

{kind=link}

(GarryKillian/Shutterstock)
Wonderful-tuning is a vital course of in optimizing the efficiency of pre-trained LLMs. It entails additional coaching the mannequin on a smaller, extra particular dataset tailor-made to a selected job or area. This course of permits the Giant Language Mannequin (LLM) to adapt its current information and capabilities to excel in particular purposes reminiscent of answering questions, summarizing textual content, or producing code. Wonderful-tuning allows the incorporation of domain-specific information and terminology that may not have been adequately coated within the unique pre-training information. It may possibly additionally assist align an LLM’s output type and format with particular necessities.
Nevertheless, conventional fine-tuning strategies aren’t with out their limitations. They sometimes require a considerable quantity of high-quality, labeled coaching information, which will be pricey and time-consuming to accumulate or create. Even after fine-tuning, the mannequin would possibly nonetheless be vulnerable to producing inaccuracies if the coaching information will not be complete sufficient or if the bottom mannequin has inherent biases. The fine-tuning course of itself will also be computationally intensive, particularly for very giant fashions.
Maybe most significantly, conventional fine-tuning might not successfully instill deep, structured information or strong reasoning skills throughout the LLM. For instance, supervised fine-tuning entails coaching on question-answer pairs to optimize efficiency. Whereas this could enhance the mannequin’s capability to reply questions, it might not essentially improve its underlying understanding of the subject material.
Regardless of its utility in adapting LLMs for particular functions, conventional fine-tuning typically falls brief in offering the deep, factual grounding vital for really reliable and exact efficiency in domains that require intensive information. Merely offering extra question-answer pairs might not handle the elemental lack of structured information and reasoning capabilities in these fashions.

