

{kind=link}

TL;DR
- Large language models and various generative AI styles can replicate crucial segments of instructional content.
- Certain triggers seem to liberate valuable insights within coaching sessions.
- We face numerous pressing copyright concerns: while coaching must not infringe on existing rights, “authorized” does not necessarily equate to “authentic.” For instance, we can draw an analogy to MegaFace, where surveillance models were trained on images of minors without their informed consent.
- As creative industries rely on artificial intelligence, traditional copyright laws may no longer suffice to incentivize innovation and cultural production?
In Jorge Luis Borges’s famous tale “Pierre Menard, Author of the Quixote,” the protagonist Pierre Menard endeavors to recreate a specific portion of Miguel de Cervantes’s classic novel Don Quixote. Rewrite the classic novel phrase by phrase
His objective lay far beyond mere mechanical transcription, with no intention of merely replicating the original. He aspired to pen numerous passages that mirrored, word-for-word and verse-by-verse, the literary masterpieces of Miguel de Cervantes, a feat of remarkable ambition.
Be taught quicker. Dig deeper. See farther.
Seeking authenticity, he initially attempted to channel Don Quixote’s creator, Miguel de Cervantes, by mastering Spanish and erasing historical context, only to conclude that rewriting the text from the perspective of Menard himself would yield greater insight. Here is the rewritten text:
The narrator notes a striking similarity between Cervantes’ textual content and Menard’s: both are verbally identical, yet the latter is infinitely richer. This phenomenon bears an uncanny resemblance to the capabilities of generative AI models (LLMs, text-to-image, et al.), which can reproduce vast swaths of training data without explicitly storing those chunks in their architecture or weights; the output mimics the original with probabilistic precision, lacking the very essence of human creativity – blood, sweat, tears, and life experience that permeates human writing and cultural production.
ChatGPT doesn’t receive coaching information in itself? What’s the current state of software engineering in 2023?
Fate’s whim besets this artificial form, impelling it to commit its musings to parchment as if guided by some whimsical Muse: “To” doth beguile, inviting “be”, which in turn entices “or” – and thus the chain of thought unfoldeth.
So, apparently, next-word prediction and its associated features on Prime can effectively replicate segments of coaching content. What is the purpose of that statement? I’ve had the opportunity to participate in projects that are comparable to those found on Project Gutenberg, alongside. Researchers are uncovering ways to distill actionable insights from ChatGPT.
While exploring diverse types of foundation styles, recent research by Gary Marcus and Reid Southerland has demonstrated the ability to generate photographs from text-to-image models for a wide range of films, including movies, series, and numerous other multimedia formats. This appears to be a natural evolution, rather than a bug, and it’s likely self-evident why they titled their IEEE opinion piece “Generative AI Has a Visible Plagiarism Shortcoming.” It’s ironic that, in this very article, we refrained from reproducing Marcus’ photographs due to concerns about copyright infringement—a risk that Midjourney seemingly disregards, and one that even IEEE and the authors may have taken. The field is moving swiftly: OpenAI’s text-to-video model is still on the horizon, while DALL-E 2 has already been released.
There exist two main categories: lossless and lossy compression, with machine learning being an example of the latter. While they share some characteristics, their generative abilities truly set them apart from traditional compressors.
Ted Chiang penned an insightful article for the New Yorker, titled “____”, which commences by drawing parallels between a photocopier’s minor misstep and its compression algorithm’s subtle flaws in capturing digital images. While it’s a captivating piece that warrants consideration, its uneasy tone leaves me feeling awkward. While the analogy initially appears flawed: fundamentally, LLMs don’t merely blur but execute extremely non-linear transformations, making it impossible to simply squint and grasp the original; conversely, for the photocopier, an error is a bug, whereas for LLMs, all errors are deliberate choices. Let me clarify. Or, slightly, :
When discussing the concept of “hallucination” in Large Language Models (LLMs), I often find myself grappling with certain reservations. As a consequence, in essence, LLMs merely fabricate reality. They’re dream machines.
We guide their objectives with targeted cues. The prompts initiate the dream, generally yielding a productive outcome based on the Large Language Model’s fuzzy recollection of its training documentation.
When language models stray from factual accuracy, we categorize them as “hallucinations.” Though initially seeming like an anomaly, this outcome is merely the LLM’s consistent behavior in action.
What kind of search are you on about? The AI system promptly retrieves and presents a precise match for the coaching documentation, reproducing the original content from its database with exactitude. This search engine has a notable “creativity limitation” – it will never proffer anything novel. An LLM (Lucid Dreamer’s Manual) with a 100% probability of dreaming possesses the incapacitating hallucination drawback. While a search engine may lack subjective imagination, its primary function of processing vast amounts of data and providing accurate results doesn’t necessarily rely on creative thinking?
By developing products that harmoniously merge the strengths of search engines and language models, we may be creating a highly lucrative domain; companies like [company name], for instance, are also making noteworthy progress in this area.
