
, enabling faster query execution.")
{kind=link}
Dataricks is pleased to announce that its latest release, Databricks Runtime 15.2 and Databricks SQL 2024.30, now feature the general availability of Major Key (PK) and International Key (FK) constraints, a major milestone in our ongoing commitment to innovation and customer satisfaction. Following a highly successful public preview that garnered widespread enthusiasm from numerous active users each week, this launch marks a significant milestone in advancing knowledge integrity and relational data management within the Lakehouse ecosystem.
Additionally, Databricks leverages these constraints to intelligently optimize queries, eliminating unnecessary operations from the execution plan, thereby accelerating performance.
The primary constraint on a major key is that all non-prime attributes must depend entirely upon the prime attribute(s). In other words, any attribute that is not part of the candidate key must rely solely on the candidate key for its uniqueness. This means that if a table has multiple candidates, they must work together to ensure the integrity of the data.
International keys are more flexible and can be used in situations where the primary keys from different tables need to be combined.
Major keys (primary keys) and international keys (foreign keys) are crucial elements in relational databases, serving as fundamental building blocks for knowledge representation. They provide insight into the intricate relationships between information, schemas, and entities, offering customers, instruments, and purposes valuable context; simultaneously, they enable optimisations that capitalise on constraints to expedite query execution. Major and overseas keys are typically located within your Delta Lake tables hosted in Unity Catalog.
SQL Language
When outlining constraints while creating a desk, you likely consider factors such as space limitations?
UserName STRING, E mail STRING, );The primary restriction governing the column is outlined. UserID. Databricks also enables constraints on teams of columns effectively.
You can also modify existing Delta tables by adding or removing constraints to improve data integrity and ensure that related data remains consistent.
ProductName STRING, ); The initial key is established as products_pk on the non-nullable column ProductID in an present desk. To successfully carry out this task, one must possess ownership of the desk. Ensure uniqueness among constraint names within the schema structure.
The following command deletes the first dictionary item by specifying its title.
The same principles apply to international keys as well. The newly created desk defines and assigns two international key combinations at its inception.
);Consult the documentation on `and` and `statements for further information on syntax and operations related to constraints?
While major keys and overseas keys are not enforced by the Databricks engine, they can still serve as a useful indicator of intended data relationships, aiming to ensure data integrity is maintained accurately. Databricks allows for the implementation of primary key constraints upstream, as part of the ingestion process. For further information on enforced constraints, please refer to our supplementary documentation. Databricks additionally helps enforced NOT NULL and CHECK Constraints: see below for additional information.
Accomplice Ecosystem
Tools and solutions comparable to the latest versions of Tableau and Power BI can seamlessly integrate and leverage your primary and foreign key relationships from Databricks through JDBC and ODBC connectors.
View the constraints
Methods for viewing the first key and overseas key constraints are described on the table. You can simply execute SQL queries to retrieve and manipulate constraint data directly. DESCRIBE TABLE EXTENDED command:
... (omitting different outputs) # Constraints The catalog explorer is an intuitive tool that enables users to visualize and navigate the structure of a database. By providing a graphical representation of the tables, relationships, and data entities, the catalog explorer simplifies complex database queries and facilitates efficient data manipulation.
The entity-relationship diagram (ERD) is a visual representation of the relationships between different data entities within a database. It illustrates the interactions between various tables, including one-to-one, one-to-many, many-to-many, and self-referential relationships. This graphical model serves as a blueprint for designing and optimizing databases, ensuring data consistency and integrity.
By combining the strengths of both tools, organizations can streamline their database management processes, improve data quality, and enhance overall business efficiency.
You may as well view the constraints data via a dashboard.
