{kind=link}
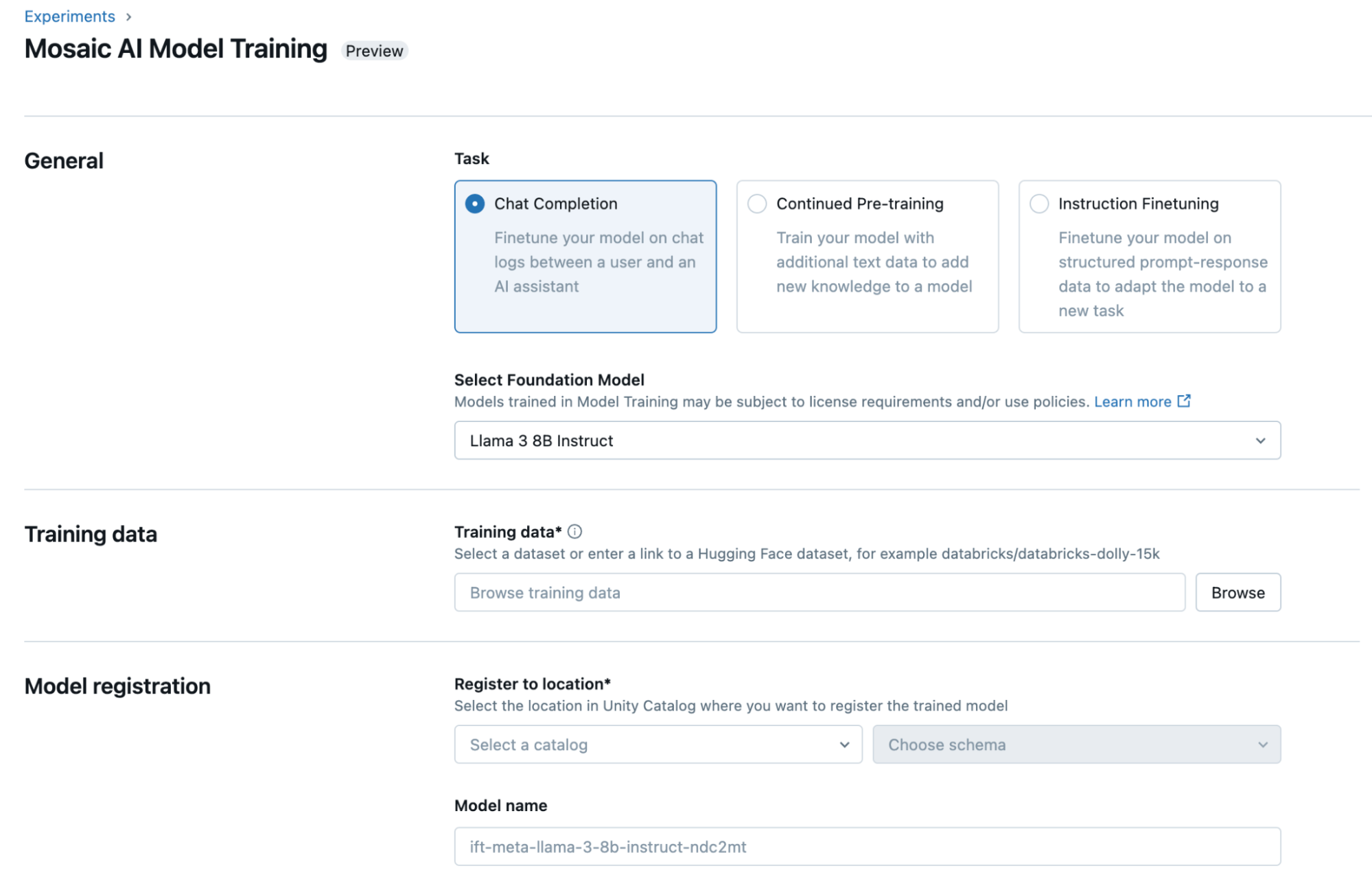
“At Experian, we’re driving innovation by refining open-source large language models to unlock new possibilities.” By leveraging the Mosaic AI Mannequin Coach, we significantly reduced the average training time for our models, enabling us to accelerate our GenAI development cycle to multiple iterations daily. “The outcome yields a manikin that adapts to the pattern we define, surpasses industry norms in our specific usage scenarios, and costs us significantly less to operate.”
