

{kind=link}
Knowledge is important for contemporary enterprise selections. Many staff, nonetheless, are unfamiliar with SQL. This creates a bottleneck between questions and solutions. A Textual content-to-SQL system solves this drawback immediately. It interprets easy questions into database queries. This text exhibits you learn how to construct a SQL generator. We’ll comply with the concepts from Pinterest’s Textual content-to-SQL engineering group. You’ll learn to convert pure language to SQL. We will even use superior methods like RAG for desk choice.
Understanding Pinterest’s Method
Pinterest needed to make knowledge accessible to everybody. Their staff wanted insights from huge datasets. Most of them weren’t SQL specialists. This problem led to the creation of Pinterest’s Textual content-to-SQL platform. Their journey supplies a terrific roadmap for constructing related instruments.
The First Model
Their first system was simple. A person would ask a query and in addition listing the database tables they thought had been related. The system would then generate a SQL question.
Let’s take a better have a look at its structure:
The person asks an analytical query, selecting the tables for use.
- The related desk schemas are retrieved from the desk metadata retailer.
- The query, chosen SQL dialect, and desk schemas are compiled right into a Textual content-to-SQL immediate.
- The immediate is fed into the LLM.
- A streaming response is generated and exhibited to the person.
This strategy labored, but it surely had a significant flaw. Customers typically had no concept which tables contained their solutions.
The Second Model
