
 is a neural network component that enables contextualized processing of input sequences by capturing their intrinsic relationships. Meta SAM 2 builds upon this foundation, introducing enhancements that further expand its applicability and versatility. Architecture: The core structure of Meta SAM 2 consists of three primary components – Query, Key, and Value matrices – which work in tandem to generate attention weights. These matrices are calculated through the combination of input embeddings and learned parameters. Functions: 1. **Self-Attention**: By calculating weighted sums of Value vectors based on attention weights, Meta SAM 2 captures complex relationships within input sequences, allowing it to model contextual dependencies. 2. **Multi-Head Attention**: The model employs multiple parallel attention mechanisms (heads) to jointly process different representation subspaces at once, thereby enabling more comprehensive and robust modeling of contextual relationships. Limitations: 1. **Computational Complexity**: As the number of heads or input sequence length increases, computational demands rise exponentially, posing scalability challenges for large-scale applications. 2. **Overfitting Risk**: Without proper regularization techniques, Meta SAM 2 may suffer from overfitting issues due to its complex architecture and high-dimensional parameter space. By understanding the intricacies of Meta SAM 2’s structure, functions, and limitations, developers can effectively integrate this powerful component into their deep learning architectures, unlocking new possibilities for natural language processing and beyond.")
{kind=link}
Introduction
Meta has again pushed the frontiers of artificial intelligence with the introduction of the Phase Something Model 2 (SAM-2), a groundbreaking innovation. This milestone innovation in PC vision builds upon the exceptional achievements of its precursor, SAM, pushing the boundaries even further.
The SAM-2 technology empowers seamless real-time object detection and segmentation in both images and videos. As this breakthrough in visual comprehension propels the possibilities of AI applications across various sectors, it establishes a new benchmark for what is attainable in computer vision.
Overview
- Meta’s SAM-2 technology takes a significant leap forward in computer vision by introducing real-time image and video segmentation, building upon the foundation established by its predecessor.
- SAM-2 revolutionises Meta AI’s fashion capabilities, expanding from static image segmentation to dynamic video processing with enhanced features and increased productivity.
- The SAM-2 system optimizes video segmentation, harmonizes the architecture for both image and video tasks, incorporates memory-enhanced features, and enhances efficiency in occlusion handling.
- A cutting-edge computer vision model, SAM-2, boasts unparalleled performance in real-time video segmentation, effortlessly handling zero-shot segmentation for previously unseen objects, while allowing users to refine results with guided annotations. It also predicts occlusions and generates multiple mask predictions, consistently outperforming competitors across benchmark tests.
- The SAM-2 platform leverages advanced technologies to deliver a wide range of applications, including AI-powered video enhancement, immersive augmented reality experiences, real-time surveillance, in-depth sports analytics, environmental monitoring solutions, cutting-edge e-commerce tools, and autonomous vehicle capabilities.
- Despite progress, SAM-2 encounters hurdles in maintaining temporal coherence, distinguishing between objects, preserving beneficial features, and monitoring long-term memory recall, highlighting opportunities for further research.
In the rapidly evolving landscape of artificial intelligence and computer vision, Meta AI is pioneering innovative models that are rewriting the rules.
What lies at the core of SAM’s innovative approach is its pioneering work on picture segmentation, which enables a flexible response to consumer prompts and has the potential to democratize exceptional AI-powered vision across various sectors? SAM’s ability to generalize to novel objects and scenarios without additional training, coupled with its performance on the Phase Something Dataset (SA-1B), has established a new benchmark in the field.
With the advent of Meta SAM 2, we observe a significant milestone in the development of this technology, as it transcends its traditional realm of still images to seamlessly segment and analyze dynamic video content. Building on previous understandings, this exploration delves into how Meta SAM 2 not only capitalizes on the foundational advancements of its precursor but also introduces innovative features that have the potential to revolutionize our interaction with visual information in real-time?
Variations from the Unique SAM
While building on the innovative foundation established by its precursor, SAM 2 makes significant strides with a range of crucial improvements.
- Unlike its predecessor, SAM 2 can successfully phase objects in film footage.
