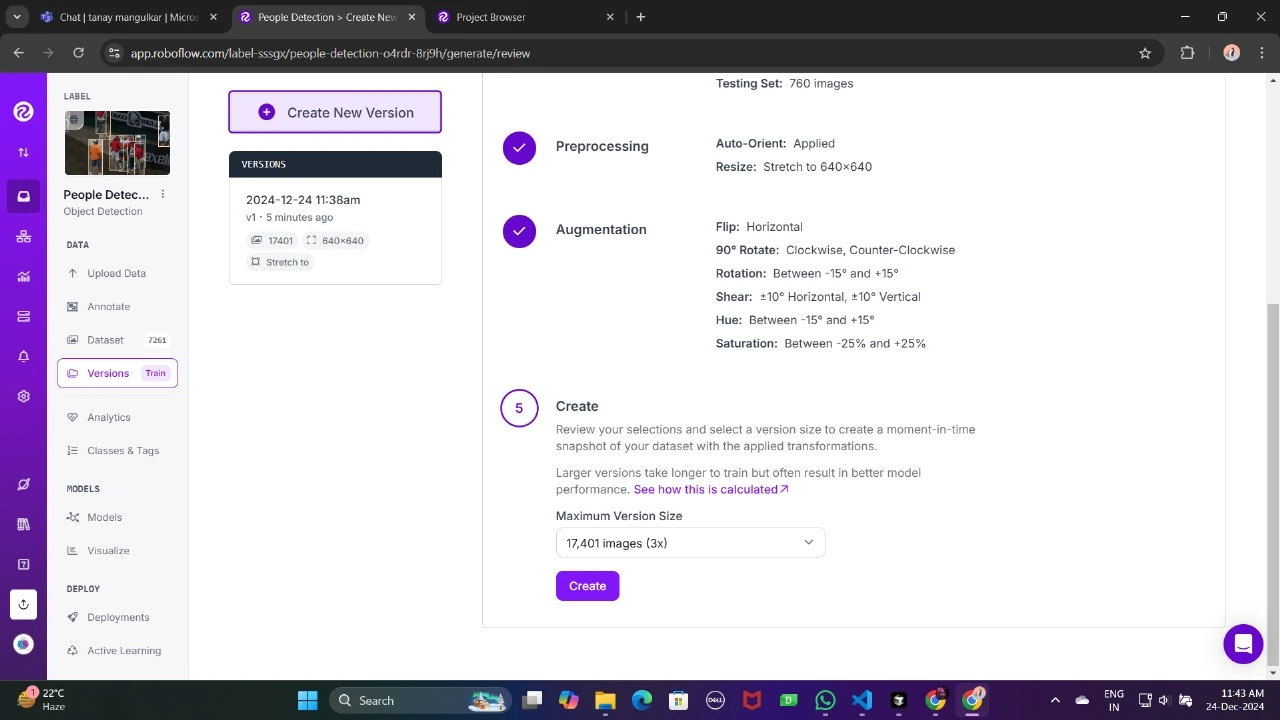
Obtain it in TFRecord format, which is a binary format optimized for TensorFlow workflows? TensorFlow efficiently processes and stores data in TFRecord format, thereby allowing seamless learning of large datasets during training while maintaining a low overhead.
