{kind=link}

Resilience has all the time been a prime precedence for purchasers operating mission-critical Apache Kafka functions. Amazon Managed Streaming for Apache Kafka (Amazon MSK) is deployed throughout a number of Availability Zones and offers resilience inside an AWS Area. Nevertheless, mission-critical Kafka deployments require cross-Area resilience to attenuate downtime throughout service impairment in a Area. With Amazon MSK Replicator, you’ll be able to construct multi-Area resilient streaming functions to supply enterprise continuity, share information with companions, combination information from a number of clusters for analytics, and serve world purchasers with lowered latency. This submit explains the way to use MSK Replicator for cross-cluster information replication and particulars the failover and failback processes whereas protecting the identical matter identify throughout Areas.
MSK Replicator overview
Amazon MSK presents two cluster varieties: Provisioned and Serverless. Provisioned cluster helps two dealer varieties: Customary and Specific. With the introduction of Amazon MSK Specific brokers, now you can deploy MSK clusters that considerably scale back restoration time by as much as 90% whereas delivering constant efficiency. Specific brokers present as much as 3 occasions the throughput per dealer and scale as much as 20 occasions quicker in comparison with Customary brokers operating Kafka. MSK Replicator works with each dealer varieties in Provisioned clusters and together with Serverless clusters.
MSK Replicator helps an an identical matter identify configuration, enabling seamless matter identify retention throughout each active-active or active-passive replication. This avoids the chance of infinite replication loops generally related to third-party or open supply replication instruments. When deploying an active-passive cluster structure for regional resilience, the place one cluster handles reside site visitors and the opposite acts as a standby, an an identical matter configuration simplifies the failover course of. Purposes can transition to the standby cluster with out reconfiguration as a result of matter names stay constant throughout the supply and goal clusters.
To arrange an active-passive deployment, it’s a must to allow multi-VPC connectivity for the MSK cluster within the main Area and deploy an MSK Replicator within the secondary Area. The replicator will eat information from the first Area’s MSK cluster and asynchronously replicate it to the secondary Area. You join the purchasers initially to the first cluster however fail over the purchasers to the secondary cluster within the case of main Area impairment. When the first Area recovers, you deploy a brand new MSK Replicator to copy information again from the secondary cluster to the first. You might want to cease the shopper functions within the secondary Area and restart them within the main Area.
As a result of replication with MSK Replicator is asynchronous, there’s a risk of duplicate information within the secondary cluster. Throughout a failover, shoppers may reprocess some messages from Kafka subjects. To deal with this, deduplication ought to happen on the buyer facet, similar to through the use of an idempotent downstream system like a database.
Within the subsequent sections, we exhibit the way to deploy MSK Replicator in an active-passive structure with an identical matter names. We offer a step-by-step information for failing over to the secondary Area throughout a main Area impairment and failing again when the first Area recovers. For an active-active setup, confer with Create an active-active setup utilizing MSK Replicator.
Resolution overview
On this setup, we deploy a main MSK Provisioned cluster with Specific brokers within the us-east-1 Area. To supply cross-Area resilience for Amazon MSK, we set up a secondary MSK cluster with Specific brokers within the us-east-2 Area and replicate subjects from the first MSK cluster to the secondary cluster utilizing MSK Replicator. This configuration offers excessive resilience inside every Area through the use of Specific brokers, and cross-Area resilience is achieved via an active-passive structure, with replication managed by MSK Replicator.
The next diagram illustrates the answer structure.

