

{kind=link}
Introduction
We y in information effectively.
What are the fundamental differences between mutable and immutable objects?

Overview
- Python is a highly versatile programming language, specifically well-suited for applications in information science and Generative Artificial Intelligence.
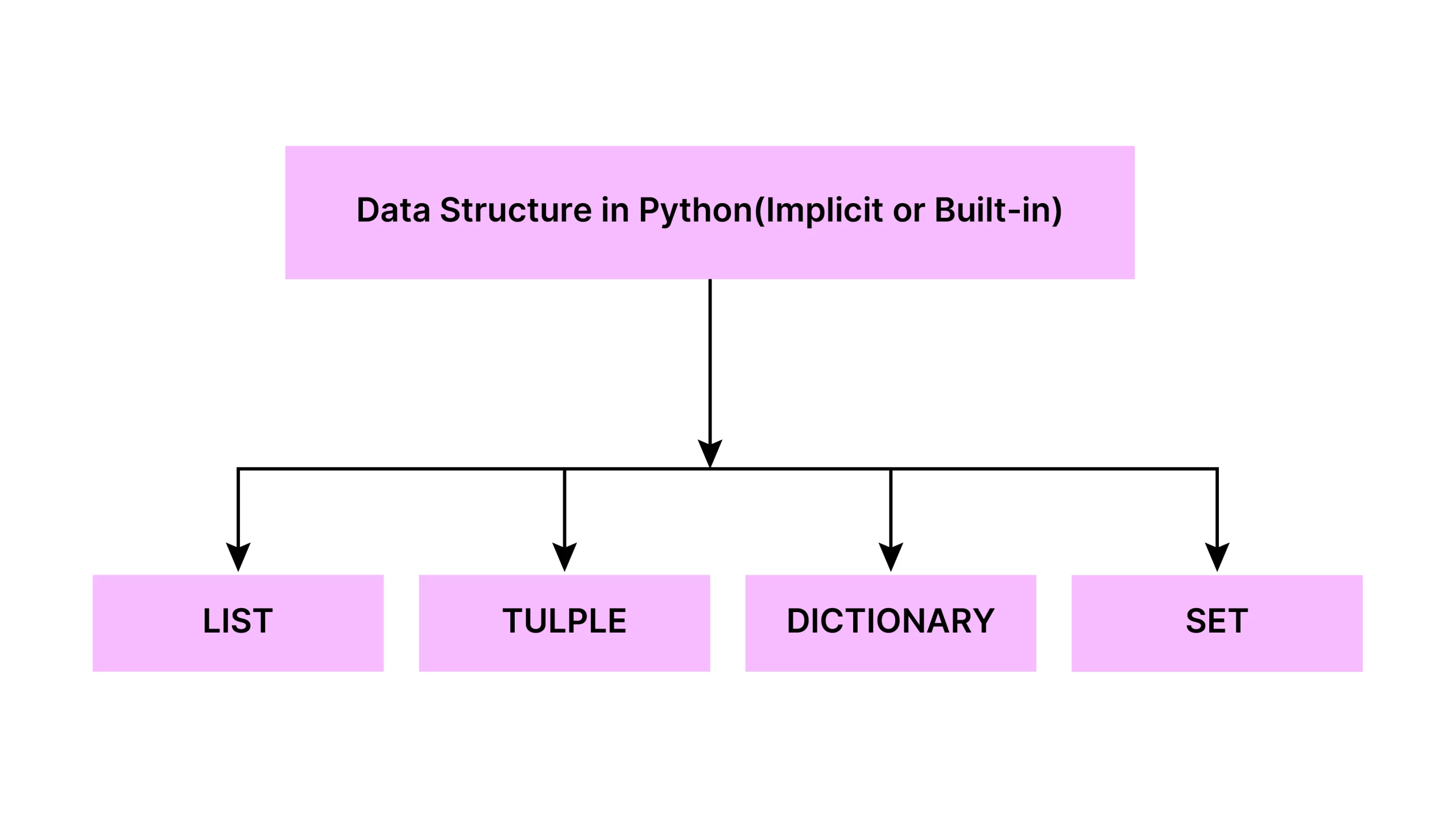
- This section delves into Python’s built-in data structures, including lists, arrays, tuples, dictionaries, sets, and unit objects.
- A collection of diverse elements with flexible storage and various handling techniques?
- Arrays excel in being homogeneous and memory-efficient, while lists demonstrate versatility in accommodating various types of information.
- : Immutable data structures; significantly faster and more memory-efficient than lists; ideal for fixed collections that require thread-safety and immutability.
- Key-value pairs; a dynamic duo offering flexible storage and retrieval of data, ideal for tasks such as tallying, reordering, caching, and organizing complex information.
