

{kind=link}
Bases of fashion are massive, deep-learning models that were pre-trained on an enormous, unrestricted volume of general-purpose, unlabeled information. Customer service representatives are frequently utilized for a wide range of tasks, including creating photographs and responding to customer inquiries.
Despite their potential to revolutionize synthetic intelligence, highly advanced models such as ChatGPT and DALL-E are not immune to generating inaccurate or misleading information. In high-stakes situations akin to a pedestrian approaching a self-driving vehicle, minor errors may have catastrophic consequences.
To mitigate errors, researchers at MIT and the MIT-IBM Watson AI Lab have developed methods to estimate the reliability of machine learning models before deploying them to a specific process.
They achieve this by contemplating a set of fundamental fashion styles that are remarkably similar to one another. By applying their algorithm, the team assesses the coherence of the conceptual frameworks each mannequin develops from exposure to the same test data level. If the representations remain consistent, the mannequin proves to be reliable.
Compared to state-of-the-art baseline methods, our approach demonstrated superior performance in accurately assessing the reliability of various fashion styles across numerous downstream classification tasks.
To assess whether a mannequin is suitable for deployment in a specific context without requiring evaluation on a real-world dataset. When datasets are inaccessible due to privacy concerns, such as those in healthcare settings, this approach can prove particularly valuable. Moreover, this approach could be applied to rank fashion items by reliability scores, empowering individuals to select the most suitable option for their needs.
All fashions may become outdated; those that recognize their limitations are truly valuable. Quantifying uncertainty or reliability proves challenging for such fashion styles due to the difficulties in verifying their summarised representations. Our team’s innovative approach enables researchers to objectively measure the reliability of an illustration model based on specific input data, according to Navid Azizan, senior author and researcher. As an Edgerton Assistant Professor in both the MIT Department of Mechanical Engineering and the Institute for Information, Programs, and Society (IDSS), and a member of the Laboratory for Information and Decision Systems (LIDS).
They’re accompanied by three experts: Younger-Jin Park, a lead writer and LIDS graduate scholar; Hao Wang, an analysis scientist at the prestigious MIT-IBM Watson AI Lab; and Shervin Ardeshir, a senior research scientist at Netflix. The convention on uncertainty in synthetic intelligence: a comprehensive exploration of its implications and limitations.
Traditional machine-learning methods are trained to accomplish a specific task. These predictive models typically yield a specific forecast grounded in the input data. The AI-powered mannequin might potentially inform you whether a specific image features a feline or canine. Assessing reliability often boils down to verifying whether the predicted outcome aligns with the model’s accuracy.
Fashion trends may differ significantly. The pre-trained mannequin leverages general knowledge in an open-world setting where its developers are unaware of the diverse downstream tasks it will be applied to. Employees tailor the training to fit their individual job requirements once they have received initial instruction.
Unlike conventional machine learning approaches, basis functions do not produce concrete outputs such as specific “cat” or “dog” labels. Instead of generating a summary illustration as an alternative, they create concise visualizations of entered knowledge levels.
Researchers employed an ensemble approach to assess the reliability of a benchmark model by training multiple models that shared numerous characteristics but exhibited subtle differences.
We aim to quantify societal sentiment through measuring the collective opinion. “If the various fashion models consistently deliver accurate representations of data in our dataset, we can confidently deem this model reliable,” Park asserts.
How do they assess and evaluate these summary representations effectively?
“These simple fashion models merely produce a numerical vector, so we won’t judge their performance based solely on that.”
They addressed this limitation by leveraging a notion called neighbourhood consistency.
The researchers assembled a reliable framework of benchmark metrics to evaluate their diverse design strategies. For each mannequin, they investigate the reference indicators situated adjacent to its depiction of the test stage.
By analyzing the consistency of adjacent variables, they will gauge the dependability of fashion trends.