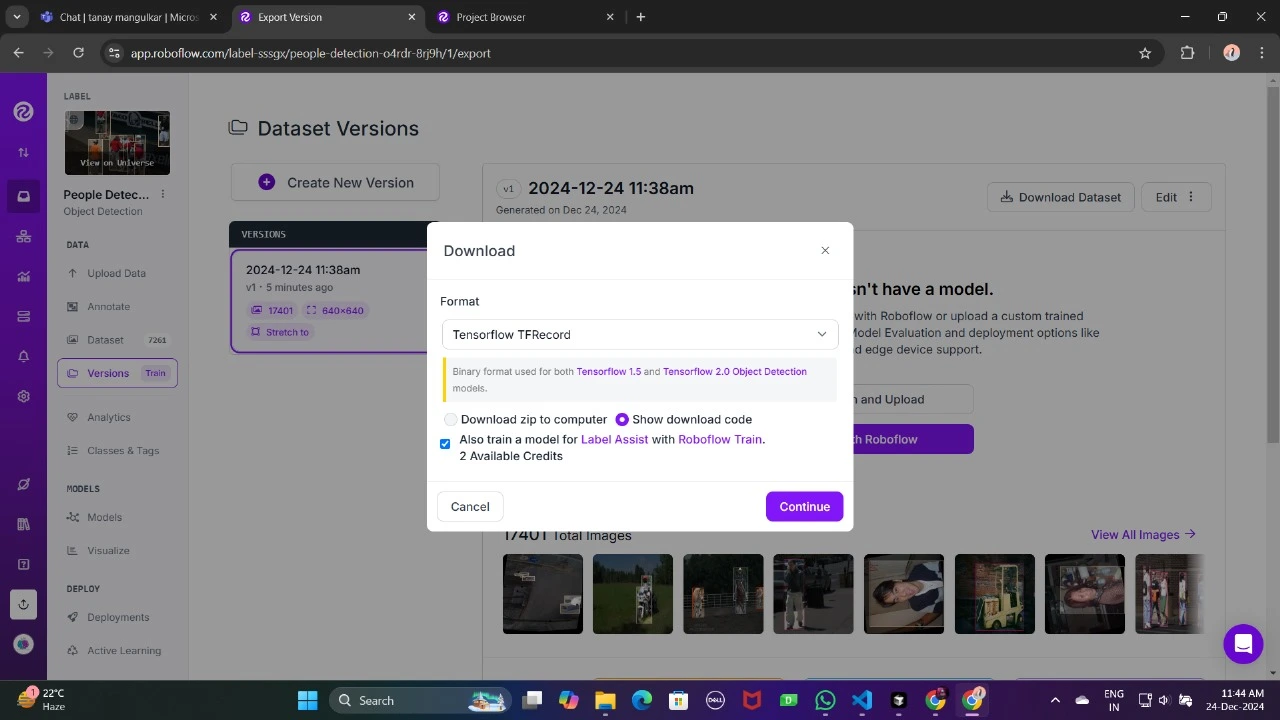
Once downloaded, store the dataset information in your Google Drive, then mount your code to your drive and load this data into your code for usage.
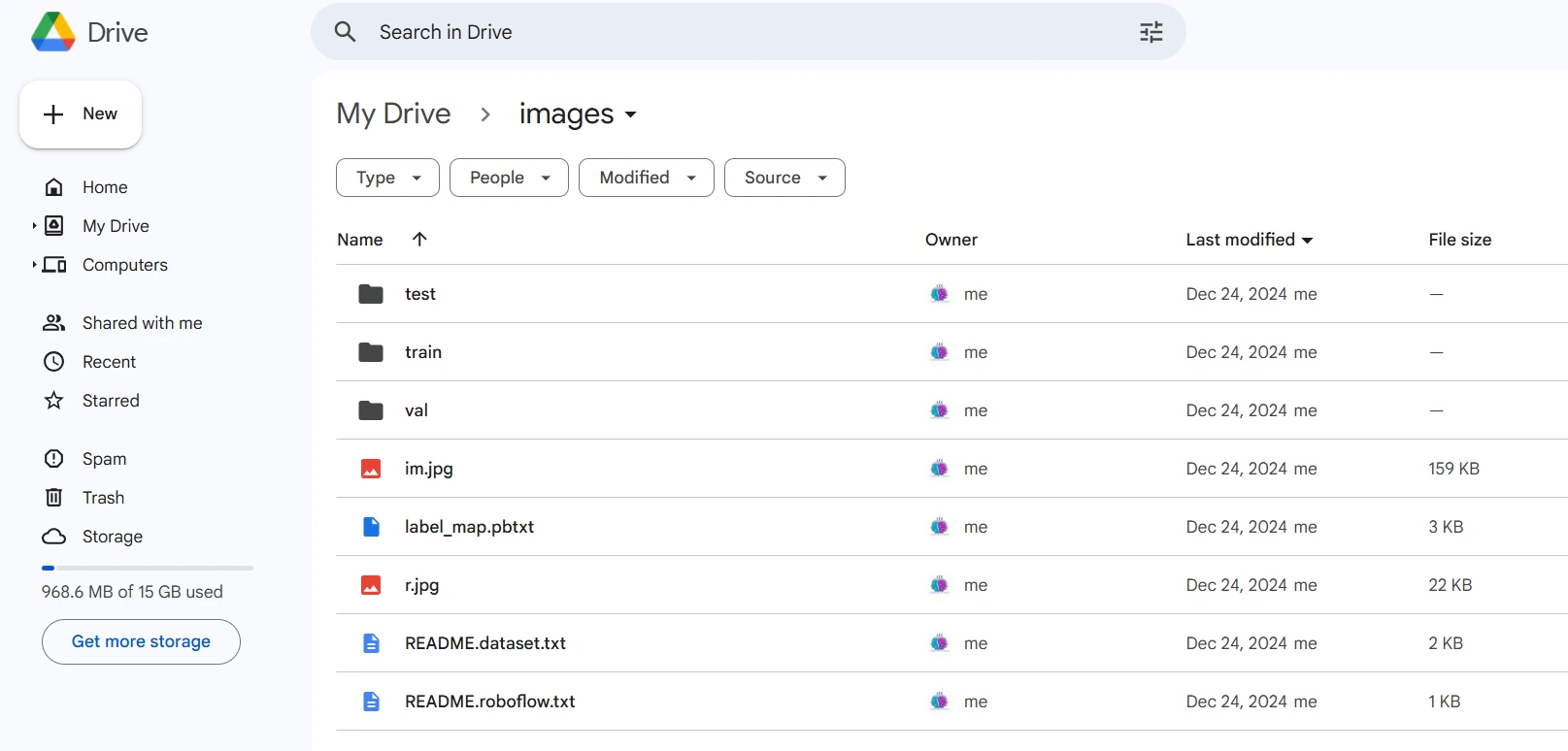
drive.mount('/content/gdrive') train_record_fname = "/content/gdrive/MyDrive/photos/prepare/prepare.tfrecord" val_record_fname = "/content/gdrive/MyDrive/photos/test/test.tfrecord" label_map_pbtxt_fname = "/content/gdrive/MyDrive/photos/label_map.pbtxt"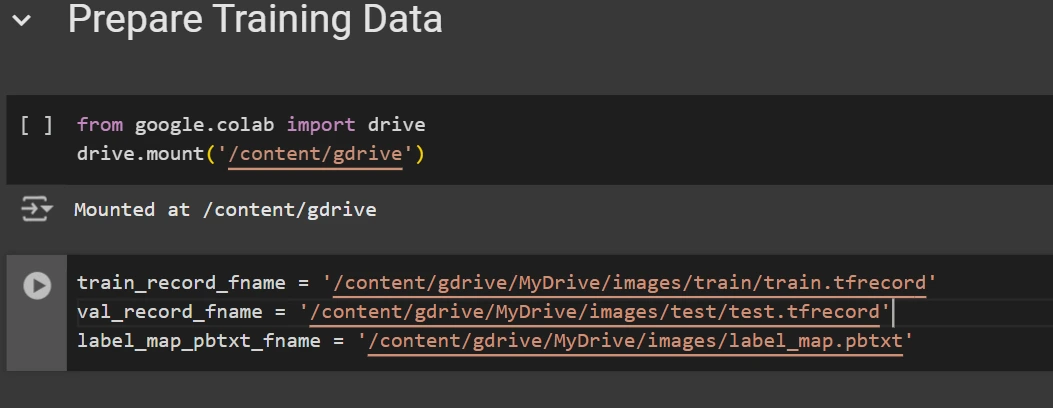
Coaching Configuration Established Successfully?
To optimize the coaching experience for all participants, follow these crucial steps to set up your coaching configuration.
Configure Your Coaching Space
Begin by defining the coaching space where your sessions will take place. This could be a dedicated room or even an online platform like Zoom. Ensure that it is quiet, private, and free from distractions.
Determine Your Coaching Schedule
Decide on a schedule that suits you and your coachees best. Will you have regular weekly sessions or ad-hoc meetings? Set realistic expectations for both yourself and your participants.
Establish Communication Channels
Designate clear communication channels to facilitate seamless coordination before, during, and after the coaching sessions. This might include email, phone, or messaging apps like WhatsApp.
Agree on Coaching Format
Discuss and agree upon the format of your coaching sessions with each participant. Will they be one-on-one, group sessions, or a combination? Clarify any specific goals, topics, or expectations for each session.