- While SAM 2 leverages a solitary mannequin for both photographic and video applications, its predecessor SAM is designed specifically for image-oriented tasks.
- The incorporation of reminiscence capabilities enables SAM 2 to track objects across video frames, a feature lacking in its original iteration.
- SAM 2’s advanced occlusion detection enables predictive object visibility tracking, a feature absent from its predecessor SAM.
- SAM 2 outperforms SAM by a significant margin of six times when tasked with picture segmentation responsibilities.
- The modified version of SAM (SAM 2) surpasses its original counterpart across a range of metrics, including picture segmentation tasks, demonstrating its enhanced capabilities.
SAM-2 Options
Let’s explore the options for this model:
- The system will likely consolidate image and video processing responsibilities within a unified framework.
- The mannequin can realistically simulate the phase-in of objects on film, achieving a seamless effect at approximately 44 frames per second.
- The proposed model exhibits remarkable flexibility in that it can effortlessly phase novel objects it has never encountered before, seamlessly adapt to entirely new visual domains without any additional training, and perform zero-shot segmentation on fresh images featuring unfamiliar objects.
- Customers can further refine the segmentation of specific pixels by providing custom prompts.
- The occlusion head enables the mannequin to accurately forecast whether an object will be visible within a specific time frame.
- The proposed SAM-2 approach significantly surpasses existing methodologies in multiple benchmark evaluations for both image and video segmentation tasks.
What’s New in SAM-2?
Right here’s what SAM-2 has:
- The ability to phase objects within a video allows for a high degree of flexibility, enabling users to track their movement seamlessly across multiple frames while effectively managing occlusions that may arise.
- This mannequin enables processing of video frames individually, thereby allowing for real-time playback of extended videos.
- When faced with ambiguous pictures or videos, SAM 2 can generate various feasible mask options.
- The new feature enables the mannequin to efficiently manage and retrieve small items that might otherwise be lost or fall from its body.
- The state-of-the-art SAM 2 system exhibits enhanced capabilities in photograph segmentation, outperforming its predecessor. While it excels in its video capabilities.
The demo and net UI of SAM-2 are as follows:
SAM-2 Demo
———-
In the SAM-2 demo, you will see a user interface that showcases the system’s capabilities. The demo allows users to interact with the system through various interfaces, including graphical and command-line based interfaces.
Net UI of SAM-2
—————-
The net UI of SAM-2 is designed for network administrators and other technical professionals who need to manage and monitor network resources remotely. The net UI provides a comprehensive set of tools and features that enable users to configure, troubleshoot, and optimize network performance.
Meta has also introduced a web-based platform showcasing SAM 2 features for users to explore.
- What would you like to improve? Please provide the text and I’ll get started!
- Phases are objectified in real-time by leveraging factors, bins, and masks.
- Refine Segmentation throughout video frames
- Applying video results primarily based on model predictions.
- You can dynamically overlay an image or video as a background in Avid Media Composer. To do this, follow these steps:
The demo webpage presents a comprehensive display of options, enabling users to select from a range of possibilities, pin articles for tracing, and apply diverse outcomes with ease.
