

{kind=link}
As the cornerstone of medical progress, the pharmaceutical industry stands at a critical juncture in its reliance on clinical trial data. The current state of medical information management is beset by numerous obstacles that imperil the pace of progress and hinder the delivery of timely, life-altering treatments.
As we navigate the overwhelming deluge of data, where a typical Part III trial now yields an astonishing 3.6 million data points – a threefold increase from 15 years ago and exceeding the output of over 4,000 new trials approved annually – our current information infrastructure is struggling to keep pace with the sheer volume. Outdated approaches, defined by compartmentalized information, inadequate connectivity, and crippling intricacy, are hindering researchers, patients, and the advancement of medical research. Despite the gravity of this issue being highlighted by alarming figures, approximately 80% of medical trials are hindered by recruitment difficulties, resulting in premature terminations, while an astonishing 37% of research sites struggle to attract a sufficient number of participants.
Inefficiencies in the product’s development and launch process result in significant financial losses, ranging from $600,000 to $8 million daily, as delays hinder growth opportunities. By 2032, the booming medical trials market is expected to reach an impressive $886.5 billion [1], making it imperative to pioneer innovative technologies like Medical Information Repositories (CDRs) that can meet its growing demands.
Reimagining Medical Information Repositories (CDR)
Medical trials’ information administration often relies on sophisticated specialized platforms. The underlying factors contributing to these disparities include the formal certification process employed by regulatory bodies, individuals’ proficiency in specific software and coding languages, and their reliance on platform providers to furnish industry-specific data.
As global harmonization of medical analytics takes hold and regulatory requirements shift toward digital submissions, it is crucial to understand and operate within the framework of international medical progress. Effective management of medical information relies on leveraging requirements to design and implement architectures, policies, guidelines, best practices, and protocols that ensure a seamless lifecycle process.
The following processes are included:
- Information Modeling for Medical Information Repositories or Warehouses: A Comprehensive Approach to Standardizing Healthcare Data.
The healthcare industry is increasingly reliant on electronic health records (EHRs) and other digital systems to store, manage, and share patient data. As a result, the need for standardized information modeling in medical information repositories or warehouses has become crucial. This article explores the importance of information modeling in the context of medical information repositories or warehouses, highlighting its role in ensuring seamless data sharing, improving data quality, and enhancing clinical decision-making.
To achieve these goals, healthcare organizations must adopt a comprehensive approach to information modeling that involves standardizing data structures, vocabularies, and terminologies. This can be achieved by leveraging established standards such as Fast Healthcare Interoperability Resources (FHIR), Health Level Seven International (HL7), and the Systematized Nomenclature of Medicine (SNOMED). By implementing these standards, healthcare organizations can ensure that their data is accurate, consistent, and easily accessible, ultimately improving patient care and outcomes.
- Information Management, Standard Operating Procedures (SOPs), and Pointers Administration, combined with Entry Governance, Archival, Privacy, and Security.
- Information administration, ensuring the integrity of data and guaranteeing high-quality assurance, facilitating seamless information integration, and enabling swift external information switching. Additionally, this includes metadata discovery, publication, and standardization for optimal information management.
- Instruments for Information Mining and Extract, Transform, Load (ETL) Processes?
Effective management of complex medical information relies heavily on these crucial components.
Pharmaceutical companies are revising their approaches to medical information management. While specialized software programs have traditionally been the standard, mainstream platforms offer significant advantages, including the flexibility to incorporate innovative data types, near-real-time processing capabilities, seamless integration of cutting-edge technologies like artificial intelligence and machine learning, and robust data processing methodologies honed from handling vast data volumes.
While considerations surrounding customization and the transition from familiar distributors may influence decisions, established platforms can often surpass specialized alternatives in managing medical trial data. Databricks enables Life Sciences organizations to streamline their handling of medical trial data by seamlessly integrating diverse data types and providing a unified view of patient health information.
As specialized platforms are being eclipsed, common platforms like Databricks are spearheading a revolutionary era of efficiency and innovation in medical trial data management, redefining the status quo with unprecedented capabilities.
What’s the best approach to integrating data analytics with customer data record (CDR)?
The Databricks Information Intelligence Platform is built upon. The Lakehouse structure combines the best features of data lakes and data warehouses to create a contemporary information architecture. The latest development in cognitive dynamic reasoning matches perfectly with the contemporary demands of modern learners.
While traditional medical trial data often takes the form of organized tabular information, emerging modalities such as imaging and wearable devices are increasingly prominent. These are the innovative means of revolutionizing the medical trials process. Databricks is hosted on cloud infrastructure, offering the flexibility to leverage cloud-based object storage and store large amounts of medical data at scale. The storage solution enables the retention of various types of data, while also regulating costs by potentially migrating older information to less expensive tiers to conserve resources while still complying with regulatory requirements for data retention and ensuring information availability and redundancy. By leveraging Databricks as the foundation for Customer Data Repository (CDR), organizations can transition to an agile development approach, enabling the incremental release of new features through controlled iterations rather than relying on massive, Big Bang-style software updates.
