

{kind=link}
Databricks is likely one of the main platforms for constructing and executing machine studying notebooks at scale. It combines Apache Spark capabilities with a notebook-preferring interface, experiment monitoring, and built-in knowledge tooling. Right here on this article, I’ll information you thru the method of internet hosting your ML pocket book in Databricks step-by-step. Databricks gives a number of plans, however for this text, I’ll be utilizing the Free Version, as it’s appropriate for studying, testing, and small tasks.
Understanding Databricks Plans
Earlier than we get began, let’s simply rapidly undergo all of the Databricks plans which can be accessible.
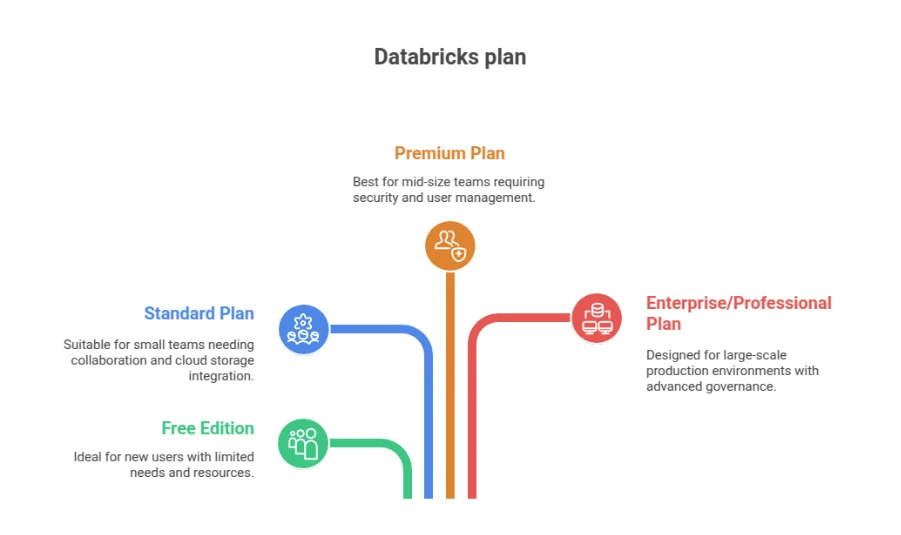
1. Free Version
The Free Version (beforehand Group Version) is the best approach to start.
You may enroll at databricks.com/be taught/free-edition.
It has:
- A single-user workspace
- Entry to a small compute cluster
- Help for Python, SQL, and Scala
- MLflow integration for experiment monitoring
It’s completely free and is in a hosted surroundings. The most important drawbacks are that clusters timeout after an idle time, sources are restricted, and a few enterprise capabilities are turned off. Nonetheless, it’s excellent for brand spanking new customers or customers attempting Databricks for the primary time.
2. Commonplace Plan
The Commonplace plan is good for small groups.
It supplies extra workspace collaboration, bigger compute clusters, and integration with your individual cloud storage (akin to AWS or Azure Knowledge Lake).
This stage means that you can hook up with your knowledge warehouse and manually scale up your compute when required.
3. Premium Plan
The Premium plan introduces safety features, role-based entry management (RBAC), and compliance.
It’s typical of mid-size groups that require person administration, audit logging, and integration with enterprise id programs.
4. Enterprise / Skilled Plan
The Enterprise or Skilled plan (relying in your cloud supplier) consists of all that the Premium plan has, plus extra superior governance capabilities akin to Unity Catalog, Delta Dwell Tables, jobs scheduled mechanically, and autoscaling.
That is usually utilized in manufacturing environments with a number of groups working workloads at scale. For this tutorial, I’ll be utilizing the Databricks Free Version.
Fingers-on
You need to use it to check out Databricks free of charge and see the way it works.
Right here’s how one can comply with alongside.
Step 1: Signal Up for Databricks Free Version
- Join together with your e mail, Google, or Microsoft account.
- After you sign up, Databricks will mechanically create a workspace for you.
The dashboard that you’re taking a look at is your command heart. You may management notebooks, clusters, and knowledge all from right here.
No native set up is required.
Step 2: Create a Compute Cluster
Databricks executes code in opposition to a cluster, a managed compute surroundings. You require one to run your pocket book.
- Within the sidebar, navigate to Compute.
- Click on Create Compute (or Create Cluster).