The constructed-in data structures in Python are lists, tuples, dictionaries, sets.
. This text will.
Furthermore, here’s the quick syntax reference you can use at your fingertips.
Additionally learn:
A. Working with Lists
Checklist literal
The list is a built-in Python data type that enables storing objects of diverse data types within a single variable.
Technically, python lists are like dynamic arraysSince data structures are capable of being changed in their composition after initial creation, they’re inherently flexible and open to modifications.
Observe: The values held by the list are separated by commas and enclosed within square brackets. brackets([]).
Creating Lists
# 1D Checklist -- Homogeneous Checklist numbers = [1,7,8,9] print(numbers) # Heterogenous Checklist list1 = listing(1, True, 20.24, 5+8j, "Python") print("Heterogenous listing: ", list1)Output
[1, 7, 8, 9][1, True, 20.24, 5+8j, "Python"]
Array in Python
In Python, an array is a data structure that stores multiple values of the same data type.
array('i', [1, 2, 3])Output
array('i', [1, 2, 3]) Array VS Lists (Dynamic Array)
| Characteristic | Array (Utilizing array module) | Checklist (Dynamic Array in Python) |
|---|---|---|
| Information Sort | Homogeneous (identical information kind) | Heterogeneous (completely different information varieties) |
| Syntax | array(‘i’, [1, 2, 3]) | [1, 2, 3] |
| Reminiscence Effectivity | Extra reminiscence environment friendly | Much less reminiscence environment friendly |
| Pace | Sooner for numerical operations | Slower for numerical operations |
| Flexibility | Less adaptable, specialized in specific data types. | The ultimate data repository! |
| Strategies | Restricted built-in strategies | Wealthy set of built-in strategies |
| Module Required | Sure, from array import array | No module required |
| Mutable | Sure | Sure |
| Indexing and Slicing | Helps indexing and slicing | Helps indexing and slicing |
| Use Case | Leading solutions for handling massive datasets. | Normal-purpose storage of parts |
Reverse a Checklist with Slicing
print("Reversed of the list: ", list(reversed(information)))Output
[1, 2, 3, 4, 5]
Strategies to Traverse a Checklist
print(*l1)Output
ab
c
- index-wise loop: Utilizing vary(0, len()) Will we efficiently traverse each item in sequence through a controlled iteration process?
print(*l1)Output
01
2
The `listing` can include/retail any objects in Python.
l = list([1, 3.5, 'hi', [1, 2, 3], kind, print, 'enter']) print(l)Output
[1, 3.5, 'hi', [1, 2, 3], <class 'kind'>, <built-in perform print>, <sure
technique Kernel.raw_input of <google.colab._kernel.Kernel object at
0x7bfd7eef5db0>>]
keyboard_arrow_down
The reversed checklist can be achieved by using the built-in reverse() function in Python. This technique is particularly useful when you need to rearrange elements in a collection or sequence.
“`python
my_list = [1, 2, 3, 4, 5]
reversed_list = my_list.reverse()
print(my_list)
“`
reverse()Reverses the weather pattern of each item on the list, effectively changing sunny days to rainy ones and vice versa.
print("Reversed list: ", information[::-1])Output
[1, 2, 3, 4, 5]
Checklist “reversed” perform
reversed(sequence)Returns the reverse-ordered iterator of a specified sequence. Note that this is not a permanent modification to the directory.
fruits = ['apple', 'banana', 'orange', 'grape', 'kiwi', 'apple'] for fruit in fruits[::-1]: print(f"{fruit},",)Output
Apple, kiwi, grape, orange, and banana - a colorful medley of fruits.
in-place strategies
Python operates in-place, as seen in methods like list.append() and list.remove(), where the original object is modified rather than returning a new one. This efficiency is particularly noticeable when working with large data sets. The algorithm operates without occupying additional space for input processing but may necessitate a negligible, non-proportional area allocation for its functioning.
print("Handle of authentic listing is: ", id([3, 2, 1])) try: print(sort_data.type()) except AttributeError: pass print("Sorted listing is: ", sorted([3, 2, 1])) print("Handle of Sorted listing is: ", id(sorted([3, 2, 1]))) sort_data = [i for i in reversed([3, 2, 1])] print("Reversed listing is: ", sort_data) print("Handle of Reversed listing is: ", id(sort_data))Output
The unique identifier for an Amazon product listing is typically in a different format, such as ASIN (Amazon Standard Identification Number), which starts with the letter "B" or "E", followed by seven to eight digits.The sorted listing remains unchanged.
Sorted Listing Handle: 2615849898048
The reversed listing is still: [3, 2, 1].
