
, and tailoring custom generative AI designs to unlock unparalleled insights.")
{kind=link}
We’re thrilled to introduce a range of enhancements that empower builders to quickly develop sophisticated AI solutions with greater flexibility and choice, utilizing the Azure AI toolchain.
As businesses scale their AI capabilities, Azure is committed to offering an unparalleled breadth of options and a comprehensive toolkit to address the unique, complex, and diverse needs of modern organizations. This innovative blend of cutting-edge technologies and tailored fashion enables construction teams to develop bespoke solutions rooted in their collective expertise.
We’re thrilled to unveil a series of enhancements designed to empower builders to quickly craft AI solutions that are more versatile and adaptable, utilizing our streamlined toolchain.
- Significant upgrades to the Phi family of fashion platforms, now featuring a cutting-edge Combination of Experts (CoE) model and support for over 20 languages.
- Azure AI’s Jamba 1.5 Massive and Jamba 1.5 on Azure AI fashion themselves as a service, offering innovative solutions.
- Streamlined Retrieval Augmented Technology (RAG) pipelines are enhanced by leveraging built-in vectorization capabilities, which seamlessly integrate knowledge preparation and embedding processes.
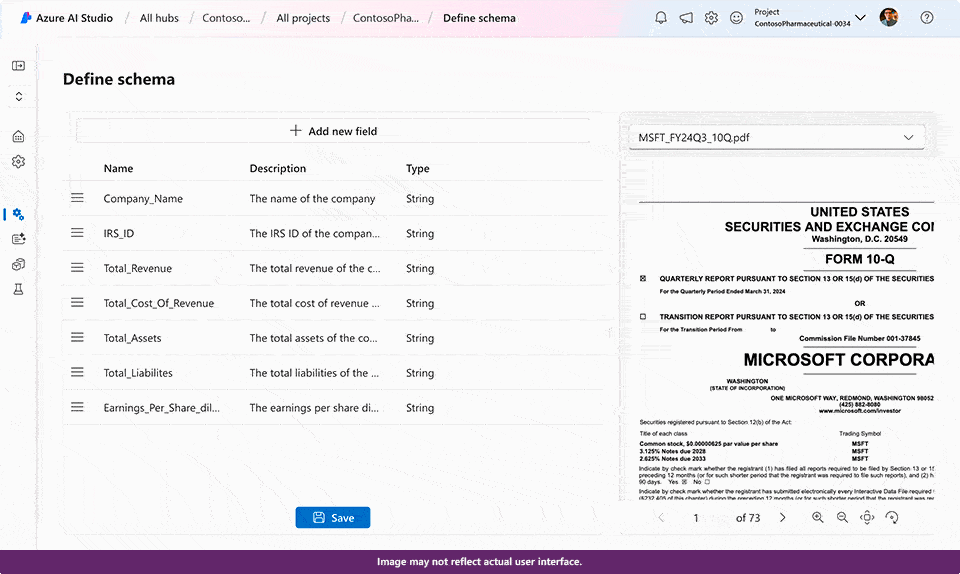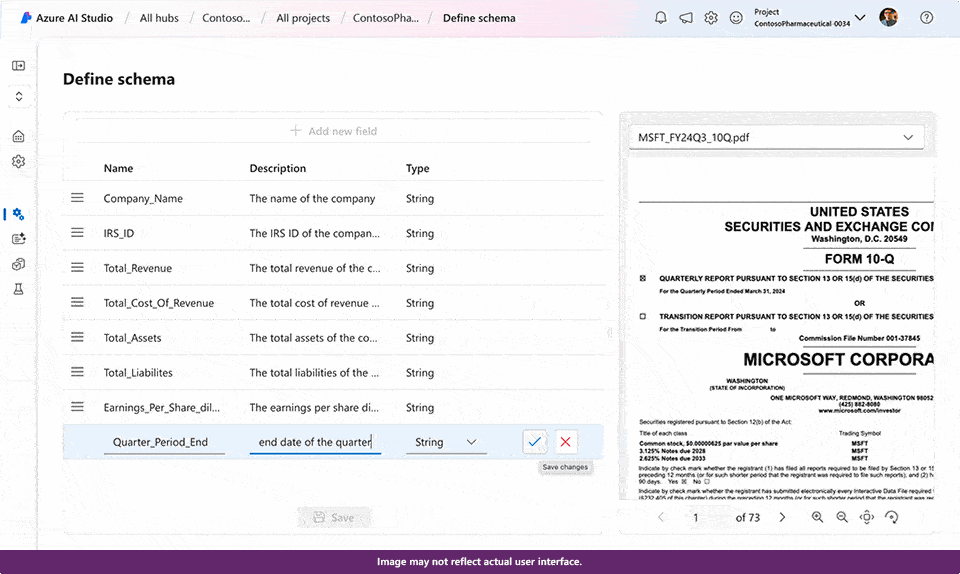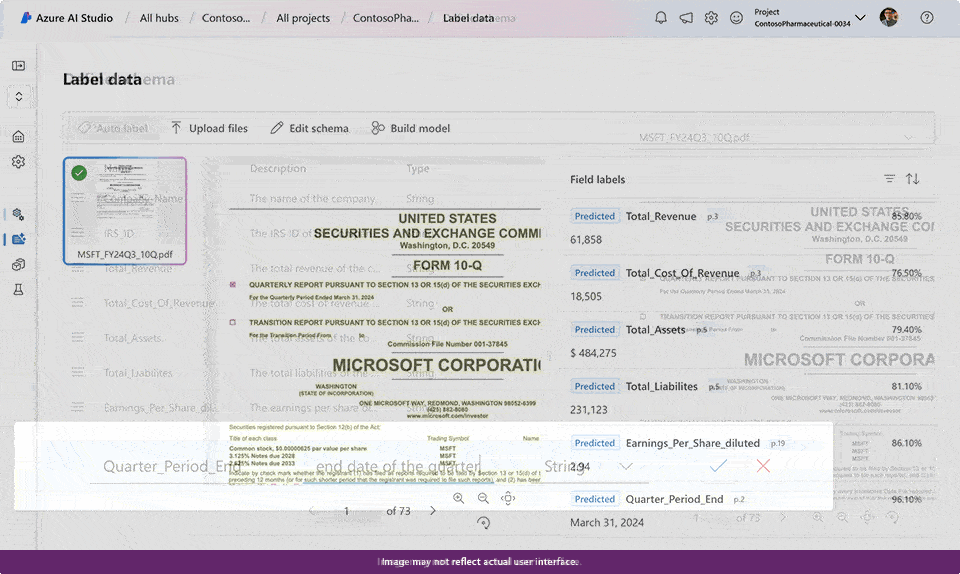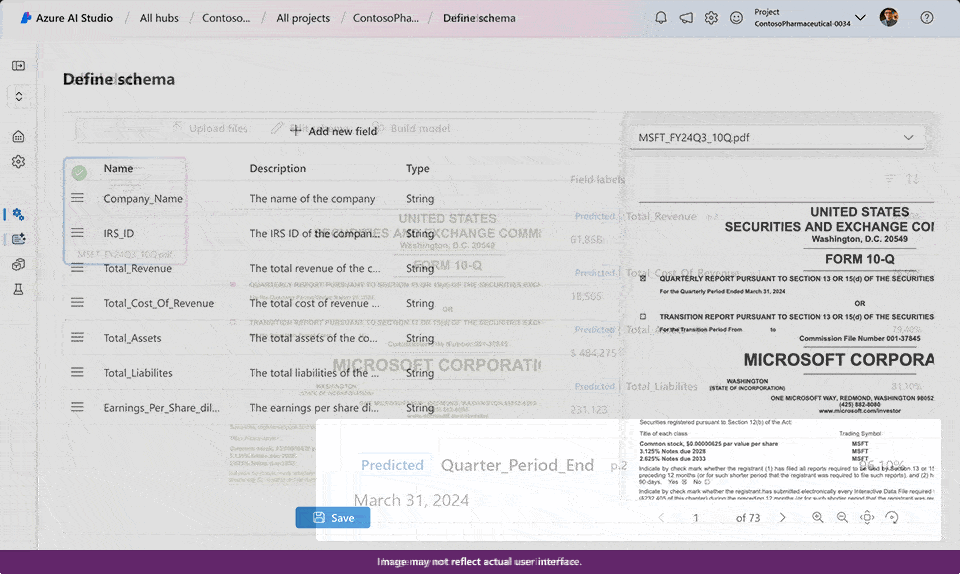
- Azure AI Document Intelligence enables the development of tailored generative extraction styles, allowing for highly accurate extraction of custom fields from unstructured documents.