To resolve this, their group constructed a wiser system. It used a method referred to as Retrieval-Augmented Era (RAG). As an alternative of asking the person for tables, the system discovered them mechanically. It searched a set of desk descriptions to seek out probably the most related ones for the query. This use of RAG for desk choice made the instrument way more user-friendly.
- An offline job is employed to generate a vector index of tables’ summaries and historic queries towards them.
- Suppose the person doesn’t specify any tables. In that case, their query is reworked into embeddings, and a similarity search is carried out towards the vector index to deduce the highest N appropriate tables.
- The highest N tables, together with the desk schema and analytical query, are compiled right into a immediate for LLM to pick out the highest Ok most related tables.
- The highest Ok tables are returned to the person for validation or alteration.
- The usual Textual content-to-SQL course of is resumed with the user-confirmed tables.
We’ll replicate this highly effective two-step strategy.
Our Plan: A Simplified Replication
This information will aid you construct a SQL generator in two elements. First, we’ll create the core engine that converts pure language to SQL. Second, we’ll add the clever table-finding characteristic.
- The Core System: We’ll construct a fundamental chain. It takes a query and an inventory of desk names to create a SQL question.
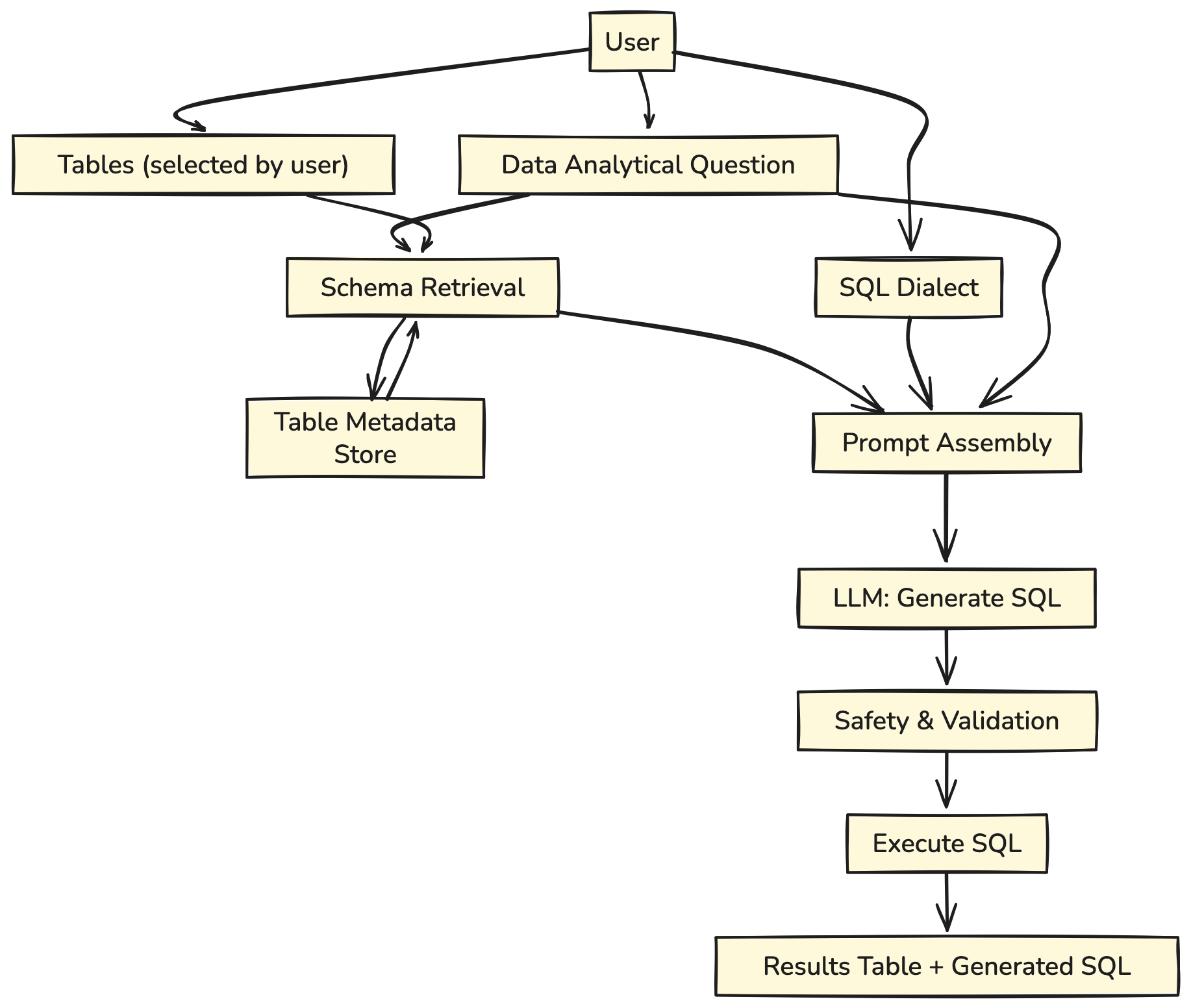
- Consumer enter: Supplies an analytical query, chosen tables, and SQL dialect.
- Schema Retrieval: The system fetches related desk schemas from the metadata retailer.
- Immediate Meeting: Combines query, schemas, and dialect right into a immediate.
- LLM Era: Mannequin outputs the SQL question.
- Validation & Execution: Question is checked for security, executed, and outcomes are returned.
- The RAG-Enhanced System: We’ll add a retriever. This element mechanically suggests the proper tables for any query.