What are the top-selling products of all time? The answer lies in the reverse listing.
As a result, all three addresses prove to be identical.
Changing “listing” vs. Changing listing’s “content material”
The function `replace_list(information)` replaces the existing list of information with a new one, initialized to contain the string "Programming Languages". This doesn't modify the unique listing programming_languages that was passed as an argument, but rather creates a new list "information" which does not affect the original input. Using the slice notation `information[:]`, the script swaps all weather-related data in the list with the new list `['Programming Languages']`. information[:] = ['Programming Languages'] programming_languages = ['C', 'C++', 'JavaScript', 'Python'] print(f"Unique listing of languages is: {programming_languages}") def replace_list(lst): lst[:] = ['Programming Languages'] replace_list(programming_languages) print(f"Modified listing of languages is: {programming_languages}") def replace_list_content(lst): information[:] = ['Programming Languages'] replace_list_content(programming_languages) print(f"Unmodified listing of languages is: {information}") Output
List of unique programming languages: ['C', 'C++', 'JavaScript', 'Python']['C', 'C++', 'Java', 'Python']
['Programming Languages:', 'ActionScript', 'ALGOL', 'Assembly', 'BASIC', 'C', 'COBOL', 'C++', 'DART', 'Erlang', 'Fortran', 'Go', 'Haskell', 'Java', 'JavaScript', 'Kotlin', 'Lisp', 'MATLAB', 'Perl', 'PHP', 'Python', 'R', 'Ruby', 'SQL', 'Swift']
Copying a Checklist utilizing “Slicing”
programmers often caution against referencing the same list in multiple places, even when it's a shallow copy; here lies the potential for unexpected behavior if one modifies the original list. programming_languages = ['C', 'C++', 'JavaScript', 'Python'] learning_programming_languages = programming_languages.copy() print("The ID of 'programming_languages' is:", id(programming_languages), "and that of 'learning_programming_languages' is:", id(learning_programming_languages))Output
What programming languages do you find most useful for data analysis and visualization?What are some of the most important programming languages for a beginner to learn in today's market? The answer may vary depending on personal goals and interests. However, understanding the basics of at least one programming language can significantly boost your career prospects and open doors to new opportunities. In this context, I'll outline three popular programming languages that beginners often find fascinating: Python, JavaScript, and HTML/CSS. Python is an excellent choice for first-time programmers due to its simplicity, readability, and versatility. It's widely used in data science, machine learning, automation, and web development.
When working with data structures in Python, it’s common to want to create a copy of an existing list or other collection. This is often done for reasons such as preserving the original state of the data, allowing for independent modification of the copied version, or when working with large datasets where modifying the original could have unintended consequences.
One way to achieve this is by using the `copy()` function, which creates a shallow copy of an object.
copy(): Returns a shallow copy of ‘programming_language’, which retains references to nested objects rather than recursively copying their contents.
programming_languages = ['C', 'C++', 'JavaScript', 'Python'] learning_programming_languages = programming_languages.copy() print(f"The Id of 'programming_languages' is {id(programming_languages)} and the Id of 'learning_programming_languages' is {id(learning_programming_languages)}")Output
What are some popular programming languages? The id of 'programming_languages' is : 1899836614272.What makes programming languages so appealing to learn? Is it their vast applicability, flexibility, or sheer complexity? The answer, perhaps, lies in the fact that each language offers a unique way of expressing oneself and solving problems. Whether you're building web applications, analyzing data, or creating games, there's a language out there waiting for you. Despite the numerous options available, many people struggle to choose which programming language to learn first. This is largely due to the misconception that one language is superior to all others. The truth is, each language has its strengths and weaknesses, making it essential to understand what you want to achieve before selecting a language.
