
` read in the bookmark data from a CSV file “`R bookmarks % select(id, search_term) “` `library(bookdown)` create a new bookdown project and add the searchable bookmarks as a chunk “`R bookdown::render_book(“path/to/bookmark.Rmd”, “distill”) “` Note that this is just a basic example and you may need to adjust it based on your specific use case.")
{kind=link}
new_my_likes Combining innovative insights with established expertise creates a powerful synthesis.
deduped_my_likes Save the updated knowledge by overwriting any existing version of the file.
rio::export(deduped_my_likes, 'my_likes.parquet') Step 4. Examine and research your existing expertise
I aim to develop a model of this information primarily for utilization within a searchably accessible database. The feature offers a hyperlink at the end of each post’s text, enabling seamless access to original posts on Bluesky, where I can easily view images, replies, parents, or threads not included in the post’s plain text. I remove certain columns from the table that I no longer require.
my_likes_for_table mutate( Put up = str_glue("{Put up} "), ExternalURL = ifelse(!is.na(ExternalURL), str_glue(""), "") ) |> choose(Put up, Title, CreatedAt, ExternalURL) One effective method to generate an HTML index of your knowledge, leveraging the DT package, is to utilize its capabilities.
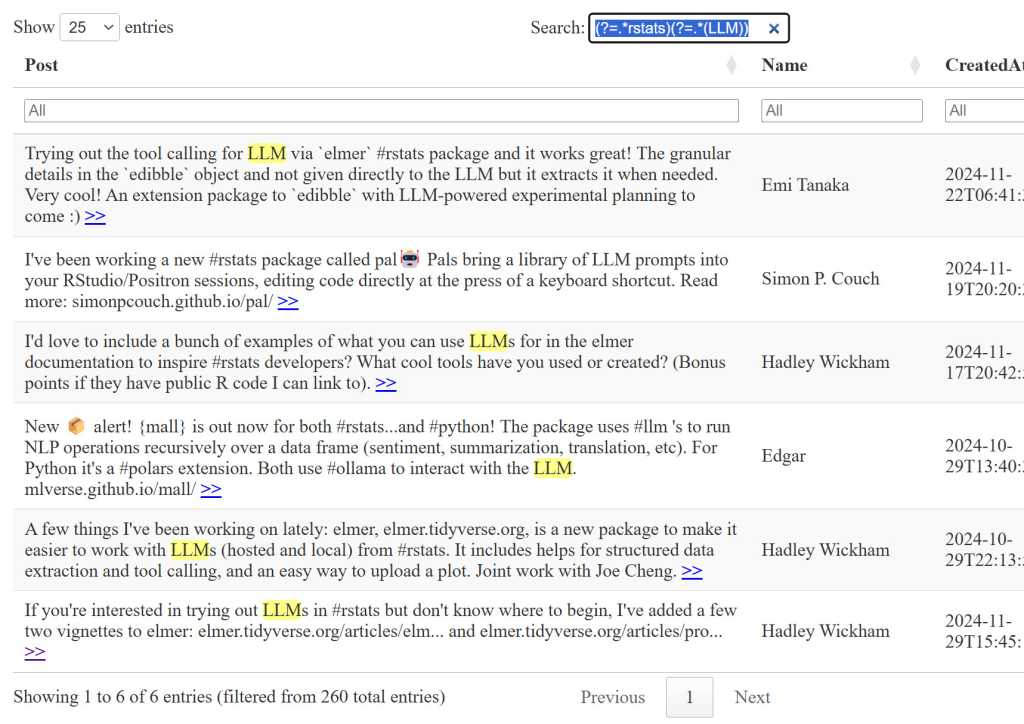
DT::datatable(my_likes_for_table, rownames = FALSE, filter = list(value = "high"), escape = FALSE, choices = list(pageLength = 25, autoWidth = TRUE, lengthMenu = c(25, 50, 75, 100), searchHighlight = TRUE, search = list(regex = TRUE))) The desk features a comprehensive table-wide search field located at the top, allowing users to quickly find specific information by entering two phrases in the main search bar. After submitting their query, users can further refine their results using search filters for each column, including the ability to search for text containing “LLM” within the Post filter bar, which is case-insensitive. Or, as a result of enabling common expressions and searching search = checklist(regex = TRUE) Possibly, you might utilize a solitary regular expression lookahead pattern.?=.(LLM)) within the search field.
