
 to accelerate the growth of innovative applications. By marrying Cerebras’ Wafer-Scale Engine (WSE) with DataRobot’s AutoPilot, this potent partnership enables rapid creation, deployment, and iteration of high-performance ML models, propelling the development of transformative AI solutions at unprecedented speed.")
{kind=link}
Customers expect faster, more intelligent, and hyper-responsive experiences from you. When giant language models are slow to respond, human expertise atrophies? Each millisecond counts.
By deploying Cerebras’ accelerated inference endpoints, organizations can significantly reduce latency, accelerate model response times, and maintain exceptional quality even at massive scales with models like Llama 3.1-70B. By simplifying a few straightforward processes, you’ll be empowered to tailor and deploy your personalized Large Language Models (LLMs), thereby enabling you to fine-tune performance for unique speed and quality requirements.
On this blog, we’ll guide you through the steps to:
- Arrange Llama 3.1-70B within the .
- To generate and apply an API key to leverage Cerebras for inference, you need to follow these steps:
Firstly, you have to create a new project in your Cerebras account by going to the Cerebras dashboard and clicking on “Create Project”.
- Deploy strategic initiatives more swiftly to achieve transformative results.
With our advanced technology, you’ll be empowered to rapidly deploy Large Language Models (LLMs) that deliver exceptional velocity, precision, and real-time responsiveness, revolutionizing your applications’ performance.
Streamline development of language models with a centralized hub.
Developing prototypes for generative AI fashion often necessitates cobbling together disparate tools in an ad hoc manner. By leveraging well-defined retrieval strategies, robust analysis metrics, and streamlined workflows, developers can accelerate the translation of innovative ideas into functional prototypes while minimizing obstacles along the way.
By leveraging a comprehensive AI platform, developers can effortlessly create sophisticated applications that deliver tangible results without the tedious process of integrating disparate tools.
Let’s explore a practical scenario that showcases how you can harness these features to.
Low latency is crucial for developing prompt and reactive AI applications. High-quality results do not necessarily come at the expense of rapid response times.
The platform’s velocity enables builders to create applications that surpass expectations, delivering a seamless, intuitive, and intelligent user experience.
By combining intuitive growth expertise with other strategies, you can effectively.
- for sooner person interactions.
- with new fashions and workflows.
- Immediate responses foster instant connections.
Diagrams showcasing Cerebras’ impressive performance on LLaMA 3.1-70B demonstrate significantly faster response times and reduced latency compared to other platforms. This enables rapid iteration and real-time efficiency in manufacturing processes.
As large language models evolve to produce more sophisticated and comprehensive responses, they pay the price in terms of increased latency? Cerebras addresses this challenge through the strategic combination of optimized computational pathways, streamlined knowledge transfer protocols, and innovative decoding strategies, all engineered to accelerate performance.
Velocity enhancements are revolutionizing AI applications across industries such as pharmaceuticals and voice-assisted artificial intelligence. For instance:
- GlaxoSmithKline leverages Cerebras’ Inference technology to accelerate the drug discovery process, thereby boosting productivity.
- Has significantly accelerated the processing speed of ChatGPT’s voice mode pipeline, enabling prompter response times than traditional inference methods.
The outcomes are measurable. By leveraging the Llama 3.1-70B on Cerebras, organisations can accelerate inference by a staggering 70 times compared to traditional graphics processing units (GPUs), thereby facilitating seamless, real-time engagements and expedited experimentation loops.
Cerebras’ WSE-3, their third-generation Wafer-Scale Engine, fuels efficiency through its custom-designed processor optimized for tensor-based, sparse linear algebra operations that are fundamental to large language model inference.
By optimizing efficiency, effectiveness, and adaptability, the WSE-3 enables expedited, consistently superior model performance.
Cerebras Inference’s innovative architecture significantly minimizes latency in AI-powered applications fueled by its proprietary models, thereby empowering deeper cognitive processing and more intuitive user interactions. By hosting these optimised styles on the Cerebras platform, users can effortlessly integrate them into their workflow via a streamlined, single-endpoint access point, thereby minimizing setup complexities and expediting adoption.
By integrating Large Language Models (LLMs) like Llama 3.1-70B from Cerebras, you can streamline the process of customizing, checking, and deploying AI fashion models in just a few steps, facilitating accelerated growth, interactive testing, and enhanced management over LLM customization.
