

{kind=link}
Apache Spark™ Structured Streaming has lengthy powered mission-critical pipelines at scale, from streaming ETL to close real-time analytics and machine studying. Now, we’re increasing that functionality to a completely new class of workloads with real-time mode, a brand new set off sort that processes occasions as they arrive, with latency within the tens of milliseconds.
Not like current micro-batch triggers, which both course of knowledge on a set schedule (ProcessingTime set off) or course of all accessible knowledge earlier than shutting down (AvailableNow set off), real-time mode constantly processes knowledge and emits outcomes as quickly as they’re prepared. This allows ultra-low-latency use circumstances like fraud detection, dwell personalization, and real-time machine studying characteristic serving, all with out altering your current code or replatforming.
This new mode is being contributed to open supply Apache Spark and is now accessible in Public Preview on Databricks.
On this submit, we’ll cowl:
- What real-time mode is and the way it works
- The varieties of purposes it allows
- How one can begin utilizing it right now
What’s real-time mode?
Actual-time mode delivers steady, low-latency processing in Spark Structured Streaming, with p99 latencies as little as the single-digit milliseconds. Groups can allow it with a single configuration change — no rewrites or replatforming required — whereas conserving the identical Structured Streaming APIs they use right now.
How real-time mode works
Actual-time mode runs long-lived streaming jobs that schedule phases concurrently. Knowledge passes between duties in reminiscence utilizing a streaming shuffle, which:
- Reduces coordination overhead
- Removes the fastened scheduling delays of micro-batch mode
- Delivers constant sub-second efficiency
In Databricks inner assessments, p99 latencies ranged from just a few milliseconds to ~300 ms, relying on transformation complexity:
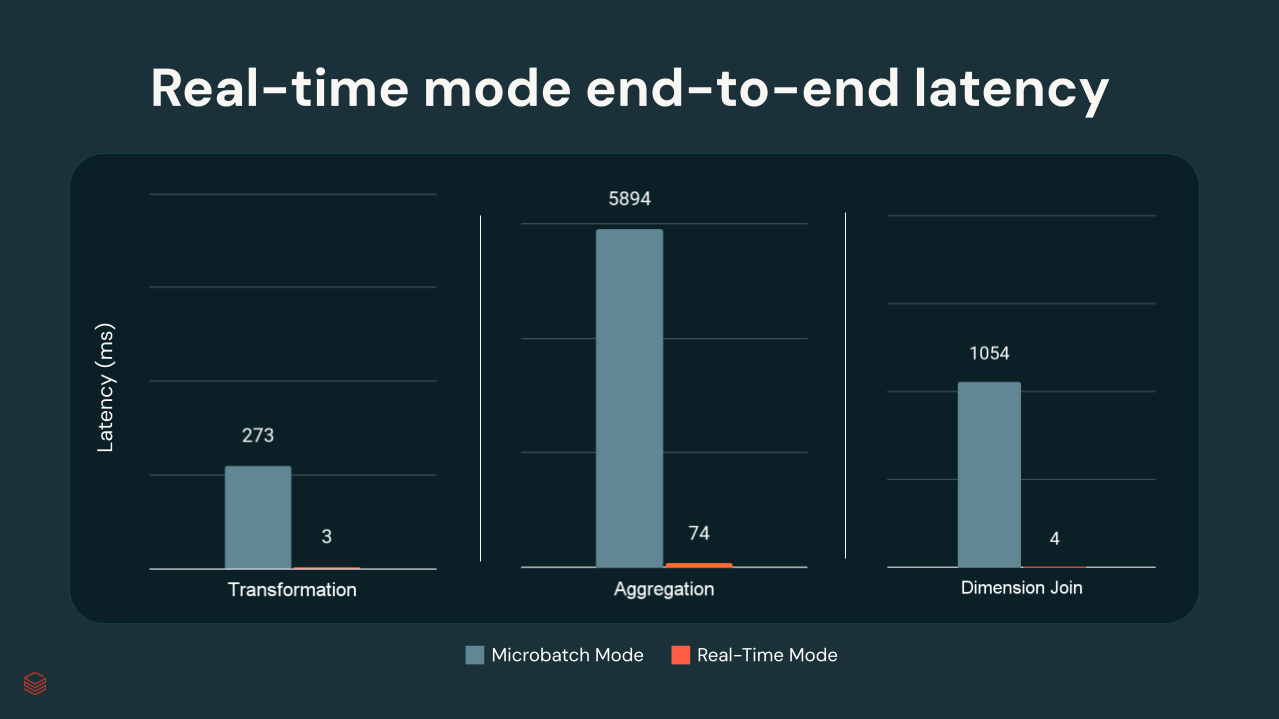
Purposes and Use Circumstances
Actual-time mode is designed for streaming purposes that require ultra-low-latency processing and fast response occasions, typically within the crucial path of enterprise operations.