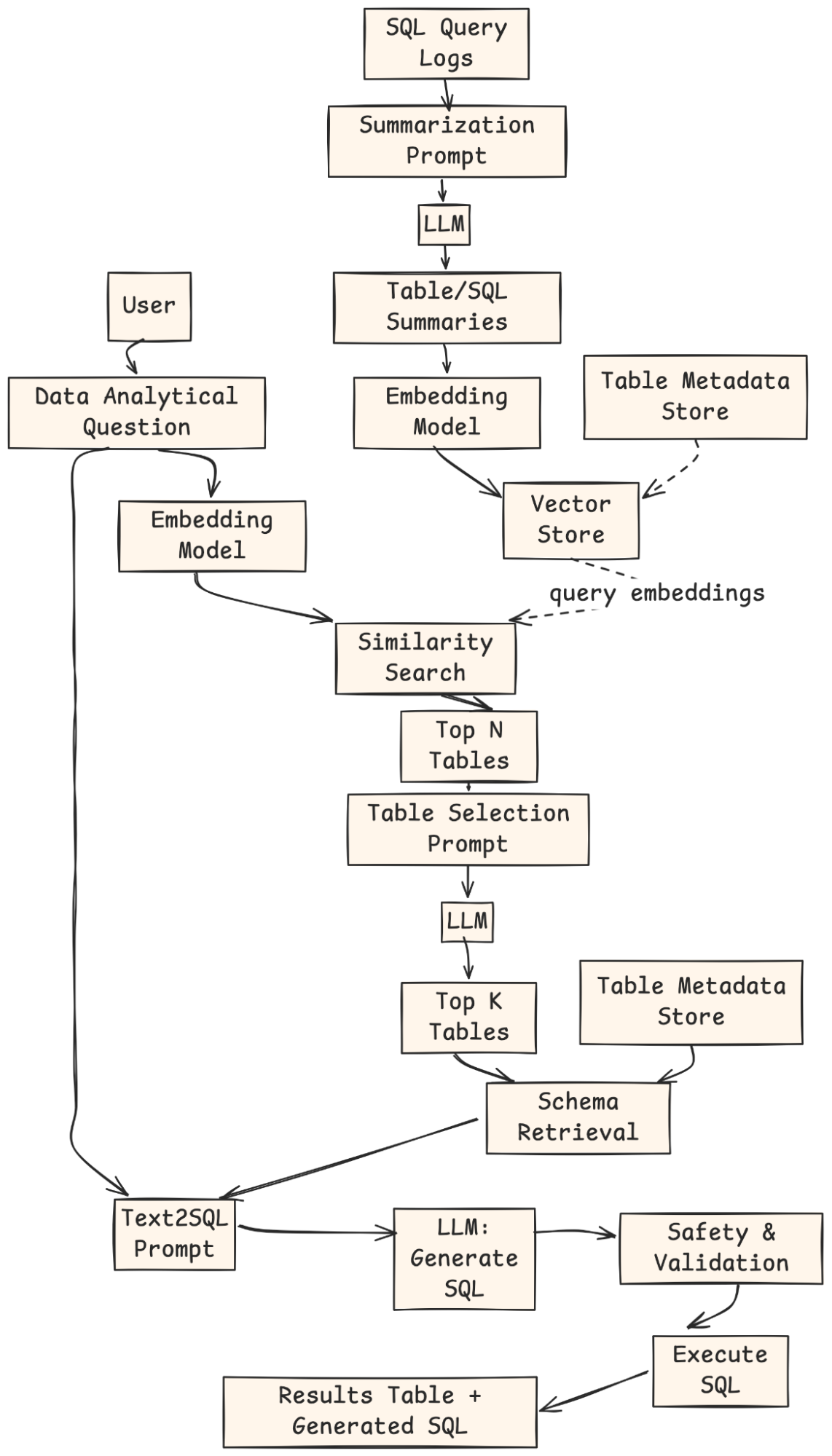
- Offline Indexing: SQL question logs are summarized by an LLM, embedded, and saved in a vector index with metadata.
- Consumer Question: The person supplies a natural-language analytical query.
- Retrieval: The query is embedded, matched towards the vector retailer, and Prime-N candidate tables are returned.
- Desk Choice: An LLM ranks and selects the Prime-Ok most related tables.
- Schema Retrieval & Prompting: The system fetches schemas for these tables and builds a Textual content-to-SQL immediate.
- SQL Era: An LLM generates the SQL question.
- Validation & Execution: The question is checked, executed, and the outcomes + SQL are returned to the person.
We’ll use Python, LangChain, and OpenAI to construct this Textual content-to-SQL system. An in-memory SQLite database will act as our knowledge supply.
Fingers-on Information: Constructing Your Personal SQL Generator
Let’s start constructing our system. Observe these steps to create a working prototype.
Step 1: Setting Up Your Surroundings
First, we set up the required Python libraries. LangChain helps us join parts. Langchain-openai supplies the connection to the LLM. FAISS helps create our retriever, and Pandas shows knowledge properly.
