
")
{kind=link}
 |
As we speak, we’re saying the preview of Amazon S3 Vectors, a purpose-built sturdy vector storage resolution that may cut back the entire price of importing, storing, and querying vectors by as much as 90 p.c. Amazon S3 Vectors is the primary cloud object retailer with native assist to retailer giant vector datasets and supply subsecond question efficiency that makes it reasonably priced for companies to retailer AI-ready information at huge scale.
Vector search is an rising method utilized in generative AI purposes to seek out related information factors to given information by evaluating their vector representations utilizing distance or similarity metrics. Vectors are numerical illustration of unstructured information created from embedding fashions. You employ embedding fashions to generate vector embeddings of your information and retailer them in S3 Vectors to carry out semantic searches.

S3 Vectors introduces vector buckets, a brand new bucket kind with a devoted set of APIs to retailer, entry, and question vector information with out provisioning any infrastructure. Once you create an S3 vector bucket, you manage your vector information inside vector indexes, making it easy for operating similarity search queries in opposition to your dataset. Every vector bucket can have as much as 10,000 vector indexes, and every vector index can maintain tens of tens of millions of vectors.
After making a vector index, when including vector information to the index, you can too connect metadata as key-value pairs to every vector to filter future queries based mostly on a set of situations, for instance, dates, classes, or consumer preferences. As you write, replace, and delete vectors over time, S3 Vectors routinely optimizes the vector information to realize the very best price-performance for vector storage, even because the datasets scale and evolve.

S3 Vectors can be natively built-in with Amazon Bedrock Information Bases, together with inside Amazon SageMaker Unified Studio, for constructing cost-effective Retrieval-Augmented Era (RAG) purposes. By way of its integration with Amazon OpenSearch Service, you may decrease storage prices by retaining rare queried vectors in S3 Vectors after which shortly transfer them to OpenSearch as calls for improve or to assist real-time, low-latency search operations.
With S3 Vectors, now you can economically retailer the vector embeddings that characterize huge quantities of unstructured information similar to photographs, movies, paperwork, and audio information, enabling scalable generative AI purposes together with semantic and similarity search, RAG, and construct agent reminiscence. You can too construct purposes to assist a variety of business use instances together with personalised suggestions, automated content material evaluation, and clever doc processing with out the complexity and value of managing vector databases.
S3 Vectors in motion
To create a vector bucket, select Vector buckets within the left navigation pane within the Amazon S3 console after which select Create vector bucket.
Enter a vector bucket title and select the encryption kind. In the event you don’t specify an encryption kind, Amazon S3 applies server-side encryption with Amazon S3 managed keys (SSE-S3) as the bottom degree of encryption for brand new vectors. You can too select server-side encryption with AWS Key Administration Service (AWS KMS) keys (SSE-KMS). To be taught extra about managing your vector bucket, go to S3 Vector buckets within the Amazon S3 Consumer Information.

Now, you may create a vector index to retailer and question your vector information inside your created vector bucket.

Enter a vector index title and the dimensionality of the vectors to be inserted within the index. All vectors added to this index will need to have precisely the identical variety of values.
For Distance metric, you may select both Cosine or Euclidean. When creating vector embeddings, choose your embedding mannequin’s beneficial distance metric for extra correct outcomes.

Select Create vector index after which you may insert, checklist, and question vectors.