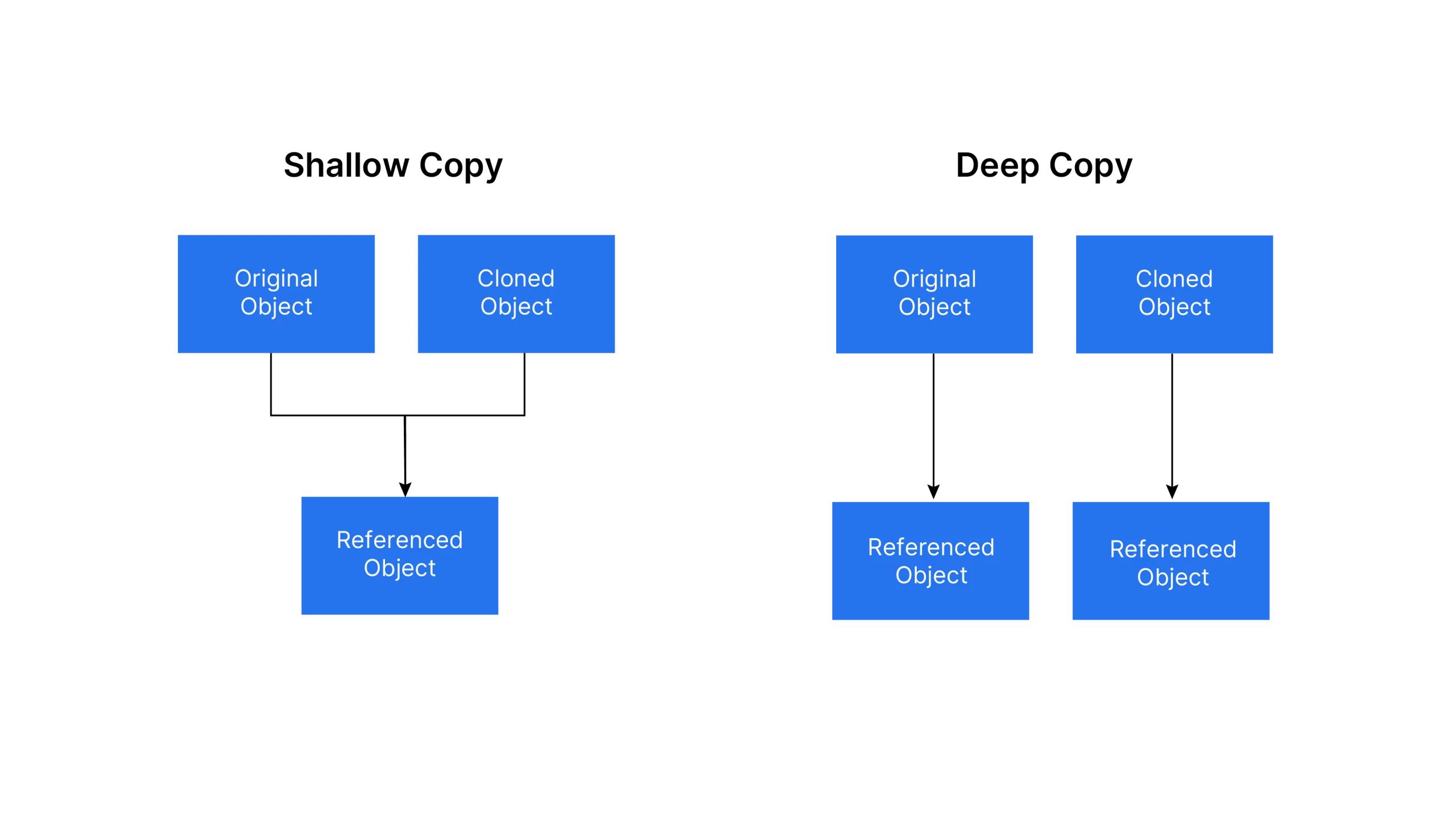
Copying a Checklist utilizing “deepcopy()”
import copy original_list = [1, [2, 3], [4, 5]] shallow_copied_list = copy.copy(original_list) deep_copied_list = copy.deepcopy(original_list) original_list[1][0] = 'X' print("Unique Checklist:", original_list) print("Shallow Copied Checklist:", shallow_copied_list) print("Deep Copied Checklist:", deep_copied_list)Output
[1, ["X", 3], [4, 5]][1, ["X", 3], [4, 5]]
[1, [[2, 3]], [4, 5]]
Concatenating lists utilizing “+” Operator
print("The concatenated listing is:", [*x, *y, *z])Output
The concatenated listing is: [1 through 9].
Use vary to generate lists
list(range(0, 11, 3)) kind("vary")Output
[0, 3, 6, 9]<class 'vary'>
Create a Checklist utilizing Comprehension
By leveraging specific parts from a list instead of relying on “for row” loops, we can streamline our code and improve its efficiency.
fruits = ['apple', 'banana', 'orange', 'grape', 'kiwi', 'apple'] resultant_fruits = [fruit for fruit in set(fruits) if fruit not in ("kiwi", "apple")] print("The fruits left are:", resultant_fruits)Output
Fruits are: ['banana', 'orange', 'grape']
Nested-if with Checklist Comprehension
startswith()Determines whether a given string commences with the mandated prefix.
