

{kind=link}
AI brokers are actually part of enterprises massive and small. From filling kinds at hospitals and checking authorized paperwork to analyzing video footage and dealing with buyer help – we have now AI brokers for every kind of duties. Corporations usually spend a whole lot of hundreds of {dollars} on hiring buyer help employees who can perceive the wants of a buyer and resolve them based mostly on the corporate’s pointers. Right this moment, having an clever chatbot to reply FAQs can effectively enhance customer support. On this article, we’ll learn to construct an FAQ chatbot that may resolve buyer queries in seconds, utilizing agentic RAG (Retrieval Augmented Technology), LangGraph and ChromaDB.
Temporary on Agentic RAG
RAG is a sizzling subject these days. Everyone seems to be speaking about RAG and constructing functions on high of it. RAG helps LLMs to get entry to the real-time information, which makes LLMs extra correct than ever earlier than. Nevertheless, conventional RAG techniques are likely to fail with regards to selecting the most effective retrieval methodology, altering the retrieval workflow, or offering multi-step reasoning. That is the place agentic RAG is available in.
Agentic RAG enhances conventional RAG by incorporating the capabilities of AI brokers into it. With this superpower, RAGs can dynamically change the workflow based mostly on the character of the question, do multi-step reasoning, and multi-step retrieval as effectively. We will even combine instruments into the agentic RAG system, and it may dynamically determine which instrument to make use of when. Total, it ends in improved accuracy and makes the system extra environment friendly and scalable.
Right here’s an instance of an agentic RAG workflow.
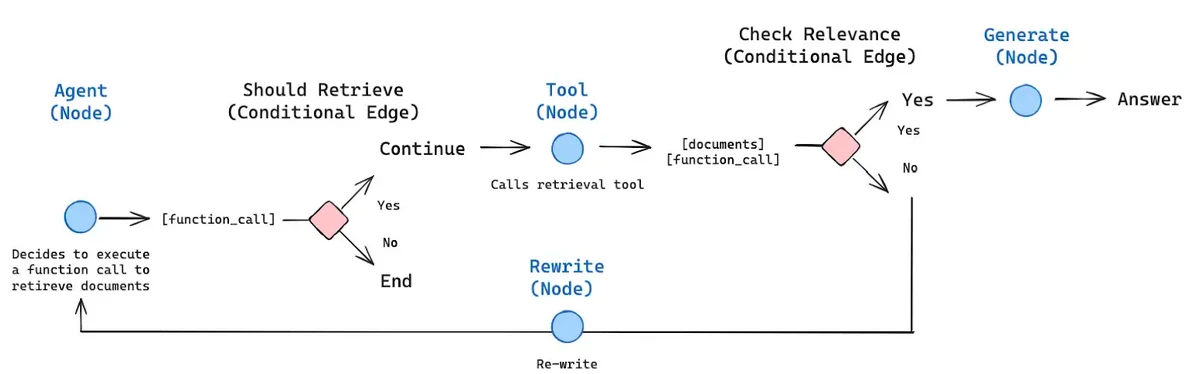
The picture above denotes the structure of an agentic RAG framework. It exhibits how AI brokers, when mixed with RAG, could make choices underneath sure circumstances. The picture clearly exhibits that if a conditional node is there, the agent will determine which edge to decide on based mostly on the context supplied.
Additionally Learn: 10 Enterprise Functions of LLM Brokers
Structure of the Clever FAQ Chatbot
Now we’re going to dive into the structure of the chatbot we’re going to construct. We’ll be exploring the way it works and what its necessary elements are.
The next determine exhibits the general construction of our system. We will probably be implementing this utilizing LangGraph, which is an open-source AI brokers framework from LangChain.
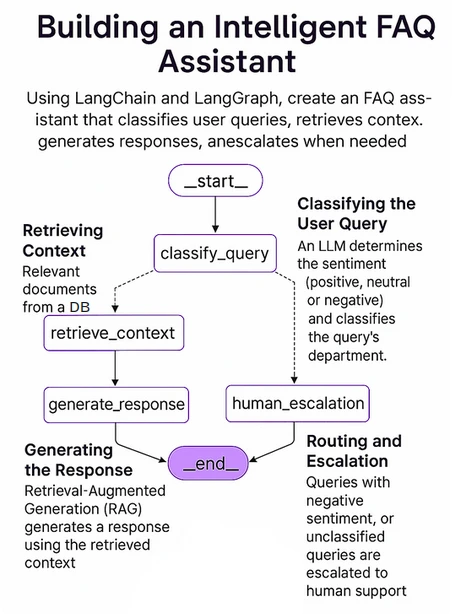
The important thing elements of our system embrace:
- LangGraph: A robust open-source AI agent framework that effectively creates advanced, multi-agent, cyclic graph-based brokers. These brokers can keep the states all through the workflow and may effectively deal with the advanced queries.