- Title your cluster.
- Select the default runtime (ideally Databricks Runtime for Machine Studying).
- Click on Create and watch for it to change into Working.
When the standing is Working, you’re able to mount your pocket book.
Within the Free Version, clusters can mechanically shut down after inactivity. You may restart them everytime you need.
Step 3: Import or Create a Pocket book
You need to use your individual ML pocket book or create a brand new one from scratch.
To import a pocket book:
- Go to Workspace.
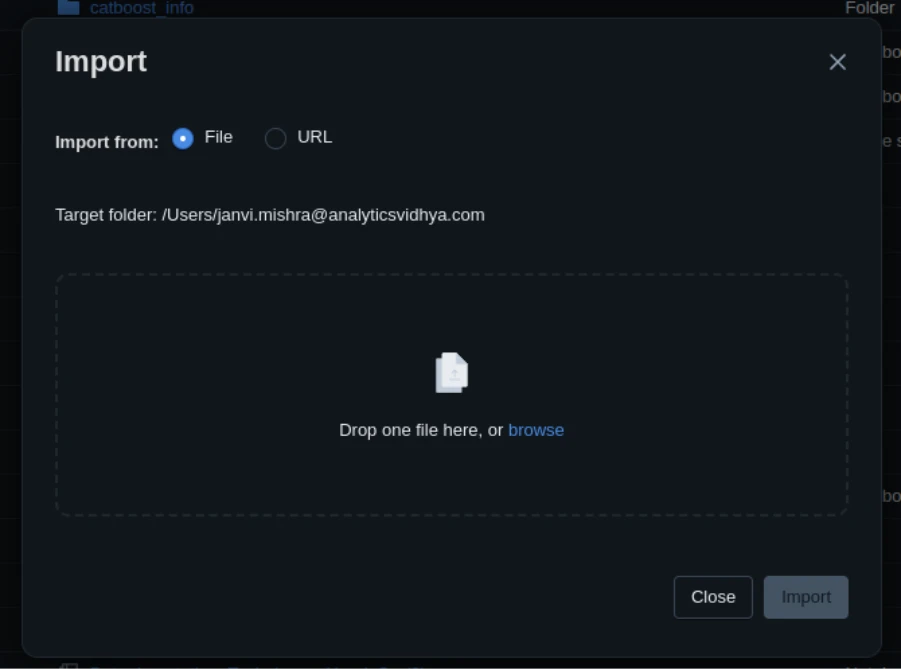
- Choose the dropdown beside your folder → Import → File.
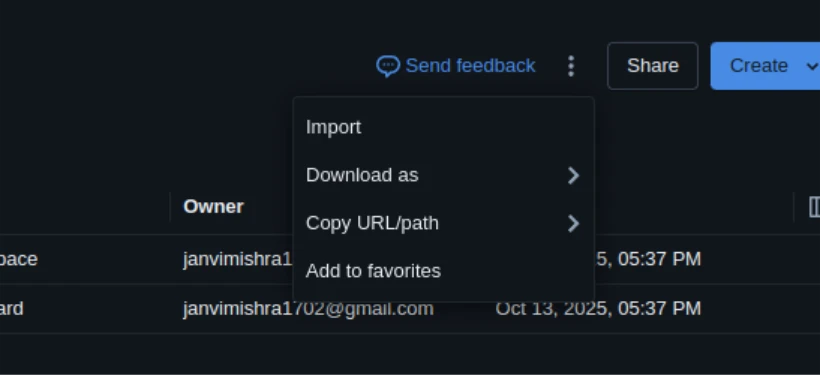
- Add your .ipynb or .py file.
To create a brand new one:
- Click on on Create → Pocket book.
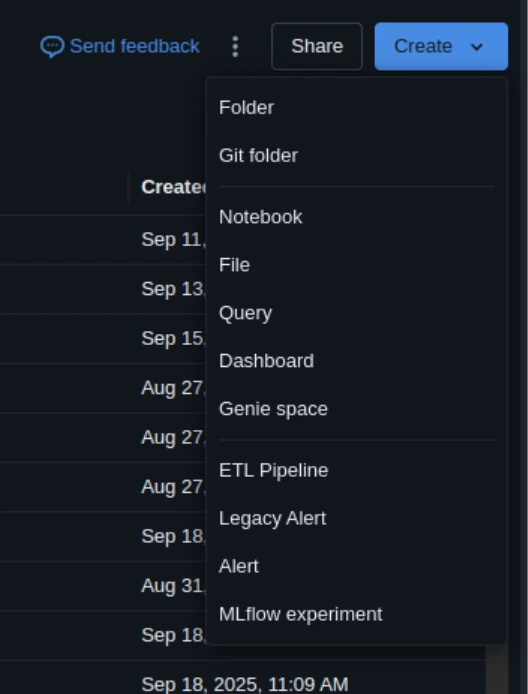
After creating, bind the pocket book to your operating cluster (seek for the dropdown on the prime).