(a-image/Shutterstock)
Unlocking Enhanced LLM Wonderful-tuning via Information Graphs
Leveraging information graphs (KGs) affords a robust method to reinforce the fine-tuning course of for LLMs, successfully addressing lots of the limitations related to conventional strategies. By integrating the structured and semantic information from KGs, organizations can create extra correct, dependable, and contextually conscious LLMs. A number of strategies facilitate this integration.
One vital means information graphs can enhance LLM fine-tuning is thru the augmentation of coaching information. KGs can be utilized to generate high-quality, knowledge-rich datasets that transcend easy question-answer pairs. A notable instance is the KG-SFT (Information Graph-Pushed Supervised Wonderful-Tuning) framework. This framework makes use of information graphs to generate detailed explanations for every question-answer pair within the coaching information. The core thought behind KG-SFT is that by offering LLMs with these structured explanations in the course of the fine-tuning course of, the fashions can develop a deeper understanding of the underlying information and logic related to the questions and solutions.
The KG-SFT framework sometimes consists of three principal elements:
- Extractor which identifies entities within the Q&A pair and retrieves related reasoning subgraphs from the KG;
- Generator which makes use of these subgraphs to create fluent explanations; and
- Detector which ensures the reliability of the generated explanations by figuring out potential information conflicts.
This method affords a number of advantages, together with improved accuracy, notably in situations the place labeled coaching information is scarce, and enhanced information manipulation skills throughout the LLM. By offering structured explanations derived from information graphs, fine-tuning can transfer past mere sample recognition and deal with instilling a real understanding of the information and the reasoning behind it. Conventional fine-tuning would possibly educate an LLM the right reply to a query, however KG-driven strategies may help it comprehend why that reply is the right one by leveraging the structured relationships and semantic info throughout the information graph.
Incorporating Information Graph Embeddings
One other highly effective approach entails incorporating information graph embeddings into the LLM fine-tuning course of. Information graph embeddings are vector representations of the entities and relationships inside a KG, capturing their semantic meanings in a dense, numerical format. These embeddings can be utilized to inject the structured information from the graph immediately into the LLM throughout fine-tuning.
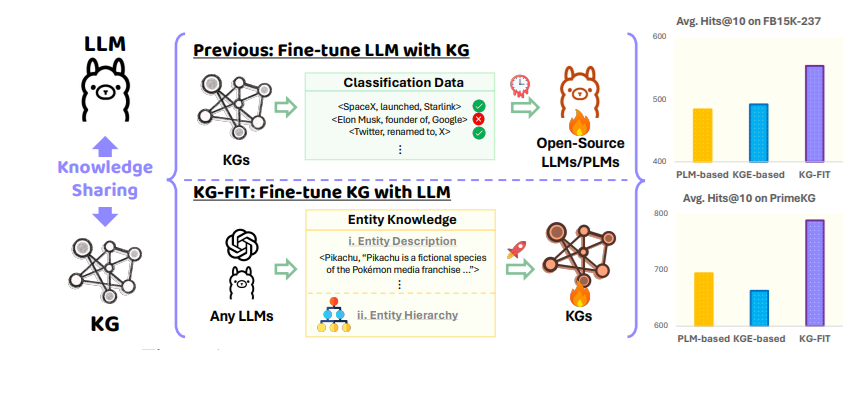
“Wonderful-tune LLM with KG” vs “Wonderful-tune KG with LLM (Supply: KG-FIT: Information Graph Wonderful-Tuning Upon Open-World Information)
KG-FIT is an instance of this method. It makes use of LLM-guided refinement to assemble a hierarchical construction of entity clusters from the information graph. This hierarchical information, together with textual info, is then integrated in the course of the fine-tuning of the LLM. This technique has the potential to seize each the broad, contextual semantics that LLMs are good at understanding and the extra particular, relational semantics which are inherent in information graphs.
By embedding the information from a graph, LLMs can entry and make the most of relational info in a extra environment friendly and nuanced method in comparison with merely processing textual descriptions of that information. These embeddings can seize the intricate semantic connections between entities in a KG in a format that LLMs can readily course of and combine into their inner representations.
Graph-Aligned Language Mannequin (GLaM) Wonderful-tuning
Frameworks like GLaM (Graph-aligned Language Mannequin) symbolize one other revolutionary method to leveraging information graphs for LLM fine-tuning. GLaM works by reworking a information graph into an alternate textual illustration that features labeled question-answer pairs derived from the graph’s construction and content material. This reworked information is then used to fine-tune the LLM, successfully grounding the mannequin immediately within the information contained throughout the graph. This direct alignment with graph-based information enhances the LLM’s capability for reasoning based mostly on the structured relationships current within the KG.
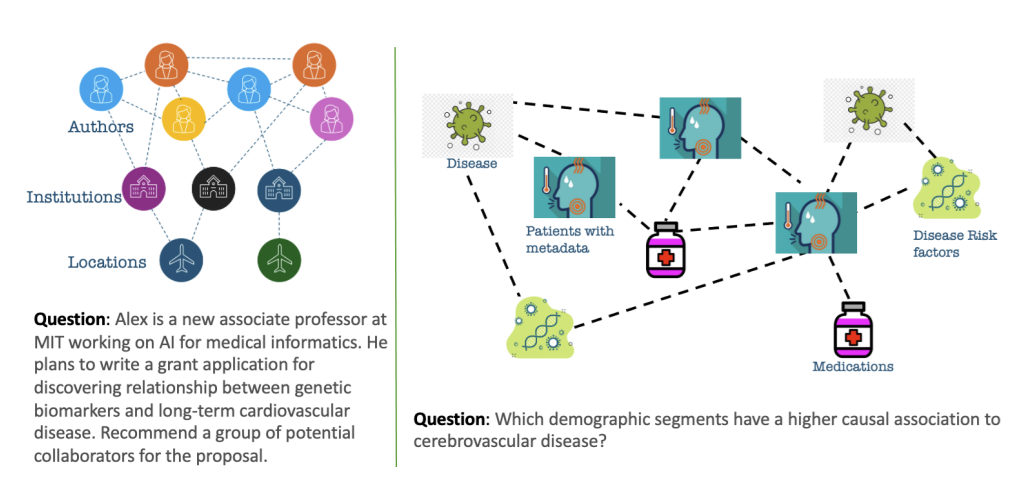
Determine 1: Motivating examples for aligning foundational fashions with domain-specific information graphs. The left determine demonstrates a question the place a LLM must be built-in with a information graph derived from a social community. The precise determine demonstrates a necessity the place a LLM must be built-in with a patient-profiles to illness community extracted from an digital healthcare information database (Supply: GLaM: Wonderful-Tuning Giant Language Fashions for Area Information Graph Alignment by way of Neighborhood Partitioning and Generative Subgraph Encoding)
For sure duties that closely depend on structured information, this method can function an environment friendly various to strategies based mostly on Retrieval-Augmented Technology (RAG). By immediately aligning the LLM with the construction of the information graph in the course of the fine-tuning part, a deeper integration of information and improved reasoning capabilities will be achieved. As a substitute of simply retrieving info from a KG on the time of inference, this technique goals to internalize the graph’s structural info throughout the LLM’s parameters, permitting it to cause extra successfully in regards to the relationships between entities.
Instruction Wonderful-tuning for Information Graph Interplay
LLMs will also be instruction fine-tuned to enhance their capability to work together with information graphs. This entails coaching the LLM on particular directions that information it in duties reminiscent of producing queries in graph question languages like SPARQL or extracting particular items of knowledge from a KG. Moreover, LLMs will be prompted to extract entities and relationships from textual content, which might then be used to assemble information graphs. Wonderful-tuning the LLM on such duties can additional improve its understanding of information graph constructions and enhance the accuracy of knowledge extraction.
After present process such fine-tuning, LLMs will be extra successfully used to automate the creation of information graphs from unstructured information and to carry out extra subtle queries towards current KGs. This course of equips LLMs with the particular abilities required to successfully navigate and make the most of the structured info contained inside information graphs, resulting in a extra seamless integration between the 2.
Attaining Superior LLM Efficiency and Reliability
The improved LLM fine-tuning capabilities enabled by information graphs present a compelling new cause for organizations to take a position on this know-how, notably within the age of GenAI. This method affords vital advantages that immediately handle the constraints of each conventional LLMs and conventional fine-tuning strategies. Wonderful-tuning LLMs with information derived from verified information graphs considerably reduces the prevalence of hallucinations and enhances the factual accuracy of their outputs. Information graphs function a dependable supply of fact, offering LLMs with a basis of verified info to floor their responses.
As an illustration, a information graph can present real-world, verified info, permitting AI to retrieve correct info earlier than producing textual content, thereby stopping the fabrication of knowledge. In vital purposes the place accuracy is paramount, reminiscent of healthcare, finance, and authorized domains, this functionality is essential. By considerably lowering the technology of incorrect info, organizations can deploy LLM-powered options in these delicate areas with larger confidence and belief.
In regards to the Creator: Andreas Blumauer is Senior VP Development, Graphwise the main Graph AI supplier and the newly fashioned firm as the results of the current merger of Ontotext with Semantic Net Firm. To study extra go to https://graphwise.ai/ or observe on Linkedin.
Associated Objects:
The Way forward for GenAI: How GraphRAG Enhances LLM Accuracy and Powers Higher Choice-Making
Why Younger Builders Don’t Get Information Graphs