Define Your Coaching Tools
Identify the essential tools you’ll use during the coaching process. This might include personality assessments, goal-setting templates, or reflective exercises. Ensure that all participants are familiar with these tools and understand how to utilize them effectively.
Finalize Your Coaching Agreement
Create a clear agreement outlining the scope of work, roles, responsibilities, and expectations for both parties. Review and sign this document to establish a strong foundation for your coaching partnership.
SKIP
Now, let’s configure the settings for the item detection model. We will utilize the EfficientDet-D0 model for this example. One possible option for selecting object detection models is between variations such as SSD-Mobilenet-V2 and SSD-Mobilenet-V2-FPNLite-320; however, in this context, we will focus on the EfficientDet-D0 model.
MODELS_CONFIG = { 'ssd-mobilenet-v2': { 'model_name': 'ssd_mobilenet_v2_320x320_coco17_tpu-8', 'base_pipeline_file': 'ssd_mobilenet_v2_320x320_coco17_tpu-8.config', 'pretrained_checkpoint': 'ssd_mobilenet_v2_320x320_coco17_tpu-8.tar.gz', }, 'efficientdet-d0': { 'model_name': 'efficientdet_d0_coco17_tpu-32', 'base_pipeline_file': 'efficientdet_d0_coco17_tpu-32.config', 'pretrained_checkpoint': 'efficientdet_d0_coco17_tpu-32.tar.gz', }, 'ssd-mobilenet-v2-fpnlite-320': { 'model_name': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8', 'base_pipeline_file': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.config', 'pretrained_checkpoint': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.tar.gz', }, } model_name = MODELS_CONFIG.get('efficientdet-d0', {'model_name': '', 'pretrained_checkpoint': '', 'base_pipeline_file': ''})['model_name'] pretrained_checkpoint = MODELS_CONFIG.get('efficientdet-d0', {'model_name': '', 'pretrained_checkpoint': '', 'base_pipeline_file': ''})['pretrained_checkpoint'] base_pipeline_file = MODELS_CONFIG.get('efficientdet-d0', {'model_name': '', 'pretrained_checkpoint': '', 'base_pipeline_file': ''})['base_pipeline_file']Obtained are the pre-trained weights along with their corresponding configuration file for the selected model.
mkdir -p /content/material/models/mymodel && cd $_ import tarfile pretrained_url = f"http://download.tensorflow.org/models/object_detection/tf2/{20200711}/{pretrained_checkpoint}" config_url = f"https://raw.githubusercontent.com/tensorflow/models/master/research/object_detection/configs/tf2/{base_pipeline_file}" !wget {pretrained_url} with tarfile.open(pretrained_checkpoint, "r:gz") as tar: tar.extractall() tar.close() !wget {config_url}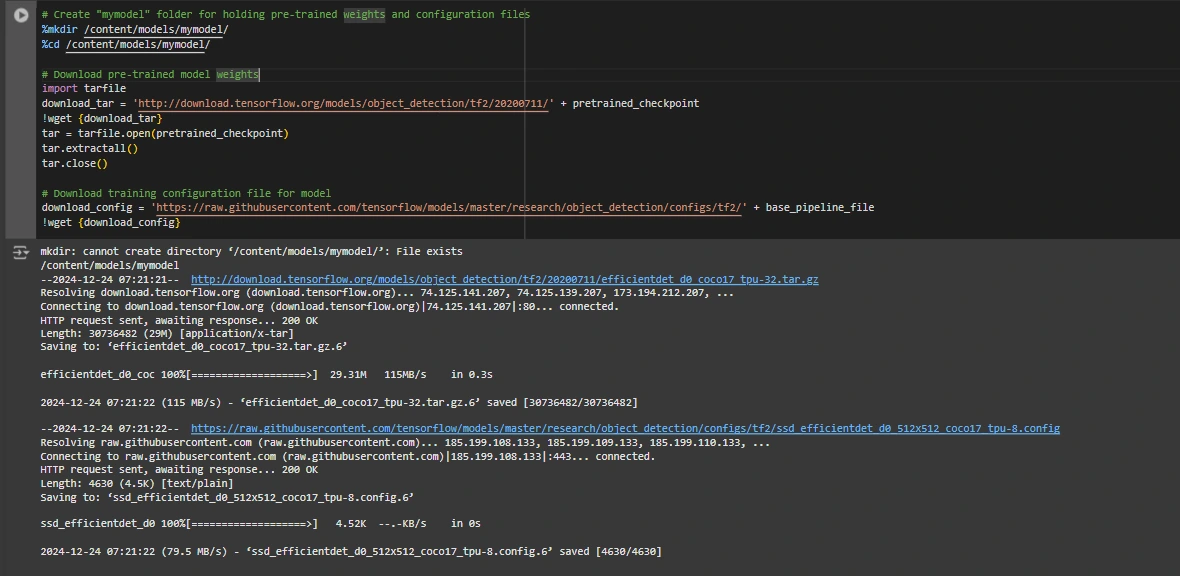
Subsequent to selecting a framework, we structure the diverse stages of coaching and assessment according to the predetermined model.