- LLM: An environment friendly and highly effective Massive Language Mannequin that may comply with the directions of the consumer and reply accordingly with the most effective of its data. Right here we will probably be utilizing OpenAI’s o4-mini, which is a small reasoning mannequin that’s particularly designed for velocity, affordability, and gear use.
- Vector Database: A vector database is used to retailer, handle and retrieve vector embeddings that are normally the numeric illustration of information. Right here we’re utilizing ChromaDB which is an open supply AI native vector database. It’s designed to empower the techniques that depend upon similarity searches, semantic searches, and different duties involving vector information.
Additionally Learn: How one can Construct a Buyer Help Voice Agent
Fingers-on Implementation on Constructing the Clever FAQ Chatbot
Now, we will probably be implementing the end-to-end workflow of our chatbot based mostly on the structure that we have now mentioned above. We will probably be doing it step-by-step with detailed explanations, code, in addition to pattern outputs. So let’s start.
Step 1: Set up Dependencies
We are going to begin by putting in all of the required libraries into our Jupyter pocket book. This contains libraries akin to langchain, langgraph, langchain-openai, langchain-community, chromadb, openai, python-dotenv, pydantic, and pysqlite3.
!pip set up -q langchain langgraph langchain-openai langchain-community chromadb openai python-dotenv pydantic pysqlite3Step 2: Import Required Libraries
Now we’re able to import all of the remaining libraries that we are going to want for this challenge.
import os import json from typing import Listing, TypedDict, Annotated, Dict from dotenv import load_dotenv # Langchain & LangGraph particular imports from langchain_openai import ChatOpenAI, OpenAIEmbeddings from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from pydantic import BaseModel, Discipline from langchain_core.messages import SystemMessage, HumanMessage, AIMessage from langchain_core.paperwork import Doc from langchain_community.vectorstores import Chroma from langgraph.graph import StateGraph, ENDStep 3: Set Up the OpenAI API Key
Enter your OpenAI key to set it as an setting variable.
from getpass import getpass OPENAI_API_KEY = getpass("OpenAI API Key:") load_dotenv() os.getenv("OPENAI_API_KEY")Step 4: Obtain the Dataset
Now we have made a pattern FAQ dataset in json format for various departments. We’ll have to obtain it from the drive and unzip it.
!gdown 1j6pdIansfQzKOZSEUinnHd8w6GlkKE6w !unzip -o /content material/blog_faq_files.zipOutput:
Step 5: Defining the Division Names for Mapping
Now, let’s outline the mapping of the departments in order that our agentic system can perceive which file belongs to which division.
# Outline Division Names (guarantee these match metadata used throughout ingestion) DEPARTMENTS = [ "Customer Support", "Product Information", "Loyalty Program / Rewards" ] UNKNOWN_DEPARTMENT = "Unknown/Different" FAQ_FILES = { "Buyer Help": "customer_support_faq.json", "Product Info": "product_information_faq.json", "Loyalty Program / Rewards": "loyalty_program_faq.json", }Step 6: Outline the Helper Features
We are going to outline some helper capabilities which will probably be answerable for loading FAQs from the json recordsdata and in addition storing them in ChromaDB.
1. load_faqs(…): It’s a helper operate which hundreds the FAQ from the json recordsdata and retailer them in a listing referred to as all_faqs.
def load_faqs(file_paths: Dict[str, str]) -> Dict[str, List[Dict[str, str]]]: """Hundreds QA pairs from JSON recordsdata for every division.""" all_faqs = {} print("Loading FAQs...") for dept, file_path in file_paths.gadgets(): strive: with open(file_path, 'r', encoding='utf-8') as f: all_faqs[dept] = json.load(f) print(f" - Loaded {len(all_faqs[dept])} FAQs for {dept}") besides FileNotFoundError: print(f" - WARNING: FAQ file not discovered for {dept}: {file_path}. Skipping.") besides json.JSONDecodeError: print(f" - ERROR: Couldn't decode JSON for {dept} from {file_path}. Skipping.") return all_faqs2. setup_chroma_vector_store(…): This operate units up the ChromaDB to retailer the vector embeddings. For this, we’ll first outline the Chroma configuration i.e., the listing which can comprise the chroma database recordsdata. Then we’ll convert the FAQs to LangChain’s Paperwork. It’s going to comprise metadata and web page content material which is the predefined format for an correct RAG. We will mix query and solutions for higher contextual retrieval or simply embed the reply. We’re conserving the query as effectively division identify within the metadata.
