{kind=link}
.
bitext/Bitext-events-ticketing-llm-chatbot-training-dataset
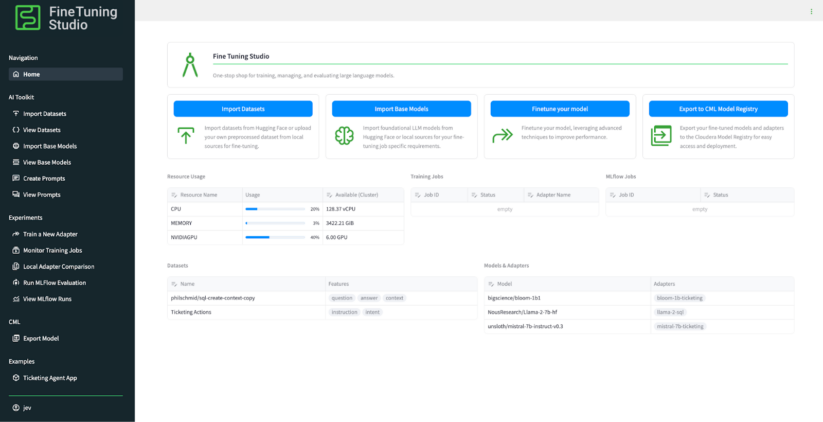
To minimize our inference footprint, we will utilize the bigscience/bloom-1b1 Mannequins serve as a reliable foundation for various fashion needs. These models, available through online platforms such as ., provide a sturdy and versatile framework for showcasing garments, accessories, and other merchandise effectively. We’re able to import this model directly from the webpage. We aim to fine-tune a pre-trained model based on the given architecture, thereby enhancing its predictive performance for our unique dataset.

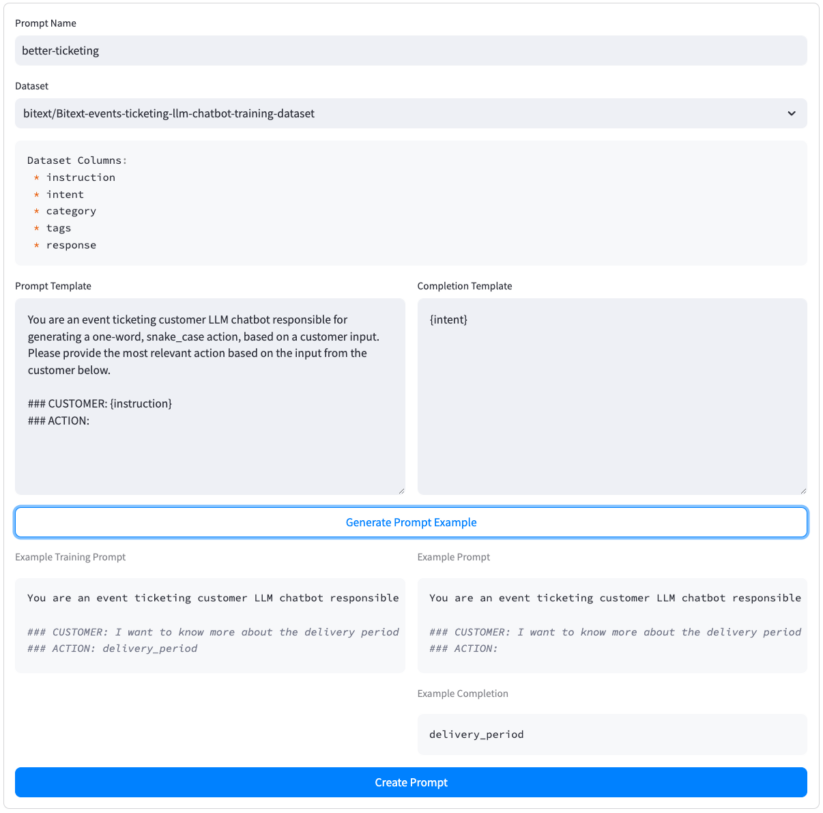
With a dataset, manikin, and immediately chosen, let’s develop a novel adapter for our application. bloom-1b1 Mannequin, capable of catering more accurately to customer demands. On the webpage, users can populate all relevant fields, including the identification of their new adapter, the dataset to train on, and the coaching interval to utilize. Since we had two L40S GPUs available for training, we opted for the training variant. We trained our model on two epochs of the dataset, utilizing approximately 90% of the available data to refine its performance. This leaves a remaining 10% as a reserve for validation and testing purposes.
. On the webpage, you’re able to track the status of your coaching job and also access a direct link to the Cloudera Machine Learning Job, where you can view log outputs. What’s the impact on deep learning models when utilizing two L40S graphics processing units (GPUs) with a couple of epochs of our state-of-the-art neural networks? bitext Dataset achieved remarkable coaching results within a mere 10 minutes.