While Large Language Models (LLMs) consistently exhibit hallucinations in their outputs.1 They will also reproduce large segments of coaching content, rather than simply pointing to a useful destination, as Karpathy aptly describes summarization. Does the mannequin store the coaching data within its framework? Properly, no, not fairly. But additionally… Sure?
Can you really hold onto the original painting by disassembling it into tiny fragments and reassembling them as a new work of art? Does the essence of the original remain, or has it been irreparably altered? The question itself becomes a thought-provoking puzzle, challenging our understanding of identity and existence. Until you discover the method to reorder these elements and obtain a distinct outcome. You want a key. Here are the potential triggers or cues that can unlock valuable insights and guidance for those in the know.
Whether generative AI can create something truly novel remains a topic of debate; while I’m cautiously optimistic, I think it’s still too early to say for certain. When considering the broader implications, there are crucial factors to take into account regarding what happens.
The legal status of LLMs remains ambiguous, with questions surrounding their potential to infringe on creative works like those owned by Sarah Silverman and George R.R. Martin? Whoever may have borrowed from our collective wisdom – Martin and I among them. While I don’t assume that copyright is the ideal framework for evaluating whether training and deployment should be allowed or not, Copyright was established in reaction to the possibilities offered by mechanical reproduction; now, we inhabit an era of digital replication, dissemination, and technological advancements that demand a reevaluation of its scope and applicability. Ultimately, the revised text is:
It’s also about the kind of society we wish to coexist in collectively; originally, copyright was designed to encourage specific forms of cultural creation.
Early precursors to modern copyright law, dating back to 1710 in England, were established to encourage authors to write and stimulate further creative output. Prior to this point, the Crown had conferred exclusive printing privileges on the Stationers’ Company, effectively establishing a monopoly, and there were no financial inducements to author work. While OpenAI and its counterparts refrain from violating intellectual property laws, what type of cultural production are we inadvertently fostering – or neglecting – when we fail to consider an array of externalities at play in this space?
Keep in mind the context. Actors and writers are increasingly being paid a base salary ranging from $300,000 to $900,000 USD.2 In today’s world, where numerous creatives are submerged in promoting and advertising efforts? As the effects of AI-powered tools like ChatGPT take hold, certain occupations may be disproportionately affected, particularly in the event that macroeconomic pressures persistently weigh heavily on the global economy. !
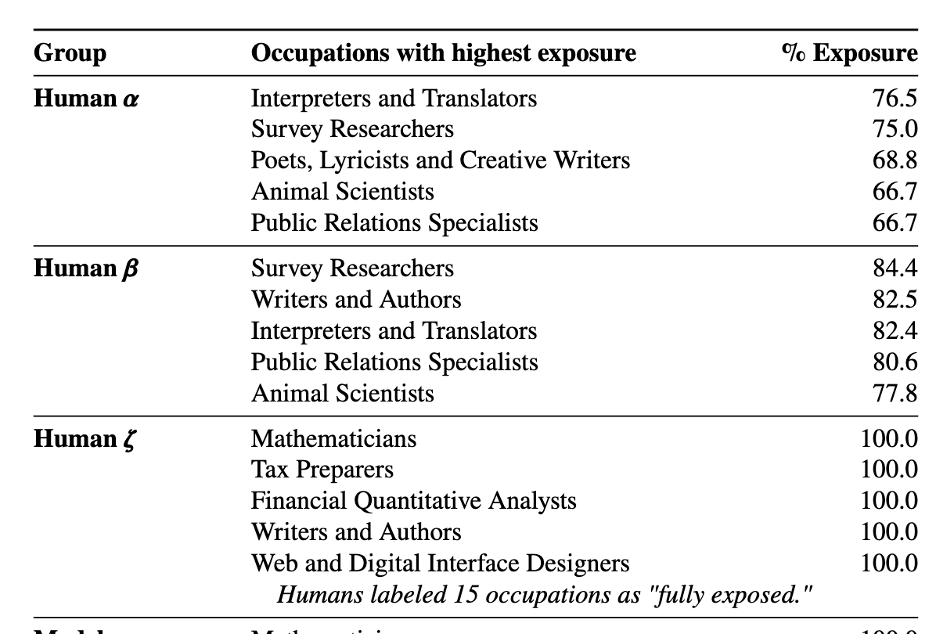
Regarding copyright law, despite lacking expertise in this area, it seems that Large Language Models (LLMs) could potentially be considered “transformative” works under US legislation, thereby warranting fair use protections. Fashions’ lack of output appears to negate any potential copyright infringement concerns. However, even if a corpus’s collection of knowledge is legally permitted – albeit improbable on a massive scale – this authorization does not guarantee authenticity, nor does it suggest that informed consent was obtained.
Let’s consider another example – namely, MegaFace. In “,” the reported that
In 2005, a mother from Evanston, Illinois, registered on Flickr. She posted pictures of her children, Chloe and Jasper. She had all but forgotten about the online account, its existence a faint memory.
