

{kind=link}
As know-how progresses, the Web of Issues (IoT) expands to embody increasingly more issues. Consequently, organizations gather huge quantities of knowledge from numerous sensor gadgets monitoring every little thing from industrial gear to good buildings. These sensor gadgets regularly bear firmware updates, software program modifications, or configuration modifications that introduce new monitoring capabilities or retire out of date metrics. Consequently, the information construction (schema) of the knowledge transmitted by these gadgets evolves constantly.
Organizations generally select Apache Avro as their knowledge serialization format for IoT knowledge on account of its compact binary format, built-in schema evolution assist, and compatibility with large knowledge processing frameworks. This turns into essential when sensor producers launch updates that add new metrics or deprecate previous ones, permitting for seamless knowledge processing. For instance, when a sensor producer releases a firmware replace that provides new temperature precision metrics or deprecates legacy vibration measurements, Avro’s schema evolution capabilities enable for seamless dealing with of those modifications with out breaking present knowledge processing pipelines.
Nevertheless, managing schema evolution at scale presents important challenges. For instance, organizations must retailer and course of knowledge from hundreds of sensors and replace their schemas independently, deal with schema modifications occurring as regularly as each hour on account of rolling gadget updates, keep historic knowledge compatibility whereas accommodating new schema variations, question knowledge throughout a number of time intervals with completely different schemas for temporal evaluation, and guarantee minimal question failures on account of schema mismatches.
To handle this problem, this submit demonstrates the right way to construct such an answer by combining Amazon Easy Storage Service (Amazon S3) for knowledge storage, AWS Glue Knowledge Catalog for schema administration, and Amazon Athena for one-time querying. We’ll focus particularly on dealing with Avro-formatted knowledge in partitioned S3 buckets, the place schemas can change regularly whereas offering constant question capabilities throughout all knowledge no matter schema variations.
This resolution is particularly designed for Hive-based tables, resembling these within the AWS Glue Knowledge Catalog, and isn’t relevant for Iceberg tables. By implementing this method, organizations can construct a extremely adaptive and resilient analytics pipeline able to dealing with extraordinarily frequent Avro schema modifications in partitioned S3 environments.
Resolution overview
On this submit for instance, we’re simulating a real-world IoT knowledge pipeline with the next necessities:
- IoT gadgets constantly add sensor knowledge in Avro format to an S3 bucket, simulating real-time IoT knowledge ingestion
- The schema change occurs regularly over time
- Knowledge shall be partitioned hourly to replicate typical IoT knowledge ingestion patterns
- Knowledge must be queryable utilizing the newest schema model by Amazon Athena.
To realize these necessities, we show the answer utilizing automated schema detection. We use AWS Command Line Interface (AWS CLI) and AWS SDK for Python (Boto3) scripts to simulate an automatic mechanism that frequently screens the S3 bucket for brand new knowledge, detects schema modifications in incoming Avro information, and triggers needed updates to the AWS Glue Knowledge Catalog.
For schema evolution dealing with, our resolution will show the right way to create and replace desk definitions within the AWS Glue Knowledge Catalog, incorporate Avro schema literals to deal with schema modifications, and use the Athena partition projection for environment friendly querying throughout schema variations. The info steward or admin must know when and the way the schema is up to date in order that the admin can manually change the columns within the UpdateTable API name. For validation and querying, we use Amazon Athena queries to confirm desk definitions and partition particulars and show profitable querying of knowledge throughout completely different schema variations. By simulating these parts, our resolution addresses the important thing necessities outlined within the introduction:
- Dealing with frequent schema modifications (as typically as hourly)
- Managing knowledge from hundreds of sensors updating independently
- Sustaining historic knowledge compatibility whereas accommodating new schemas
- Enabling querying throughout a number of time intervals with completely different schemas
- Minimizing question failures on account of schema mismatches
Though in a manufacturing atmosphere this is able to be built-in into a complicated IoT knowledge processing software, our simulation utilizing AWS CLI and Boto3 scripts successfully demonstrates the ideas and methods for managing schema evolution in large-scale IoT deployments.