!pip set up -qU langchain langchain-openai faiss-cpu pandas langchain_communitySubsequent, it’s essential to configure your OpenAI API key. This key permits our software to make use of OpenAI’s fashions.
import os from getpass import getpass OPENAI_API_KEY = getpass("Enter your OpenAI API key: ") os.environ["OPENAI_API_KEY"] = OPENAI_API_KEYStep 2: Simulating the Database
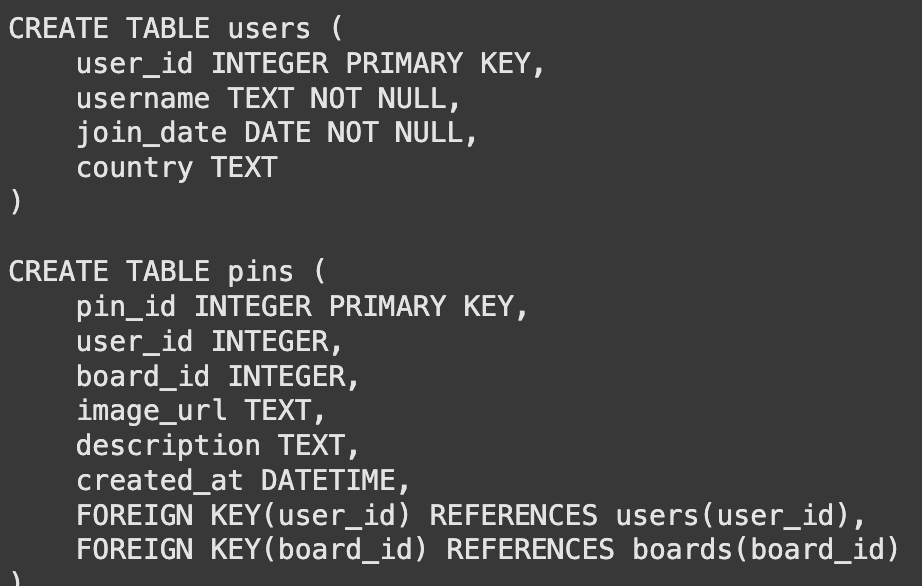
A Textual content-to-SQL system wants a database to question. For this demo, we create a easy, in-memory SQLite database. It can comprise three tables: customers, pins, and boards. This setup mimics a fundamental model of Pinterest’s knowledge construction.
import sqlite3 import pandas as pd # Create a connection to an in-memory SQLite database conn = sqlite3.join(':reminiscence:') cursor = conn.cursor() # Create tables cursor.execute(''' CREATE TABLE customers ( user_id INTEGER PRIMARY KEY, username TEXT NOT NULL, join_date DATE NOT NULL, nation TEXT ) ''') cursor.execute(''' CREATE TABLE pins ( pin_id INTEGER PRIMARY KEY, user_id INTEGER, board_id INTEGER, image_url TEXT, description TEXT, created_at DATETIME, FOREIGN KEY(user_id) REFERENCES customers(user_id), FOREIGN KEY(board_id) REFERENCES boards(board_id) ) ''') cursor.execute(''' CREATE TABLE boards ( board_id INTEGER PRIMARY KEY, user_id INTEGER, board_name TEXT NOT NULL, class TEXT, FOREIGN KEY(user_id) REFERENCES customers(user_id) ) ''') # Insert pattern knowledge cursor.execute("INSERT INTO customers (user_id, username, join_date, nation) VALUES (1, 'alice', '2023-01-15', 'USA')") cursor.execute("INSERT INTO customers (user_id, username, join_date, nation) VALUES (2, 'bob', '2023-02-20', 'Canada')") cursor.execute("INSERT INTO boards (board_id, user_id, board_name, class) VALUES (101, 1, 'DIY Crafts', 'DIY')") cursor.execute("INSERT INTO boards (board_id, user_id, board_name, class) VALUES (102, 1, 'Journey Desires', 'Journey')") cursor.execute("INSERT INTO pins (pin_id, user_id, board_id, description, created_at) VALUES (1001, 1, 101, 'Handmade birthday card', '2024-03-10 10:00:00')") cursor.execute("INSERT INTO pins (pin_id, user_id, board_id, description, created_at) VALUES (1002, 2, 102, 'Eiffel Tower at evening', '2024-05-15 18:30:00')") cursor.execute("INSERT INTO pins (pin_id, user_id, board_id, description, created_at) VALUES (1003, 1, 101, 'Knitted scarf sample', '2024-06-01 12:00:00')") conn.commit() print("Database created and populated efficiently.")Output:

Step 3: Constructing the Core Textual content-to-SQL Chain
The language mannequin can not see our database immediately. It must know the desk constructions, or schemas. We create a operate to get the CREATE TABLE statements. This data tells the mannequin about columns, knowledge varieties, and keys.
