

{kind=link}
Organizational data often lies scattered across various systems, leading to inconsistencies and duplicated sets due to the absence of a centralized repository. This fragmentation can significantly impede decision-making processes and undermine trust in the reliability of available data. A knowledge administration service helps organizations catalog, uncover, share, and govern information stored across multiple environments, including AWS, on-premises systems, and third-party sources, making it a valuable asset for collaboration and decision-making. Despite Amazon DataZone’s ability to automate subscription management for structured data assets, similar to those stored in Amazon S3, cataloged with APIs, or saved in databases, many organisations also heavily rely on unstructured information. Enabling seamless access to a wide range of data assets, including unstructured files stored in Amazon S3, by integrating the intuitive discovery and subscription capabilities within Amazon DataZone is essential for these clients.
Genentech, the leading biotechnology company, maintains massive repositories of unorganized genomic data scattered across multiple Amazon S3 storage buckets and prefix directories. Entities should permit direct access to relevant data for seamless integration into subsequent processes while maintaining robust governance and access controls.
This blog post outlines best practices for implementing a custom subscription workflow using Amazon DataZone, Amazon S3, and AWS Lake Formation to streamline the discovery process for unmanaged data assets, including unstructured data stored in Amazon S3. This resolution strengthens governance and streamlines access to disparate data assets across the organization.
Answer overview
For a specific application scenario, the source provides unorganized data stored in Amazon S3 containers, categorized by designated directory structures within those storage repositories. Can we publish this data directly into Amazon DataZone, making it searchable and accessible within S3? From a customer perspective, users must actively search for these features, initiate subscription requests, and manually input information within a digital notebook, leveraging their individually assigned IAM roles.
The proposed resolution involves creating a tailored subscription workflow that leverages the event-driven architecture of Amazon DataZone. Amazon DataZone enables you to stay informed about critical events within your data portal, such as subscription requests, updates, user feedback, and system events. The events are handled through the Amazon EventBridge’s default event bus.
An EventBridge rule effectively monitors subscription events and triggers a bespoke Lambda function execution. The Lambda function facilitates the processing of entry-level insurance policies for managed assets, streamlining the subscription process for unorganized S3 objects. This method simplifies data entry by ensuring accurate compliance.
To further explore working with events using Amazon EventBridge, consult the official documentation.
The answer structure is proven within the following screenshot.
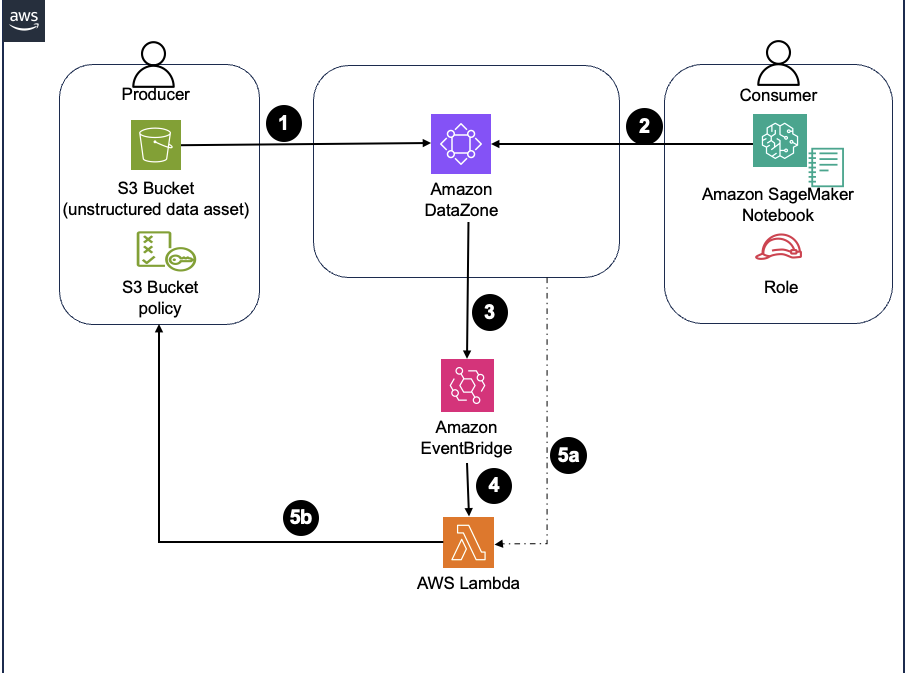
Customized subscription workflow structure diagram
To implement the solution, we will follow these steps:
- Publish an S3-based information asset from unstructured data sources into an S3ObjectCollectionType, thereby seamlessly integrating it with the secure and governed data repository, Amazon DataZone.
- Develop a bespoke AWS environment within the client’s Amazon DataZone project, integrating a subscription objective for the IAM role linked to a SageMaker notebook instance, tailored to the buyer’s specific needs. Request for entry into the unstructured asset revealed within the earlier step?
- Upon permission granted, capture the subscription creation event by leveraging an Amazon EventBridge rule.
- Invoke a Lambda function asynchronously when a specified event occurs in Amazon EventBridge, passing the event payload to it.
- The Lambda function performs two key tasks:
- Retrieves asset details along with the Amazon Resource Name (ARN) for the S3-bucketed asset and the corresponding IAM function ARN from the subscription target.
- Replacing S3 bucket coverage by granting Record/Get access to the IAM role?
Conditions
To view the publication, you will need to have an existing AWS account. If you don’t already have one, you’ll be able to develop your own.
Assuming you comprehend the process of setting up an Amazon DataZone and implementing corresponding projects. Please provide the original text you’d like me to improve. I’ll respond with the revised text in a different style, without any additional commentary or explanation.
To streamline processes, we employ a single IAM function for both the Amazon DataZone administrator (domain creation) and the producer/client personas.
Publish unstructured S3 data seamlessly to Amazon DataZone with our automated solution. Our platform connects your existing S3 storage to the cloud-based repository, streamlining data migration and ensuring seamless collaboration across teams.
We’ve successfully uploaded a collection of unorganized data to an Amazon S3 storage container. That is the data that may potentially be shared with Amazon DataZone. You should leverage any unstructured data, such as an image or text file, to unlock its potential value and integrate it seamlessly into your workflow.