- The ultimate availability of this cutting-edge service feature, dubbed “natural-sounding voices” and photorealistic avatars, revolutionizes the way buyers engage with product offerings across multiple languages and voice options, thereby elevating overall expertise and experience.
- Is the Conversational PII Detection Service finally available to customers in Azure AI Language?
Why not leverage the versatility of the Phi mannequin system by augmenting it with additional language capabilities and optimizing its processing power to streamline household tasks?
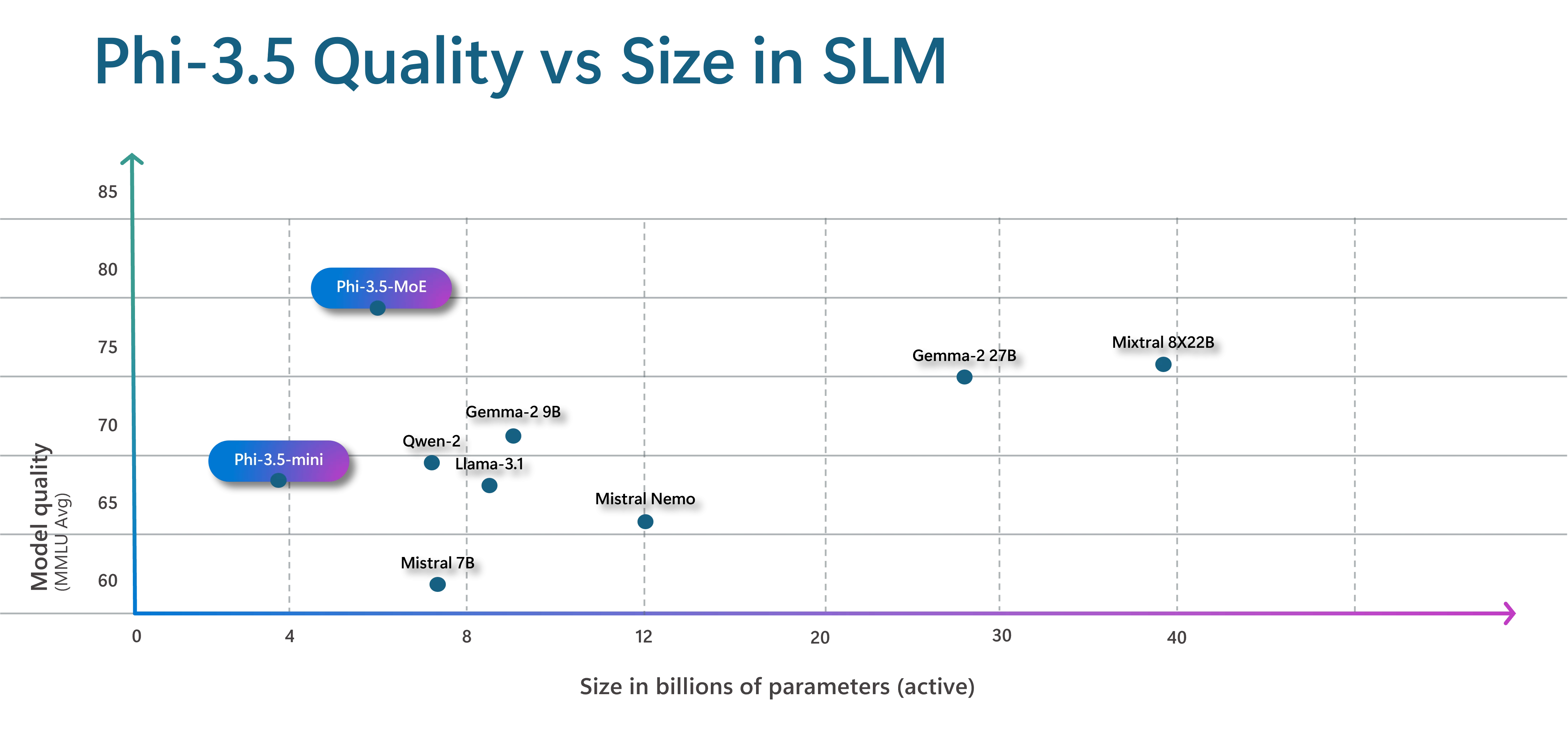
Introducing Phi-3.5 MoE, a groundbreaking addition to the Phi family: a cutting-edge Combination of Consultants mannequin. This integrated mannequin merges the capabilities of 16 individual experts, resulting in a significant upgrade to its overall quality and a reduction in latency. While the mannequin is defined by 42B parameters, its MoE design enables it to utilize only 6.6B active parameters simultaneously by allocating subsets of parameters (specialists) during training and then leveraging the relevant specialists at runtime for specific tasks. By leveraging this innovative approach, clients can reap the benefits of rapid processing speeds and computational efficiency typically associated with smaller models, while still enjoying the rich spatial data and enhanced output quality often characteristic of larger models. Discovering the Synergies: How Our Hybrid Approach with Multiple Experts Amplified Results.
We are introducing a novel mini model, phi-3.5 Mini. The all-new MoE model and its mini variant are both multilingual, capable of supporting. The added languages enable users to collaborate seamlessly with the model in their native language, fostering a more intuitive and effective interaction.
Although boasting advanced language capabilities, the newly introduced Phi-3.5-mini model still maintains its compact size with only 3.8 billion parameters.
Corporations such as CallMiner, leaders in conversational intelligence, are opting for Phi frameworks due to their speed, precision, and security.
As Bruce McMahon, CallMiner’s Chief Product Officer states:
We’re introducing Steerage to the Phi-3.5-mini serverless endpoint to ensure outputs are exceptionally predictable and align with the expected construction of a utility.
