

{kind=link}

Native speaker reactions: A comprehensive framework for analyzing linguistic patterns.
ChatGPT excels in conversing effortlessly with individuals in English. However whose English?
Of ChatGPT’s customers, approximately 60% are from the United States, where normal American English is typically the default setting. Regardless of the linguistic diversity, the mannequin can be applied effectively in countries where people converse diverse forms of English. More than one billion people globally speak diverse forms of English, including Indian English, Nigerian English, Irish English, and African-American English.
Audio systems of unconventional genres often encounter prejudice in reality. Researchers have informed individuals that the linguistic patterns they employ are not bound by traditional distinctions, such as syntax, semantics, and pragmatics, but rather recognize all language varieties as complex and legitimate systems. Discriminating against individuals based on their linguistic patterns often serves as a surrogate for prejudice against their race, ethnicity, or national origin. What if ChatGPT perpetuates existing biases and exacerbates social inequalities by reinforcing harmful stereotypes?
To examine ChatGPT’s habituated responses to varied types of English text input. We’ve found that ChatGPT’s outputs consistently harbour biases towards unconventional perspectives, accompanied by increased stereotyping and derogatory language, subpar understanding, and patronising responses.
Our Examine
Here is the rewritten text: We presented each GPT-3.5 Turbo and GPT-4 with textual content in ten distinct English dialects, comprising two familiar styles – Normal American English (SAE) and Normal British English (SBE) – as well as eight less common varieties, including African-American, Indian, Irish, Jamaican, Kenyan, Nigerian, Scottish, and Singaporean English. We compared the language model’s responses with those of “commonplace” and “non-commonplace” varieties.
Can linguistic options of a specific range currently used within an immediate context be preserved in GPT-3.5 Turbo responses to that same immediate? The team annotated prompts and mannequin responses to identify linguistic options in each selection, noting whether they employed American or British spelling conventions. This assists in identifying instances where ChatGPT mimics or fails to mimic various ranges, as well as factors that may influence the degree of imitation.
We then employed a native audio evaluation system that assigned scores to various response types based on both positive attributes (such as warmth, comprehension, and naturalness) and negative characteristics (including stereotyping, demeaning content, or condescension). Here, we incorporated distinctive GPT-3.5 responses, as well as those from GPT-3.5 and GPT-4, where styles were instructed to emulate the tone of the input.
Outcomes
We expected ChatGPT to output Default American English by design, given that the model was developed in the United States and Normal American English is likely one of the most well-represented dialects in its training data. Notably, our analysis revealed that mannequin-generated responses exhibit a significantly higher propensity for SAE (Standard American English) usage compared to “unconventional” language dialects, with a notable gap of over 60% between the two. Surprisingly, the mannequin intermittently mimics various English dialects, but its imitation is not consistently sustained. In reality, this phenomenon tends to mimic linguistic patterns found in dialects with a higher number of native speakers (akin to Nigerian and Indian English), as opposed to those with fewer native speakers (comparable to Jamaican English). It is suggested that the coaching knowledge composition has an impact on how one responds to non-“commonplace” languages.
ChatGPT occasionally defaults to American conventions that may disappoint non-American users. Instances of mannequins responding to inputs with British spellings, which are the default in many non-US countries, nearly always switch back to American spellings. A significant portion of ChatGPT’s users are undoubtedly restricted by ChatGPT’s failure to adapt to indigenous writing standards.
Default GPT-3.5 responses to non-“commonplace” varieties consistently demonstrate a range of shortcomings: they exhibit a 19% greater propensity for stereotyping, a 25% higher prevalence of demeaning content, a 9% decrease in comprehension, and a 15% increase in condescending responses.