The first Area MSK cluster handles shopper requests. Within the occasion of a failure to speak to MSK cluster because of main area impairment, you’ll want to fail over the purchasers to the secondary MSK cluster. The producer writes to the buyer matter within the main MSK cluster, and the buyer with the group ID msk-consumer reads from the identical matter. As a part of the active-passive setup, we configure MSK Replicator to make use of an identical matter names, ensuring that the buyer matter stays constant throughout each clusters with out requiring modifications from the purchasers. The whole setup is deployed inside a single AWS account.
Within the subsequent sections, we describe the way to arrange a multi-Area resilient MSK cluster utilizing MSK Replicator and in addition present the failover and failback technique.
Provision an MSK cluster utilizing AWS CloudFormation
We offer AWS CloudFormation templates to provision sure assets:
This can create the digital non-public cloud (VPC), subnets, and the MSK Provisioned cluster with Specific brokers inside the VPC configured with AWS Identification and Entry Administration (IAM) authentication in every Area. It would additionally create a Kafka shopper Amazon Elastic Compute Cloud (Amazon EC2) occasion, the place we are able to use the Kafka command line to create and examine a Kafka matter and produce and eat messages to and from the subject.
Configure multi-VPC connectivity within the main MSK cluster
After the clusters are deployed, you’ll want to allow the multi-VPC connectivity within the main MSK cluster deployed in us-east-1. This can enable MSK Replicator to hook up with the first MSK cluster utilizing multi-VPC connectivity (powered by AWS PrivateLink). Multi-VPC connectivity is barely required for cross-Area replication. For same-Area replication, MSK Replicator makes use of an IAM coverage to hook up with the first MSK cluster.
MSK Replicator makes use of IAM authentication solely to hook up with each main and secondary MSK clusters. Subsequently, though different Kafka purchasers can nonetheless proceed to make use of SASL/SCRAM or mTLS authentication, for MSK Replicator to work, IAM authentication needs to be enabled.
To allow multi-VPC connectivity, full the next steps:
- On the Amazon MSK console, navigate to the MSK cluster.
- On the Properties tab, underneath Community settings, select Activate multi-VPC connectivity on the Edit dropdown menu.

- For Authentication kind, choose IAM role-based authentication.
- Select Activate choice.
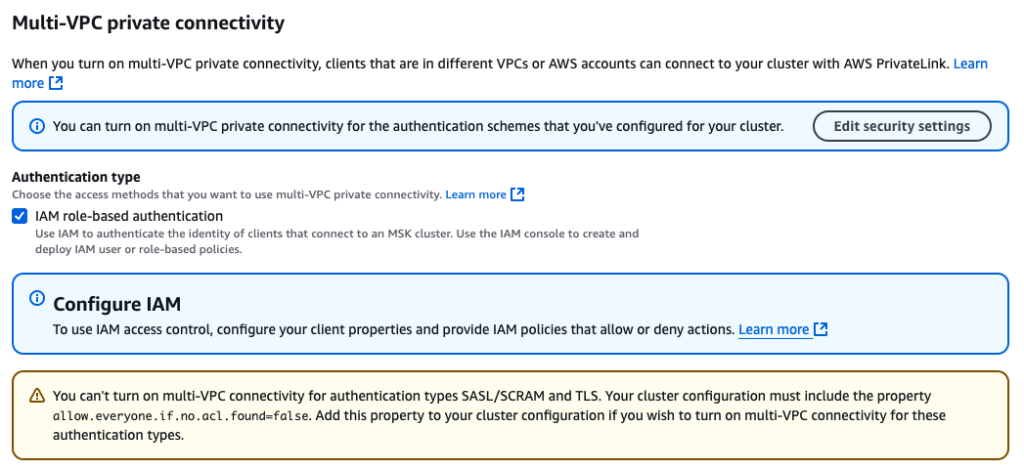
Enabling multi-VPC connectivity is a one-time setup and it might probably take roughly 30–45 minutes relying on the variety of brokers. After that is enabled, you’ll want to present the MSK cluster useful resource coverage to permit MSK Replicator to speak to the first cluster.
- Below Safety settings¸ select Edit cluster coverage.
- Choose Embody Kafka service principal.

Now that the cluster is enabled to obtain requests from MSK Replicator utilizing PrivateLink, we have to arrange the replicator.
Create a MSK Replicator
Full the next steps to create an MSK Replicator:
- Within the secondary Area (
us-east-2), open the Amazon MSK console. - Select Replicators within the navigation pane.
- Select Create replicator.
- Enter a reputation and optionally available description.