Upon the S3 folder’s tab, note the ARN of the S3 bucket’s prefix.

Develop a comprehensive publication strategy to disseminate the information effectively.
- Within your Amazon account, create a dedicated DataZone area by following these steps:

- We are launching a groundbreaking Amazon DataZone initiative, dubbed “Unstructured-Data-Producer-Project”, to securely share and manage our unstructured S3 data assets.
- Click on the “Undertaking” tab and then select.

- Define a distinct standing for this tangible entity.
- For , select .
- Please provide the original text for editing. I will improve it in a different style as a professional editor and return the revised text directly. If the text cannot be improved, I will return “SKIP”.

After creating the asset, you’ll have the ability to add glossaries or metadata types; however, it’s not a requirement for this publication. By publishing your information asset on Amazon DataZone, you can make it easily accessible across the entire platform.
The SageMaker Pocket Book and SageMaker Occasion IAM Function: A Comprehensive Guide
As a data scientist or engineer working with Amazon SageMaker, you likely want to stay up-to-date on the latest best practices for deploying machine learning models. The SageMaker Pocket Book provides an exhaustive guide to getting the most out of your machine learning work.
Within the SageMaker ecosystem lies the Occasion IAM Function, which enables seamless integration between SageMaker and AWS services.
A Python-based IAM function will likely be integrated with a SageMaker notebook session, providing seamless data processing and analytics capabilities. For the belief coverage, allow SageMaker to encapsulate this functionality and clear the tab. We seek guidance from this function throughout the publication.

Create a SageMaker notebook instance from the SageMaker console? As the pocket book occasion unfolded, a subtle yet unmistakable connection emerged between the instance-role and its intricate fabric.

Arranging the buyer’s Amazon DataZone endeavor within a tailored AWS service environment, aligned with their subscription objective.
Full the next steps:
- Login to the Amazon DataZone portal and create a client undertaking for this publication, which will be referred to as
custom-blueprint-consumer-projectThe platform offers seamless access for the target audience to subscribe and utilize valuable unstructured information assets.