Step 4: Set up Dependencies
In case your pocket book depends upon libraries akin to scikit-learn, pandas, or xgboost, set up them throughout the pocket book.
Use:
%pip set up scikit-learn pandas xgboost matplotlib 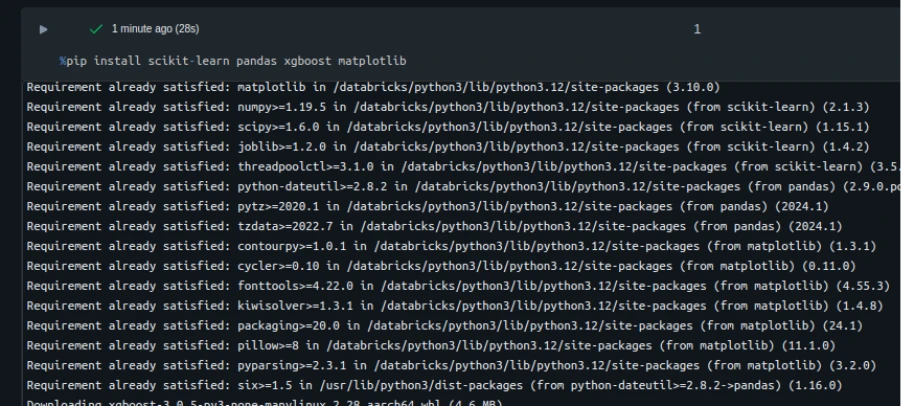
Databricks may restart the surroundings after the set up; that’s okay.
Word: You could have to restart the kernel utilizing %restart_python or dbutils.library.restartPython() to make use of up to date packages.
You may set up from a necessities.txt file too:
%pip set up -r necessities.txt To confirm the setup:
import sklearn, sys print(sys.model) print(sklearn.__version__) Step 5: Run the Pocket book
Now you can execute your code.
Every cell runs on the Databricks cluster.
- Press Shift + Enter to run a single cell.
- Press Run All to run the entire pocket book.
You’re going to get the outputs equally to these in Jupyter.
In case your pocket book has massive knowledge operations, Databricks processes them by way of Spark mechanically, even within the free plan.
You may monitor useful resource utilization and job progress within the Spark UI (accessible beneath the cluster particulars).
Step 6: Coding in Databricks
Now that your cluster and surroundings are arrange, let’s be taught how one can write and run an ML pocket book in Databricks.
We are going to undergo a full instance, the NPS Regression Tutorial, which makes use of regression modeling to foretell buyer satisfaction (NPS rating).