- Within the Supply cluster part, present the next info:
- For Cluster area, select us-east-1.
- For MSK cluster, enter the Amazon Useful resource Identify (ARN) for the first MSK cluster.
For cross-Area setup, the first cluster will seem disabled if the multi-VPC connectivity is just not enabled and the cluster useful resource coverage is just not configured within the main MSK cluster. After you select the first cluster, it mechanically selects the subnets related to main cluster. Safety teams should not required as a result of the first cluster’s entry is ruled by the cluster useful resource coverage.

Subsequent, you choose the goal cluster. The goal cluster Area is defaulted to the Area the place the MSK Replicator is created. On this case, it’s us-east-2.
- Within the Goal cluster part, present the next info:
- For MSK cluster, enter the ARN of the secondary MSK cluster. This can mechanically choose the cluster subnets and the safety group related to the secondary cluster.
- For Safety teams, select any extra safety teams.
Ensure that the safety teams have outbound guidelines to permit site visitors to your secondary cluster’s safety teams. Additionally make it possible for your secondary cluster’s safety teams have inbound guidelines that settle for site visitors from the MSK Replicator safety teams supplied right here.

Now let’s present the MSK Replicator settings.
- Within the Replicator settings part, enter the next info:
- For Matters to copy, we preserve the subjects to copy as a default worth that replicates all subjects from the first to secondary cluster.
- For Replication beginning place, we select Earliest, in order that we are able to get all of the occasions from the beginning of the supply subjects.
- For Copy settings, choose Preserve the identical matter names to configure the subject identify within the secondary cluster as an identical to the first cluster.
This makes positive that the MSK purchasers don’t want so as to add a prefix to the subject names.