The next diagram illustrates the answer structure.
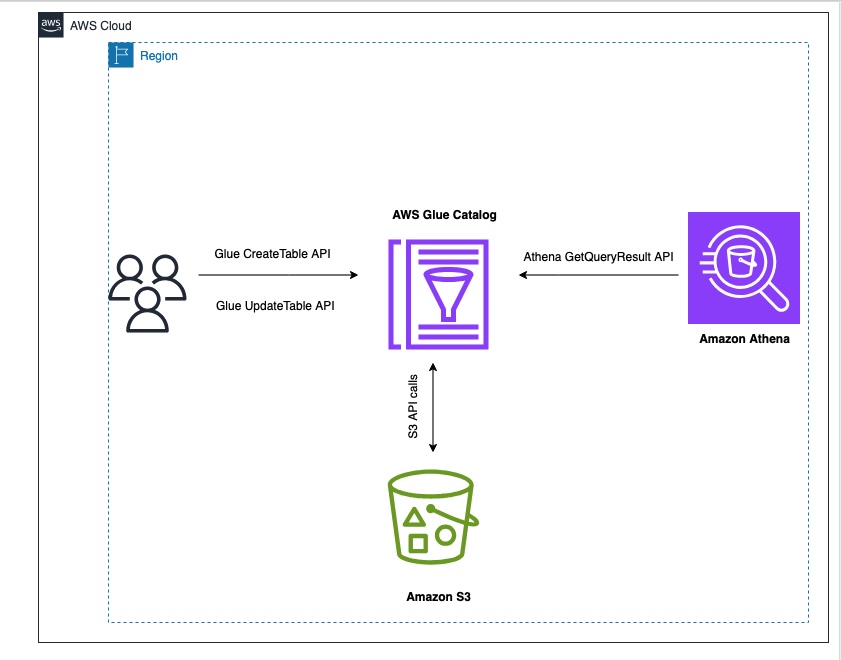
Stipulations:
To carry out the answer, you could have the next conditions:
Create the bottom desk
On this part, we simulate the preliminary setup of a knowledge pipeline for IoT sensor knowledge. This step is essential as a result of it establishes the muse for our schema evolution demonstration. This preliminary desk serves as the place to begin from which our schema will evolve. It permits us to show the right way to deal with schema modifications over time. On this state of affairs, the bottom desk incorporates three key fields: customerID (bigint), sentiment (a struct containing customerrating), and dt (string) as a partition column. And Avro schema literal (‘avro.schema.literal’)together with different configurations. Observe these steps:
- Create a brand new file named
`CreateTableAPI.py`with the next content material. Change'Location': 's3://amzn-s3-demo-bucket/'together with your S3 bucket particulars and
- Run the script utilizing the command:
The schema literal serves as a type of metadata, offering a transparent description of your knowledge construction. In Amazon Athena, Avro desk schema Serializer/Deserializer (SerDe) properties are important for guaranteeing schema is appropriate with the information saved in information, facilitating correct translation for question engines. These properties allow the exact interpretation of Avro-formatted knowledge, permitting question engines to appropriately learn and course of the knowledge throughout execution.
The Avro schema literal supplies an in depth description of the information construction on the partition degree. It defines the fields, their knowledge sorts, and any nested constructions throughout the Avro knowledge. Amazon Athena makes use of this schema to appropriately interpret the Avro knowledge saved in Amazon S3. It makes certain that every discipline within the Avro file is mapped to the proper column within the Athena desk.
The schema info helps Athena optimize question run by understanding the information construction upfront. It may make knowledgeable choices about the right way to course of and retrieve knowledge effectively. When the Avro schema modifications (for instance, when new fields are added), updating the schema literal permits Athena to acknowledge and work with the brand new construction. That is essential for sustaining question compatibility as your knowledge evolves over time. The schema literal supplies specific sort info, which is important for Avro’s sort system. This supplies correct knowledge sort conversion between Avro and Athena SQL sorts.