Actual-Time Mode in Spark Structured Streaming has delivered outstanding leads to our early testing. For a mission-critical funds authorization pipeline, the place we carry out encryption and different transformations, we achieved P99 end-to-end latency of simply 15 milliseconds. We’re optimistic about scaling this low-latency processing throughout our knowledge flows whereas persistently assembly strict SLAs. — Raja Kanchumarthi, Lead Knowledge Engineer, Community Worldwide

Along with Community Worldwide’s fee authorization use case quoted above, a number of early adopters have already used it to energy a variety of workloads:
Fraud detection in monetary companies: A worldwide financial institution processes bank card transactions from Kafka in actual time and flags suspicious exercise, all inside 200 milliseconds – lowering danger and response time with out replatforming.
Customized experiences in retail and media: An OTT streaming supplier updates content material suggestions instantly after a person finishes watching a present. A number one e-commerce platform recalculates product gives as prospects browse – conserving engagement excessive with sub-second suggestions loops.
Stay session state and search historical past: A significant journey website tracks and surfaces every person’s current searches in actual time throughout units. Each new question updates the session cache immediately, enabling customized outcomes and autofill at once.
Actual-time ML Characteristic Serving: A meals supply app updates options like driver location and prep occasions in milliseconds. These updates move instantly into machine studying fashions and user-facing apps, enhancing ETA accuracy and buyer expertise.
These are just some examples. Actual-time mode can help any workload that advantages from turning knowledge into choices in milliseconds, from IoT sensor alerts and provide chain visibility to dwell gaming telemetry and in-app personalization.
Getting Began with real-time mode
Actual-time mode is now accessible in Public Preview on Databricks. In the event you’re already utilizing Structured Streaming, you possibly can allow it with a single configuration and set off replace – no rewrites required.
To attempt it out in DBR 16.4 or above:
- Create a cluster (we suggest Devoted Mode) on Databricks with Public Preview entry.
-
Allow real-time mode by setting the next Spark configuration:
-
Use the brand new set off in your question:
Checkpointing
The set off(RealTimeTrigger.apply(...)) choice allows the brand new real-time execution mode, permitting you to realize sub-second processing latencies. RealTimeTrigger accepts an argument that specifies how often the question checkpoints. For instance, set off(RealTimeTrigger.apply(“x minutes”)) By default, the checkpoint interval is 5 minutes, which works effectively for many use circumstances. Lowering this interval will increase checkpoint frequency, however could affect latency. Most streaming sources and sinks are supported, together with Kafka, Kinesis, and forEach for writing to exterior techniques.
Abstract
Actual-time mode is right to be used circumstances that demand the bottom attainable latency. For a lot of analytical workloads, customary micro-batch mode could also be less expensive whereas nonetheless assembly latency necessities. Actual-time mode introduces slight system overhead, so we suggest utilizing it for latency-critical pipelines comparable to these examples above. Assist for added sources and sinks is increasing, and we’re actively working to broaden compatibility and additional cut back latency.
For extra particulars, please assessment the real-time mode documentation for full implementation particulars, supported sources and sinks, and instance queries. You’ll discover every little thing you have to allow the brand new set off and configure your streaming workloads.
For a broader take a look at what’s new in Apache Spark 4.0, together with how real-time mode matches into the evolution of the engine, watch Michael Armbrust’s Spark 4.0 keynote from DAIS 2025. It covers the architectural shifts behind Spark’s subsequent chapter, with real-time mode as a core a part of the story.
To go deeper on the engineering behind real-time mode, watch our engineers’ technical deep dive session, which walks by way of the design and implementation.
And to see how real-time mode matches into the broader streaming technique on Databricks, try the Complete Information to Streaming on the Knowledge Intelligence Platform.