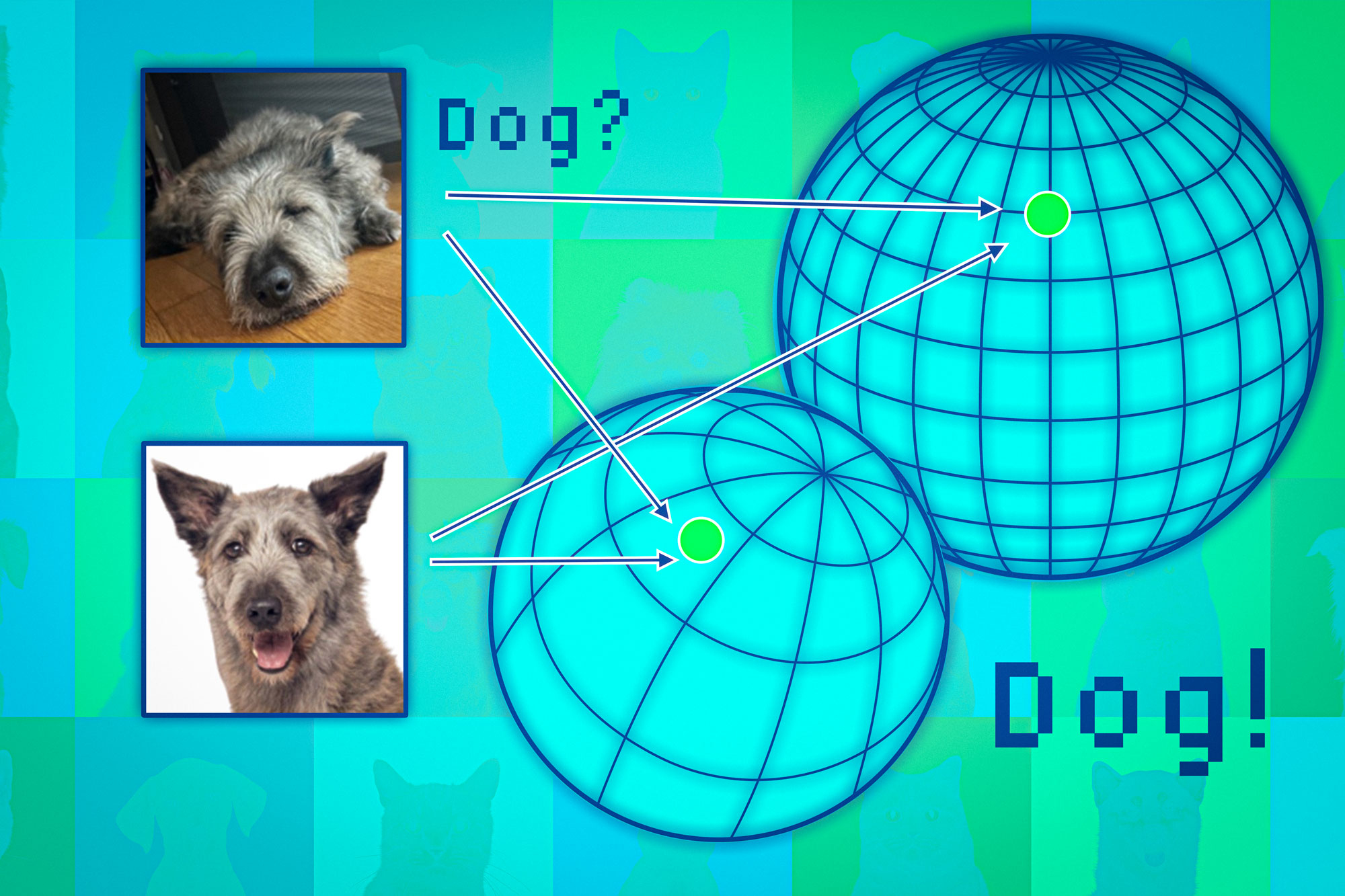
Based on the foundation of fashion, mapping knowledge factors to what is often referred to as an illustration house. Considering this house as an irregular polyhedron would be more accurate than a sphere. Each mannequin aligns analogous cognitive attributes to a specific sector of its domain, thereby categorizing images of felines into one region and those of canine species into another.
While each model would necessarily assign unique coordinates to animals within its own spatial framework, differing models may place species like cats in distinct regions or hemispheres.
Researchers utilize nearby variables, akin to anchors, to synchronize the spheres and facilitate comparable representation construction. Since neighboring knowledge levels exhibit consistency across multiple representations, confidence in the model’s accuracy can be reasonably expected for that specific timeframe.
After investigating this approach across diverse classification tasks, the team found it exhibited greater consistency than baseline methods. Unlike previous initiatives, this approach was unfazed by complex assessment variables that had led to the demise of other tactics.
By adapting this approach, it is possible to assess the reliability of any acquired knowledge, thereby considering how well a model performs for a specific type of individual, such as a patient with distinct characteristics?
When fashion trends converge on a single standard of excellence, individuals still need to prioritize what works best for them personally, notes Wang.
Despite this, a significant limitation arises from the need to generate an ensemble of basis fashions, a process that can be computationally expensive. As sustainability becomes increasingly important, industry leaders will inevitably explore innovative eco-friendly approaches to manufacture multiple models, potentially leveraging small perturbations of a single model.
As fine-tuned representations are increasingly leveraged for various downstream tasks, including fine-tuning, retrieval-augmented generation, and others, there exists a growing imperative to quantify uncertainty at the representation level – a challenge compounded by the fact that these embeddings lack inherent grounding. According to Marco Pavone, an affiliate professor in Stanford University’s Department of Aeronautics and Astronautics, this research effectively addresses how various input embeddings are linked together, a concept that is neatly captured by the proposed neighborhood consistency rating. “This breakthrough has the potential to revolutionize uncertainty quantification for complex models, and I’m eagerly anticipating future developments that can seamlessly integrate with larger models without necessitating model ensembling.”
The research underlying this work has been supported, in part, by the MIT-IBM Watson AI Laboratory, MathWorks, and Amazon.