For complicated Avro schemas with nested constructions, the schema literal informs Athena the right way to navigate and question these nested parts. The Avro schema can specify default values for fields, which Athena can use when querying knowledge the place sure fields is likely to be lacking. Athena can use the schema to carry out compatibility checks between the desk definition and the precise knowledge, serving to to determine potential points. Within the SerDe properties, the schema literal tells the Avro SerDe the right way to deserialize the information when studying it from Amazon S3.
It’s essential for the SerDe to appropriately interpret the binary Avro format right into a kind Athena can question. The detailed schema info aids in question planning, permitting Athena to make knowledgeable choices about the right way to execute queries effectively. The Avro schema literal specified within the desk’s SerDe properties supplies Athena with the precise discipline mappings, knowledge sorts, and bodily construction of the Avro file. This allows Athena to carry out column pruning by calculating exact byte offsets for required fields, studying solely these particular parts of the Avro file from S3 reasonably than retrieving the whole report.
- After creating the desk, confirm its construction utilizing the
SHOW CREATE TABLEcommand in Athena:
Be aware that the desk is created with the preliminary schema as described beneath:
With the desk construction in place, you possibly can load the primary set of IoT sensor knowledge and set up the preliminary partition. This step is essential for organising the information pipeline that may deal with incoming sensor knowledge.
- Obtain the instance sensor knowledge from the next S3 bucket
Obtain preliminary schema from the primary partition
Obtain second schema from the second partition
Obtain third schema from the third partition
- Add the Avro-formatted sensor knowledge to your partitioned S3 location. This represents your first day of sensor readings, organized within the date-based partition construction. Change the bucket identify
amzn-s3-demo-buckettogether with your S3 bucket identify and add a partitioned folder for thedtdiscipline.
- Register this partition within the AWS Glue Knowledge Catalog to make it discoverable. This tells AWS Glue the place to seek out your sensor knowledge for this particular date:
- Validate your sensor knowledge ingestion by querying the newly loaded partition. This question helps confirm that your sensor readings are appropriately loaded and accessible:
The next screenshot reveals the question outcomes.
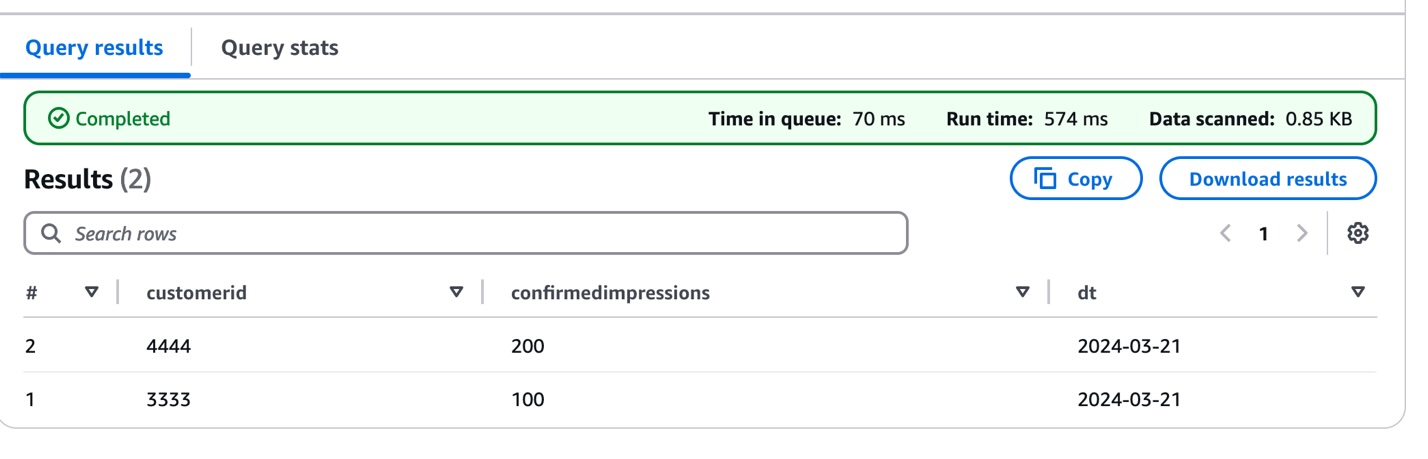
This preliminary knowledge load establishes the muse for the IoT knowledge pipeline, which suggests you possibly can start monitoring sensor measurements whereas getting ready for future schema evolution as sensor capabilities broaden or change.
