

{kind=link}
DeepSeek AI has simply launched its extremely anticipated DeepSeek R1 reasoning fashions, setting new requirements on the planet of generative synthetic intelligence. With a concentrate on reinforcement studying (RL) and an open-source ethos, DeepSeek-R1 delivers superior reasoning capabilities whereas being accessible to researchers and builders all over the world. The mannequin is about to compete with OpenAI’s o1 mannequin and infact has outperformed the identical on a number of benchmarks. With DeepSeek R1, it certainly has made lots of people marvel if is it an finish to Open AI LLM supremacy. Let’s dive in to learn extra!
What’s DeepSeek R1?
DeepSeek-R1 is a reasoning-focused giant language mannequin (LLM) developed to reinforce reasoning capabilities in Generative AI methods via the strategy of superior reinforcement studying (RL) strategies.
- It represents a big step towards bettering reasoning in LLMs, notably with out relying closely on supervised fine-tuning (SFT) as a preliminary step.
- Basically, DeepSeek-R1 addresses a key problem in AI: enhancing reasoning with out relying closely on supervised fine-tuning (SFT).
Progressive coaching methodologies energy the fashions to deal with complicated duties like arithmetic, coding, and logic.

Additionally Learn: Andrej Karpathy Praises DeepSeek V3’s Frontier LLM, Educated on a $6M Funds
DeepSeek-R1: Coaching
1. Reinforcement Studying
- DeepSeek-R1-Zero is educated solely utilizing reinforcement studying (RL) with none SFT. This distinctive method incentivizes the mannequin to autonomously develop superior reasoning capabilities like self-verification, reflection, and CoT (Chain-of-Thought) reasoning.
Reward Design
- The system assigns rewards for reasoning accuracy based mostly on task-specific benchmarks.
- It additionally provides secondary rewards for structured, readable, and coherent reasoning outputs.
Rejection Sampling
- Throughout RL, a number of reasoning trajectories are generated, and the best-performing ones are chosen to information the coaching course of additional.
2. Chilly-Begin Initialization with Human-Annotated Information
- For DeepSeek-R1, human-annotated examples of lengthy CoT reasoning are used to initialize the coaching pipeline. This ensures higher readability and alignment with person expectations.
- This step bridges the hole between pure RL coaching (which might result in fragmented or ambiguous outputs) and high-quality reasoning outputs.
3. Multi-Stage Coaching Pipeline
- Stage 1: Chilly-Begin Information Pretraining: A curated dataset of human annotations primes the mannequin with primary reasoning buildings.
- Stage 2: Reinforcement Studying: The mannequin tackles RL duties, incomes rewards for accuracy, coherence, and alignment.
- Stage 3: Fantastic-Tuning with Rejection Sampling: The system fine-tunes outputs from RL and reinforces the most effective reasoning patterns.
4. Distillation
- Bigger fashions educated with this pipeline are distilled into smaller variations, sustaining reasoning efficiency whereas drastically decreasing computational prices.
- Distilled fashions inherit the capabilities of bigger counterparts, resembling DeepSeek-R1, with out important efficiency degradation.
DeepSeek R1: Fashions
DeepSeek R1 comes with two core and 6 distilled fashions.
Core Fashions
DeepSeek-R1-Zero
Educated solely via reinforcement studying (RL) on a base mannequin, with none supervised fine-tuning.Demonstrates superior reasoning behaviors like self-verification and reflection, reaching notable outcomes on benchmarks resembling:
Challenges: Struggles with readability and language mixing attributable to a scarcity of cold-start information and structured fine-tuning.
DeepSeek-R1
Builds upon DeepSeek-R1-Zero by incorporating cold-start information (human-annotated lengthy chain-of-thought (CoT) examples) for enhanced initialization.Introduces multi-stage coaching, together with reasoning-oriented RL and rejection sampling for higher alignment with human preferences.
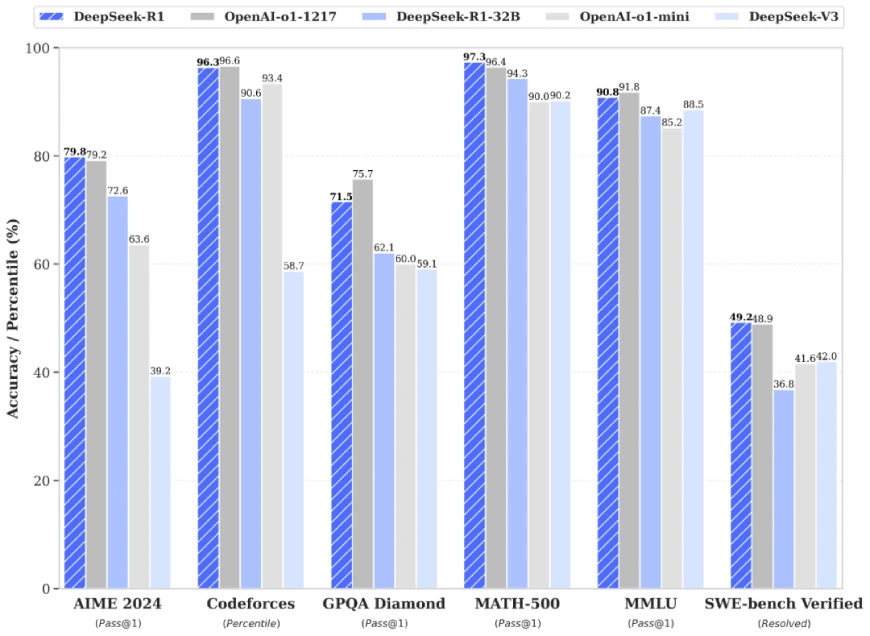
Competes instantly with OpenAI’s o1-1217, reaching:
- AIME 2024: Move@1 rating of 79.8%, marginally outperforming o1-1217.
