

{kind=link}
We’re excited to share the primary fashions within the Llama 4 herd can be found right now in Azure AI Foundry and Azure Databricks.
We’re excited to share the primary fashions within the Llama 4 herd can be found right now in Azure AI Foundry and Azure Databricks, which permits folks to construct extra personalised multimodal experiences. These fashions from Meta are designed to seamlessly combine textual content and imaginative and prescient tokens right into a unified mannequin spine. This progressive strategy permits builders to leverage Llama 4 fashions in purposes that demand huge quantities of unlabeled textual content, picture, and video knowledge, setting a brand new precedent in AI improvement.
As we speak, we’re bringing Meta’s Llama 4 Scout and Maverick fashions into Azure AI Foundry as managed compute choices:
- Llama 4 Scout Fashions
- Llama-4-Scout-17B-16E
- Llama-4-Scout-17B-16E-Instruct
- Llama 4 Maverick Fashions
- Llama 4-Maverick-17B-128E-Instruct-FP8
Azure AI Foundry is designed for multi-agent use instances, enabling seamless collaboration between totally different AI brokers. This opens up new frontiers in AI purposes, from advanced problem-solving to dynamic job administration. Think about a staff of AI brokers working collectively to investigate huge datasets, generate artistic content material, and supply real-time insights throughout a number of domains. The chances are infinite.
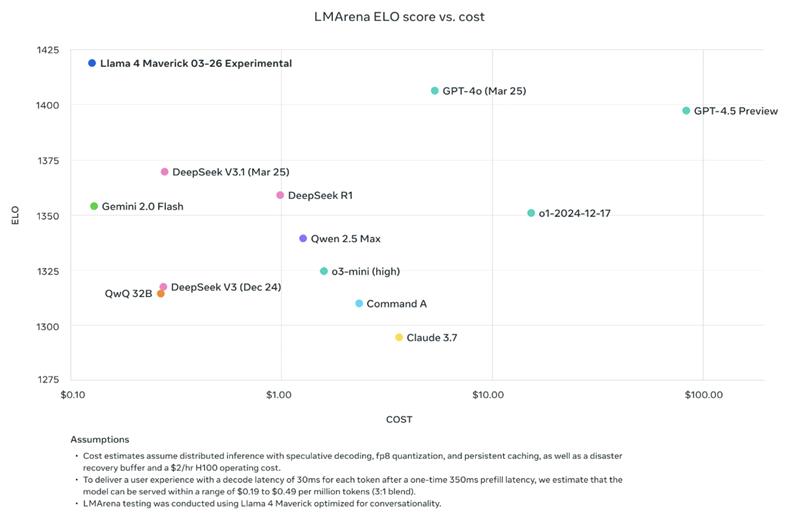
To accommodate a variety of use instances and developer wants, Llama 4 fashions are available in each smaller and bigger choices. These fashions combine mitigations at each layer of improvement, from pre-training to post-training. Tunable system-level mitigations protect builders from adversarial customers, empowering them to create useful, secure, and adaptable experiences for his or her Llama-supported purposes.
Llama 4 Scout fashions: energy and precision
We’re sharing the primary fashions within the Llama 4 herd, which can allow folks to construct extra personalised multimodal experiences. In accordance with Meta, Llama 4 Scout is among the greatest multimodal fashions in its class and is extra highly effective than Meta’s Llama 3 fashions, whereas becoming in a single H100 GPU. And Llama4 Scout will increase the supported context size from 128K in Llama 3 to an industry-leading 10 million tokens. This opens up a world of potentialities, together with multi-document summarization, parsing in depth consumer exercise for personalised duties, and reasoning over huge codebases.
Focused use instances embody summarization, personalization, and reasoning. Due to its lengthy context and environment friendly dimension, Llama 4 Scout shines in duties that require condensing or analyzing in depth info. It will probably generate summaries or stories from extraordinarily prolonged inputs, personalize its responses utilizing detailed user-specific knowledge (with out forgetting earlier particulars), and carry out advanced reasoning throughout massive data units.
For instance, Scout might analyze all paperwork in an enterprise SharePoint library to reply a selected question or learn a multi-thousand-page technical handbook to supply troubleshooting recommendation. It’s designed to be a diligent “scout” that traverses huge info and returns the highlights or solutions you want.
Llama 4 Maverick fashions: innovation at scale
As a general-purpose LLM, Llama 4 Maverick incorporates 17 billion lively parameters, 128 consultants, and 400 billion whole parameters, providing prime quality at a lower cost in comparison with Llama 3.3 70B. Maverick excels in picture and textual content understanding with assist for 12 languages, enabling the creation of refined AI purposes that bridge language limitations. Maverick is right for exact picture understanding and artistic writing, making it well-suited for common assistant and chat use instances. For builders, it affords state-of-the-art intelligence with excessive pace, optimized for greatest response high quality and tone.
Focused use instances embody optimized chat eventualities that require high-quality responses. Meta fine-tuned Llama 4 Maverick to be a wonderful conversational agent. It’s the flagship chat mannequin of the Meta Llama 4 household—consider it because the multilingual, multimodal counterpart to a ChatGPT-like assistant.
It’s significantly well-suited for interactive purposes:
- Buyer assist bots that want to grasp photos customers add.