Now, we show how the IoT knowledge pipeline handles evolving sensor capabilities by introducing a schema change within the second knowledge batch. As sensors obtain firmware updates or new monitoring options, their knowledge construction must adapt accordingly. To point out this evolution, we add knowledge from sensors that now embrace visibility measurements:
- Study the advanced schema construction that accommodates the brand new sensor functionality:
Be aware the addition of the visibility discipline throughout the sentiment construction, representing the sensor’s enhanced monitoring functionality.
- Add this enhanced sensor knowledge to a brand new date partition:
- Confirm knowledge consistency throughout each the unique and enhanced sensor readings:
This demonstrates how the pipeline can deal with sensor upgrades whereas sustaining compatibility with historic knowledge. Within the subsequent part, we discover the right way to replace the desk definition to correctly handle this schema evolution, offering seamless querying throughout all sensor knowledge no matter when the sensors have been upgraded. This method is especially useful in IoT environments the place sensor capabilities regularly evolve, which suggests you possibly can keep historic knowledge whereas accommodating new monitoring options.
Replace the AWS Glue desk
To accommodate evolving sensor capabilities, you could replace the AWS Glue desk schema. Though conventional strategies resembling MSCK REPAIR TABLE or ALTER TABLE ADD PARTITION work for small datasets for updating partition info, you should use an alternate technique to deal with tables with greater than 100K partitions effectively.
We use the Athena partition projection, which eliminates the necessity to course of intensive partition metadata, which may be time-consuming for big datasets. As an alternative, it dynamically infers partition existence and site, permitting for extra environment friendly knowledge administration. This technique additionally hurries up question planning by shortly figuring out related partitions, resulting in sooner question execution. Moreover, it reduces the variety of API calls to the metadata retailer, doubtlessly reducing prices related to these operations. Maybe most significantly, this resolution maintains efficiency because the variety of partitions grows, producing scalability for evolving datasets. These advantages mix to create a extra environment friendly and cost-effective means of dealing with schema evolution in large-scale knowledge environments.
To replace your desk schema to deal with the brand new sensor knowledge, observe these steps:
- Copy the next code into the
UpdateTableAPI.pyfile:
This Python script demonstrates the right way to replace an AWS Glue desk to accommodate schema evolution and allow partition projection:
- It makes use of Boto3 to work together with AWS Glue API.
- Retrieves the present desk definition from the AWS Glue Knowledge Catalog.
- Updates the
'sentiment'column construction to incorporate new fields. - Modifies the Avro schema literal to replicate the up to date construction.
- Provides partition projection parameters for the partition column
dt- Units projection sort to
'date' - Defines date format as
'yyyy-MM-dd' - Allows partition projection
- Units date vary from
'2024-03-21'to'NOW'
- Units projection sort to
- Run the script utilizing the next command:
The script applies all modifications again to the AWS Glue desk utilizing the UpdateTable API name. The next screenshot reveals the desk property with the brand new Avro schema literal and the partition projection.
