
 refine their linguistic capabilities, they autonomously construct novel conceptions of reality.")
{kind=link}
The aroma of a rain-soaked campsite wafts through the air, carrying with it the damp earthy scent of fallen leaves, the sweet tang of wet grass, and the faint hint of campfire smoke lingering in the atmosphere. The aroma of impending precipitation hung heavy in the atmosphere, its subtle yet potent essence tantalizing the senses as the skies prepared to unleash their bounty. As the air vibrated with electric tension, the sweet, loamy fragrance of dampened earth mingled with the crisp, clean scent of ozone, creating an olfactory experience that was at once both familiar and novel. One plausible explanation for this occurrence may stem from the large language model’s propensity to mirror existing textual patterns within its vast training dataset, rather than exhibiting a genuine comprehension of rain or smell.
Doesn’t the scarcity of eyes suggest that language trends cannot possibly grasp the notion that a lion is inherently larger than a domestic cat? Scholars in philosophy and science have long debated whether the ability to impose meaning on language is a hallmark of human intelligence, and pondered the pivotal factors that enable us to do so.
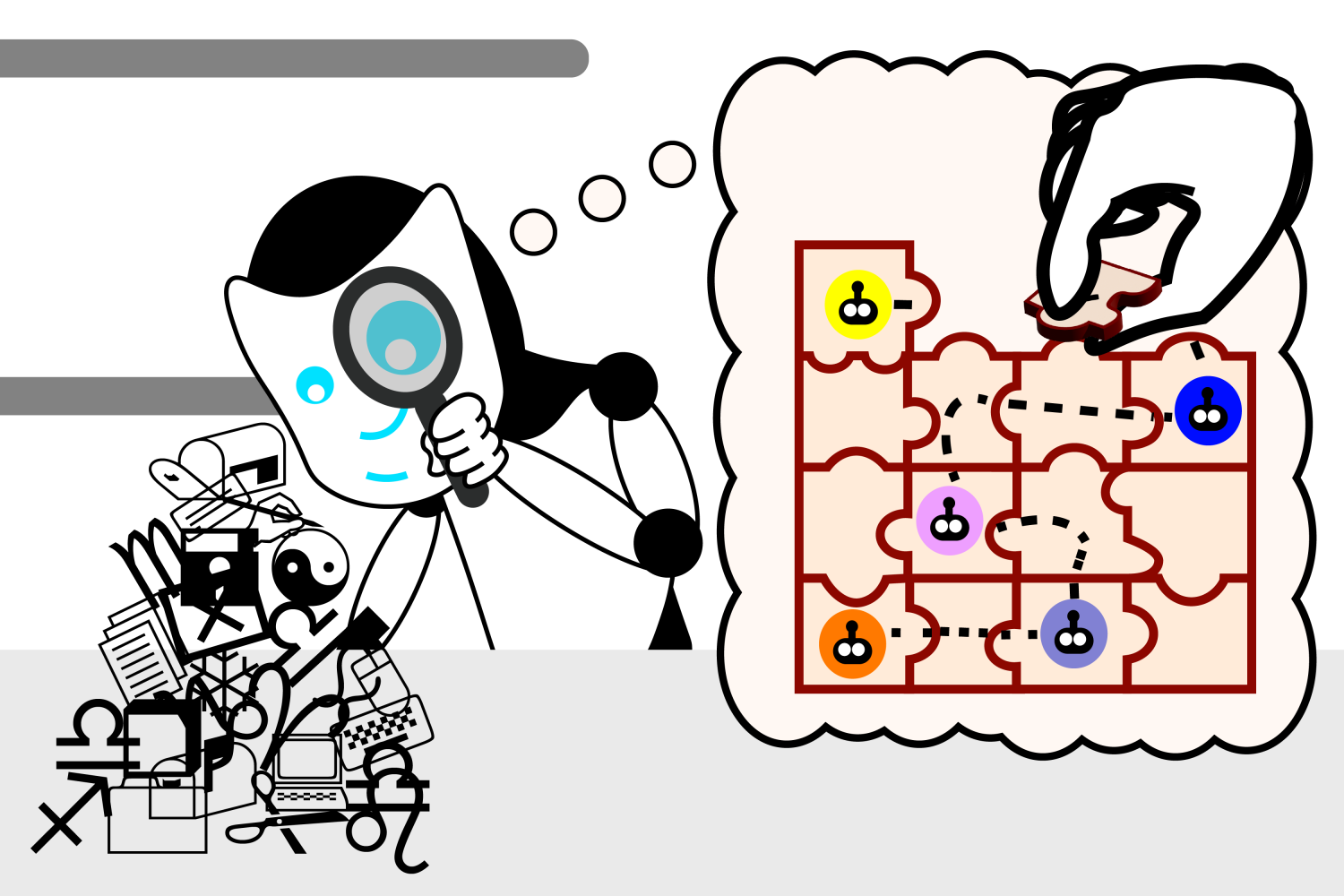
Researchers at MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) have made a groundbreaking discovery, finding that language models may develop their own comprehension of reality in an effort to improve their ability to generate text, uncovering surprising implications for the future of artificial intelligence. The workforce initially crafted a collection of compact Karel puzzles, guiding participants to navigate a robotic through a simulated environment using predefined directional commands. They subsequently trained an LLM on the available options, without illustrating how these options actually functioned. By employing a machine learning technique called “probing,” researchers examined the inner workings of the model’s thought process as it produces novel ideas.