- AI artistic companions that may talk about and generate content material in varied languages.
- Inside enterprise assistants that may assist workers by answering questions and dealing with wealthy media enter.
With Maverick, enterprises can construct high-quality AI assistants that converse naturally (and politely) with a worldwide consumer base and leverage visible context when wanted.
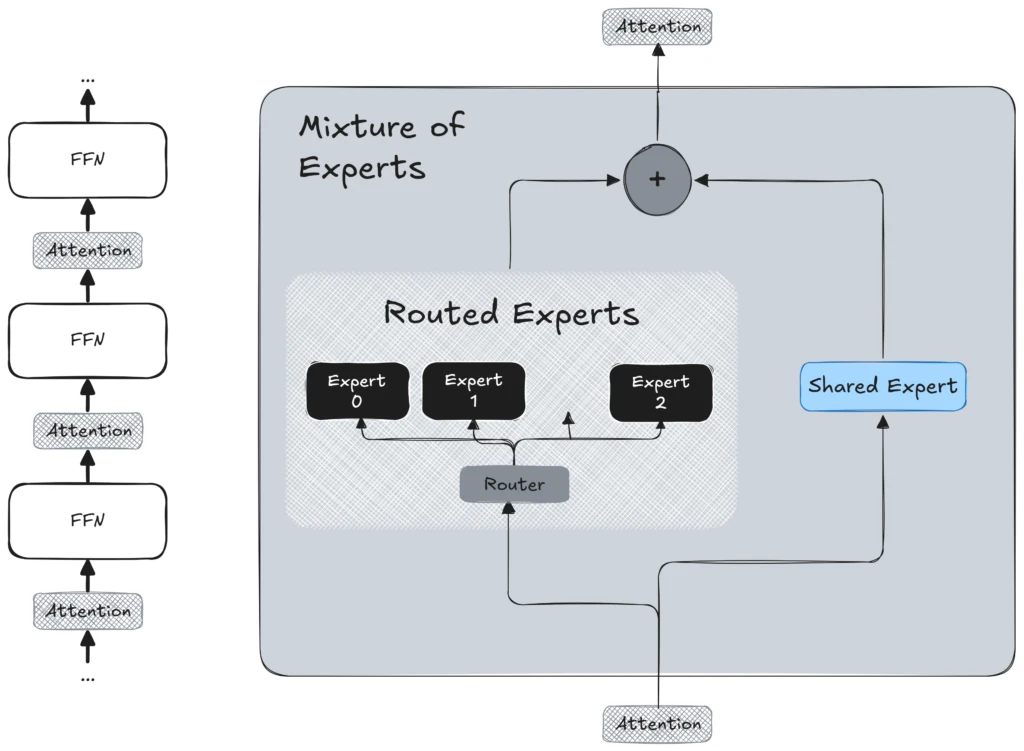
Architectural improvements in Llama 4: Multimodal early-fusion and MoE
In accordance with Meta, two key improvements set Llama 4 aside: native multimodal assist with early fusion and a sparse Combination of Specialists (MoE) design for effectivity and scale.
- Early-fusion multimodal transformer: Llama 4 makes use of an early fusion strategy, treating textual content, photos, and video frames as a single sequence of tokens from the beginning. This allows the mannequin to grasp and generate varied media collectively. It excels at duties involving a number of modalities, corresponding to analyzing paperwork with diagrams or answering questions on a video’s transcript and visuals. For enterprises, this enables AI assistants to course of full stories (textual content + graphics + video snippets) and supply built-in summaries or solutions.
- Reducing-edge Combination of Specialists (MoE) structure: To realize good efficiency with out incurring prohibitive computing bills, Llama 4 makes use of a sparse Combination of Specialists (MoE) structure. Basically, which means that the mannequin contains quite a few knowledgeable sub-models, known as “consultants,” with solely a small subset lively for any given enter token. This design not solely enhances coaching effectivity but in addition improves inference scalability. Consequently, the mannequin can deal with extra queries concurrently by distributing the computational load throughout varied consultants, enabling deployment in manufacturing environments with out necessitating massive single-instance GPUs. The MoE structure permits Llama 4 to develop its capability with out escalating prices, providing a major benefit for enterprise implementations.
Dedication to security and greatest practices
Meta constructed Llama 4 with the most effective practices outlined of their Developer Use Information: AI Protections. This consists of integrating mitigations at every layer of mannequin improvement from pre-training to post-training and tunable system-level mitigations that protect builders from adversarial assaults. And, by making these fashions accessible in Azure AI Foundry, they arrive with confirmed security and safety guardrails builders come to anticipate from Azure.
We empower builders to create useful, secure, and adaptable experiences for his or her Llama-supported purposes. Discover the Llama 4 fashions now within the Azure AI Foundry Mannequin Catalog and in Azure Databricks and begin constructing with the newest in multimodal, MoE-powered AI—backed by Meta’s analysis and Azure’s platform energy.
The provision of Meta Llama 4 on Azure AI Foundry and thru Azure Databricks affords clients unparalleled flexibility in selecting the platform that most closely fits their wants. This seamless integration permits customers to harness superior AI capabilities, enhancing their purposes with highly effective, safe, and adaptable options. We’re excited to see what you construct subsequent.