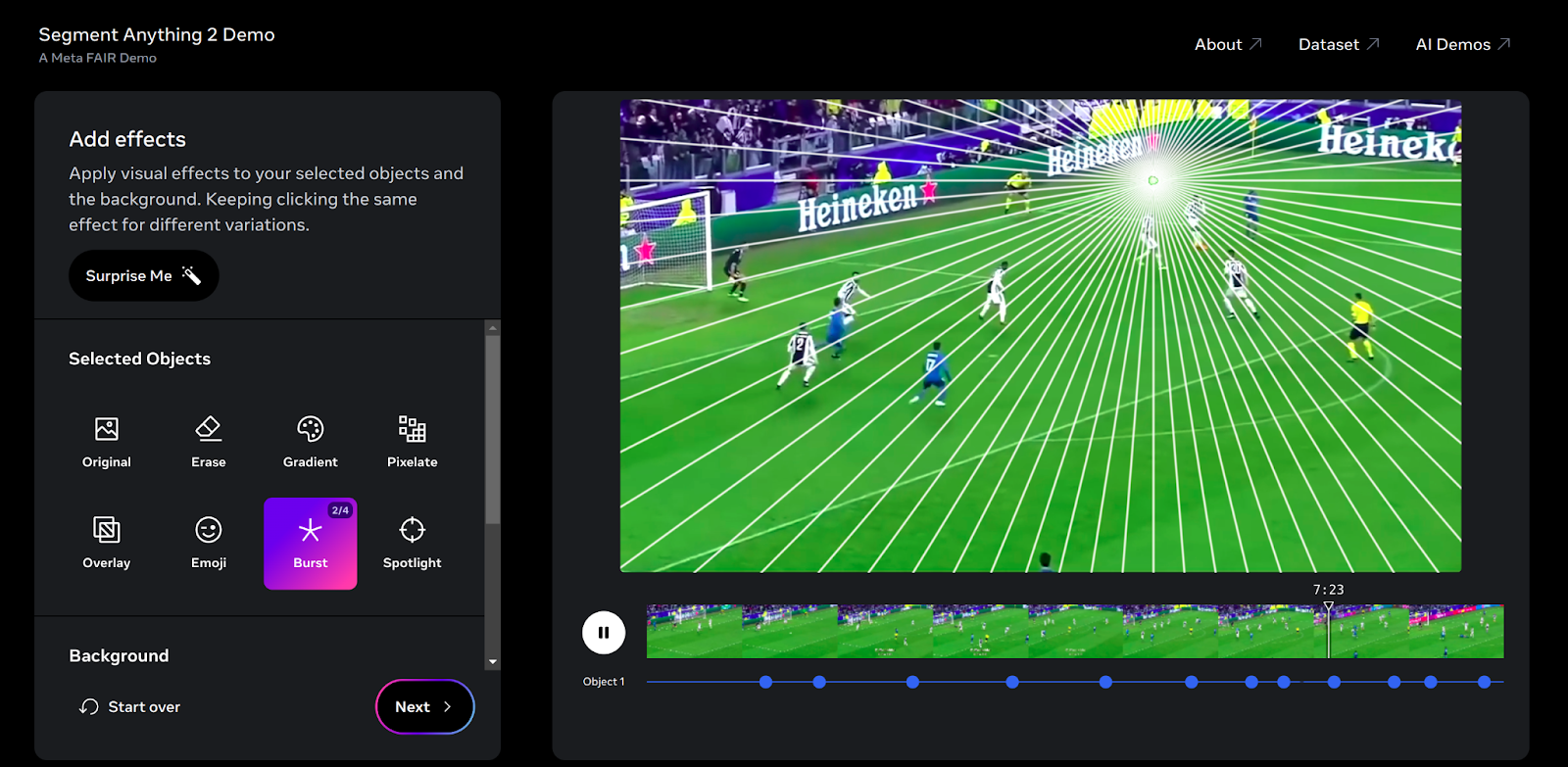
The DEMO is an effective tool for researchers and developers to uncover the full capabilities and practical applications of SAM 2.
Let’s get this play by play correct, we’re tracking the trajectory of the ball precisely.
Analysis on the Mannequin
The mannequin structure of Meta SAM 2 is composed of a rigid internal skeleton covered by synthetic skin, allowing for the precise control of facial expressions and body language.
Meta SAM 2 builds upon the innovative SAM mannequin, broadening its capabilities to efficiently handle images and videos as well. The proposed framework empowers the processing of diverse types of prompts, including factors, bins, and masks, on specific individual video frames, thereby facilitating real-time segmentation across entire video sequences.
- Utilizes a pre-trained hierarchical model to enable environmentally friendly, real-time processing of video frames.
-
“Circumstances offer body options based on prior body data, leveraging transformer blocks that integrate self-attention and cross-attention mechanisms to generate innovative solutions.”
- Unlike SAM, a platform optimized for static asset management, your solution caters to the unique demands of video content, ensuring seamless management and delivery across various platforms. The decoder enables predictive processing of various mask options for uncertain prompts, while boasting an innovative module dedicated to identifying the existence of objects within frames.