# ChromaDB Configuration CHROMA_PERSIST_DIRECTORY = "./chroma_db_store" CHROMA_COLLECTION_NAME = "Chatbot_faqs" def setup_chroma_vector_store( all_faqs: Dict[str, List[Dict[str, str]]], persist_directory: str, collection_name: str, embedding_model: OpenAIEmbeddings, ) -> Chroma: """Creates or hundreds a Chroma vector retailer with FAQ information and metadata.""" paperwork = [] print("nPreparing paperwork for vector retailer...") for division, faqs in all_faqs.gadgets(): for faq in faqs: # Mix Q&A for higher contextual embedding, or simply embed solutions # content material = f"Query: {faq['question']}nAnswer: {faq['answer']}" content material = faq['answer'] # Usually embedding simply the reply is efficient for FAQ retrieval doc = Doc( page_content=content material, metadata={ "division": division, "query": faq['question'] # Preserve query in metadata for potential show } ) paperwork.append(doc) print(f"Complete paperwork ready: {len(paperwork)}") if not paperwork: increase ValueError("No paperwork discovered so as to add to the vector retailer. Verify FAQ loading.") print(f"Initializing ChromaDB vector retailer (Persistence: {persist_directory})...") vector_store = Chroma( collection_name=collection_name, embedding_function=embedding_model, persist_directory=persist_directory, ) strive: vector_store = Chroma.from_documents( paperwork=paperwork, embedding=embedding_model, persist_directory=persist_directory, collection_name=collection_name ) print(f"Created and populated ChromaDB with {len(paperwork)} paperwork.") vector_store.persist() # Guarantee persistence after creation print("Vector retailer endured.") besides Exception as create_e: print(f"FATAL ERROR: Couldn't create Chroma vector retailer: {create_e}") increase create_e print("ChromaDB setup full.") return vector_storeStep 7: Outline the LangGraph Agent Elements
Let’s now outline our AI agent element which is the primary element of our work circulate.
1. State definition: It’s a python class containing the present state of the agent whereas operating. It incorporates variables akin to question, sentiment, division.
class AgentState(TypedDict): question: str sentiment: str division: str context: str # Retrieved context for RAG response: str # Last response to the consumer error: str | None # To seize potential errors2. Pydantic mannequin: Now we have outlined a pydantic mannequin right here which can guarantee a structured LLM output. It incorporates a sentiment which could have three values, “optimistic”, “adverse” and “impartial” and a division identify which will probably be predicted by the LLM.
class ClassificationResult(BaseModel): """Structured output for question classification.""" sentiment: str = Discipline(description="Sentiment of the question (optimistic, impartial, adverse)") division: str = Discipline(description=f"Most related division from the listing: {DEPARTMENTS + [UNKNOWN_DEPARTMENT]}. Use '{UNKNOWN_DEPARTMENT}' if uncertain or not relevant.")3. Nodes: The next are the node capabilities which can deal with every activity one after the other.
- Classify_query_node: It classifies the incoming question into the sentiment in addition to the goal division identify based mostly on the character of the question.
- retrieve_context_node: It performs the RAG over the vector database and filter the outcomes on the idea of division identify.
- generate_response_node: It generates the ultimate response based mostly on the question and retrieved context from the database.
- Human_escalation_node: If the sentiment is adverse or the goal division is unknown, it’ll escalate the question to the human consumer.
- route_query: It determines the subsequent step based mostly on the question and output of the classification node.
