

{kind=link}
Organizations frequently waste considerable time investigating issues, applying fixes, and rebooting faulty processes. Engineers often dedicate their entire working day to meticulously examining and troubleshooting their projects.
With our recent enhancements, knowledge engineers can now easily monitor and identify areas that require attention in their work processes. When a job runs unexpectedly slow or encounters an error, promptly identify the root cause and swiftly rectify the underlying problem to ensure seamless process execution.
Job runs are displayed in a chronological timeline.
To maximize efficiency and optimize a workflow, the initial step involves identifying where most time is being devoted. In a sophisticated knowledge ecosystem, searching for information can sometimes resemble an exercise in futility, akin to finding a needle amidst a vast and seemingly endless haystack. The innovative Timeline view presents job runs as visually intuitive horizontal bars on a chronological axis, effectively illustrating activity dependencies, duration, and status updates. The feature enables you to swiftly identify performance bottlenecks and time-consuming zones within your DAG workflows. By providing a comprehensive view of interconnected tasks and pinpointing where bottlenecks occur, the Timeline View optimizes workflow and amplifies productivity.
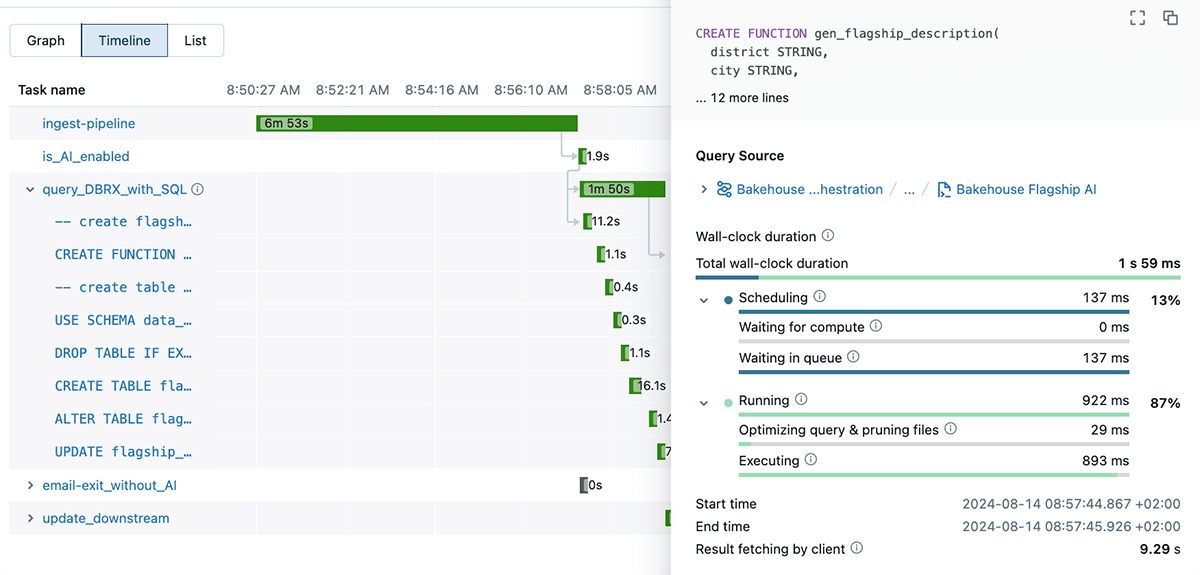
Rapidly Access Job Status: Unlock Critical Insights into Project Milestones
Monitoring the progress of workflow runs can often prove opaque and laborious, requiring tedious review of detailed logs to extract critical troubleshooting information. We’ve developed run scenarios that enable instant visualization of progress within the product, empowering users to track their journey in real-time. Occasions that are crucial and relevant, such as computing startup and shutdown, customer initiation of runs, retries, standing adjustments, and notifications, among others, can be easily discovered with this function.