Through extensive training on more than one million diverse puzzles, researchers observed that the AI model autonomously formulated a unique understanding of the simulated environment, despite never directly encountering or being explicitly taught about it during its learning process. The discovery raises questions about the types of data required to study linguistic phenomena, and whether large language models (LLMs) can potentially comprehend language at a more profound level in the future.
Initially, the language model produced randomly generated instructions that were ineffective. According to MIT electrical engineering and computer science (EECS) PhD student and CSAIL affiliate Charles Jin, the language model generated correct directions at a rate of 92.4% by the time they completed coaching, he says as the lead author of a study. As we reflected on this milestone, we realized that if our language model could achieve such a high level of accuracy at a specific stage, we should be able to rely on its ability to comprehend linguistic nuances across various languages? Our initial exploration of LLMs revealed potential for perceiving textual content, and it’s now clear they can accomplish much more than merely assembling sentences haphazardly.
As the probe allowed Jin to bear witness to this transformation up close. The model’s role was to infer the intended meaning of the instructions from the Large Language Model’s perspective, revealing that it had created a personalized internal simulation of the robotic strikes in response to each directive. As the mannequin’s capacity to unravel puzzles became increasingly sophisticated, its conceptions of the task also became more accurate, suggesting that the large language model (LLM) had begun to grasp the instructions. Before long, the model consistently arranged items correctly to form functional instructions.
As Jin observes, the Large Language Model’s grasp of linguistics progresses in distinct stages, mirroring the gradual process by which infants acquire spoken communication skills. At first blush, it sounds like a toddler’s incoherent chatter: redundant and mostly incomprehensible. As the language model acquires syntax, it grasps the fundamental principles of linguistic communication. This allows it to produce directions that seemingly resemble real possibilities, yet still do not function effectively.
While the LLM’s directions initially seem straightforward, they progressively become more sophisticated and nuanced. As the mannequin attains proficiency, it seamlessly generates instructions that accurately incorporate the desired specifications, much like a child learning to form grammatically correct sentences.
While designed to merely “interface with” the language model’s thought processes, as Jin describes it, there existed a remote possibility that the probe also performed some cognitive processing on behalf of the model. To guarantee their mannequin’s autonomous understanding of instructions, the researchers aimed to decouple the probe’s influence from the robotic’s actions, thereby precluding the probe from inferring the robot’s behavior through its comprehension of syntactical structures.
“Consider that you might have a repository of data containing the LM’s thought process,” Jin proposes. The probe functions as a digital forensics expert: You provide it with a dataset and instruct it to analyze the robotic strikes, then ask it to identify the robotic’s actions within the data. Later, the probe informs you that it has gained insight into the robotic’s activities within the dataset. What if instead, the heap of knowledge genuinely merely embodies the raw guidelines, and the investigator has identified a savvy technique to distill the guidelines and follow them accordingly? The language model has yet to decipher the underlying implications of the instructions.
Researchers sought to clarify their roles by reversing the instructions in a novel experiment. On the disorienting “Bizarro World” that Jin refers to, traditional guidelines such as “up” were redefined as “down,” causing the robotic system to traverse its grid in a reversed manner.
“If the probe translates robotic positions based on given directions, it should also be able to interpret those directions in alignment with unconventional meanings,” says Jin. As the probe successfully uncovers the encoded representations of distinct robotic behaviors within the linguistic model’s cognitive process, it must grapple with extracting the aberrant robotic actions from their original mental framework.
The brand-new probe encountered unforeseen issues, struggling to decipher a language model whose instructions held fundamentally different meanings. The novel semantic nuances were seamlessly integrated into the language model’s framework, thereby showcasing the large language model’s capacity to grasp instructions autonomously, unfettered by the distinct probing classifier’s influence.
Can deep learning models’ impressive abilities be attributed solely to statistical patterns emerging at scale, or do these massive language models truly develop a profound comprehension of the concepts they’re intended to process? According to Martin Rinard, a professor at MIT’s Department of Electrical Engineering and Computer Science (EECS) and a member of the Computer Science and Artificial Laboratory (CSAIL), the Large Language Model (LLM) develops an internal representation of simulated reality, despite never having been trained to do so.
This experiment further substantiates the workforce’s assessment that linguistic patterns can foster a more profound comprehension of language. Despite the significance of their findings, Jin’s study is not without its limitations; for instance, they relied on a relatively straightforward programming language and a modestly sized model to derive their conclusions. Within an environment, they will strive to utilize an additional ordinary setting. While Jin’s latest findings do not explicitly accelerate the training of language models, he suggests that future research can build upon his insights to improve the process.
“The question arises: Is the LLM levering its internal model of reality to create and manipulate that reality as it tackles the robotic navigation challenge?” While our results align with the LLM’s predictions based on this model, our experiments should not be designed to answer this very question.
“There is ongoing debate about whether large language models are truly ‘understanding’ language or if their success can be attributed to methods and heuristics derived from processing vast amounts of textual data,” notes Ellie Pavlick, assistant professor of computer science and linguistics at Brown University, who was not involved in the research. These fundamental queries delve into the very essence of how we design AI and what inherent capabilities or limitations we anticipate from our technology. While exploring the potential of computer code as research material, the authors effectively leverage the understanding that programming languages, akin to natural languages, possess both syntax and semantics; however, unlike their natural counterparts, the semantic aspects of code can be directly observed and controlled for experimental purposes. While the experimental design is indeed refined, their research holds promise, implying that large language models might actually grasp a more profound comprehension of linguistic nuances.
The research of Jin and Rinard received partial funding from the United States government in the form of grants. The Defense Advanced Research Projects Agency.