- Produces concise summaries of past forecasts and contextualized entity representations.
- Data from both current and prompted frames are combined with spatial options and object pointers to facilitate access to semantic data.
- Processes video frames in a sequential manner, enabling real-time segmentation of lengthy films.
- The model utilizes reminiscence consideration, incorporating information from preceding frames and prompts to inform its decision-making process.
- The company introduces innovative permits for real-time video feedback, revolutionizing engagement and fostering immersive experiences across various content formats.
- What scenarios assume the target object won’t be present throughout every frame?
The mannequin is trained on a vast array of images and videos, enabling it to simulate realistic interactions by generating hypothetical scenarios. The AI’s training mechanism relies on sequences of precisely eight frames, punctuated by up to two frames deliberately selected to stimulate creative responses. This approach enables the mannequin to adapt to various prompting scenarios and accurately disseminate segmentation across video frames.
This innovative architecture enables Meta SAM 2 to provide a more flexible and engaging experience for complex video segmentation tasks. While leveraging the distinct advantages of the SAM mannequin, this approach also thoughtfully addresses the novel difficulties inherent in processing video data.
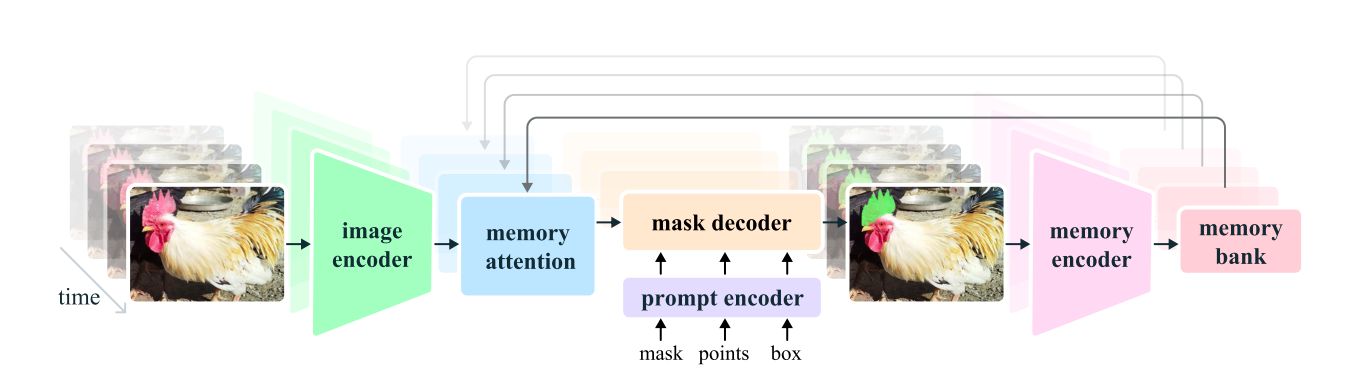
The promptable visible segmentation technology enhances the capabilities of Structured Audio Monitor (SAM), a video surveillance system that enables effective monitoring and analysis of visual data.
Promptable Visible Segmentation (PVS) marks a significant milestone in the development of Phase Something (PSA), expanding its scope beyond traditional still-image applications to encompass the complexity and dynamism of video data. This innovative feature enables real-time segmentation of entire video sequences, maintaining the adaptability and quickness that cemented SAM’s reputation as a game-changer.
Within the PVS framework, customers can collaborate seamlessly with any video content creator, leveraging a variety of intuitive formats, including clicks, boxes, and masks, to streamline their workflow. The mannequin successfully segments and tracks the targeted object throughout the entire video. This interplay preserves instantaneity of response on prompted bodies, similarly to SAM’s efficiency on static images, while also generating near-real-time segmentations for entire videos.
Key options of PVS embody:
- PVS allows for prompt creation on any body part, unlike traditional video object segmentation tasks that often rely on initial-frame annotations.
- Customers can utilize a range of prompts, including clicks, masks, and bounding boxes, thereby increasing flexibility in their interactions.
- The mannequin provides real-time recommendations for the prompted body, along with seamless segmentation throughout the entire video.