- For this instance, we preserve the Client group replication setting as default and set Goal compression kind as None.
Additionally, MSK Replicator will mechanically create the required IAM insurance policies.
- Select Create to create the replicator.
The method takes round 15–20 minutes to deploy the replicator. After the MSK Replicator is operating, this will probably be mirrored within the standing.
Configure the MSK shopper for the first cluster
Full the next steps to configure the MSK shopper:
- On the Amazon EC2 console, navigate to the EC2 occasion of the first Area (
us-east-1) and connect with the EC2 occasiondr-test-primary-KafkaClientInstance1utilizing Session Supervisor, a functionality of AWS Methods Supervisor.
After you may have logged in, you’ll want to configure the first MSK cluster bootstrap handle to create a subject and publish information to the cluster. You may get the bootstrap handle for IAM authentication on the Amazon MSK console underneath View Consumer Info on the cluster particulars web page.
- Configure the bootstrap handle with the next code:
- Configure the shopper configuration for IAM authentication to speak to the MSK cluster:
Create a subject and produce and eat messages to the subject
Full the next steps to create a subject after which produce and eat messages to it:
- Create a
buyermatter:
- Create a console producer to write down to the subject:
- Produce the next pattern textual content to the subject:
- Press Ctrl+C to exit the console immediate.
- Create a shopper with
group.idmsk-consumerto learn all of the messages from the start of the shopper matter:
This can eat each the pattern messages from the subject.
- Press Ctrl+C to exit the console immediate.
Configure the MSK shopper for the secondary MSK cluster
Go to the EC2 cluster of the secondary Area us-east-2 and comply with the beforehand talked about steps to configure an MSK shopper. The one distinction from the earlier steps is that you need to use the bootstrap handle of the secondary MSK cluster because the setting variable. Configure the variable $BS_SECONDARY to configure the secondary Area MSK cluster bootstrap handle.
Confirm replication
After the shopper is configured to speak to the secondary MSK cluster utilizing IAM authentication, listing the subjects within the cluster. As a result of the MSK Replicator is now operating, the buyer matter is replicated. To confirm it, let’s see the listing of subjects within the cluster:
The subject identify is buyer with none prefix.
By default, MSK Replicator replicates the small print of all the buyer teams. Since you used the default configuration, you’ll be able to confirm utilizing the next command if the buyer group ID msk-consumer can also be replicated to the secondary cluster:
Now that we have now verified the subject is replicated, let’s perceive the important thing metrics to watch.
Monitor replication
Monitoring MSK Replicator is essential to make it possible for replication of knowledge is occurring quick. This reduces the chance of knowledge loss in case an unplanned failure happens. Some vital MSK Replicator metrics to watch are ReplicationLatency, MessageLag, and ReplicatorThroughput. For an in depth listing, see Monitor replication.
To know what number of bytes are processed by MSK Replicator, you need to monitor the metric ReplicatorBytesInPerSec. This metric signifies the common variety of bytes processed by the replicator per second. Information processed by MSK Replicator consists of all information MSK Replicator receives. This contains the info replicated to the goal cluster and filtered by MSK Replicator. This metric is relevant when you use Preserve identical matter identify within the MSK Replicator copy settings. Throughout a failback state of affairs, MSK Replicator begins to learn from the earliest offset and replicates information from the secondary again to the first. Relying on the retention settings, some information may exist within the main cluster. To forestall duplicates, MSK Replicator processes the info however mechanically filters out duplicate information.
Fail over purchasers to the secondary MSK cluster
Within the case of an surprising occasion within the main Area wherein purchasers can’t connect with the first MSK cluster or the purchasers are receiving surprising produce and eat errors, this could possibly be an indication that the first MSK cluster is impacted. You could discover a sudden spike in replication latency. If the latency continues to rise, it might point out a regional impairment in Amazon MSK. To confirm this, you’ll be able to verify the AWS Well being Dashboard, although there’s a likelihood that standing updates could also be delayed. When you determine indicators of a regional impairment in Amazon MSK, you need to put together to fail over the purchasers to the secondary area.
For crucial workloads we advocate not taking a dependency on management aircraft actions for failover. To mitigate this threat, you might implement a pilot gentle deployment, the place important elements of the stack are saved operating in a secondary area and scaled up when the first area is impaired. Alternatively, for quicker and smoother failover with minimal downtime, a sizzling standby method is really useful. This entails pre-deploying your complete stack in a secondary area in order that, in a catastrophe restoration state of affairs, the pre-deployed purchasers might be rapidly activated within the secondary area.
Failover course of
To carry out the failover, you first have to cease the purchasers pointed to the first MSK cluster. Nevertheless, for the aim of the demo, we’re utilizing console producer and shoppers, so our purchasers are already stopped.
In an actual failover state of affairs, utilizing main Area purchasers to speak with the secondary Area MSK cluster is just not really useful, because it breaches fault isolation boundaries and results in elevated latency. To simulate the failover utilizing the previous setup, let’s begin a producer and shopper within the secondary Area (us-east-2). For this, run a console producer within the EC2 occasion (dr-test-secondary-KafkaClientInstance1) of the secondary Area.
The next diagram illustrates this setup.