The platform offers a comprehensive information hub, seamlessly integrating information processing, orchestration, and artificial intelligence capabilities in one intuitive location. The platform offers a range of pre-built data ingestion capabilities, including native connectors and the ability to implement custom connectors. This integration enables seamless combination of CDR with relevant information sources and downstream processes. This solution provides flexibility and end-to-end visibility into high-quality information, ensuring seamless monitoring. The native integration of streaming capabilities enables the seamless fusion of CDR data with IoMT information, thereby facilitating near-real-time insights that can be accessed as soon as relevant data becomes available. Platform observability is a significant concern for CDR not only because of strict regulatory requirements, but also because it enables the secondary use of data and the ability to generate insights that ultimately enhance the overall medical trial process. Processing medical information on Databricks enables seamless access to a wide range of versatile options, thereby facilitating insight into the methodology. Is MRI image processing computationally more demanding than its CT counterpart, with notable differences in performance metrics?
What do healthcare providers and researchers need most? Fast access to accurate medical information. That’s where Databricks comes in – an open-source analytics platform that can help you build a scalable, secure, and governed repository for your organization’s medical information.
In this article, we’ll outline a layered strategy for implementing a medical information repository using Databricks, covering data ingestion, processing, storage, security, and integration.
Medical information repositories represent advanced digital frameworks that seamlessly integrate data storage and processing capabilities to facilitate efficient management and retrieval of vital healthcare data. LakeHouse, a robust methodology for information processing, excels in handling complex CDRs (customer data records). This hierarchical structure often comprises three tiers, each successively distilling high-quality information.
- Unrefined data obtained from diverse sources and methodologies
- Data formatted to standard structural formats (e.g., SDTM) and verified for accuracy.
- Data consolidated and refined for comprehensive analysis and quantitative assessment.
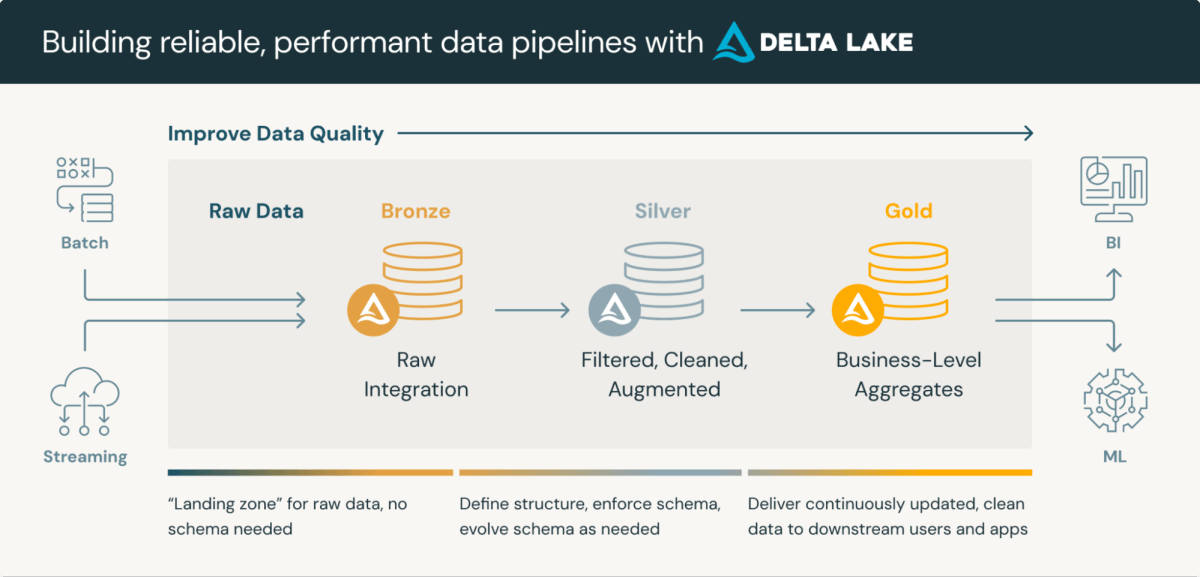
In Databricks, utilizing a specific data format enables inherent benefits that mirror schema validation and allow for time-traveling capabilities. While these options aim to fully satisfy regulatory requirements, they provide a solid foundation for compliance and efficient processing, thereby streamlining operations.
The Databricks Intelligent Information Platform arrives equipped with robust governance tools. The all-in-one solution, providing comprehensive coverage of information governance, auditing, and entry management capabilities within its robust platform. Within the context of Cloud Data Replication (CDRs), Unity Catalog enables users to:
- Effective lineage monitoring of both desktop and column data enables precise tracking of changes, ensuring integrity and transparency throughout the analytical process.