- Like SAM, PVS focuses on targeting objects with distinct, visible boundaries, deliberately omitting uncertain or ambiguous regions.
- This style guide specifically outlines the process for capturing and processing static photographs, serving as a unique example within the broader framework of the Phase Something activity.
- It surpasses traditional semi-supervised and interactive video object segmentation capabilities, venturing beyond limitations imposed by specific prompts or initial frame annotations.
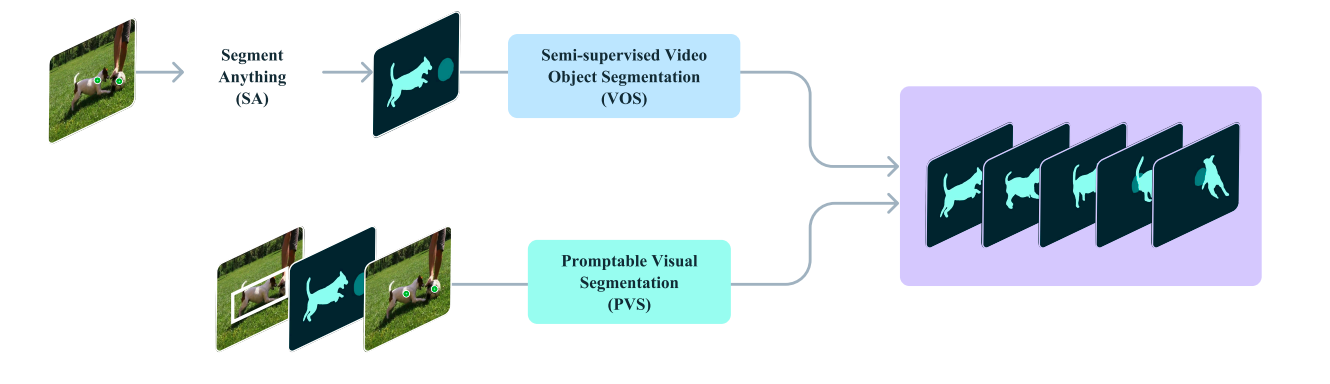
The evolution of Meta SAM 2 focused on a three-phased analysis curriculum, each segment introducing pivotal advancements in annotation efficiency and model capabilities.
The SAM (Semantic Annotation Markup) framework offers a robust approach to foundational annotation by providing a structured way to categorize and connect concepts. By leveraging this toolset, researchers can create a comprehensive repository of annotated texts, enabling the development of sophisticated AI models that accurately capture nuances in human language.
- Utilized an innovative image-based interactive Systematic Annotation Model (SAM) to facilitate precise and efficient frame-by-frame annotation.
- Annotators manually segmented objects at a rate of approximately six frames per second, leveraging the power of Scene Understanding Model (SAM) and advanced tools for optimal performance.
- Outcomes:
- A staggering 16,000 masklets were gathered across 1,400 films.
- Average annotation time: 37.8 seconds per body
- Generated precise spatial annotations with a high level of accuracy, albeit at the cost of considerable time investment.
SAM 2 masks are a breakthrough innovation in respiratory protection, offering unparalleled filtration efficiency and comfort. Designed for the most demanding industrial applications, these versatile masks provide reliable defense against airborne contaminants, particulate matter, and biological agents. With its advanced silicone seal and adjustable straps, SAM 2 ensures a secure fit that minimizes air leaks and reduces eye strain. Whether you’re working in a manufacturing plant or a healthcare setting, SAM 2 masks guarantee unparalleled respiratory protection for the modern worker.
- What’s driving this temporal mask’s spread? Built-in SAM 2 for robust temporal propagation of masks.
-
- Preliminary body annotated with SAM
- SAM 2 successfully propagated annotations to subsequent frames.
- Annotators refined predictions as wanted
-
- 63,500 masklets collected
- Our annotation time has plummeted to a remarkable 7.4 seconds per body, representing a staggering 5.1 times speed-up!
- The mannequin underwent two rounds of rigorous retraining during this segment.