Twenty years hence, the faces of these individuals would be incorporated into a vast repository utilized for testing and refining cutting-edge facial recognition technologies, renowned for their unparalleled subtlety across the globe.
What’s extra,
The facial recognition database contains likenesses of nearly 700,000 individuals, having been acquired by scores of corporations to train a novel generation of face-identification algorithms capable of tracing protesters, surveilling terrorists, identifying problem gamblers, and monitoring the general public en masse.
It would be challenging to convincingly argue that the authorization, which appears to be the norm in most cases, is genuine, and even more difficult to assert that informed consent exists. It’s unlikely that many people would view such an approach as morally justifiable. I improve this instance for a multitude of reasons:
- Just because something is authorized doesn’t necessarily mean we’d want it to proceed.
- This innovative paradigm, fueled by specialized expertise, empowers the collection, processing, and utilization of vast amounts of knowledge to drive algorithmic, fashion-based, and product applications – the same framework that underlies the operation of GenAI models.
- The ubiquitous paradigm of Huge Tech’s operations has become commonplace, with many accepting its proliferation across various forms; yet, for those who developed LLMs two decades ago by harnessing web-scale data, this conversation would likely have a distinct tone.
You should clarify what you mean by “authentic/illegitimate” and provide at least a preliminary definition to avoid confusion. In 1626, the Dutch West India Company “purchased” the island of Manhattan from the Lenape Native Americans at a reportedly modest cost of $24 worth of trinkets, with Peter Minuit overseeing the transaction. That wasn’t unlawful. Was it authentic? The assessment depends entirely on one’s perspective. The Lenape did not possess a notion of land ownership, just as they did not have a concept of knowledge ownership. This notion that the Dutch “purchased” Manhattan from Native Americans has echoes of unwitting acquiescence. It’s additionally related as .
.
It’s entirely plausible that OpenAI may settle out of court; OpenAI has strong incentives to act, and the potential litigant also has short-term incentives to do so. Notwithstanding its initial hesitation, the entity has subsequently proven adept at persisting through the prolonged gaming session. Beware the temptation to view a situation in isolation, for its true implications and consequences often extend far beyond the immediate context. As we step back, we inhabit a world where traditional journalism lies decimated, its very fabric torn asunder by the pervasive influence of the internet, online search, and social media. Are likely to be among the last major publications standing, having toiled tirelessly and innovatively throughout the evolution of the internet since its inception.3
The rise of platforms affiliated with Google has disrupted traditional industry dynamics, inserting themselves as intermediaries between creators and consumers, thereby crippling business models for many content producers. They are also misleading about their actions: while the Australian authorities were contemplating requiring Google to provide payment information retailers it links to in search results,
Here’s where you can find help: Now, remember that we don’t offer comprehensive articles; instead, we direct you to a location where you can receive assistance and guide you in getting there. Paid links fundamentally alter the functioning of search engines like Google, compromising their integrity and disrupting the internet’s underlying dynamics. When assigning monetary value to link to credible information, you undermine the fundamental principles of search engines like Google, ultimately compromising the freedom and openness of the internet. While we’re not introducing entirely new legislation, we aim for this proposal to set a high standard. Google has developed an alternative resolution to support journalism. Known as Google Information Showcase, this innovative platform revolutionizes how users access information online.
While Google has admirably organized the world’s information, their self-evaluation as a friend offering coffee shop recommendations is disingenuous; friends typically lack access to global data, AI-driven insights, and infrastructure, let alone being founded on surveillance capitalism.
While copyright concerns are a valid issue, the threat posed by generative AI to creative professionals is a pressing concern: Would Jorge Luis Borges be able to write under today’s economic conditions, where artistic expression is often driven by financial gain? When indifference towards Jorge Luis Borges prevails, perhaps your interest in Philip K. Dick becomes more pronounced instead. The literary and cinematic worlds owe a debt to Jorge Luis Borges’ innovative and philosophical storytelling, as evident in the works of Dick, Nolan, Rushdie, and the Magic Realists, whose own narratives have been profoundly shaped by his pioneering spirit.
Don’t we still long to fantasize beyond the vestiges of human culture’s manufactured norms? Will we surrender creativity entirely, relinquishing control to LLMs and having them dream on our behalf?
Footnotes
- While citing concerns, I’m still uneasy about attributing human-like qualities to language models; it’s crucial to scrutinize this methodology.
- While my intention isn’t to suggest that Netflix as a whole is unhealthily fixated on its own popularity or success, Removed from it, in truth: Netflix has revolutionized content distribution by providing a vast global platform for creatives to showcase their work. It’s difficult.
- The potential outcome of this case may exert a profound impact on the trajectory of Open Source Software (OSS) and open-source fashion movements, an aspect that I intend to explore further in my subsequent writing.
The original essay that initially saw the light of day on. Thank you for the early suggestions offered.