1: Load and Examine Knowledge
Import your CSV file into your workspace and cargo it with pandas:
from pathlib import Path import pandas as pd DATA_PATH = Path("/Workspace/Customers/[email protected]/nps_data_with_missing.csv") df = pd.read_csv(DATA_PATH) df.head()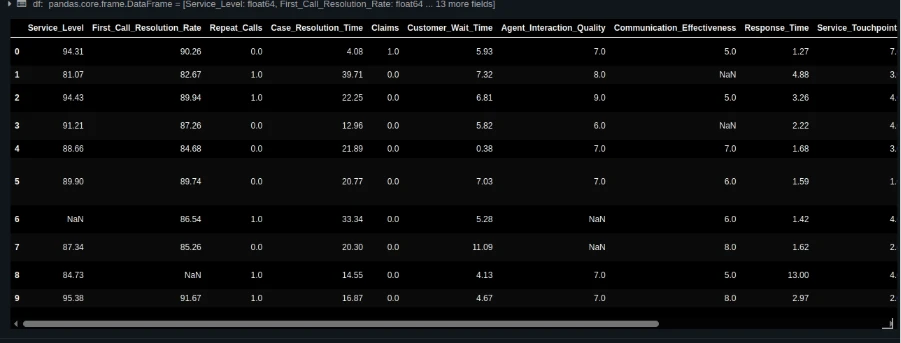
Examine the info:
df.data() 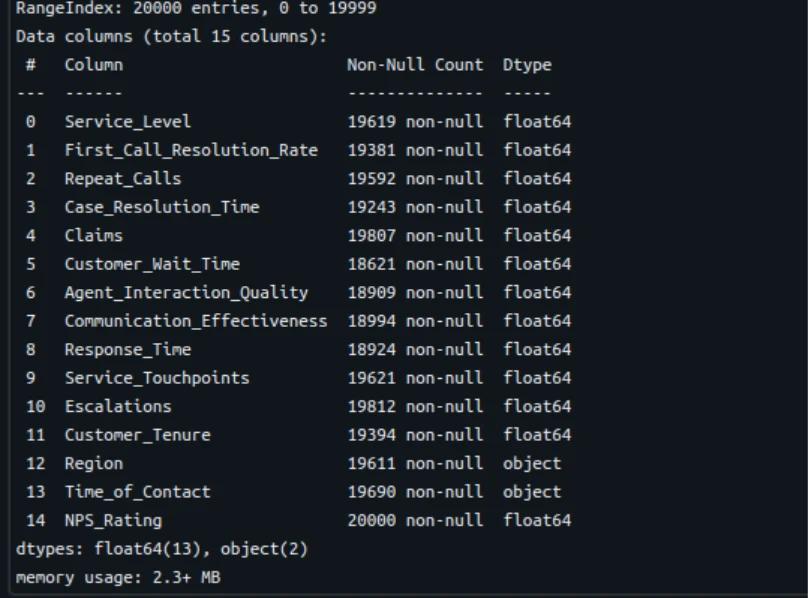
df.describe().T 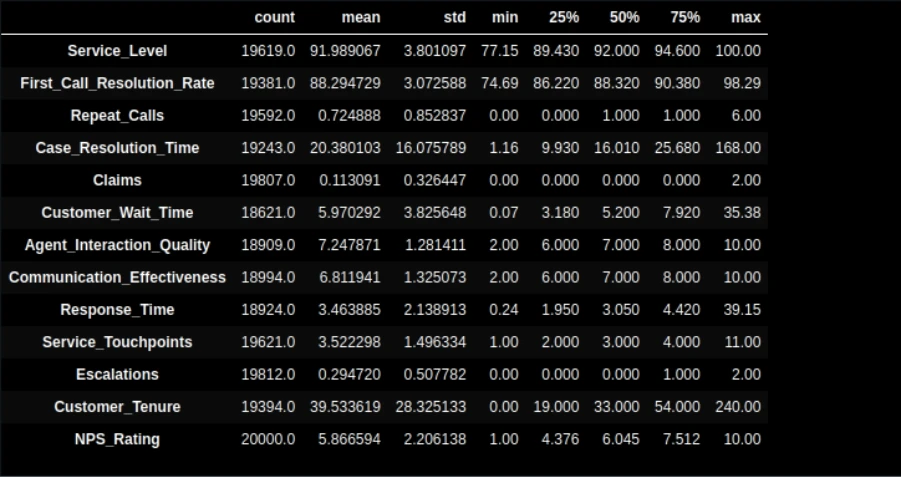
2: Prepare/Take a look at Break up
from sklearn.model_selection import train_test_split TARGET = "NPS_Rating" train_df, test_df = train_test_split(df, test_size=0.2, random_state=42) train_df.form, test_df.form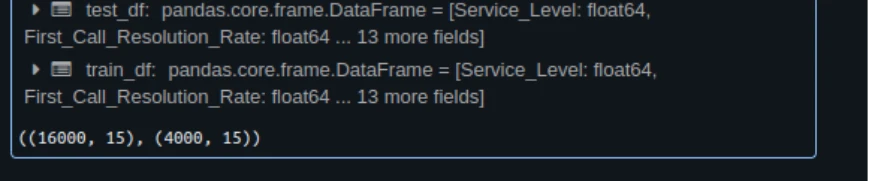
3: Fast EDA
import matplotlib.pyplot as plt import seaborn as sns sns.histplot(train_df["NPS_Rating"], bins=10, kde=True) plt.title("Distribution of NPS Scores") plt.present() 4: Knowledge Preparation with Pipelines
from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer from sklearn.impute import KNNImputer, SimpleImputer from sklearn.preprocessing import StandardScaler, OneHotEncoder num_cols = train_df.select_dtypes("quantity").columns.drop("NPS_Rating").tolist() cat_cols = train_df.select_dtypes(embrace=["object", "category"]).columns.tolist() numeric_pipeline = Pipeline([ ("imputer", KNNImputer(n_neighbors=5)), ("scaler", StandardScaler()) ]) categorical_pipeline = Pipeline([ ("imputer", SimpleImputer(strategy="constant", fill_value="Unknown")), ("ohe", OneHotEncoder(handle_unknown="ignore", sparse_output=False)) ]) preprocess = ColumnTransformer([ ("num", numeric_pipeline, num_cols), ("cat", categorical_pipeline, cat_cols) ]) 5: Prepare the Mannequin