def get_table_schemas(conn, table_names): """Fetches the CREATE TABLE assertion for an inventory of tables.""" schemas = [] cursor = conn.cursor() # Get cursor from the handed connection for table_name in table_names: question = f"SELECT sql FROM sqlite_master WHERE kind="desk" AND identify="{table_name}";" cursor.execute(question) end result = cursor.fetchone() if end result: schemas.append(end result[0]) return "nn".be a part of(schemas) # Instance utilization sample_schemas = get_table_schemas(conn, ['users', 'pins']) print(sample_schemas)Output:
With the schema operate prepared, we construct our first chain. A immediate template instructs the mannequin on its activity. It combines the schemas and the person’s query. We then join this immediate to the mannequin.
from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough, RunnableLambda import sqlite3 # Import sqlite3 template = """ You're a grasp SQL professional. Primarily based on the offered desk schema and a person's query, write a syntactically right SQLite SQL question. Solely return the SQL question and nothing else. Right here is the database schema: {schema} Right here is the person's query: {query} """ immediate = ChatPromptTemplate.from_template(template) llm = ChatOpenAI(mannequin="gpt-4.1-mini", temperature=0) sql_chain = immediate | llm | StrOutputParser() Let's check our chain with a query the place we explicitly present the desk names. user_question = "What number of pins has alice created?" table_names_provided = ["users", "pins"] # Retrieve the schema in the principle thread earlier than invoking the chain schema = get_table_schemas(conn, table_names_provided) # Move the schema on to the chain generated_sql = sql_chain.invoke({"schema": schema, "table_names": table_names_provided, "query": user_question}) print("Consumer Query:", user_question) print("Generated SQL:", generated_sql) # Clear the generated SQL by eradicating markdown code block syntax cleaned_sql = generated_sql.strip() if cleaned_sql.startswith("```sql"): cleaned_sql = cleaned_sql[len("```sql"):].strip() if cleaned_sql.endswith("```"): cleaned_sql = cleaned_sql[:-len("```")].strip() print("Cleaned SQL:", cleaned_sql) # Let's run the generated SQL to confirm it really works strive: result_df = pd.read_sql_query(cleaned_sql, conn) show(result_df) besides Exception as e: print(f"Error executing SQL question: {e}")Output:
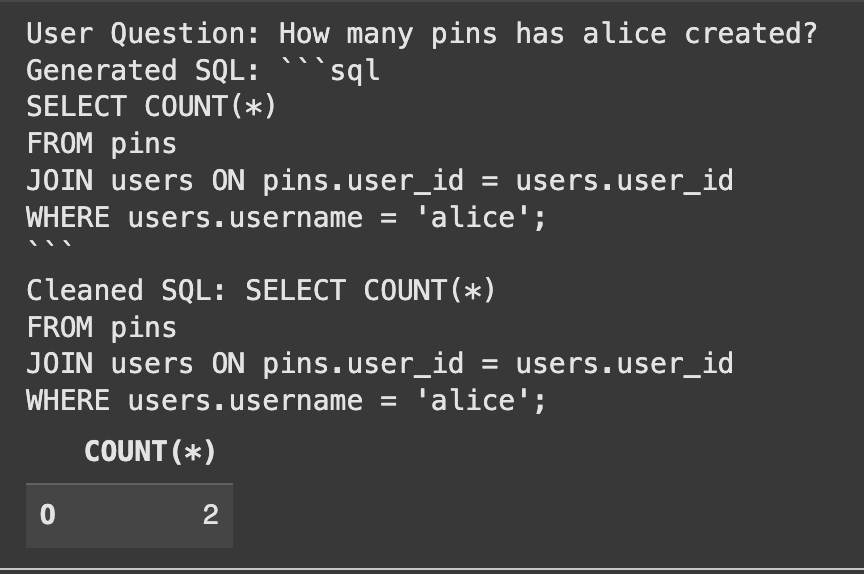
The system appropriately generated the SQL and located the precise reply.