Steerage is an open-source framework (boasting over 18K GitHub stars) that empowers developers to declaratively specify programmatic constraints within a single API name, thereby ensuring structured output in JSON, Python, HTML, and SQL, regardless of the use case or requirements. You can eliminate expensive retries using Steerage, which allows you to restrict the model to select from predefined lists, for instance, limiting output to specific medical codes, prohibiting quotes from provided context, or conforming to a given regex pattern. Steering the mannequin token-by-token through the inference stack enables it to generate higher-quality outputs while reducing computational costs and latency by up to 30-50% in highly structured scenarios.
We’re also upgrading the Phi imagination model by incorporating multi-frame support. This innovative Phi-3.5-vision model, boasting 4.2 billion parameters, enables sophisticated reasoning across multiple input images, opening up novel scenarios where it can identify nuances and variations between photographs.


At its core, Microsoft is committed to driving the development of secure and responsible artificial intelligence, empowering developers with a robust set of tools and capabilities.
Builders collaborating with Phi Fashions can evaluate high-quality and security by utilising both pre-built and customised metrics, thereby informing critical mitigation strategies? Provides built-in controls and guardrails that offer immediate safeguards and safeguarded material detection capabilities. These capabilities will be leveraged across various industries, including fashion, seamlessly integrating with Phi and other systems through a unified API. As manufacturers set out to build, they can ensure high-quality construction, safeguard against sudden and malicious attacks, and protect intellectual property by acting promptly in response to real-time warnings, thereby preventing potential breaches.
Introducing AI21 Jamba 1.5: Unlocking the Power of Large-Scale Language Models on Azure AI’s Fashionable Services
To expand its offerings to builders and provide unparalleled access to a diverse range of styles, we are pleased to introduce two new open models, Jamba 1.5 Massive and Jamba 1.5, now available in the Azure AI model catalog. Fashions leveraging the Jamba architecture combine Mamba and Transformer layers to facilitate efficient processing of extended contextual information in an environmentally sustainable manner.