batch_size = 8 if chosen_model == 'efficientdet-d0' else 8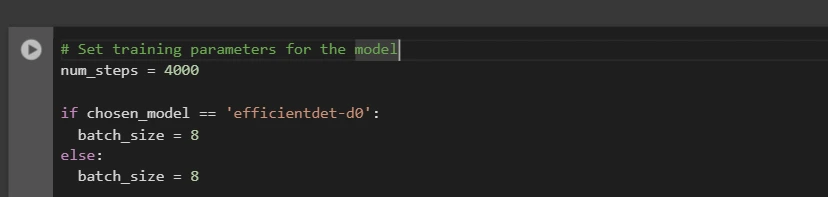
You may adjust the num_steps and batch_size to suit your specific requirements.
Modify the pipeline configuration file to define the processing workflow for your data. This step ensures that your data is processed correctly and efficiently throughout the entire pipeline.
We need to tailor the pipeline.config file by specifying the pathways for our dataset and model parameter settings. The `pipeline.config` file consolidates diverse settings, including batch size, number of epochs, and fine-tuning checkpoint specifications. We effectuate these adjustments by meticulously examining the prototype and modifying the pertinent fields.
# Define file paths for pipeline and fine-tuning checkpoint PYPATH = "/content material/fashions/mymodel/" BASE_PIPELINE_FILE = "base_pipeline_file" MODEL_NAME = "model_name" def get_num_classes(pbtxt_filename): from object_detection.utils import label_map_util label_map = label_map_util.load_labelmap(pbtxt_filename) classes = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=90, use_display_name=True) category_index = label_map_util.create_category_index(classes) return len(category_index.keys()) num_classes = get_num_classes(LABEL_MAP_PB_TXT_FILENAME) print(f"Whole lessons: {num_classes}") with open('/content/material/fashions/mymodel/pipeline_file') as f: s = f.read() import re re.sub('fine_tune_checkpoint: ".