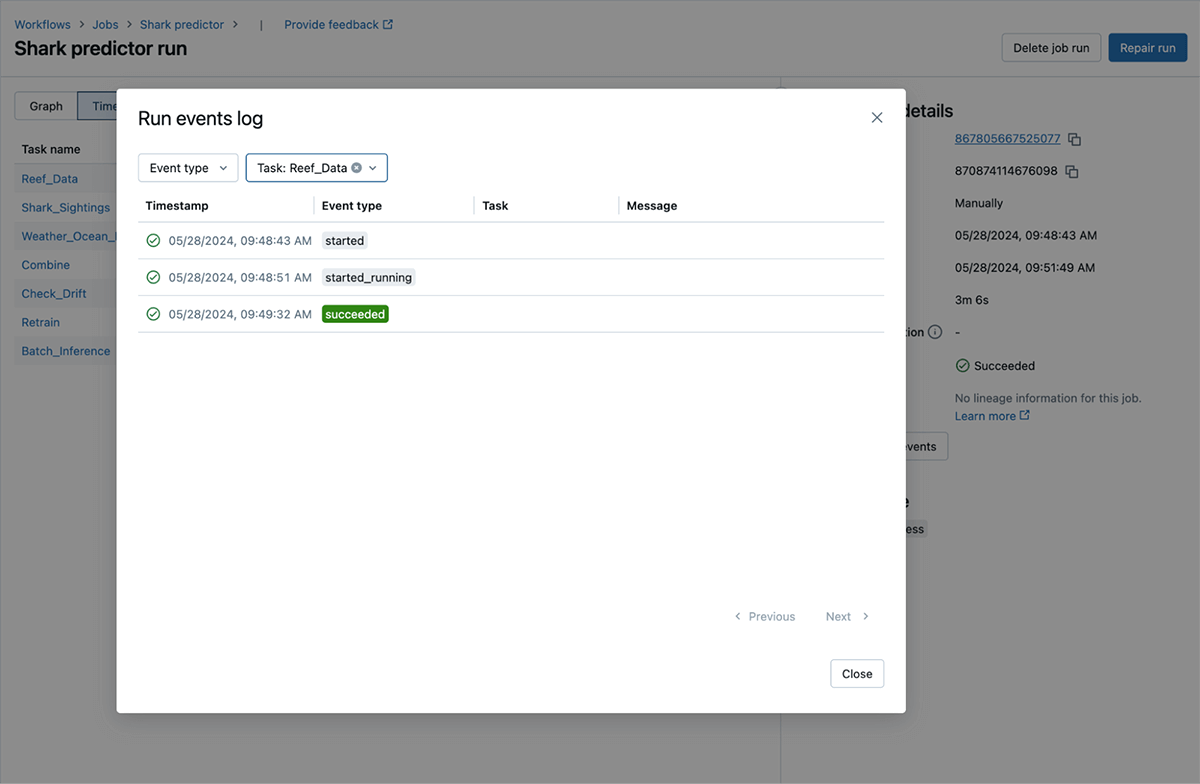
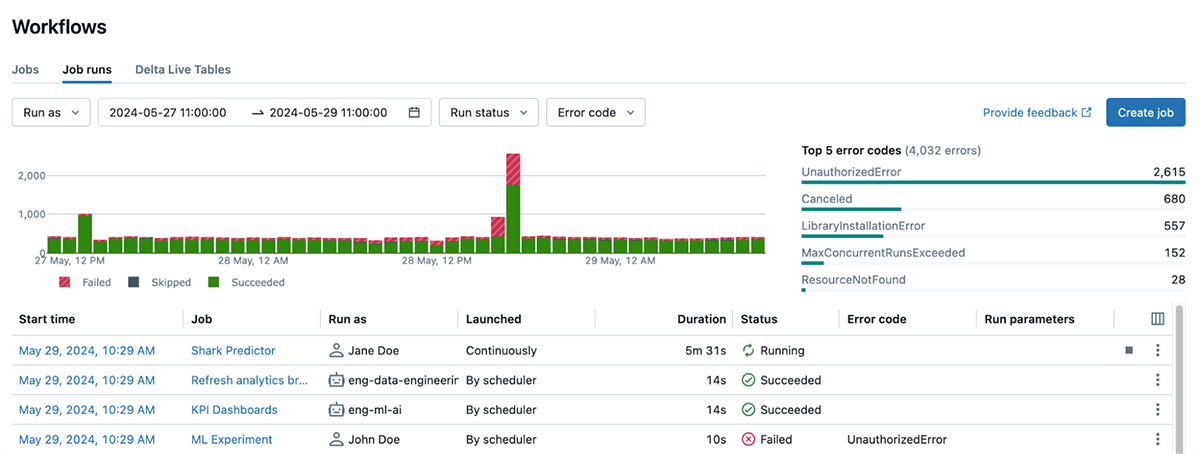
Higher, easier, and actionable errors
Navigating error messages often proves to be a frustrating experience, as the complexity and inconsistency of these notifications can lead to prolonged periods of troubleshooting. By refining our error codes, we’ve made them both straightforward and practical in nature. By leveraging this tool, you can effectively track and identify unusual mistakes that may arise during job execution, streamline the process of filtering runs based on specific error codes, and promptly address any job failures to minimize downtime. These concise error descriptions facilitate swift comprehension of where errors occurred, eliminating the need to sift through verbose logs or painstakingly review entire codebases. An UnauthorizedError during a run can indicate a permissions issue hindering access to the necessary resource required for the job execution.
