

{kind=link}

(Yurchanka-Siarhei/Shutterstock)
When Cloudflare reached the boundaries of what its current ELT instrument might do, the corporate had a choice to make. It might attempt to discover a an current ELT instrument that would deal with its distinctive necessities, or it might construct its personal. After contemplating the choices, Cloudflare selected to construct its personal massive information pipeline framework, which it calls Jetflow.
Cloudflare is a trusted international supplier of safety, community, and content material supply options utilized by hundreds of organizations world wide. It protects the privateness and safety of thousands and thousands of customers each day, making the Web a safer and extra helpful place.
With so many providers, it’s not shocking to be taught that the corporate piles up its share of knowledge. Cloudflare operates a petabyte-scale information lake that’s full of hundreds of database tables each day from Clickhouse, Postgres, Apache Kafka, and different information repositories, the corporate stated in a weblog submit final week.
“These duties are sometimes complicated and tables could have a whole lot of thousands and thousands or billions of rows of latest information every day,” the Cloudflare engineers wrote within the weblog. “In whole, about 141 billion rows are ingested each day.”
When the quantity and complexity of knowledge transformations exceeded the potential its current ELT product, Cloudflare determined to switch it with one thing that would deal with it. After evaluating the marketplace for ELT options, Cloudflare realized that there have been nothing that was generally out there was going to suit the invoice.