from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score, mean_squared_error lin_pipeline = Pipeline([ ("preprocess", preprocess), ("model", LinearRegression()) ]) lin_pipeline.match(train_df.drop(columns=["NPS_Rating"]), train_df["NPS_Rating"]) 6: Consider Mannequin Efficiency
y_pred = lin_pipeline.predict(test_df.drop(columns=["NPS_Rating"])) r2 = r2_score(test_df["NPS_Rating"], y_pred) rmse = mean_squared_error(test_df["NPS_Rating"], y_pred, squared=False) print(f"Take a look at R2: {r2:.4f}") print(f"Take a look at RMSE: {rmse:.4f}") 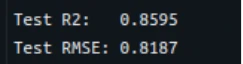
7: Visualize Predictions
plt.scatter(test_df["NPS_Rating"], y_pred, alpha=0.7) plt.xlabel("Precise NPS") plt.ylabel("Predicted NPS") plt.title("Predicted vs Precise NPS Scores") plt.present() 8: Characteristic Significance
ohe = lin_pipeline.named_steps["preprocess"].named_transformers_["cat"].named_steps["ohe"] feature_names = num_cols + ohe.get_feature_names_out(cat_cols).tolist() coefs = lin_pipeline.named_steps["model"].coef_.ravel() import pandas as pd imp_df = pd.DataFrame({"characteristic": feature_names, "coefficient": coefs}).sort_values("coefficient", ascending=False) imp_df.head(10) 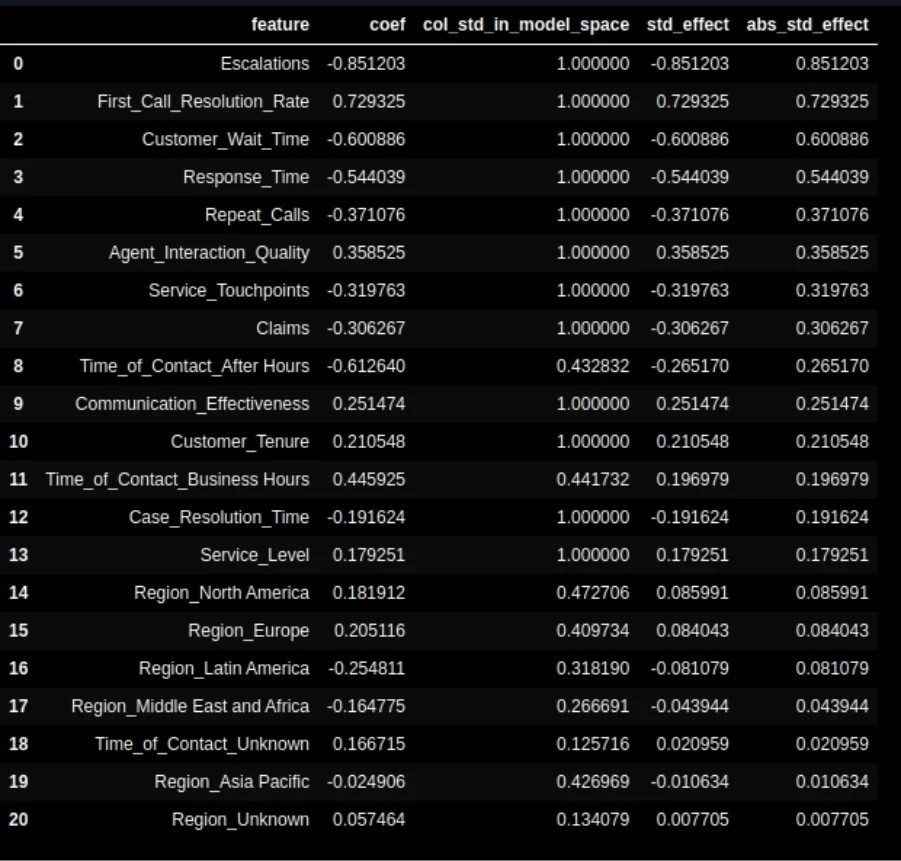
Visualize:
prime = imp_df.head(15) plt.barh(prime["feature"][::-1], prime["coefficient"][::-1]) plt.xlabel("Coefficient") plt.title("Prime Options Influencing NPS") plt.tight_layout() plt.present() 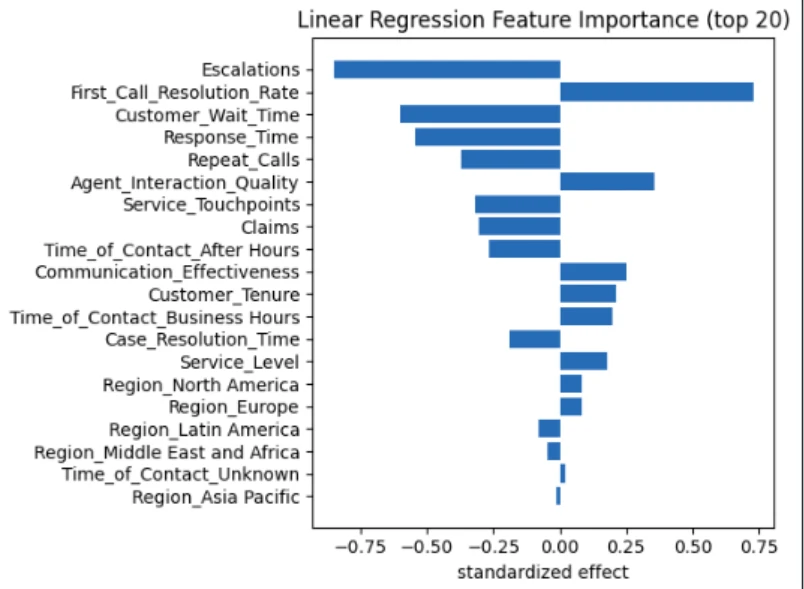
Step 7: Save and Share Your Work
Databricks notebooks mechanically save to your workspace.
You may export them to share or save them for a backup.
- Navigate to File → Click on on the three dots after which click on on Obtain
- Choose .ipynb, .dbc, or .html
You may as well hyperlink your GitHub repository beneath Repos for model management.