Step 4: Enhancing with RAG for Desk Choice
Our core system works properly, however requires customers to know desk names. That is the precise drawback Pinterest’s Textual content-to-SQL group solved. We’ll now implement RAG for desk choice. We begin by writing easy, pure language summaries for every desk. These summaries seize the which means of every desk’s content material.
table_summaries = { "customers": "Comprises details about particular person customers, together with their username, be a part of date, and nation of origin.", "pins": "Comprises knowledge about particular person pins, linking to the person who created them and the board they belong to. Contains descriptions and creation timestamps.", "boards": "Shops details about user-created boards, together with the board's identify, class, and the person who owns it." }Subsequent, we create a vector retailer. This instrument converts our summaries into numerical representations (embeddings). It permits us to seek out probably the most related desk summaries for a person’s query by way of a similarity search.
from langchain_openai import OpenAIEmbeddings from langchain_community.vectorstores import FAISS from langchain.schema import Doc # Create LangChain Doc objects for every abstract summary_docs = [ Document(page_content=summary, metadata={"table_name": table_name}) for table_name, summary in table_summaries.items() ] embeddings = OpenAIEmbeddings() vector_store = FAISS.from_documents(summary_docs, embeddings) retriever = vector_store.as_retriever() print("Vector retailer created efficiently.")Step 5: Combining Every little thing right into a RAG-Powered Chain
We now assemble the ultimate, clever chain. This chain automates your entire course of. It takes a query, makes use of the retriever to seek out related tables, fetches their schemas, after which passes all the things to our sql_chain.
def get_table_names_from_docs(docs): """Extracts desk names from the metadata of retrieved paperwork.""" return [doc.metadata['table_name'] for doc in docs] # We want a solution to get schema utilizing desk names and the connection throughout the chain # Use the thread-safe operate that recreates the database for every name def get_schema_for_rag(x): table_names = get_table_names_from_docs(x['table_docs']) # Name the thread-safe operate to get schemas schema = get_table_schemas(conn, table_names) return {"query": x['question'], "table_names": table_names, "schema": schema} full_rag_chain = ( RunnablePassthrough.assign( table_docs=lambda x: retriever.invoke(x['question']) ) | RunnableLambda(get_schema_for_rag) # Use RunnableLambda to name the schema fetching operate | sql_chain # Move the dictionary with query, table_names, and schema to