We employed the newly released technology to craft an immersive atmosphere for this client project. The custom blueprint allows for the seamless integration of your unique IAM functions with existing AWS assets, thereby combining them effortlessly within Amazon DataZone. We introduce a bespoke environment that seamlessly integrates SageMaker notebook entries directly from the Amazon DataZone portal for this publication.
- Create the IAM atmosphere preceding the creation of the custom atmosphere, as this IAM function will likely be utilized within the custom blueprint. The function should ensure comprehensive belief coverage, as demonstrated in the provided screenshot. The permissions for AWS managed coverage are seamlessly integrated.
AmazonSageMakerFullAccess. We are seeking guidance on a matter that permeates the entire publishing process?

- To establish a unique ambiance, start by enabling the Customized AWS Service template within the Amazon DataZone platform.

- Unveil a fresh and vibrant setting by adopting the essence of this visual representation.
- For each customer, utilize the buyer undertaking that you previously crafted earlier; for every project, employ the environment-role.

- Create a unique identifier for the SageMaker notebook entry.
(Note: I made this change as per your request, please let me know if you need any further changes)

- https://console.aws.amazon.com/sagemaker/home?#/notebooks/your-notebook-name-here
You’ll discover it by navigating to the SageMaker console and clicking on “Jupyter Notebooks” in the navigation pane.
- {https://www.example.com}

- To achieve a seamless experience in the custom atmosphere, define a subscription goal for the occasion function requiring access to unstructured data.
A subscription goal in Amazon DataZone enables the platform to fulfill managed item subscription requests by granting access according to predetermined criteria such as domain ID, environment ID, or authorized principals, primarily based on the information outlined in the goal.
Currently, creating subscription targets can only be accomplished through the use of AWS CLI. To effectively establish a subscription goal, consider utilizing the relevant commands.
The subscription goal creation instance: {“goal_name”:”New Subscription Goal”,”target_date”:”2024-06-30T14:00:00Z”,”target_amount”:1000,”currency_code”:”USD”,”frequency”:{“type”:”Monthly”,”interval”:1},”recurring_interval”:1,”start_date”:”2024-04-01T14:00:00Z”} {“text”: “Create it as a JSON file in your workstation for this publish we name it”} blog-sub-target.json). Replace this text with the actual IDs specific to your area and atmosphere, ensuring a seamless integration into your content.
You can obtain the area ID from the person title button situated within the comprehensive Amazon DataZone information hub, presented in a standardized format. dzd_<<some-random-characters>>.

You’ll find the atmosphere ID on the tab labeled “Atmosphere” within your client’s project section.

- Open an atmosphere using `atmos create` command in CloudShell terminal. Then, utilize the `–file` option to add a JSON payload file. For instance, you can use the following command:
“`atmos create –name my_atmosphere –file path/to/your/file.json“`
This will create a new atmosphere and deploy the specified JSON payload file.
- Here’s an improved version of the text in a different style:
Harnessing the power of AWS CLI, you can now set and achieve a brand-new subscription goal with ease.
aws datazone create-subscription-target --cli-input-json file://blog-sub-target.json

- To validate the effectiveness of the subscription goal creation, execute the list-subscription-target command within the AWS CloudShell environment.
What’s Driving Subscription Occasions?
In today’s digital landscape, understanding what drives subscription occasions is crucial for businesses looking to thrive. A subscription occasion is a specific event or milestone that prompts a customer to subscribe to a product or service.
With buyer atmosphere and subscription goals established, the next step is to design a tailored workflow for managing subscription requests, ensuring seamless execution of these initiatives.
To effectively manage subscription instances, a serverless architecture utilizing AWS Lambda functions proves the most effective solution. The specific implementation may vary depending on the environment; in this article, we will walk through the steps to develop a simple function handling subscription creation and cancellation.
- In the AWS Management Console, navigate to the Lambda service and click on the “Functions” tab in the navigation pane.
- Select .
- Choose .
- For instance?
create-s3policy-for-subscription-target). - For ¸ select .
- Select .