- Data Retention: Historical Records and Alter Logs
- Robust entry management with granular controls and comprehensive audit trails.
- The harmonization of external martial arts principles within one’s own unique system of combat?
- Implementation of robust access controls ensures seamless protection against illicit data infiltration.
Past the realm of information processing, Certificates of Disclosure and Receipt (CDRs) play a pivotal role in maintaining the integrity of information validation procedures. Validation checks should be version-controlled within a code repository, allowing multiple versions to exist simultaneously and linking seamlessly to distinct research findings. Databricks facilitates the establishment of robust CI/CD pipelines, thereby empowering the development of a comprehensive validation examination library.
This implementation of centralized data repositories (CDRs) on Databricks ensures information integrity and compliance, providing the flexibility and scalability required for modern healthcare data management.
The Databricks Information Intelligence Platform naturally aligns itself with the healthcare industry by offering a highly advanced approach to managing medical growth information. This ensures seamless data discovery, utilization, compatibility, and recyclability while maintaining a robust foundation.
Challenges in Implementing Fashionable CDRs
Innovative approaches rarely emerge without encountering obstacles. While medical information administration is intricately tied to SAS, modern information systems predominantly leverage Python, R, and SQL for optimal performance. This introduction of non-technical and additional social integration challenges is clear. R bridges the gap between data and decision-making, providing top-tier R expertise to empower clients. While migrating data, integrating Databricks with SAS enables seamless transitions and facilitates the process of assimilating systems. Enables novice developers to access the support needed to craft exceptional code and comprehend existing code examples, thereby bridging the gap for those less familiar with programming languages.
A knowledge processing platform built atop a generic foundation will consistently lag behind in integrating domain-specific features. Strong partnership with project stakeholders effectively minimizes the risk of such challenges. By employing a consumption-based value model, it is essential to factor in prices carefully, thereby ensuring that the platform’s monitoring and observability capabilities are accurate, individual training is effective, and adherence to best practices is maintained.
However, the prevailing issue lies in the overall success-based compensation structure of many such initiatives. Pharmaceutical companies consistently strive to modernize their medical trial information platforms. Can accelerating the pace of clinical trials lead to more timely and cost-effective treatments? The sheer volume of data accumulated by pharmaceutical companies enables access to a boundless array of valuable insights waiting to be unearthed and shared. Despite the best intentions, most initiatives of this nature ultimately prove unsuccessful. While no single approach guarantees a 100% success rate, leveraging a ubiquitous platform like Databricks enables seamless integration of CDR as a lightweight layer atop the existing architecture, thereby eliminating the pains associated with disparate data and infrastructure hurdles.
What’s subsequent?
Every Custom Desktop Runtime (CDR) implementation starts with a comprehensive inventory of essential components. Although the industry adheres to rigorous standards for data formatting and processing, grasping the distinct parameters of Critical Design Requirements (CDR) within each sector is crucial to ensure the success of any project. The Databricks Information Intelligence Platform offers a wealth of additional features for customers who leverage Customer Data Records (CDR), necessitating a comprehensive grasp of its functionality and benefits. Discovering the Power of Databricks: Unlock Insights from Your Data In today’s data-driven landscape, unified governance, seamless information ingestion pipelines, advanced information intelligence suites, and potent AI capabilities are no longer obscure concepts; rather, they are essential ingredients for crafting a successful and forward-thinking Customer Data Repository (CDR). Moreover, seamless integration with Posit and enhanced observational capabilities will likely enable the consideration of CDR as a pivotal hub within the comprehensive healthcare data ecosystem rather than just another cog in the larger medical information processing machinery?
As the digital landscape continues to evolve, many companies are proactively upgrading their healthcare data infrastructures by leveraging cutting-edge technologies such as Lakehouse architecture? Despite the significant shift being necessary to get back on track? The rapid proliferation of generative AI and related technologies is transforming various sectors, yet the pharmaceutical industry lags behind, hindered by regulatory constraints, high risk, and the cost of unintended consequences. Platforms like Databricks empower cross-industry innovation and drive data-driven growth in medical trials, revolutionizing the way we approach these studies and fostering a more innovative mindset across the board.
Let’s get started immediately!
Medical trials statistics 2024: a comprehensive overview by phase, definition, and interventions?
Medical trials statistics 2024: a snapshot of the latest trends by phase, definition, and interventions. What does this mean for future research?
[2] Lu, Z., & Su, J. (2010). Medical Information Administration: Current Landscape, Key Challenges, and Future Directions from an Industry Perspective? Journal of Medical Trials, Volume 2, pp. 93-105.
In regard to the Databricks Information Intelligence Platform for Healthcare and Life Sciences?