1. To generate an API key for Llama 3.1-70B within the Cerebras platform, please follow these steps:
1. Log in to your Cerebras account and navigate to the “API Keys” tab.
2. Click on the “Generate New Key” button.
3. Select “Llama 3.1-70B” as the API key type from the dropdown menu.
4. Enter a label for your new API key, such as “Llama 3.1-70B”.
5. Click on the “Generate” button to create the new API key.
Once you’ve generated the API key, you can find it in the “API Keys” tab of your Cerebras account.
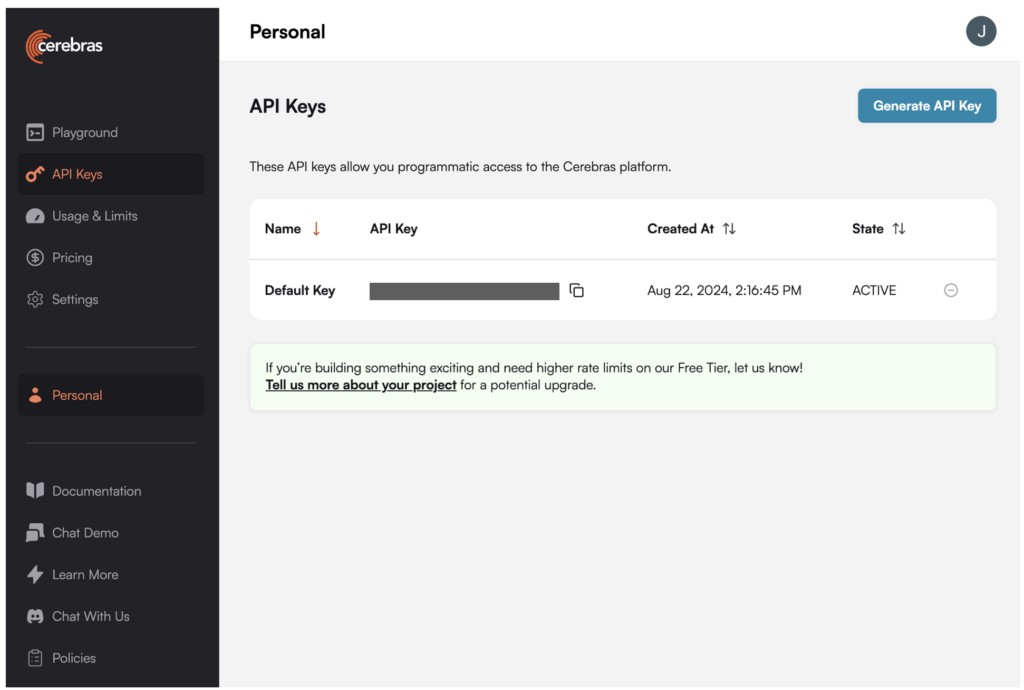
2. In the DataRobot Mannequin Workshop, create a tailored model that invokes the Cerebras endpoint hosting Llama 3.1 70B.