IDG
Generative AI chatbots such as ChatGPT and Claude demonstrate impressive capabilities in crafting sophisticated and nuanced sentence structures. With matching textual content highlights enabled within the desk, it will be easy to discern whether the regex pattern is performing as intended.
What’s the vibe you’re looking for in a language model, Bluesky?
To effectively utilize generative AI for evaluating these posts, consider uploading the data file to a compatible platform of your preference. I’ve experienced positive results using Google’s features, which are free and display the underlying text of their responses. Notebook Large Models have a generous file limit of 500,000 characters or 200MB per dataset, ensuring seamless integration with large-scale projects; reassuringly, Google guarantees that its Large Language Models will not train on user data.
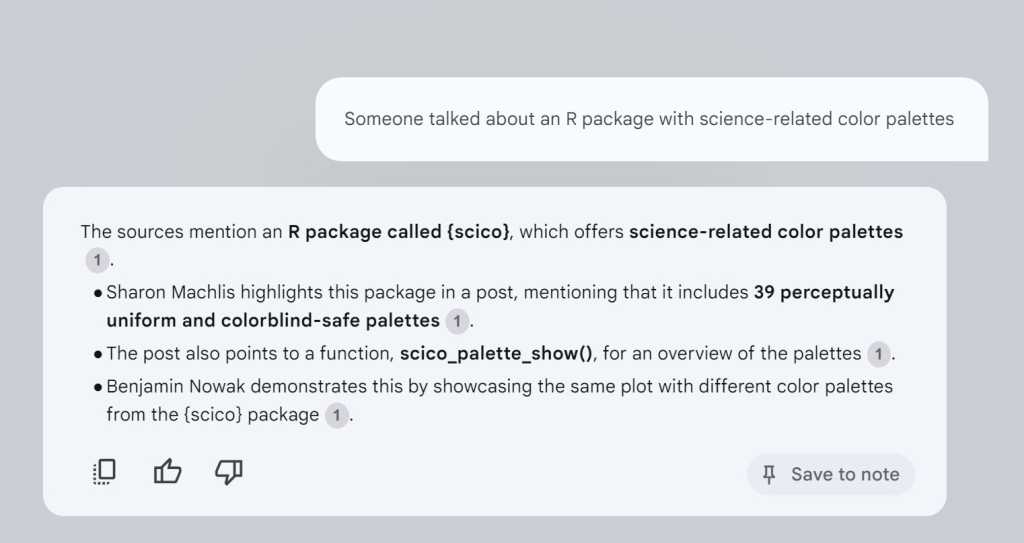
When a query about an R package featuring science-themed color palettes surfaced, it triggered memories of a submission I had previously considered and re-shared with my own commentary. Without having to provide my own custom prompts or instructions, I didn’t need to instruct NotebookLLM that I required it to work exclusively with that specific document, utilizing its contents solely for generating responses, while also displaying the original source text it leveraged in the process? I’m happy to help you with your query; however, your initial statement seems incomplete. Could you please clarify what you mean by “ask my query”?
IDG
By refining the formatting, I limited the CreatedAt timestamp to precise dates only, retained the submit URL as a distinct column for easier reference, and eliminated the redundant external URLs column to optimize data organization and usability. Since I saved the slimmer model as a plain text (.txt) file rather than a comma-separated values (.csv) file, this is because NotebookLM does not work with .csv extensions.
my_likes_for_ai mutate(CreatedAt = substr(CreatedAt, 1, 10)) |> choose(Put up, Title, CreatedAt, URL) rio::export(my_likes_for_ai, "my_likes_for_ai.txt") Once imported into NotebookLM, your likes file will enable instant querying, allowing you to pose questions immediately after processing.

IDG
If you need to query a doc within R instead of using an external service, one option is the `dplyr` package available on GitHub. It should be relatively straightforward to toggle its instant access and provide the necessary information according to your needs. Despite my best efforts, I’ve had limited success using the software domestically, despite having a robust Windows PC at home.