To insert your vector embeddings to a vector index, you should use the AWS Command Line Interface (AWS CLI), AWS SDKs, or Amazon S3 REST API. To generate vector embeddings on your unstructured information, you should use embedding fashions provided by Amazon Bedrock.
In the event you’re utilizing the newest AWS Python SDKs, you may generate vector embeddings on your textual content utilizing Amazon Bedrock utilizing following code instance:
# Generate and print an embedding with Amazon Titan Textual content Embeddings V2. import boto3 import json # Create a Bedrock Runtime shopper within the AWS Area of your alternative. bedrock= boto3.shopper("bedrock-runtime", region_name="us-west-2") The textual content strings to transform to embeddings. texts = [ "Star Wars: A farm boy joins rebels to fight an evil empire in space", "Jurassic Park: Scientists create dinosaurs in a theme park that goes wrong", "Finding Nemo: A father fish searches the ocean to find his lost son"] embeddings=[] #Generate vector embeddings for the enter texts for textual content in texts: physique = json.dumps({ "inputText": textual content }) # Name Bedrock's embedding API response = bedrock.invoke_model( modelId='amazon.titan-embed-text-v2:0', # Titan embedding mannequin physique=physique) # Parse response response_body = json.masses(response['body'].learn()) embedding = response_body['embedding'] embeddings.append(embedding)Now, you may insert vector embeddings into the vector index and question vectors in your vector index utilizing the question embedding:
# Create S3Vectors shopper s3vectors = boto3.shopper('s3vectors', region_name="us-west-2") # Insert vector embedding s3vectors.put_vectors( vectorBucketName="channy-vector-bucket", indexName="channy-vector-index", vectors=[ {"key": "v1", "data": {"float32": embeddings[0]}, "metadata": {"id": "key1", "source_text": texts[0], "style":"scifi"}}, {"key": "v2", "information": {"float32": embeddings[1]}, "metadata": {"id": "key2", "source_text": texts[1], "style":"scifi"}}, {"key": "v3", "information": {"float32": embeddings[2]}, "metadata": {"id": "key3", "source_text": texts[2], "style":"household"}} ], ) #Create an embedding on your question enter textual content # The textual content to transform to an embedding. input_text = "Listing the flicks about adventures in house" # Create the JSON request for the mannequin. request = json.dumps({"inputText": input_text}) # Invoke the mannequin with the request and the mannequin ID, e.g., Titan Textual content Embeddings V2. response = bedrock.invoke_model(modelId="amazon.titan-embed-text-v2:0", physique=request) # Decode the mannequin's native response physique. model_response = json.masses(response["body"].learn()) # Extract and print the generated embedding and the enter textual content token rely. embedding = model_response["embedding"] # Performa a similarity question. You can too optionally use a filter in your question question = s3vectors.query_vectors( vectorBucketName="channy-vector-bucket", indexName="channy-vector-index", queryVector={"float32":embedding}, topK=3, filter={"style":"scifi"}, returnDistance=True, returnMetadata=True ) outcomes = question["vectors"] print(outcomes) To be taught extra about inserting vectors right into a vector index, or itemizing, querying, and deleting vectors, go to S3 vector buckets and S3 vector indexes within the Amazon S3 Consumer Information. Moreover, with the S3 Vectors embed command line interface (CLI), you may create vector embeddings on your information utilizing Amazon Bedrock and retailer and question them in an S3 vector index utilizing single instructions. For extra data, see the S3 Vectors Embed CLI GitHub repository.
Combine S3 Vectors with different AWS providers
S3 Vectors integrates with different AWS providers similar to Amazon Bedrock, Amazon SageMaker, and Amazon OpenSearch Service to boost your vector processing capabilities and supply complete options for AI workloads.
Create Amazon Bedrock Information Bases with S3 Vectors
You should utilize S3 Vectors in Amazon Bedrock Information Bases to simplify and cut back the price of vector storage for RAG purposes. When making a information base within the Amazon Bedrock console, you may select the S3 vector bucket as your vector retailer choice.
In Step 3, you may select the Vector retailer creation technique both to create an S3 vector bucket and vector index or select the prevailing S3 vector bucket and vector index that you simply’ve beforehand created.