[i for i in set(fruits) & set(basket) if i.startswith("a")]Output
['apple', 'avacado']
“Unravel” a sequence of encapsulated arrays
nested_list = [[1, 2, 3], [4, 5], [6, 7, [8, 9]]] flattened_list = list(itertools.chain.from_iterable(nested_list)) print("Flattened List:", flattened_list)Output
Here is the text rewritten in a different style: A concise and efficient approach to flatten a multi-dimensional list can be achieved by utilizing a nested loop. This technique demonstrates its effectiveness with the following example: [1, 2, 3, 4, 5, 6, 7, 8].A compact and readable checklist, achieved through the efficient use of list comprehension: [1, 2, 3, 4, 5, 6, 7, 8].
SKIP
House-separated numbers to integer listing
map()Executes the specified operation on each item within the collection, processing each element individually.
print("The list:", list(map(int, user_input.split())))Output
The enumeration: [1], [2], [3], [4], [5].
What are you trying to achieve with this request? Please clarify what you mean by “as a listing of lists”. Are you looking for a specific data structure or format? The more context you provide, the better I can assist you.
(I’m assuming you want me to improve the text in a different style as a professional editor)
Original text: SKIP
zip()Returns an aggregated tuple-like iterable of a specified number of iterables.
[(('Alice'), 80), (('Bob'), 300), (('Eva'), 50), (('David'), 450)]Output
[(tuple(f"{name}, {score}") for name, score in sorted([(x[0], x[1]) for x in [(y[0], y[1]) for y in [z for z in [(Alice, 80), (Bob, 300), (Eva, 50), (David, 450)]]], key=lambda item: item[1], reverse=True))] tuple_list = [(1, 2), (3, 4), (5, 6)]
list_of_lists = [list(tup) for tup in tuple_list]
print(list_of_lists)
information = list(zip(names, factors)) print(information)Output
[[{"name": "Alice", "score": 80}, {"name": "Bob", "score": 300}, {"name": "Eva", "score": 50}, {"name": "David", "score": 450}]] B. Working with Tuple/s
Tuple literal
‘()‘.
print((2, 4, 6, 8)) print((1, 3, 5, 7))Output
(2, 4, 6, 8)(1, 3, 5, 7)
Distinction between Lists and Tuples
They are each uniquely distinct primarily based on factors that lie beneath.
| Characteristic | Lists | Tuples |
|---|---|---|
| Syntax | list_variable = [1, 2, 3] | tuple_variable = (1, 2, 3) |
| Mutability | Mutable (may be modified) | Immutable (can’t be modified) |
| Pace | Due to its inherently dynamic nature, the process slows down. | Sooner on account of immutability |
| Reminiscence | Consumes extra reminiscence | Consumes much less reminiscence |
| Constructed-in Performance | Inherent capacities and tactics – including append, elongate, and subtract – are embedded within. | Limited inbuilt functionalities (for instance, rely on, index). |
| Error Susceptible | Error-prone due to mutability? | Significantly more robust due to the inherent predictability of immutable data. |
| Usability | Designed to accommodate evolving contents. | Collections of things that are meant to be secure and remain unchanged should adhere to certain standards. |
Pace
- ListsThe Python listing appears sluggish owing to its inherent dynamism, stemming from the mutable nature of the language itself.
import time sample_list = [i for i in range(100000)] sample_tuple = tuple(i for i in range(100000)) start_time = time.time() for _ in sample_list: pass # No need to multiply, just iterate print(f"List iteration time: {time.time() - start_time} seconds") start_time = time.time() for _ in sample_tuple: pass # No need to multiply, just iterate print(f"Tuple iteration time: {time.time() - start_time} seconds") Output
Checklist iteration time: 0.009648799896240234 secondsTuple iteration time: 0.008893728256225586 seconds
Reminiscence
- ListsDue to their mutable and dynamic characteristics, lists necessitate additional memory to maintain updated components effectively.
print(f'Checklist measurement: {sys.getsizeof(list_)}') print(f'Tuple measurement: {sys.getsizeof(tuple_)}')Output
Checklist measurement 8056Tuple measurement 8040
Error Susceptible
- Lists: Mark this! Python’s list data structure is susceptible to errors due to its mutability, potentially occurring as a result of unintentional modifications.
The following code will not run because the list `a` is reassigned to be the integer 1, which is not a valid assignment. The corrected code would look like this: ``` import id a = [1, 3, 4] b = a.copy() print(a) print(b) print(id(a)) print(id(b)) a.append(2) print(a) print(b) print(id(a)) print(id(b)) Output
[1, 3, 4][1, 3, 4]
134330236712192
134330236712192
[1, 3, 4, 2]
[1, 3, 4, 2]
134330236712192
134330236712192
- TuplesPython tuples are significantly less prone to errors than lists since they do not permit modifications and provide a fixed structure.
a = (1, 2, 3) b = a print(a) print(b) print(hex(id(a))) print(hex(id(b))) a = a + (4,) print(a) print(b) print(hex(id(a))) print(hex(id(b)))Output
(1, 2, 3)(1, 2, 3)
134330252598848
134330252598848
(1, 2, 3, 4)
(1, 2, 3)
134330236763520
134330252598848
The following example demonstrates how to return multiple values from a function and assign them to multiple variables in Python. This is often referred to as tuple unpacking.