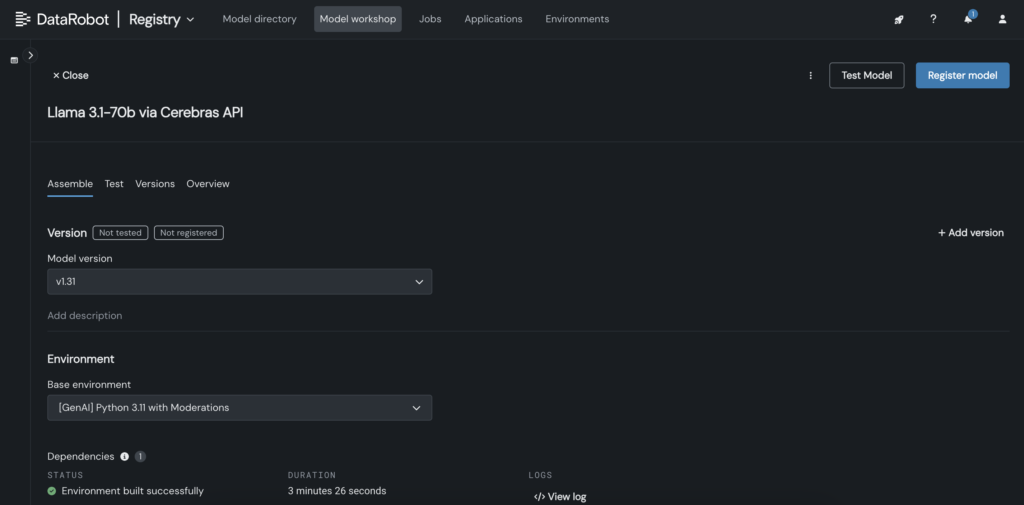
3. Inside the customised mannequin, insert the Cerebras API key within the customised.py file.
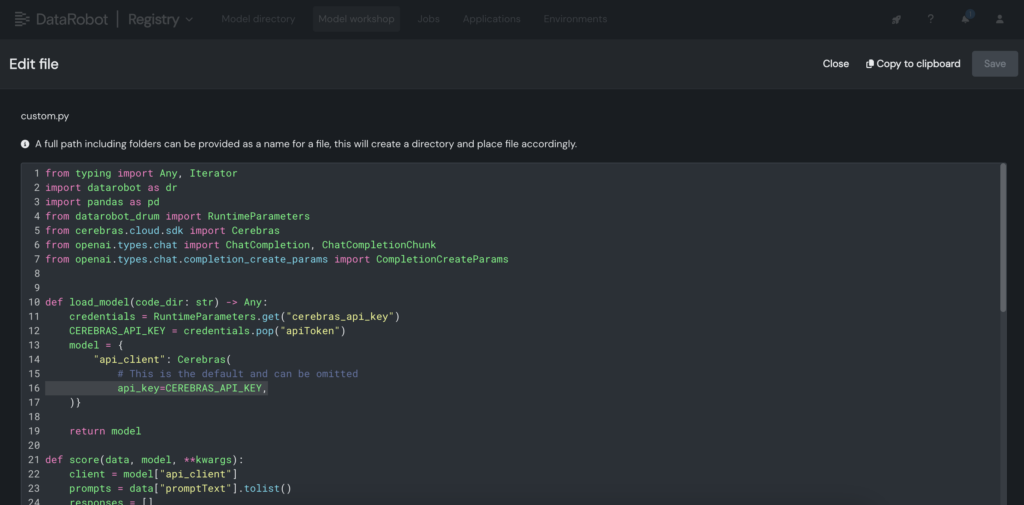
4. Deploy the tailored mannequin to a designated endpoint within the DataRobot Console, thereby empowering LLM blueprints to utilize it for predictions.
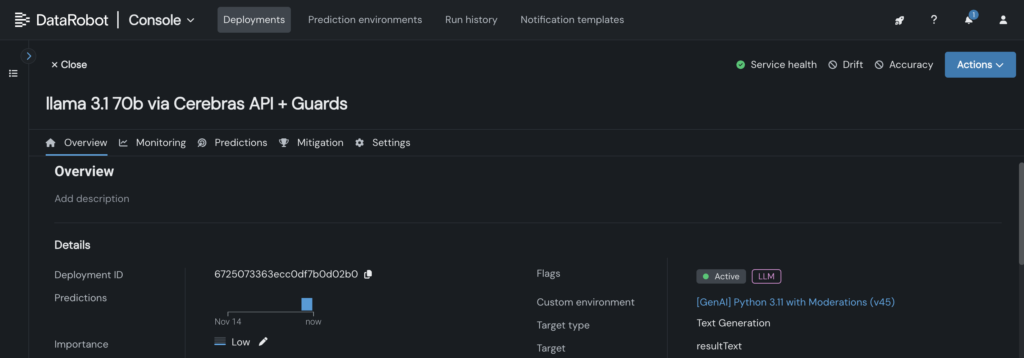
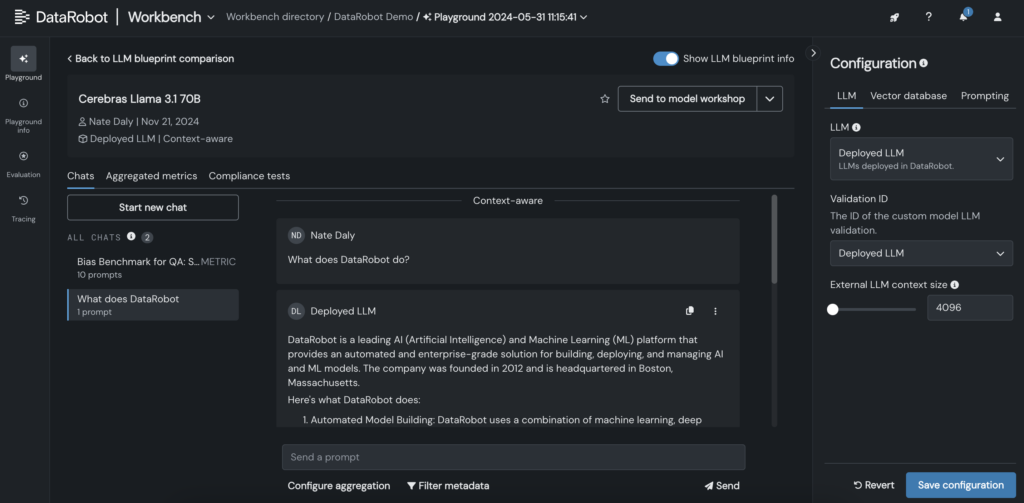
5. Deployed Cerebras Large Language Model (LLM) is added to the LLM blueprint within the DataRobot LLM Playground, initiating a conversational experience with Llama 3.1-70B.