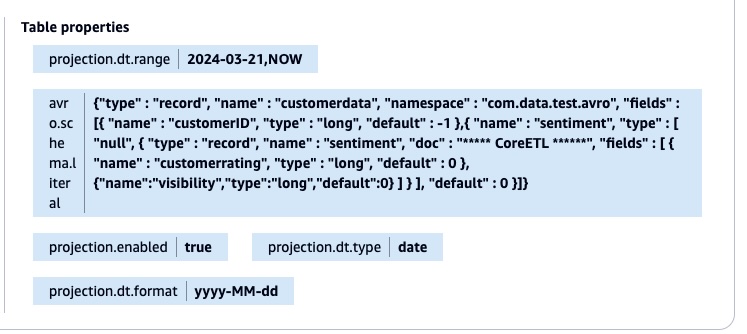
After the desk property is up to date, you don’t want so as to add the partitions manually utilizing the MSCK REPAIR TABLE or ALTER TABLE command. You may validate the consequence by working the question within the Athena console.
The next screenshot reveals the question outcomes.

This schema evolution technique effectively handles new knowledge fields throughout completely different time intervals. Contemplate the 'visibility' discipline launched on 2024-03-22. For knowledge from 2024-03-21, the place this discipline doesn’t exist, the answer robotically returns a default worth of 0. This method makes the question constant throughout all partitions, no matter their schema model.
Right here’s the Avro schema configuration that permits this flexibility:
Utilizing this configuration, you possibly can run queries throughout all partitions with out modifications, keep backward compatibility with out knowledge migration, and assist gradual schema evolution with out breaking present queries.
Constructing on the schema evolution instance, we now introduce a 3rd enhancement to the sensor knowledge construction. This new iteration provides a text-based classification functionality by a 'class' discipline (string sort) to the sentiment construction. This represents a real-world state of affairs the place sensors obtain updates that add new classification capabilities, requiring the information pipeline to deal with each numeric measurements and textual categorizations.
The next is the improved schema construction:
This evolution demonstrates how the answer flexibly accommodates completely different knowledge sorts as sensor capabilities broaden whereas sustaining compatibility with historic knowledge.
To implement this newest schema evolution for the brand new partition (dt=2024-03-23), we replace the desk definition to incorporate the ‘class’ discipline. Right here’s the modified UpdateTableAPI.py script that handles this variation:
- Replace the file
UpdateTableAPI.py:
- Confirm the modifications by working the next question:
The next screenshot reveals the question outcomes.
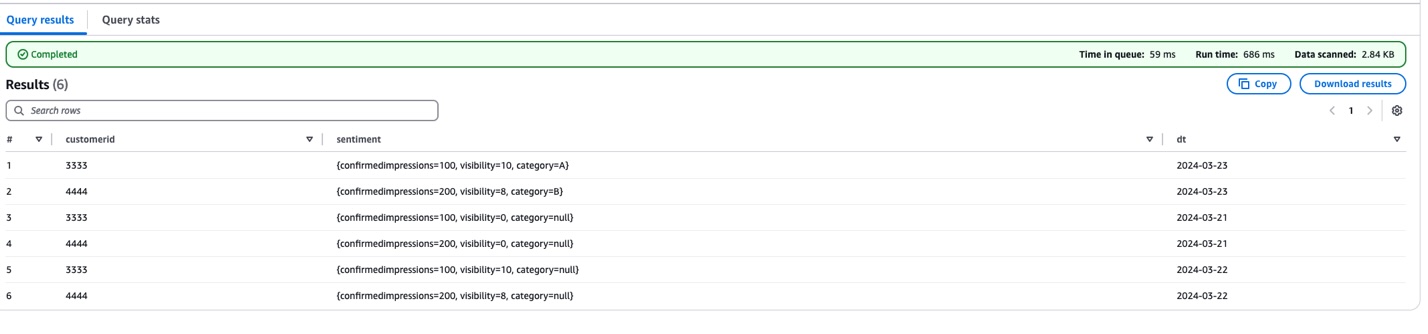
There are three key modifications on this replace:
- Added
'class'discipline (string sort) to the sentiment construction - Set default worth
"null"for the class discipline - Maintained present partition projection settings
To assist that newest sensor knowledge enhancement, we up to date the desk definition to incorporate a brand new text-based 'class' discipline within the sentiment construction. The modified UpdateTableAPI script provides this functionality whereas sustaining the established schema evolution patterns. It achieves this by updating each the AWS Glue desk schema and the Avro schema literal, setting a default worth of "null" for the class discipline.