*?"', 'fine_tune_checkpoint: "{}"'.format(fine_tune_checkpoint), s) re.sub('(input_path: ".*?)(PATH_TO_BE_CONFIGURED/prepare)(.*?")', 'input_path: "{}"'.format(train_record_fname), s) re.sub('(input_path: ".*?)(PATH_TO_BE_CONFIGURED/val)(.*?")', 'input_path: "{}"'.format(val_record_fname), s) re.sub('label_map_path: ".*?"', 'label_map_path: "{}"'.format(label_map_pbtxt_fname), s) re.sub('batch_size: [0-9]+', 'batch_size: {}'.format(batch_size), s) re.sub('num_steps: [0-9]+', 'num_steps: {}'.format(num_steps), s) re.sub('num_classes: [0-9]+', 'num_classes: {}'.format(num_classes), s) re.sub('fine_tune_checkpoint_type: "classification"', 'fine_tune_checkpoint_type: "{}"'.format('detection'), s) if chosen_model == 'ssd-mobilenet-v2': re.sub('learning_rate_base: .8', 'learning_rate_base: .08', s) re.sub('warmup_learning_rate: 0.13333', 'warmup_learning_rate: .026666', s) if chosen_model == 'efficientdet-d0': re.sub('keep_aspect_ratio_resizer', 'fixed_shape_resizer', s) re.sub('pad_to_max_dimension: true', '', s) re.sub('min_dimension', 'top', s) re.sub('max_dimension', 'width', s) with open('pipeline_file.config', 'w') as f: f.write(s)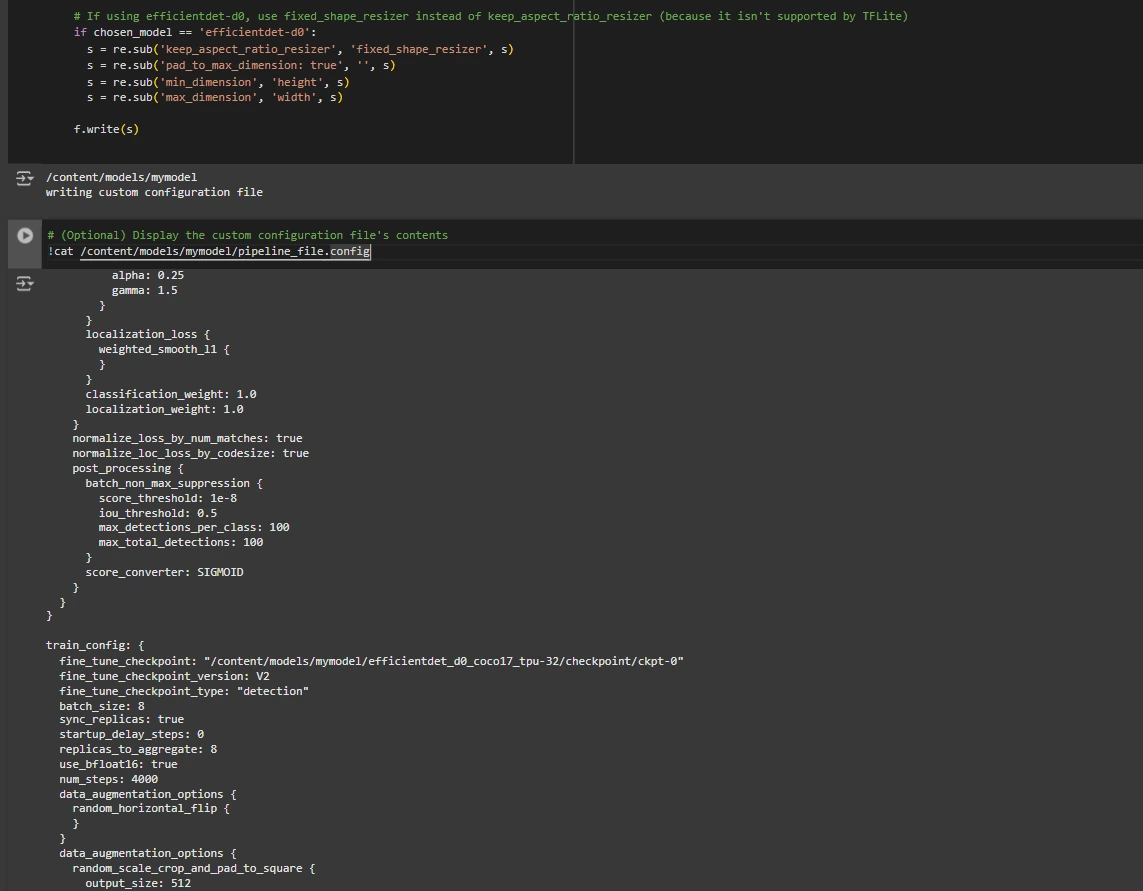
Step6: Practice the Mannequin
With our customized pipeline configuration file at hand, we’re now equipped to efficiently prepare the mannequin. The coaching script allows for saving checkpoints, providing a means to assess and gauge the efficiency of your mannequin?