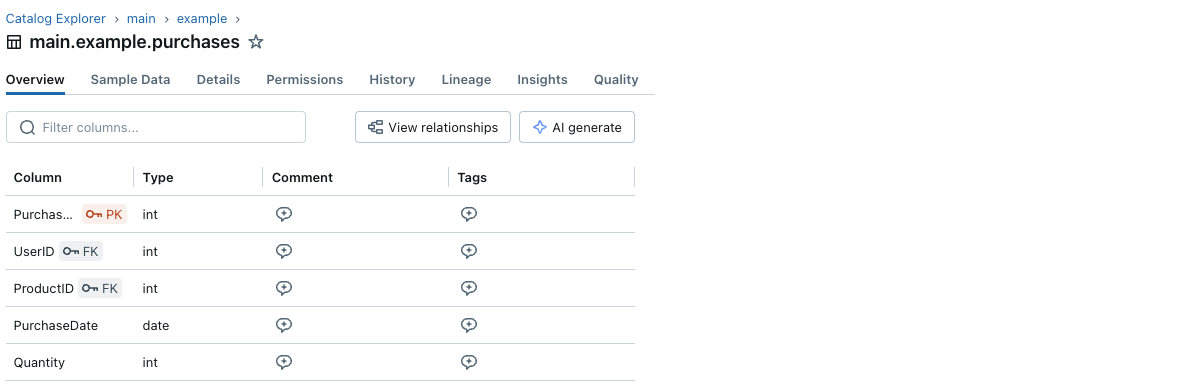
Every primary key and foreign key column boasts a discreet key icon situated adjacent to its label.
You can visualise the primary and foreign key data and their relationships between tables using Catalog Explorer. The furniture that holds my daily tasks stands sturdy beneath me. purchases referencing two tables, customers and merchandise:

INFORMATION SCHEMA
The following tables also provide constraint information:
Releying on data analytics and AI-driven insights allows for seamless optimization of processes, thereby streamlining operations and enhancing overall efficiency?
If the first key constraint is indeed legitimate – for instance, resulting from a well-designed knowledge pipeline or ETL job that enforces this rule – then you can leverage optimizations based largely on the constraint by specifying it with the RELY option, such as:
By leveraging the RELY possibility, Databricks can optimize queries depending on the constraints’ validity, ensuring the integrity of the information remains intact as guaranteed. When a constraint is labeled as RELY and the data does not conform to that constraint, your queries may produce inaccurate results because the query optimizer will rely on the constraint’s accuracy?
When unspecified, the default reliance (RELY) possibility for a constraint defaults to NORELY; in this instance, constraints can still serve as useful information or statistical tools, but queries will not rely on their existence to function correctly.
The reliability of RELY and its optimization options are currently available for primary keys, with international key support expected to follow shortly.
You can modify a desk’s primary key to toggle between RELY and NOT RELY by executing an ALTER TABLE statement.
Streamline your query performance by judiciously removing unnecessary aggregations.
We will simplify our RELY primary key constraints by eliminating unnecessary aggregations. As an instance, when employing a specific operation on a desktop via the primary keyboard function relying on.
We will eliminate the unnecessary DISTINCT operation.
The revised text reads: As it stands, the query’s accuracy relies heavily on the integrity of the RELY main key constraint; specifically, the absence of duplicate buyer IDs within the buyer desk is crucial to prevent incorrect duplicate outcomes. When setting the RELY possibility, you assume accountability for verifying the constraint’s validity.
If the first secret’s NORELY (default) is set to “NO”, then the optimizer won’t remove the DISTINCT operation by default. However, running the query repeatedly may result in slower performance, as it still produces accurate results despite duplicate values. If the initial query relies on a single distinct value, Databricks can potentially eliminate the need for the DISTINCT operation, resulting in a performance boost of approximately two-fold for this specific example.
Effortlessly accelerate query performance by strategically pruning unnecessary joins.
We will optimize RELY main keys by removing unnecessary joins. When a query joins a table not mentioned elsewhere except in the WHERE clause, the optimizer can conclude that the WHERE clause is unnecessary and remove it from the query plan.
To illustrate this point effectively, let’s consider the scenario where joining two tables becomes necessary to answer a specific query. store_sales and buyerThe agent carefully entered the initial details on the customer’s file. PRIMARY KEY (c_customer_sk) RELY.
Without the first key, every row would have been a unique identifier. store_sales will likely align with several lines in buyerWhat’s the correct sum we’re looking for? Despite being seated at their desk, buyer are joined on their main key, which enables us to retrieve a single combined row for each matching pair of rows in both datasets. store_sales.
The column. ss_quantity from the actual fact desk store_sales. Because of this fact, the question optimizer seamlessly eliminates the irrelevant portion of the inquiry, reframing it as:
The speed at which this optimisation process unfolds is significantly accelerated when we bypass the entire ‘be’ part, yielding a marked improvement in performance. When tables are numerous and potentially redundant, the benefits will be even more substantial.
