

{kind=link}

(whiteMocca/Shutterstock)
One of many complaints heard about Databricks over time–that it’s advanced to arrange and generally troublesome to make use of–will must be revisited now that the corporate is making its complete information platform serverless.
Databricks presently gives a serverless choice for some features, which means that clients aren’t accountable for spinning up clusters or spinning them again down after they’re accomplished. However many of the platform depends on underlying compute clusters that value the shoppers cash whether or not or not they’re utilizing them.
That’s altering. Throughout his keynote on the firm’s Knowledge + AI Summit on Wednesday, Databricks CEO and co-founder Ali Ghodsi introduced that, beginning July 1, all the Databricks platform will likely be accessible as serverless.
“With serverless, you’re simply paying for what you’re utilizing,” Ghodsi mentioned. “In actual fact, there isn’t any cluster to arrange for it to be idle or not idle. So we’ll care for all of that for you beneath the hood.”
Databricks runs on all the main clouds–AWS, Azure, and Google Cloud–and depends on these cloud platforms for storage, compute, and networking. Storage is fairly simple within the cloud, as Databricks expects buyer information to be saved of their cloud object storage accounts, whether or not its S3 (Easy Storage Service) on AWS, ALCS (Azure Lake Cloud Storage) on Azure, or GCS (Google Cloud Storage) on GCP.

Databricks CEO Ali Ghodsi delivers a keynote at Knowledge + AI Summit 2024 (Picture courtesy Databricks)
However establishing the compute is extra sophisticated. Prospects might provision the compute for his or her ETL, streaming information, SQL analytics, or ML/AI coaching jobs via Databricks, however they’re billed for the compute via their account with the cloud platform. Going serverless modifications that compute equation.
“All these knobs that we had earlier than are gone,” Ghodsi mentioned. “Cluster tuning–you’ve gotten individuals establishing clusters. What kind of machines ought to they use? Spot cases?…Ought to we auto scale? None of that’s accessible anymore. It’s simply gone. There’s no such web page. You’ll be able to’t do this.”
Going serverless additionally helps clients by decreasing the necessity to perceive previous utilization and use that for capability planning functions, Ghodsi mentioned. (Nevertheless, there’s a caveat round networking, as Databricks presently doesn’t cost for incurred community prices for serverless workloads, however reserves the proper to take action sooner or later, based on its serverless documentation.)
There are additionally advantages to going serverless from the angle of safety and information layouts, Ghodsi mentioned.
“We’re additionally capable of do safety a special manner as a result of once more, we personal all of the machines and are capable of actually lock it down differently. That’s not doable when it’s not serverless,” he mentioned. “The info format–how are you going to set out precisely your information units? How are you going to optimize your information units? That’s additionally gone. We’re simply optimizing behind the scenes. As a result of it’s serverless, we simply run within the background optimization in your information set to make it actually quick and optimum utilizing machine studying. In order that’s additionally actually superior.”
Databricks will profit from the shift away from versioning software program releases; there will likely be no extra variations, as Databricks will mechanically replace the software program, giving all customers entry to the identical fixes and options on the similar time.
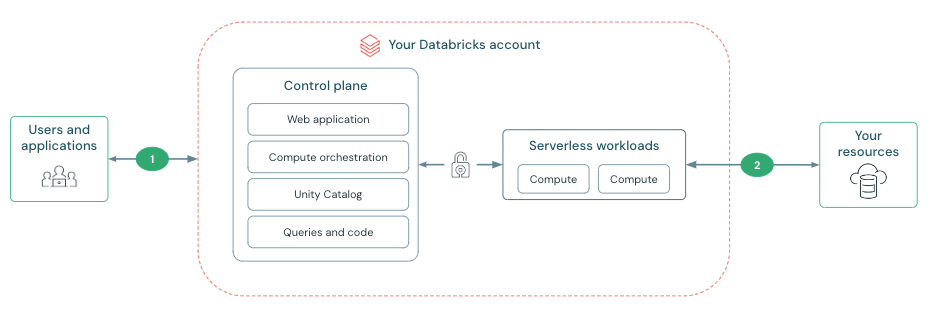
The Databricks Compute Airplane (Picture courtesy Databricks)
Databricks engineers spent the previous three years engaged on the serverless model of its platform, Ghodsi mentioned. It took that lengthy as a result of the engineers primarily needed to rewrite all of its choices, which is one thing that was a matter of debate inside the firm.
“Two to 3 years in the past, my cofounder Matei [Zaharia, Databricks’ CTO] and I informed the corporate ‘We’ve bought to construct a lift-and-shift, easy model of serverless.’ And really our engineers pushed again, and mentioned ‘Hey, you guys are mistaken. We must always redesign it from scratch for the serverless period.’ And we informed them ‘Nope. We resolve within the firm.’ And it turned out we had been mistaken. The tech leads had been proper. And so they’ve been working actually exhausting for 2 years to mainly redesign most of the merchandise–the notebooks, the roles, every thing–as if we’ve got began a brand new firm.”
The shift to serverless received’t occur in a single day on June 30 (though it’s a Sunday, which is right). It should take time to transition all 12,000 Databricks clients to the serverless variations of the merchandise they’re utilizing, whether or not it’s Spark clusters or Structured Streaming or notebooks or MosaicAI.
Databricks is making investments all over the world to make sure serverless variations of its merchandise can be found in each cloud information heart it runs. The corporate will likely be strongly encouraging clients to make the transfer to serverless earlier than later.
“Please begin utilizing serverless,” Ghodsi mentioned. “Sooner or later, new merchandise that we roll out…they’ll most likely solely be accessible in serverless. So in case your group just isn’t on serverless, please get on it.”
For more information on Databricks’ serverless, see the discharge notes.
Associated Objects:
Databricks to Open Supply Unity Catalog
Databricks Unveils LakeFlow: A Unified and Clever Instrument for Knowledge Engineering
Databricks Sees Compound Programs as Treatment to AI Illnesses