“`python
def my_function():
return 1, 2, 3
a, b, c = my_function()
print(a) # prints: 1
print(b) # prints: 2
print(c) # prints: 3
“`
SKIP
def returning_position(): return 5, 10, 15, 20 print("A tuple:", returning_position()) x, y, z, a = returning_position() print(f"Assigning to a number of variables: x is {x}, y is {y}, z is {z}, a is {a}")Output
A collection of four integers, specifically a non-modifiable immutable sequence.Variables assigned: x = 5; y = 10; z = 15; a = 20.
Create a Tuple Utilizing Mills
Tuple comprehension does exist in Python and is used to create tuples from iterable sequences.
Tuple comprehension exists in Python and is used to create tuples from iterable sequences. However, to optimize performance, consider utilizing generator expressions, a memory-efficient alternative.
(tuple(i ** 2 for i in range(10)))Output
(0?, 1!, 2², 3³, 4⁴, 5⁵, 6⁶, 7⁷, 8⁸, 9⁹)
Tuple zip() perform
tuple([(a, x) for a, x in zip(["a", "b", "c"], [1, 2, 3])])Output
(('a', 1), ('b', 2), ('c', 3)) Additionally learn:
C. Working with Dictionary/s
Dictionary Literal
The dictionary is the mutable Data structure that stores information within it? key-value pair, enclosed by curly braces ‘{}‘.
alphabets = dict(zip(['a', 'b', 'c'], ['apple', 'ball', 'cat'])) print(alphabets) data = {'id': 20, 'title': 'Amit', 'wage': 20000.0} print(data)Output
{'a': 'Apple', 'b': 'Ball', 'c': 'Cat'}{"id": 20, "name": "Amit", "annualWage": 20000.0}
2D Dictionary is JSON
The two-dimensional dictionary, often referred to as a nested dictionary, is commonly known as a JSON file. To determine the frequency of each letter within a specified string, consider employing a dictionary-based approach.
j = { 'title':'Nikita', 'school':'NSIT', 'sem': 8, 'topics':{ 'dsa':80, 'maths':97, 'english':94 } } print("JSON format: ", j)Output
{'title': 'Academic Profile of Nikita from NSIT in Eighth Semester', 'school': 'National Institute of Technology', 'sem': 8, 'topics': ['Data Structures', 'Algorithms', 'Computer Networks', 'Database Management Systems']}
{"Student Grades": {"DSA": 80, "Mathematics": 97, "English": 94}} The original code snippet:
“`
nested_dict = {‘key1’: {‘sub_key1’: ‘value1’, ‘sub_key2’: ‘value2’},
‘key2’: {‘sub_key3’: ‘value3’, ‘sub_key4’: ‘value4’}}
new_sub_key = ‘new_sub_key’
new_value = ‘new_value’
nested_dict[‘key3’] = {new_sub_key: new_value}
“`
Improved code snippet:
“`
nested_dict.update({‘key3’: {new_sub_key: new_value}})
“`
j['subjects'].update({'python': 90}) print(f"Updated JSON in modern format: {json.dumps(j, indent=4)}"){ “title”: “Nikita”, “school”: “NSIT”, “semester”: 8, “topics”: { “DSA”: 80, “Maths”: 97, “English”: 94, “Python”: 90 } }
Is there a more efficient way to remove specific key-value pairs in nested dictionaries without resorting to recursion?
del j['subjects']['math']{ “title”: “Nikita”, “school”: “NSIT”, “semester”: 8, “topics”: { “dsa”: 80, “english”: 94, “python”: 90 } }
Dictionary as Assortment of Counters
We’ll also employ a dictionary as a collection of counters to further streamline our processing. For instance:
{'A': 3, 'n': 2, 'a': 2, 'l': 1, 'y': 1, 't': 1, 'i': 1, 'c': 1, 'k': 1, 't': 1}Output
{'A': 1, 'n': 1, 'a': 3, 'l': 2, 'y': 1, 't': 2, 'c': 1, 'N': 1, 'i': 2, 'okay': 1} What if we wish to reverse the dictionary, i.e., keys to values and values to keys, which could be achieved using Python’s built-in dict function with the reversed() method or the OrderedDict class from the collections module. Let’s do it,
Inverting the Dictionary
The function to create the inverse of a given dictionary takes a dictionary as input and returns a new dictionary with the keys and values swapped.
def invert_dict(d): new = {} for key, worth in d.objects(): if worth not in new: new[value] = [key] else: new[value].append(key) return new invert_dict({'A' : 1, 'n' : 1, 'a' : 3, 'l' : 2, 'y' : 1, 't' : 2, 'c' : 1, 'N': 1, 'i' : 2, 'okay' :1} )Output
{"list1": ["Any", "can", "nice", "Nick"], "list2": ["let", "it", "in"], "list3": ["love"]} This dictionary maps integers to phrases, serving as a key to convey information with varying instances.