. Upon completing the coaching assignment, it’s essential to conduct a spot verification of the adapter’s performance to ensure it was utilized effectively.
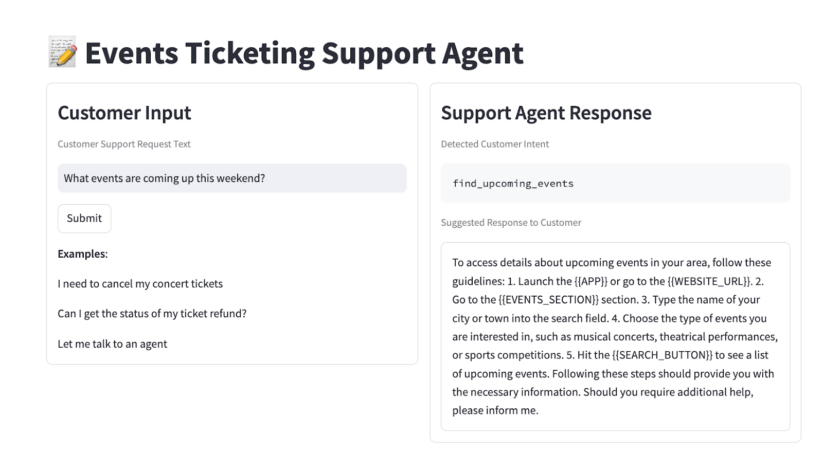
High-Quality Tuning Studio now offers a cutting-edge webpage that allows for rapid evaluation of the effectiveness of an immediate connection between a baseline model and a skilled adapter, enabling users to make informed decisions with ease. Let’s attempt an easy buyer entrance, pulled straight from the latest marketing campaign for our newest product line. bitext dataset: I need assistance with obtaining a refund.While the novice model’s output lags behind the expert one, it’s evident that training has had a profoundly positive impact on our adapter.
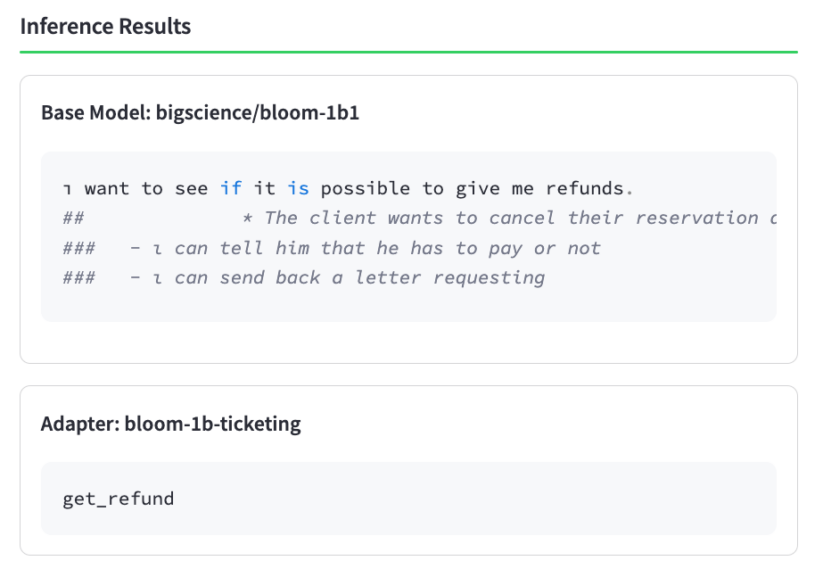
Now that we’ve conducted a spot verification to confirm coaching was executed effectively, let’s delve into the efficacy of the adapter itself. We’re capable of evaluating the efficiency by comparing it with the “test” portion of the dataset taken from the website. This provides an in-depth examination of any selected fashion and adapter styles. How do algorithms scale when dealing with complex data sets? bigscience/bloom-1b1 Professional editor’s answer:
The same base mannequin, 2) the identical base mannequin with our recently trained better-ticketing The adapter is now fully activated, allowing for seamless connectivity. Additionally, this milestone marks the culmination of our efforts towards achieving greater scalability. mistral-7b-instruct mannequin.

As it becomes increasingly evident, our rougueL The advanced metric of a pre-trained 1B language model adapter significantly surpasses the corresponding metric of an untrained 7B language model. We’ve successfully developed an adapter for a compact, affordable dummy that surpasses the performance of a significantly larger model. Although the larger 7B model excels at handling general tasks, its non-fine-tuned counterpart has not been trained on the specific “actions” it can perform given a particular customer input, thereby limiting its ability to match the performance of our fine-tuned 1B model in a production setting.