# 3. Nodes def classify_query_node(state: AgentState) -> Dict[str, str]: """ Classifies the consumer question for sentiment and goal division utilizing an LLM. """ print("--- Classifying Question ---") question = state["query"] llm = ChatOpenAI(mannequin="o4-mini", api_key=OPENAI_API_KEY) # Use a dependable, cheaper mannequin # Put together immediate for classification prompt_template = ChatPromptTemplate.from_messages([ SystemMessage( content=f"""You are an expert query classifier for ShopUNow, a retail company. Analyze the user's query to determine its sentiment and the most relevant department. The available departments are: {', '.join(DEPARTMENTS)}. If the query doesn't clearly fit into one of these, or is ambiguous, classify the department as '{UNKNOWN_DEPARTMENT}'. If the query expresses frustration, anger, dissatisfaction, or complains about a problem, classify sentiment as 'negative'. If the query is asking a question, seeking information, or making a neutral statement, classify sentiment as 'neutral'. If the query expresses satisfaction, praise, or positive feedback, classify sentiment as 'positive'. Respond ONLY with the structured JSON output format.""" ), HumanMessage(content=f"User Query: {query}") ]) # LLM Chain with structured output classifier_chain = prompt_template | llm.with_structured_output(ClassificationResult) strive: end result: ClassificationResult = classifier_chain.invoke({}) # Go empty dict as enter appears required now print(f" Classification Outcome: Sentiment="{end result.sentiment}", Division="{end result.division}"") return { "sentiment": end result.sentiment.decrease(), # Normalize "division": end result.division } besides Exception as e: print(f" Error throughout classification: {e}") return { "sentiment": "impartial", # Default on error "division": UNKNOWN_DEPARTMENT, "error": f"Classification failed: {e}" } def retrieve_context_node(state: AgentState) -> Dict[str, str]: """ Retrieves related context from the vector retailer based mostly on the question and division. """ print("--- Retrieving Context ---") question = state["query"] division = state["department"] if not division or division == UNKNOWN_DEPARTMENT: print(" Skipping retrieval: Division unknown or not relevant.") return {"context": "", "error": "Can not retrieve context and not using a legitimate division."} # Initialize embedding mannequin and vector retailer entry embedding_model = OpenAIEmbeddings(api_key=OPENAI_API_KEY) vector_store = Chroma( collection_name=CHROMA_COLLECTION_NAME, embedding_function=embedding_model, persist_directory=CHROMA_PERSIST_DIRECTORY, ) retriever = vector_store.as_retriever( search_type="similarity", search_kwargs={ 'ok': 3, # Retrieve high 3 related docs 'filter': {'division': division} # *** CRITICAL: Filter by division *** } ) strive: retrieved_docs = retriever.invoke(question) if retrieved_docs: context = "nn---nn".be part of([doc.page_content for doc in retrieved_docs]) print(f" Retrieved {len(retrieved_docs)} paperwork for division '{division}'.") # print(f" Context Snippet: {context[:200]}...") # Non-obligatory: log snippet return {"context": context, "error": None} else: print(" No related paperwork present in vector retailer for this division.") return {"context": "", "error": "No related context discovered."} besides Exception as e: print(f" Error throughout context retrieval: {e}") return {"context": "", "error": f"Retrieval failed: {e}"} def generate_response_node(state: AgentState) -> Dict[str, str]: """ Generates a response utilizing RAG based mostly on the question and retrieved context. """ print("--- Producing Response (RAG) ---") question = state["query"] context = state["context"] llm = ChatOpenAI(mannequin="o4-mini", api_key=OPENAI_API_KEY) # Can use a extra succesful mannequin for technology if not context: print(" No context supplied, producing generic response.") # Fallback if retrieval failed however routing determined RAG path anyway response_text = "I could not discover particular info associated to your question in our data base. Might you please rephrase or present extra particulars?" return {"response": response_text} # RAG Immediate prompt_template = ChatPromptTemplate.from_messages([ SystemMessage( content=f"""You are a helpful AI Chatbot for ShopUNow. Answer the user's query based *only* on the provided context. Be concise and directly address the query. If the context doesn't contain the answer, state that clearly. Do not make up information. Context: --- {context} ---""" ), HumanMessage(content=f"User Query: {query}") ]) RAG_chain = prompt_template | llm strive: response = RAG_chain.invoke({}) response_text = response.content material print(f" Generated RAG Response: {response_text[:200]}...") return {"response": response_text} besides Exception as e: print(f" Error throughout response technology: {e}") return {"response": "Sorry, I encountered an error whereas producing the response.", "error": f"Technology failed: {e}"} def human_escalation_node(state: AgentState) -> Dict[str, str]: """ Supplies a message indicating the question will probably be escalated to a human. """ print("--- Escalating to Human Help ---") cause = "" if state.get("sentiment") == "adverse": cause = "As a result of nature of your question," elif state.get("division") == UNKNOWN_DEPARTMENT: cause = "As your question requires particular consideration," response_text = f"{cause} I have to escalate this to our human help workforce. They are going to overview your request and get again to you shortly. Thanks in your persistence." print(f" Escalation Message: {response_text}") return {"response": response_text} # 4. Conditional Routing Logic def route_query(state: AgentState) -> str: """Determines the subsequent step based mostly on classification outcomes.""" print("--- Routing Choice ---") sentiment = state.get("sentiment", "impartial") division = state.get("division", UNKNOWN_DEPARTMENT) if sentiment == "adverse" or division == UNKNOWN_DEPARTMENT: print(f" Routing to: human_escalation (Sentiment: {sentiment}, Division: {division})") return "human_escalation" else: print(f" Routing to: retrieve_context (Sentiment: {sentiment}, Division: {division})") return "retrieve_context"Step 8: Outline the Graph Operate
Let’s construct the operate for the graph and assign the nodes and edges to the graph.