The full-scale implementation of Software Asset Management (SAM) version 2 across all departments and subsidiaries will require a comprehensive strategic plan. This plan should include key performance indicators (KPIs), metrics, and milestones to ensure successful integration and ongoing management.
- A unified framework for interactive image segmentation and mask propagation.
-
- Embraces a wide range of instant diversities (elements, disguises).
- Harnessing temporal reminiscence enables more accurate forecasting.
-
- 197,000 masklets collected
- The annotation time has been further accelerated, now taking just 4.5 seconds per body – an impressive eightfold increase in efficiency since the first iteration.
- The mannequin underwent five rounds of retraining, incorporating novel information.
Here’s a comparison between the stages:

- Time taken for annotation decreased significantly, from 37.8 seconds per body in earlier phases down to a mere 4.5 seconds.
- Transforming laborious frame-by-frame annotations into efficient and streamlined video segmentation.
- Evolved into a streamlined process that only necessitates periodic adjustments through intuitive click-based interactions.
- Consistent retraining with fresh knowledge significantly boosted productivity.
This phased strategy demonstrates the iterative refinement of Meta SAM 2, emphasizing crucial advancements in both the model’s capabilities and the efficacy of its annotation process. The analysis illustrates a transparent progression towards developing a more robust, adaptable, and intuitive video segmentation tool.
The analysis paper showcases several pivotal advancements accomplished by Meta SAM 2:
- While it outperforms the standardised model (SAM) on its comprehensive 23-dataset zero-shot evaluation set, it also accelerates picture segmentation tasks by a notable six-fold margin.
- Meta SAM 2 sets a new standard for excellence in video object segmentation, outperforming established benchmarks like DAVIS, MOSE, LVOS, and YouTube-VOS to achieve state-of-the-art results.
- The mannequin attains an impressive inference velocity of approximately 44 frames per second, providing a seamless and responsive user experience in real-time. Meta SAM 2 outperforms guided per-frame annotation with the original SAM by a significant margin of 8.4 times when utilized for video segmentation annotation.
- To ensure optimal resource allocation and consistency across diverse customer segments, investigators conducted comprehensive equity assessments of Meta SAM 2.
While initial findings suggest that mannequins demonstrate subtle differences in video segmentation efficiency across perceived gender groups, further investigation is necessary to fully elucidate these discrepancies and their potential implications.
Meta SAM 2’s advancements in velocity, accuracy, and flexibility are showcased across various segmentation tasks, consistently delivering efficient results across diverse demographic groups? By combining cutting-edge technology with socially conscious considerations, Meta SAM 2 emerges as a groundbreaking innovation in transparent segmentation strategies.
Based on the provided dataset, SA-V (Phase Something – Video), the Phase Something 2 mannequin is built upon a robust and diverse collection of data. This dataset marks a significant milestone in PC vision, particularly with regards to training general-purpose object segmentation models from open-world movies.
The SA-V dataset comprises a comprehensive collection of approximately 51,000 diverse films, accompanied by 643,000 spatially and temporally precise segmentation masks, known as masklets, offering in-depth insights into the visual content of each movie. This comprehensive dataset has been engineered to support an array of PC vision analysis tasks, all released under the permissive terms of the CC BY 4.0 license, allowing for broad applicability and collaboration in the field of computer vision.
The SA-V dataset’s core characteristics encapsulate.
- The SA-V database boasts an impressive 51,000 films, accompanied by an average of 12.61 masklets per video, offering a richly diverse and extensive body of knowledge at its disposal. The films cover a wide range of subjects, including settings, objects, and complex scenarios, thereby ensuring comprehensive coverage of realistic events.
- The dataset combines both human-curated and AI-aided annotation efforts. Among the total of 643,000 masklets, 191,000 were produced through a collaborative process involving SAM 2-assisted guide annotation, while 452,000 were generated automatically by SAM 2 and subsequently validated by human experts.
- SA-V employs a class-agnostic approach to annotation, excelling at generating mask annotations without relying on specific class labels. This strategy significantly boosts the mannequin’s adaptability in categorizing a wide range of objects and scenarios.
- Typical video decisions within the dataset are 1401×1037 pixels, providing high-resolution visual data to support effective model training.