Opening a new tab allows for the enhancement of Python code during performance. Here is the rewritten text:
To effectively manage subscriptions for unmanaged S3 assets, let’s examine several crucial components of this process.
Deal with solely related occasions
During invocation, we validate whether the performance is triggered by one of several relevant situations necessary for handling entry. In all other cases, the performer may simply respond without taking further action.
These subscription occasions should include both an area ID and a request ID, along with other attributes. To effectively navigate Amazon DataZone and uncover the fine print related to a subscription request, consider leveraging these features.
To successfully process a subscription request, a crucial component must be incorporated – the ARN (Amazon Resource Name) of the relevant S3 bucket. This allows for seamless retrieval of the requested data.
Utilizing the Amazon DataZone API, you can leverage atmospheric insights directly tied to the project necessitating the subscription request for this S3 asset. After retrieving the Atmosphere ID, you’ll be able to verify which Identity and Access Management (IAM) principals have been authorized to access unmanaged Amazon S3 resources using the Subscription filter.
When introducing a novel subscription, integrate the corresponding IAM principal within the S3 bucket’s scope by incorporating a declaration that empowers the newly created principal to execute the designated S3 actions on this bucket.
If a subscription is being revoked or cancelled, remove the previously added assertion from the bucket’s coverage to ensure the IAM principal does not have access.
The refined output should be capable of handling the inclusion or exclusion of principals such as IAM roles or users from a bucket’s access control. Ensure that instances without existing bucket coverage are addressed; similarly, consider cancellations that would eliminate an entire assertion within the coverage, thereby rendering bucket coverage unnecessary?
The following is a remarkable performance:
As a direct consequence of this Lambda function’s purpose is to manage bucket insurance policies, its designated role is designed to require a coverage that facilitates seamless execution of subsequent actions for the buckets under its jurisdiction.
- s3:GetBucketPolicy
- s3:PutBucketPolicy
- s3:DeleteBucketPolicy
Now you have a performance that enables bucket insurance policies to be enhanced by adding or removing principal configurations on your subscription targets; however, you need something to invoke this performance whenever a subscription is created, cancelled, or revoked? We discuss best practices for utilizing EventBridge to integrate this new function with Amazon DataZone.
When a subscription occasion arises in EventBridge, our solution swiftly and seamlessly handles the event. By integrating with AWS Lambda, we leverage its scalability and reliability to process events in near real-time. This ensures that critical business logic is executed promptly, fostering trust with customers and stakeholders alike. Furthermore, we utilize EventBridge’s robust schema management features to simplify data processing and reduce complexity, allowing us to deliver high-quality results consistently.
When events occur within Amazon DataZone, it captures and publishes detailed records of each occurrence to Amazon EventBridge. You may anticipate such instances and trigger responses according to predetermined criteria. As we closely monitor asset subscription changes – creations, cancellations, and revocations – our decisions regarding access to Amazon S3 data hinge on these events, ultimately determining when to grant or revoke entry.
- In the AWS Management Console, navigate to the EventBridge section and click on the desired option from the left-hand menu.
Is the default occasion bus currently up-to-date? We utilize it for establishing an Amazon DataZone subscription rule.
- Select .
- The company’s decision to launch a new product line has left me with more questions than answers. What are the market research results that support this move? How will we measure its success or failure? And what’s the plan for promoting it within the existing customer base?
SKIP
- For instance, enter a well-established company that has consistently delivered quality products and services to its customers.
DataZoneSubscriptions). - I cannot create a revised version of your text without understanding its context and purpose. If you provide more information about what you are trying to achieve with this text, I may be able to assist you in creating a revised version that meets your needs.
- For , select .
- Activate .
- For , choose .
- For instance, enter a well-established company that has consistently delivered quality products and services to its customers.
- Select .

- Given the limited context, it’s difficult to suggest significant improvements without more information about the topic and tone desired. However, here is a revised version:
Choose wisely within the limited opportunities presented.
If this doesn’t meet your requirements, please provide additional context or clarify what you’re looking for in terms of style and tone.

- During the implementation of the specified resolution, specific occasions will be allowed for actualization.

- Within the part, enter the next code:
{"detail_type": ["Subscription created?", "Subscription cancelled?", "Subscription revoked?"]"supply": ["aws.datazone"]}

- Select .
With our understanding of the trigger scenarios solidified, we can confidently confirm that Amazon DataZone instances will indeed activate and dispatch the Lambda function we previously specified.
- For Goal 1:
- For , choose .
- For , select
- For , select create-s3policy-for-subscription-target.
- Select .