This supplies backward compatibility. Older knowledge (earlier than 2024-03-23) reveals "null" for the class discipline, and new knowledge consists of precise class values. The script maintains the partition projection settings, enabling environment friendly querying throughout all time intervals.
You may confirm this replace by querying the desk in Athena, which can now present the whole knowledge construction, together with numeric measurements (customerrating, visibility) and textual content categorization (class) throughout all partitions. This enhancement demonstrates how the answer can seamlessly incorporate completely different knowledge sorts whereas preserving historic knowledge integrity and question efficiency.
Cleanup
To keep away from incurring future prices, delete your Amazon S3 knowledge if you happen to not want it.
Conclusion
By combining Avro’s schema evolution capabilities with the facility of AWS Glue APIs, we’ve created a strong framework for managing numerous, evolving datasets. This method not solely simplifies knowledge integration but additionally enhances the agility and effectiveness of your analytics pipeline, paving the best way for extra subtle predictive and prescriptive analytics.
This resolution affords a number of key benefits. It’s versatile, adapting to altering knowledge constructions with out disrupting present analytics processes. It’s scalable, in a position to deal with rising volumes of knowledge and evolving schemas effectively. You may automate it and cut back the guide overhead in schema administration and updates. Lastly, as a result of it minimizes knowledge motion and transformation prices, it’s cost-effective.
Associated references
Concerning the authors
 Mohammad Sabeel Mohammad Sabeel is a Senior Cloud Help Engineer at Amazon Internet Providers (AWS) with over 14 years of expertise in Data Know-how (IT). As a member of the Technical Subject Neighborhood (TFC) Analytics workforce, he’s a Subject material skilled in Analytics providers AWS Glue, Amazon Managed Workflows for Apache Airflow (MWAA), and Amazon Athena providers. Sabeel supplies skilled steering and technical assist to enterprise and strategic clients, serving to them optimize their knowledge analytics options and overcome complicated challenges. With deep subject material experience he allows organizations to construct scalable, environment friendly, and cost-effective knowledge processing pipelines.
Mohammad Sabeel Mohammad Sabeel is a Senior Cloud Help Engineer at Amazon Internet Providers (AWS) with over 14 years of expertise in Data Know-how (IT). As a member of the Technical Subject Neighborhood (TFC) Analytics workforce, he’s a Subject material skilled in Analytics providers AWS Glue, Amazon Managed Workflows for Apache Airflow (MWAA), and Amazon Athena providers. Sabeel supplies skilled steering and technical assist to enterprise and strategic clients, serving to them optimize their knowledge analytics options and overcome complicated challenges. With deep subject material experience he allows organizations to construct scalable, environment friendly, and cost-effective knowledge processing pipelines.
 Indira Balakrishnan Indira Balakrishnan is a Principal Options Architect within the Amazon Internet Providers (AWS) Analytics Specialist Options Architect (SA) Workforce. She helps clients construct cloud-based Knowledge and AI/ML options to deal with enterprise challenges. With over 25 years of expertise in Data Know-how (IT), Indira actively contributes to the AWS Analytics Technical Subject neighborhood, supporting clients throughout numerous Domains and Industries. Indira participates in Girls in Engineering and Girls at Amazon tech teams to encourage women to pursue STEM path to enter careers in IT. She additionally volunteers in early profession mentoring circles.
Indira Balakrishnan Indira Balakrishnan is a Principal Options Architect within the Amazon Internet Providers (AWS) Analytics Specialist Options Architect (SA) Workforce. She helps clients construct cloud-based Knowledge and AI/ML options to deal with enterprise challenges. With over 25 years of expertise in Data Know-how (IT), Indira actively contributes to the AWS Analytics Technical Subject neighborhood, supporting clients throughout numerous Domains and Industries. Indira participates in Girls in Engineering and Girls at Amazon tech teams to encourage women to pursue STEM path to enter careers in IT. She additionally volunteers in early profession mentoring circles.