-
More than 643,000 Masklet annotations were thoroughly evaluated and validated by human experts, ensuring exceptionally high-quality and reliable data.
- The dataset provides masks in various formats to accommodate diverse needs – COCO’s run-length encoding (RLE) for training sets, and PNG format for validation and test units.
The development of SA-V entailed a painstaking process of compiling, annotating, and verifying vast amounts of information with utmost precision. Films were meticulously curated through a contracted third-party provider, carefully selected for their thematic relevance. By combining the strengths of the SAM 2 model and the expertise of human annotators, the annotation course successfully yielded a dataset that harmoniously blends efficiency with precision.
Instances of movies from the SA-V dataset are depicted, featuring masklets superimposed on each graphic representation. Each masklet is uniquely characterized by its distinct coloration, and each row showcases consecutive frames from a solitary video, with a one-second gap between each frame.

Obtain the SA-V dataset easily and promptly from Meta AI’s readily accessible resources. The dataset is available for download at the following URL:
To enter the dataset, ensure you provide the necessary data via the submission process. This may occasionally include details regarding intended usage of the dataset and conformity with the terms of use. While acquiring and employing the dataset, it is crucial to meticulously study and adapt to the CC BY 4.0 licensing terms and usage guidelines provided by Meta AI for seamless integration.
While Meta SAM 2 marks a significant milestone in the evolution of video segmentation capabilities, it is crucial to recognize both its current strengths and the need for further refinement and innovation.
1. Temporal Consistency
In situations where scene modifications are rapid-fire or video sequences prolong, the mannequin may struggle to maintain consistent object tracking. To maintain up with the tempo of a fast-paced sporting event and numerous camera angles, Meta SAM 2 may well struggle to focus on a specific player?
2. Object Disambiguation
The mannequin may occasionally misclassify the target objective in complex settings featuring multiple interconnected items. A bustling metropolis street may potentially misidentify various models of the same vehicle, merely due to its identical appearance and coloring.
3. Effective Element Preservation
The Meta SAM 2 sometimes struggled to accurately capture subtle details about objects in rapid motion. When endeavouring to grasp the swift movements of a hen’s plumage while in flight, this discrepancy might become apparent.
4. Multi-Object Effectivity
As the number of objects to track increases, the mannequin’s processing power is compromised, resulting in decreased efficiency when handling multiple segments simultaneously? This limitation becomes particularly evident in situations like crowd evaluation or multi-character animation.
5. Lengthy-term Reminiscence
The limitations of a mannequin’s ability to retain and notice objects for extended periods in feature-length films are well-established. This could pose significant challenges in functions like surveillance or long-form video enhancement.
6. Generalization to Unseen Objects
Despite being broadly trained, Meta SAM 2 can still grapple with extremely rare or novel objects that deviate significantly from its existing knowledge?
7. Interactive Refinement Dependency
Despite challenging situations, the mannequin typically relies on additional customer guidance to achieve accurate segmentation, limiting its ability to perform fully autonomous tasks.
8. Computational Sources
While more efficient than its precursor, the Meta SAM 2 still necessitates considerable computing power to function in real-time, likely restricting its application in scenarios with limited resources.
Future analysis instructions may significantly boost temporal consistency, optimize the retention of crucial elements within dynamic scenes, and pioneer innovative, eco-friendly techniques for monitoring multiple objects. Developing strategies to significantly reduce the need for human oversight and enhancing the model’s ability to generalise to an even broader range of objects, scenarios and situations would be highly valuable. As the sector advances, it will be crucial to address these limitations to fully unlock the potential of AI-driven video segmentation expertise?
The Meta SAM 2’s unveiling presents exciting possibilities for future developments in artificial intelligence and computer vision.
- As fashion trends evolve with the emergence of Meta SAM 2, we can expect increasingly seamless collaborations between AI systems and human users in visual assessment tasks?
- The enhanced real-time segmentation functionality has the potential to significantly enhance the AI-driven programs of autonomous vehicles and robots, enabling more accurate and efficient navigation and interaction within their surroundings.