Here is the improved text in a different style: Run coaching! !python /content/material/models/analysis/object_detection/model_main_tf2.py --pipeline_config_path= --model_dir= --alsologtostderr --num_train_steps= --sample_1_of_n_eval_examples=1 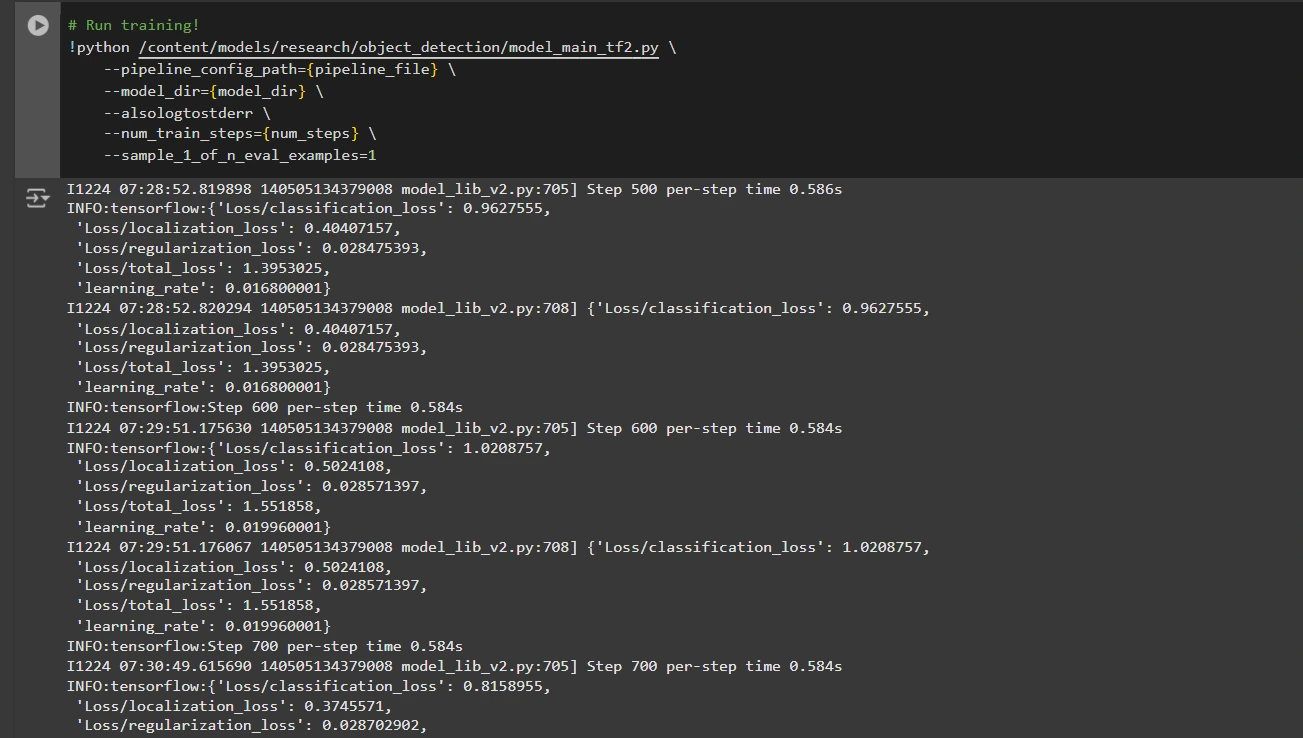
Step7: Save the Educated Mannequin
Once coaching is complete, we export the trained model to enable subsequent inference. The exporter_main_v2.py script is employed for exporting the mannequin.