Full the next steps to carry out a failover:
- Create a console producer utilizing the next code:
- Produce the next pattern textual content to the subject:
Now, let’s create a console shopper. It’s vital to ensure the buyer group ID is precisely the identical as the buyer connected to the first MSK cluster. For this, we use the group.id msk-consumer to learn the messages from the buyer matter. This simulates that we’re mentioning the identical shopper connected to the first cluster.
- Create a console shopper with the next code:
Though the buyer is configured to learn all the info from the earliest offset, it solely consumes the final two messages produced by the console producer. It is because MSK Replicator has replicated the buyer group particulars together with the offsets learn by the buyer with the buyer group ID msk-consumer. The console shopper with the identical group.id mimic the behaviour that the buyer is failed over to the secondary Amazon MSK cluster.
Fail again purchasers to the first MSK cluster
Failing again purchasers to the first MSK cluster is the frequent sample in an active-passive state of affairs, when the service within the main area has recovered. Earlier than we fail again purchasers to the first MSK cluster, it’s vital to sync the first MSK cluster with the secondary MSK cluster. For this, we have to deploy one other MSK Replicator within the main Area configured to learn from the earliest offset from the secondary MSK cluster and write to the first cluster with the identical matter identify. The MSK Replicator will copy the info from the secondary MSK cluster to the first MSK cluster. Though the MSK Replicator is configured to begin from the earliest offset, it won’t duplicate the info already current within the main MSK cluster. It would mechanically filter out the present messages and can solely write again the brand new information produced within the secondary MSK cluster when the first MSK cluster was down. The replication step from secondary to main wouldn’t be required when you don’t have a enterprise requirement of protecting the info identical throughout each clusters.
After the MSK Replicator is up and operating, monitor the MessageLag metric of MSK Replicator. This metric signifies what number of messages are but to be replicated from the secondary MSK cluster to the first MSK cluster. The MessageLag metric ought to come down near 0. Now you need to cease the producers writing to the secondary MSK cluster and restart connecting to the first MSK cluster. You must also enable the shoppers to learn information from the secondary MSK cluster till the MaxOffsetLag metric for the shoppers is just not 0. This makes positive that the shoppers have already processed all of the messages from the secondary MSK cluster. The MessageLag metric needs to be 0 by this time as a result of no producer is producing information within the secondary cluster. MSK Replicator replicated all messages from the secondary cluster to the first cluster. At this level, you need to begin the buyer with the identical group.id within the main Area. You’ll be able to delete the MSK Replicator created to repeat messages from the secondary to the first cluster. Ensure that the beforehand current MSK Replicator is in RUNNING standing and efficiently replicating messages from the first to secondary. This may be confirmed by wanting on the ReplicatorThroughput metric, which needs to be larger than 0.
Failback course of
To simulate a failback, you first have to allow multi-VPC connectivity within the secondary MSK cluster (us-east-2) and add a cluster coverage for the Kafka service principal like we did earlier than.
Deploy the MSK Replicator within the main Area (us-east-1) with the supply MSK cluster pointed to us-east-2 and the goal cluster pointed to us-east-1. Configure Replication beginning place as Earliest and Copy settings as Preserve the identical matter names.
The next diagram illustrates this setup.

After the MSK Replicator is in RUNNING standing, let’s confirm there isn’t a duplicate whereas replicating the info from the secondary to the first MSK cluster.
Run a console shopper with out the group.id within the EC2 occasion (dr-test-primary-KafkaClientInstance1) of the first Area (us-east-1):
This could present the 4 messages with none duplicates. Though within the shopper we specify to learn from the earliest offset, MSK Replicator makes positive the duplicate information isn’t replicated again to the first cluster from the secondary cluster.
Now you can level the purchasers to begin producing to and consuming from the first MSK cluster.
Clear up
At this level, you’ll be able to tear down the MSK Replicator deployed within the main Area.
Conclusion
This submit explored the way to improve Kafka resilience by establishing a secondary MSK cluster in one other Area and synchronizing it with the first cluster utilizing MSK Replicator. We demonstrated the way to implement an active-passive catastrophe restoration technique whereas sustaining constant matter names throughout each clusters. We supplied a step-by-step information for configuring replication with an identical matter names and detailed the processes for failover and failback. Moreover, we highlighted key metrics to watch and outlined actions to supply environment friendly and steady information replication.
For extra info, confer with What’s Amazon MSK Replicator? For a hands-on expertise, check out the Amazon MSK Replicator Workshop. We encourage you to check out this characteristic and share your suggestions with us.
In regards to the Creator

Subham Rakshit is a Senior Streaming Options Architect for Analytics at AWS based mostly within the UK. He works with clients to design and construct streaming architectures to allow them to get worth from analyzing their streaming information. His two little daughters preserve him occupied more often than not exterior work, and he loves fixing jigsaw puzzles with them. Join with him on LinkedIn.