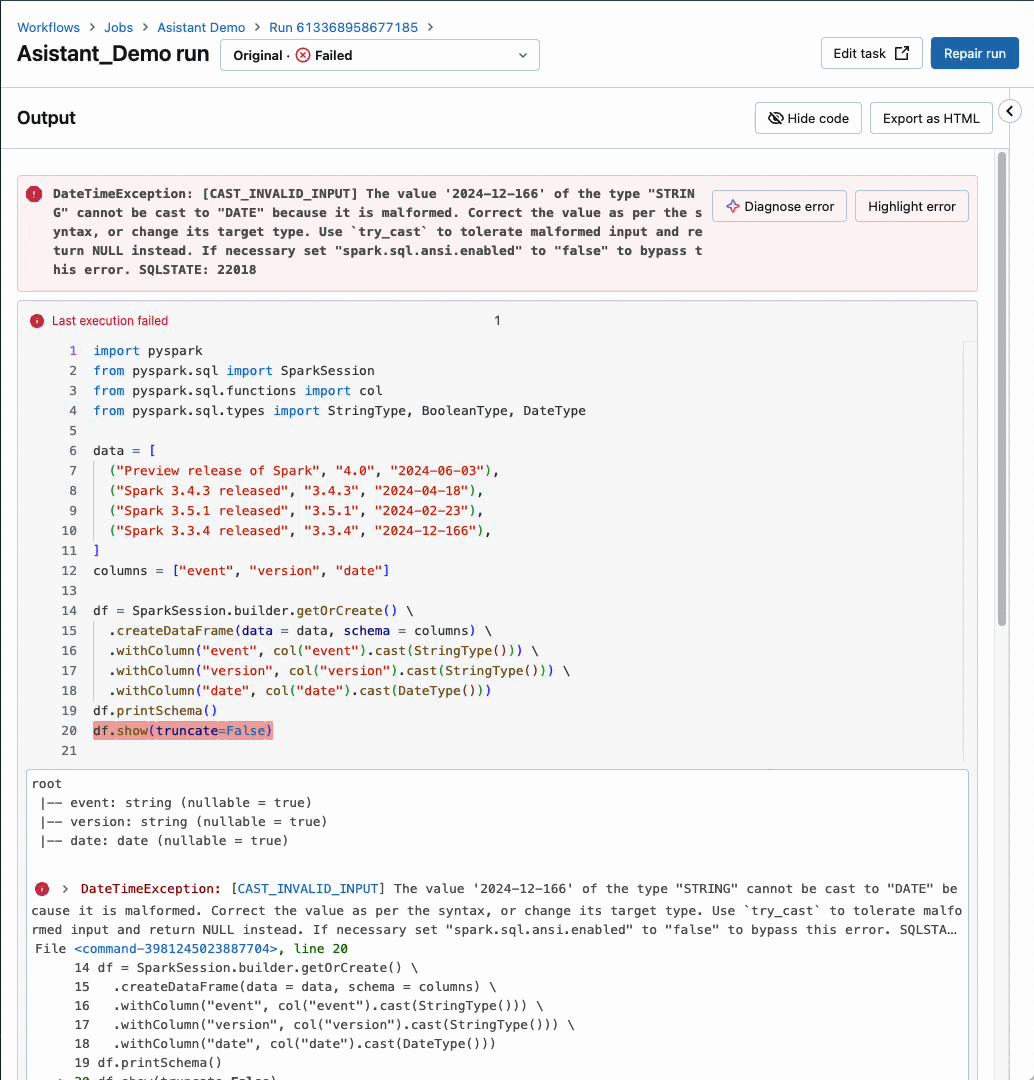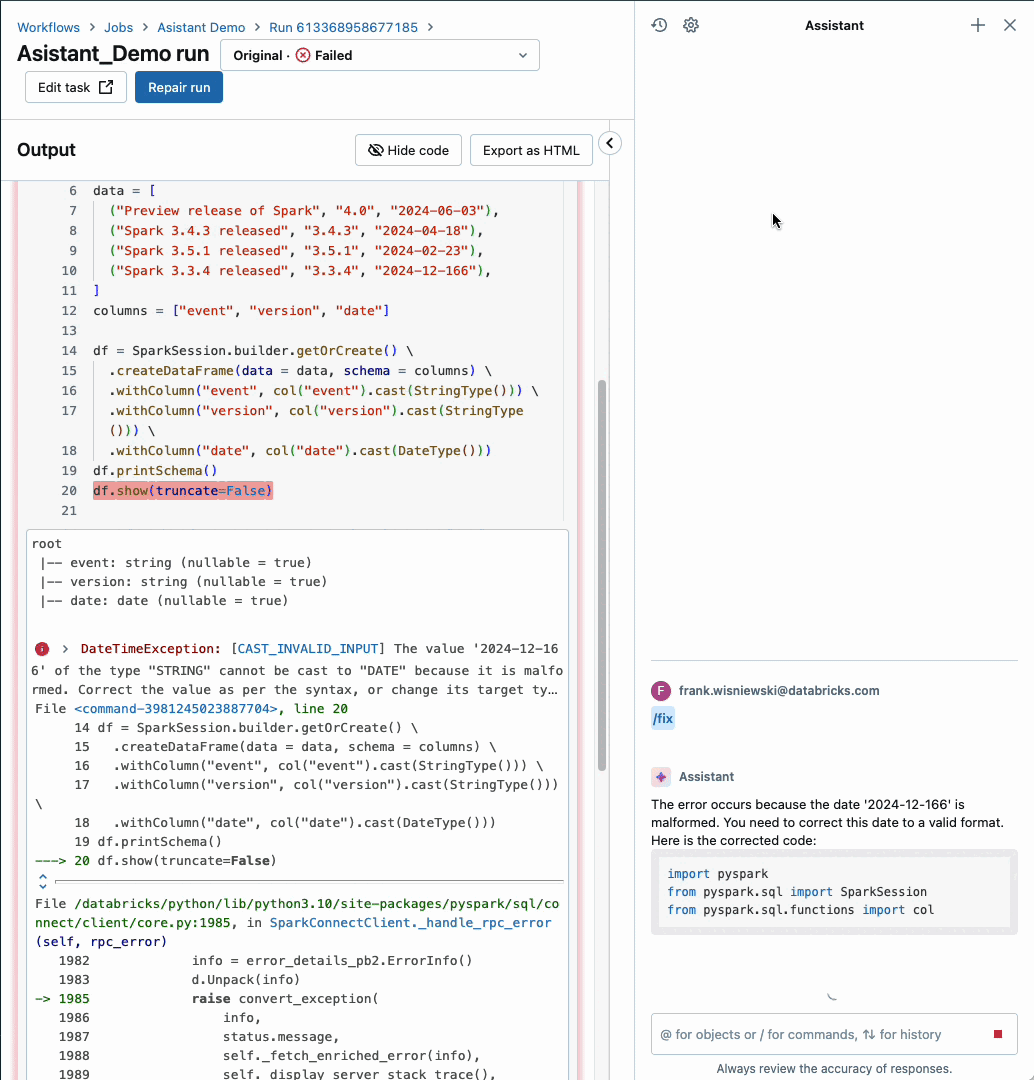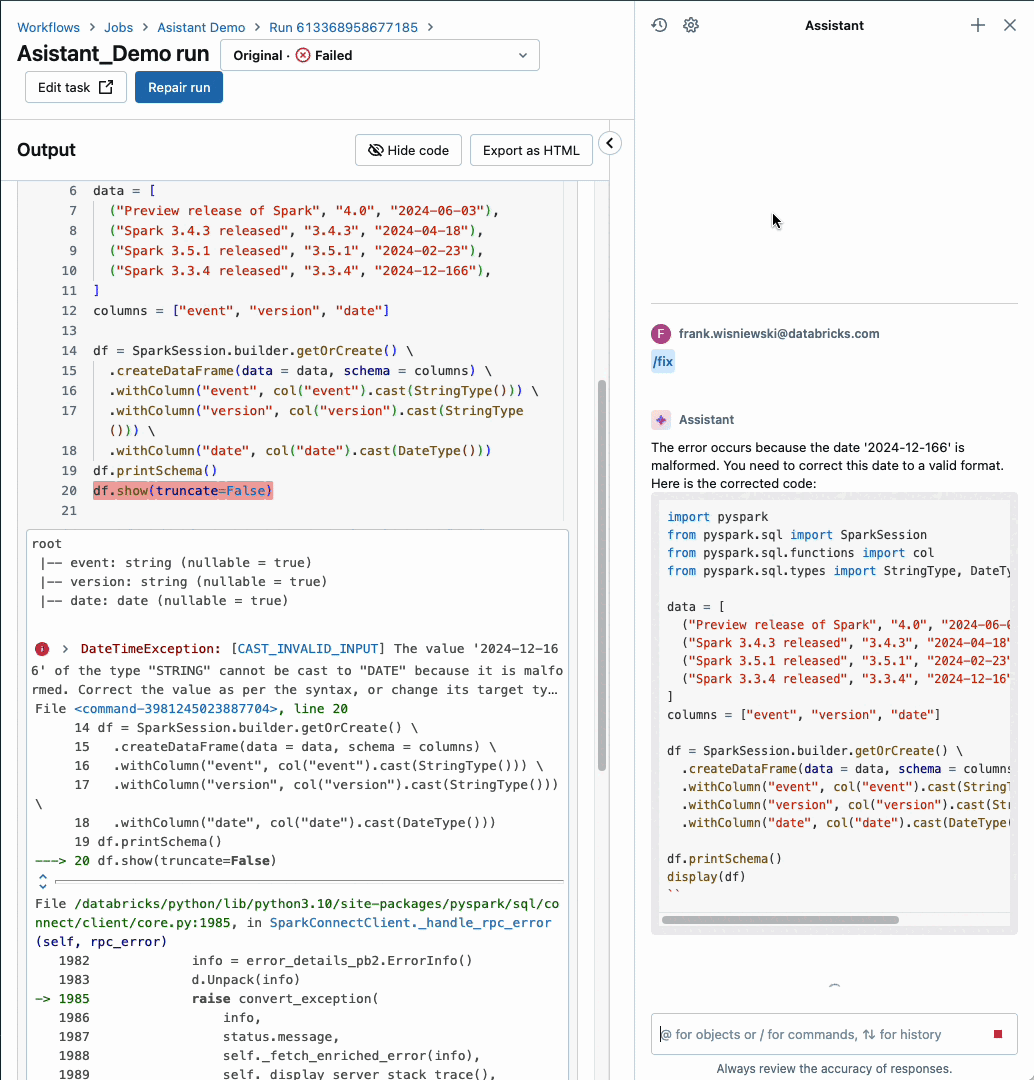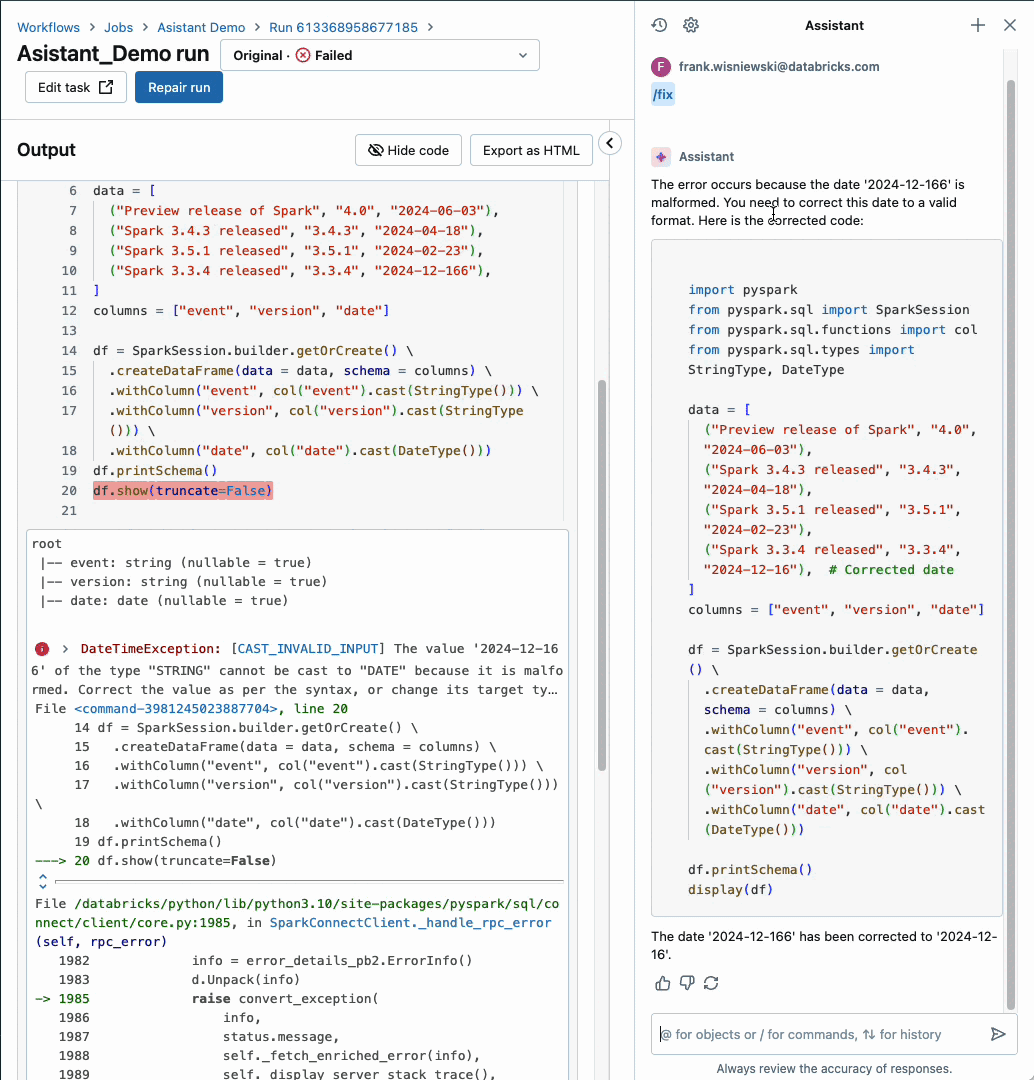
Databricks Assistant is now seamlessly integrated within Databricks Workflows, allowing users to effortlessly leverage the power of automated workflows and AI-driven insights.
Our AI-driven Insights Platform, empowered by machine learning algorithms, effectively identifies job failures and provides actionable guidance on how to troubleshoot and rectify issues for enhanced workflow efficiency. With our workflow assistant, you enjoy seamless context-aware support exactly where and when you need it most in Databricks Workflows. The function is currently optimized for handling pocket book duties alone, but support for other task types will be introduced shortly.
You have been tasked with creating a checklist of Python libraries that you commonly use for your jobs?
Here is what I came up with:
• **pandas**: For data manipulation and analysis.
• **numpy**: For numerical computations.
• **scikit-learn**: For machine learning tasks.
• **matplotlib** and/or **seaborn**: For creating plots and visualizations.
• **openpyxl**: For working with Excel files.
• ** requests**: For making HTTP requests.
• **BeautifulSoup**: For parsing HTML and XML documents.
• **lxml**: For parsing XML and HTML documents.
• **xarray**: For working with multidimensional data.
• **statsmodels**: For statistical modeling.
Let me know if this helps!