sql_chain ) Let's check the entire system. We ask a query with out mentioning any tables. The system ought to deal with all the things. user_question_no_tables = "Present me all of the boards created by customers from the USA." # Move the person query inside a dictionary final_sql = full_rag_chain.invoke({"query": user_question_no_tables}) print("Consumer Query:", user_question_no_tables) print("Generated SQL:", final_sql) # Clear the generated SQL by eradicating markdown code block syntax, being extra strong cleaned_sql = final_sql.strip() if cleaned_sql.startswith("```sql"): cleaned_sql = cleaned_sql[len("```sql"):].strip() if cleaned_sql.endswith("```"): cleaned_sql = cleaned_sql[:-len("```")].strip() # Additionally deal with circumstances the place there could be main/trailing newlines after cleansing cleaned_sql = cleaned_sql.strip() print("Cleaned SQL:", cleaned_sql) # Confirm the generated SQL strive: result_df = pd.read_sql_query(cleaned_sql, conn) show(result_df) besides Exception as e: print(f"Error executing SQL question: {e}")Output:
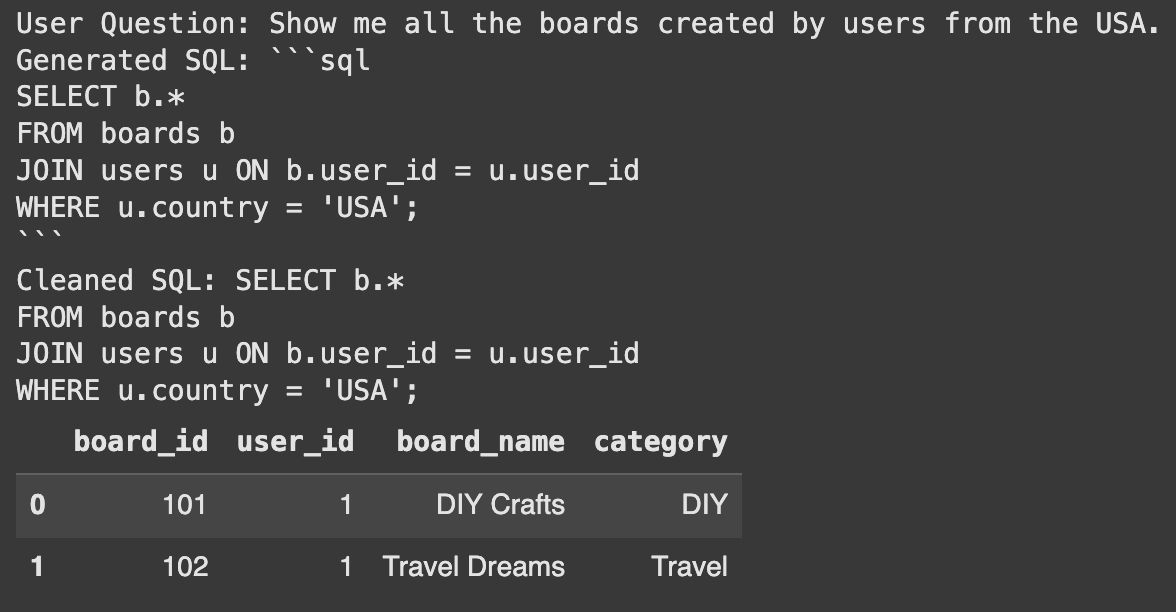
Success! The system mechanically recognized the customers and board tables. It then generated the proper question to reply the query. This exhibits the facility of utilizing RAG for desk choice.
Conclusion
We’ve efficiently constructed a prototype that exhibits learn how to construct an SQL generator. Shifting this to a manufacturing surroundings requires extra steps. You may automate the desk summarization course of. You may additionally embrace historic queries within the vector retailer to enhance accuracy. This follows the trail taken by Pinterest’s Textual content-to-SQL group. This basis supplies a transparent path to creating a robust knowledge instrument.
Often Requested Questions
A. Textual content-to-SQL system interprets questions written in plain language (like English) into SQL database queries. This enables non-technical customers to get knowledge with out writing code.
A. RAG helps the system mechanically discover probably the most related database tables for a person’s query. This removes the necessity for customers to know the database construction.
A. LangChain is a framework for creating purposes powered by language fashions. It helps join totally different parts like prompts, fashions, and retrievers right into a single chain.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Giant Language Fashions than precise people. Captivated with GenAI, NLP, and making machines smarter (so that they don’t exchange him simply but). When not optimizing fashions, he’s in all probability optimizing his espresso consumption. 🚀☕
Login to proceed studying and luxuriate in expert-curated content material.