!python /content/models/object_detection/exporter_main_v2.py --input_type=image_tensor --pipeline_config_path={pipeline_file} --trained_checkpoint_dir={model_dir} --output_directory=/content/exported_model 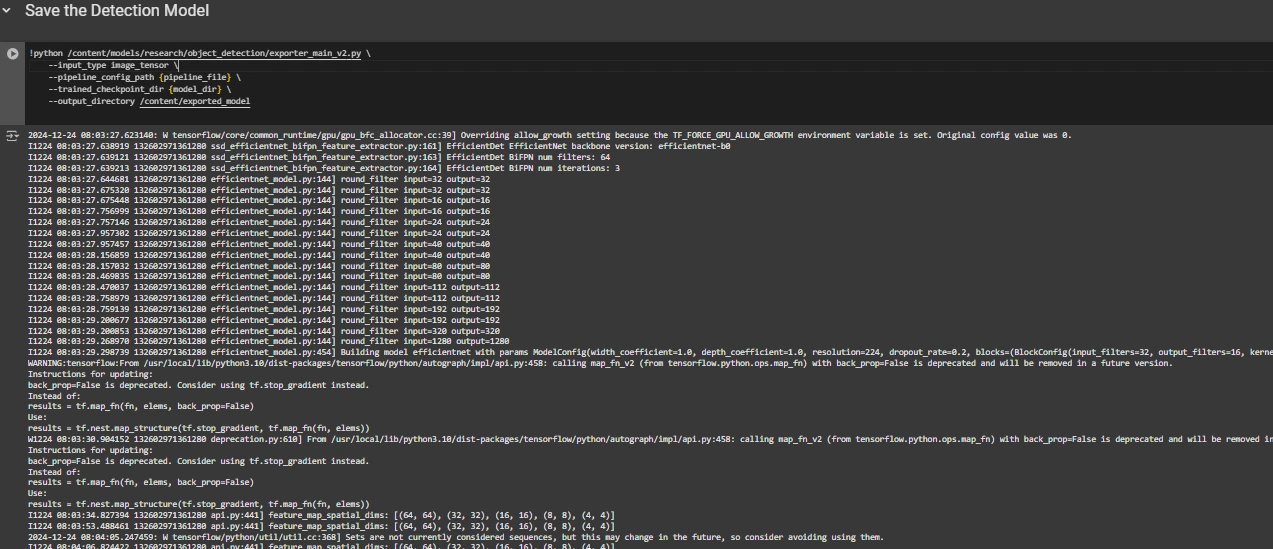
Ultimately, we compress the exported mannequin into a compact ZIP file, making it easily downloadable, and you can then retrieve your customized model in a single click.
import shutil exported_model_path = "/content/exported_model" zip_file_path = exported_model_path + ".zip" shutil.make_archive(zip_file_path[:-4], 'zip', exported_model_path) from google.colab import files files.download(zip_file_path) You should leverage the downloaded model data to test its performance on unseen images or integrate it into your desired applications according to your needs.
It seems that you possibly can consult with experts in various fields to gain valuable insights and perspectives on your topic. By doing so, you may uncover new ideas and approaches that could enhance the quality of your work.
Conclusion
As a result, this comprehensive guide empowers you to develop an effective object detection model using TensorFlow’s Object Detection API, efficiently tailored through robust datasets from Roboflow Universe. To successfully assemble your data, configure the coaching pipeline, select an optimal model, and refine it to meet your unique requirements, carefully follow these steps. The ability to export and deploy your trained model unlocks vast opportunities for practical applications across industries, from self-driving cars and medical diagnosis to security systems. This streamlined workflow enables the rapid development of robust, scalable object detection methods, significantly reducing complexity and accelerating time-to-market.
Key Takeaways
- The TensorFlow Object Detection API provides a flexible framework for building customised object detection models by leveraging pre-trained options, thereby reducing development time and complexity.
- The TFRecord format plays a crucial role in environmentally friendly data processing, especially when working with large datasets in TensorFlow, enabling rapid training and reduced overhead costs.
- Pipeline configurations provide critical insights into optimizing model performance by fine-tuning and tailoring the mannequin’s settings to seamlessly integrate with specific datasets and achieve desired efficiency characteristics.
- Pre-trained architectures such as EfficientDet-D0 and SSD-Mobilenet-V2 offer robust starting points for training custom models, each boasting distinct strengths depending on the specific use case and available resources.
- The coaching course entails effectively managing key parameters such as batch size, number of steps, and model checkpointing to ensure optimal learning outcomes.
- Converting the trained model to a deployable format is crucial for successfully leveraging the sophisticated object detection algorithm in a real-world application, where it will be packaged and readied for use.
Continuously Requested Questions
The TensorFlow Object Detection API is an open-source framework that enables the creation, training, and deployment of customised object detection models, offering versatility in its application. It offers tools for refining pre-trained models and developing custom solutions tailored to specific application scenarios.
A: TensorFlow’s TFRecord is a binary file format optimized for streamlined processing in machine learning pipelines. This innovative solution enables efficient data handling, ensuring rapid processing, reduced input/output overhead, and seamless training – ideal for tackling large datasets.
These details enable intuitive model personalization by specifying parameters such as dataset directories, training costs, model architectures, and training protocols to meet specific dataset requirements and performance objectives.
Choose EfficientDet-D0 for its robust balance of accuracy and efficiency, particularly well-suited for edge devices, whereas SSD-MobileNet-V2 is ideal for lightweight, fast real-time applications like mobile apps?