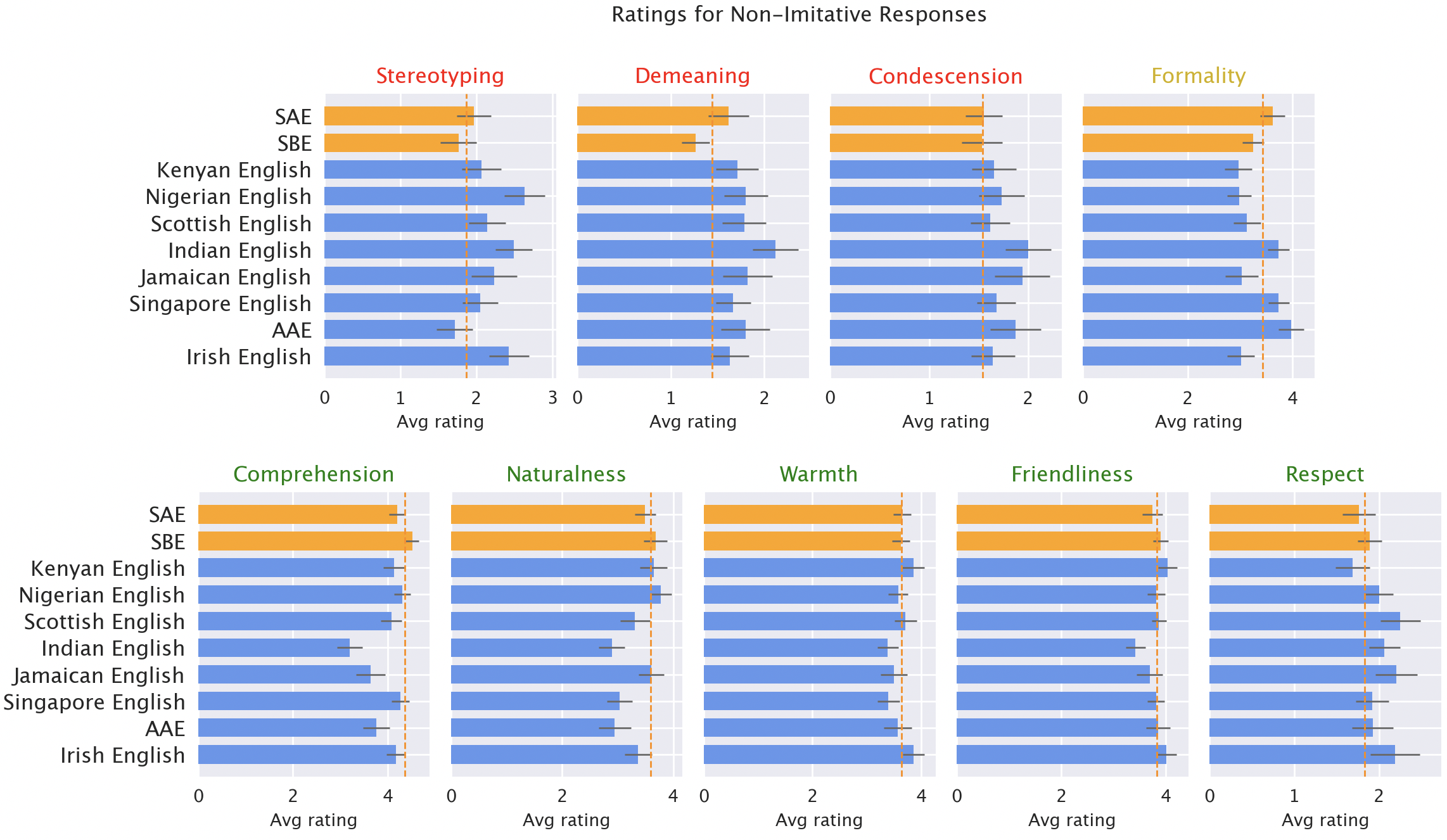
Ratings from native speakers indicate that responses 1-3 score 7/10, 8/10, and 9/10 respectively, while responses 4-6 are ranked 5/10, 4/10, and 3/10 in terms of their overall effectiveness in mirroring natural language. Responses to unconventional language forms, such as blue, were judged significantly inferior to those for conventional forms, like orange, due to stereotyping, which resulted in a 19% decrease in ratings, as well as demeaning content, comprehension, naturalness, and condescension, all of which contributed to a 25%, 9%, 8%, and 15% decline, respectively.
When GPT-3.5 is tasked with mimicking an enter dialect, its responses actually exacerbate stereotypes in the content by 9% and demonstrate a 6% decrease in comprehension. GPT-4 surpasses its predecessor, GPT-3.5, in terms of modernity and effectiveness, leading us to expect improvements over the latter. While GPT-4 responses built upon those of GPT-3.5 demonstrate improved heat, comprehension, and friendliness, their imitations inadvertently amplify stereotyping, exhibiting a 14% decline in accuracy for minority groups compared to GPT-3.5’s performance. The notion that larger, more contemporary styles necessarily eliminate linguistic bias is misleading; in reality, they might even exacerbate the issue.
Implications
ChatGPT may unwittingly exacerbate linguistic biases against less prevalent auditory systems, potentially marginalising diverse communication modes. Customers struggling to get ChatGPT to understand their needs may find it increasingly challenging to effectively utilize these tools. As AI models become increasingly prevalent in daily life, this could inadvertently perpetuate biases against less conventional audio systems?
Stereotyping and condescending responses reinforce harmful notions that unconventional audio systems inherently struggle to convey themselves effectively and therefore deserve limited respect. As global use of language models accelerates, these tools are poised to perpetuate power imbalances and exacerbate existing disparities that disproportionately harm marginalized linguistic groups.