# --- Graph Definition --- def build_agent_graph(vector_store: Chroma) -> StateGraph: """Builds the LangGraph agent.""" graph = StateGraph(AgentState) # Add nodes graph.add_node("classify_query", classify_query_node) graph.add_node("retrieve_context", retrieve_context_node) graph.add_node("generate_response", generate_response_node) graph.add_node("human_escalation", human_escalation_node) # Set entry level graph.set_entry_point("classify_query") # Add edges graph.add_conditional_edges( "classify_query", # Supply node route_query, # Operate to find out the route { # Mapping: output of route_query -> vacation spot node "retrieve_context": "retrieve_context", "human_escalation": "human_escalation" } ) graph.add_edge("retrieve_context", "generate_response") graph.add_edge("generate_response", END) graph.add_edge("human_escalation", END) # Compile the graph # reminiscence = SqliteSaver.from_conn_string(":reminiscence:") # Instance for in-memory persistence app = graph.compile() # checkpointer=reminiscence non-compulsory for stateful conversations print("nAgent graph compiled efficiently.") return appStep 9: Provoke Agent Execution
Now, we will probably be initialising the agent and start executing the workflow.
1. Let’s begin by loading the FAQs.
# 1. Load FAQs faqs_data = load_faqs(FAQ_FILES) if not faqs_data: print("ERROR: No FAQ information loaded. Exiting.") exit()Output:

2. Arrange the embedding fashions. Right here, we’ll be establishing OpenAI embedding fashions for a quicker retrieval.
# 2. Setup Vector Retailer embedding_model = OpenAIEmbeddings(api_key=OPENAI_API_KEY) vector_store = setup_chroma_vector_store( faqs_data, CHROMA_PERSIST_DIRECTORY, CHROMA_COLLECTION_NAME, embedding_model )Output:
Additionally Learn: How one can Select the Proper Embedding for Your RAG Mannequin?
3. Now, construct the agent utilizing the predefined operate, visualizing the agent circulate utilizing the mermaid diagram.
# 3. Construct the Agent Graph agent_app = build_agent_graph(vector_store) from IPython.show import show, Picture, Markdown show(Picture(agent_app.get_graph().draw_mermaid_png()))Output:
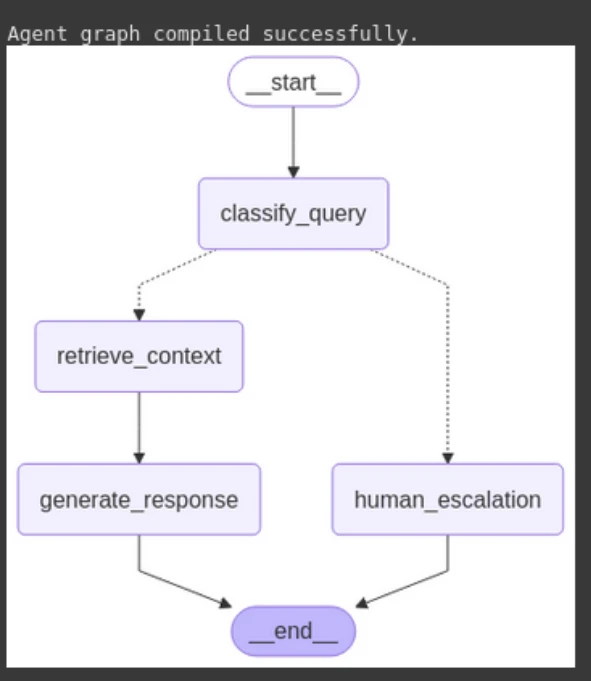
Step 10: Testing the Agent
Now we have arrived on the final a part of our workflow. Up to now we have now constructed a number of nodes and capabilities. Now’s the time to check our agent and see the output.