Picture courtesy Cloudflare
“It grew to become clear that we would have liked to construct our personal framework to deal with our distinctive necessities–and so Jetflow was born,” the Cloudflare engineers wrote.
Earlier than laying down the primary bits, the Cloudflare staff set out its necessities. The corporate wanted to maneuver information into its information lake in a streaming trend, because the earlier batch-oriented system typically exceeded 24 hours, stopping day by day updates. The quantity of compute and reminiscence additionally ought to come down.
Backwards compatibility and suppleness had been additionally paramount. “As a consequence of our utilization of Spark downstream and Spark’s limitations in merging disparate Parquet schemas, the chosen answer needed to provide the pliability to generate the exact schemas wanted for every case to match legacy,” the engineers wrote. Integration with its metadata system was additionally required.
Cloudflare additionally needed the brand new ELT instruments’ configuration information to be model managed, and to not grow to be a bottleneck when many adjustments are made concurrently. Ease-of-use was one other consideration, as the corporate deliberate to have individuals with completely different roles and technical skills to make use of it.
“Customers mustn’t have to fret about availability or translation of knowledge sorts between supply and goal methods, or writing new code for every new ingestion,” they wrote. “The configuration wanted also needs to be minimal–for instance, information schema ought to be inferred from the supply system and never have to be provided by the person.”
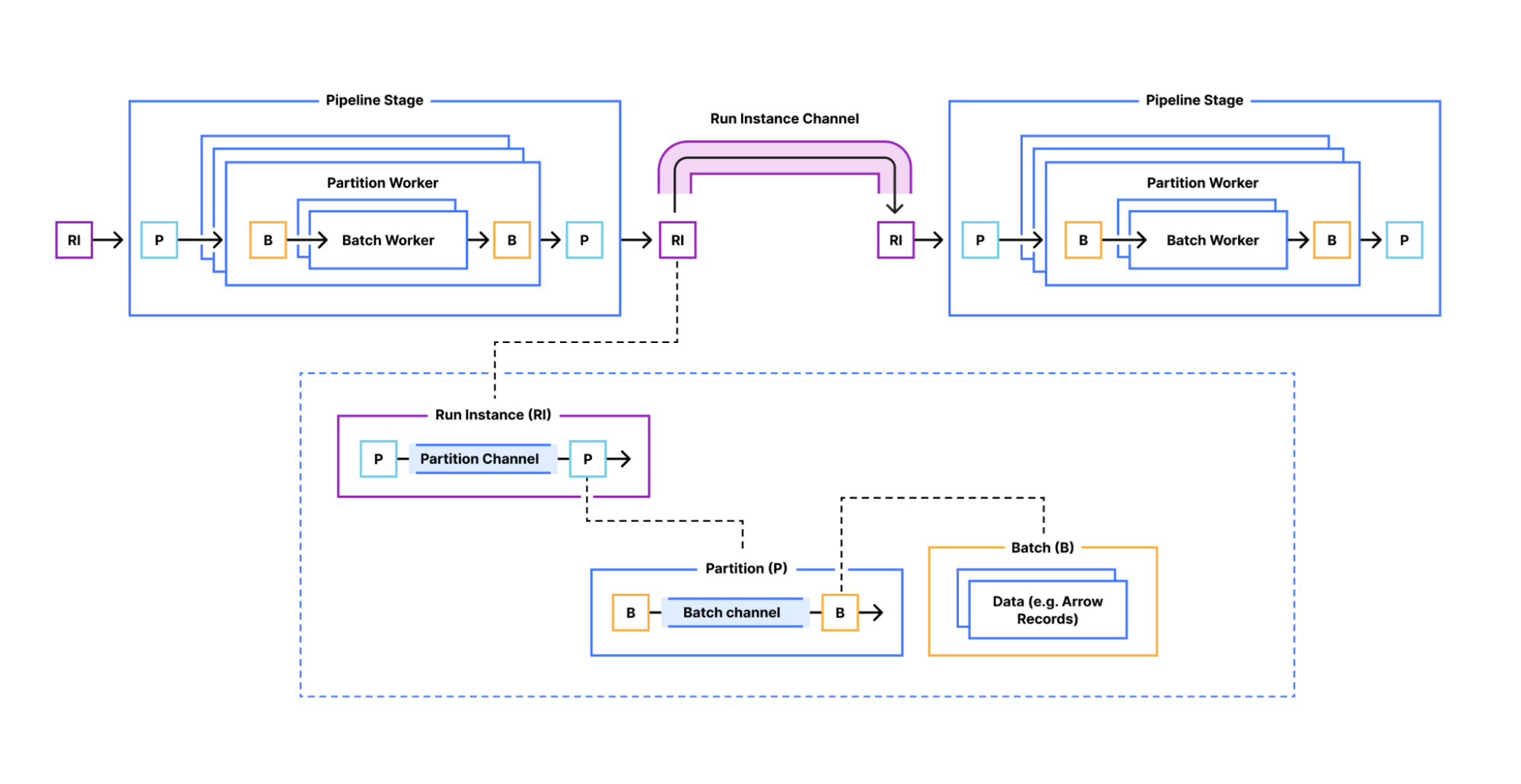
Jetflow is an ELT instrument from Cloudflare (Picture courtesy Cloudflare)
On the identical time, Cloudflare needed the brand new ELT instrument to be customizable, and to have the choice of tuning the system to deal with particular use instances, resembling allocating extra assets to deal with writing Parquet information (which is a extra resource-heavy job than studying Parquet information). The engineers additionally needed to have the ability to spin up concurrent staff in several threads, completely different containers, or on completely different machines, on an as-needed foundation.
Lastly, they needed the brand new ELT instrument to be testable. Engineers needed to allow customers to have the ability to write checks for each stage of the info pipeline to make sure that all edge instances are accounted for earlier than selling a pipeline into manufacturing.
The ensuing Jetflow framework is a streaming information transformation system that’s damaged down into customers, transformers, and loaders. The information pipeline is created as a YAML file, and the three levels might be independently examined.
The corporate designed Jetflow’s parallel information processing capabilities to be idempotent (or internally constant) each on complete pipeline re-runs in addition to with retries of updates to any specific desk as a result of an error. It additionally encompasses a batch mode, which supplies chunking of huge information units down into smaller items for extra environment friendly parallel stream processing, the engineers write.
One of many greatest questions the Cloudflare engineers confronted was how to make sure compatibility with the assorted Jetflow levels. Initially the engineers needed to create a customized sort system that will permit levels to output information in a number of information codecs. That become a “painful studying expertise,” the engineers wrote, and led them to maintain every stage extractor class working with only one information format.
The engineers chosen Apache Arrow as its inner, in-memory information format. As a substitute of an inefficient strategy of studying row-based information after which changing it into the columnar format, that are used to generate Parquet information (its main information format for its information lake), Cloudflare makes an effort to ingest information in column codecs within the first place.![]()
This paid dividends for shifting information from its Clickhouse information warehouse into the info lake. As a substitute of studying information utilizing Clickhouse’s RowBinary format, Jetflow reads information utilizing Clickhouse’s Blocks format. Through the use of the ch-go low stage library, Jetflow is ready to ingest thousands and thousands of rows of knowledge per second utilizing a single Clickhouse connection.
“A invaluable lesson realized is that as with every software program, tradeoffs are sometimes made for the sake of comfort or a typical use case that will not match your individual,” the Cloudflare engineers wrote. “Most database drivers have a tendency to not be optimized for studying massive batches of rows, and have excessive per-row overhead.”
The Cloudflare staff additionally made a strategic choice when it got here to the kind of Postgres database driver to make use of. They use the jackc/pgx driver, however bypassed the database/sql Scan interface in favor of receiving uncooked information for every row and utilizing the jackc/pgx inner scan capabilities for every Postgres OID. The ensuing speedup permits Cloudflare to ingest about 600,000 rows per second with low reminiscence utilization, the engineers wrote.
At present, Jetflow is getting used to ingest 77 billion data per day into the Cloudflare information lake. When the migration is full, it will likely be operating 141 billion data per day. “The framework has allowed us to ingest tables in instances that will not in any other case have been attainable, and offered vital value financial savings as a result of ingestions operating for much less time and with fewer assets,” the engineers write.
The corporate plans to open supply Jetflow sooner or later sooner or later.
Associated Gadgets:
ETL vs ELT for Telemetry Information: Technical Approaches and Sensible Tradeoffs
Exploring the Prime Choices for Actual-Time ELT
50 Years Of ETL: Can SQL For ETL Be Changed?