For detailed step-by-step directions, go to Create a information base by connecting to an information supply in Amazon Bedrock Information Bases within the Amazon Bedrock Consumer Information.
Utilizing Amazon SageMaker Unified Studio
You may create and handle information bases with S3 Vectors in Amazon SageMaker Unified Studio while you construct your generative AI purposes via Amazon Bedrock. SageMaker Unified Studio is on the market within the subsequent technology of Amazon SageMaker and gives a unified improvement surroundings for information and AI, together with constructing and texting generative AI purposes that use Amazon Bedrock information bases.
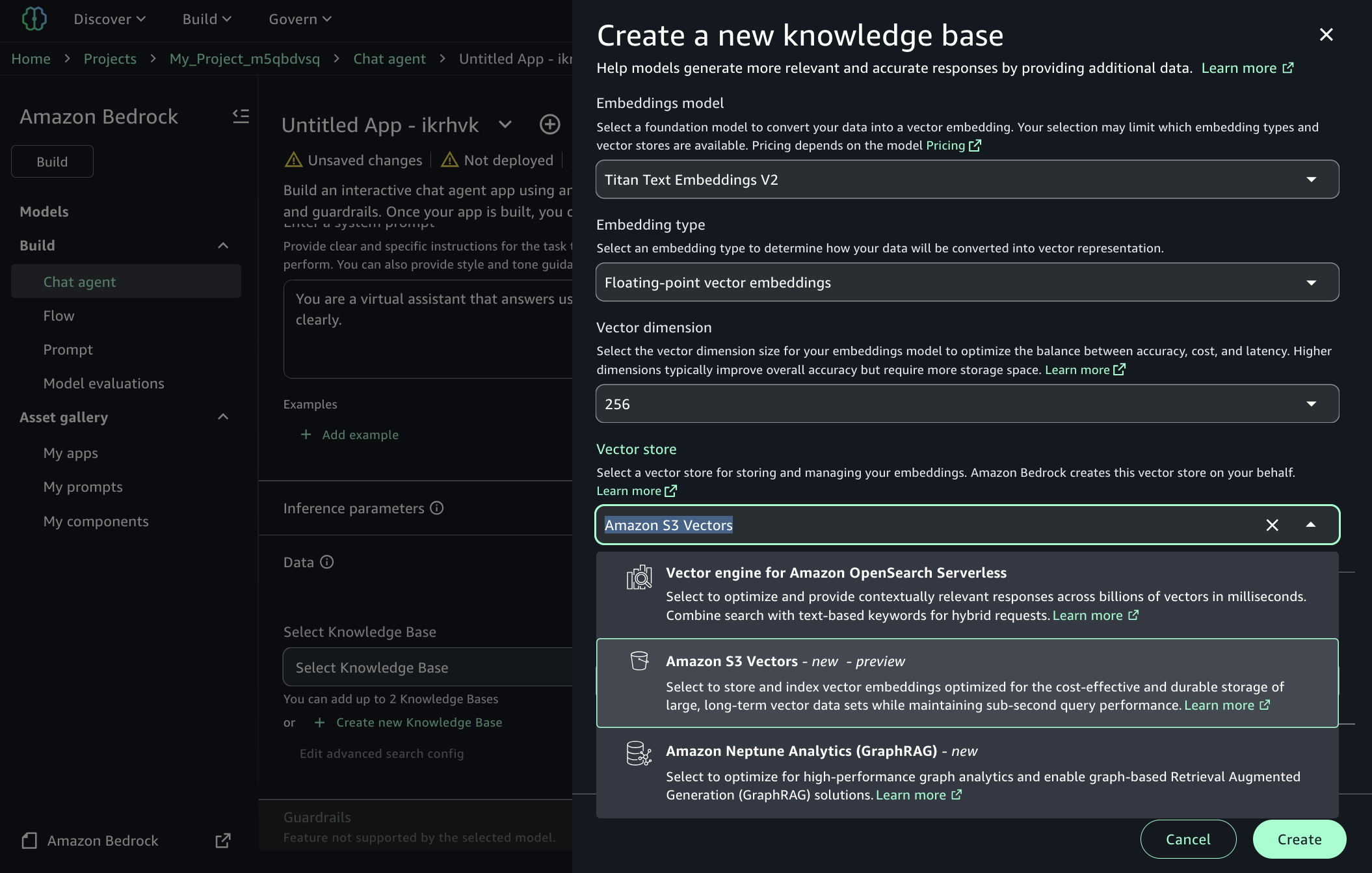
You may select Amazon S3 Vectors because the Vector retailer while you create a brand new information bases within the SageMaker Unified Studio. To be taught extra, go to Add an Amazon Bedrock Information Base element to a chat agent app within the Amazon SageMaker Unified Studio Consumer Information.
Export S3 vector information to Amazon OpenSearch Service
You may steadiness price and efficiency by adopting a tiered technique that shops long-term vector information cost-effectively in Amazon S3 whereas exporting excessive precedence vectors to OpenSearch for real-time question efficiency.
This flexibility means your organizations can entry OpenSearch’s excessive efficiency (excessive QPS, low latency) for essential, real-time purposes, similar to product suggestions or fraud detection, whereas retaining much less time-sensitive information in S3 Vectors.
To export your vector index, select Superior search export, then select Export to OpenSearch within the Amazon S3 console.

Then, you can be dropped at the Amazon OpenSearch Service Integration console with a template for S3 vector index export to OpenSearch vector engine. Select Export with pre-selected S3 vector supply and a service entry function.

It would begin the steps to create a brand new OpenSearch Serverless assortment and migrate information out of your S3 vector index into an OpenSearch knn index.
Select the Import historical past within the left navigation pane. You may see the brand new import job that was created to make a replica of vector information out of your S3 vector index into the OpenSearch Serverless assortment.

As soon as the standing modifications to Full, you may hook up with the brand new OpenSearch serverless assortment and question your new OpenSearch knn index.
To be taught extra, go to Creating and managing Amazon OpenSearch Serverless collections within the Amazon OpenSearch Service Developer Information.
Now accessible
Amazon S3 Vectors, and its integrations with Amazon Bedrock, Amazon OpenSearch Service, and Amazon SageMaker are actually in preview within the US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Frankfurt), and Asia Pacific (Sydney) Areas.
Give S3 Vectors a strive within the Amazon S3 console right this moment and ship suggestions to AWS re:Put up for Amazon S3 or via your regular AWS Help contacts.
— Channy
Up to date on July 15, 2025 – Revised the console screenshot of Amazon SageMaker Unified Studio.