While the Jamba 1.5 Massive and Jamba 1.5 Fashion may be considered standout models in the Jamba series, they are likely to be among the most impressive offerings in terms of overall performance and features. The hybrid design leverages the Mamba-Transformer architecture to strike a harmonious balance between velocity, recall, and quality, combining the benefits of Mamba layers for handling local relationships and Transformer layers for modeling distant connections. Consequently, this household of fashion excellence stands out for its mastery of complex scenarios, well-suited for industries such as financial services, healthcare, and life sciences, as well as retail and consumer packaged goods.
Pankaj Kumar Duggal, Senior Vice President and General Manager of North America at AI21.
Red (R): High priority tasks that require human intervention, such as content moderation, fact-checking, and sensitive topic handling.
We’re simplifying RAG pipeline workflows by integrating comprehensive, end-to-end knowledge preparation and contextualization processes directly into the workflow. Organisations commonly employ RAG (Red-Amber-Green) indicators within generative AI functionalities to incorporate data on personal group-specific knowledge without necessitating model retraining. By leveraging techniques such as vector and hybrid retrieval, you can effectively surface relevant, well-informed information that is closely tied to a query, all while drawing upon your existing expertise. Despite the importance of vector search, prior knowledge preparation is essential to execute it effectively. Your application is designed to absorb, analyze, augment, integrate, and catalog diverse forms of knowledge, primarily sourced from multiple places, so that it can be leveraged within your co-pilot.
Currently, we are confirming the fundamental feasibility of native vectorization within Azure AI Search. Vectorization seamlessly integrates multiple processes, simplifying workflows through automation. By leveraging automated vector indexing and querying capabilities powered by integrated embedded models, your application unlocks the full potential of your data.
By enhancing developer productivity, vectorization enables organizations to provide turnkey RAG solutions as options for new projects, allowing teams to quickly build an application tailored to their specific datasets and requirements, without needing to construct a custom deployment each time.
Clients like SGS & Co, a worldwide model impression group, are streamlining their workflows with built-in vectorization.
—Laura Portelli, Product Supervisor, SGS & Co
With the latest advancements in AI technology, you can now efficiently extract tailored field data from unorganized documents with exceptional precision by developing and fine-tuning a bespoke generative model within the Doc Intelligence platform. The introduction of this innovative feature leverages the power of generative AI to swiftly extract consumer-specified data fields from a diverse array of visual templates and document types, streamlining workflows with unparalleled efficiency. You’ll begin with as few as 5 coaching sessions. Automated labeling enables the construction of tailored generative models by conserving time and effort previously spent on manual annotation, thus yielding results that are more effectively contextualized where applicable, with confidence scores readily available to swiftly eliminate low-quality extracted data and minimize manual evaluation time.
Craft immersive interactions by bringing your own personalized avatar to life, or explore prebuilt characters designed for unique playstyles.
Currently, we are thrilled to announce the availability of a key feature within our service, which is now readily accessible. This innovative service unleashes the power of lifelike voices and photorealistic avatars, available in diverse languages and tones, thereby elevating customer interactions and overall proficiency. With Total Tech Solutions (TTS) Avatar, architects can design bespoke and engaging environments for their clients and staff, thereby enhancing productivity and providing cutting-edge amenities.
The TTS Avatar service provides builders with a diverse range of pre-built avatars, featuring a comprehensive portfolio of natural-sounding voices, as well as the option to create custom artificial voices using Azure Custom Neural Voice. Moreover, these photorealistic avatars will be meticulously customized to align with an organization’s distinct brand identity. While utilizing a Text-to-Speech (TTS) avatar, the world’s first AI-powered wellbeing screening hub is brought to life.
—Dr. As Kasim, Chief Government Director and Chief Working Officer of Nura AI Well being Screening, I’m proud to lead a group that’s revolutionizing the way we consider well being.