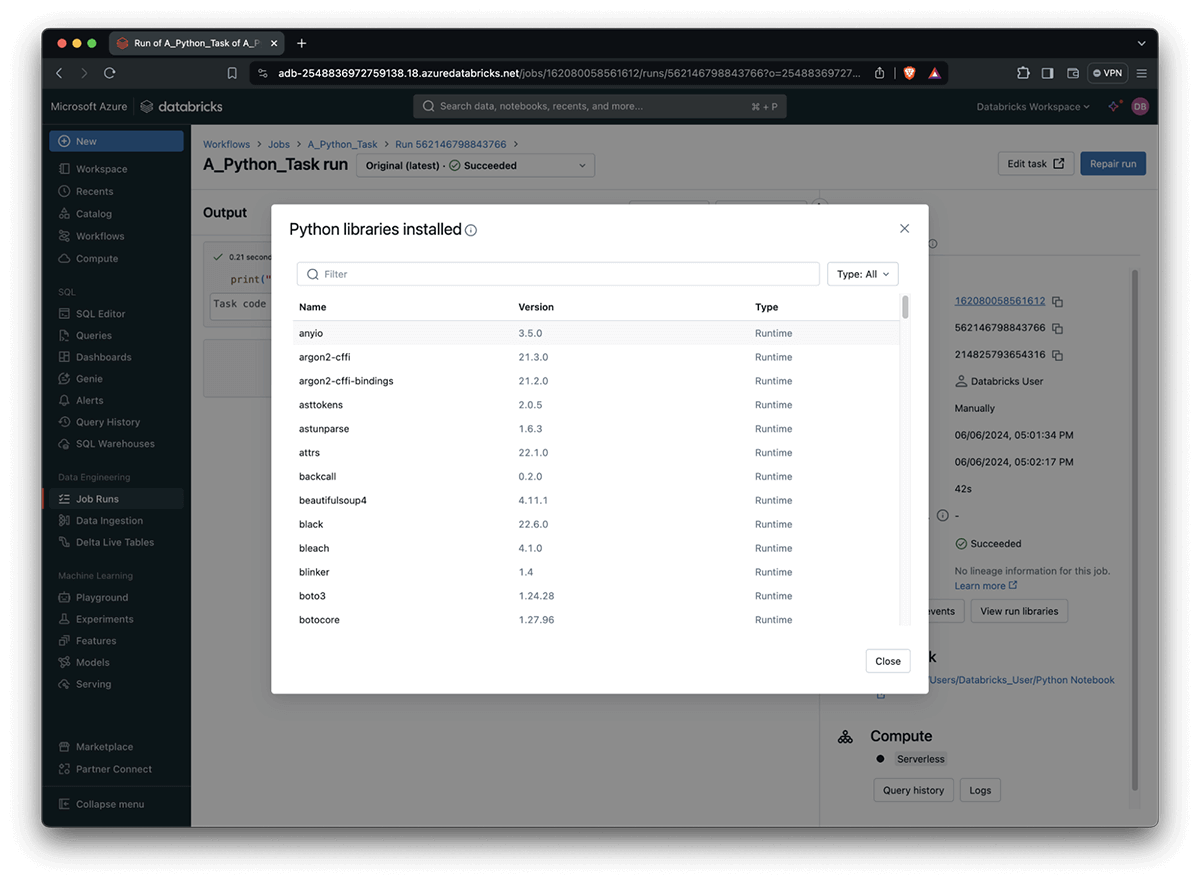
Debugging library issues often proves to be an exasperating and laborious ordeal due to the confluence of conflicting versions, damaged packages, and obscure error messages. Now you can check-list the Python libraries utilised by your activity, run along with the model quantity used? As Python packages are often pre-installed within the DBR environment or during bootstrap actions on your compute cluster, this makes it particularly useful. This functionality further emphasizes which of the aforementioned outcomes are encompassed by the bundled approach employed.
Starting a new journey requires a clear roadmap. Here are some tips to help you set off:
To get started with Databricks Workflows, please refer to the documentation. You possibly can strive these capabilities throughout Azure, AWS & GCP by merely clicking on the Workflows tab at the moment.
What’s Subsequent
Let’s expand our focus on refining monitoring, alerting, and management capacities. We’re engaged on new methods to search out the roles you care about by enhancing looking & tagging capabilities. We’re also interested in learning more about your areas of specialization and any other alternatives you might appreciate considering.