The system must automate these preferences programmatically?
To remain informative, you should regularly update your understanding of previously engaged topics. I execute my script manually on my local machine at intervals when I’m energized about Bluesky; however, you can also configure the script to run automatically daily or weekly. Listed below are three choices:
- If you’re comfortable with running your R script according to a set schedule, tools like those designed for Windows or macOS/Linux can automate the process.
- Johannes Grüber, the creator of the aTRELLIS package, provides instructions on running his R bloggers’ BlueSky bot. His instructions may be tailored to suit various R scripts.
- . You could utilize a scheduled event on a public cloud platform, similar to a cron job,
Is it not a peculiar phenomenon that Bluesky’s liking for knowledge doesn’t align with every submission you’ve esteemed? Usually, a “like” is sufficient to show appreciation for a post’s existence, acknowledging its visibility and encouraging creators that people are engaged; only occasionally do we feel compelled to revisit the content again.
While manual bookmarking in a spreadsheet can be manageable for a smaller number of posts, as the scale increases, this approach can become increasingly laborious, necessitating a significant commitment to upkeep. While it’s acceptable to glance through your entire collection of liked content in place of bookmarking, it’s often more productive to create a curated list of notable items.
Here’s the improved text: That being said, here’s an example of the method I’ve been using. To simplify the initial process, consider leveraging an Excel or comma-separated values (.csv) file for your preliminary setup.
Step 1. SKIPPING
I’ll start by loading my_likes.parquet, adding empty Bookmark and Notes columns, then saving it as a new file.
my_likes mutate(Notes = as.character(""), .earlier than = 1) |> mutate(Bookmark = as.character(""), .after = Bookmark) rio::export(likes_w_bookmarks, "likes_w_bookmarks.xlsx") Following experiments, I decided on a bookmark column comprising character-based entries, allowing me to easily insert “T” or “F” in my spreadsheet, eschewing a dedicated TRUE/FALSE column altogether. Without relying on R’s specific characteristics, I’m free from worrying about whether its Boolean fields will accurately translate when applying this understanding outside of the R environment. The Notes column enables me to append contextual information explaining the reasoning behind wanting to revisit a particular item.
Is subsequent a part of the method, specifically referring to marking points that you wish to retain as bookmarks? By opening the data in a spreadsheet, you gain the flexibility to effortlessly drag the F or T label across multiple cells simultaneously, simplifying your workflow. With a significant number of likes already accrued, this process becomes quite laborious. Consider resolving to mark all of them ‘F’ for now and begin bookmarking manually, which will be significantly less arduous.
Save the file manually again as “Likes with Bookmarks.xlsx”.
Step 2. Are you suggesting a seamless integration between your preferred social media platforms and your digital planning tools?
To ensure consistency and accuracy, you’ll need to regularly update your spreadsheet as new data emerges. One effective technique to put this into practice is to simply start implementing small changes.
Following the update to the newly deduplicated ‘likes’ file, I created a bookmark examination lookup and merged it seamlessly with my deduplicated likes file.
bookmarks check(URL, bookmark, notes) my_bookmark_recommendations relocate(bookmark, notes) Now you’ve acquired a file that combines the brand-new likes knowledge with your existing bookmarks knowledge, featuring numerous entries without any corresponding Bookmark or Notes sections. Save this data to your designated storage file.
rio::export(my_likes_w_bookmarks, "likes_w_bookmarks.xlsx") A more appealing option to this comprehensive and immersive program might be employing dplyr::filter() By leveraging the deduplicated knowledge base, it’s essential to remove well-known items that will no longer be needed, such as posts about favorite sports teams or specific dates when you’ve already discussed a topic that doesn’t warrant revisitation?
Subsequent steps
Are you considering a thorough examination of all my previous responses? Pulling them by way of the Bluesky API in a similar workflow using atrrr’s? get_skeets_authored_by() perform. As you embark on this journey, you’ll discover a multitude of possibilities unfolding before you. You’ll probably also have firms among your R customers.