“With Databricks, we can potentially streamline laborious data processing tasks by leveraging Large Language Models (LLMs) to process over a million records daily, efficiently extracting transactional and entity-level insights from property documents.” By leveraging the optimized Meta Llama3 8b model and harnessing the capabilities of Mosaic AI’s serving architecture, we successfully surpassed our accuracy targets. “We successfully scaled this operation without requiring a substantial investment in a costly GPU infrastructure.” – Prabhu Narsina, VP Knowledge and AI, First American
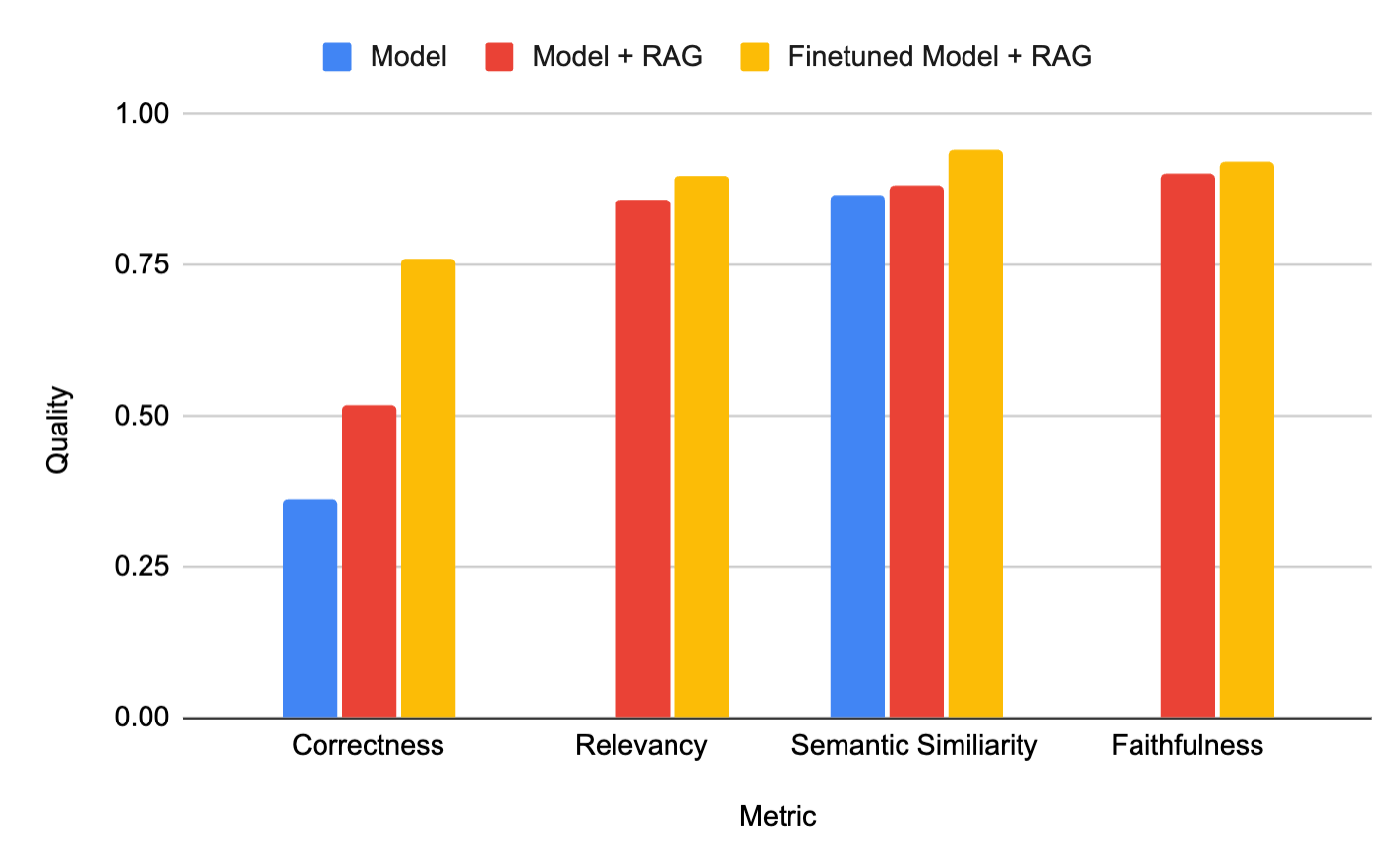
However, our experience with RAG suggested that we had reached a plateau; the need for an abundance of prompts and guidance became increasingly cumbersome. With the transition to fine-tuning, we seamlessly navigated the process of refining our models using RAG and Mosaic AI Mannequin Coaching, simplifying the experience for us. While not exclusively focused on the mannequin for Knowledge Linguistics and Area, it also reduced hallucinations and accelerated processing speed in RAG systems?
“After integrating our Databricks-fine-tuned language model with our RAG system, we achieved higher utility and accuracy while utilizing significantly fewer tokens.”