As we bring this knowledge to market, ensuring responsible deployment and sustainable development of AI technology remains our top priority? Customized textual content to speech avatars: a platform where built-in security and robust security measures ensure seamless interactions. The system embeds invisible digital watermarks within avatar outputs to ensure authenticity and traceability. Accredited customers can verify whether a video has been created using Azure AI Speech’s avatar feature via watermarks. We also provide guidelines for responsible use of TTS avatars, including measures to promote transparency in consumer interactions, detect and mitigate potential bias or harmful artificial content, and learn how to integrate with other systems. We necessitate that all builders and content creators conform to our guidelines when utilizing TTS Avatar options alongside both prebuilt and custom-designed avatars.
You can leverage Azure Machine Learning (AML) capabilities within Visual Studio Code (VS Code) to streamline your machine learning workflows. By installing the Azure Machine Learning extension for VS Code, you’ll gain access to a range of features that enable seamless integration with AML services and improve your productivity.
With this extension, you can easily create and manage AML compute instances directly from within VS Code. This allows you to quickly spin up or shut down resources as needed, depending on the complexity of your machine learning models or the scale of your data processing tasks.
Additionally, you’ll be able to deploy your trained models to Azure Machine Learning without having to leave VS Code. This eliminates the need for manual copying and pasting between different environments, streamlining your workflow and reducing errors.
Moreover, the extension provides real-time feedback on your code as you write it, ensuring that your AML assets are correctly configured and free from common errors. This feature helps prevent issues at runtime, saving you valuable time and effort in debugging and troubleshooting.
Whether you’re working on a new machine learning project or refining an existing one, the Azure Machine Learning extension for VS Code is a powerful tool that can help you achieve greater efficiency and accuracy in your work.
We’re excited to announce the general availability of the VS Code extension for Azure Machine Learning.
The extension empowers you to create, configure, deploy, troubleshoot, and manage machine learning models directly from your preferred VS Code environment, seamlessly integrating with Azure Machine Learning, regardless of whether you’re working on a desktop or web platform. The extension’s enhanced features, including VNET support, IntelliSense, and seamless integration with Azure Machine Learning CLI, effectively position it for widespread adoption in production environments. Discover the nuances of the extension by devoting yourself to learning its intricacies and complexities?
Companies like Fashable have successfully brought these ideas to market.
Orlando Ribas Fernandes, Co-Founder and Chief Executive Officer,
Shield customers’ privateness
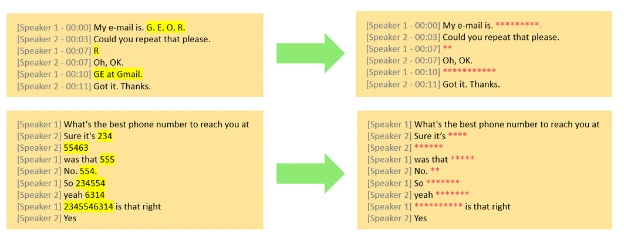
We’re pleased to announce that our Conversational PII Detection Service is now generally available within Azure AI Language, further expanding Azure AI’s capacity to identify and protect sensitive information in conversations, initially supporting the English language. Our service aims to strengthen the privacy and security of knowledge for developers creating generative AI applications for their organizations. Our advanced Conversational PII redaction solution empowers clients to identify, classify, and securely remove sensitive data, such as phone numbers and email addresses, from unstructured text content with precision. This specialized conversational PII mannequin is designed specifically to handle conversational-style inputs, particularly those found in speech transcriptions from conferences and calls.
Why not simplify this title to: **Self-Serve Your Azure OpenAI**
Recently, we unveiled enhancements to the Azure OpenAI Service, accompanied by the ability to manage your quota deployments independently within your Azure account, thereby enabling more flexible and efficient provisioning of Provisioned Throughput Units (PTUs). Upon the release of OpenAI’s latest model on August 7, we concurrently introduced support for the innovative Structured Outputs, including JSON Schemas, for the newly launched GPT-4o and GPT-4o mini models. Well-formatted structured outputs prove invaluable to developers who need to verify and format AI-generated data into standardized formats like JSON Schemas.
As we advance through the Azure AI stack, we’re empowered to deliver revolutionary innovations to our customers, enabling them to build, deploy, and scale their AI solutions with unparalleled safety and confidence. What new creations will you bring forth?