- MATH-500: Move@1 rating of 97.3%, on par with o1-1217.
Excels in knowledge-intensive and STEM-related duties, in addition to coding challenges.
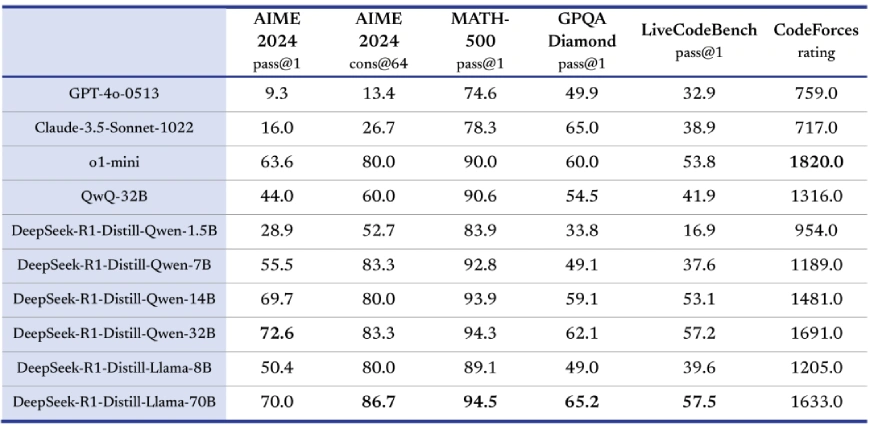
Distilled Fashions
In a groundbreaking transfer, DeepSeek-AI has additionally launched distilled variations of the R1 mannequin, guaranteeing that smaller, computationally environment friendly fashions inherit the reasoning prowess of their bigger counterparts. These distilled fashions embody:
These smaller fashions outperform open-source opponents like QwQ-32B-Preview whereas competing successfully with proprietary fashions like OpenAI’s o1-mini.
DeepSeek R1: Key Highlights
DeepSeek-R1 fashions are engineered to rival a number of the most superior LLMs within the trade. On benchmarks resembling AIME 2024, MATH-500, and Codeforces, DeepSeek-R1 demonstrates aggressive or superior efficiency when in comparison with OpenAI’s o1-1217 and Anthropic’s Claude Sonnet 3:
- AIME 2024 (Move@1)
- MATH-500
- Codeforces
Along with its excessive efficiency, DeepSeek-R1’s open-source availability positions it as an economical different to proprietary fashions, decreasing boundaries to adoption.
The best way to Entry R1?
Internet Entry
In contrast to OpenAI’s o1 for which you must pay a premium worth, DeepSeek has made its R1 mannequin free for everybody to strive of their chat interface.
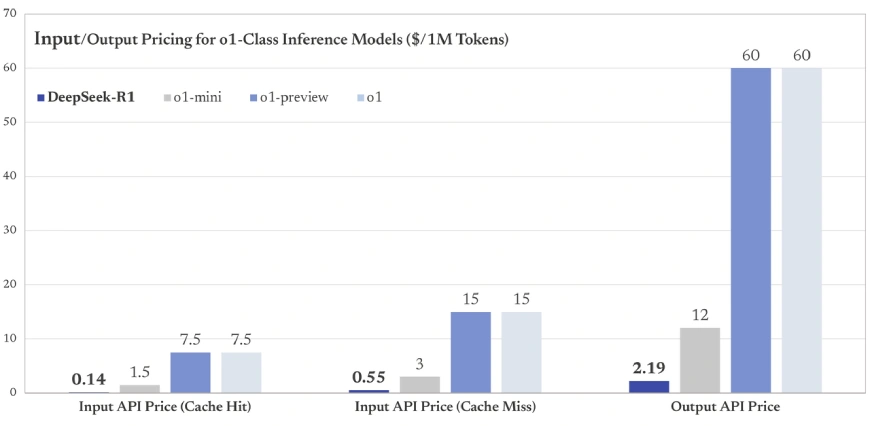
API Entry
You’ll be able to entry its API right here: https://api-docs.deepseek.com/
With a base enter price as little as $0.14 per million tokens for cache hits, DeepSeek-R1 is considerably extra reasonably priced than many proprietary fashions (e.g., OpenAI GPT-4 enter prices begin at $0.03 per 1K tokens or $30 per million tokens).
Purposes
- STEM Schooling: Excelling in math-intensive benchmarks, these fashions can help educators and college students in fixing complicated issues.
- Coding and Software program Growth: With excessive efficiency on platforms like Codeforces and LiveCodeBench, DeepSeek-R1 is good for aiding builders.
- Basic Data Duties: Its prowess in benchmarks like GPQA Diamond positions it as a robust device for fact-based reasoning.
Additionally Learn:
Finish Word
By open-sourcing the DeepSeek-R1 household of fashions, together with the distilled variations, DeepSeek-AI is making high-quality reasoning capabilities accessible to the broader AI neighborhood. This initiative not solely democratizes entry but in addition fosters collaboration and innovation.
Because the AI panorama evolves, DeepSeek-R1 stands out as a beacon of progress, bridging the hole between open-source flexibility and state-of-the-art efficiency. With its potential to reshape reasoning duties throughout industries, DeepSeek-AI is poised to turn into a key participant within the AI revolution.
Keep tuned for extra updates on Analytics Vidhya Information!
Anu Madan has 5+ years of expertise in content material creation and administration. Having labored as a content material creator, reviewer, and supervisor, she has created a number of programs and blogs. At the moment, she engaged on creating and strategizing the content material curation and design round Generative AI and different upcoming know-how.