

{kind=link}
Meta at present launched V-JEPA 2, a 1.2-billion-parameter world mannequin skilled totally on video to assist understanding, prediction, and planning in robotic programs. Constructed on the Joint Embedding Predictive Structure (JEPA), the mannequin is designed to assist robots and different “AI brokers” navigate unfamiliar environments and duties with restricted domain-specific coaching.
V-JEPA 2 follows a two-stage coaching course of all with out extra human annotation. Within the first, self-supervised stage, the mannequin learns from over 1 million hours of video and 1 million photographs, capturing patterns of bodily interplay. The second stage introduces action-conditioned studying utilizing a small set of robotic management knowledge (about 62 hours), permitting the mannequin to consider agent actions when predicting outcomes. This makes the mannequin usable for planning and closed-loop management duties.
Meta mentioned it has already examined this new mannequin on robots in its labs. Meta experiences that V-JEPA 2 performs properly on frequent robotic duties like and pick-and-place, utilizing vision-based purpose representations. For easier duties comparable to choose and place, the system generates candidate actions and evaluates them based mostly on predicted outcomes. For harder duties, comparable to choosing up an object and putting it in the fitting spot, V-JEPA2 makes use of a sequence of visible subgoals to information habits.
In inside assessments, Meta mentioned the mannequin confirmed promising capability to generalize to new objects and settings, with success charges starting from 65% to 80% on pick-and-place duties in beforehand unseen environments.
“We imagine world fashions will usher a brand new period for robotics, enabling real-world AI brokers to assist with chores and bodily duties while not having astronomical quantities of robotic coaching knowledge,” mentioned Meta’s chief AI scientist Yann LeCun.
Though V-JEPA 2 reveals enhancements over prior fashions, Meta AI mentioned there stays a noticeable hole between mannequin and human efficiency on these benchmarks. Meta suggests this factors to the necessity for fashions that may function throughout a number of timescales and modalities, comparable to incorporating audio or tactile data.
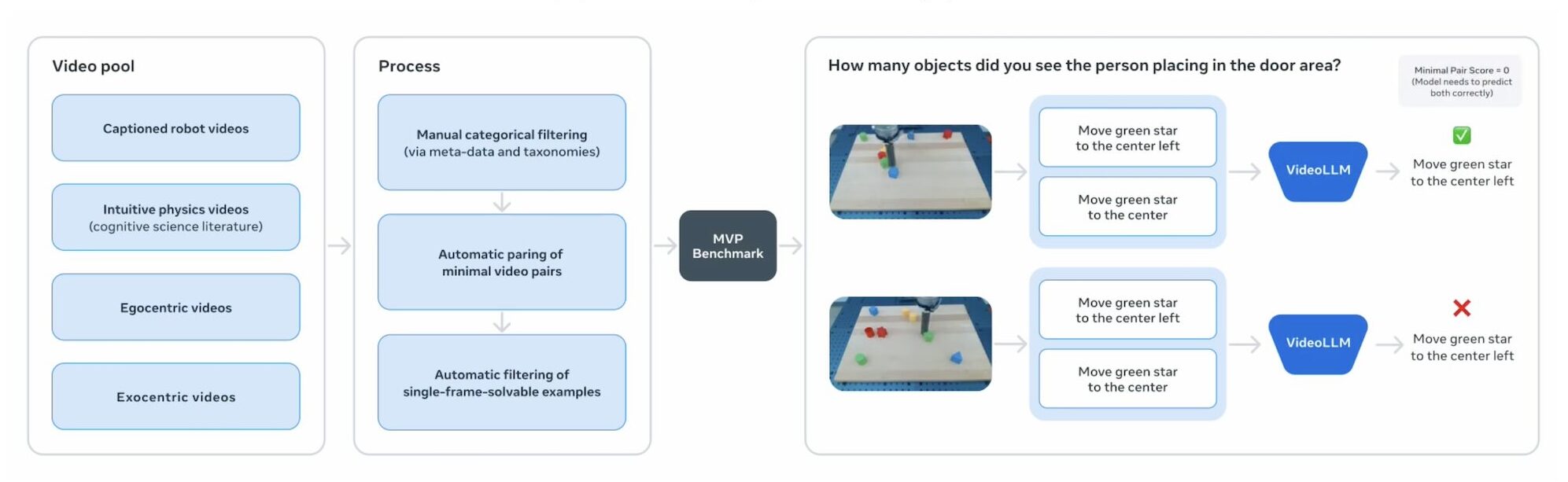
To evaluate progress in bodily understanding from video, Meta can be releasing the next three benchmarks:
- IntPhys 2: evaluates the mannequin’s capability to tell apart between bodily believable and implausible situations.
- MVPBench: assessments whether or not fashions depend on real understanding somewhat than dataset shortcuts in video question-answering.
- CausalVQA: examines reasoning about cause-and-effect, anticipation, and counterfactuals.
The V-JEPA 2 code and mannequin checkpoints can be found for business and analysis use, with Meta aiming to encourage broader exploration of world fashions in robotics and embodied AI.
Meta joins different tech leaders in growing their very own world fashions. Google DeepMind has been growing its personal model, Genie, which might simulate whole 3D environments. And World Labs, a startup based by Fei-Fei Li, raised $230 million to construct giant world fashions.