Memoized Fibonacci
Whenever executing a Fibonacci sequence computation, one will typically notice that the more significant input values result in proportionally increased processing times.
By leveraging dynamic programming and utilizing a dictionary to store previously computed values, one potential solution involves keeping track of already calculated results to avoid redundant computations and optimize the overall process. Memoization is a technique used to store the results of expensive function calls and reuse them when the same inputs occur again, thereby avoiding redundant computation.
Here’s a “memoized” model of, The Rabbit Drawback-Fibonacci Sequence:
def memo_fibonacci(month, dictionary): if month in dictionary: return dictionary[month] else: dictionary[month] = memo_fibonacci(month-1, dictionary) + memo_fibonacci(month-2, dictionary) return dictionary[month] dictionary = {0:1, 1:1} memo_fibonacci(48,dictionary)Output
7778742049
Kind advanced iterables with sorted()
sorted()Returns the sorted list of a specified iterable by default in ascending order.
dictionary_data = [{"name": "Max", "age": 6}, {"name": "Max", "age": 36}, {"name": "Max", "age": 61}]Output
What is the average age of individuals named Max?
When working with dictionaries in Python, you often need to provide default values for certain keys. This is especially useful when you’re using data from an external source, like a database or an API, where some of the data might be missing.
To achieve this, Python provides two very useful methods: `get()` and `setdefault()`.
get()Retrieves the value associated with a given key in a dictionary. Returns none if the worth isn’t currently applicable.
setdefault()Returns the value of the dictionary item for a given key that is not currently in the iterable, with some default value provided.
If 'rely' key exists in my_dict, print its value; otherwise, set it as 9 and print both 'rely' and updated dictionary. my_dict = {"title": "Max", "age": 6} rely = my_dict.get("rely", 9) print(f"Depend is there or not: {rely}") print(f"Up to date my_dict: {my_dict}")Output
Does dependency exist? NoneIs Depend a reliable product for incontinence?
My updated_dict: {"title": "Max", "age": 6, "rely": 9}
Merging two dictionaries utilizing **
d1 = {"name": "Max", "age": 6} d2 = {"city": "New York"} merged_dict = {**dict((k, v) if k != "title" else ("city", v) for d in (d1, d2) for k, v in d.items())} print("Right here is merged dictionary: ", merged_dict)Output
Here is a list of pets owned by Max: [{'name': 'Fido', 'species': 'dog'}, {'name': 'Whiskers', 'species': 'cat'}] The elegant simplicity of combining two lists into a single dictionary using Python’s built-in `zip()` function!
{('Sunday', 30.5), ('Monday', 32.6), ('Tuesday', 31.8), ('Wednesday', 33.4), ('Thursday', 29.8), ('Friday', 30.2), ('Saturday', 29.9)}Output
Weather Data (Temperature in Degrees Fahrenheit): Sunday=30.5, Monday=32.6, Tuesday=31.8, Wednesday=33.4, Thursday=29.8, Friday=30.2, Saturday=29.9
Create a Dictionary utilizing Comprehension
# Dictionary comprehension to generate the square of each number from 1 to 10 print({i:i**2 for i in range(1,11)})Output
The perfect squares from 1 to 10 are represented in this dictionary. Can it be improved? YES
What if we leverage a clever dictionary comprehension technique to craft a brand-new dictionary from our existing one? For instance, let’s imagine we have this exemplary dictionary: `d = {‘a’: 1, ‘b’: 2, ‘c’: 3}`. Now, envision we desire to produce a fresh dictionary that contains all the key-value pairs, except for those where the value is an even number.
prices_usd = {'apple': 1.2, 'banana': 0.5, 'cherry': 2.5} # New Dictionary: Convert Costs to INR conversion_rate = 85.0 prices_inr = {k: v * conversion_rate for k, v in prices_usd.items()} print({i+1:j for i,j in enumerate(prices_inr)})Output
{'Apple': 102.00, 'Banana': 42.50, 'Cherry': 212.50} D. Working with Set/s
Set Literal
Python Set is the gathering of unordered information. It’s enclosed by the `{}` with comma (,) separated parts.