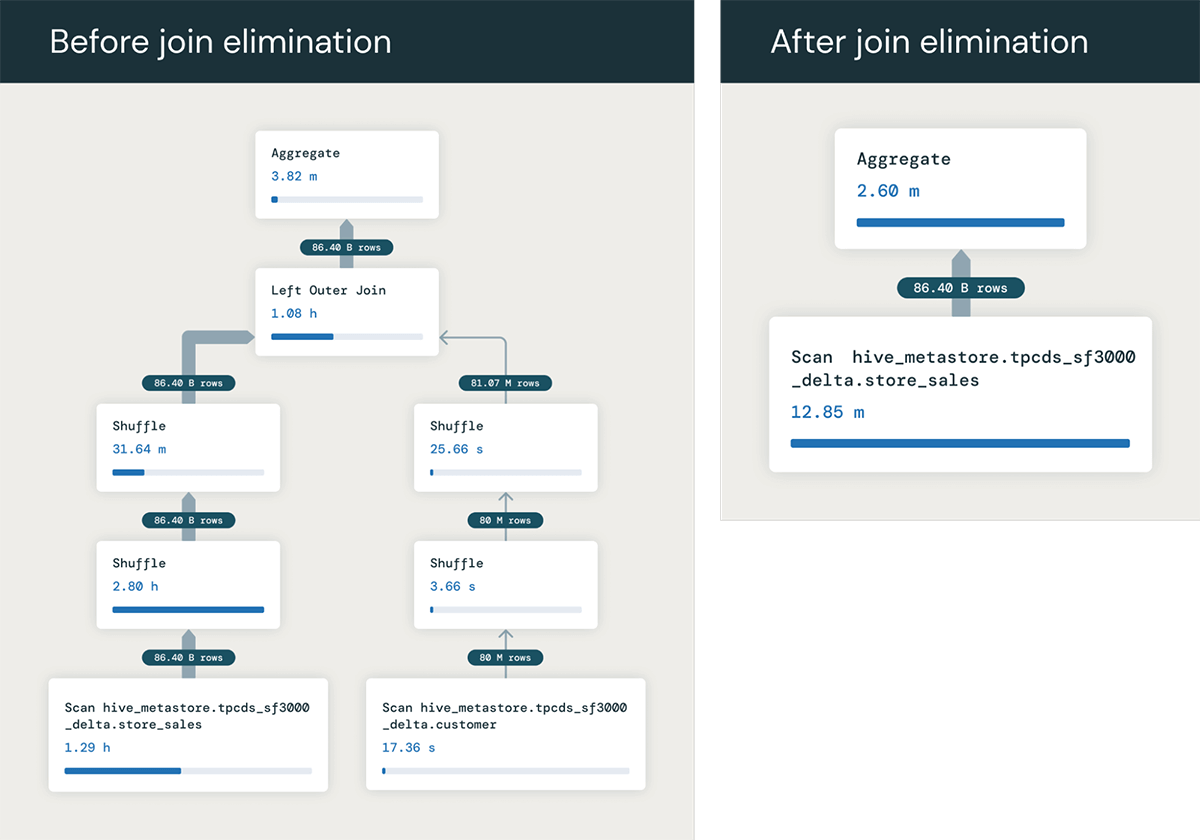
What’s the motivation behind someone’s actions, you wonder? Many people are often unaware of just how prevalent this phenomenon actually is. A common driving force is the need for customers to combine views from multiple tables into a single comprehensive dataset, effectively merging various fact and dimension tables. Their queries operate on specific views that commonly utilize columns from only a select few tables, rather than all – allowing the optimizer to effectively eliminate unnecessary joins against the tables that aren’t required for each query. This query can also be prevalent across numerous Enterprise Intelligence (BI) tools, where they often produce queries joining multiple tables within a schema, even when the query only utilizes columns from a subset of those tables?
Conclusion
Since its public debut as a preview, more than 2,600 Databricks customers have leveraged the power of primary keys and overseas constraints to transform their data management processes. With great enthusiasm, we’re proud to declare that this feature is now widely accessible, representing a significant milestone in our ongoing commitment to advancing data governance and integrity within Databricks.
Databricks leverages key constraints with the RELY option, optimizing queries by pruning unnecessary aggregates and joins, thereby significantly enhancing query speed.