- The technological prowess driving Meta SAM 2 may yield exceptionally advanced tools for video editing and content production, potentially revolutionizing sectors such as film, television, and social media.
- Future advancements in this expertise have the potential to revolutionize medical image analysis, leading to more accurate and timely diagnoses across multiple medical disciplines?
- The equity assessments conducted on Meta SAM 2 established a landmark precedent for considering demographic fairness in AI model development, potentially shaping the trajectory of future AI research and innovation endeavors?
Meta SAM 2’s versatile features unlock a wide range of possibilities across various sectors, including.
- The mannequin’s ability to seamlessly manipulate objects in video could significantly simplify complex tasks such as object removal or replacement, thereby streamlining enhancement processes.
- The Meta SAM 2’s real-time segmentation capabilities may significantly enhance AR functions by enabling more accurate and responsive object interactions within immersive augmented environments.
- The mannequin’s ability to track and phase objects across video frames could significantly enhance safety protocols by enabling more nuanced monitoring and threat detection.
- In the realm of sports broadcasting and analysis, Meta SAM 2 can monitor player movements, dissect game strategies, and generate more captivating visual content for audiences to engage with.
- Using a mannequin could enable researchers to track and assess changes in landscapes, vegetation, or wildlife populations over time, facilitating ecological studies and urban planning initiatives.
- The application of expertise could significantly enhance digital try-on experiences in online shopping, enabling more accurate and realistic product visualizations.
- Meta’s SAM 2 technology may significantly boost the accuracy of object detection and scene comprehension in autonomous vehicle projects, thereby fortifying safety and navigation features.
Here are the improved text:
Meta SAM 2’s versatility is highlighted through these functions, which demonstrate its capacity to foster innovation across diverse industries, including leisure, commerce, scientific research, and public safety.
Conclusion
The Meta SAM 2 marks a significant advancement in visible segmentation, building on the innovative foundation established by its predecessor. This cutting-edge model showcases remarkable adaptability, adeptly tackling both image and video segmentation tasks with precision and efficiency. The ability to process video frames in real-time while maintaining high-quality segmentation marks a significant breakthrough in computer vision technology.
The mannequin’s enhanced efficacy across various assessments, accompanied by a reduced need for human oversight, highlights the transformative power of AI in reshaping our collaboration with and analysis of visual data. While Meta SAM 2 has some limitations, such as difficulties with rapid scene changes and preserving beneficial elements in dynamic scenarios, it sets a new benchmark for real-time visual segmentation. This groundbreaking research sets a strong foundation for future advancements within its field.
Regularly Requested Questions
Ans. Meta SAM 2 is a cutting-edge artificial intelligence model designed for precise picture and video segmentation tasks. Unlike its predecessor, SAM, which was limited to processing still images, SAM 2 has the ability to phase objects in both photographs and video footage. With its enhanced capabilities, this system achieves picture segmentation six times faster than SAM, processes movies at approximately 44 frames per second, and boasts innovative features such as a memory mechanism and occlusion prediction.
Ans. SAM 2’s key options embody:
Unified structure for picture and video segmentations: A Consistent Framework
– Actual-time video segmentation capabilities
Zero-shot segmentation: discovering novel object boundaries without prior training.
– Person-guided refinement of segmentation
– Occlusion prediction
Forecasts abound for unpredictable situations –
Boosted performance across multiple metrics, yielding tangible gains in efficiency.
Ans. The SAM 2 leverages a streaming architecture to process video frames in real-time succession. The proposed system integrates a memory-based framework, comprising a reminiscence encoder, a reminiscence bank, and a reminiscence attention module, to effectively track objects across frames while addressing occlusion challenges. This feature allows for seamless phrasing and compliance with objects throughout a video, including rapid disappearances or re-entry into the body.
Ans. The SAM 2 model was trained on the SA-V (Phase Unknown – Video) dataset. The dataset comprises approximately 51,000 diverse films accompanied by 643,000 spatial-temporal segmentation masks, commonly known as masklets. The dataset seamlessly integrates both human-curated and AI-driven annotations, ensuring accuracy through rigorous validation by human experts, and is now commercially available under the Creative Commons Attribution 4.0 license.