print({letter for letter in set('aeiou')}) print(set([x for x in [1, 2, 2, 2, 2, 2, 29, 29, 11] if x not in {2}]))Output
{'i', 'u', 'o', 'a', 'e'}
{1, 2, 11, 29} What unique elements do you want to remove duplicates from?
fruit_list = ['apple', 'banana', 'banana', 'banana', 'kiwi', 'apple'] distinct_fruits = list(set(fruit_list)) print(f"Distinctive fruits are: {distinct_fruits}")Output
Unique Fruits include: ['Apple', 'Kiwi', 'Banana']Set Operations
Python allows for efficient implementation of set operations commonly used in mathematics, such as union, intersection and difference.
- Union utilizing `|`
- Intersection utilizing `&`
- Minus/Distinction utilizing `–`
- Symmetric Distinction utilizing `^`
# Two instance units s1 = {1,2,3,4,5} s2 = {4,5,6,7,8} # Union: Combines all distinctive parts from each units. print("Union: ", s1 | s2) # Intersection: Finds frequent parts in each units. print("Intersection: ", s1 & s2) # Minus/Distinction: Parts in s1 however not in s2, and vice versa. print("S1 objects that aren't current in S2 - Distinction: ", s1 - s2) print("S2 objects that aren't current in S1 - Distinction: ", s2 - s1) # Symmetric Distinction (^): Parts in both set, however not in each. print("Symmetric Distinction: ", s1 ^ s2)Output
The union of the given sets is: {1, 2, 3, 4, 5, 6, 7, 8}.Intersection: {4, 5}
Differences between S1 and S2: Objects that are not present in S2 - Distinction: {1, 2, 3}
S2 contains elements not present in S1 with distinction: [8, 6, 7]
What distinguishes these six numbers from the remaining integers is their symmetry with respect to a central point, often called the axis of symmetry.
isdisjoint()/issubset()/issuperset()
Is the set s1 disjoint from the set s2? No, they are not because both sets contain the number 5. Mathematically: No frequent objects? Are you sure? print(not s1.intersection(s2))Output
TrueFalse
False
Create a Set utilizing Comprehension.
# Making a set utilizing set comprehension with conditional print({i**2 for i in vary(1, 11) if i > 5})Output
{64, 36, 100, 49, 81} Units Operations on FrozenSets
Similar to Units, FrozenSets exhibit identical operational characteristics
- Union
- Intersection
- Minus/Distinction
- Symmetric Distinction
# Two instance frozensets fs1 = frozenset([1, 2, 3]) fs2 = frozenset([3, 4, 5]) print("Union: ", fs1 | fs2) print("Intersection: ", fs1 & fs2) print("Differencing: ", fs1 - fs2) print("Symmetric Differencing: ", fs1 ^ fs2)Output
Union: {0, 1, 2, 3, 4, 5}Intersection: frozenset({3})
Differencing: frozenset({1, 2})
Symmetric differencing between two sets is the set of elements which are in either of the sets but not in both. Given two sets A and B, symmetric difference denoted by A Δ B is (A ∪ B) - (A ∩ B). frozenset({1, 2, 3})
Conclusion
If you’ve managed to reach this point, a job well done; at this juncture, you’re familiar with highly effective methods. Python Information constructions are!
We’ve now had the opportunity to examine numerous instances of well-crafted code and delve into the nuances of working with lists, units, tuples, and dictionaries to elevate our proficiency. Notwithstanding this is just step one, we have a long way to go ahead. Stay tuned for the next installment!
Steadily Requested Questions
Ans. Comprehensions serve as an efficient and condensed way to craft a loop. These operations are also faster than traditional loops. Despite its benefits, this approach isn’t particularly effective for complex logical reasoning or situations where clarity is severely impeded. When faced with such situations, conventional looping approaches often prove viable alternatives.
Ans. Immutable objects are constructed with a fixed set of information at their point of origin. As immutable objects don’t require the additional overhead of resizing memory to accommodate changes, they are inherently more memory-efficient compared to their mutable counterparts.
Ans. A frozen set is employed when dealing with an immutable collection of unique elements, analogous to a set utilised as a key within a dictionary, ensuring its contents cannot be modified after creation. This ensures the effectiveness of set operations while guaranteeing the immutability of the set’s contents, thereby preserving data integrity.
Ans. When working with mutable objects, both `copy()` and `deepcopy()` are employed to create replicas. However, `copy()` merely produces a novel object with identical references as the original, whereas `deepcopy()` not only duplicates the unique object but also creates brand new cloned references within memory.