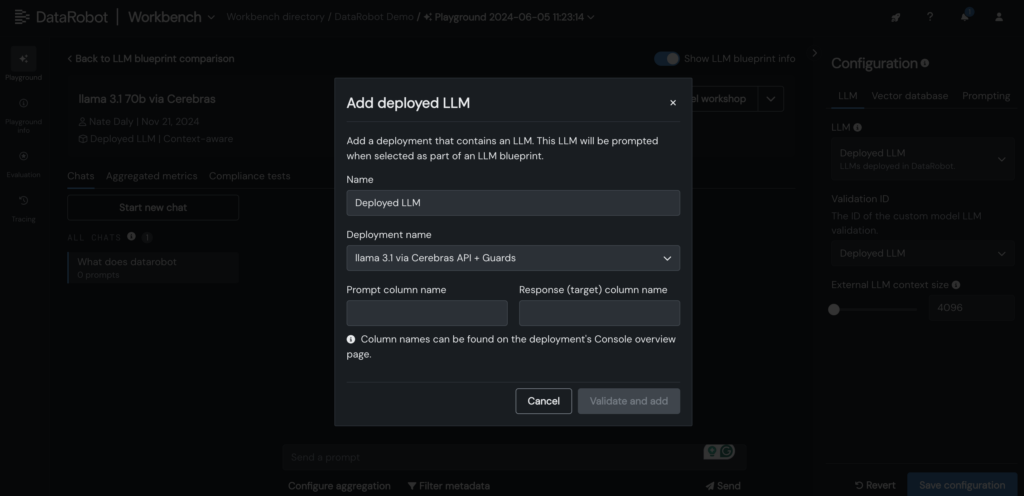
6. Upon incorporating the Large Language Model into the blueprint, promptly inspect responses by fine-tuning prompting and retrieval parameters, and scrutinize outputs utilizing various LLMs directly within the intuitive DataRobot interface.
Can we push the limits of language model inference further to unlock new possibilities for artificial intelligence?
Deploying large language models like Llama 3.1-70B, which demand exceptional latency and real-time responsiveness, is an undertaking of considerable complexity. With the right instruments and workflows, you can achieve both.
By seamlessly integrating large language models (LLMs) within DataRobot’s LLM Playground and harnessing Cerebras’ optimized inference capabilities, businesses can streamline customization, accelerate testing, and minimize complexity – all while maintaining the high performance their users expect.
As language models (LLMs) continue to advance in sophistication and capability, the need for an efficient framework for testing, customization, and integration becomes increasingly critical for organizations seeking to stay ahead of the curve.
Discover it your self. Create your API key and start building today!
Concerning the creator

Kumar Venkateswar serves as Vice President of Product, Platform, and Ecosystem at DataRobot. As Head of Product Administration, he oversees foundational providers and ecosystem partnerships at DataRobot, seamlessly connecting sustainable infrastructure with AI-driven solutions to optimize outcomes. Prior to joining DataRobot, Kumar worked at Amazon and Microsoft, holding key product management positions in the teams responsible for Amazon SageMaker and Amazon Q Enterprise.

Nathaniel Daly serves as Senior Product Supervisor at DataRobot, focusing on the development of AutoML and time-series products. He focuses on applying knowledge advancements to help clients unlock value and tackle real-world business challenges effectively. He earned a degree in Arithmetic from the University of California, Berkeley.