Issues to Know About Free Version
Free Version is fantastic, however don’t neglect the next:
- Clusters shut down after an idle time (roughly 2 hours).
- Storage capability is restricted.
- Sure enterprise capabilities are unavailable (akin to Delta Dwell Tables and job scheduling).
- It’s not for manufacturing workloads.
Nonetheless, it’s an ideal surroundings to be taught ML, strive Spark, and check fashions.
Conclusion
Databricks makes cloud execution of ML notebooks simple. It requires no native set up or infrastructure. You may start with the Free Version, develop and check your fashions, and improve to a paid plan later in the event you require extra energy or collaboration options. Whether or not you’re a pupil, knowledge scientist, or ML engineer, Databricks supplies a seamless journey from prototype to manufacturing.
You probably have not used it earlier than, go to this web site and start operating your individual ML notebooks at this time.
Steadily Requested Questions
A. Join the Databricks Free Version at databricks.com/be taught/free-edition. It offers you a single-user workspace, a small compute cluster, and built-in MLflow help.
A. No. The Free Version is totally browser-based. You may create clusters, import notebooks, and run ML code instantly on-line.
A. Use %pip set up library_name inside a pocket book cell. You may as well set up from a necessities.txt file utilizing %pip set up -r necessities.txt.
Hello, I’m Janvi, a passionate knowledge science fanatic presently working at Analytics Vidhya. My journey into the world of knowledge started with a deep curiosity about how we will extract significant insights from complicated datasets.
Login to proceed studying and revel in expert-curated content material.