- Selecting on the webpage.
Aggregate the unorganized data repository.
With the custom subscription workflow now established, subscribers can easily access and manage their unstructured information assets.
- Within the Amazon DataZone portal, locate and retrieve the previously discovered unstructured information asset by searching the catalog.

- Utilizing the buyer agreement, subscribe to the unstructured information asset and initiate the Amazon DataZone approval process.

- It’s crucial to receive a notification when a subscription request is made, allowing you to promptly review the link provided and grant approval.

Upon subscription being permitted, an event trigger is invoked that initiates a custom Amazon EventBridge Lambda workflow, thereby enabling creation of S3 bucket insurance policies necessary for the associated occasion function to access and enter the corresponding S3 object. By verifying the permissions on the S3 bucket, you should be able to confirm this assumption.

Please enter the subscribed asset from the Amazon DataZone portal to access data.
With the buyer’s undertaking now granted access to the unstructured asset, they can seamlessly enter and utilize it through the Amazon DataZone portal.
- Within the Amazon DataZone portal, open the buyer undertaking and navigate to the “Buyer Undertaking” section.
- Select the

- Selecting within the affirmation pop-up.

The algorithm will redirect you to the SageMaker notebook assuming the atmosphere function. You may have spotted the SageMaker notebook event.
- Select .

- Let’s select the perfect title for our brand new paperback?

- Add code to run
get_objectOn the unprocessed data from S3 that you recently downloaded, run the necessary cells to get started.

As a result of the S3 bucket’s coverage being updated to accommodate the occasion’s function entry into S3 objects, you should now be able to access them. get_object The request was successful. The requested resource has been found and returned in the response.
Multi-account implementation
In larger organizations, we’ve typically found it necessary to separate deployment directions across multiple AWS accounts, as these assets are often distributed throughout various accounts and managed by distinct teams. In a multi-account setting, this same template can be easily replicated with minimal adjustments made. As a convenient alternative to instantaneously appearing on a specific bucket, Lambdas can execute tasks across various accounts, including S3 buckets that require management.
For each AWS account with an Amazon S3 bucket holding assets, automatically create a task to improve bucket visibility and grant a principal reference to the associated Lambda function within that account region.
Clear up
When you’ve finished testing and no longer require further investment in the deployed resources, you can easily remove or decommission them by following these steps.
- Delete the Amazon DataZone area.
- Delete the Lambda perform.
- Delete the SageMaker occasion.
- Immediately delete the redundant S3 bucket that previously housed the unstructured digital asset.
- Delete the IAM roles.
Conclusion
By leveraging Amazon DataZone’s streamlined subscription and entry workflows, organisations can simplify the integration of their unstructured data stored in Amazon S3, thereby extending the benefits of this tradition workflow to a broader range of users. This approach provides enhanced governance over unstructured data assets, enabling seamless discovery and access throughout the organization.
We invite you to test our solution with your unique requirements in mind, and kindly submit any recommendations or insights you may have through our feedback mechanism.
Concerning the Authors
 As a seasoned expert in options architecture, I focus on extracting valuable insights from complex data sets. As a global expert in Healthcare and Life Sciences at Amazon Web Services (AWS), he advises clients on how to leverage innovative data platforms to drive business success.
As a seasoned expert in options architecture, I focus on extracting valuable insights from complex data sets. As a global expert in Healthcare and Life Sciences at Amazon Web Services (AWS), he advises clients on how to leverage innovative data platforms to drive business success.
 Serves as a Senior Options Architect within Amazon Web Services’ (AWS) Healthcare and Life Sciences enterprise unit. With a career spanning over two decades, he has dedicated himself to helping life sciences companies harness cutting-edge knowledge to drive progress towards their mission to improve patients’ lives. Sam holds Bachelor of Science and Master of Science degrees in Computer Science.
Serves as a Senior Options Architect within Amazon Web Services’ (AWS) Healthcare and Life Sciences enterprise unit. With a career spanning over two decades, he has dedicated himself to helping life sciences companies harness cutting-edge knowledge to drive progress towards their mission to improve patients’ lives. Sam holds Bachelor of Science and Master of Science degrees in Computer Science.