1. First let’s outline the take a look at queries.
# Check the Agent test_queries = [ "How do I track my order?", "What is the return policy?", "Tell me about the 'Urban Explorer' jacket materials.", ]2. Now let’s take a look at the agent.
print("n--- Testing Agent ---") for question in test_queries: print(f"nInput Question: {question}") # Outline the enter for the graph invocation inputs = {"question": question} # strive: # Invoke the graph # The config argument is non-compulsory however helpful for stateful execution if wanted # config = {"configurable": {"thread_id": "user_123"}} # Instance config final_state = agent_app.invoke(inputs) #, config=config) print(f"Last State Division: {final_state.get('division')}") print(f"Last State Sentiment: {final_state.get('sentiment')}") print(f"Agent Response: {final_state.get('response')}") if final_state.get('error'): print(f"Error encountered: {final_state.get('error')}") # besides Exception as e: # print(f"ERROR operating agent graph for question '{question}': {e}") # import traceback # traceback.print_exc() # Print detailed traceback for debugging print("n--- Agent Testing Full ---")print(“n— Testing Agent —“)
Output:
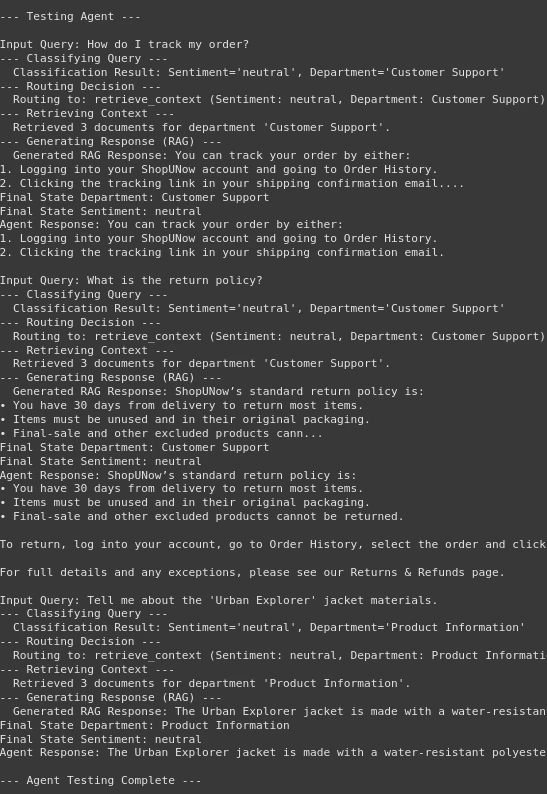
We will see within the output that our agent is performing effectively. Firstly, it classifies the question after which routes the choice to the retrieval node or the human node. Then, the retrieval half comes it efficiently retrieves the context from the vector database. Within the final, producing the response as wanted. Therefore, we have now made our clever FAQ Chatbot.
You possibly can entry the Colab Pocket book with all of the code right here.
Conclusion
When you have reached this far, it means you’ve got realized methods to construct an clever FAQ chatbot utilizing agentic RAG and LangGraph. Right here, we noticed that constructing an clever agent which might cause and decide, shouldn’t be that tough. The agentic chatbot that we constructed is price environment friendly, quick, and is able to absolutely understanding the context of the questions or enter queries. The structure we’ve used right here is absolutely customizable which implies one can edit any node of the agent for his or her specific use case. With agentic RAG, LangGraph, and ChromaDB, making brokers has by no means been this straightforward. by no means really easy earlier than. I’m certain what we have now lined on this information has given you the foundational data to construct extra advanced system utilizing these instruments.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Massive Language Fashions than precise people. Enthusiastic about GenAI, NLP, and making machines smarter (so that they don’t exchange him simply but). When not optimizing fashions, he’s in all probability optimizing his espresso consumption. 🚀☕
Login to proceed studying and revel in expert-curated content material.